AI 生成代码的生命周期 [译]
不管是编写代码、撰写文本、制作图像,还是其它应用,生成式 AI 对众多用户来说都如同一个充满神秘的黑盒。一般而言,用户只需简单地访问网站、安装应用或添加扩展,便可以直接体验到 AI 工具带来的便捷。但是,您是否好奇过这个黑盒背后的运作原理呢?
本文旨在揭开我们的代码 AI 助手 Cody —— 它能深入理解您的整个代码库 —— 在代码 AI 生成过程中所涉及的奥秘。虽然使用大语言模型(LLM)来回应代码 AI 生成请求看似简单,但要在涵盖广泛用例、编程语言、工作流以及其他多变因素的生产环境中实现,确保既满足高质量完成的标准又能保证开发者的满意,却是一项极其复杂的挑战。本文将不仅探讨大语言模型的重要性,还将详述如何将其扩展为一个包含多个预处理和后处理步骤的全功能 AI 工程系统,讨论上下文的作用及其获取方法等多个方面,一起来深入了解代码 AI 生成的完整生命周期吧!
代码自动补全入门
简单来说,一个代码补全的请求会将编辑器中当前的代码片段提交给一个大语言模型(LLM)来进行补全。这个过程,用 ChatGPT 也能轻松完成!来看一个例子:
// sort.jsfunction bubbleSort(array) {|}
即使是这样一个简短的代码片段,我们也能从中提取出大量有用的信息:
- 鉴于光标位于函数体内部,显然用户接下来很可能在这个位置继续编码。
- 我们得知这个文件被命名为
sort.js。 - 光标之前的部分(我们称之为代码的“头部”)提供了强有力的线索,指示我们可能想要添加的代码。
- 光标之后的部分(称为代码的“尾部”)则是空白的,仅包含一个闭合的大括号。
我们可以将这些信息转化成一个给 ChatGPT 的提示,并让它帮我们生成代码实现: https://chat.openai.com/share/27aeb581-2d68-4ac8-94eb-3c64af91f0c6
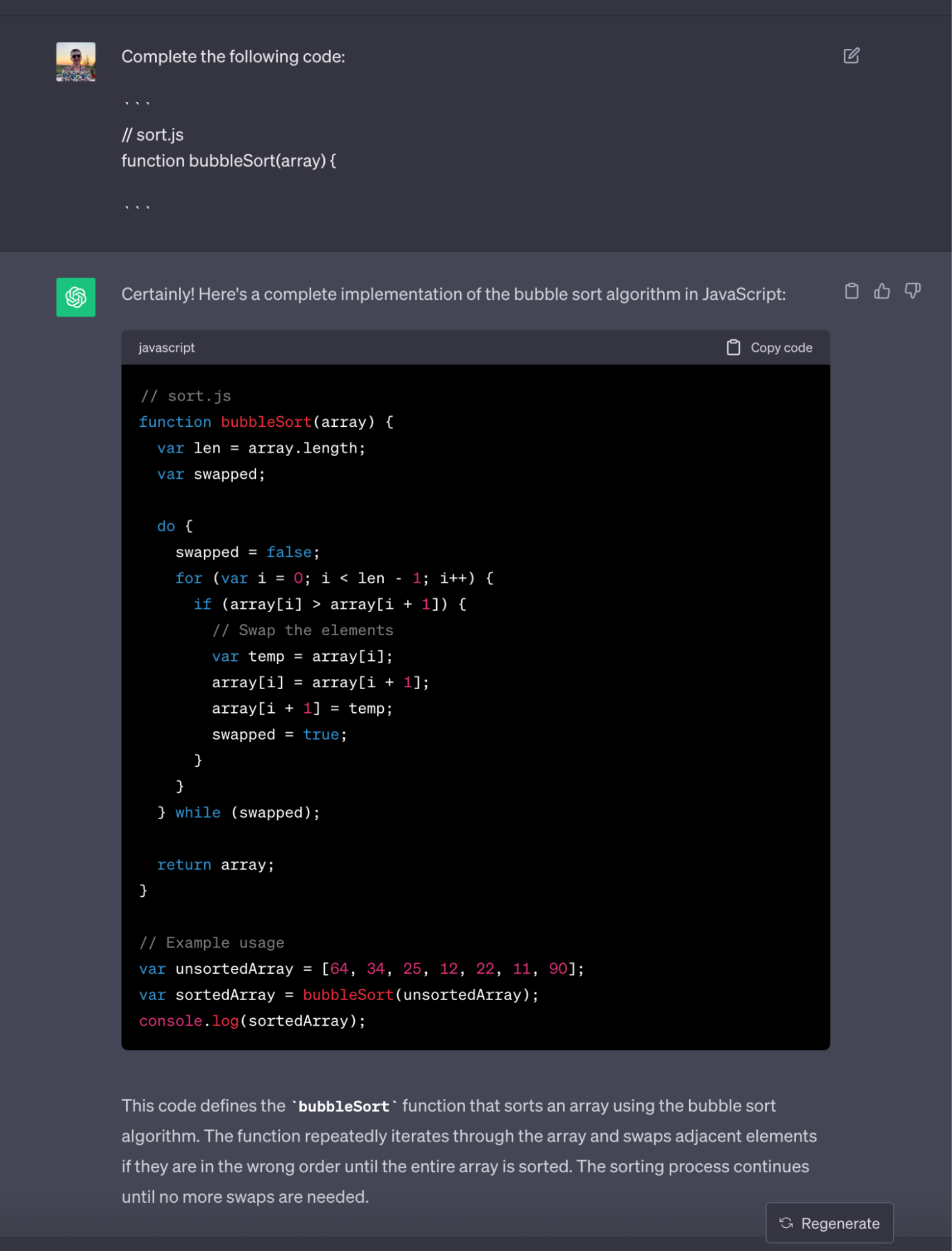
就这样,你利用 AI 完成了一段代码的自动补全!
实际上,这正是我们在开发 Cody 自动补全功能时的起点。要将这个过程转化为一个完整的 VS Code 扩展,你只需实现以下 API 接口:
/*** Provides inline completion items for the given position and document.* If inline completions are enabled, this method will be called whenever the user stopped typing.* It will also be called when the user explicitly triggers inline completions or explicitly asks for the next or previous inline completion.* In that case, all available inline completions should be returned.* `context.triggerKind` can be used to distinguish between these scenarios.** @param document The document inline completions are requested for.* @param position The position inline completions are requested for.* @param context A context object with additional information.* @param token A cancellation token.* @return An array of completion items or a thenable that resolves to an array of completion items.*/provideInlineCompletionItems(document: TextDocument, position: Position, context: InlineCompletionContext, token: CancellationToken): ProviderResult<InlineCompletionItem[] | InlineCompletionList>;
但这种简易实现方式也有其局限性:在实际应用中,这种方式可能太慢,它不能准确理解代码的正确语法结构,也缺乏对代码库上下文的认识。与大语言模型的交互虽然重要,但它只是构建更复杂 AI 工程系统的一部分。让我们深入探索一下,了解将 Cody 打造成一个生产级 AI 应用需要做哪些工作。
如何实现高质量的 AI 代码补全
在我们深入探讨之前,先来了解几个基本原则,这些原则能帮助我们实现高质量的 AI 代码补全。其实,这些原则跟你期望团队新成员能够出色完成任务的期望没什么两样!无论是新来的开发者还是 AI 智能体,要想出色地完成任务,首先需要对手头的任务有所了解。这种理解力我们称之为“上下文知识”。理解得越深入,你在项目中的表现就越出色。
在编码过程中,我们可以利用当前的代码文件来构建这样的上下文知识。开始编写代码时,你需要先将光标放到文档的某个特定位置。以这个位置为起点,我们定义光标之前的文本为“代码前缀”,光标之后的文本为“代码后缀”。编程的基础任务就是在这前后缀之间插入新的代码。
但开发者还需要查阅项目中的其他文件,尝试理解它们之间的联系:这部分扩展的上下文可能来自入职培训材料、个人的思维模式、现有代码和 API 接口等多种来源。
要实现高质量的 AI 代码补全,我们也需要采用类似的思维模式,抓取与当前问题密切相关的上下文知识。现代的大语言模型已经内含了丰富的上下文信息,这些信息来源于它们的训练数据,包括编程语言知识和常用的开源库等。因此,我们的任务是补充特定项目的特定上下文知识。
在 AI 工程领域,这一过程被称为“检索增强生成”(RAG)。这一过程中,我们会从外部知识源(不论是否包含在模型的训练集内)检索特定的知识,比如代码片段和文档,来指导代码的生成过程。就像如果我让你在某个项目的任意文件中写代码,你也会希望了解一些该项目的背景信息。RAG 正是自动化了这个获取背景信息的过程。
在编辑器中实现代码补全时,我们能够利用编辑器提供的 API 来获取尽可能多的上下文信息。例如,你正在哪个仓库中工作?最近有哪些文件被你编辑过?你是想要编写文档字符串、实现函数体,还是确定方法调用的正确参数?
我们通过 Cody 实现了一个两步获取上下文的过程。首先,我们会进行一个基于丰富经验的规划阶段,此阶段旨在确定需要哪种类型的代码补全,接着根据这一判断,获取最适合解决当前问题的上下文信息。
获取到上下文集合后,我们为底层的大语言模型 (LLM) 构建了一个优化的提示。以我们的 ChatGPT 为例,我们会让它“完成以下代码”。接下来,就是让 GPU 投掷骰子,然后给我们一些反馈文本的时候了。这一步通常被称作生成。
在最后一步,我们需要对生成的内容进行一些加工处理。以之前提到的 ChatGPT 示例为例,我们需要清理掉一些不希望出现在文本编辑器中的文本。这一步称为后处理。
综上所述,Cody 的代码补全流程目前包括以下四个步骤:
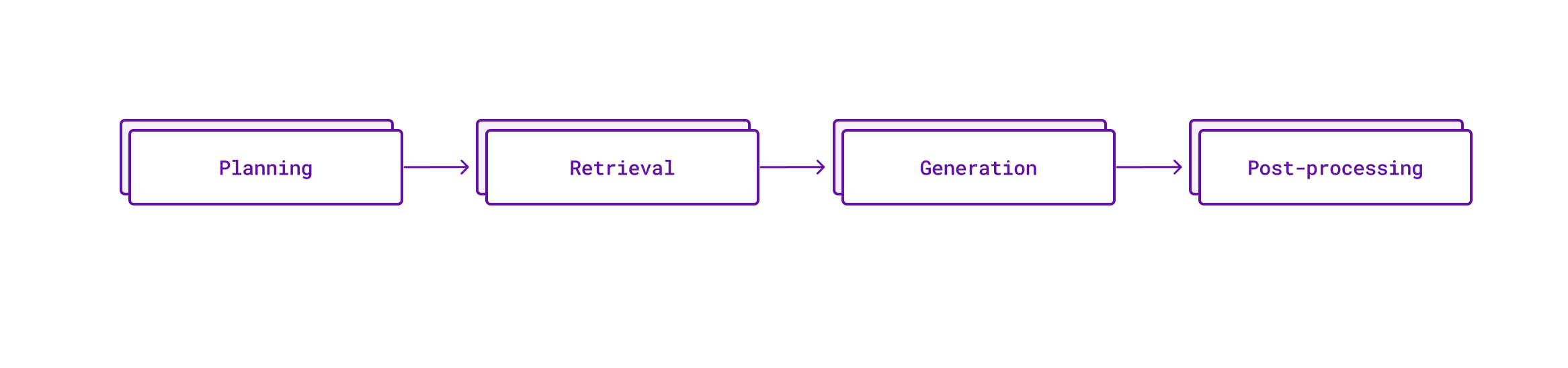
计划
第一步全力以赴地为自动完成请求准备出最佳执行方案。我们需要确定哪些上下文最为合适,以及生成过程中应使用的参数。目前,所有这些步骤都基于规则,不涉及任何 AI 系统的调用,通常能迅速完成,并基于我们逐渐积累的经验规则。这有点像数据库在执行繁重任务之前,先进行查询规划,帮助我们将问题空间分成不同的类别,并针对每个类别进行单独的优化,而非试图找到一个万能的解决方案。
现在,让我们看看这一阶段我们目前在生产环境中使用的一些经验规则:
单行与多行代码补全请求

我们首次发现,在编程时,开发者可能只希望补全当前行的代码,而在另一些场合,他们可能愿意等待更长时间,以获取一个能够完整填写整个函数定义的更详尽补全。为了区分这两种情况,我们结合了语言的启发式分析(比如通过检查缩进和特定的符号)和更精确的语言信息(这部分由 Tree-sitter 提供支持,对此我们将在后续详细说明)。
尽管多行请求的处理流程与单行请求相同,我们在后处理阶段加入了额外的逻辑,确保补全结果能够和已有的文档内容无缝对接。我们的一个重要发现是,如果开发者愿意为多行补全等待更长时间,适当延长处理时间以换取更高的质量是值得的。在我们的生产环境中,这意味着我们会为多行补全使用比单行补全更为复杂的语言模型。
由于这种方法特别依赖于语言特性,我们并不支持所有编程语言的多行补全。但是,我们始终欢迎扩展我们支持的语言列表。由于 Cody 是开源项目,你也可以参与贡献和完善这个列表。
句法触发点
当我们在编程时,光标在代码中的位置,比如说在一个表达式的开头或者是某个代码块的范围内,能够帮助揭示我们打算做什么,以及我们期望代码自动补全的方式。Cody 的初版尝试通过正则表达式来捕捉这些编码时的线索,但这种方式能提供的信息毕竟有限。现在,Cody 采用了一个强大的工具 Tree-sitter,为每个文件建立起了清晰的语法结构图。
Sourcegraph 长期以来都在用 Tree-sitter 来提升我们的代码搜索体验,将它应用于自动补全功能似乎是水到渠成的一步。更具体地,我们通过特制的 WASM 绑定技术,分析当前文档的状态,从而激活针对不同编码场景的自动补全建议——比如,判断光标是否位于注释之中。
Tree-sitter 特别适合进行这类任务,不仅因为它处理速度极快,还能够支持增量解析,即在文档初次解析后,对后续的修改能够迅速响应。它的稳健性也确保了即使在文档正在被编辑且存在语法错误的情况下也能够正常工作。
在规划自动补全的策略时,我们借助 Tree-sitter 对请求进行语法上的分类,比如是要补全一个函数体、写一个文档字符串,还是实现一个方法调用。这样的信息帮助我们针对不同的编程上下文做出调整,或者在生成代码建议时进行参数上的微调。
建议小部件的互动体验
如果你曾经使用过 VS Code,你应该会对那个经常弹出的建议小部件不陌生。它会在你尝试对一个类进行方法调用时出现,展示出该类实现的所有方法,这一切都得益于强大的 IntelliSense 系统。在代码自动补全的场景中,VS Code 为了加强 AI 建议与建议小部件之间的互操作性,提供了一些有用的指引,这些指引是通过 InlineCompletionContext 实现的,它定义了将被建议内容替换的文档范围以及当前被选中的建议。
借助建议小部件来导引大语言模型(LLM)的结果,这种体验简直不可思议:
检索
在使用不同的模型时,所能处理的上下文窗口大小有着各种限制。然而,无论存在什么样的限制,寻找合适的代码示例并以正确的方式加以提示,都将极大地提升自动完成功能的质量,正如前文所述。
在检索实现上,最大的限制之一是延迟。检索是生成工作开始之前的第一步,因此是整个过程的关键环节。我们的目标是尽量缩短从敲击键盘到自动完成提示显现的总时延,确保它在一秒钟以下。考虑到网络延迟和处理速度,我们几乎没有太多余地去执行复杂的检索操作。
Cody 从最初版本起的主要检索手段是关注编辑器上下文。这意味着会考虑您当前打开的其他标签页或您近期浏览的文件。通过这种方式,我们可以得到一些根据相关性排序的代码示例。目前,我们采用滑动窗口Jaccard 相似度 (Jaccard similarity)搜索方法来实现这一点:选取当前光标位置上方的几行作为参考点,然后在相关文件中使用滑动窗口搜索,以寻找最佳的匹配结果。
为了降低客户端的 CPU 负担,我们只对那些最相关的文件进行检索。这些文件通常是您最近查阅过的,而且大多数情况下,这些文件是用同一种编程语言编写的。

在过去的几个月里,我们尝试了多种不同的上下文改进方法。有一个非常有希望的尝试是,重用我们已经在其他 Cody 功能中使用的现有嵌入式索引 (embeddings index)。随着我们在提高嵌入式回应的准确性和减少广泛缓存需求方面的工作进展,我们逐渐开始转向其他方法。
虽然编辑器环境是获取信息的一个渠道,但借助于全球最庞大的代码库之一,我们的探索远不止于此。当前,我们面临的主要挑战之一是如何从众多信息源中筛选并优先考虑相关信息。我们的内部实验表明,掺杂无关信息会质量下降,因此我们正在研究如何只整合那些确实关键的内容。
生成阶段深入
进入下一环节,我们将深入探讨代码自动补全过程的核心——大语言模型 (LLM)。大语言模型负责接受输入提示,并快速生成相关且准确的补全内容。
Sourcegraph 是 Anthropic 的 Claude 的早期积极试用者。基于此,我们最初尝试使用 Claude Instant(因其响应更迅速)进行代码补全的实验,与我们之前讨论过的 ChatGPT 实例相似。不过,我们很快意识到,仅仅使用简单的提示,会使用户体验挫败:
- 不支持中间插入:如果不加入文档后缀中的信息,LLM 常会重复下一行已存在的代码。在大语言模型的术语里,这种情况通常被称为“中间填充”(FITM) 或填充,其挑战在于要在已有文本中间插入新文本。
- 响应延时:我们发现,大量的请求得不到任何回应(LLM 提前终止了请求)。
- 质量问题:即使是提示中非常微小的变化,也可能极大影响补全内容的质量。例如,在一个旨在提高注释准确性的实验中,我们发现,仅仅提及“注释”一词,就会使生成的注释数量增加,而不是实际的代码。
在过去几个月中,我们对 Claude Instant 的提示做了许多改进,以下是其中的几点亮点:
-
提示的首次重大更新包括三项改变,显著提升了响应的质量,尤其是明显减少了无响应的情况:
- 我们根据 Anthropic 的建议,从 markdown 的代码段反引号标签改为 XML 标签。因为 Claude 对 XML 标签定义的结构给予了特别关注,我们发现这个简单的改变显著提高了回应的质量。深入阅读文档总是有益的!
-
我们注意到,如果在指令的结尾添加了额外的空格,会让回答的准确度大大降低。 举个例子,在
bubbleSort的示例中,指令的结尾会包含所有导致光标位置的空白处,这意味着它会以一个换行符加上四个空格结束。在现实世界的应用场景中,往往会有更多的缩进空间,从而导致更多的空格。我们通过删除这些额外的空格并在后续处理中调整空格差异,有效减少了无响应的情况。 -
我们还尝试了一种方法,即在最初的问题中省略某些信息,然后在随后的指令中补充这些信息,这样做就好像是在引导对话的方向。例如,针对以下两行代码的补全任务:
const array = [1, 2, 3];console.log(|可以转化为如下的指令:
Human: Complete the following code<code>const array = [1, 2, 3];</code>Assistant: Sure! Here is the completion:<code>console.log( -
我们的第二个重大更新是增加了“中段填充”功能:除了引用代码的前缀部分,我们还加入了光标后面代码的信息。这个任务并不简单,因为简单的做法往往会导致大语言模型仅仅是重复后缀部分的代码,而不是生成新的代码。为了解决这个问题,我们采用了 XML 标签和利用 Claude Instant 1.2 的高级推理能力,最终取得了成功。
追求更快响应时间的旅程
通用模型如 Claude Instant 极具魅力,它让我们通过更精心编写的指令拓展了系统的功能。但这里面有一个难点:要实现这些高级的推理能力,就必须依赖于更庞大的模型。这直接导致了一个问题——从按下按键到看到反馈的整个过程,即端到端的响应时间,并没有达到我们的预期,这严重地影响了用户体验。早期用户的大量反馈也证实了这一点,使得优化这一状况成为我们团队的共同目标。
在自动完成的整个生命周期中,延迟无处不在,但生成反馈无疑是最耗时的环节。这不仅涉及到后端请求的路由,还包括了对大语言模型(LLM)提供者的请求。为了提升用户体验,我们对这一过程的每个环节都进行了细致的审查。这意味着我们得对流程中的每一个步骤都加入追踪,然后深入分析如何对它们进行优化。在这个过程中,我们发现了许多有趣的见解。
过去几个月里,我们通过一系列措施,成功将单行反馈的 75th 百分位端到端延迟从 1.8 秒减少到不到 900 毫秒:
-
**限制令牌数量和使用停用词:**我们发现,请求中的大部分时间是在等待 LLM 的响应。通过调整输入和输出中的令牌数量,并特别是加入停用词后,我们显著提高了处理速度。
-
**引入流式处理:**随后,我们开始采用流式处理方式,让 LLM 能够逐个令牌地返回结果,这样客户端就可以更灵活地决定何时结束一个反馈请求。
比如,当你想要得到一个函数的定义,而 LLM 开始在当前函数完成后定义另一个函数时,你可能并不希望看到第二个函数。那么,为什么还要等到整个请求完成后才能获得反馈呢?
-
TCP 连接复用: 使用自动补全功能时,我们几乎每敲几个键就会发出一个请求。通常我们不会意识到,每一次新的请求都需要客户端和服务器之间进行一次握手,这一过程会造成额外的延迟。
好消息是,有一个简单的解决方案:保持 TCP 连接不断开。这里有个我们以前未曾注意到的细节:不同 HTTP 客户端对此有不同的默认做法。因为 Cody 的自动补全请求需要从客户端发送到 Sourcegraph 服务器,再传递到大语言模型,我们必须确保在整个流程中 TCP 连接得以有效复用。
-
后端性能提升: 故事还远未结束,我们在后端也做了一些关键的优化。当我们发现 Sourcegraph 服务器上的日志系统会同步写入 BigQuery 时,很快我们就意识到这样做效率不高。现在,我们可以自信地说,服务器端的日志记录过程已经不会再阻碍到核心操作的执行了。真是个小失误!
-
并行请求的限制: 在早期,Cody 的自动补全功能为每个请求触发了多次生成,这是为了弥补最初提示的不足。如果我们能够基于两三个不同的完成选项,选择出最佳的一个,就能显著提高结果的质量。但这也带来了一个问题:现在,响应时间被定义为三次请求中耗时最长的一个。我们已经设法降低了这种影响,目前仅在需要处理多行补全时(这通常更容易出错,对延迟的敏感度也低)请求多个不同的结果。
-
优化之前的完成请求: 这是在客户端层面上取得的一项改进,它在某些情况下显著降低了延迟。设想你正在输入
console.log(,但在console.和log(之间犹豫了一下。开发人员在思考下一步怎么写的时候,这种短暂的停顿是很常见的。这样的小延迟会触发 Cody 发出一个自动补全请求。但如果你迅速恢复输入,之前的结果可能还没来得及显示,因为文档的状态已经发生了变化。
但是,往往初始的请求(即包含
console.的那个)就已经提供了足够的信息,让大语言模型能够生成用户所需的输出。通过实际测试,我们发现这种情况不在少数(大约十分之一的请求会出现这种情况)。因此,我们对客户端进行了改进,加入了特别的追踪机制,用以识别这类情况,并重新利用之前的请求。 -
针对下游性能退化进行跟踪: 当下游推理服务提供商的性能出现退化时,我们全面的延迟监测系统显示出了其价值。我们与 Anthropic 的紧密合作,及时共享数据,这让我们能够迅速解决了性能退化的问题,这一点令我们感到骄傲。
然而,我们的旅程尚未结束,我们清楚地认识到还有很多改进的空间。目前的一个限制是我们的后端服务(Sourcegraph 服务器和推理端点)仅在一个区域部署,这对全球其他地区的用户来说并不是最佳选择。随着新的硬件和算法的出现,我们还有机会进一步提升推理速度。
专为特定场景设计的大语言模型
尽管我们努力加速 Claude Instant 的响应速度,但其作为通用模型的本质意味着它远比实际需要的庞大。为避免仅在局部达到最优,我们探索了专门用于代码生成的特定场景大语言模型。我们认为:
-
特定场景的大语言模型 在其训练领域能展现更佳性能,且体积更小、运行更快。
-
利用专门针对 填充中间 场景训练的先进模型,我们能显著提升响应品质。
-
针对编程模型的分词技术 更加符合我们的需求,意味着我们可以用更少的分词生成更多内容。
-
使用 开源大语言模型 不仅有利于我们对系统进行长期规划,还能更好地控制部署过程(比如,如果我们想在特定地点部署一个推理服务,就必须自行掌控)。
我们特别关注 StarCoder,一个专为我们的需求打造的模型。它根据参数大小有不同的版本,让我们能根据需求选择运行速度更快但精度稍低的模型版本。我们还可以采用 量化技术(一种通过降低模型精度来缩小模型体积的技术),以几乎不损失质量的同时,进一步加速模型运行。
经过与其他模型的长期对比评估,我们对社区用户群进行了广泛的 A/B 测试。在进行了若干次错误修复和性能提升后,我们最近完成了该模型的社区用户推广,显著降低了响应延迟,用户接受率也有了显著提升。
在 Sourcegraph,我们一直坚持认为,我们的强大不在于专注并极致优化某个特定的大语言模型(LLM)(反正,今天精心调优的模型可能几个月后就落伍了!),而在于我们的灵活性,能够运用最佳的工具并向它们提供最贴切的上下文。这开启了众多可能性,使我们能够便捷地为用户切换到更优秀的模型,甚至支持使用像 Ollama 这样的工具进行完全本地化的推理。毕竟,AI 的探索之路才刚刚开始!
后处理
从后端拿到字符串后,我们的任务就算完成了……对吧?事实并非如此简单。有时,我们得到的回应并不总是符合预期。但考虑到我们已经投入了巨大的努力来生成这些文本,我们会尽一切可能来优化这些结果。
在 Cody 的开发过程中,有一个重要的环节被称作后处理。在这一步骤中,我们运用各种方法确保屏幕上展示的文本内容尽量贴近用户的实际需求:
-
**避免内容重复:**大语言模型(LLM)有一个特点,那就是它们特别善于复制内容。不幸的是,这种特性有时会带来我们不希望看到的结果,比如生成的文本中包含了光标上方或下方已经出现过的内容。虽然我们通过指令调整尽可能避免这种情况,但我们也采用了基于规则的系统来应对这一挑战,比如利用 Levenshtein 编辑距离算法来防止重复。
-
**截断多行文本:**自实现多行文本生成以来,我们就认识到有必要根据语言的具体规则来确定何时触发多行生成以及何时停止。
大语言模型在连续输出文本方面表现出色,因此在你请求它填写一个函数体时,它可能会连续不断地添加更多的函数。为了避免这种情况,我们结合使用了两种技术来确定截断文本的最佳时机:
-
**基于缩进:**这种方法利用代码的缩进规则来判断回应何时超出了当前的缩进层级。这种方法的好处在于它几乎不受编程语言的影响,我们只需对一些特殊情况(如闭合的括号)进行处理就可以得到有效的结果。
-
**基于语法:**我之前提到过我们使用 Tree-sitter 进行语法分析,这也是一个利用代码的语法知识来解决问题的例子。借助 Tree-sitter,我们可以精确地知道一个代码块何时结束。采用这种方法后,我们在文本截断的质量上取得了显著进步,并计划将此方法扩展应用到更多编程语言中。
-
-
**如何判定自动生成文本的相关性:**当我们得到一个自动生成的文本时,判断其相关性是非常重要的。目前我们主要针对多行文本生成(在后期处理时会有多个候选文本可供选择,此时可以利用这些信息选出最合适的)采用以下方法:
-
**通过句法解析降低错误文本的分值:**再次利用 Tree-sitter 工具,我们能够自动降低那些含有语法错误的文本的评分。
-
**利用 LLM 提供的概率数据:**相比之前使用 Claude Instant,现在我们能够访问到 LLM 在生成文本时使用的概率数据。通过汇总这些概率值,我们可以更好地理解模型对于某一生成内容的把握程度。
-
-
**排除明显不合适的建议:**虽然这已不如我们刚开始时那般成问题,但我们仍通过正则表达式来标记那些显然不合适的文本。比如,在我们最初使用 Claude 提示时,有时会收到类似 git diff 补丁的反馈。
一个重要的经验教训是,我们不宜过度筛选生成的文本。如果我们过于保守,不展示这些文本,用户的反馈通常是产品无法正常工作,而且他们往往不明白其中的原因。因此,我们更倾向于专注于生成更加相关的文本内容。
数据,数据还是数据……
在 Sourcegraph,我们深信一句话:“如果你无法测量它,你就无法改善它”。正因为此,数据分析在我们优化 Cody 自动补全功能方面起着至关重要的作用。随着时间的推移,这个系统变得更为复杂和高级,因为它需要处理所有 VS Code API 的特殊情况和日益增长的需求。让我们来看看一些具体的案例。
-
建议: 在我们的数据收集系统中,对于用户每一个接收到的建议,都会记录一个事件
-
包括该建议的行数和字符数以及执行方案,让我们清楚知道向用户提供了什么建议。此外,我们还会附上响应时间和其他调试信息。
-
每个建议都有一个唯一的 UUID,使我们能够整合多种数据源,从而对建议有一个更全面的了解。
-
理解 VS Code 何时展示一个建议的确是一个挑战(即,除非你是 GitHub,并能实现一些特定的 VS Code API,这些 API 其他人在生产环境中无法使用)。为了弄清楚 VS Code 决定何时展示一个建议,我们自行实现了一套展示标准。即便如此,如果另一个建议提供者反应更快,我们就无法知道展示的是我们的建议还是他们的。我们尽可能地通过记录用户是否启用了我们已知的一些其他建议扩展来减少这种情况的发生。
-
我们也尝试测量一个建议在屏幕上显示的时间长短。然而,这个测量并不精确,因为缺乏直接的 VS Code API 支持,所以我们是通过一些 VS Code 特定的启发式方法来估计的。
-
-
接受: 一个直观的成功标志:如果用户通过按 Tab 键来采纳一个建议,这强烈表明这个建议是有用的。
-
部分接受: VS Code 特别提供了一个界面,让用户只接受一个建议中的某个词或某一行。对于部分接受,我们还会记录下被添加的字符数,并且只有当至少一个完整单词被插入时,我们才记录为部分接受。
- **完成保留分析:**为了深入理解用户对自动生成的代码片段的实际应用情况,我们跟踪了这些代码片段插入后随时间的变化。我们通过记录文档的修改来更新代码片段初次插入的位置,并定期利用 Levenshtein 编辑距离来评估原始代码片段还保留了多少内容。
依据这些数据,我们得以计算出一个至关重要的指标——代码完成接受率。这个指标综合考虑了延迟、质量等多个因素,用一个数字体现了用户对自动完成功能的认可程度。
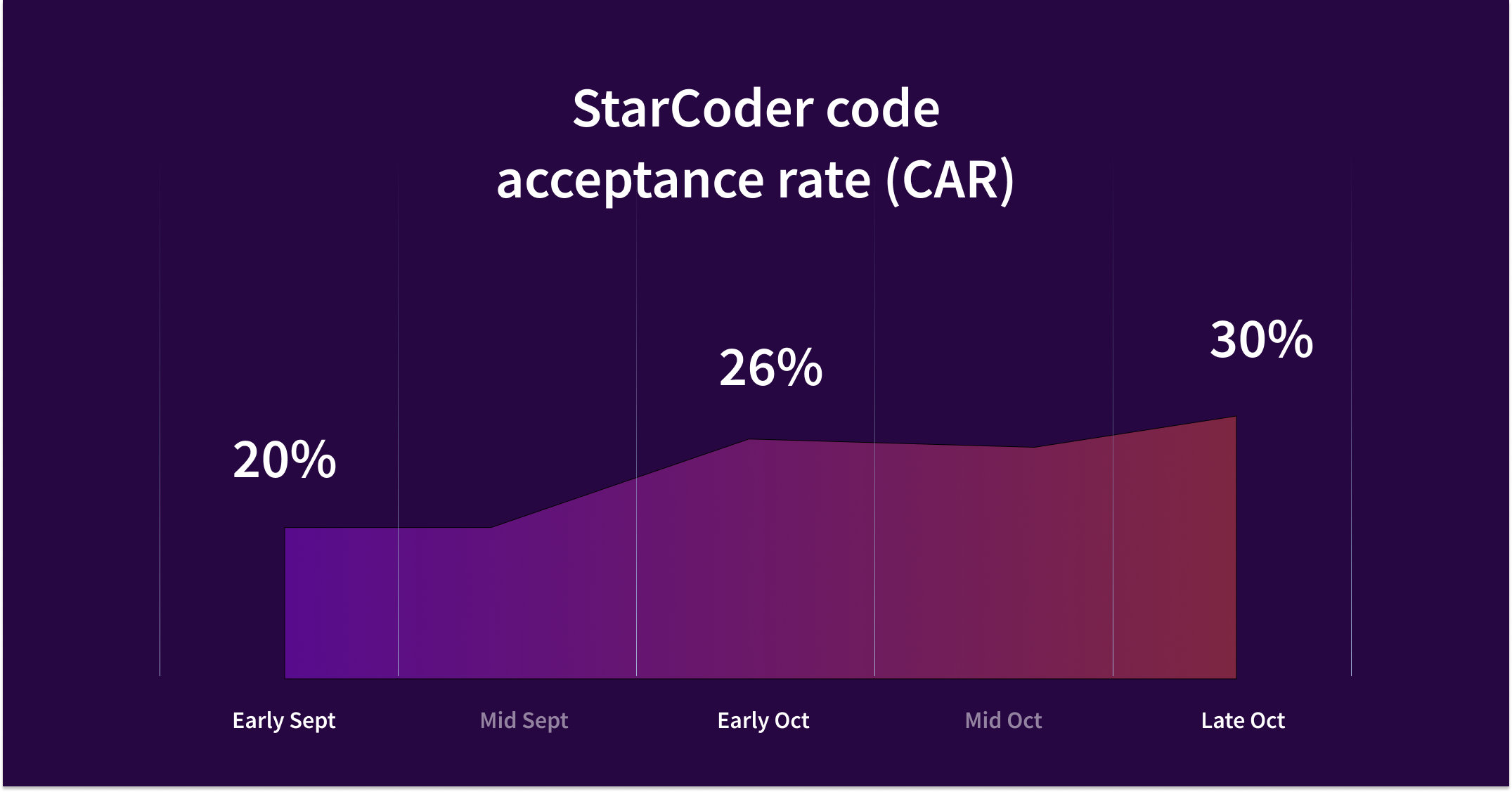
好消息是,我们的用户非常喜欢使用 Cody 的自动完成功能。这使我们能够通过收集用户的反馈迅速进行改进,并据此进行 A/B 测试。我们的日志系统十分敏感,以至于仅仅数小时的记录就能发现到 50ms 的响应延迟。实际上,我们的日志系统非常先进,甚至帮助我们洞察并解决了由 Anthropoic 引起的性能下降问题。
通过向每次自动完成操作中添加丰富的元数据,我们能够区分出哪些功能表现良好,哪些还需要进一步优化。此外,Tree-sitter 语法信息的整合极大地帮助我们定位并解决这些问题。
一个具体的改进例子是,我们减少了在识别到不需要补全的行末尾进行补全的频率,比如当一行代码已经完整时:
console.log();|// ^ showing an autocomplete at this point is likely not very useful 😅
可靠性
在软件开发中,有一个我认为经常被低估的方面是可靠性。更确切地说,我们不仅要确保系统理论上的有效性,还要防止随着时间的推移功能上的退化,不管是因为我们推送了错误的更新,还是基础设施在实际运行中出现问题。
确保系统可靠性的基础措施包括单元测试和监控生产中的错误,这是每个项目都必须执行的。但由于我们处于一个高度不确定性的环境——大语言模型的非确定性特性,我们增加了更多的保护措施。
自动补全测试的重要性
虽然我不打算深入讨论这个话题,但自动化测试已经成为无需争议的加速开发的重要手段。我们对启发式改进的日常工作大多依赖于一个庞大的集成测试套件,这个套件能够直接调用 VSCode 的 provideInlineCompletionItems API。这使我们能够通过定义测试文档和可能的大语言模型(LLM)响应,在自动补全流程的每一个环节上进行验证和断言。这里有一个进行这种测试的示例:
it('properly truncates multi-line responses for python', async () => {const items = await getInlineCompletionsInsertText(params(dedent`for i in range(11):if i % 2 == 0:█`,[completion`├print(i)elif i % 3 == 0:print(f"Multiple of 3: {i}")else:print(f"ODD {i}")for i in range(12):print("unrelated")┤`,],{languageId: 'python',}))expect(items[0]).toMatchInlineSnapshot(`"print(i)elif i % 3 == 0:print(f\\"Multiple of 3: {i}\\")else:print(f\\"ODD {i}\\")"`)})
除此之外,我们还对 VS Code 扩展进行端到端(E2E)测试,这涉及到启动 VS Code 的无头版本并利用 Playwright 工具进行控制,以确保一切运行正常。
大语言模型推理测试套件
因此,我们已经确认了我们的实现可以有效应对静态定义的大语言模型反馈。但是,如何确保我们所做的改进真的能增强用户体验呢?一个办法是监控生产指标,但即便拥有海量数据,通常也会面临反馈周期长的问题,因为需要推出更改、执行实验、等待结论出炉、进行评估,然后再次开始整个过程...
为了加快反馈获取,我们早期就开始收集特定文档状态的静态样例,自动地在我们的完整自动补全系统中进行测试。这些样例主要包含前缀和后缀的配对,多数通过我们自己开发的一个小型 Web 界面手动评估。这对于接入新模型、修改提示内容及调整生成参数非常有用。
随着更多样例的加入和时间的推移,手动评估的工作量越来越大,而且仅仅关注一个文件并不能真实反映用户在其开发环境中的使用情况。测试专门为代码生成设计的大语言模型一直是一个挑战,因此我们参考了如 HumanEval 测试这样的知名解决方案。虽然这些测试通常也只针对单一输入文件,但它们包含可以运行的测试,用以验证解决方案的正确性。这些测试在验证大语言模型的准确性上很有帮助,但仍无法全面反映用户利用开发环境编码的整体场景。
我们明白,为了打造出最佳的自动补全体验,需要做更多工作。因此,我们最近彻底更新了我们的大语言模型推理测试套件,记录了越来越多关于如何在编辑器中使用代码补全的场景。例如,编写一个类后转到另一个文件试图为这个类编写单元测试时,这涉及到整个工作区的配置。我们还引入了一个自动测试系统,用于评估生成的补全内容的正确性。这使我们能够快速全面地测试整个自动补全系统的改动,无需部署就能获知是否提升了体验……而且,这只是开始!
总结
在这篇文章中,我们深入探讨了 Cody 在代码自动生成领域的一个重要过程:它的生命周期。简而言之,Cody 的智能代码生成遵循四个关键步骤:
-
规划 - 审视代码的具体场景,决定出最合适的生成策略,例如,是选择生成单行代码还是多行代码。
-
检索 - 挖掘代码库中的相关代码片段,为大语言模型(LLM)构建最理想的上下文环境。
-
生成 - 借助大语言模型(LLM),根据已有的提示和上下文,智能生成代码片段。
-
后处理 - 对 AI 直接生成的代码进行优化和筛选,确保提供的代码建议最贴切实际需求。
Cody 的宗旨是打造出能够无缝集成进开发者日常工作的高品质代码生成工具。为了达成这一目标,我们需要精确地处理上下文、提示信息和选择合适的大语言模型(LLM)。通过对代码语法的深入分析、智能化地设计提示、选择最适合的大语言模型(LLM)和利用精确的数据反馈,我们在不断地提升 Cody 的代码生成质量和用户接受度。最新的数据显示,Cody 生成的代码片段有高达 30% 的接受率。
想要亲身体验 Cody 的魔力?立即免费开始,开启你的代码自动生成之旅。