长故事概要:针对长视频问答的“概括后检索”方法 [译]
摘要
GPT-3 等大语言模型展现了它们在不需要特定训练数据的情况下适应新任务的惊人能力。这一能力在诸如叙事性问题解答的场景中特别有用,那里的任务种类繁多,而可供学习的数据却相对匮乏。在这项研究中,我们探讨了这些语言模型是否能将它们的零样本推理才能延伸到多媒体内容中的长篇多模态叙事,如戏剧、电影和动画,故事在其中发挥着核心作用。我们提出了一种名为“Long Story Short”的视频叙事问答框架,它首先把视频的故事概括为简短的情节,再检索与问题相关的视频片段。我们还建议采用 CLIPCheck 来提升视觉匹配的效果。我们的模型在长视频问答方面,相较于现有的最先进监督模型取得了显著的领先,展现了零样本问答技术的巨大潜力。
Jiwan Chung https://jiwanchung.github.io1 \addauthorYoungjae Yu https://yj-yu.github.io/home1 \addinstitution MIR Lab
延世大学
韩国 首尔
1 引言
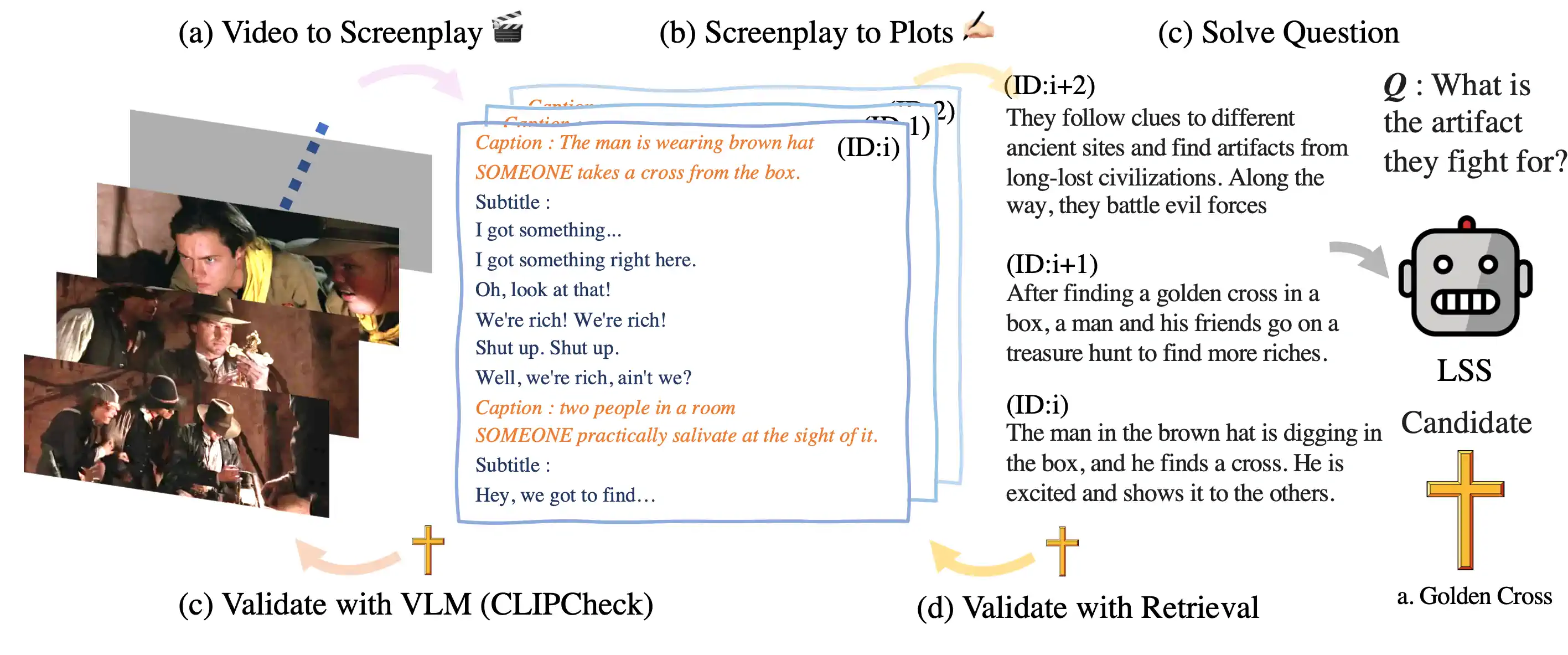
图 1: "长故事概要"(LSS)项目利用大语言模型(LLMs),比如 GPT-3,来创作 (a) 剧本,并对视频内容进行摘要化处理 (b) 情节。关于数据处理的更多细节,请参阅第 2 节。当 LSS 需要回答视频相关问题时,它会 (c) 通过视觉语言模型 CLIP 来验证原始视频片段,并且 (d) 采取逆向搜索方法来查找更多确凿的剧本内容,这一方法我们在第 2.3 节中称为 CLIPCheck。
近期的视频问答(QA)模型在处理长视频叙事 QA 任务时遇到了难题[choi2020dramaqa, tapaswi2016movieqa, kim2017deepstory],例如电影、电视剧和 YouTube 视频等,主要是由于数据和标注的局限性。这些局限导致了模型无法充分理解长视频中的复杂叙事,仅仅能回答那些基于短视频片段的视觉问题[xu2017video, lei2018tvqa, lei2019tvqa]。长视频 QA 的规模不足,不足以训练模型以完全理解视频中的复杂故事结构,这使得模型的表现不尽如人意。(jasani2019we)的研究表明,监督学习模型更倾向于依赖问题中的语言偏差,而不是视频的叙事背景:即使不观看任何视频内容,模型也能取得相似的成绩。这强调了需要有超越特定小型任务监督的多模态推理能力。
为应对这种泛化能力低下带来的挑战,采用预训练的大语言模型(LLMs)进行零样本(zero-shot)学习,可能是解决复杂 QA 任务的一种高效方法 yang2021empirical,并且对文本内容进行摘要处理 zhang2020pegasus; He2022ZCodeAP。但是,这种方法是否能够将 LLMs 在文本叙事 QA 方面的能力成功迁移到视频领域呢?
我们提出了一个新奇的框架——“Long Story Short”(LSS),如图 1所演示,该框架能够将视频片段转换为文本剧本格式,这种转换的灵感来源于著名的苏格拉底模型。利用 GPT-3 技术,我们不仅能将漫长的视频内容浓缩成一个个精彩的情节列表,而且能够结合这些总结和视频本身的内容来精准回答特定的问题。在没有任何先前样本的情况下,我们的方法在电影问答库 MovieQA 和 DramaQA 中展现了比传统顶尖方法更卓越的性能。另外,我们还推出了一个名为 CLIPCheck 的视觉 - 文本匹配技术,通过这种技术,可以更好地确保 GPT-3 提供的推理结果在视觉上的一致性。总结我们的工作,主要有三大创新点:
-
我们设计了 LSS 框架,它能够把长视频的内容概括为关键情节,并且能找出与提问最相关的那部分内容。
-
我们证明了在视觉提示中利用基于 CLIP 的匹配考虑视觉一致性是多么重要。
-
在 MovieQA 和 DramaQA 数据集上,我们的零样本方法取得了业界领先的成绩,超过了传统的有监督学习方法。
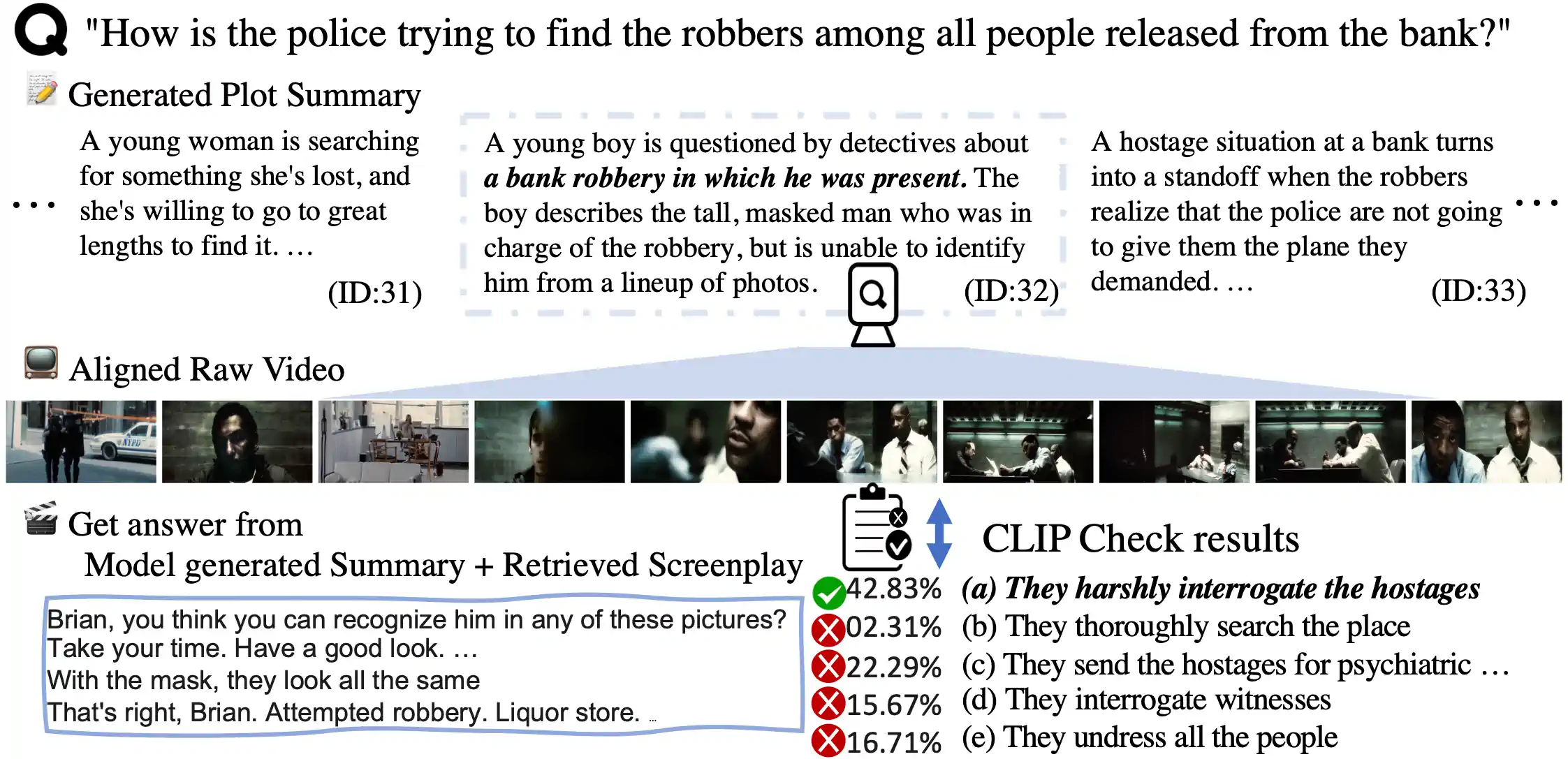
图 2: 展示了“Long Story Short”(LSS)模型的应用效果,这个模型能够生成并找到视频原始片段的索引位置。当模型根据(i)生成的摘要和(ii)检索到的文本内容预测出最终答案后,CLIPCheck 还会进一步验证每个可能答案,以确保我们对问题的回答更加精确。
方法 2
在这里,我们介绍了一个名为 Long Story Short (LSS) 的策略,这是一种利用提示将叙事性视频问答任务分解并逐一攻克的策略,它通过概括情节并检索与之相关的信息来实现。我们旨在从内容繁多的长视频 中准确预测出正确答案 。考虑到语言模型仅能处理有限长度的标记(比如 GPT-3 的 4096 个标记),它们无法处理电影中丰富的、可能长达两个小时的上下文信息(比如字幕或场景描述)。
为了解决这个问题,我们提出了一种“先概括后搜索”的视频问题回答法。我们先将漫长的视频内容分割成多个片段,并用 GPT-3 把每个片段概括为子情节,形成一个子情节列表 。接着,我们根据子情节列表检索与提问相关的视频片段 。我们利用选定片段的全文本内容以及全局情节信息,来推算出各个答案选项的可能性 。最终,我们运用 CLIPCheck 技术来强化选定答案的视觉根据。我们在附录中提供了相应的提示模板。
2.1 情节创作
我们依据视频的原始分段(Ground-truth partitions)来将一整个视频剪辑成一系列较短的视频片段。每个较长视频 由 个小片段 组成,每个片段既有视频内容 也包括相对应的文字信息 ,例如字幕或自动语音识别 (ASR)。
在处理一个视频 时,我们首先抽取它的视觉特征和文本特征,并将这些特征转化为自然语言的形式。参考 (yang2021empirical) 的研究,他们将图像内容转换成了 GPT-3 的语言提示,我们也同样提取视频 中的 DVS 字幕(rohrbach-arxiv-2016)和利用预先训练好的 BLIP(li2022blip)获取的图像字幕,并将其与文字 结合起来,生成了 份脚本。这一过程在图 1 中有详细描绘。接下来,我们会创建一个简短提示来概述视频片段的背景情境,并用三句话以内将其浓缩成一个情节片段,然后利用 GPT-3 编排出一个与视频片段索引 相对应的情节序列。
2.2 叙事搜索
当我们有了一个故事摘要和相关的问题,接下来的任务就是在一部长视频中找到和问题相关的短片段。通常,语言模型生成的文本既不规则也可能包含许多干扰信息。为了精准地找到视频中的正确片段,我们需要模型提供情节的索引位置,而不仅是文本内容。
首先,我们为视频分段对应的摘要情节列表 分配一系列连续的索引。接着,我们让语言模型给出我们需要查找的情节片段的索引号码 。
但由于语言模型本身的开放性和不确定性,这些生成出的索引有时候会包含错误。如果模型给出的是文本形式的答案,我们就会运用 rouge-l lin-2004-rouge 得分来筛选那些与生成句子相似度高于特定阈值 的情节片段作为候选。
最终,我们会将情节 、被选中片段的视觉及文本表现形式 、问题 以及答案选项 结合起来,形成一个完整的问题回答提示。我们用设置了权重 的语言模型来处理这个提示,并将索引令牌的可能性作为判断答案的依据。
2.3 视觉检查
为了让视频画面与文字描述更好地配对,我们推出了一种名为 CLIPCheck 的新方法,它结合了 CLIP 视觉距离 [radford2021learning] 和语言模型的可能性评估。这一过程起始于选定的视频片段 ,备选答案 ,以及 GPT-3 对这些答案的可能性评估 。
首先,我们利用 CLIP 的图像编码器来处理选段中的每一帧画面 。如果一个片段中有 帧:
接下来,我们会抽取每个答案的 CLIP 文本特征 ,并将其与视频输入进行余弦相似度比较。我们会为每个答案找出最匹配的帧,并据此计算出余弦相似度得分。
首先,我们利用一个温度参数 来运用 softmax 函数处理评分,得到对各个可能答案的规范化视觉可能性 。接着,我们把语言模型计算出的答案可能性 与视觉可能性 结合起来,算出一个最终的可能性分数。然后,我们选出这些分数中最高的一个作为模型给出的答案。
我们只在语言模型对其给出的答案不够确定时,才考虑使用 CLIPCheck。根据语言模型给出的前两个答案的可能性 ,我们用二元熵 来评估模型的确信度,二元熵是对这两个概率重新归一化后计算得出的。只有当二元熵大于设定的阈值 时,我们才综合这两种可能性来决定答案。如果二元熵小于这个阈值,我们就不使用 CLIPCheck,只依赖语言模型的结果。
| 模型 | 是否对齐 | 视频 + 字幕 | 仅视频 | 仅字幕 | |
| 监督式 | A2A | 41.66 | 40.28 | 41.05 | |
| PAMN | 43.34 | 42.33 | 42.56 | ||
| UniversalQA | 48.87 | 50.67 | 47.62 | ||
| DHTCN | 49.60 | 47.38 | 48.43 | ||
| 零样本学习 | 无相关上下文 | ✗ | 36.36 | 34.28 | 38.07 |
| LSS | 53.44 | 49.83 | 56.42 | ||
| LSS-搜索版 | ✗ | 51.24 | 49.00 | 53.09 | |
| LSS-搜索版+CLIPCheck | ✗ | 51.49 | 49.55 | 53.09 |
图 1: 对电影问答题库的验证分割进行的评估。数据集提供平均 3 分钟视频片段的真实对齐数据:此外,我们还展示了在没有真实对齐数据的情况下,通过搜索整个电影内容获得的结果(Ours-search)。"视频 (V)" 代表视频内容的评分,"字幕 (S)" 代表仅字幕内容的评分。
| 模型 | 是否有标签 | 准确度 | ||
| 剧情 | 是否对齐 | |||
| 监督式 kim2017deepstory | 68.00 | |||
| GPT3 无上下文 | ✗ | ✗ | 36.90 | |
| LSS | 基本版 | 66.76 | ||
| + 搜索功能 | ✗ | 48.98 | ||
| + 剧情分析 | ✗ | 65.80 | ||
| + 剧情分析 + 搜索功能 | ✗ | ✗ | 53.34 |
图 2: 对 PororoQA 验证分割的评估。机器生成的剧情 (+剧情) 几乎能与人工标注的数据(基本版)媲美。
| 第三级 | 第四级 | |
|---|---|---|
| 模型 | ||
| CharacterAttention | 60.82 | 65.62 |
| Kim et al\bmvaOneDot kim2021aaai | 70.00 | 70.00 |
| LSS | 72.20 | 75.23 |
| +Caption | 73.54 | 75.68 |
| +CLIPCheck | 75.78 | 79.28 |
| +Caption+CLIPCheck | 75.34 | 77.93 |
| +CLIPCheck-Shuffle | 71.74 | 73.87 |
表 3: 在 DramaQA 验证集的第三级和第四级的评估结果。 CLIPCheck 技术在基准模型和一种通过提示输入图像描述的方法 zeng2022socratic 上取得了领先成绩。
| 对齐 | 视频 + 字幕 | |
|---|---|---|
| 模型 | ||
| LSS | 53.44 | |
| LSS-Search | ✗ | 51.24 |
| LSS-Search+CLIPCheck | ✗ | 51.49 |
| LSS-Random | ✗ | 48.92 |
| LSS-Full | ✗ | 48.57 |
表 4: 在 MovieQA 验证集上的模型消融研究。
3 实验
在所有实验中,我们都采用了 GPT-3 brown2020gpt3 (text-davinci-003) 作为核心的语言模型。除非有特别指出,我们通常用实际的剪辑边界来分割视频材料。所有的 LSS 模型变种都不依赖于训练数据,属于零样本方法。
3.1 简述长篇故事的评估
MovieQA 是一个基于 408 部电影打造的庞大问答数据集。数据集中融合了字幕、剧本、描述性视频服务(DVS)、视频片段和剧情概要等多种信息。我们参照了四个先进的有监督学习方法:A2A、PAMN、UniversalQA 以及 DHTCN 作为基准。
表 1 显示了在没有额外信息帮助的情况下,LSS 方法比之前的有监督方法表现更好。而且,我们的搜索技术即使没有正确的视频段落索引标签,也展现出强劲的性能。CLIPCheck 在视频分类上略微提高了准确性,不过由于 MovieQA 更侧重于基于角色的识别,而非通用的视觉匹配,这种提升是微小的。我们还对一个无情境假设进行了实验:测试 GPT-3 是否仅仅通过记忆所有事实来解答 MovieQA,结果显示这种“无情境”的方法效果远不如 LSS,从而推翻了这一假设。
PororoQA 是根据卡通系列制作的视频故事问答数据集。有监督学习基准采用人工编写的剧情和精确的视频段索引,而 LSS +Plot+Search 方法则不需要这些信息。
表 2 汇总了我们对 PororoQA 数据集的实验结果。使用准确的剧集和剧情概要时,GPT-3 的表现几乎和有监督基准相当。将人工编写的摘要替换为由模型生成的摘要,性能只是轻微下降。有趣的是,使用模型生成的剧情概要进行搜索时,效果甚至更佳。我们认为这是因为人工注解并不是特别为区分不同剧集而设计的。

图 3: 展示了由 LSS 生成的剧情摘要和维基百科真实摘要的比较,由于篇幅限制,这里仅展示了整个剧情的前两段。
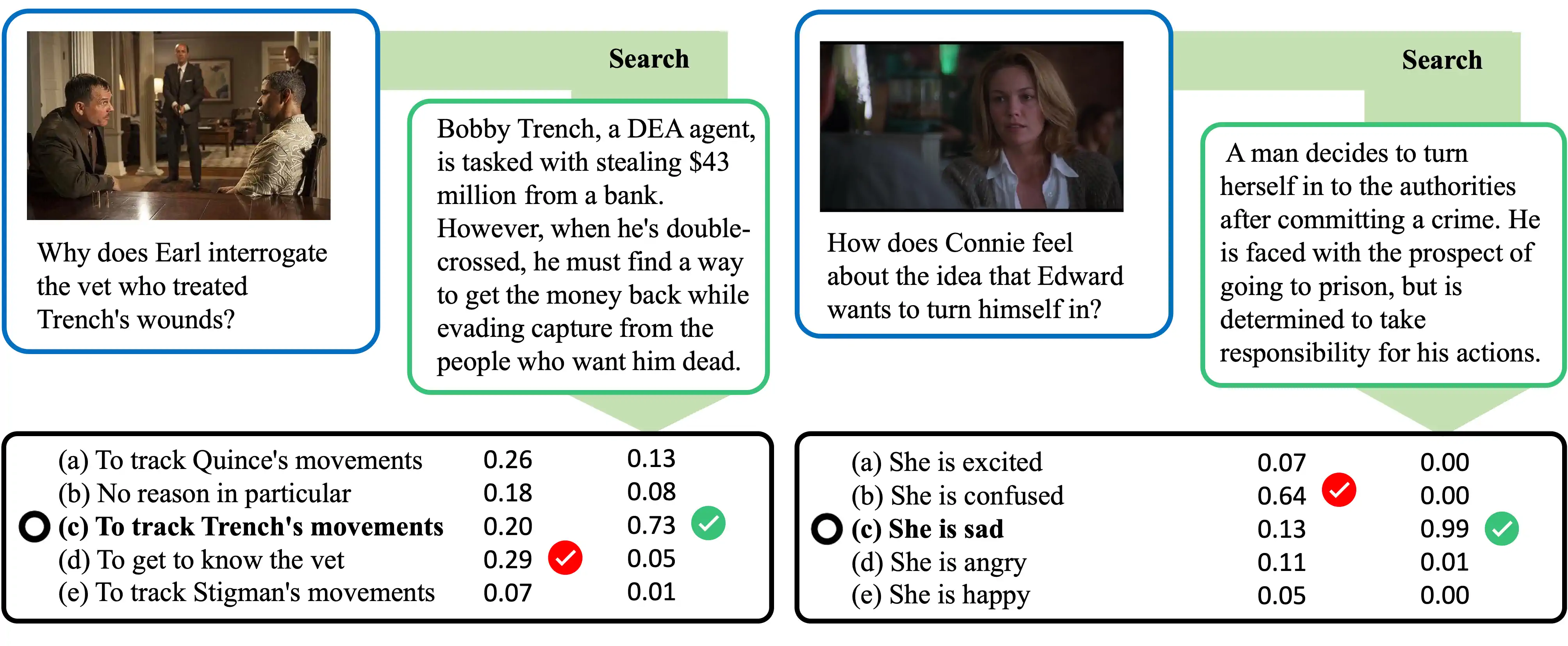
图 4: 展示了 LSS 问答过程的示例。根据搜索到的剧情片段,明显影响了语言模型回答的可能性分布。
3.2 CLIPCheck 的评估
DramaQA choi2021dramaqa 是一个集中于故事理解的视频问答数据集。这个数据集被分为四个层级,每个层级的难度都对应着人类的认知发展阶段。我们选择 DramaQA 中难度较高的两个层级对 LSS 进行测试,目的是检验其对情节的理解能力。我们列出了 DramaQA 分级难度中最新的两个基准:CharacterAttention 和 Kim et al \bmvaOneDot kim2021aaai。
我们研究了 CLIPCheck 与 Caption 的不同影响,后者是一种将从 BLIP li2022blip 中提取的图像框描述作为输入提示到 GPT-3 的方法。表 3 表明,与图像描述相比,CLIPCheck 能带来更显著的改进。另外,尽管添加图像字幕能够提升 LSS 的表现,但当和 CLIPCheck 一起使用时,这种提升效果却消失了。我们认为这可能是因为图像字幕提供的信息和 CLIPCheck 相似,但包含更多的噪声。需要指出的是,这里的自动化字幕并不是 LSS 的核心部分。鉴于 DramaQA 本身已经有了基于视觉的注解,再增加自动图像字幕未必能提高模型的性能。我们之所以使用字幕,是为了明确比较视觉对齐的早期方法和后期方法。
最终,我们还调查了 CLIPCheck 是否仅是利用了数据集的偏差而没有真正理解视觉上下文。为了验证这一点,我们创建了一个随机视觉上下文版本的 CLIPCheck(称为 CLIPCheck-Shuffle)。CLIPCheck-Shuffle 的表现并没有超过不使用 CLIPCheck 的 LSS,这反驳了数据集偏差的假设。
3.3 剖析研究
总结和搜索在叙事理解中是否同等重要?我们对 LSS 的不同变体进行了评估,比如只有完整上下文没有叙事搜索的 LSS-Full,以及输入了情节概要和随机片段的 LSS-Random。表 4 显示,无论是 LSS-Full 还是 LSS-Random 的表现都不如 LSS-Search,这证明了检索功能的重要性。但由于令牌长度的限制,我们无法在 LSS-Full 中使用完整的上下文。作为替代,我们使用了 GPT-3 能够接受的最长的完整上下文前缀(4000 个令牌减去指令的长度)。
3.4 定性成果展示
图 3 展示了在长视频问答(QA)系统中,语言模型如何在 LSS 框架内自动生成情节摘要,并将其作为处理的中间步骤。从展出的样本来看,机器生成的情节与维基百科上人工编写的情节高度一致。比如,在《哈利·波特与死亡圣器》的开篇场景中,LSS 系统就准确描述了哈利·波特现年 17 岁,以及死食者对主角发起攻击的主要情节。
图 4 则描绘了情节检索与问题可能答案之间的关系。以左边的例子为例,系统找到的情节概要提到了 Trench 犯了罪并在逃,这暗示了其他角色可能在追捕他。语言模型通过理解这段背景,适当调整了答案可能性的估算。在右边的例子中,LSS 提供的情节段落指出 Edward 对自己的决定非常自信。尽管这段情节并没有直接回答问题,语言模型还是认为它包含了足够的信息量,可以据此调整答案的可能性。
4 相关工作
电影摘要 电影是长篇视频的代表作,它们往往有非常明确的叙事架构。Gorinski et al.\bmvaOneDot 2015 年的研究 Gorinski2015MovieSS 将电影剧本压缩为更短版本的工作定义为找到电影场景图的最佳链条。TRIPOD papalampidi-etal-2019-movie 是一个含有转折点标记的剧本数据集。在相同的研究中,他们提出了一种自动化模型,用于识别电影叙事中的转折点。Papalampidi et al.\bmvaOneDot 2020 年的工作 papalampidi2020ScreenplaySU 利用电视连续剧《CSI》来说明转折点在自动电影摘要中的实用性。Lee et al.\bmvaOneDot 2021 年的研究 lee2021TransformerbasedSS 则进一步利用对话特征和变换器架构来提高识别转折点的能力。
长视频问答 视频问答这一任务已经得到了广泛的研究,无论是开放式问答 QA jang2017tgif 还是多选题问题 xiao2021next; wu2021star。从 RNN 基础的注意力网络 zeng2017leveraging; xu2017video; zhao2017video; jang2017tgif,到记忆网络 tapaswi2016movieqa; na2017read; kim2019progressive,再到变换器 gao2018motion; fan2019heterogeneous,多种方法相继被提出。近期,预先在大型视频数据集上训练的多模态模型(如 VideoQA yang2021just, VIOLET fu2021violet, 以及 MERLOT zellers_2021_merlot 和 MERLOT-Reserve zellers2022merlot)在视频问答任务上表现出了很有前景的性能。
但是,长视频问答任务,尽管非常关键,却相对得到较少的关注。MovieQA tapaswi2016movieqa 将问答设定在整部长达两小时的电影上。DramaQA choi2021dramaqa 则选择单部电视剧作为视觉内容,挑战解题者对从一分钟到二十分钟不等的视频片段进行理解。
5 总结
我们推出了一种名为 "Long Story Short" 的创新方法,这种 "先概括后搜索" 的技术帮助理解视频故事问答中的宏观叙事和相关细节。在长视频问答中,由于背景信息量巨大,必须要进行高层次的互动才能解答问题,我们的方法在这种情境下显得尤为有效。此外,我们还尝试使用一种名为 CLIPCheck 的后置检查技术来提高模型生成答案的视觉一致性。我们的零样本方法在电影问答和剧情问答的基准测试中,较之有监督的最新技术有所提升。我们计划向公众开放我们的代码和所生成的情节数据。
在本研究基础上,未来的研究方向有两个:第一,通过角色重识别和指代消解,提供更紧贴故事情节的视觉描述,这样可以提高输入到 GPT-3 的内容质量。第二,人们可以开发一种更加动态的多步搜索技术,将宏观与微观信息进行层次化结合。
6 局限性
本研究存在一些局限性,具体包括:
-
[leftmargin=*,topsep=0pt,itemsep=-1ex,partopsep=1ex,parsep=1ex]
-
我们的实验只针对有英文字幕的视频。不过,如果配合强大的多语种语言模型,我们的方法有潜力应用于包括多种语言的上下文中。
-
鉴于我们的方法高度依赖于大语言模型 GPT-3,因此在计算和内存需求上相当巨大。
-
我们仅使用了一个 GPT-3 实例来评估 "Long Story Short" 的效果。
潜在风险。使用 GPT-3 对长视频内容进行概括可能会带来一些伦理风险,这与语言模型的开放式特性有关。GPT-3 可能会(a)编造关于内容的虚假事实,(b)生成有害言论,或者(c)在总结和回答中潜意识地嵌入社会偏见。
参考文献
附录 A 实验详情
计算资源。在我们的项目"Long Story Short"中,我们利用 OpenAI API 提供的 GPT-3(含有 1750 亿参数)作为计算支柱。一般来说,生成一个视频片段摘要的提示要处理大约 个 token,而问答(QA)类型的提示则需要处理 个 token。至于 CLIPCheck 部分,我们使用了 NVIDIA A6000 GPU 来提取视频帧的 CLIP 特征,并计算它们的余弦相似度,对 MovieQA 的验证集视频帧处理需要半小时。
超参数设置。我们是通过分析单一的训练样例来预先定义所有的超参数的。在进行叙事搜索时,我们会设定一个句子相似度的阈值 ,以找出情节片段,这是在 GPT-3 未能给出单一索引时采用的方案。在 CLIPCheck 中,则使用了一个二进制熵阈值 。我们的实验都只进行一次,因为我们采用的方法是确定性的,即不会因为初始化的随机性而产生变数。
视频分段策略。对于本文中使用的所有数据集,我们都预设了视频段的界限标注。同样,所有情节片段都有与之对应的视频剪辑段,这是因为我们根据预设的界限进行了视频剪辑的概括。而且,在使用 LSS 筛选剪辑段之前,我们会剔除那些太短、没有对应图像帧或没有文本背景的剪辑段,以确保我们能够通过情节摘要来检索视频剪辑段。
外部工具库。我们利用 OpenAI API 来接入 GPT-3 语言模型。CLIP 特征的计算是基于 Huggingface 提供的实现方案来完成的(详见:https://huggingface.co/docs/transformers/main/en/model_doc/clip)。
附录 B 操作示例
在 Long Story Short 的各个步骤中,我们会用到如下的操作提示。为了让提示更易阅读,我们将长句断行,但真正的换行符则用 \n 来标示。另外,提示内的条目用省略号 (...) 来简化。
从剧本到故事梗概。
我是一位智能程度极高的故事讲述机器人。 只要你提供一份剧本,我就能还你 一个详尽的故事简介。\n\n [生成的剧本]\n\n 故事梗概:
情节索引检索。
情节:\n (1) [情节1]\n (2) [情节2]\n ...\n (N) [情节N]\n\n 我是一位智能程度极高的问答机器人。 如果你有问题要问,告诉我,我可以快速告诉你 哪个情节索引能帮你找到答案。\n Q: [问题]\n 最佳情节索引:(
解答问题。
情节:\n (1) [情节1]\n (2) [情节2]\n ...\n (N) [情节N]\n\n [生成的剧本]\n\n 我是一位智能程度极高的剧情问答机器人。 如果你提出一个问题并且给出了几个选项,我能帮你 指出正确答案的索引。\n Q: [问题]\n 可选答案:\n (1): [答案1]\n ...\n (5): [答案5]\n 答案索引:(