代码链:借助语言模型增强的代码模拟器进行推理 [译]
摘要
https://chain-of-code.github.io
代码为构建复杂程序和执行精确计算提供了一种通用的语法结构。当与代码解释器 (interpreter) 配合使用时,我们推测,语言模型 (LMs) 能够通过编写代码来增强“思维链条 (Chain of Thought)”式的推理。这不仅适用于逻辑和算术任务[ 5 , 26 , 1 ],也适用于语义任务,特别是逻辑与语义相结合的任务。例如,如果让一个语言模型编写一个检测文章中讽刺次数的代码,它可能难以编写一个可以被解释器执行的“detect_sarcasm(string)”函数(处理边缘情况会非常困难)。然而,如果语言模型不仅编写代码,还能模拟解释器的行为,通过生成“detect_sarcasm(string)”及其他无法执行的代码行的预期输出,它仍有可能找到有效的解决方案。在本研究中,我们提出了“代码链 (Chain of Code, CoC)”方法,这是一个简单但效果惊人的扩展,用于改进基于代码的语言模型推理。其核心思想是鼓励语言模型将程序中的语义子任务格式化为伪代码 (pseudocode),使解释器能够明确地捕获未定义行为,并由语言模型(作为一个“LMulator”)模拟。实验显示,“代码链”在多个基准测试中都优于“思维链条 (Chain of Thought)”和其他基准线;在 BIG-Bench Hard 测试中,“代码链”达到了 84% 的成绩,比“思维链条”高出 12%。CoC 适用于大型和小型模型,扩展了语言模型通过“用代码思考”正确回答推理问题的范围。






图 1: 我们的代码逻辑链通过使用增强的大语言模型 (Large Language Model, LLM) 辅助的代码模拟器来生成代码并进行逻辑推理。图中用 Python 执行的代码行以红色显示,而大语言模型辅助执行的行则以紫色显示。完整的查询内容可见于图 LABEL:fig:intro_query。图中还展示了 (0(a)-0(c)) 我们的方法在 BIG-Bench Hard 测试中与人类表现的对比结果 [ 34 ]。
1 引言
在一定规模下,语言模型(LMs)展现出解决复杂推理问题的显著能力 [3, 41] - 从编写数学程序 [9] 到解决科学问题 [17]。特别是,当采用“思维链”(Chain of Thought, CoT)的提示方法 [42] 时,这些能力得到了显著提升,此方法将复杂问题拆解为一系列中间推理步骤。CoT 在语义推理任务中表现卓越,但在涉及数字或符号推理的问题上则常遇到难题 [36, 23]。为了应对这一挑战,后续研究通过激发 LMs(例如,那些在 Github [4] 上训练的)来编写和执行代码 [5, 26, 1]。代码特别有用,因为它提供了(i)一个构建和编码复杂程序(如逻辑结构、功能性词汇等,达到图灵完备)的通用语法结构 [19],以及(ii)一个通过结合现有 API 和解释器来执行精确算法计算的接口(比如,从大数乘法到排序一个包含 10,000 个元素的数组),而这些是单纯通过模仿统计上最可能的下一个 Token 来训练的语言模型难以完成的任务。
虽然编写和执行代码可以在许多算术任务上提高 LMs 的推理性能,但这种方法也存在一个问题:许多语义任务很难(有时甚至几乎不可能)用代码来表达。例如,目前还不清楚如何编写一个函数,使其能在检测到字符串中的讽刺时返回布尔值 [36](这涉及的复杂情况几乎无法处理)。从根本上说,使用 LMs 编写程序而不是进行多步文本推理,意味着假设所有中间推理过程(用代码行表示)都需要能被解释器执行。我们是否可以突破这些限制,同时兼顾代码推理和语言推理的优势呢?
在这项研究中,我们提出了一种名为“代码链”(Chain of Code, CoC)的方法。这种方法虽然简单,但意外地有效,它旨在增强大语言模型(LLM/Large Language Model, LM)进行代码驱动推理的能力。在这种机制下,LM 不仅能编写程序,还能有选择地“模拟”解释器,生成一些原本解释器无法执行的代码行的预期输出。其核心思想在于促使大语言模型将程序中的语义子任务转换成灵活的伪代码,这些伪代码在运行时能被明确识别并由 LM 模拟执行。我们将这种方式称为 LMulator(LM 和 emulator 的结合词)。例如,在处理“统计上文中某人讽刺的次数”这样的任务时,LM 可以编写一个程序,调用如 is_sarcastic(sentence) 这类辅助函数,LM 对此进行语言判断并以布尔值形式返回结果,随后这些结果会与程序的其他部分一起被处理。具体而言,我们将大语言模型的推理过程定义为如下(见图 1):LM 编写代码,解释器逐行执行这些代码(用红色标出),如果某行代码执行失败,LM 则模拟出结果(用紫色标出)并更新程序状态(用绿色标出)。CoC 结合了编写可执行代码的优势(这些代码的精确算法计算交由解释器完成)和编写伪代码来解决语义问题并生成输出的优势(这可视为一种简单的格式调整,而大语言模型在这方面表现出了强大的适应性 [ 22 ]),从而使大语言模型能够以代码的形式进行思考。
研究显示,Chain of Code (CoC) 可广泛应用于众多难度较高的数字与语义推理问题,并且在众多热门基准测试中表现出色。特别是在 BIG-Bench Hard 任务[36]上,CoC 不仅超越了普通人类评估者的平均水平,甚至在某些算法性质的任务中,其表现也超越了顶尖人类评估者。据我们所知,CoC 创造了一个新的技术高峰。我们进一步证明了代码解释器的执行和语言模型模拟执行对于达到这一性能是必不可少的,并且这种方法无论是应用于大型还是小型模型上都非常有效 - 这与像 Chain of Thought 那样仅在大规模应用中才显现的提示技术形成了鲜明对比。最后,我们通过跨任务提示基准测试展示了 Chain of Code 如何作为一个多功能推理器,不同于以往工作,我们使用来自不同问题类型的提示作为上下文,仅提供回应的结构而非直接的解决方案。这一发现强调了结合代码的结构和计算能力以及语言模型的推理能力,可以创造出一种集多种优势于一身的推理器。
2Chain of Code: 与 LMulator 合作进行推理
在这一部分中,我们将介绍 Chain of Code (CoC) 的提示方法。这种方法充分利用了语言模型在编码、推理方面的能力,以及利用一个语言模型增强的代码仿真器(LMulator)来模拟代码的运行。首先,我们在第 2.1 节介绍背景信息,随后在第 2.2 节对这种方法进行概述,第 2.3 节讨论其实现方式,最后在第 2.4 节探讨它的能力。
2.1 基本概念
首先,让我们简单回顾一下大语言模型 (Large Language Model, LM) 推理的背景。许多推理技术都得益于上下文学习[ 3 ],这种方法在推断时向模型提供几个示例,而非通过梯度更新权重。这些示例为场景提供上下文和格式,帮助模型在适应新问题时模仿这些示例。这一特性对于大语言模型在新任务中的快速适应和最小数据需求至关重要。
通过上下文学习,人们开发了多种利用人类思维过程并借助工具来提升语言模型性能的方法。我们介绍三种这样的方法,它们为“代码链”提供了理论基础。思维链 (Chain of Thought, CoT) [ 42 ]、记事本 (ScratchPad) [ 26 ] 和思维程序 (Program of Thoughts) [ 5 ] 展示了将问题分解成子步骤的有效性。对于 CoT,这些子步骤用自然语言描述,仿照人在解决复杂问题时的思维过程。而记事本则在模拟代码输出时保留中间步骤的程序状态,使得大语言模型能够像代码解释器一样运作。思维程序则专注于生成代码本身,通过代码解释器执行来解决推理问题。这些方法都在图 1(c) 中展示。
![(a) 思维链 [ 42 ]](https://browse.arxiv.org/html/2312.04474v2/extracted/5282137/fig/code_prelim_cot.png)
![(b) 思维程序 [ 5 ]](https://browse.arxiv.org/html/2312.04474v2/extracted/5282137/fig/code_prelim_pot.png)
![(c) 记事本 [ 26 ]](https://browse.arxiv.org/html/2312.04474v2/extracted/5282137/fig/code_prelim_scratch.png)


图 2: 早期推理方法:为解决复杂问题,(1(a)) “思维链”提示法通过将问题分解为若干中间步骤,(1(b)) “思维程序”提示法涉及编写并执行代码,(1(c)) “ScratchPad”提示法则通过追踪代码中间状态来模拟代码的执行过程。我们的推理方法:“代码链”首先 (LABEL:fig:method_generation) 生成代码或伪代码以解决问题,随后 (LABEL:fig:method_execution) 若可能,使用代码解释器来执行代码,否则使用 LMulator(一种模拟代码的大语言模型)。其中,蓝色高亮表示由大语言模型生成的代码,红色高亮表示这些代码的执行过程,紫色高亮则表示 LMulator 通过绿色标识的程序状态来模拟代码执行。
2.2 代码链
代码链 (Chain of Code) 的灵感来源于人们在面对复杂问题时,会融合自然语言、伪代码和实际运行代码的思维方式,类似于研究者在开发新的通用算法时,会首先基于代码形式构建,然后应用于具体问题。代码链分为两个步骤:(1)生成阶段,即根据提出的问题,大语言模型 (LM) 会生成代码来分析和解决问题;(2)执行阶段,即尝试通过代码解释器来运行这些代码,如果无法执行,则使用大语言模型进行模拟执行。关于具体实现的更多细节,请参见第 2.3 节。
在代码链的生成过程中,针对一个待解决的问题,CoC 会生成一系列以代码形式表现的推理步骤。这些代码构成了问题解决过程的逻辑框架,可以是具体的代码、伪代码或自然语言。例如,图 LABEL:fig:method_generation 展示了一个解决 BIG-Bench 中对象计数问题的潜在生成过程。
代码链的执行过程是其核心创新之一,不仅仅在于生成推理代码,还在于这些代码的执行方式。一旦代码编写完成,系统会首先尝试通过代码解释器执行它。本研究中使用的是 Python,但这种方法适用于任何解释器。如果代码能够成功执行,程序状态将会更新,并继续执行。如果代码不可执行或出现异常,那么将采用语言模型来模拟执行过程。语言模型的输出将用于更新程序状态,然后继续执行。这里,我们将这种方法称为 LMulator(LM 和代码模拟器的结合),这一简单的变革为代码带来了更多结合语义和数值的新应用场景。图 LABEL:fig:method_execution 展示了生成代码的运行过程,如何维持程序状态,并在 Python 执行器和 LMulator 之间进行切换。
2.3 代码链的实施
尽管生成式实现(指通过提示和语言模型生成)相对直接,执行实现的过程稍显复杂。我们的方法是基于 Python 的 try 和 except 语句,同时维持一个程序状态。CoC(代码链)会逐行处理代码。如果某行代码能被解释器执行,则它会被执行,程序状态随之更新,并继续运行。如果代码无法被解释器执行,则语言模型会根据程序的上下文(问题、之前的代码行和程序状态的历史)生成下一个程序状态。这个模拟过程还可以借助于思维链来确定回应方式。生成的程序状态接着被更新,供代码解释器使用。这种程序状态的共享使代码解释器和语言模型模拟器(LMulator)相互交织,适用于任何形式的交织,包括控制流结构,如 for 循环和 if 语句。这个过程持续到整个代码执行完毕,最终以变量 answer 的值形式得到答案,或者在出现无法恢复的错误时,通过语言模型输出 A: answer。
例如,对于代码 answer = 0; answer += is_sarcastic('you don’t say'); answer += 1;,执行过程如下:(1)Python 执行第一行 answer = 0;,更新程序状态,(2)Python 尝试执行第二行但失败,此时 LMulator 模拟执行 answer += is_sarcastic('you don’t say');,并生成新的程序状态,然后在程序中进行更新,(3)Python 执行最后一行 answer += 1;,再次更新程序状态,(4)最后,答案以值 2 的形式被提取出来。
2.4 代码链的能力
代码链是一个具有多项优势的新兴概念:
-
它结合了编程的优点和语言模型的强大语义及常识知识,让代码应用于全新的领域。例如,它能轻松表达一些在传统编程中难以实现的规则(比如,判断哪些食物是水果)。这不仅能改进推理问题的处理,还能使得表达更为灵活和生动,如使用伪代码等。
-
它充分利用了语言模型编写代码的能力,这得益于近年来高质量数据的广泛可用性,成为了最新语言模型的一大优势。
-
它继承了代码推理的多项好处,包括代码的正式且富有表现力的结构(例如,图灵完备性)以及为编程提供的强大计算工具(无论是简单的数字乘法,计算五次方根,还是模拟物理过程)。
-
它还集成了通过中间步骤推理的技术,如“思维链条”,使得语言模型能够在解决问题时进行更多的计算,并提高解决方案的可解释性。
我们在第 3 节的实证研究中观察到,这些优势显著提高了在各种具有挑战性任务中的推理性能。
3 语言推理实验评估
我们选择了一系列具有挑战性的问题,这些问题涉及算术、常识或符号推理等不同类型的推理任务,主要是为了解答以下几个问题:
-
在各种任务中,代码链(CoC)的整体表现如何?
-
CoC 在哪些类型的问题上表现最佳?
-
CoC 的每个组成部分如何影响其整体性能?
-
CoC 随着模型规模的增大表现如何变化?
-
作为一个通用推理工具,CoC 在面对不同任务的提示下(我们称之为跨任务提示)的表现如何?
-
CoC 与经过指令调整的聊天模型(无论是否使用工具)相比表现如何?
我们首先在第 3.1 节讨论了我们采用的方法、进行的消融实验和基准测试,接着在第 3.2 节讨论了我们选取的任务,最后在第 3.3 节展示了实验结果。
3.1 基线和消融实验
我们主要研究的方法是 CoC (Interweave),也称为 CoC (Ours)。此外,我们还提出了两种更简单实现且性能略低的变体:CoC (try Python except LM) 和 CoC (try Python except LM state)。这两种变体首先尝试用 Python 运行整个生成的代码,如果运行失败,则通过 LMulator(大语言模型模拟器)模拟代码执行过程,最终输出答案或中间状态追踪。我们还进行了一些消融实验,其中有些与以往的工作相似。例如,在 CoC (Python) 中,完全使用 Python 运行生成的代码,若代码无法执行,则视为失败。这可以看作是与 Program of Thoughts [5] 或 Program-aided language models [10] 的对比。值得注意的是,在处理某些推理问题时(比如判断一句话是否具有讽刺意味),这种方法面临着巨大挑战。为了更公平的比较,我们可能更关注于仅涉及算法的任务结果。在 CoC (LM) 中,代码由 LMulator(大语言模型模拟器)解释,输出最终答案;在 CoC (LM state) 中,LMulator 输出代码执行的中间步骤状态追踪,这类似于用于推理的 ScratchPad 提示 [26]。值得一提的是,这两种消融实验并未使用 Python 解释器。
我们还将此方法与以下几种基线方法进行了比较:直接问答(直接回答问题的最终答案)和思维链提示 (Chain of Thought,CoT)。在 CoT 方法中,大语言模型使用中间步骤来解决问题。我们将 CoT 作为子步提示领域的标准提示技术 [16, 48],因为这种提示方式是现成可用的。
3.2 任务介绍
我们关注的是 BIG-Bench [34] 中一系列具有挑战性的任务,特别挑选了被称为 BIG-Bench Hard (BBH) [36] 的任务子集,以确保我们面对的是最有挑战性的任务。这些任务被选中是因为它们对语言模型而言难度较大,数据集提供了人类评估者的基准数据和一些思维链条 (Chain of Thought) 的提示。这些共计 23 个任务包括了语义推理(如“电影推荐”)、数字推理(如“多步算术”)以及二者的结合(如“对象计数”)。这样的设计使我们能够评估 CoC 在各种问题中的效果,不仅仅局限于那些适合编程解决的问题。附录图 A1 展示了几种提示方式。我们还在附录部分 A.2 展示了针对小学数学(GSM8K)基准的结果 [7],但我们发现这些问题主要是通过代码的算法解决的。
我们通过少样本 (few-shot) 提示来评估这些任务,即提供三个同类问题的示例作为上下文。我们还引入了一种新的评估模式,即跨任务 (cross-task) 提示,也就是提供三个不同问题的示例作为上下文。在这种情况下,语言模型虽然有推理格式的示例,但并没有具体的推理方法指导。我们认为这能成为评估通用推理能力的重要指标,在许多实际应用场景中(例如聊天机器人),常常需要跨多种任务进行推理。
本研究使用了 OpenAI 系列的多个模型,包括 text-ada-001、text-baggage-001、text-curie-001 和 text-davinci-003(在图表中分别表示为 a-1, b-1, c-1 和 d-3)。同时,我们还考虑了 PaLM-2 的代码微调版本 [6, 12]。在指令调整模型方面,我们与最新的 GPT 变体(gpt-3.5-turbo 和 gpt-4)进行了比较,这些模型的聊天完成模式于 2023 年 10 月运行。除非特别说明,以下结果均使用 text-davinci-003 模型得出。
3.3 结果
问题 1: 总体表现。图 1 和表 1 展示了 CoC 在各项任务中的整体表现(详细数据见表 A1)。我们观察到,无论是在超越人类标准的任务数量还是超出的程度上,CoC 都显著优于其他方法。据我们所知,CoC 达到了 84% 的顶级水平(SoTA)[11]。在某些任务中,CoC 远远超越人类的基准和其他方法,几乎达到了 100%。这些任务虽然在语言描述上复杂,但在编码上却相对简单(例如,涉及多步算术的任务,如 Q: )。我们还注意到,CoT 在许多任务上也超过了人类的基准,而直接回答则表现不佳。
表 1: 总体表现 (%),展示了使用单一任务和跨任务情景下的少样本提示与直接提示的对比。括号内显示了与直接提示相比的差异。
| text-davinci-003 | PaLM 2-S* (代码变体 [12]) | ||||||
| 人类 | 直接 | CoT | CoC | 直接 | CoT | CoC | |
| 单一任务 | 68 | 55 | 72 (+17) | 84 (+29) | 49 | 61 (+12) | 78 (+29) |
| 跨任务 | - | 50 | 55 (+5) | 61 (+11) | 45 | 47 (+2) | 47 (+2) |
问题2: 类型分析。图 3 显示了按问题类型分类的研究结果,具体任务标签可见于表 A1。首先,我们区分了主要基于算法和主要基于自然语言的问题(这些分类见于文献[36])。结果显示,在算法性质的任务上,CoC(代码链)的表现尤为出色,而在自然语言任务上,CoC 与 CoT(思维链)不相上下。这一点尤其令人振奋,因为人们通常会认为,这些偏向语言的任务对代码来说不太适合。关键在于,我们的方法灵活运用了 LMulator(语言模型模拟器),通过模拟代码的执行结果,使之在处理自然语言问题时也能发挥大语言模型的语义推理能力。
图 3 进一步将任务细分为不同的子类别,这些子类别描述了每个问题的回答有多大差异,以及这些代码是否能被 Python 完全执行(区分为“仅 Python”和“Python + LM”)。在基准测试中,有些任务的每个问题使用的是相同的代码或思维链,唯一的变化是输入参数——这种情况下我们将其归类为“重复代码”,反之则为“新代码”。符合预期的是,当重复的代码由 Python 执行时,CoC 的准确率几乎达到了 100%,但这些任务(如多步骤算术问题)对其他基准测试,包括人类评估者来说,却是最具挑战性的。尽管在其他类别的任务中 CoC 面临更多挑战,但在每一个类别中,它相比其他基线测试仍有显著优势。

问题 3: 消融实验。图 4 和 图 5, 以及表 2 展示了为了探究链式代码提示各个方面的动机而进行的消融实验。正如所预期的,那些运行 Python 代码的方法(例如:CoC (交织,Python, 尝试 Python 但若失败则用 LM, 尝试 Python 但若失败则用 LM 状态))在若干任务中实现了 100% 的成功率 - 如果代码是正确的,那么模型每次都将得出正确结果。然而,那些仅依赖 Python 的方法(CoC (Python))在处理非算法任务时表现不佳,几乎全部失败。CoC (Python) 的消融实验与最近的一些研究[10, 5]类似,这些研究表明在数值问题上应用代码推理可以取得良好效果。不包含 Python 解释器的 CoC(例如:CoC (LM, LM 状态))同样表现不佳,但我们可以看到,在 ScratchPad 提示[26]中提出的逐步方法在每个任务上都有所提升。
我们还展示了 CoC 的另一种消融实验(尝试 Python 但若失败则用 LM, 尝试 Python 但若失败则用 LM 状态),其中 CoC 首先尝试用 Python 运行整个代码,若失败则使用大语言模型 (LM) 模拟代码,这种方法表现相当出色。我们再次看到,保持程序状态对于提升性能是有效的。尽管这些方法在性能上略有下降,但由于其简单性,它们是复杂的完全交织式 CoC 的合理替代方案。需要注意的是,这些消融实验在那些确实需要交织代码与语义的场景下表现会大打折扣 - 例如,想象一个场景:需要代码来解析图像输入或访问外部数据库,同时需要语言来解析结果(参见第 4 节的机器人应用)。







图 5: 展示了在所有高难度的 BIG-Bench 任务中的成绩,并与人类的基准水平进行了比较[ 34 ]。每张图中的任务(x 轴)都根据其表现进行了排序。更多关于任务类型的详细信息,请参见表 A1 和图 4。
表 2: 展示了在处理单一任务和多任务场景时,不同方法的整体性能百分比。括号内显示了与完整模型“Interweave”相比的性能差异。
| 代码链 | ||||||
| Interweave(交织) | 尝试 Python 后除去 LM 状态 | 尝试 Python 后除去 LM | 仅 Python | 仅 LM 状态 | 仅 LM | |
| 提示方式 | ||||||
| 处理单一任务 | 84 | 82 (-2) | 80 (-4) | 48 (-36) | 63 (-21) | 57 (-27) |
| 处理多任务 | 61 | 57 (-4) | 60 (-1) | 35 (-26) | 49 (-12) | 50 (-11) |
问题 4: 规模扩大。图 6 展示了 CoC 在不同模型规模下的表现。我们注意到,与“思维链”(Chain of Thought)提示法相似,CoC 的性能改进随着模型规模的增大而提升。实际上,在某些算法任务中,"代码链"(Chain of Code)甚至超越了最优秀的人类评价者(他们没有代码访问权限)。与“思维链”提示不同,后者仅在最大型号模型(d-3)中带来性能提升,CoC 也在更小型号的模型(a-1, b-1, c-1)中超越了直接问答的基准线,这表明对于较小的模型来说,输出结构化代码作为中间步骤比输出自然语言更为容易。
问题 5: 跨任务提示。在跨任务提示中,我们用来自不同问题的几个示例来引导语言模型。在图 6 和表 2 中,我们可以看到所有方法的性能都有所下降。尽管存在这种下降,CoC 在规模化方面仍超越了 CoT 和直接提示,几乎达到了人类的平均表现水平。这是一个指向通用目的推理发展的有希望的标志,这种推理中模型不期望在其提示中接收到类似问题的示例。

图 6: 随模型规模增大的平均性能表现。
问题 6: 指令调优模型的比较。为了比较聊天界面中的指令调优模型,我们用特定指令激发模型,目的是引导其采用特定的推理方法。对于基准测试,我们让模型选择“直接回答”或“逐步思考”(CoT,思维链)。对于 CoC(代码链)的变体,我们让模型“编写 Python 代码来帮助解决问题(如果这样做有助于解决问题的话)”。如果模型编写了程序,我们要么使用 Python 解释器执行该代码,再将执行结果(或失败时的错误信息)回馈给模型以得出最终答案(CoC (Python)),要么让模型模拟代码执行的输出,即作为一个“代码模拟器”(CoC (LM))。CoC (Python) 基准可以视为与配备了 Python 工具的大语言模型的比较。
表 3 显示了各种方法的表现。使用 gpt-3.5-turbo 时,无论是 CoT 还是 CoC (Python),它们都显示出比直接提示更好的效果,尽管都远不及 CoC (Interweave)。在使用 gpt-4 的情况下,尽管其模型能力远超 text-davinci-003,CoC (Interweave) 仍然表现更佳,但差距已经缩小。由于聊天界面的限制,我们无法在这些模型上实现完整的 CoC (Interweave) 方法,但如果能与 gpt-4 配对使用,我们预计会有更大的提升。
表 3: 在聊天界面中,带工具和不带工具使用时,与指令调优模型的比较。
| text-davinci-003 | gpt-3.5-turbo | gpt-4 | ||||||
|---|---|---|---|---|---|---|---|---|
| CoC | Direct | CoT | CoC | CoC | Direct | CoT | CoC | CoC |
| (Interweave) | (Python) | (LM) | (Python) | (LM) | ||||
| 84 | 51 (-33) | 56 (-28) | 56 (-28) | 45 (-39) | 70 (-14) | 78 (-6) | 82 (-2) | 75 (-9) |
4 机器人应用
机器人领域的应用特别适合采用 CoC,因为机器人任务涉及到语义和算法推理,同时还需要通过编码与其他 API(如控制或感知 API [ 19 ])及通过自然语言与用户进行交互。举个例子,面对“按大小对水果排序”的任务时,机器人需要判断哪些物体是水果,并按大小顺序排列,接着把这些决策转化为机器人可以执行的动作。CoC(交织模式)能够在实时运行中利用 Python 解释器和语言模型模拟器(LMulator)来应对这些挑战,这不仅提高了解释性,还能对机器人的操作策略进行更精细的控制。
环境与机器人配置。我们的实验环境是一个放有小物件(如容器、玩具等)的桌面,以及配备真空抓手和手腕式 RGB-D 摄像头的 UR5 机械臂。在我们的实验中,使用的感知 API 是 detect_objects(),它能从手腕摄像头返回检测到的物体列表(包括概率、标签、边界框和分割掩码)。这个 API 首先通过 GPT-4V [ 27 ] 查询以获取物体列表,再利用 Grounding-SAM [ 15 , 20 ] 进行定位。控制 API 是 pick_place(obj1, obj2),这是一个能拾起 obj1 并放置于 obj2 上的编程动作。还有一个文本到语音 API say(sentence),用于机器人与用户的交流。
实验结果。我们通过多种桌面拾放任务来评估机器人的表现,这些任务涉及到语义推理,具体列在 A.4 节。在少样本提示下,我们提供一个关于食品服务问题的示例作为上下文,帮助语言模型理解预期的结构及可用的机器人 API。通过这个单一示例,我们发现模型能够适应新的物体、语言和任务领域(参见图 A3 和图 7 中的一个示例轨迹)。值得注意的是,对于这些机器人任务,我们的主要方法 CoC(交织模式)是唯一有效的方法,因为它需要在 Python 解释器(执行机器人 API)和语言模型模拟器(处理常识问题,如 is_compostable)之间进行逐行交互。




图 7: 展示了在“将桌上的物品分类至堆肥箱和回收箱”任务中的机器人轨迹可视化。首先,CoC 生成解决方案的代码,然后利用 Python 执行这些代码,如果可能的话(例如,使用机器人 API,如检测对象(detect_objects)和移动放置(pick_place))。对于不能用 Python 执行的任务,比如需要常识判断的问题(例如,判断是否可堆肥(is_compostable)),则使用 LMulator 来执行。机器人成功地将便签纸放入回收箱,橙皮放入堆肥箱。详细代码请见图 A3,更多任务执行视频可在我们的网站 https://chain-of-code.github.io/ 观看。
5 相关工作
语言模型推理 随着语言模型的整体性能 [参考文献 6, 37, 31, 11] 和新兴能力(如少样本提示 [参考文献 3] 和抽象推理 [参考文献 42])的显著进步,它们的能力和应用范围不断扩大。特别相关的是,一些研究通过提示来增强推理能力 [参考文献 8]:例如,“思维链式 (Chain of Thought)” [参考文献 42] 提出了将任务分解为中间推理步骤的方法;“最少至最多 (least-to-most)” [参考文献 48] 则提出了一系列逐渐简化的问题;而“ScratchPad” [参考文献 26] 则提出维持代码解释中的中间结果追踪(这是首次展示语言模型 (LMs) 用于我们的“LMulator”所需的代码模拟能力)。类似的,“一步步来思考” [参考文献 16] 通过关键词来引导问题的逐步分解(这些词在 Yang et al. [参考文献 43] 中进一步优化为“深呼吸,一步步解决这个问题”)。除此之外,其他方法将解决方案结构化为图形 [参考文献 45, 2]、计划 [参考文献 39, 25] 或基于专家混合的采样 [参考文献 40, 49]。CoC 在这些工作的基础上,观察到作为一种正式、结构化的方法,代码能够将问题分解为子步骤,这种方法比单纯的自然语言具有更多的优势。
语言模型工具使用 最近,许多研究提出了让语言模型使用各种工具来响应查询的技术 [参考文献 21]。这些工具通常通过提示方式提供给语言模型 [参考文献 7, 14, 6, 9, 44],例如用于数学问题的计算器、代码解释器、数据库等。这些工具还可以在新的模态上提供反馈 [参考文献 35, 46]。为了扩大工具范围,其他研究利用外部工具数据库或对语言模型进行微调 [参考文献 32, 30, 29, 28]。由于工具接口不同,工具的反馈也有助于提升性能 [参考文献 13, 47]。在本研究中,我们利用完整代码的表现力和通用性,以及其结构特性,将代码同时视为工具和框架。
在程序合成领域,语言模型的编程能力已经被公认,它们不仅作为编程助手 [ 4 ] 发挥作用,甚至还展现出独立编程的能力 [ 1 , 18 , 24 ]。这种能力不仅限于处理语言相关的任务,还被扩展到了新的应用场景。例如,在机器人学 [ 19 , 33 ]、实体智能体 [ 38 ] 和视觉 [ 35 ] 领域,语言模型利用编码进行推理的能力得到了应用。此外,一些项目如“思维编程” [ 5 ] 和“程序辅助语言模型” [ 10 ],特别为解决数值推理问题而开发,通过生成代码来进行推理。我们在这里重点探讨的是编写代码、执行代码以及语言模型模拟代码之间的相互作用,这为语言模型在代码应用方面,例如在语义推理上,开辟了新的可能性。
6 结论、局限与未来展望
我们提出了一种名为“链式代码” (Chain of Code) 的方法,它通过编写代码并利用解释器或模拟执行代码的语言模型(此处称为 LMulator)来推动语言模型的推理能力。因此,CoC 不仅能利用代码的表现力和强大的工具,还能通过模拟非可执行代码的执行,将应用范围扩展到代码之外的领域,如语义推理问题。我们已经证明,这种方法在各种语言和数值推理挑战中超越了基准水平,某些任务甚至超过了最佳人类评估者。
然而,这项工作也存在局限。首先,生成和执行代码的双重步骤以及代码与语言执行的交织增加了上下文长度和计算时间。其次,虽然我们没有在语义任务的整体性能上看到下降,但在某些任务中,如“Ruin Names”(判断名字修改是否幽默),代码并没有提供帮助。此外,我们将 LM 和代码的交织实现得相当简单,仅通过字符串追踪程序状态并将其解析为 Python 内置数据类型(例如 dict, tuple)。按照目前的方法,LM 在模拟代码执行时不能修改自定义的 Python 对象。不过,理论上这是可行的,只要这些对象有序列化和反序列化的方法,比如使用 Protocol Buffers 等技术。
未来,CoC 的研究方向很广泛。首先,我们认为融合代码与语言的解释器能够将语言模型的常识性与代码的分析力、结构和可解释性相结合。这样的技术可以将代码和类代码推理应用于更广阔的问题领域,不仅仅局限于基础推理。其次,我们对细化语言模型以使其成为 LMulator,并探索其在语义代码推理上的潜在优势感兴趣。第三,我们发现通过多重路径推理可以带来性能提升,这是一个充满希望的进展。最后,我们相信,与代码的整合将开启通向新领域的大门,例如视觉或数据库,这对新应用如机器人技术和增强现实等领域将是一个有趣的探索方向。
References
- Austin et al. [2021]↑Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al.Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021.
- Besta et al. [2023]↑Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, et al.Graph of thoughts: Solving elaborate problems with large language models.arXiv preprint arXiv:2308.09687, 2023.
- Brown et al. [2020]↑Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al.Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020.
- Chen et al. [2021]↑Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al.Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021.
- Chen et al. [2022]↑Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen.Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588, 2022.
- Chowdhery et al. [2022]↑Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al.Palm: Scaling language modeling with pathways.arXiv preprint arXiv:2204.02311, 2022.
- Cobbe et al. [2021]↑Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al.Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021.
- Dohan et al. [2022]↑David Dohan, Winnie Xu, Aitor Lewkowycz, Jacob Austin, David Bieber, Raphael Gontijo Lopes, Yuhuai Wu, Henryk Michalewski, Rif A Saurous, Jascha Sohl-Dickstein, et al.Language model cascades.arXiv preprint arXiv:2207.10342, 2022.
- Drori et al. [2022]↑Iddo Drori, Sarah Zhang, Reece Shuttleworth, Leonard Tang, Albert Lu, Elizabeth Ke, Kevin Liu, Linda Chen, Sunny Tran, Newman Cheng, et al.A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level.Proceedings of the National Academy of Sciences, 119(32):e2123433119, 2022.
- Gao et al. [2023]↑Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig.Pal: Program-aided language models.In International Conference on Machine Learning, pp. 10764–10799. PMLR, 2023.
- Gemini Team [2023]↑Google Gemini Team.Gemini: A family of highly capable multimodal models.2023.URL https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf.
- Google et al. [2023]↑Google, Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al.Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023.
- Gou et al. [2023]↑Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen.Critic: Large language models can self-correct with tool-interactive critiquing.arXiv preprint arXiv:2305.11738, 2023.
- Khot et al. [2022]↑Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal.Decomposed prompting: A modular approach for solving complex tasks.arXiv preprint arXiv:2210.02406, 2022.
- Kirillov et al. [2023]↑Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick.Segment anything.arXiv:2304.02643, 2023.
- Kojima et al. [2022]↑Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa.Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022.
- Lewkowycz et al. [2022]↑Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al.Solving quantitative reasoning problems with language models, 2022.2022.URL https://arxiv.org/abs/2206.14858.
- Li et al. [2022]↑Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al.Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022.
- Liang et al. [2023]↑Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng.Code as policies: Language model programs for embodied control.In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9493–9500. IEEE, 2023.
- Liu et al. [2023]↑Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al.Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023.
- Mialon et al. [2023]↑Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, et al.Augmented language models: a survey.arXiv preprint arXiv:2302.07842, 2023.
- Min et al. [2022]↑Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer.Rethinking the role of demonstrations: What makes in-context learning work?arXiv preprint arXiv:2202.12837, 2022.
- Mirchandani et al. [2023]↑Suvir Mirchandani, Fei Xia, Pete Florence, Brian Ichter, Danny Driess, Montserrat Gonzalez Arenas, Kanishka Rao, Dorsa Sadigh, and Andy Zeng.Large language models as general pattern machines.arXiv preprint arXiv:2307.04721, 2023.
- Nijkamp et al. [2022]↑Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong.Codegen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474, 2022.
- Ning et al. [2023]↑Xuefei Ning, Zinan Lin, Zixuan Zhou, Huazhong Yang, and Yu Wang.Skeleton-of-thought: Large language models can do parallel decoding.arXiv preprint arXiv:2307.15337, 2023.
- Nye et al. [2021]↑Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al.Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021.
- OpenAI [2023]↑OpenAI.Gpt-4 technical report, 2023.
- Paranjape et al. [2023]↑Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro.Art: Automatic multi-step reasoning and tool-use for large language models.arXiv preprint arXiv:2303.09014, 2023.
- Parisi et al. [2022]↑Aaron Parisi, Yao Zhao, and Noah Fiedel.Talm: Tool augmented language models.arXiv preprint arXiv:2205.12255, 2022.
- Qin et al. [2023]↑Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al.Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023.
- Radford et al. [2019]↑Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al.Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019.
- Schick et al. [2023]↑Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom.Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023.
- Singh et al. [2023]↑Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg.Progprompt: Generating situated robot task plans using large language models.In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 11523–11530. IEEE, 2023.
- Srivastava et al. [2022]↑Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al.Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.arXiv preprint arXiv:2206.04615, 2022.
- Surís et al. [2023]↑Dídac Surís, Sachit Menon, and Carl Vondrick.Vipergpt: Visual inference via python execution for reasoning.arXiv preprint arXiv:2303.08128, 2023.
- Suzgun et al. [2022]↑Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al.Challenging big-bench tasks and whether chain-of-thought can solve them.arXiv preprint arXiv:2210.09261, 2022.
- Touvron et al. [2023]↑Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al.Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023.
- Wang et al. [2023a]↑Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar.Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023a.
- Wang et al. [2023b]↑Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim.Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models.arXiv preprint arXiv:2305.04091, 2023b.
- Wang et al. [2022]↑Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou.Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022.
- Wei et al. [2022a]↑Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al.Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022a.
- Wei et al. [2022b]↑Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al.Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022b.
- Yang et al. [2023]↑Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen.Large language models as optimizers.arXiv preprint arXiv:2309.03409, 2023.
- Yao et al. [2022]↑Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao.React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022.
- Yao et al. [2023]↑Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan.Tree of thoughts: Deliberate problem solving with large language models.arXiv preprint arXiv:2305.10601, 2023.
- Zeng et al. [2022]↑Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, et al.Socratic models: Composing zero-shot multimodal reasoning with language.arXiv preprint arXiv:2204.00598, 2022.
- Zhou et al. [2023]↑Aojun Zhou, Ke Wang, Zimu Lu, Weikang Shi, Sichun Luo, Zipeng Qin, Shaoqing Lu, Anya Jia, Linqi Song, Mingjie Zhan, et al.Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification.arXiv preprint arXiv:2308.07921, 2023.
- Zhou et al. [2022a]↑Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al.Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625, 2022a.
- Zhou et al. [2022b]↑Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, Quoc V Le, James Laudon, et al.Mixture-of-experts with expert choice routing.Advances in Neural Information Processing Systems, 35:7103–7114, 2022b.
附录 A 附录
A.1 语言推理任务的量化结果
表 A1 显示了在 BIG-Bench Hard (BBH) 任务上,针对不同设置的全部单项任务的结果,并根据任务类型和执行方式进行分类。
表 A1: BIG-Bench Hard (BBH) 任务上不同设置的完整结果。
| Srivastava et al. [34] | |||||||||||
| Suzgun et al. [36] | Chain of Code | ||||||||||
| BIG-Bench Hard Task | Rand. | Human (Avg.) | Human (Max) | Direct | CoT | Inter-weave | try Python except LM state | try Python except LM | Python | LM state | LM |
| Boolean Expressions | 50 | 79 | 100 | 88 | 89 | 100 | 100 | 100 | 100 | 95 | 90 |
| Causal Judgement | 50 | 70 | 100 | 64 | 64 | 56 | 57 | 63 | 0 | 57 | 60 |
| Date Understanding | 17 | 77 | 100 | 61 | 84 | 75 | 72 | 74 | 59 | 66 | 57 |
| Disambiguation QA | 33 | 67 | 93 | 70 | 68 | 71 | 67 | 68 | 0 | 67 | 68 |
| Dyck Languages | 1 | 48 | 100 | 6 | 50 | 100 | 100 | 99 | 99 | 1 | 7 |
| Formal Fallacies | 25 | 91 | 100 | 56 | 56 | 55 | 54 | 55 | 0 | 54 | 56 |
| Geometric Shapes | 12 | 54 | 100 | 48 | 66 | 100 | 100 | 100 | 100 | 13 | 44 |
| Hyperbaton | 50 | 75 | 100 | 63 | 64 | 98 | 62 | 55 | 0 | 62 | 55 |
| Logical Deduction | 23 | 40 | 89 | 49 | 66 | 68 | 79 | 57 | 0 | 79 | 58 |
| Movie Recommendation | 25 | 61 | 90 | 85 | 81 | 80 | 83 | 80 | 0 | 83 | 79 |
| Multi-Step Arithmetic | 0 | 10 | 25 | 0 | 48 | 100 | 100 | 100 | 100 | 0 | 1 |
| Navigate | 50 | 82 | 100 | 58 | 94 | 86 | 84 | 68 | 0 | 84 | 68 |
| Object Counting | 0 | 86 | 100 | 30 | 82 | 96 | 98 | 98 | 98 | 57 | 50 |
| Penguins in a Table | 0 | 78 | 100 | 62 | 82 | 90 | 88 | 90 | 88 | 71 | 59 |
| Reasoning about Colored Objects | 12 | 75 | 100 | 64 | 87 | 78 | 74 | 78 | 64 | 64 | 70 |
| Ruin Names | 25 | 78 | 100 | 76 | 70 | 55 | 56 | 46 | 0 | 56 | 47 |
| Salient Translation Error Detection | 17 | 37 | 80 | 66 | 61 | 58 | 63 | 64 | 0 | 63 | 64 |
| Snarks | 50 | 77 | 100 | 70 | 71 | 76 | 76 | 66 | 0 | 76 | 66 |
| Sports Understanding | 50 | 71 | 100 | 72 | 96 | 91 | 93 | 75 | 0 | 93 | 74 |
| Temporal Sequences | 25 | 91 | 100 | 38 | 60 | 98 | 93 | 99 | 93 | 93 | 99 |
| Tracking Shuffled Objects | 23 | 65 | 100 | 25 | 72 | 100 | 96 | 96 | 96 | 71 | 24 |
| Web of Lies | 50 | 81 | 100 | 54 | 100 | 97 | 96 | 96 | 97 | 96 | 50 |
| Word Sorting | 0 | 63 | 100 | 51 | 50 | 99 | 100 | 99 | 100 | 54 | 54 |
| Task Averages | |||||||||||
| NLP Task (avg) | 30 | 71 | 97 | 67 | 74 | 74 | 70 | 68 | 18 | 68 | 63 |
| Algorithmic Task (avg) | 21 | 64 | 92 | 41 | 71 | 95 | 95 | 92 | 80 | 58 | 50 |
| All Tasks (avg) | 26 | 68 | 95 | 55 | 72 | 84 | 82 | 80 | 48 | 63 | 57 |
| Execution Type | |||||||||||
| Python exec (same program) | 13 | 51 | 85 | 38 | 61 | 100 | 100 | 100 | 100 | 33 | 39 |
| Python exec (different program) | 17 | 77 | 100 | 49 | 84 | 89 | 87 | 89 | 84 | 71 | 52 |
| LM exec (same program) | 36 | 66 | 95 | 72 | 73 | 76 | 71 | 65 | 0 | 71 | 65 |
| LM exec (different program) | 35 | 75 | 98 | 53 | 68 | 72 | 73 | 68 | 19 | 73 | 68 |
代表算法任务, 代表 NLP (自然语言处理) 任务(详见 Suzgun 等人 [36])。 标识的任务中,提示间的代码是重复的,可由 Python 执行; 标识的任务要求提示间的代码必须改变,且可由 Python 执行; 标识的任务中,提示间的代码重复,必须由大语言模型 (LM) 执行; 标识的任务要求提示间的代码改变,且必须由 LM 执行。
A.2 GSM8K 基准测试的量化结果
表 A2 展示了在小学数学基准 (GSM8K) [7] 上,采用直接提示、思维链和代码链的表现结果。一般来说,代码链在这些主要是算法性质的任务上,其表现优于思维链和直接提示。由于这些任务均由 Python 单独解决,所有采用 Python 的代码链变体表现一致,与“思维程序”[5]中展示的结果相同。
表 A2: GSM8K [7] 的性能表现(百分比),包括少样本提示下的单个任务和跨任务对比。括号内显示与直接提示相比的性能差异。
| Chain of Code | ||||||||
| Prompt | Direct | CoT | Interweave | try Python | try Python | Python only | LM state | LM only |
| except LM state | except LM | |||||||
| Single task | 16 | 63 (47) | 71 (55) | 72 (56) | 71 (55) | 71 (55) | 45 (29) | 22 (6) |
| Cross task | 14 | 55 (41) | 60 (46) | 60 (46) | 60 (46) | 60 (46) | 41 (27) | 16 (2) |
A.3 语言推理任务的定性结果
图 A1 展示了模型在 BIG-Bench Hard (BBH) 的几个推理任务中的输出结果,而图 A2 则展示了一个关于日期推理的示例。这些例子选取的目的是为了展示 Python 解释器与 LMulator 交错执行的情况。
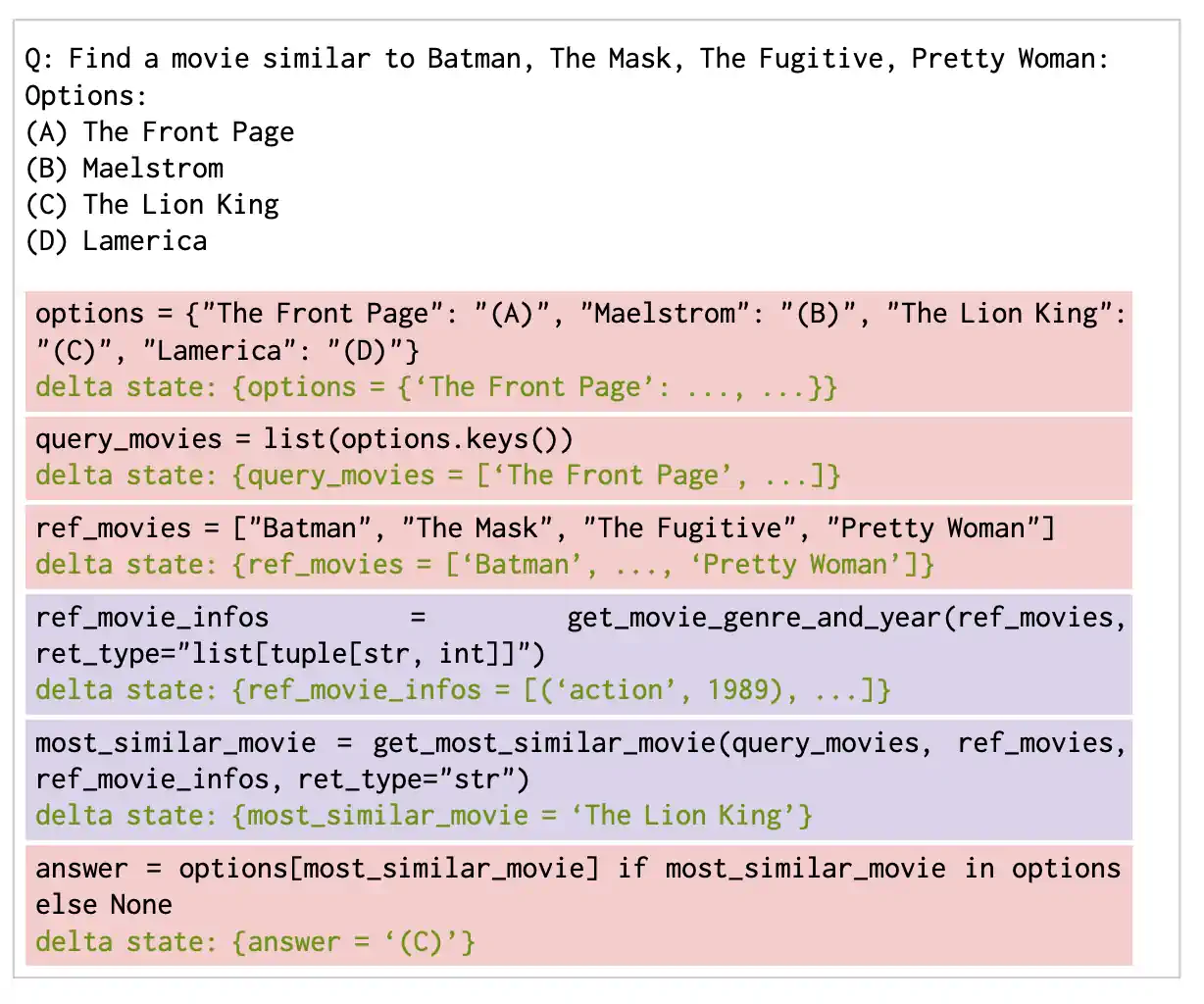



图 A1: 在 BIG-Bench Hard (BBH) 中几个推理任务的模型输出。我们发现,CoC 能够适用于一系列复杂的推理任务,这些任务涉及语义和数值推理。红色高亮显示了 Python 解释器执行的由 LM 生成的代码,紫色高亮则表示 LM 模拟执行的代码。



图 A2: 展示了链式代码如何生成代码并通过 LM 增强型代码仿真器进行推理的一个示例。红色表示用 Python 评估的行,紫色表示用 LM 评估的行。链式思维和直接回答是在 2023 年 10 月使用 gpt-4 进行评估的,而我们注意到当前模型(截至 2023 年 12 月)通过编写代码解决了这个问题,并得到了与链式代码相同的解决方案。
A.4 机器人任务的实验结果
在少样本提示的情境下,我们只用了一个示例:“根据用户的饮食限制提供餐饮服务”。测试时,我们使用以下指令来查询模型:
-
“为素食者准备一个午餐盒。”
-
“给一个素食者制作一个三明治。”
-
“准备制作花生酱三明治所需的食材,放在盘子里。”
-
“Prepare 西红柿炒蛋 in the pot.” (故意混合中英文)
-
“把所有纸质物品放进草绿色的容器里。”
-
“把桌上的物品分别放入堆肥箱和回收箱。”
-
“我的牛排太淡了,你能帮忙调味吗?”
图 A3 展示了单个示例的提示、模型输出以及几个测试指令的执行情况。



图 A3:为机器人任务提供的单个示例提示及其对几个测试指令的模型输出和执行情况。当给出一个示例作为提示(a)时,我们的方法能够应对新的物体、语言和任务领域(b-d)。红色高亮显示的是由 Python 解释器执行的 LM 生成的代码,紫色高亮的是 LM 模拟的代码执行。灰色文字仅作为示例,不输入给模型。值得注意的是,形式为 robot.<func_name> 的代码用于调用机器人 API。
图 A4:图 1 中的完整问题。