微服务的“死亡千刃” [译]
软件行业正在重新领悟一个老教训:复杂性是致命的
崇拜复杂性的教派
想象一个场景:一名工程师试图向项目经理解释,为了得到一个用户的生日,他们构建了一个错综复杂的微服务迷宫,结果却是徒劳无功。这一幕生动描绘了当前科技文化中的荒唐现象。我们对此哑然失笑,然而,若在正经的讨论中提起这件事,几乎等同于触犯了职业禁忌,让人边缘化至难以被聘用的地步。
我们怎么走到了这一步?为何我们的目标不再是解决眼前的问题,反而变成了烧掉一堆钱去应对那些根本不存在的问题?
触发警示:提到 JavaScript 和 NodeJS 是问题源头时,有些人可能会感到不悦,但我真正想强调的是,那些看似要不断重新学习我们刚刚结束学习的课程的封闭软件生态系统所带来的危险。我们以前就已经撞上了复杂性的高墙并选择了重置 - 否则我们现在仍将使用 CORBA 和 SOAP。这些孤立的开发者气泡对整个行业造成了巨大的破坏,而摆脱它们大约需要十年的时间。
完美风暴
近期历史上的几件事件可能对当前形势产生了重大影响。首先,众多开发者开始在浏览器中使用 JavaScript 编程,并自诩为“全栈”开发者,他们涉足服务器开发与异步编程。毕竟,JavaScript 不还是 JavaScript 吗?无论是开发用户界面、服务器、游戏还是嵌入式系统,使用它有什么区别呢?*对,不是吗?*然而,Node 当时仅仅是一个人的学习项目,而早期的 JavaScript 成为服务器开发的选择充满了问题。向那些尚未成熟的服务器端开发者指出这个问题,通常会引起他们的极度不满。毕竟,这是他们所了解的全部。在他们眼中,除了 Node,别无选择,Node 的方式成了唯一的方式,因此,我们至今还在应对这种固执与教条的思维模式。

接着,从FAANG退伍的资深人士开始加入到初创公司的洪流中,指导那些新晋且易受影响的年轻 JavaScript 服务器端工程师们。那些崇尚复杂性的前辈们断言,“在谷歌的做法”是毋庸置疑且正确的——即便这在特定的场景和规模下完全不适用。你怎么可能没有一个独立的_用户偏好服务_呢?这根本_不可能扩展,伙计!_
但是,将所有责任归咎于那些资深人士和新人其实是件容易的事。还有其他什么因素在起作用呢?哦,对了——轻松获得的资金。
当你拥有充足的风险资本时,你会做些什么呢?当然不是去追求收入。不止一次,我收到管理层的邮件,要求我们到办公室,整理桌面,表现得忙碌,因为一群 Patagonia 马甲即将巡视办公区。投资者想要看到的是爆炸性的增长,而不是盈利性的增长。他们只是想看到公司能多快地聘请价格高昂的软件工程师去完成……一些事情。
尝试我们的服务,为代码审查任务和通知提供便捷解决方案——友好之火:
-
直接在 Slack 中发送通知
-
自动略过不在岗的审查者
-
匹配文件模式
-
个别提醒进行代码审查
-
不需要访问您的代码库
现在,既然你已经招募到了这些开发人员,你打算怎样利用他们的才华呢?他们可以创建一个简单易维护且容易扩展的系统;或者,他们也可能设计出一个连设计者本人都难以完全理解的、由“微服务”构成的复杂体系。微服务(microservices)——编写可伸缩软件的新潮方法!难道我们要假装从未听说过“分布式系统”(distributed systems)这个概念吗?(我们这里不深入讨论微服务并非真正分布式系统的技术细节)。
回想起科技行业还未变成如今这般泛滥成灾的岁月,分布式系统曾经被重视、畏惧,通常只有在面对特别棘手的问题时,才会作为最后手段被考虑使用。与分布式系统相关的一切——无论是开发、调试、部署、测试还是系统的韧性——都会变得更加具有挑战性,耗时更长。但谁知道呢——也许在当下,由于强大的_工具_支持,一切变得轻而易举了。
针对基于微服务的开发,并没有一套标准的工具或通用的框架。即便到了 2020 年代,分布式系统的开发依然只是略显容易了那么一点。Docker 和 Kubernetes 这些工具,并没有如魔法一般消除分布式布局固有的复杂性。
我特别喜欢引用这篇5 年创业公司技术审计的总结,里面充满了一针见血的常识性结论:
…我们审计的那些现在发展得最好的创业公司,通常都采取了一种几乎到了无耻程度的‘保持简单’原则来进行工程设计。任何为了显摆聪明而做的复杂设计都是不被看好的。相反,那些让我们觉得“哇,这些人真聪明”的公司,大多数最终都黯淡无光了。
通常,过早转向微服务、依赖分布式计算的架构以及过度依赖消息传递设计,成为了让许多公司陷入困境的主要原因。
字面意义上——“复杂性致命”。
这次审计揭示了一个有趣的模式,即许多创业公司在构建直接、简单、高效的系统时,会体验到一种集体的冒名顶替综合征。一种围绕着不从第一天就开始使用微服务的耻辱感——不管面对什么问题。“大家都在使用微服务,而我们只有一个由几位工程师维护的单体 Django 系统和一个 MySQL 实例——我们哪里做错了?”几乎总是,“你们没有做错任何事”。
同样,即使是经验丰富的工程师在当今的科技界也常常感到迷茫和不自信,但好消息是,问题可能并不出在你身上。团队有时候会装作他们在做“大规模网络开发”,隐藏在各种库、对象关系映射(ORMs)和缓存技术背后——他们对自己的技术水平过于自信(毕竟他们轻松解决了 Leetcode 上的难题!),但他们可能连数据库索引的基本知识都不了解。你正处于一个充满无端自信、资源浪费和邓宁 - 克鲁格效应的环境中,那么,真正的冒充者又是谁呢?
单体结构也未尝不可
那种认为只有拥有复杂系统才能成长的观念,实际上是一个迷思。

Dropbox、Twitter、Netflix、Facebook、GitHub、Instagram、Shopify、StackOverflow —— 这些知名公司最初都是以单一代码库的形式启动的。直至今日,许多公司的核心仍然是单体结构。StackOverflow 就以其用极少的硬件运行庞大网站为荣【链接】。Shopify 依然运行着一个 Rails 单体应用,通过使用经过验证的 Resque 来处理数以十亿计的任务。
WhatsApp 如何仅凭借其 Erlang 单体应用和相对较小的团队实现快速增长?
WhatsApp 有意地保持工程团队规模小,仅约 50 名工程师。
每个工程团队的规模也很小,通常由 1 到 3 名工程师组成,每个团队都享有很大的自主权。
在服务器选择上,WhatsApp 倾向于使用较少的服务器数量,并尽可能地对每台服务器进行垂直扩展。
Instagram 则是以一个仅有 12 人的团队被收购,价值数十亿美元。
而对于 Threads,你可能认为其开发涉及整个 Meta 集团的资源?事实并非如此。他们采取了与 Instagram 类似的模式,这就是整个 Threads 团队的全貌:

来源:Substack - The Pragmatic Engineer
也许,声称你面临的特定领域问题需要一个复杂的分布式系统和一个充满“天才”的开放式办公空间,实际上更多的是自负,而不是真正的才智呢?
避免空担心:只解决当前面临的问题
这是一个看似简单却至关重要的问题:你的目标是解决什么问题?是否在追求系统规模的增长?如何分析并确定系统的扩展性和性能需求?你是否收集了充足的数据来明确分离服务的必要性及其原因?分布式系统旨在实现规模扩大与系统弹性,但真正的挑战是如何保证系统在扩展时仍保持高度的稳定性。如果系统中的某个服务出现故障或响应缓慢,你会怎么办?仅仅通过扩展服务规模来应对吗?而当其他服务遭受流量冲击时又该如何应对?你是否对可能发生的各种情况进行了充分预演,包括系统是否有足够的容错机制,如反压、断路、队列管理、网络抖动处理和各服务端点的超时设置?是否有充分的安全措施,确保简单的变更不会导致整个系统崩溃?对于系统性能的调整和优化需要密切关注,因为这些因素会根据系统的实际使用和负载情况而有所不同。
大多数公司实际上可能永远不会达到需要构建复杂分布式系统的规模。盲目模仿像亚马逊和谷歌这样的巨头,而忽视了自身规模、专业知识和资源的限制,最终可能只会导致资源的巨大浪费。认真执行一些所谓的“成功人士早晨习惯”并不能保证成功。
处理一个糟糕的分布式系统可能比构建一个分布式系统本身更加困难。
“团队各自为政,独立但又需要交流,API 成了唯一桥梁”
将分布式架构融入公司的运作被视为一种理想,但实际操作起来往往适得其反。常见做法是将大问题拆解成小块,逐个击破。因此,理论上将一个服务拆分为多个服务听起来会简化问题。
这个理念听上去非常美好和优雅 - 每个微服务都有一个专门的团队在背后精心维护,通过一套完美的、向后兼容的、带版本的 API 与外界隔离。实际上,这种做法非常稳固,以至于团队之间的沟通变得少之又少 - 宛如这些微服务是由外部供应商提供和维护的。听上去很简单!
如果你觉得这听起来很陌生,那是因为实际情况很少如此。实际上,我们的 Slack 频道常常被各种关于发布、缺陷、配置更新、破坏性更改以及公告的消息淹没。每个人都需要随时掌握所有信息。更不用说,经常有一些已经忙不过来的团队对多个微服务敷衍了事,而不是专注做好一个服务。随着人员变动,服务的负责人也频繁更换。
在这场竞赛中,我们并没有打造一辆优秀的赛车,反而是制造了一整队表现平平的高尔夫球车。
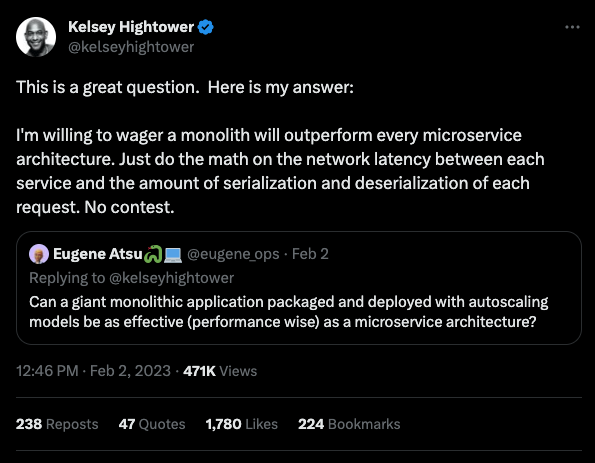
失去了什么
采用微服务架构构建系统有不少陷阱,而这些问题往往要么被忽视,要么根本没有得到足够的重视。团队可能会花费数月的时间开发高度定制化的工具,学习与核心产品毫不相关的课程。以下是一些经常被忽略的问题……
与 DRY 原则说再见
经过几十年来教育开发者编写不重复(Don’t Repeat Yourself)代码的传统,现在似乎我们已经完全停止了讨论。默认情况下,微服务并不遵循 DRY 原则,每个服务中都
充斥着重复的模板代码。往往这些“基础设施”工作的负担如此之重,微服务本身的规模如此之小,以至于每个服务实例中“服务”的成分远大于“产品”的成分。那些可能共享的代码该怎么处理呢?
- 是否建立一个公共库?
- 公共库该如何更新?是否要在每处都保留不同版本?
- 是否定期强制更新,从而在所有仓库中创建大量的拉取请求?
- 是否将所有代码保留在一个单一仓库中?但这同样会带来自己的问题。
- 是否允许一定程度的代码重复?
- 忘了它,每个团队都要每次重新发明轮子。
面对这些抉择,每个公司都必须找到自己的痛苦之路。
开发者的效率挑战将变得更加严峻
“开发者效率”涉及的是开发人员在完成工作—不论是开发新功能还是修复 bug—所必须克服的障碍和所需付出的努力。
面对微服务架构,工程师需要有一个对整个系统全局的理解,以便知道执行特定任务时应该启动哪些服务,需要与哪些团队沟通,找谁讨论相关问题。这就体现了一种“行动前必须全知”的原则。怎样才能做到这一点呢?Spotify,一家价值数十亿美元的公司,为了管理其庞大的系统和服务,投入了相当一部分内部资源开发了 Backstage。
这至少告诉我们,这样的挑战并不适合每个人,其代价相当高昂。那么对于那些工具怎么办呢?非 Spotify 们只能依靠自己创造解决方案,其稳定性和可移植性的实际效果,你可能已有所预料。
真正有多少团队能够有效简化启动一个新服务—“又一个不必要的服务(YASS)”—的流程呢?包括:
- 在 GitHub/GitLab 中赋予开发者的权限
- 预设的环境变量和配置
- 持续集成/持续部署(CI/CD)
- 代码质量检测工具
- 代码审查配置
- 分支管理规则与保护措施
- 监控与可观察性
- 测试框架
- 代码即基础设施
并且,根据公司使用的不同编程语言的数量,这个清单还会相应增长。或许你已经有了一个可行的模板或操作指南?或者是一个无需繁琐步骤、一键即可启动新服务的系统?要彻底解决这种自动化过程中的问题,可能需要数月的时间。因此,你面临的选择是:专注于产品开发,或者投入时间在工具开发上。
集成测试 - 真是讽刺
就好像日常的微服务磨砺还不够似的,你还得放弃那种通过稳健集成测试而来的心理安宁。你的单服务和单元测试可能顺利通过,但每次代码提交后,那些至关重要的业务流程还能完好无损吗?整个集成测试套件的责任又落在谁身上,在 Postman 或其它地方呢?我们真的有这样的测试套件吗?

对于分布式架构的集成测试几乎是个不可能完成的任务,因此我们几乎放弃了这种尝试,转而采用另一种解决方案 - 可观测性。正如“微服务”成为了“分布式系统”的新代名词,“可观测性”也成了“生产环境下的调试”的新说法。没错,如果你不在进行……可观测性,那么你可能并不是在进行真正的软件开发!
可观测性已经发展成为一个独立的领域,你需要为此付出不菲的代价和开发时间。而且,它也不是即插即用的 - 你需要去理解和实施金丝雀发布、功能开关等策略。这项工作是由谁来完成的呢?难道是那位已经应接不暇的工程师吗?
如你所见,简单地将问题分解并不会使得解决它们变得更容易 - 你面对的只是另一组更加棘手的问题。
不,采用单体架构并不意味着“代码更优”
这些论点常常被误解为,似乎是在暗示单体架构代表“优质代码”,而微服务架构则意味着“可能是糟糕的代码”。虽然后者可能是对的,但我从未直接表明单体架构的代码就默认优秀。世界上充斥着由仓促的团队编写的、平庸的单体应用,这些都是中等水平的产物。遇到性能瓶颈时怎么办?增加更多的 CPU 和内存,你就能再苟延残喘几年。我经常对自己那些平凡无奇的代码为何能在生产环境中运行得如此顺畅感到好奇——直到我看到了服务器的配置。
然而,分布式系统对于偷工减料、错误决策、以及忽略的失败模式毫不留情。你需要始终保持最佳状态,否则你必将面临惩罚。
为什么只谈“服务”?
我们为什么偏爱“微服务”而不是简单的服务体系呢?一些创业公司甚至更进一步,每个功能都搭建了一个独立的服务,而这不就跟 Lambda 服务类似吗?这种情况让我们看到了这股不加选择地盲目跟风已经到了什么程度。
那么,我们应该如何应对呢?首选的方案之一就是从一个整体的单体应用开始。另一个在许多情况下也十分有效的设计模式是“主体与分支”,即主要的核心单体应用得到了一系列“分支”服务的支持。这些分支服务能够负责特定的、可单独扩展的负载。例如,一个消耗大量 CPU 资源的图像缩放服务远比一个用户注册服务来得更有实际意义。毕竟,你的注册操作并不会每秒钟达到需要独立扩展的量级,对吧?

补充说明:谈到版本控制,回想 CVS 和 Subversion 的时代,我们很少使用“主”分支。我们采用的是“主干与分支”的方式,寓意于 - 树。后来,“主”分支逐渐流行起来,当 GitHub 决定改变这一不太恰当的命名习惯时,许多工程师由于年轻,几乎忘记了“主干”的概念,于是“main”成为了新的默认选项。

趋势正在逆转
然而,这波炒作似乎正在退烧。随着风投资金的逐渐紧缩,企业开始被迫做出更具常识性的决策,认识到在他们面临的并非互联网级别的问题时,盲目追求互联网规模的架构是不可持续的。
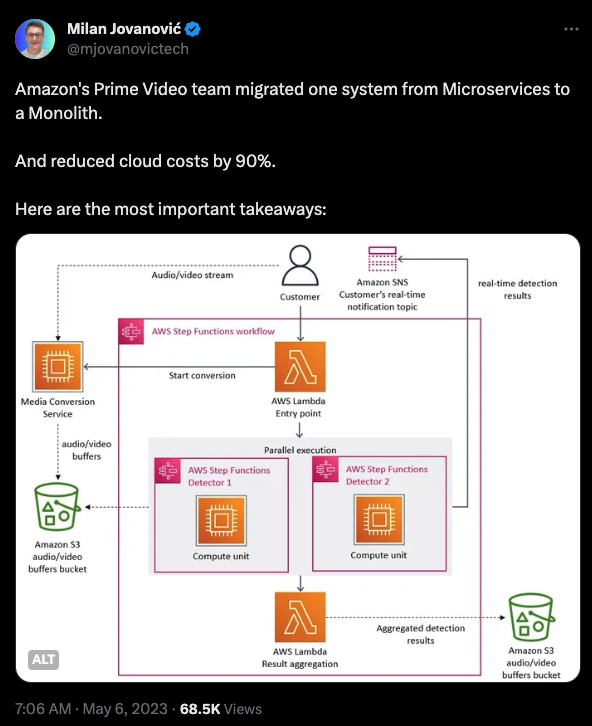
归根结底,当你需要从纽约前往费城时,你有两种选择。一种是尝试构建一个高度复杂的宇宙飞船,进行轨道飞行以抵达目的地;另一种则是简单地购买一张 Amtrak 火车票,享受 90 分钟的旅程。这正是我们面临的问题。