如何理解关于 OpenAI Q* 的流言 [译]
OpenAI 还没具体说明 Q* 是什么,但已经透露了许多线索。
TIMOTHY B LEE 2023 年 12 月 7 日
11 月 22 日,就在 OpenAI 因某些原因解雇后又重新聘用了 CEO Sam Altman 几天之后,The Information 的一篇报道指出 OpenAI 实现了一个技术上的飞跃,这使得他们可以构建更加强大的人工智能模型。这个新模型被称为 Q*(读作“Q 星”),它能够解决一些它之前未曾遇到的数学问题。
路透社 也发布了相似的报道,但具体细节不甚明了。
两家媒体都提到,这一技术突破是导致董事会决定解雇 Altman 的原因之一。据路透社报道,一些 OpenAI 的员工曾向董事会发出警告,称他们发现了一种可能对人类构成威胁的强大人工智能。然而,路透社并未能获得这封信的副本,而且后续报道并未将 Altman 被解雇与对 Q* 的担忧直接关联起来。
The Information 报道称,今年早些时候,OpenAI 开发出了一种能够解决基础数学问题的系统,这对现有的 AI 模型来说是一项挑战。路透社则描述 Q* 能够执行小学生水平的数学运算。
在对这些报道进行猜测之前,我决定先花几天时间来深入研究。尽管 OpenAI 还没有公开其所谓的 Q* 突破的具体细节,但他们确实发表了两篇关于努力解决小学数学问题的论文。除此之外,包括谷歌 DeepMind 在内的其他研究机构也在这一领域做出了重要贡献。
我对 Q*——无论它是什么——是否真的是那个能够引领我们走向人工通用智能的关键突破持怀疑态度。我也不认为它会对人类构成威胁。但它或许是迈向具备一般推理能力的 AI 的重要一步。
在这篇文章中,我将带你深入了解这一 AI 研究领域的核心,并解释为什么针对数学问题设计的逐步推理技术可能在更广泛的应用中发挥重要作用。
逐步推理的威力
想象一下这样一个数学难题:
约翰先后给苏珊送了五个和六个苹果。苏珊吃掉了三个苹果,又把三个给了查理。剩下的苹果她全部交给了鲍勃,而鲍勃吃了一个后把剩下的一半给了查理。接着,约翰又送了查理七个苹果,而查理把这些苹果的三分之二给了苏珊。最后,苏珊又把四个苹果给了查理。问现在查理有多少苹果?
在你继续阅读之前,不妨试试看自己能否解出这个问题。我会等着你。
我们大部分人在小学就已经记住了像 5+6=11 这样的基础数学知识。因此,如果问题只是简单地问“约翰给了苏珊五个苹果,随后又给了她六个”,我们很快就能算出苏珊有 11 个苹果。
然而,在面对更复杂的题目时,我们通常需要在纸上或心里记录下每一步的计算过程。比如,我们会先算出 5+6=11,接着是 11-3=8,然后是 8-3=5,依此类推。通过逐步的思考,我们最终能够得出正确答案:8。
这种方法同样适用于大语言模型。谷歌研究人员在他们2022 年 1 月的重要论文中指出,如果大语言模型能够被引导去一步步推理,它们就能得出更准确的结果。以下是他们论文中的一个关键图示:

这篇论文是在“零样本”(Zero-shot)提示成为常态之前发表的,因此研究者通过提供一个示例解答来引导模型。在左侧列示中,模型被直接引导去找出最终答案,但结果却是错误的。而在右侧,模型被引导逐步推理,最终找到了正确答案。谷歌的研究者们将这种技术称为“思维链提示”,它至今仍被广泛应用。
如果你之前阅读过我们在 7 月份发表的关于大语言模型解析的文章,你或许能理解为什么会发生这种情况。
对大语言模型(LLM)来说,数字如“5”和“6”只是普通的 Token,和“the”或“cat”没什么两样。LLM 能学会 5+6=11,是因为在它的训练数据中,这种 Token 序列及其变体(比如“5+6=11”)出现了无数次。但这些训练数据很可能不包含像 ((5+6-3-3-1)/2+3+7)/3+4=8 这样的复杂计算例子。因此,当要求语言模型一次性解决这样的计算问题时,它很可能会混淆,从而得出错误的答案。
换个角度来看,大语言模型并没有外部的“草稿空间”来记录中间计算结果,比如 5+6=11。通过链式思考推理(chain-of-thought reasoning),LLM 可以有效地利用自己的输出作为草稿空间。这使得它能将复杂问题分解成若干容易处理的小步骤——每个步骤都极有可能对应训练数据中的某些实例。
探索更高难度的数学难题
在 Google 发布其关于“链式思考提示法(chain-of-thought prompting)”研究的几个月前,OpenAI 推出了一个含有 8500 道小学数学应用题的数据集(名为 GSM8K)以及一篇描述解题新技术的论文。与其仅生成单一答案,OpenAI 则让大语言模型 (LLM) 输出 100 个连续思考的答案,并运用另一种模型——验证器——对每个答案进行评分。在这 100 个答案中,系统最终呈现出评分最高的答案。
你可能会以为,训练一个验证器模型会和训练一个能生成正确回答的大语言模型一样困难,但 OpenAI 的测试结果却显示了不同的情况。OpenAI 发现,即使是小型生成器结合小型验证器,也能产生与单独使用大型生成器(后者的参数量是前者的 30 倍)相似的效果。
一篇 2023 年 5 月发布的论文更新了 OpenAI 在此领域的最新研究进展。OpenAI 已经从解决小学数学题目转向挑战更复杂的数据集(称为 MATH)。与之前不同的是,OpenAI 现在正在训练验证器去评估解题过程中的每一步,就像论文中所示的图表:

每一步都有一个绿色笑脸标志,表示解题过程是正确的,直到最后一步出现“所以 x=7”的结论时,出现了一个红色不开心的脸,表示答案有误。
这篇论文的主要结论是,使用验证器来逐步检验解题过程比在最终才核验整个解决方案能够获得更优的结果。
这种分步骤验证技术的主要问题在于其自动化程度较低。MATH 训练数据包含了每个题目的正确答案,使得自动检测模型是否得出正确结论变得简单。然而,OpenAI 并没有找到一个有效的方法来自动核实这些中间步骤。因此,公司最终聘请了人工评估员,他们为 75,000 个解决方案中的 800,000 个步骤提供了反馈。
探索解决之道

图片来源:SimpleImages / Getty Images。
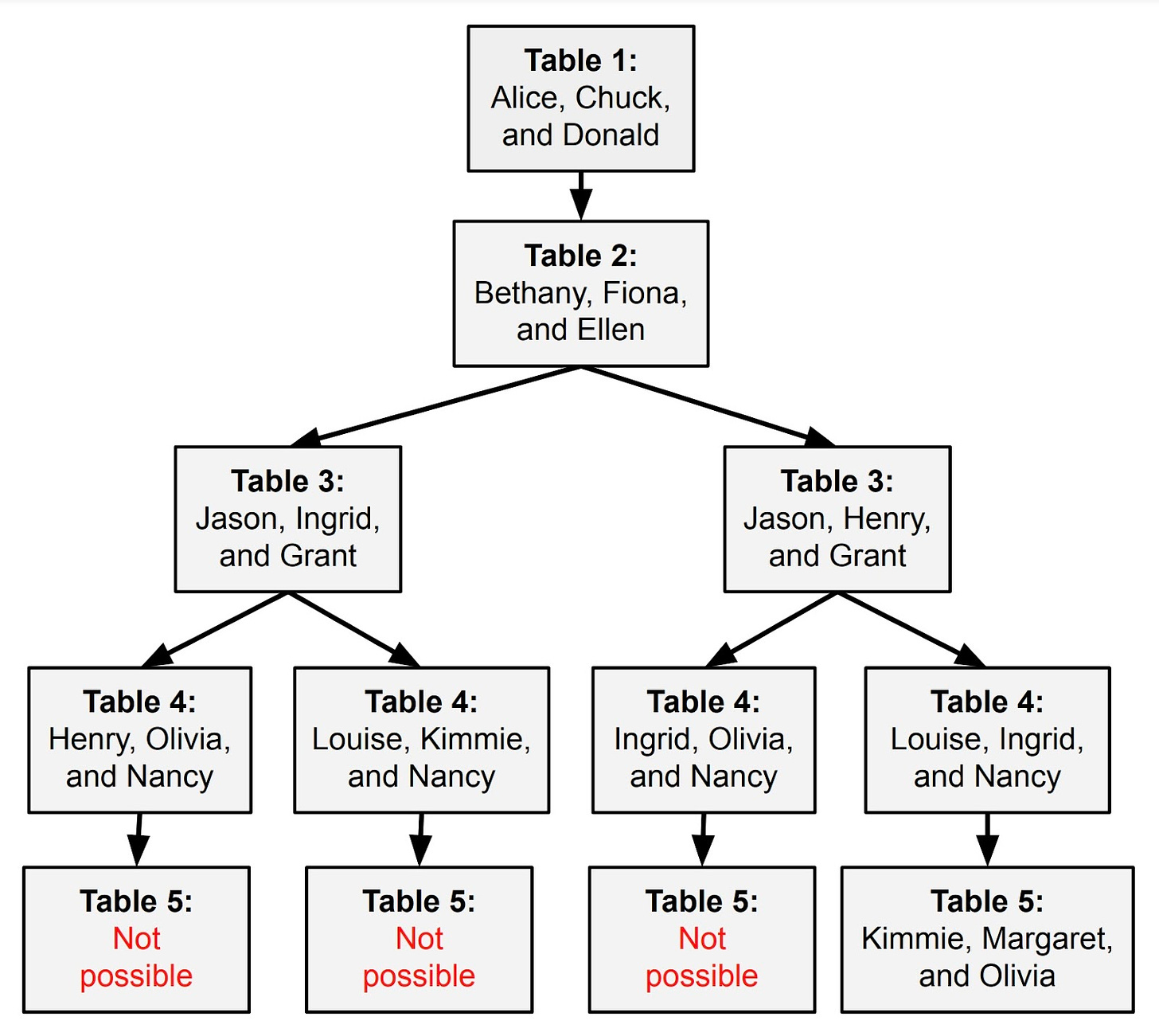
在 GSM8K 和 MATH 数据集中的问题通常可以通过简单的逐步方法来解决,但并不是所有的数学问题都这么直接。以这个问题为例:
你正筹划一个婚礼宴会,有五张桌子,每桌坐三位客人。
Alice 不愿意和 Bethany、Ellen 或 Kimmie 同桌。
Bethany 不想和 Margaret 同桌。
Chuck 不愿意和 Nancy 同桌。
Fiona 不想和 Henry 或 Chuck 同桌。
Jason 不想和 Bethany 或 Donald 同桌。
Grant 不愿意和 Ingrid、Nancy 或 Olivia 同桌。
Henry 不愿意和 Olivia、Louise 或 Margaret 同桌。
Louise 不想和 Margaret 或 Olivia 同桌。你该如何安排宾客就坐,以确保这些偏好都被考虑到?
当我将这个问题交给 GPT-4 时,它开始尝试解答,按步骤进行推理:
-
第一桌: Alice、Chuck 和 Donald。
-
第二桌: Bethany、Fiona、Ellen
-
第三桌: Jason、Grant、Ingrid
但在安排到第四桌时,它遇到了难题。Henry、Margaret 或 Louise 还没有被安排座位,他们互不愿意同桌,而此时只剩下两张桌子了。
在这种情况下,我们无法明确指出 GPT-4 在哪一步出了错。它在安排前三桌时的选择似乎都合情合理,但这些早期的决定最终导致无法为剩余的客人安排合适的座位。
计算机科学家将其定义为 NP-hard 问题,即不存在一种普遍的线性解决算法。解决这类问题,我们只能尝试一个可能的解决方案,检验其是否有效,若不行则进行回溯。
对于 GPT-4 来说,它可以通过向其上下文窗口增加更多文本来实现这种回溯,但这种方法并不适合大规模应用。更优的方案是赋予 GPT-4“退格键”,使其能删除最后(或最后几个)推理步骤,然后重新尝试。要使这种方法行之有效,系统还需能够追踪已尝试过的组合,以避免重复努力。这样,大语言模型就能探索一个可能性树,其形式如下图所示:
今年五月,普林斯顿大学和谷歌 Deepmind 的研究人员 发表了一篇论文,提出了名为“思考树(Tree of Thoughts)”的方法。这种方法让大语言模型能够系统地探索一系列推理链,这些链条会朝不同方向展开。
研究发现,这种算法在一些难题上表现出色,这些问题对传统大语言模型而言颇具挑战——不仅包括一个称为“24 点游戏”的数学难题,还有创意写作任务。
AlphaGo 模型
我刚刚讲述了 OpenAI 和 DeepMind 迄今为止发表的关于提升大语言模型 (Large Language Model) 解决数学文字题能力的研究。现在,我们来展望一下,讨论这些研究可能的未来方向。虽然我没有任何内部信息,但如果你知道如何观察,就不难理解这些暗示。
2022 年 10 月,播客主持人 Dwarkesh Patel 曾采访 DeepMind 的联合创始人兼首席科学家 Shane Legg,探讨该公司实现通用人工智能 (AGI) 的目标。Legg 认为,实现 AGI 的关键一步是将大语言模型与搜索可能答案的树状结构相结合:
这些基础模型其实是一种世界模型,要解决复杂有创意的问题,就需要启动搜索过程。就拿 AlphaGo 和它在比赛中著名的第 37 步举例,这一步是怎么来的?是来自它对人类棋局数据的学习吗?并非如此。它是通过识别一个看似不太可能但又合理的走法,然后通过搜索过程,逐步认识到这其实是一个极佳的着法。因此,要想真正创新,就需要在可能性的海洋中搜索,发掘那些隐藏的珍宝。
Legg 提到的“著名的第 37 步”,是指 AlphaGo 和世界顶级围棋手李世石在2016 年对决中的第二局。当时,大多数围棋专家起初都认为 AlphaGo 的这一步是失误。但最终 AlphaGo 赢得了比赛,事后分析证明这实际上是一个高明的着法。AlphaGo 在这一过程中领悟到了围棋的某些人类棋手未曾触及的奥秘。
AlphaGo 通过模拟成千上万种从当前棋盘状态出发的可能棋局来获得这样的领悟。由于可能的走法序列太多,电脑无法一一检查,AlphaGo 便利用神经网络来使这个过程可控。
其中一个名为策略网络 (policy network) 的网络用于预测哪些走法最有前景,从而值得在模拟对局中尝试。另一个名为价值网络 (value network) 的网络则估算结果棋盘状态对于黑白双方的利弊。AlphaGo 基于这些评估,从而反向确定下一步的最佳走法。
Legg 提出的观点是,一种类似树搜索的方法可能会增强大语言模型(Large Language Model)的推理能力。这种模型不仅仅是预测一个最有可能的 Token,而是在确定答案之前,可能会探索数千种不同的回答。实际上,DeepMind 的思考树(Tree of Thoughts)论文看起来就是向这个方向迈出的第一步。
我们之前看到,OpenAI 尝试通过一个生成器(产生可能的解决方案)和一个验证器(判断这些解决方案是否正确)来解决数学问题。这和 AlphaGo 的设计有明显的相似之处,AlphaGo 有一个策略网络(产生可能的棋步)和一个价值网络(估计这些棋步是否能带来有利的棋盘局面)。
如果把 OpenAI 的生成器和验证器网络与 DeepMind 的思考树(Tree of Thoughts)概念结合起来,我们可能就能得到一个像 AlphaGo 那样运作的语言模型,它可能也会具备 AlphaGo 那样强大的推理能力。
为何称其为 Q*
在 AlphaGo 出现之前,DeepMind 在 2013 年发表了一篇论文,论述了如何训练一个神经网络来赢得雅达利视频游戏。与其手动编写每款游戏的规则,DeepMind 让网络实际玩雅达利游戏,通过试错法来学习游戏规则。
DeepMind 将其雅达利游戏的解决方案命名为 Deep Q-learning,这是基于一种名为 Q-learning 的早期强化学习技术。其雅达利 AI 中包含一个关键功能——Q 函数,用于估算任何特定操作(比如向左或向右移动摇杆)可能获得的奖励(如更高分数)。随着 AI 玩雅达利游戏,它逐渐优化 Q 函数,以更准确预测哪些动作能取得最好的成绩。
在 2016 年的 AlphaGo 论文中,DeepMind 再次使用了字母 Q 来表示 AlphaGo 的动作价值函数——这是一个用来评估任何特定移动赢得比赛可能性的功能。
无论是 AlphaGo 还是 DeepMind 的雅达利 AI,都是强化学习的典型应用。强化学习是一种通过经验学习的机器学习技术,也曾是 OpenAI 在大语言模型崛起前的重点研究领域。例如,OpenAI 在 2019 年利用强化学习训练了一只机器手,使其能够自主解决魔方。
结合以上背景,我们可以合理推测 Q* 是一种尝试:结合大语言模型和 AlphaGo 风格的搜索技术,并且最好是通过强化学习对这种混合模型进行训练。理想的目标是找到一种方法,使语言模型能够通过在复杂的推理任务中“自我对弈”来提升自身。
此处值得注意的一点是,OpenAI 今年早些时候聘请了计算机科学家 Noam Brown。Brown 在卡内基梅隆大学获得了博士学位,他开发了世界上第一个能够超越人类水平玩扑克的 AI。随后,Brown 加入 Meta,开发了一个玩《外交》游戏的 AI。要在《外交》游戏中获胜,需要与其他玩家建立联盟,因此一个出色的《外交》游戏 AI 需要将战略思考与自然语言能力结合在一起。
这为那些致力于提高大语言模型推理能力的人提供了宝贵的经验背景。
“多年来,我致力于研究人工智能 (AI) 在诸如扑克和外交等游戏中的自我对抗与推理能力,”Brown 在 六月的一条推文中表示。“现在,我将探索如何将这些方法应用于更广泛的领域。”
AlphaGo 和 Brown 开发的扑克软件所用的搜索方法是专门针对这些特定游戏设计的。但 Brown 预言:“如果我们能开发出一种通用的方法,其益处将是巨大的。虽然这样的推理速度可能会慢上千倍,成本也更高,但想象一下,为了开发新的癌症治疗药物或证明黎曼猜想,我们愿意付出多大的努力和代价呢?”
Meta 的首席 AI 科学家 Yann LeCun 也相信 Brown 正在研究一个名为 Q* 的项目,Brown 曾在今年早些时候于 Meta 工作。
LeCun 在 11 月的一条推文中提到:“很有可能,Q* 是 OpenAI 在规划领域的一次尝试。他们实际上是为了这个项目才聘请了 Noam Brown。”
面临的两大挑战
你可能发现,科学家和工程师对白板情有独钟。回想我读计算机科学研究生时,我们常常围着白板讨论,上面画满了图表和方程,帮助我们攻克难题。就连我在谷歌纽约办公室实习的那个夏天,白板也随处可见。
白板之所以如此重要,是因为面对复杂的技术问题,人们起初往往无从下手。可能要花几小时勾勒出一个解决方案,最后却发现行不通,于是又得推翻重来,换个角度思考。有时候,他们会保留解决方案的前半部分,但后半部分得重新思索。
这其实就是一种智力上的“树状搜索”,即不断试错,直到找到真正有效的解决方案。
OpenAI 和 DeepMind 之所以对将大语言模型与 AlphaGo 式搜索树相结合充满期待,是因为他们希望这能让计算机进行类似的开放式智力探索。想象一下,晚上让一个大语言模型开始解决难题,第二天醒来,它可能已经筛选出了数千种可能的解决方案中的几个有潜力的。
这个愿景令人振奋,但要实现它,OpenAI 面临至少两大挑战。
首先是要让大语言模型能进行“自我对弈”。AlphaGo 通过和自己下棋,根据输赢学习。OpenAI 的魔方软件则是在模拟物理环境中练习,通过判断魔方是否被正确解开来学习有效的动作。
梦想是让大语言模型通过类似的自我对弈提高推理能力。但这需要一种能自动判断解决方案是否正确的方法。如果每次都需要人工检查答案的正确性,训练过程就不太可能达到与人类相媲美的规模。
截至 2023 年 5 月的一篇论文显示,OpenAI 仍在用人类来验证数学解决方案的正确性。因此,如果有什么突破性进展的话,那应该是在最近几个月内发生的。
学习:一个动态的过程
我觉得第二个挑战更加核心:通用推理算法需要能够在探索可能的解决方案时,实时地学习。
想象一下,当我们在白板上解决问题时,我们不仅仅是重复地尝试各种可能的方案。每次我们尝试一个失败的方案时,其实都在对问题有了更深入的理解。我们对正在思考的系统有了更好的心理模型,并对哪种类型的方案可能有效有了更直观的感觉。
换言之,人脑中的“策略网络”和“价值网络”是在不断变化的。我们在问题上投入的时间越多,我们就越能想出有前景的解决方案,并更准确地判断出一个提出的方案是否可行。如果没有这种实时学习的能力,我们就会在无限的推理步骤中迷失方向。
相比之下,现今大多数神经网络都严格区分了训练和推理阶段。比如一旦 AlphaGo 训练完毕,它的策略和价值网络就固定下来了——在比赛过程中不会有任何变化。对于围棋这样的游戏来说,这样做是可行的,因为围棋足够简单,可以在自我对弈中体验到所有可能的游戏情况。
但现实世界的复杂性远超围棋棋盘。从定义上说,从事研究的人正试图解决前人未曾解决的问题,所以这个问题很可能与训练时遇到的问题大不相同。
因此,一个通用的推理算法需要一种方法,能让在推理过程中获得的洞察反馈到模型在解决同一个问题时的后续决策中。但现在的大语言模型完全通过上下文窗口来维护状态,而“思考树”方法则是在模型从一个思考分支跳到另一个分支时删减上下文窗口的信息。
这里的一个可行方案是用图形搜索而不是树形搜索,这是在8 月的一篇论文中提出的。这样做能让大语言模型结合从不同“分支”中获得的洞见。
不过,我认为要构建一个真正的通用推理引擎,可能还需要更根本的架构性创新。需要的是一种方法,让语言模型能学习到超出其训练数据的新抽象概念,并让这些不断进化的抽象影响模型在探索解决方案时的决策。
我们知道这是可能的,因为人类大脑就是这样做的。但在 OpenAI、DeepMind 或其他机构找到如何在硅基环境中实现这一点之前,可能还需要一些时间。
感谢 Sam Hammond 对本文提供的宝贵见解。他还有一个关于 AI 和公共政策的精彩邮件订阅列表。