推动高级机器人技术的未来发展 [译]
The Google DeepMind Robotics Team
![推动高级机器人技术的未来发展 [译]](https://lh3.googleusercontent.com/qeWlfSbr0jW0OsZ0dvaQK2V7tYM0HtTtwivx-fUJzK4GivdM6kffvNXlSgqOJyjAQWXBCycqF77zT7XDGxIqGvPiCnTqLX_C3VRmXGJIGGW5GAv7YQ=w1072-h603-n-nu)
Google DeepMind 机器人团队推出 AutoRT、SARA-RT 和 RT-Trajectory,旨在提升机器人在真实世界环境中的数据采集效率、动作速度和应用泛化能力
设想一个未来,你只需向你的个人助理机器人发出一个简单的指令——比如“整理房间”或“为我们准备一顿美味健康的饭菜”——它就能轻松完成这些任务。对于人类而言易如反掌的这些活动,对机器人来说则需要深刻理解周围世界。
今天,我们公布了一系列重大的机器人研究进展,这些进展使我们距离这一美好未来更近一步。AutoRT、SARA-RT 和 RT-Trajectory 基于我们在 Robotics Transformers 领域的历史性成就,能够帮助机器人更迅速地做出决策,更准确地理解并导航其所处的环境。
AutoRT: 利用大型模型优化机器人训练
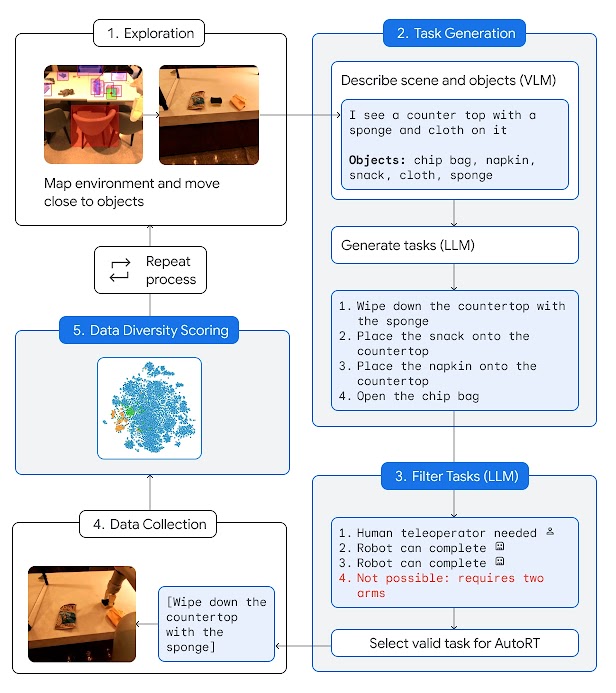
我们推出了 AutoRT,这是一个利用大型基础模型(如大语言模型 [LLM] 或视觉语言模型 [VLM])的潜力来培养能够理解实际人类目标的机器人的系统。AutoRT 通过收集更多、更多样的经验性训练数据,有助于扩展机器人的学习范围,使其更好地适应真实世界的需求。
AutoRT 结合了大型基础模型和机器人控制模型(如 RT-1 或 RT-2),打造了一个能够在新环境中部署机器人收集训练数据的系统。该系统能同时指挥多台配备视频摄像头和末端执行器的机器人,在各种环境中执行多样化任务。对于每台机器人,系统利用 VLM 理解其所处的环境和视野中的物体。然后,LLM 会提出一系列创意任务,比如“将零食放置在台面上”,并作为决策者为机器人选定合适的任务。
在长达七个月的广泛现实世界测试中,该系统能安全地同时指挥多达 20 台机器人,总共使用了多达 52 台不同的机器人,在多个办公楼中收集了包含 77,000 次机器人试验的多样化数据集,涉及 6,650 种独特任务。
机器人的多层安全防护至关重要
要将机器人融入我们的日常生活,必须负责任地开发它们,并通过严谨的研究证明它们在现实世界中的安全性。
AutoRT 虽然是个数据收集系统,但同时也展示了自主机器人在实际应用中的早期成果。它具备多项安全防护机制,其中包括为其基于大型语言模型(LLM)的决策系统设定一套以安全为核心的指导原则,即“机器人安全准则”。这些规则在挑选机器人任务时必须遵守,它们部分受到艾萨克·阿西莫夫提出的机器人三大定律的启发,首要原则是“机器人不得伤害人类”。其他的安全规则还包括禁止机器人执行涉及人类、动物、锋利物体或电器的任务。
然而,即使大型模型在指令上进行了精心设计,也不能单凭此保证安全。因此,AutoRT 系统还结合了来自传统机器人技术的多层实际安全措施。比如,协作机器人被设定了一项安全程序:一旦其关节所受力量超过特定阈值就会自动停止运作。此外,所有活动中的机器人都在人类监督员的视线内运作,且均配备有紧急停机开关。
SARA-RT: 让机器人的 Transformer 更加轻盈快捷
我们推出的新系统 自适应鲁棒注意力用于机器人 Transformer (SARA-RT),能将机器人 Transformer (RT) 模型转化为更高效的版本。
我们团队开发的 RT 神经网络架构被应用于最新的机器人控制系统,包括我们尖端技术的 RT-2 模型。在处理了一系列图像历史数据之后,SARA-RT-2 模型在准确率上比 RT-2 提高了 10.6%,在处理速度上快了 14%。我们相信,这是首个能在不牺牲质量的前提下提供计算效率改进的可扩展注意力机制。
尽管 Transformer 强大,但它们的决策速度常常受限于庞大的计算需求。Transformer 的核心是依赖于复杂度呈二次方的注意力模块。也就是说,如果 RT 模型的输入量加倍,比如给机器人增加更多或分辨率更高的传感器,那么处理这些输入所需的计算资源会增长四倍,这可能会拖慢决策过程。
SARA-RT 通过一种我们称为“上训练 (up-training)”的创新模型微调方法,提升了模型的效率。这种方法将复杂的二次方计算转换为简单的线性计算,极大地减少了计算需求。这种转换不仅提高了原始模型的速度,而且还保持了其优良的性能。
我们设计了这一系统,易于使用,希望众多研究者和实践者能在机器人领域及其他领域广泛应用。由于 SARA 提供了一种加快 Transformer 处理速度的通用方案,而且无需耗费巨大的预训练计算资源,这种方法有望大规模推广 Transformer 技术的应用。SARA-RT 不需要任何额外的编码,可以使用各种现成的开源线性变种。
当我们将 SARA-RT 应用于一个拥有数十亿参数的最新 RT-2 模型时,发现它在各种机器人任务上的决策速度更快,性能更佳。
SARA-RT-2 模型专为操控任务而设计。机器人的动作是根据图像和文本指令来决定的。
得益于其扎实的理论基础,SARA-RT 可以应用于各种类型的 Transformer 模型。例如,将 SARA-RT 应用于 点云 Transformer - 用于处理机器人深度摄像头的空间数据 - 可以使其处理速度提高一倍以上。
RT-Trajectory:助力机器人实现任务泛化
对人类而言,理解如何擦桌子似乎很简单,但对于机器人来说,将这一指令转化为实际的动作却有很多种可能性。
我们开发了一种叫做 RT-Trajectory 的模型,它能自动向训练视频中添加展示机器人动作轮廓的视觉线条。RT-Trajectory 对训练数据集中的每个视频进行处理,增加一个二维的轨迹草图,用以展示机器人手臂的抓取部分在完成任务时的移动轨迹。这些以 RGB 图像形式展示的轨迹,为模型提供了直观、实用的视觉线索,帮助它学习控制机器人的策略。
在对 41 个训练数据集中未出现过的任务进行测试时,由 RT-Trajectory 控制的机械臂的表现是现有最先进的 RT 模型的两倍多。与 RT-2 的 29% 成功率相比,RT-Trajectory 达到了 63% 的任务完成率。
传统上,训练机器人手臂主要是将抽象的自然语言指令(如“擦桌子”)转化为具体的动作(比如关闭夹持器,向左或向右移动)。这种方法使得模型难以适应新的任务。相比之下,RT-Trajectory 模型通过解析视频或草图中展示的具体机器人动作,使 RT 模型能够理解并学习“如何执行”这些任务。
这个系统非常灵活:RT-Trajectory 还可以通过观察人类展示的任务动作来创建轨迹,甚至可以接受手绘的草图。它还能轻松地适应不同类型的机器人平台。
例如,一个仅用自然语言数据集训练的 RT 模型在面对“清洁桌子”这样的新任务时可能会束手无策。而一个使用了同样数据集但增加了二维轨迹训练的 RT-Trajectory 控制的机器人,能成功规划并执行清洁动作。
另一方面,面对新任务如“清洁桌子”,一个经过训练的 RT-Trajectory 模型能够以多种方式创建二维轨迹,无论是由人类协助还是独立使用视觉与语言结合的模型。
RT-Trajectory 利用了所有机器人数据集中蕴含的丰富的运动信息,这些信息之前并未被充分利用。RT-Trajectory 不仅是构建能在新情景中精确高效运动的机器人道路上的又一重要步骤,也开启了从现有数据集中挖掘知识的新途径。
为下一代机器人奠定基石
在我们领先的 RT-1 (RT-1) 和 RT-2 (RT-2) 模型的基础上,我们正在构建越来越能干和实用的机器人。我们期待未来能够将这些模型和系统融合,打造出集 RT-Trajectory (RT-Trajectory) 的动作泛化、SARA-RT (SARA-RT) 的高效率以及像 AutoRT (AutoRT) 这样的模型所进行的大规模数据收集于一身的机器人。我们会持续面对机器人学领域的挑战,并迎接更先进的机器人技术和能力所带来的新机遇。
了解更多信息
附加说明
我们要感谢 Krzysztof Choromanski、Keerthana Gopalakrishnan、Alex Irpan 和 Ted Xiao 对本博客的重要贡献。
同时,也对参与这三篇论文的所有作者表示感谢。
AutoRT: Michael Ahn, Debidatta Dwibedi, Chelsea Finn, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Karol Hausman, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Sean Kirmani, Isabel Leal, Edward Lee, Sergey Levine, Yao Lu, Sharath Maddineni, Kanishka Rao, Dorsa Sadigh, Pannag Sanketi, Pierre Sermanet, Quan Vuong, Stefan Welker, Fei Xia, Ted Xiao, Peng Xu, Steve Xu, Zhuo Xu
SARA-RT: Isabel Leal, Krzysztof Choromanski, Deepali Jain, Avinava Dubey, Jake Varley, Michael Ryoo, Yao Lu, Frederick Liu, Vikas Sindhwani, Quan Vuong, Tamas Sarlos, Ken Oslund, Karol Hausman, Kanishka Rao
RT-Trajectory: Jiayuan Gu, Sean Kirmani, Paul Wohlhart, Yao Lu, Montserrat Gonzalez Arenas, Kanishka Rao, Wenhao Yu, Chuyuan Fu, Keerthana Gopalakrishnan, Zhuo Xu, Priya Sundaresan, Peng Xu, Hao Su, Karol Hausman, Chelsea Finn, Quan Vuong, Ted Xiao
最后,我们要对 Vincent Vanhoucke 在这些论文研究中所提供的支持表示感谢。