2023 年人工智能与开源界的风云变幻 [译]
盘点这一年的起起伏伏
2023 年即将过去,此刻不失为回首这一年人工智能领域研究成就、产业发展以及开源社区的盛况的好时机。
当然,本文仅捕捉了那些最触动我思绪的热点话题。我还推荐您翻阅档案馆中的 研究亮点 月刊和 AI 前沿 #4-12 系列,那里有对这些主题更全面的深入报道。
2022 年科技趋势的发展
在今年的人工智能产品领域,我们似乎没有见识到真正创新的技术或思想。相对而言,今年的发展更多是基于去年成功模式的深化和扩展:
- ChatGPT 结合了 GPT 3.5 技术升级至 GPT 4
- DALL-E 2 进化为更先进的 DALL-E 3
- Stable Diffusion 2.0 演变成了更大型的 Stable Diffusion XL
- ...
市场上流传一个颇为引人注目的传闻,称 GPT-4 是由 16 个子模块构成的混合专家(MoE)模型,每个子模块据说拥有高达 1110 亿参数(供参考,GPT-3 的参数是 1750 亿个)。

来源于 2023 年人工智能状况报告的 GPT-3 与 GPT-4 的幽默对比图
尽管我们还无法完全确认,但 GPT-4 是基于 MoE(混合专家模型)的可能性非常高。一个明显的趋势是,工业界的研究者们越来越少地在他们的论文中公开信息。打个比方,GPT-1、GPT-2、GPT-3 和 InstructGPT 的论文都详尽地揭露了模型的架构和训练过程,而 GPT-4 如何构建却成了一个秘而不宣的谜。再比如,Meta AI 在其首篇有关 Llama 论文 中详细阐述了训练数据集的内容,但在 Llama 2 模型 中,这部分信息则被保密了。提一句,斯坦福大学最近发布的 The Foundation Model Transparency Index 显示,Llama 2 以 54% 领先于透明度排名,而 GPT-4 以 48% 居第三。
我们也许不能苛求企业分享他们的核心机密,但这种趋势还是颇值得关注。因为看起来,在 2024 年我们将持续这样的发展方向。
在规模扩展方面,今年的另一个趋势是增加了模型处理输入信息的长度。举例来说,与 GPT-4 竞争的 Claude 2 的亮点之一就是它可以处理高达 100k 的输入令牌(而 GPT-4 目前的上限是 32k 令牌),这对于对长篇文档进行总结处理来说非常有吸引力。而它对 PDF 文件的支持,更是在实际应用中增加了它的实用价值。

借助 Claude 2 快速创建 PDF 文件的内容摘要
开源界与研究潮流
记得去年,开源界特别钟情于 潜在扩散模型(latent diffusion models)(譬如 Stable Diffusion)及其他的计算机视觉技术。扩散模型和计算机视觉技术的重要性不减当年。但是,今年大语言模型(LLMs)在开源和研究圈里引起了更大的轰动。
Meta 发布的首个预训练模型 Llama,尽管使用许可受限,但却在研究者和开发者中掀起了波澜,比如 Alpaca、Vicuna、Llama-Adapter 和 Lit-Llama 等等。
几个月之后,Llama 2 出现了,我在 Ahead of AI #11: New Foundation Models 里有更深入的报道,它基本上取代了 Llama 1,成为更强大的基础模型,并推出了多个微调过的版本。尽管如此,现在的开源大语言模型大多仍然只处理文本,虽然如 Llama-Adapter v1 和 Llama-Adapter v2 这类的微调技术,承诺将现有的大语言模型扩展到多模态领域。

来自 Llama-Adapter V2 的示意图,详见 https://arxiv.org/abs/2304.15010
最近引人注目的是 Fuyu-8B 模型,它在不久前的 10 月 17 日才亮相。

取自 https://www.adept.ai/blog/fuyu-8b 的图解
Fuyu-8B 模型有个独到之处,它直接将输入的图像切片传送到一个线性投影层(也就是嵌入层),自行学习图像切片的嵌入表示,而不像其他模型那样依赖一个预先训练好的图像编码器(比如 LLaVA 和 MiniGPT-V)这样的实践让整个架构和训练流程都简化了不少。
尽管我们提到了几个多模态的尝试,但目前研究的重点依然是如何用不足 100 亿参数的较小模型去匹敌 GPT-4 的文本处理能力。这主要是因为硬件资源的成本和限制、数据获取的困难,以及研究人员面临的发布压力,迫使他们需要在较短的时间内完成开发,而不是耗费数年时间训练一个模型。
不过,未来开源大语言模型(LLMs)的飞跃性进展,并不一定非得依赖于模型规模的增大。我们期待着看到,专家模型(MoE)技术在 2024 年是否能够帮助开源模型达到新的高度。
2023 年的研究领域内,有件事特别吸引人:除了我们熟知的基于变压器的大语言模型(LLMs),出现了一些新兴模型,比如循环型的 RWKV LLM 和卷积型的 Hyena LLM,它们的目标是提升效率。尽管如此,基于变压器的 LLMs 依旧是目前的技术顶峰。
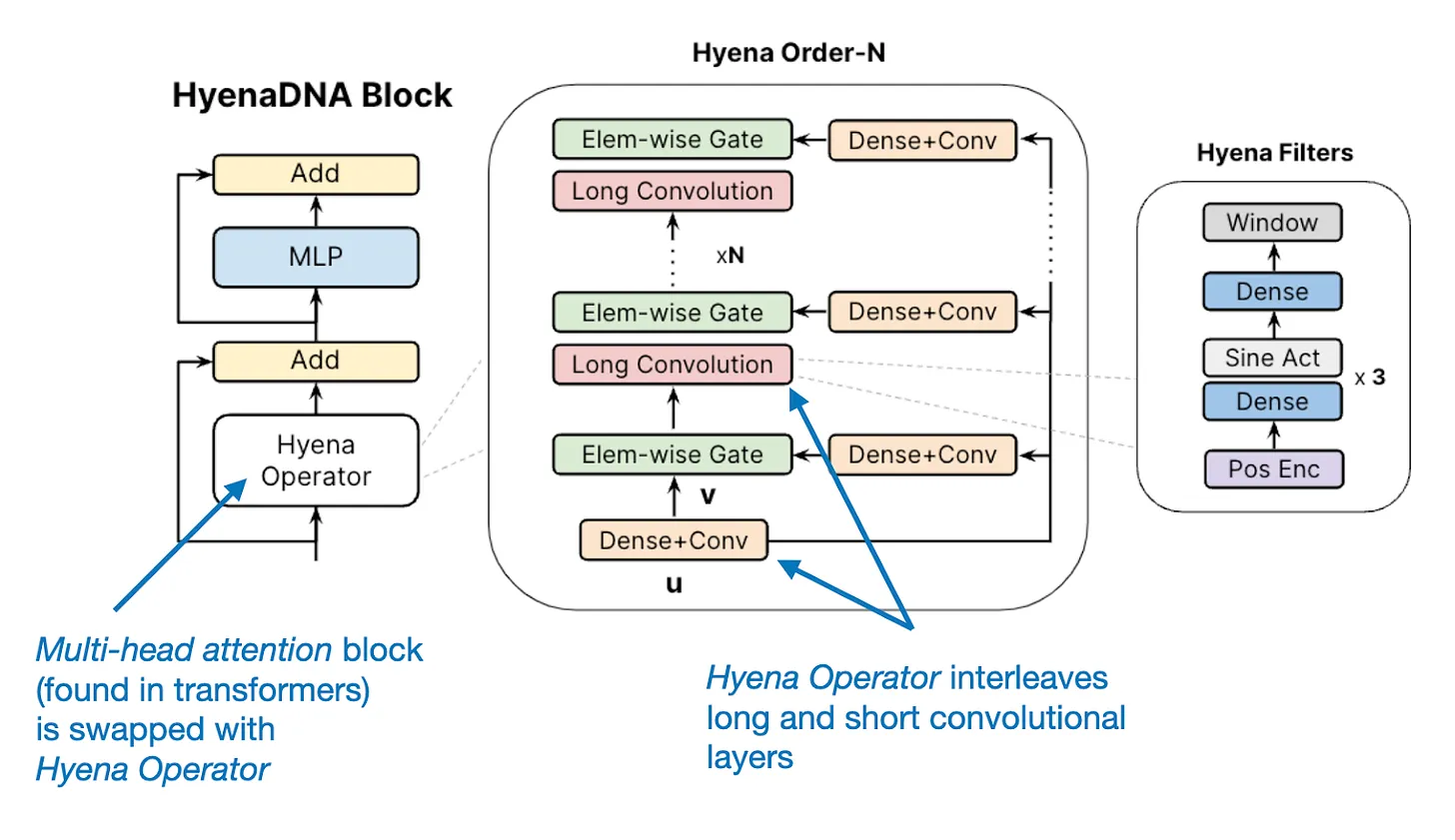
来自斯坦福大学模糊研究团队对 Hyena LLM 架构的解读:https://hazyresearch.stanford.edu/blog/2023-06-29-hyena-dna
放眼整个开源界,去年真是活跃异常,不断有令人激动的突破和进步出现。这个领域的特色就是集体智慧的力量远超个体。所以,看到有人在努力反对开源人工智能,我感到有些遗憾。但我还是希望我们能继续这股正能量,创造出更多高效的方案和替代品,而不是越来越依赖大公司推出的 ChatGPT 类产品。
在这个部分积极结束前,我要感谢开源和研究社区的贡献。我们见证了一些体积小、效能高的模型,如 1.3B 参数 phi1.5,7B Mistral 和 7B Zephyr,它们几乎能媲美大型私有模型的性能。这样的趋势让人振奋,我期待它在 2024 年能持续发展。
Ahead of AI 是一个依靠读者支持的出版平台。想要获取新文章并支持我的工作,请考虑订阅我们的免费或付费内容。
点击订阅
生产力的新承诺
在我眼中,开放源码的人工智能技术是开发高效且个性化大语言模型(LLM)解决方案的关键,这还包括根据我们个人或特定行业数据进行微调的 LLM,能广泛应用于不同领域。如果你在社交网络上关注我,可能经常看到我分享和试验 Lit-GPT——一个我正在积极参与的开源大语言模型项目。我虽然鼓励开源精神,但同样热爱设计精良的产品。
ChatGPT 问世以来,我们见证了大语言模型(LLM)的广泛应用。你作为本文读者,可能已经亲自体验过 ChatGPT,所以不用我多说,你知道 LLM 确实能在特定任务上大显身手。
关键在于我们得把它们用在“对的”地方。比如,我可能不会向 ChatGPT 询问我最爱的超市营业时间,但我最喜欢用它来纠正语法或者帮我重新构思句子和段落。更广泛地说,LLM 背后的大愿景是提升工作效率,这点你也许已经有所感受。
除了处理文本的 LLM,Microsoft 和 GitHub 的 Copilot 编程助手 也日渐成熟,越来越多的开发者开始转向使用它。今年初,Ark-Invest 发布的报告预测,编程助手能让编码任务的完成时间缩短约 55%。

这份图表来自 https://ark-invest.com/home-thank-you-big-ideas-2023/
具体节省了超过 55% 的时间还是少于这个数字,虽有争议,但如果你尝试过编程助手,肯定能感受到它的便捷,它让原本枯燥的编码工作变得轻松许多。
有一点可以肯定:编程助手已经不可或缺,并将随着时间不断进步。它们会替代人类程序员吗?我并不希望如此。但毫无疑问,它们将提升程序员的工作效率。
那么这对 StackOverflow 来说意味着什么?《2023 年人工智能状况报告》中的一张图显示了 StackOverflow 的网站访问量与 GitHub 的对比情况,这可能与 Copilot 越来越多的被使用有关。不过,我认为 ChatGPT/GPT-4 已经在编程相关的任务中大放异彩。我还怀疑 ChatGPT 在某种程度上(甚至在很大程度上)导致了 StackOverflow 访问量的减少。

来自《2023 年人工智能状况》报告的图表
人工智能面临的问题
幻觉现象
如同 2022 年的情况,大语言模型(LLMs)依然存在着生成有毒内容和幻觉的问题。在过去的一年里,我探讨了好几种可能的解决方案,包括利用人类反馈的强化学习(RLHF)和 Nvidia 推出的 NeMO Guardrails。不过,这些方案要么太过严苛,要么又显得不够到位。
到现在为止,我们还没有找到一个百分之百可靠的方法(甚至连一个合适的方法想法都没有)来彻底解决这一问题,同时又不损害 LLMs 的正面效能。我认为解决问题的关键在于我们如何使用 LLM:不应该过度依赖 LLM 解决所有问题,数学计算该用计算器,把 LLM 当作写作助手并严格审核其输出等。
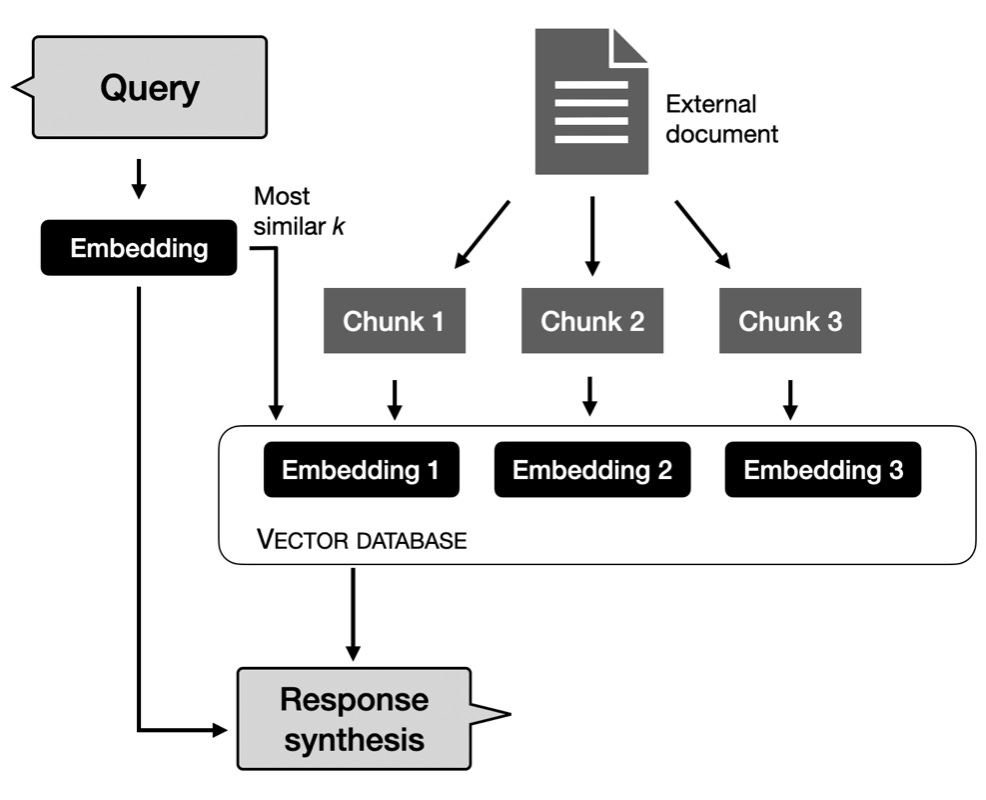
另外,对于一些特定商业用途,考虑到检索增强型增强(RAG)系统可能是个不错的折中选择。通过 RAG 系统,我们能从大量文献中找到相关信息,并基于这些信息生成基于 LLM 的文本。这样的做法使得模型能够依赖现有的数据库和文件,而非单纯依赖于内部记忆的知识。
版权问题
与此同时,AI 领域的版权争议也日益严峻。据维基百科所述,"目前我们还不完全明了基于版权作品训练的 LLMs 的版权状况。" 整体来看,很多相关规定还在起草和修改过程中。我希望最终的规定能够明确具体,这样 AI 研究人员和从业者才能根据规定做出适当的调整。(更多关于 AI 与版权争议的讨论可以参考我写的这篇文章。)
评估
在学术研究领域,人们日益担忧一个问题:广受欢迎的基准测试和排名榜单可能已经失效,因为用于测试的数据集可能已经不慎泄露,成为了大语言模型(LLM)的训练材料。这个问题在讨论 phi-1.5 和 Mistral 时显得尤为突出,正如我在上一篇文章中分析的那样。
虽然通过询问人们的偏好来自动化评估 LLM 的效果是一个普遍方法,但这种方式较为复杂。许多研究报告选择使用 GPT-4 来进行评估,将其视作次优选择。

比如在 LIMA 论文中就有使用人类和 GPT-4 的偏好评价作为评估的例子。
收入问题
当前,生成性人工智能还在试验阶段。我们都知道,无论是文本还是图像生成工具,对于特定场景确实能提供帮助。但关于这些工具是否真的能给公司带来收益,尤其是在高昂的服务器托管和运行成本面前,业界还在激烈讨论中。例如,有报道称,OpenAI 在去年的运营中亏损了 5.4 亿美元。但与此同时,最近的报告指出,OpenAI 现在每月能赚取 8000 万美元,有望弥补或甚至超出它的运营开支。
虚假图像问题
生成式人工智能(AI)当前在社交媒体上的一个显著问题,就是假图片和视频的泛滥。假图片和视频问题由来已久,软件如 Photoshop 使制造假象变得更易于普及,而 AI 技术正在将此现象推向一个全新的高度。
目前也有其他 AI 系统尝试识别由 AI 产生的内容,但无论是文本、图片还是视频,这些系统的可靠性都不高。要控制和抗击这类问题,我们唯一的办法似乎是求助于信誉良好的专家。正如我们不会轻易接受网上随便一个论坛或网站的医疗或法律意见,我们也不应当不加甄别地信任网络上随意账户分享的图片和视频。
数据集的瓶颈
涉及早前讨论的版权争议,不少公司(包括 Twitter/X 和 Reddit)关闭了他们免费的 API 接入点。他们这样做既是为了增加收益,也是为了阻止数据采集器搜集平台数据进行 AI 训练。
我发现很多公司都在做与数据集相关的业务广告。AI 可能导致某些职位的自动化,这是遗憾的一面,但它同样也在创造新的就业机会。
要为开源长期语言模型(LLM)的进步做出贡献,一个好方法可能就是建立一个众包数据集的平台。我的意思是编写、收集和整理那些已经明确允许用于 LLM 训练的数据集。
RLHF 是锦上添花吗?
当 Llama 2 的模型系列面市时,我对其中包含了针对聊天功能进行了微调的模型感到非常兴奋。Meta AI 通过人类反馈的强化学习(RLHF)技术,成功提升了模型的实用性和安全性——关于 RLHF 的更多详细内容,我在这篇文章里有深入讨论。

图片来自 Llama 2 的研究报告:开源基础与特定于聊天的微调模型,详情参见 https://arxiv.org/abs/2307.09288
尽管 RLHF 作为一个新颖且充满潜力的技术,在 InstructGPT、ChatGPT 和 Llama 2 之外并未广泛采用,我还是对发现其日益增长的受欢迎度的图表感到意外。由于 RLHF 技术的应用还不普遍,这种趋势出乎我的意料。

这是从 State of AI 2023 报告中提取的关于 RLHF 流行度上升的趋势图表。
强化学习从人类反馈(RLHF)的过程比较复杂,不易操作,所以许多开源项目依然选择在指导性微调上做监督学习。
最近,有了一个新选择叫做直接偏好优化(DPO)。相关论文中,研究者们发现,原本用于在 RLHF 中调整奖励模型的交叉熵损失,可以直接应用于大语言模型(LLM)的微调。他们的基准测试显示,DPO 不仅效率更高,而且通常在生成回应的质量上也比 RLHF/PPO 更胜一筹。
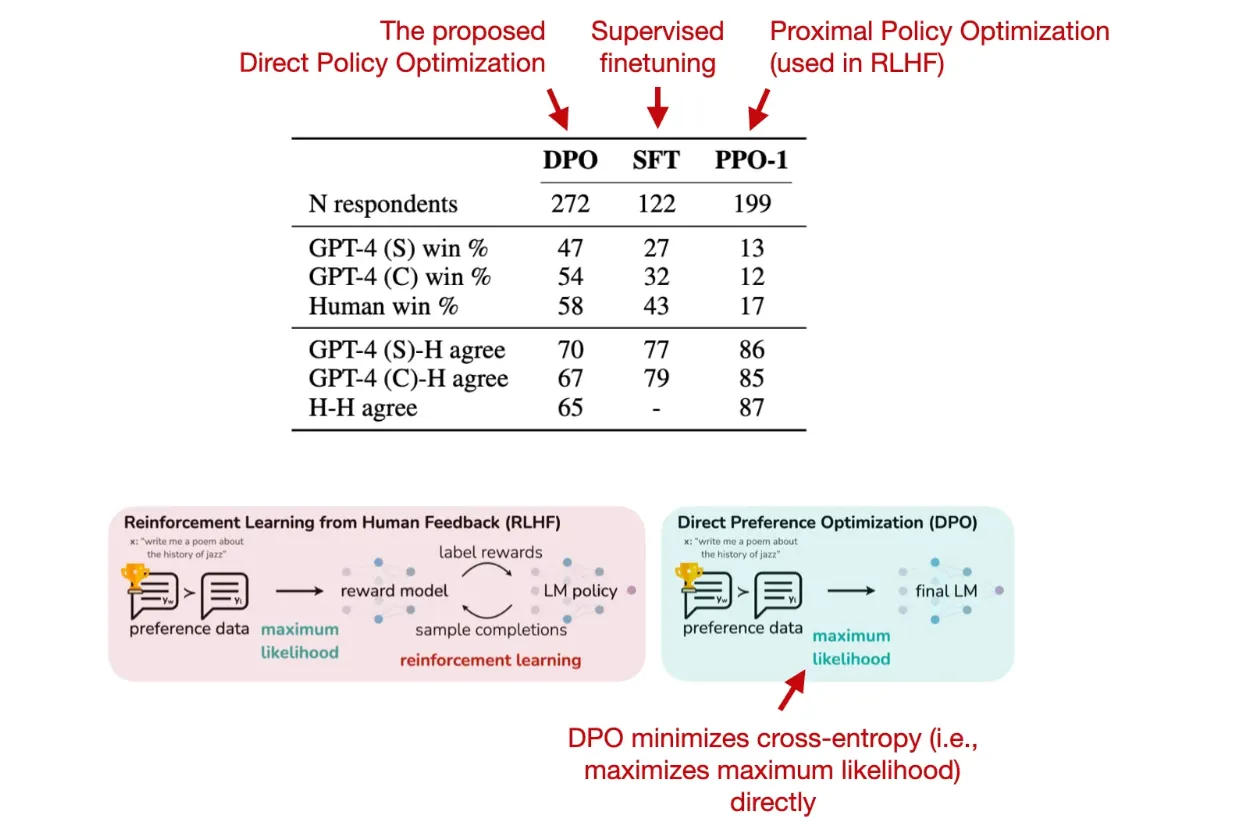
图中为 DPO 论文 中的解释性插图
目前,DPO 还没有普及。但是,让人振奋的是,两周前我们首次看到了一个经 DPO 方法训练出的开源大语言模型。这个模型由 Lewis Tunstall 和他的同事们开发 DPO via Lewis Tunstall and colleagues,在性能上似乎已经超过了采用 RLHF 训练的更大的 Llama-2 70b 对话模型:
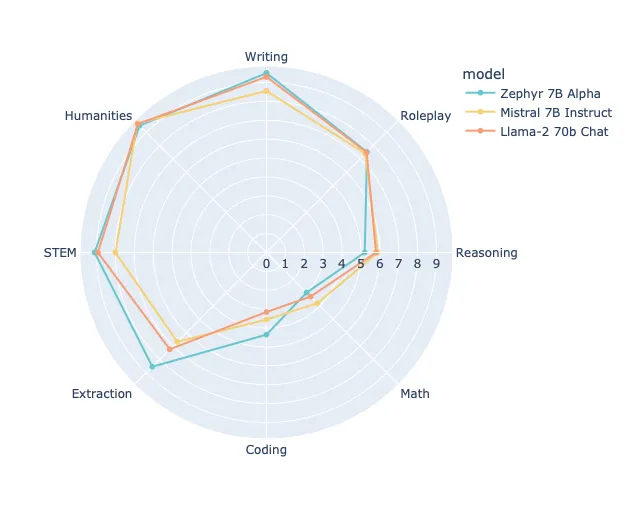
截自 Zephyr 7B 发布公告 不过,我们要注意的是,RLHF 技术并不是专门用来提升基准测试的性能;它主要的优化目标是“有用性”和“无害性”,而这些是通过人类用户来评判的,本次公告并没有涉及这方面的内容。 # 谁来分类?上周,我在 Packt's 生成式 AI 会议 上进行了一次演讲,时间是几周前,我强调了文本模型最常见的应用之一还是分类任务。比如,我们熟悉的电子邮件垃圾过滤、文档归类、客户评价分类以及社交媒体上的有害言论标注等。
基于我的实践经验,即使是使用“小型”的大语言模型(LLMs),比如 DistilBERT,仅用一块 GPU,也能取得相当不错的分类效果。

这是我会上演讲的一部分,向大家展示了怎样将小型的 LLMs 用作文本分类器进行细致调整 在今年我开设的 深度学习基础课 的第 8 单元,我发布了一个练习,是关于如何使用小型的 LLMs 来做文本分类的。其中,Sylvain Payot 通过对现成的 Roberta 模型进行微调,在 IMDB 电影评论数据集上取得了超过 96% 的预测准确率。作为对比,我曾经用那个数据集训练的最好的传统机器学习模型——词袋模型,其准确率只有 89%。

在我教授的《深度学习基础》课堂上,我们探讨了什么是最佳的分类模型。
不过,直到现在,我还没有发现任何关于分类的大语言模型(LLMs)的重大新进展或趋势。大部分从业人员还是倾向于使用基于 BERT 的编码模型或者像 2022 年推出的 FLAN-T5 这样的编码 - 解码模型。这或许是因为这些模型的表现依旧出乎意料地好,而且相当给力。
表格数据现状速览
2022 年,我写了篇博客《简述表格数据深度学习的发展历程》,里面介绍了许多深度学习处理表格数据的新颖方法。但是,和上面提到的用于分类的 LLMs 类似,表格数据领域似乎也没什么太大的进展,或者是我忙到没能跟上最新动态。
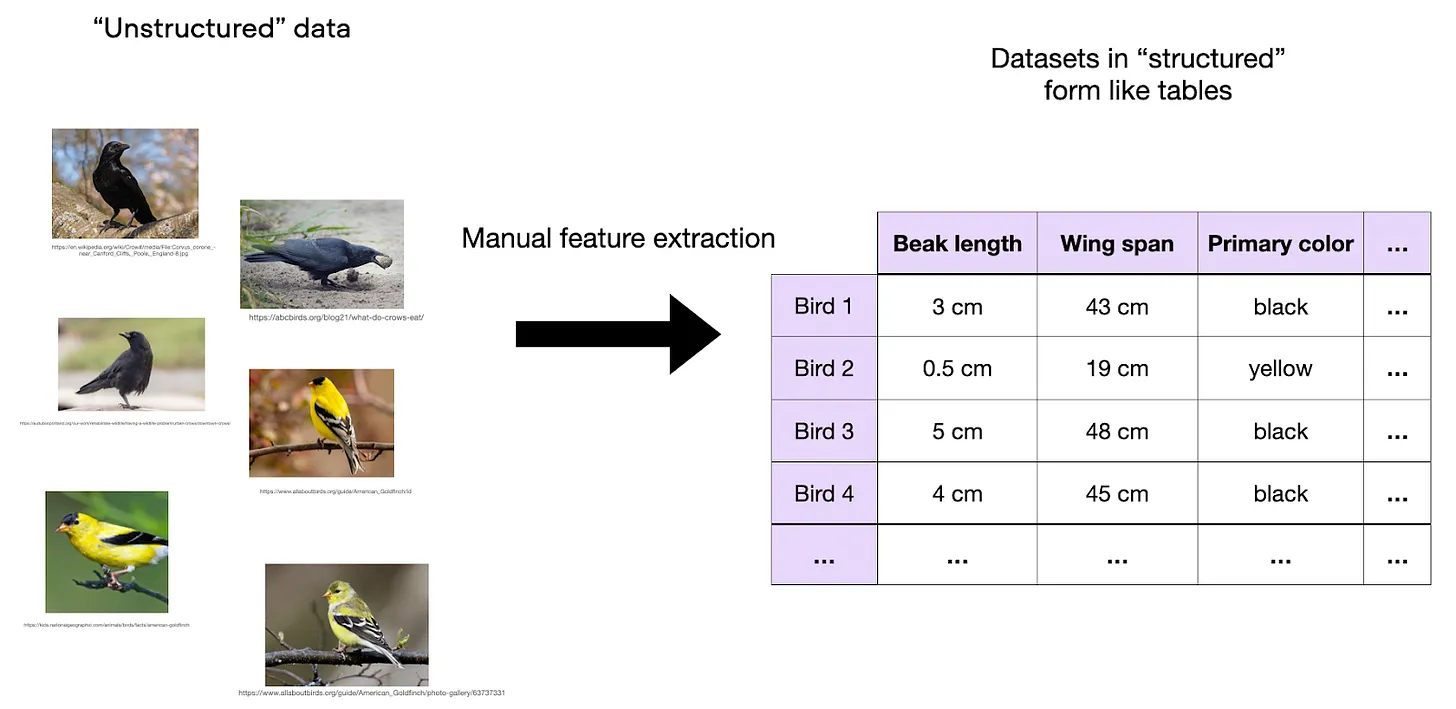
一个表格数据集的实例,供你参考。2022 年,Grinsztajn 和他的团队发表了论文 为何树形模型在表格数据处理上仍优于深度学习? 我认为论文中的核心观点——在小到中等规模的数据集上(例如 10k 训练样例),树形模型(比如随机森林和 XGBoost)仍然比深度学习方法表现得更好——依旧成立。
在这个话题上,XGBoost 在近十年的发展后,发布了具有里程碑意义的 2.0 版本,这个版本在内存效率上做得更好,支持内存容量以外的大数据集处理,加入了多目标树等诸多新功能。
2023 年计算机视觉回眸
尽管今年的热点集中在 LLMs 上,但计算机视觉领域也不断进展。鉴于篇幅所限,我不打算赘述最新的计算机视觉研究。不过,我有一篇关于《2023 年计算机视觉研究概况》的文章,它是我参加了今年夏天的 CVPR 2023 后所写:
人工智能前沿 #10:2023 年计算机视觉状况
塞巴斯蒂安·拉斯卡 博士 · 7 月 6 日
人工智能前沿 #10:2023 年计算机视觉状况 尽管大语言模型(LLM)的开发步伐未减,AI 规制的争论不断,但与之相关的新闻似乎比以往来得慢了一些。此刻正好可以把目光转向一直在辛勤工作却不太引人注意的计算机视觉领域,探讨它目前的研究进展和发展动态。讨论这个话题,也恰好与我参加的 2023 年温哥华 CVPR 大会的精彩回顾相吻合,那是迄今我体验过的最佳会议场地。阅读完整故事
除了学术研究,计算机视觉技术在人工智能领域催生了许多新产品和体验,它们在今年获得了显著的成长。
比如,今年夏天我在奥斯汀参加 SciPy 会议 时,亲眼目睹了首批真正的无人驾驶 Waymo 汽车在街上行驶。
在电影产业,AI 的应用越来越普及,最近的一个案例就是电影《印第安纳·琼斯 5》里,制片方用 AI 技术恢复了哈里森·福特的青春面貌,他们利用演员过去的影像资料来训练 AI。
还有,生成型人工智能(generative AI)技术已经成为许多流行软件产品的核心功能。Adobe's Firefly 2 就是一个新近的例证。
展望 2024
预测总是充满变数和挑战。回顾去年,我曾预见大语言模型(LLMs)将拓展到文本和编码之外的新领域。比如,“HyenaDNA”(HyenaDNA)就是专门解析 DNA 的语言模型。又如“Geneformer”(Geneformer),这是一个预先在 3000 万个单细胞转录组上进行训练的模型,旨在推动网络生物学的预测能力。
展望 2024 年,LLMs 预计将在计算机科学之外的 STEM 研究领域发挥更大影响。
另一方面,由于高性能 GPU 紧缺,各大公司纷纷开发定制的 AI 芯片。Google 正在对其 TPU 硬件(TPU 硬件)进行加倍投资,Amazon 已推出了 Trainium 芯片(Trainium 芯片),AMD 也可能在与 NVIDIA 的竞争中迎头赶上。Microsoft(Microsoft)和 OpenAI(OpenAI)也加入了自主研发 AI 芯片的行列。他们面临的挑战是如何在主流的深度学习框架中全面、稳定地支持这些硬件。
在开源界,我们还未能追上那些最大型的封闭源代码模型的步伐。目前公开的最大模型是 Falcon 180B(Falcon 180B)。但这不必过于忧虑,毕竟大部分人并没有足够的硬件资源去运行这些庞大的模型。与其追求更大型的模型,我更期待能看到更多开源的 MoE(专家模型)出现,它由多个小型子模块组成,更早前我在文章中已有讨论。
我还对人们共同创建数据集的热情和 DPO(DPO)在顶尖开源模型中取代传统监督式微调的趋势感到乐观。
今年夏天,我在 Leanpub 平台上发布了我的新作《Machine Learning Q and AI》的电子版草稿。现在,我非常激动地告诉大家,这本书的印刷版本已经可以在 No Starch Press 和 Amazon 网站预购了。之所以选择与 No Starch Press 合作出版,是因为我之前阅读过他们出版的几本书,深深被那些书的印刷品质所打动。
这本书经过了严格的编辑和打磨,可以说是字字斟酌,句句经典。新书名为《Machine Learning and AI Beyond the Basics》,相信会给读者带来全新的阅读体验。