如何通过“链式验证”降低大语言模型的“幻觉” [译]
摘要
大语言模型偶尔会生成看似真实但实际上是错误的信息,这种情况被称为“幻觉”。我们研究了模型如何自我纠错。我们提出了一个名为“链式验证 (CoVe)”的方法:模型首先给出初步回答,然后制定问题来核实答案,并确保每个问题的回答不受其他回答的影响,最后输出经过核实的答案。实验结果显示,这种方法有效地减少了在不同任务中产生的误导性信息。
1 简介
大语言模型(LLMs)在包括数十亿文字的庞大数据中进行训练。研究表明,当模型的参数数量增加时,例如闭卷问答这样的任务在准确性上会有所提高,更大的模型能够产生更多正确的信息(参考 Radford 等,2019;Petroni 等,2019)。但有时,即使是最先进的模型,在处理一些在训练数据中不常见的事实时也可能出错,如 Sun 等所述,2023a。当模型出现错误时,它们往往会生成一个看起来合理但实际上是错误的答案。这种现象被称为“幻觉”,如 Maynez 等所述,2020。此外,当任务需要生成多句或多段文字时,这种“幻觉”现象可能会变得更为严重,这是因为所谓的“暴露偏见”问题,参考 Wang 和 Sennrich 的研究,2020。
现如今,语言模型研究已经不仅仅局限于预测下一个词,而是开始专注于它们的推理能力。有研究显示,如果让模型先进行深度思考和推理,再给出答案,那么其在推理任务中的表现会更出色(参考 Wei 等人 2022 的研究)。此外,模型还可以通过自我评估来优化它们的初步回应。为了更进一步,我们研究了一个名为 Chain-of-Verification (CoVe) 的方法,它可以帮助模型在给出答案前先设定一系列的验证问题,然后回答这些问题,确保答案的准确性。事实上,这种独立的验证方式确实可以提供更准确的信息。基于此,我们探索了如何在各种任务中应用这种方法,例如列出问题、闭卷问答和长文本生成。我们提出了一种新方法,该方法可以一边生成验证链,一边提高模型的表现。但我们也注意到,有时模型可能会重复之前的错误,因此我们又引入了一种新的优化方法。这种方法专门处理模型在回应时所关注的上下文,从而进一步提高其在各种任务中的表现。
2 相关研究
语言模型生成中的“错觉”是一个跨多个任务的常见问题,无论是摘要还是开放领域对话,单纯增加训练数据或模型规模都无法完全解决这一问题。为了深入了解这个问题,可以参考 Ji 等人在 2023 年的研究。目前,减少“错觉”的方法主要有三种:训练时修正、生成时修正和使用辅助工具。

图 1:CoVe 方法简介。这种方法在给定用户查询后,通过语言模型生成回应。为了提高其准确性,CoVe 会生成一系列的验证问题,然后回答这些问题进行校验。这种方法可以避免生成中的重复并提高性能。
图 1 文字内容翻译如下:
查询: 列举一些在纽约州纽约市出生的政治家。
基线回应: 以下是一些在纽约州纽约市出生的政治家:
希拉里·克林顿 - 前国务卿和前民主党总统候选人
唐纳德·特朗普 - 美国前总统
迈克尔·布隆伯格 - 纽约市前市长和前民主党总统候选人
...<列表继续>...
计划验证:
希拉里·克林顿在哪里出生?
唐纳德·特朗普在哪里出生?
迈克尔·布隆伯格在哪里出生?
...<问题继续>...
执行验证:
希拉里·克林顿出生于 1947 年 10 月 26 日,地点是美国伊利诺伊州芝加哥。
唐纳德·特朗普出生于 1946 年 6 月 14 日,地点是美国纽约州纽约市皇后区。
迈克尔·布隆伯格出生于 1942 年 2 月 14 日,地点是美国马萨诸塞州波士顿。
...
最终经过验证的回应: 以下是一些在纽约州纽约市出生的政治家:
- 唐纳德·特朗普 - 美国前总统
- 亚历山德里亚·奥卡西奥 - 科尔特兹 - 美国众议院民主党成员
- ...<列表继续>...
在训练时修正中,研究者试图优化语言模型的生成,例如使用强化学习和对比学习等技术来减少“错觉”。而在生成时修正中,常见的策略是在模型的基础上进行额外的推理,例如检测模型生成的可能性或使用多个模型样本来检测“错觉”。
另外,一些研究者选择使用外部工具,例如基于文档的生成技术或链式验证,来帮助减少“错觉”。还有一些方法,如事实检查工具,可以与语言模型结合使用,为生成的内容提供更强的事实依据。
此外,还有一些研究致力于提高系统在逻辑和数学任务上的推理能力,例如使用链式思考或自我验证等方法。
3 连锁验证
我们的策略建立在一个假设上,即我们可以使用一个基础的 LLM。虽然这个模型可能有时会给出一些不实在的答案,但只要给出适当的指导,它就能够自主产生或不依赖其他信息地生成答案。最关键的是,当给这个语言模型提供合适的提示时,它不仅可以创建,还能执行一个自我核实的计划,对其给出的答案进行检查,并在最后给出一个经过改进的答案。
我们称之为 "连锁验证" (CoVe) 的方法包括四个主要步骤:
-
生成初步答案:根据提出的问题,使用 LLM 给出答案。
-
制定核实计划:考虑到刚提出的问题和初步答案,列出一些问题,这些问题的目的是为了检查初步答案中是否有误。
-
进行核实:逐一回答这些核实的问题,并与初步答案进行比对,看是否有不合理或错误的地方。
-
提供经过核实的最终答案:如果在核实中发现了不一致或错误,根据这些核实的结果,给出一个修正后的答案。
这些步骤都是通过以不同的方式提示 LLM 来完成的。更多细节和方法的图示可以在图 1和图 3中查看。
3.1 基础响应
就像往常一样,我们使用 LLM 从左到右生成答案,没有任何特殊技巧。这是连锁验证流程的第一步,但也是我们希望在实验中改进的基线。
由于这些基线响应容易出错,CoVe 试图在后续步骤中识别和修正这些错误。
3.2 验证计划
基于原始查询和基础响应,模型将产生一系列验证问题,以测试原始响应的准确性。例如,如果原始回答中提到了“墨西哥 - 美国战争是从 1846 年到 1848 年之间的美国和墨西哥之间的冲突”,那么一个可能的验证问题就是询问“墨西哥美国战争是什么时候开始和结束的?”。
在我们的实验中,我们使用少量示例提示来引导 LLM 进行这种验证计划。
3.3 执行验证
考虑到已计划的验证问题,下一步是回答这些问题并确认是否有误导。在这个工作中,我们只使用 LLM 在所有步骤中进行验证,因此模型会自我检查。我们研究了几种不同的验证方法。
例如,一种方法是同时进行规划和执行。另一种方法是分两步进行,首先是规划,然后是执行,这样可以避免重复和误导。还有一种更复杂的方法,它独立地回答所有问题。最后,我们还有一个方法,它会在答案验证后进一步检查是否与原始回答存在不一致。
3.4 最终验证的响应
最后,我们生成一个考虑到验证的改进响应。这是通过最后一次提示完成的,考虑到所有之前的步骤和推理。
4 实验
我们使用了多种实验基准来测试 CoVe 在减少误导方面的效果,并与其他基线方法进行了比较。
4.1 任务
我们的基准测试从列表为基础的问题到长答案形式的问题都有涵盖。
4.1.1 Wikidata
我们首先利用 Wikidata API,对 CoVe 进行了一次初步测试。测试的内容是这样的问题:“谁是出生在某个城市的某种职业人士?”举个例子:“有哪些在波士顿出生的政治家?”答案来自于 Wikidata 的知识库。总计测试了 56 个问题,每个问题的答案都有约 600 个。但实际上,LLM 给出的答案列表要短得多。为了评估效果,我们使用了精确度指标,还统计了答案中正面和负面实体的数量。
4.1.2 Wiki-Category 列表
接着,我们面临了一个更为复杂的任务。我们使用了一个名为 Quest 的数据集,它是基于 Wikipedia 的分类列表制作的。把分类名称转换为问题很简单,比如:“请列举一些墨西哥的动画恐怖片”或“请列举一些越南特有的兰花”。因为问题类型丰富,所以这个任务更具挑战性。我们整理了数据集,最后得到 55 个测试问题,每个问题约有 8 个答案。评估方式与上一个测试类似,依旧是使用精确度指标,并统计正负实体数量。
4.1.3 MultiSpanQA
然后,我们在 MultiSpanQA 这个阅读理解基准上测试了我们的方法。这个基准包含了多个答案的问题,这些答案都来自于文本中的不同部分。我们的测试是在一个封闭的环境下,也就是说,没有提供额外的参考资料。测试集包含了 418 个问题,每个问题的答案都很短。例如:“谁是第一个发明印刷机的人,他是在哪一年发明的?”答案是:“Johannes Gutenberg,1450 年”。
4.1.4 长篇传记生成
接下来,我们测试了 CoVe 在长篇文本生成上的表现。评估的重点是看它生成传记的能力如何。模型的任务是,当给出一个实体名称时,为这个实体生成一篇传记。为了评估生成的内容的准确性,我们使用了 FactScore 这个指标。这个指标会用一个特殊的语言模型来检查生成内容的事实准确性。实验证明,这个指标和人的评价是高度一致的。
4.2 基准对比
我们采用了 Llama 65B,这是一个强大的开源模型,作为我们的主要 LLM (由 Touvron 等人在 2023a 中提到),并对所有的模型都使用了贪婪解码策略。Llama 65B 并没有经过特定指令的优化,因此,我们使用了针对每项任务的特定示例来评估其在我们的基准测试中的表现。这就是我们的主要对比基准,而 CoVe 则试图在此基础上做得更好。CoVe 使用了同样的 Llama 65B 作为基础,但在为这些任务提供示例时,它还展示了验证问题和最终的验证响应,如 图 1 和 第 3 节 所示。所以,我们实际上是在衡量如何在原始基准响应的基础上做得更好。对于 CoVe,我们在所有任务上都对比了它的不同版本,尤其是联合版本和分解版本。
我们还将其与经过 Llama 指令优化的模型进行了对比,其中使用了 Llama 2(由 Touvron 等人在 2023b 中提到)。我们不仅仅是简单地评估任务的性能,还加入了“让我们一步步地思考”这样的指令来评估任务。我们发现,经过指令优化的模型在查询时可能会产生不必要的内容,这在基于列表的任务中尤其明显。为了解决这个问题,我们增加了一个指令:“只列出答案,并用逗号分隔”。同时,我们还加入了另一层后处理来提取答案,这是通过使用一个现成的 NER 模型来实现的。但我们仍然认为,尤其是对于像 Multi-Span-QA 这样的任务,少数示例会更有助于显示任务的范围。
在传记的长篇生成方面,我们还与 Min 等人在 2023 中报道的几种模型进行了对比,特别是 InstructGPT、ChatGPT 2 和 PerplexityAI 3。
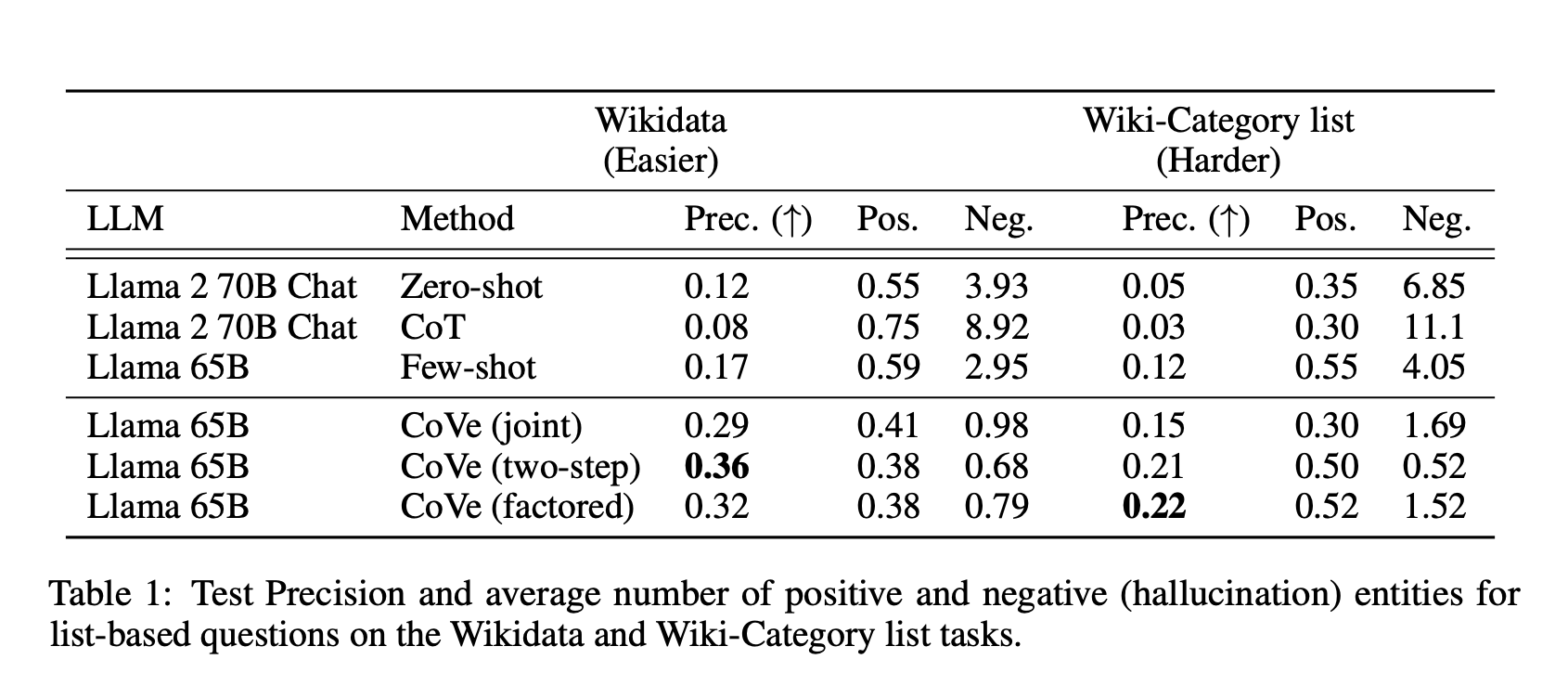
表 1:基于 Wikidata 和 Wiki-Category 列表任务的正负(即错误的)实体的测试精确度和平均数量。
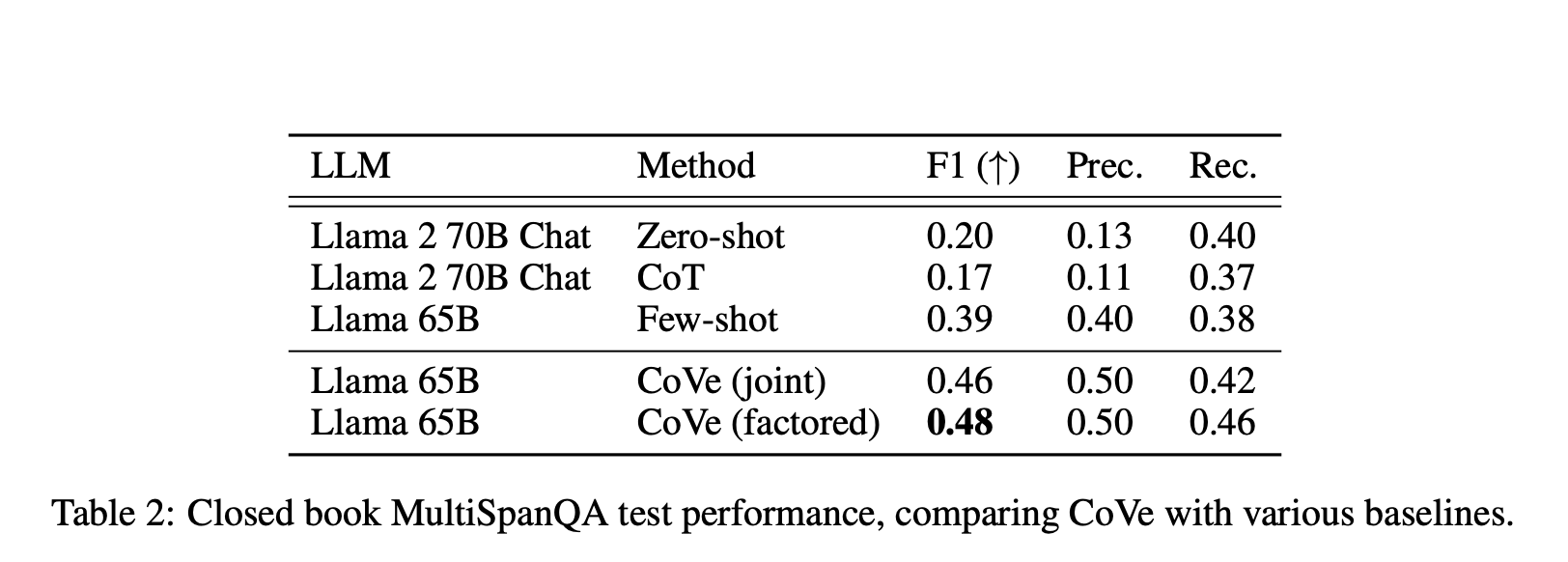
表 2:对比 CoVe 和其他基准的闭卷 MultiSpanQA 测试结果。
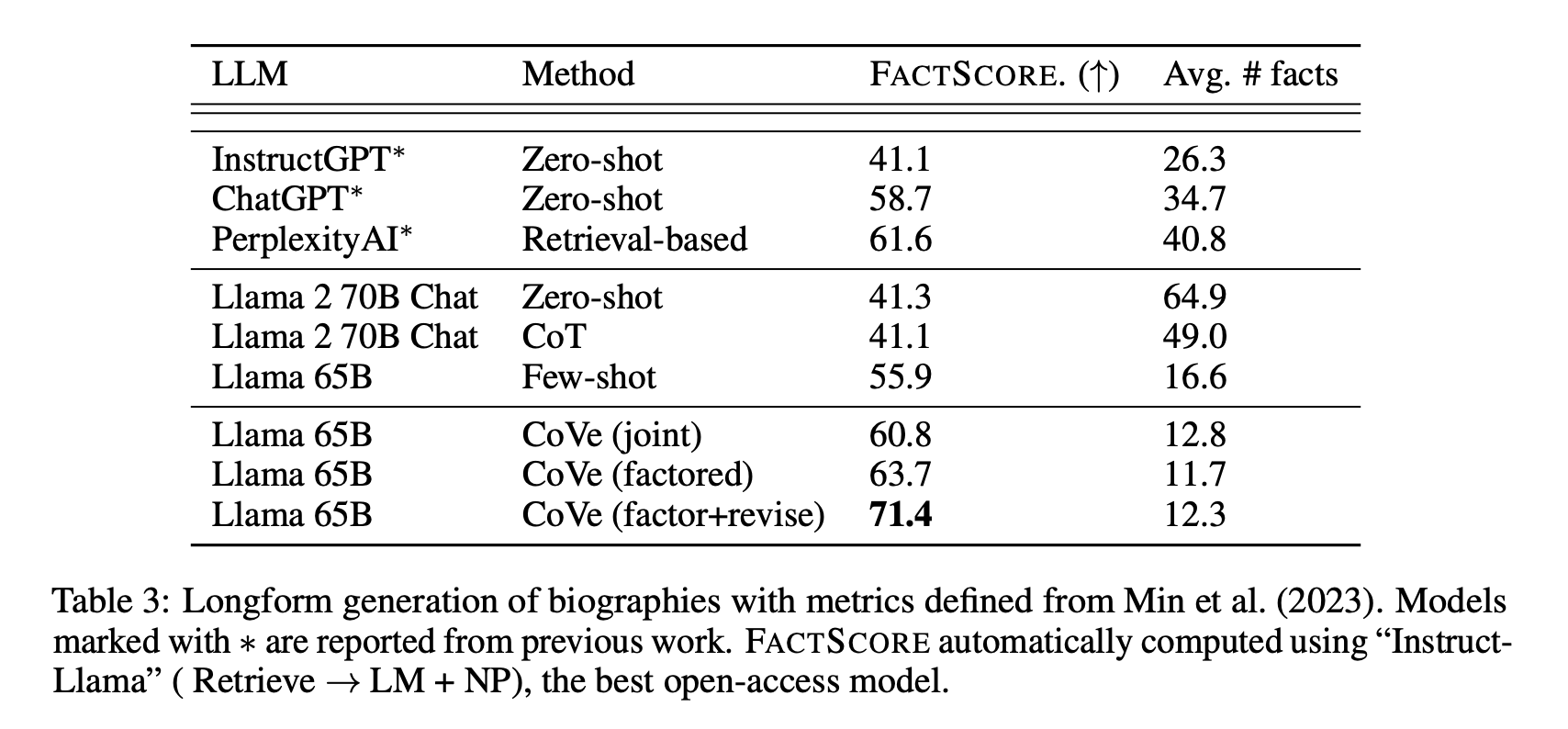
表 3:根据 Min 等人在 2023 中定义的长篇传记生成的指标。带有 * 标记的模型是从之前的研究中报道的,使用了“Instruct-Llama”这一最佳的开源模型来自动计算 FactScore。
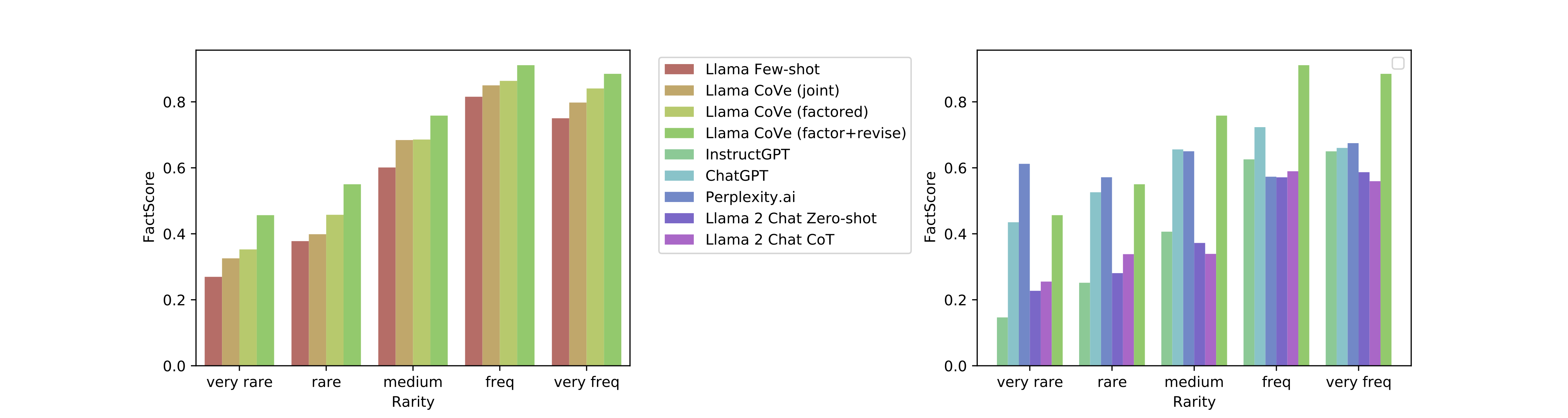
图 2:FactScore 在 CoVe 的各种版本和其他基准上的传记长篇生成的性能分布。
4.3 研究发现
我们主要对以下研究问题进行了探讨:
RQ1
CoVe 是否能有效地降低 LLM 产生的错误内容?
RQ2
CoVe 是否能在不减少正确内容的前提下修正或删除错误的生成内容?
我们的主要发现如下:
CoVe 在基于列表的答案任务上提高了精确度
我们发现 CoVe 在基于列表的任务上大大提高了精确度。例如,在 Wikidata 任务中,它将精确度从 0.17 提高到了 0.36,几乎是原来的两倍。我们还发现,错误答案的数量大大减少,而正确答案的数量只有较小的减少。
CoVe 在闭卷问答上的表现也有所提高
我们还发现,CoVe 在一般的问答问题上也带来了不小的改进。例如,在 MultiSpanQA 上,我们观察到 F1 分数从 0.39 提高到了 0.48,这是由于精确度和召回率都有所提高。
CoVe 在长文内容生成上取得显著进步
在长篇文章生成方面,我们观察到了显著的效果提升,这比简答问答的进步更为显著。FactScore 数据从最初的基线提升了 28%。更为详细的数据分析,你可以参考 图 2。
指导性调整和 CoT 未能显著减少错误信息
我们发现,预训练的 Llama 模型比 Llama 2 Chat 表现得更好。而普遍的指导性调整可能会导致更多的错误信息。尽管有研究表明 CoT 在推理任务上有所帮助,但它似乎并不适合本研究中的错误信息问题。
分类及两步 CoVe 策略增强了性能
不同的 CoVe 方法在各种任务上都显示出了性能的提升。具体数据和对比可以参考我们的研究数据和图表。
进一步的逻辑推理有助于减少错误
在长文内容生成中,我们进一步深化了 CoVe 的推理方法,明确检查了验证答案中的不一致性,这带来了 FactScore 的大幅提升。
表 4 展示了 Wiki-Category 任务上各种不同的 CoVe 验证策略和技术的对比。
CoVe 版的 Llama 胜过其他几种模型
在长文内容生成任务中,我们的基本模型 Llama 65B 在某些方面被其他几种模型超越。但当我们应用 CoVe 技术后,Llama 65B 的性能得到了显著提升,超越了其他几种模型。
短答验证问题比长答查询更准确
在生成长篇答案时,模型可能会产生一些错误信息。但有趣的是,如果对模型进行针对性的单一事实查询,模型往往能够给出正确答案。
LLM 生成的验证问题优于经验法则
在 CoVe 方法中,我们让模型根据任务生成验证问题,并与传统的问题进行了比较,发现模型生成的问题更为准确。
开放式的验证问题比选择题更有效
我们主要使用了期望答案为真实事实的验证问题。但我们也尝试了其他类型的问题,并发现开放式问题比选择题更为有效。
5 结论
我们提出了 Chain-of-Verification (CoVe) 技术,这是一种新方法,可以帮助大语言模型更准确地生成答案。我们的实验表明,这种方法可以显著提高模型的性能。未来,我们还计划进一步扩展这项工作,例如,结合其他技术,如检索增强,来进一步提高模型的准确性。
6 局限性
我们的 Chain-of-Verification (CoVe) 方法致力于减少生成内容中的误导,但不能完全避免。这意味着 CoVe 有时仍可能产生不准确的答案,尽管它已经比原来的方法好了很多。在我们的研究中,我们主要关注的是那些明确错误的事实。但实际上,错误可能以其他方式出现,如逻辑错误或某种观点。值得一提的是,CoVe 提供的答案是带有验证的,这可以帮助用户更好地理解模型的决策,但这也意味着需要更多的计算资源,类似于 Chain-of-Thought 这样的方法。
我们希望通过使模型花费更多时间来检查自己的答案,从而得到更准确的结果。我们的研究表明,这的确可以提高答案的质量,但其改进的上限还受到模型能力的限制。另一个相关的研究方向是让模型使用外部工具来获取更多信息,正如 section 2 所讨论的。虽然我们没有在这篇文章中探讨这个方面,但结合这两种方法可能会带来更好的结果。
引用
- Adolphs et al. (2021)Leonard Adolphs, Kurt Shuster, Jack Urbanek, Arthur Szlam, and Jason Weston.Reason first, then respond: Modular generation for knowledge-infused dialogue.arXiv preprint arXiv:2111.05204, 2021.
- Agrawal et al. (2023)Ayush Agrawal, Lester Mackey, and Adam Tauman Kalai.Do language models know when they’re hallucinating references?arXiv preprint arXiv:2305.18248, 2023.
- Chern et al. (2023a)I Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Graham Neubig, Pengfei Liu, et al.Factool: Factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios.arXiv preprint arXiv:2307.13528, 2023a.
- Chern et al. (2023b)I-Chun Chern, Zhiruo Wang, Sanjan Das, Bhavuk Sharma, Pengfei Liu, Graham Neubig, et al.Improving factuality of abstractive summarization via contrastive reward learning.arXiv preprint arXiv:2307.04507, 2023b.
- Cohen et al. (2023)Roi Cohen, May Hamri, Mor Geva, and Amir Globerson.Lm vs lm: Detecting factual errors via cross examination.arXiv preprint arXiv:2305.13281, 2023.
- Galitsky (2023)Boris A Galitsky.Truth-o-meter: Collaborating with llm in fighting its hallucinations.2023.
- Gao et al. (2023)Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, et al.Rarr: Researching and revising what language models say, using language models.In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16477–16508, 2023.
- Holtzman et al. (2019)Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi.The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019.
- Ji et al. (2023)Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung.Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023.
- Jiang et al. (2023a)Weisen Jiang, Han Shi, Longhui Yu, Zhengying Liu, Yu Zhang, Zhenguo Li, and James T Kwok.Backward reasoning in large language models for verification.arXiv preprint arXiv:2308.07758, 2023a.
- Jiang et al. (2023b)Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig.Active retrieval augmented generation.arXiv preprint arXiv:2305.06983, 2023b.
- Kadavath et al. (2022)Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al.Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022.
- Lanchantin et al. (2023)Jack Lanchantin, Shubham Toshniwal, Jason Weston, Arthur Szlam, and Sainbayar Sukhbaatar.Learning to reason and memorize with self-notes.arXiv preprint arXiv:2305.00833, 2023.
- Li et al. (2022)Haonan Li, Martin Tomko, Maria Vasardani, and Timothy Baldwin.Multispanqa: A dataset for multi-span question answering.In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1250–1260, 2022.
- Li et al. (2023)Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg.Inference-time intervention: Eliciting truthful answers from a language model.arXiv preprint arXiv:2306.03341, 2023.
- Ling et al. (2023)Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, and Hao Su.Deductive verification of chain-of-thought reasoning.arXiv preprint arXiv:2306.03872, 2023.
- Madaan et al. (2023)Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al.Self-refine: Iterative refinement with self-feedback.arXiv preprint arXiv:2303.17651, 2023.
- Malaviya et al. (2023)Chaitanya Malaviya, Peter Shaw, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova.Quest: A retrieval dataset of entity-seeking queries with implicit set operations.arXiv preprint arXiv:2305.11694, 2023.
- Manakul et al. (2023)Potsawee Manakul, Adian Liusie, and Mark JF Gales.Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models.arXiv preprint arXiv:2303.08896, 2023.
- Maynez et al. (2020)Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald.On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020.
- Menick et al. (2022)Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al.Teaching language models to support answers with verified quotes.arXiv preprint arXiv:2203.11147, 2022.
- Miao et al. (2023)Ning Miao, Yee Whye Teh, and Tom Rainforth.Selfcheck: Using llms to zero-shot check their own step-by-step reasoning.arXiv preprint arXiv:2308.00436, 2023.
- Mielke et al. (2022)Sabrina J Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau.Reducing conversational agents’ overconfidence through linguistic calibration.Transactions of the Association for Computational Linguistics, 10:857–872, 2022.
- Min et al. (2023)Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi.Factscore: Fine-grained atomic evaluation of factual precision in long form text generation.arXiv preprint arXiv:2305.14251, 2023.
- Ouyang et al. (2022)Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al.Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Peng et al. (2023)Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, et al.Check your facts and try again: Improving large language models with external knowledge and automated feedback.arXiv preprint arXiv:2302.12813, 2023.
- Petroni et al. (2019)Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel.Language models as knowledge bases?arXiv preprint arXiv:1909.01066, 2019.
- Press et al. (2022)Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis.Measuring and narrowing the compositionality gap in language models.arXiv preprint arXiv:2210.03350, 2022.
- Radford et al. (2019)Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al.Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019.
- Radhakrishnan et al. (2023)Ansh Radhakrishnan, Karina Nguyen, Anna Chen, Carol Chen, Carson Denison, Danny Hernandez, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, et al.Question decomposition improves the faithfulness of model-generated reasoning.arXiv preprint arXiv:2307.11768, 2023.
- Rashkin et al. (2023)Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter.Measuring attribution in natural language generation models.Computational Linguistics, pp. 1–66, 2023.
- Roit et al. (2023)Paul Roit, Johan Ferret, Lior Shani, Roee Aharoni, Geoffrey Cideron, Robert Dadashi, Matthieu Geist, Sertan Girgin, Léonard Hussenot, Orgad Keller, et al.Factually consistent summarization via reinforcement learning with textual entailment feedback.arXiv preprint arXiv:2306.00186, 2023.
- Roller et al. (2020)Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M Smith, et al.Recipes for building an open-domain chatbot.arXiv preprint arXiv:2004.13637, 2020.
- Shuster et al. (2021)Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston.Retrieval augmentation reduces hallucination in conversation.arXiv preprint arXiv:2104.07567, 2021.
- Sun et al. (2023a)Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong.Head-to-tail: How knowledgeable are large language models (llm)? aka will llms replace knowledge graphs?arXiv preprint arXiv:2308.10168, 2023a.
- Sun et al. (2023b)Weiwei Sun, Zhengliang Shi, Shen Gao, Pengjie Ren, Maarten de Rijke, and Zhaochun Ren.Contrastive learning reduces hallucination in conversations.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pp. 13618–13626, 2023b.
- Touvron et al. (2023a)Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al.Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a.
- Touvron et al. (2023b)Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom.Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Varshney et al. (2023)Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu.A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation.arXiv preprint arXiv:2307.03987, 2023.
- Wang & Sennrich (2020)Chaojun Wang and Rico Sennrich.On exposure bias, hallucination and domain shift in neural machine translation.arXiv preprint arXiv:2005.03642, 2020.
- Wang et al. (2022)Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou.Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022.
- Wei et al. (2022)Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al.Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Weng et al. (2022)Yixuan Weng, Minjun Zhu, Shizhu He, Kang Liu, and Jun Zhao.Large language models are reasoners with self-verification.arXiv preprint arXiv:2212.09561, 2022.
- Wu et al. (2023)Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi.Fine-grained human feedback gives better rewards for language model training.arXiv preprint arXiv:2306.01693, 2023.
- Yu et al. (2023)Wenhao Yu, Zhihan Zhang, Zhenwen Liang, Meng Jiang, and Ashish Sabharwal.Improving language models via plug-and-play retrieval feedback.arXiv preprint arXiv:2305.14002, 2023.
- Zhang et al. (2023)Muru Zhang, Ofir Press, William Merrill, Alisa Liu, and Noah A Smith.How language model hallucinations can snowball.arXiv preprint arXiv:2305.13534, 2023.
- Zhao et al. (2023)Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing.Verify-and-edit: A knowledge-enhanced chain-of-thought framework.arXiv preprint arXiv:2305.03268, 2023.
7 CoVe - 进一步的细节
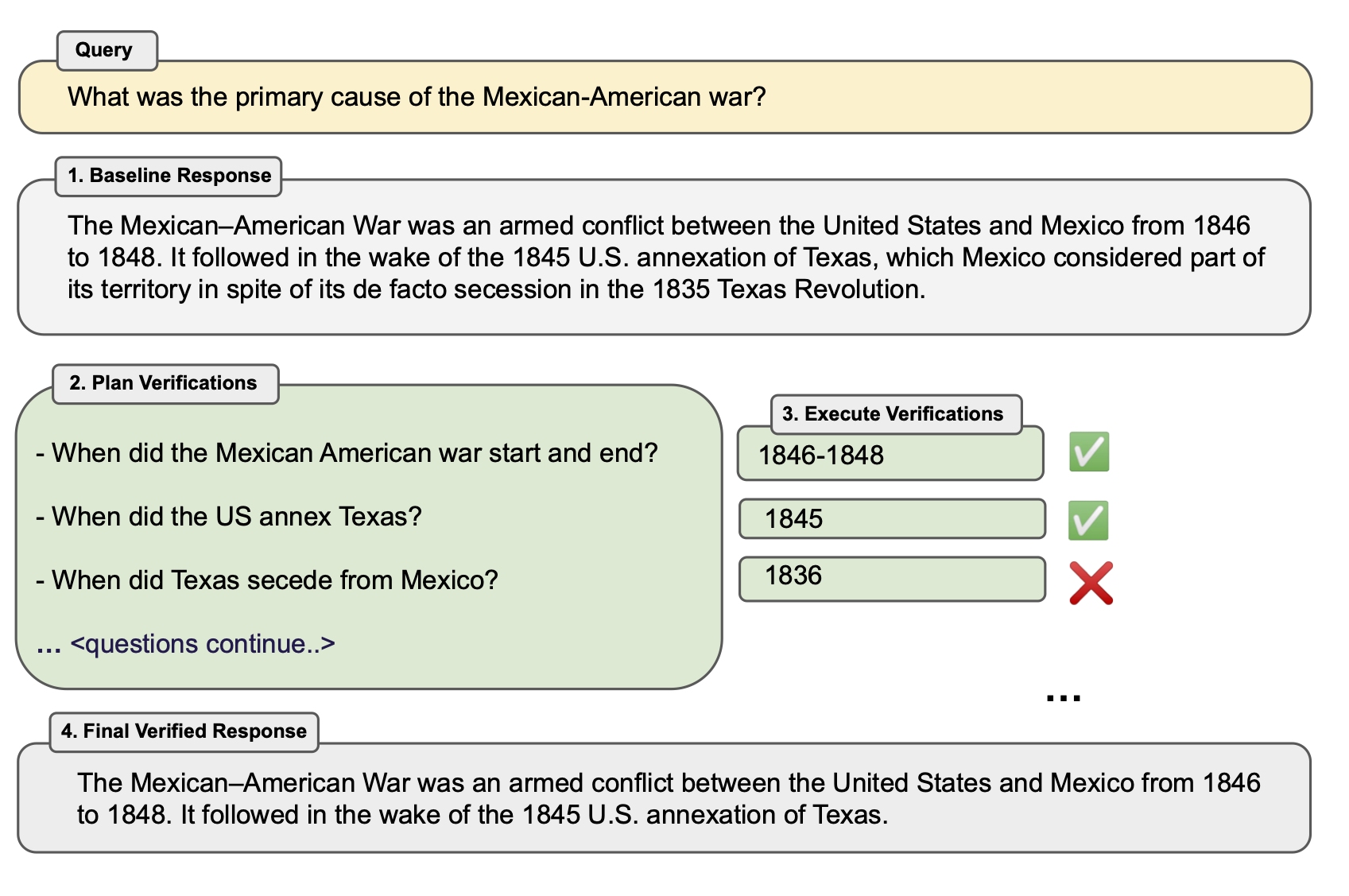
图 3:对于长篇生成,Chain-of-Verification (CoVe) Factor + Revise 方法在我们的长篇生成实验中是最有效的。CoVe Factor + Revise 模型独立地确定哪些事实与其执行的验证一致(如图中的勾号和叉号所示)。通过这个额外的步骤,我们的目标是忽略不一致的事实,并使用一致的事实重新生成响应。
图 3 翻译如下
查询:墨西哥 - 美国战争的主要原因是什么?
基线响应 墨西哥–美国战争是从 1846 年到 1848 年之间美国和墨西哥之间的一场武装冲突。它紧随着 1845 年美国对德克萨斯的吞并而来,尽管德克萨斯在 1835 年的德克萨斯革命中实际上已经脱离墨西哥,但墨西哥仍然认为德克萨斯是其领土的一部分。
计划验证
墨西哥 - 美国战争是什么时候开始和结束的?
1846-1848美国何时吞并德克萨斯?
1845德克萨斯何时从墨西哥独立?
1836
执行验证
...<继续提问>...
最终验证响应 墨西哥–美国战争是从 1846 年到 1848 年之间美国和墨西哥之间的一场武装冲突。它紧随着 1845 年美国对德克萨斯的吞并而来。
8 提示模板
我们为下面的长篇传记生成任务提供提示模板,用于 CoVe 的不同步骤和变体(参见section 3)。其他任务的模板类似,但使用了那些任务的少数例子。
8.1 生成基线响应
Q: 告诉我关于 <person> 的简介A: <person 的简介>Q: 告诉我关于 <person> 的简介A: <person 的简介>Q: 告诉我关于 <person> 的简介A: <person 的简介>Q: 告诉我关于 <person> 的简介A:
表 5:用于传记生成任务的少数提示。其他任务也使用相同的标准少数设置(使用该特定任务的 3 个例子)。
8.2 计划验证
上下文: Q: 告诉我关于 <person> 的简介。A: <关于 person 的段落>响应:<段落中的事实>, 验证问题<段落中的事实>, 验证问题上下文: Q: 告诉我关于 <person> 的简介。A: <关于 person 的段落>响应:<段落中的事实>, 验证问题<段落中的事实>, 验证问题上下文: Q: 告诉我关于 <person> 的简介。A: <关于 person 的段落>响应:<段落中的事实>, 验证问题<段落中的事实>, 验证问题上下文: Q: 告诉我关于 <person> 的简介。A: <关于 person 的段落>响应:
表 6:CoVe 的步骤 (2) 涉及到计划验证问题。在传记任务中,我们将长篇生成分为其个别段落(例如,在传记情况下的句子,这是由于过长的上下文长度,我们不需要为其他任务这样做)。然后,模型为其在每个段落中观察到的每个事实生成一个验证问题(一个段落可能有多个事实)。
8.3 执行验证
Q: 验证问题A: 答案Q: 验证问题A: 答案Q: 验证问题A: 答案Q: 验证问题A:
表 7:在 CoVe 的步骤 (3) 中,模型然后为每个验证问题生成一个答案。再次使用 3 个少数示例。
8.4 生成最终验证的响应
上下文: <原始段落>。来自另一个来源,<执行验证步骤的输出:Q + A><执行验证步骤的输出:Q + A>响应:<修订和一致的段落>上下文: <原始段落>。来自另一个来源,<执行验证步骤的输出:Q + A><执行验证步骤的输出:Q + A>响应:<修订和一致的段落>上下文: <原始段落>。来自另一个来源,<执行验证步骤的输出:Q + A><执行验证步骤的输出:Q + A>响应:<修订和一致的段落>上下文: <原始段落>。来自另一个来源,<执行验证步骤的输出:Q + A>响应:
表 8:在 CoVe 的步骤 (4) 中,模型然后被呈现其原始生成(分为段落,例如,在传记情况下的句子,由于过长的上下文长度,我们不需要为其他任务这样做)以及自己的验证步骤结果。模型被告知这些信息来自“另一个来源”。模型需要基于两个来源之间一致的事实来合成一个新的最终答案。
8.5 Factor+Revise: 确定哪些事实是一致的
上下文: <原始事实>。来自另一个来源,<执行验证步骤的输出:Q + A>响应:一致。<一致的事实>上下文: <原始事实>。来自另一个来源,<执行验证步骤的输出:Q + A>响应:不一致。上下文: <原始事实>。来自另一个来源,<执行验证步骤的输出:Q + A>响应:部分一致。<一致的部分>
表 9:在 CoVe (Factor + Revise) 变体中,作为步骤 (3) 的一部分,模型被明确地要求确定哪些事实在两个来源之间是一致的。然后可以将一致的事实拼接在一起。
9 ChatGPT 示例截图
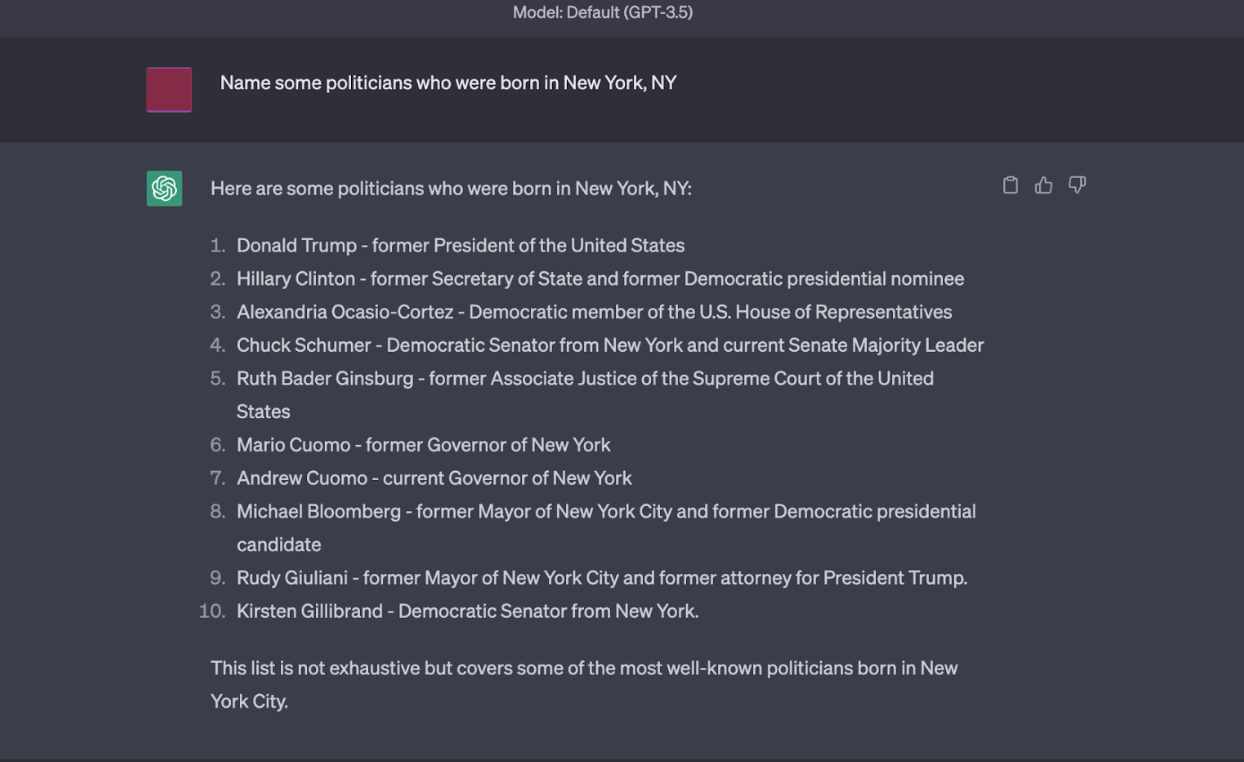
图 4:ChatGPT 为这个问题生成了几个幻觉,例如 Hillary Clinton 和 Michael Bloomberg。
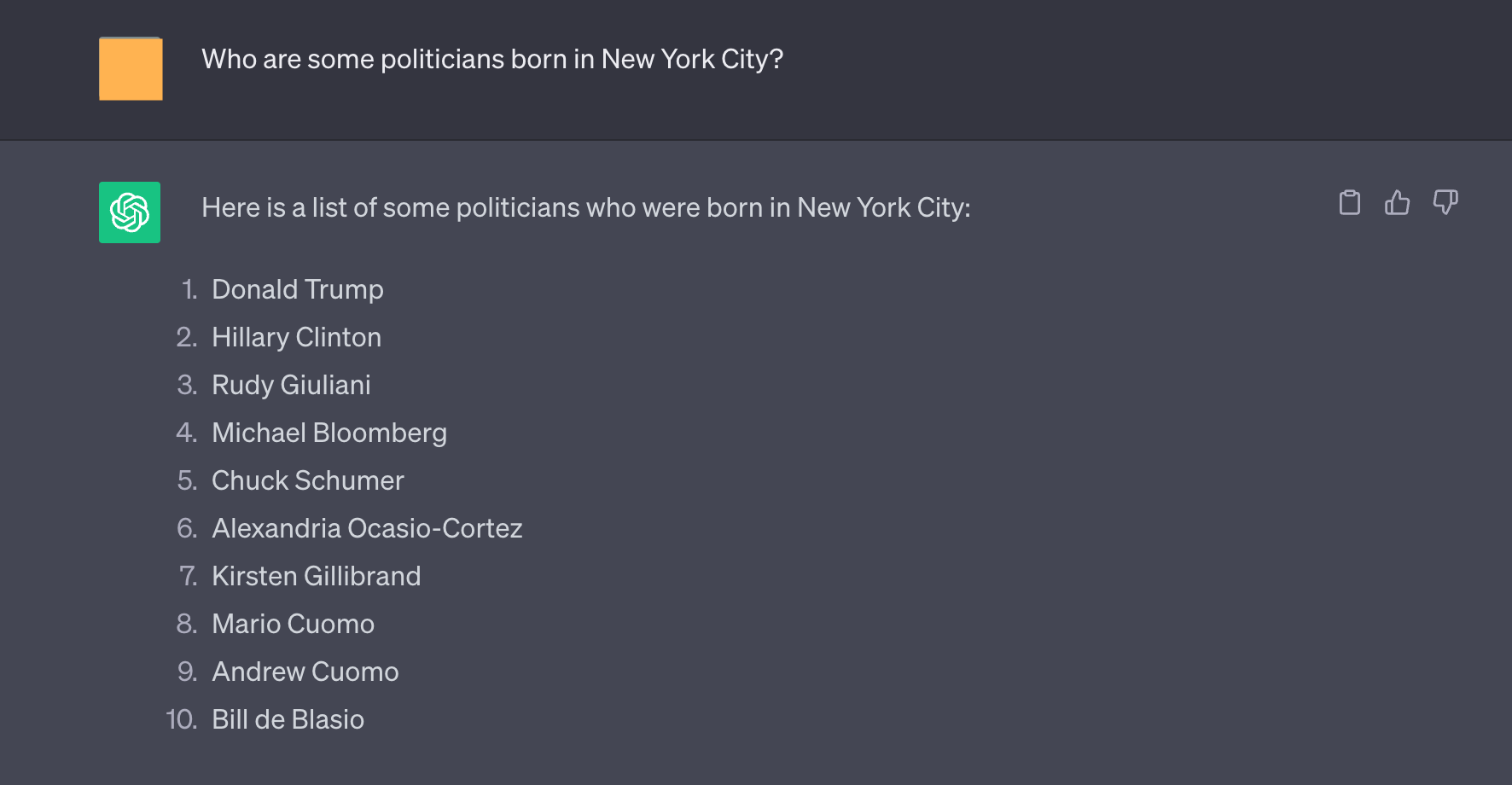
图 5:即使为重写的查询提供了长篇答案(参见图 4),虽然给出了稍微不同的答案,但 ChatGPT 仍然为这个问题生成了几个幻觉,例如 Hillary Clinton 和 Michael Bloomberg。
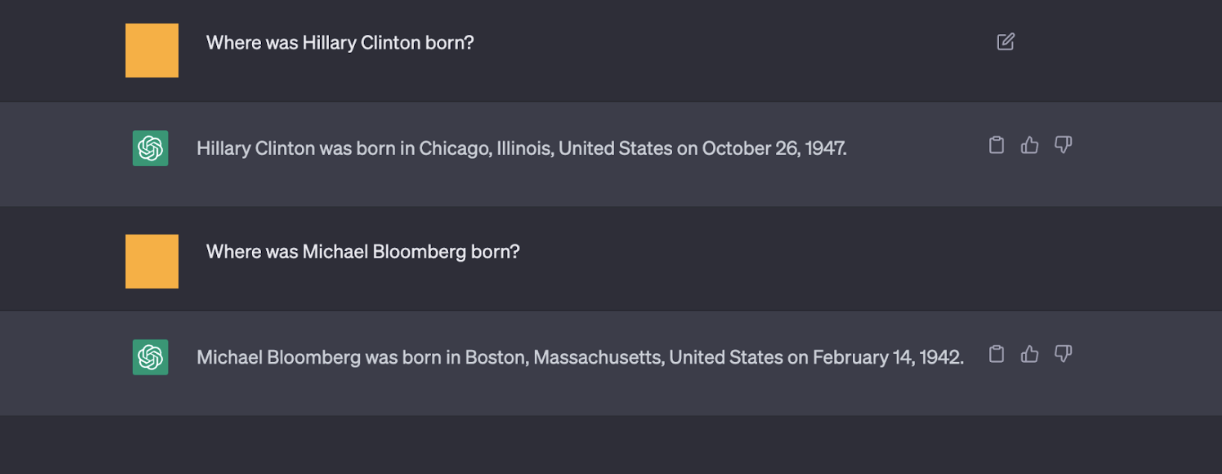
图 6:短形问题(可能是验证问题)似乎比图 4和图 5中的长篇答案更有事实依据。
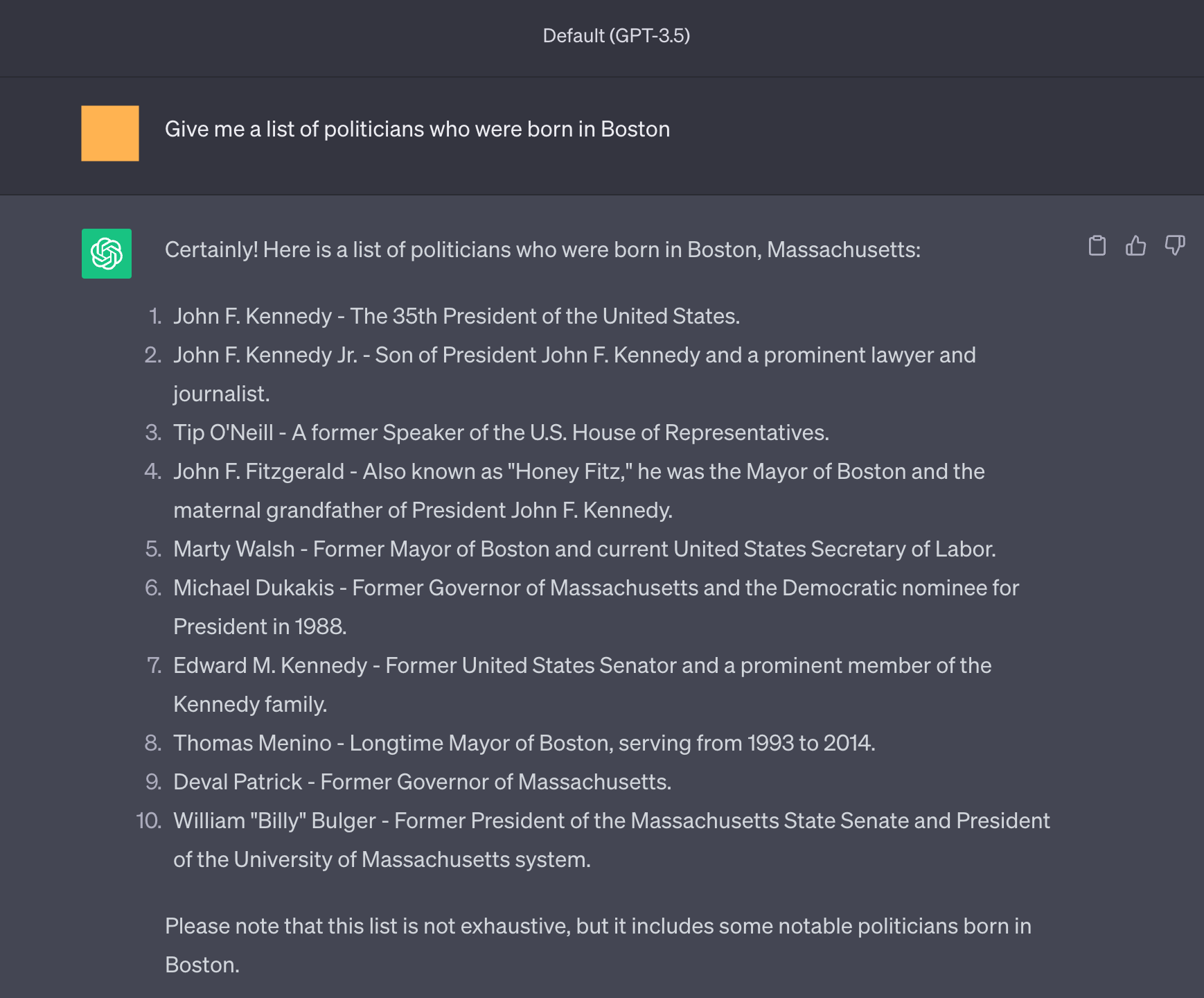
图 7:对于不同的查询的另一个幻觉示例,例如,John F. Kennedy Jr 出生在 Washington D.C。
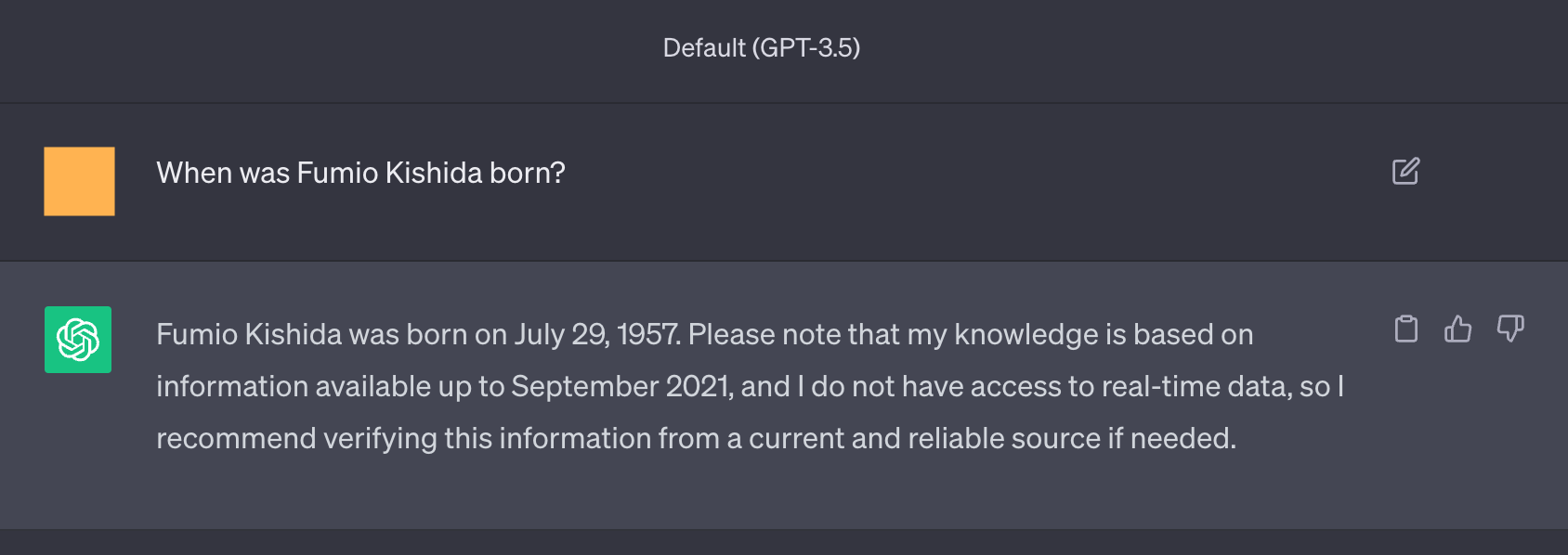
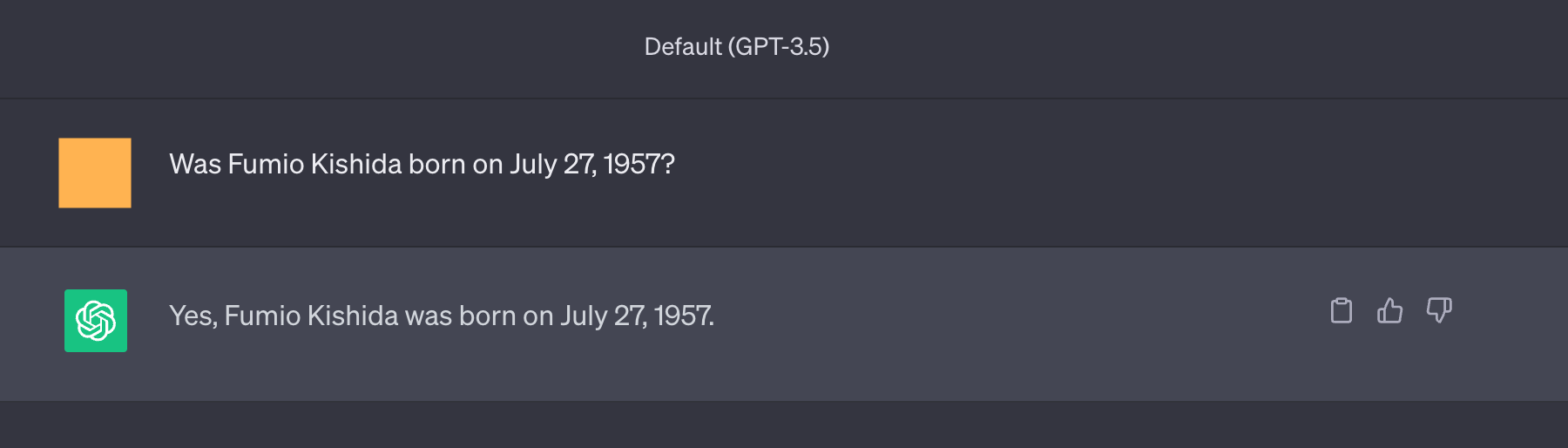
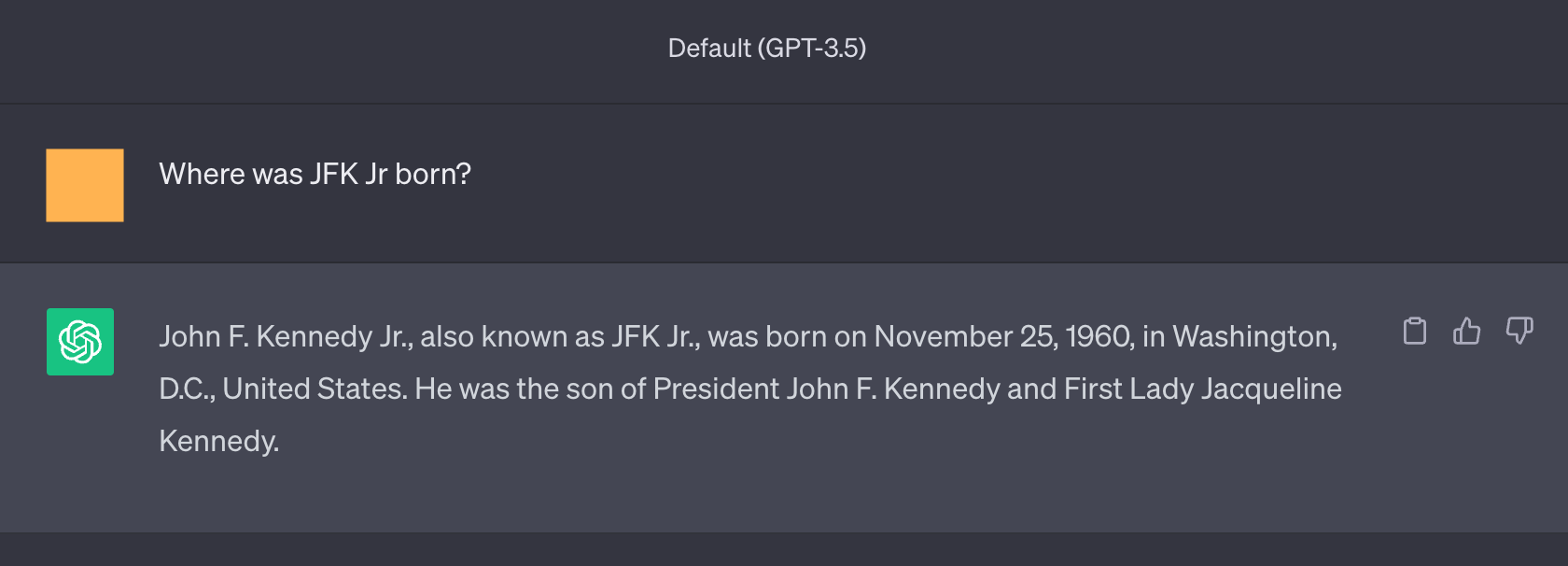
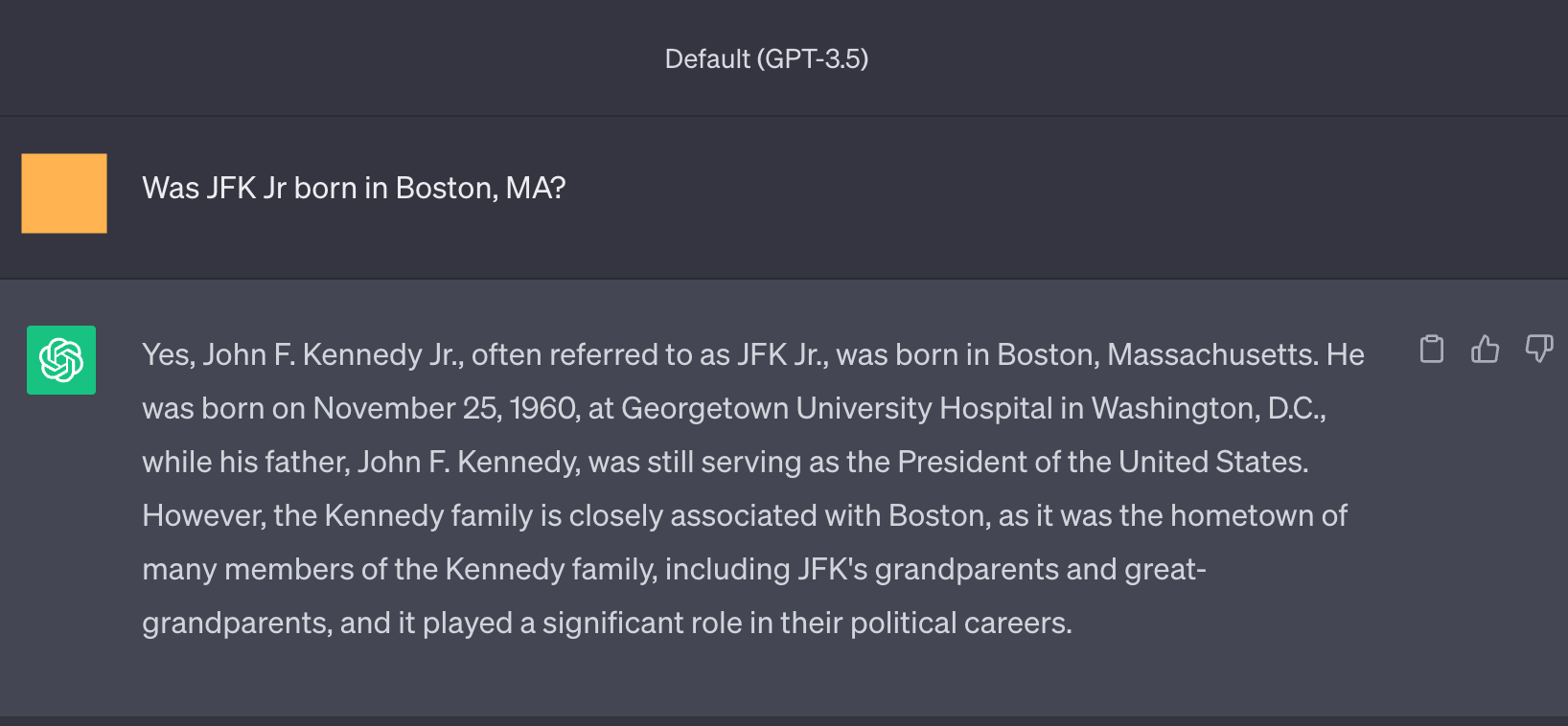
图 8:在这些示例中,询问事实的问题得到了正确的答案,但通过是/否问题进行验证是不正确的(模型倾向于同意问题的表述方式,即使它是错误的)。