新论文:《WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models》
来自浙江大学、腾讯 AI 实验室和西湖大学的新论文:《WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models》
这篇论文详细的讲解了如何借助 GPT-4V 这样的多模态模型,与开放网络中的网站交互,完成用户的各项指令。
如果你有做过类似的事情的话,会发现其实还是很有挑战的,因为让 AI 遵循指令操作网页,特定的网站相对容易,因为网页元素和路径比较固定,但是开放环境的话,每个网站都不一样,交互方式也千差万别,再加上浮动广告、弹出窗口和网页内容实时更新等等。
具体在实现层面,要先理解当前网页的内容,然后根据用户指令,在网页上选择正确的操作,根据操作的结果再继续下一步操作,直到完成任务。
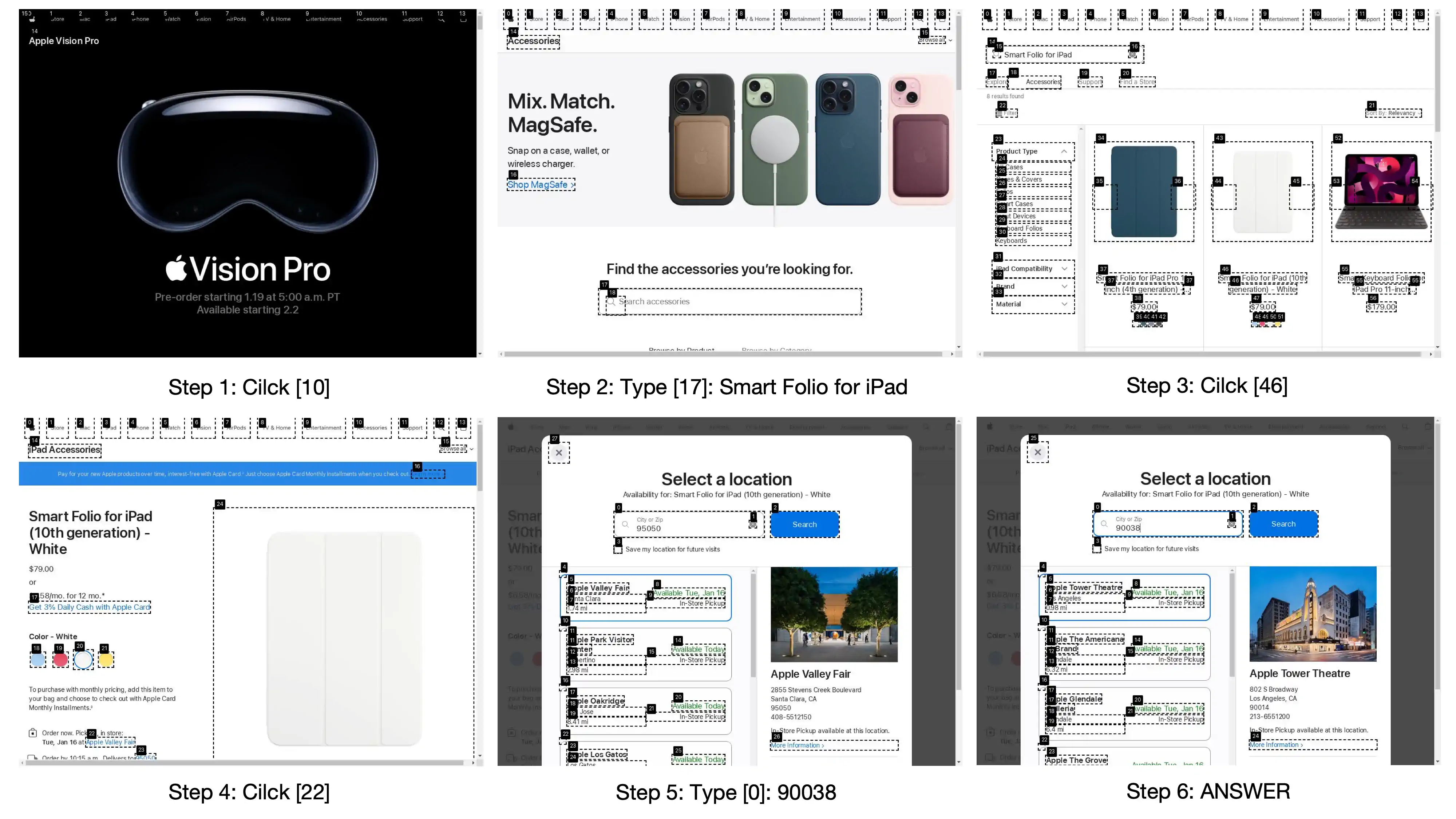
举例来说,我们要去苹果官网查询,附近的哪个苹果店能买到特定型号的 iPad 保护壳(Smart Folio)。如果是人操作的话,要打开官网,找到配件页面,搜索关键字,找到配件查看详情,从详情页选择弹出位置搜索界面,输入邮编,找到最近的苹果店。但这系列操作对于 AI 来说还是很有挑战的。
那么 WebVoyager 是怎么来做的呢?
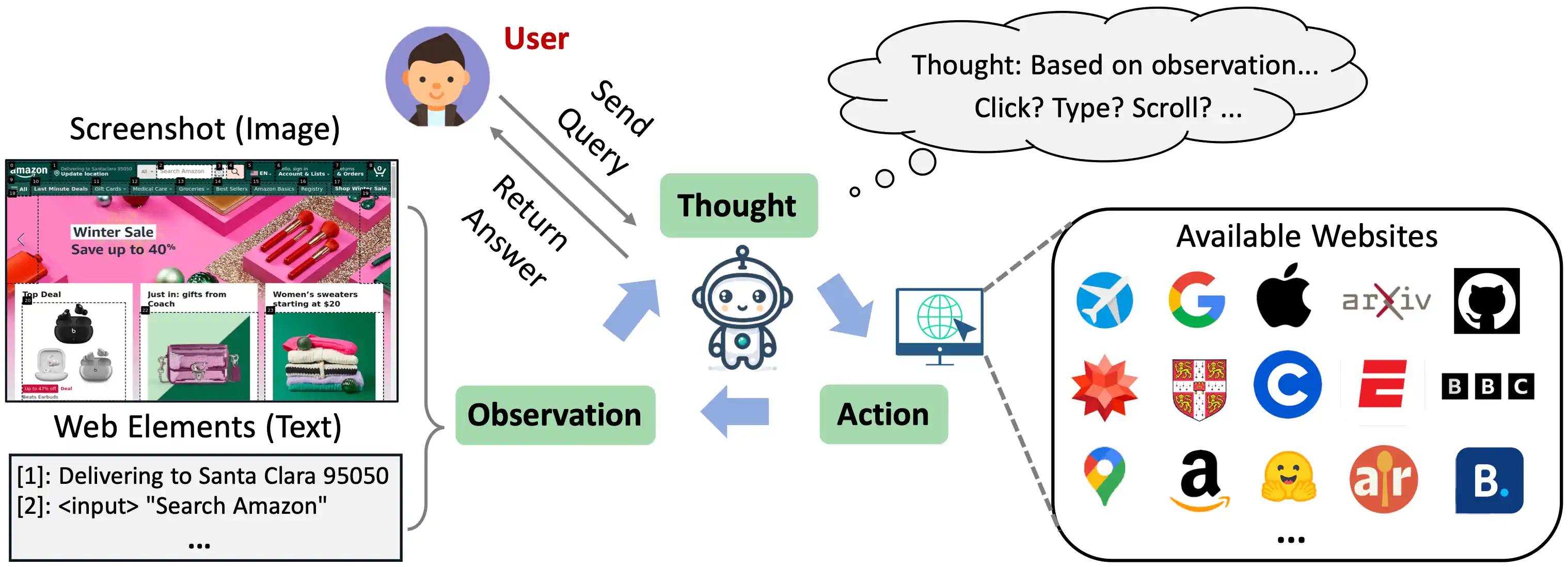
一、AI 如何浏览操作网页?
首先,WebVoyager 不是用的普通浏览器,而是基于 Selenium,这是一个自动化网页测试工具,可以方便的截图,可以自动化操作网页浏览器。
但是要让 GPT-4V 能识别和操作网页元素,还需要对网页上的可以操作的元素进行标记,WebVoyager 开发了一个叫 GPT-4-ACT4 的 JavaScript 工具,它能够根据网页元素的类型自动识别交互元素,并在这些元素上覆盖带有数字标记的黑色边框。
此外,GPT-4-ACT4 还能向智能体提供了一些辅助文本,如交互元素内的文字内容、元素类型以及 aria-label 属性中可能的注释文本,以简化观察过程。
如果你有些自动化测试代码的经验的话,可以知道我们可以用 JavaScript 或者 Python 脚本灵活的操作网页做任意操作,但是对于 AI 来说,如果让它直接写代码可能会出错率比较高,所以 WebVoyager 将常用的网页操作进行了归类,提供了有限的几种操作,例如:点击、输入、滚动、等待、返回上一页等等。
这样 AI 就不需要写代码,而是直接基于这几种操作给出清晰的指令,根据 AI 的指令,WebVoyager 将指令翻译成操作 Selenium 的代码操作网页。
这些为后面 GPT-4V 识别和提供后续指令提供了基础,否则 GPT-4V 无法清晰的描述出下一步要采取的操作。
二、如何让 AI 清晰的给出网页操作的指令?
然后就是 Prompt,Prompt 就是和 AI 交互的指令。要让 GPT-4V 帮助我们完成任务,光有截图还不够,还需要让 AI 能根据截图和任务,清晰的说明下一步如何操作,才能去相应的网站,借助外部工具进行交互。
WebVoyager 采用的是 ReAct 的 Prompt 框架,让 AI 能够根据目标任务和当前状态,推理出下一步的行动,每一步都采用:思考(Thought)、行动(Action)和观察(Observe)的结构,思考推理出行动,行动完成后观察行动后的结果,根据观察的结果进一步思考,思考推理出下一步的行动,这样一步步,直到完成任务。
举例来说要查询附近哪个苹果店可以买到特定型号的 iPad 保护壳,基于 ReAct 的框架是这样做的:
思考 1:我要找哪个苹果店可以买到特定型号的 iPad 保护壳,我需要打开苹果官网 行动 1:打开苹果官网 观察 1:苹果官网已经打开,上面有 Mac、iPhone、iPad、配件……导航
思考 2:iPad 保护壳属于配件,我已经打开配件页面 行动 2:点击打开配件页面 观察 2:配件页面打开,有导航,有推荐配件,有搜索框……
思考 3:我应该使用搜索框输入 Smart Folio 搜索 行动 3:在搜索框中输入 Smart Folio,点击搜索按钮 观察 3:列出了所有 Smart Folio 相关产品,第一项是 Smart Folio for iPad Pro 11,第二项是 Smart Folio for iPad……
思考 4:第一个搜索结果就是我想要的,我需要点击进入详情页面 行动 4:打开第一个 Smart Folio 详情页 观察 4:标题…介绍…图片…苹果商店……
思考 5:点击苹果商店链接查看有哪些商店 行动 5:点击苹果商店链接 观察 5:弹出对话框,有苹果商店列表 1,2,3,4…,有位置搜索框
思考 6:这些苹果商店离我太远,需要按照我的邮编寻找最近的 行动 6:输入邮编到位置输入框,搜索 观察 6:列出了新的苹果商店列表 1,2,3,4…
思考 7:第一个苹果商店就是离我最近的苹果店,任务完成
三、效果如何?
根据论文上的结果显示,WebVoyager 在任务成功率上达到了 55.7%。这个结果显然还达不到替代人类操作的效果,但是作为现阶段来说,已经算是个不错的成绩。未来随着 AI 能力的增强,成功率应该可以做到更高。
目前 WebVoyager 任务失败的原因主要有:
- 导航失败 a) 如果智能体的搜索查询不够精确和明确,它会被海量无关搜索结果淹没。在这种情况下,智能体可能倾向于浏览这些不相关的结果,而不是纠正之前的错误;b) 当只有屏幕的一小部分可滚动时,智能体可能找不到正确的滚动区域,反复进行无效的滚动操作;c) 有时在网页中部,智能体难以决定是向上滚动还是向下滚动。
- 视觉识别不足 a) 智能体无法正确理解一些不常见的模式,比如误将代表发音的字符或数学公式理解错了;b) 智能体没有识别出两次观察之间的微妙差异,误以为操作失败了;c) 由于元素之间位置接近,智能体有时会选错了操作对象。比如,它可能会将相邻的元素混淆,或者把日历上的数字误认为是数值标签。有时,文本信息对于区分密集的网页元素至关重要。
- 幻觉 理解和遵循复杂的提示对智能体来说是一个重大挑战。此外,长时间的操作路径可能导致上下文过于冗长,从而妨碍了有效的指令执行。
总的来说,WebVoyager 是一个很不错的尝试,期待未来 AI 能真正的帮助我们操作网页,解放双手。