Mixtral 8x7B -- 混合专家模型(Mixtral of Experts) [译]
一款高品质的稀疏专家混合模型
Mistral AI 团队,2023 年 12 月 11 日
Mistral AI 团队致力于为开发者社区提供顶尖的开源模型。在 AI 领域,要实现突破,不仅要超越现有的架构和训练方法,更重要的是让社区能够利用创新模型,激发新的发明和应用。
今日,团队隆重推出 Mixtral 8x7B——一款高品质的稀疏专家混合模型(SMoE),这款模型拥有开放的权重,且在 Apache 2.0 协议下授权。在众多基准测试中,Mixtral 的表现超越了 Llama 2 70B,推理速度快 6 倍。它是目前最强大的具有宽松许可证的开放权重模型,在成本与性能的平衡上表现最佳,尤其在大多数标准基准测试中,其表现可与 GPT3.5 相媲美。
Mixtral 的主要能力包括:
- 能够流畅处理 32k 个 Token 的上下文。
- 支持多种语言,包括英语、法语、意大利语、德语和西班牙语。
- 在代码生成领域表现出色。
- 可以调整为遵循指令的模型,在 MT-Bench 上获得了 8.3 分的高分。
开源模型的新篇章:采用稀疏架构
Mixtral 是一个采用稀疏专家混合网络的模型,它是一个仅包含解码器的模型。在这个模型中,前馈块从 8 组不同的参数组中进行选择。对于每一层的每个 Token,一个路由网络会挑选两组“专家”处理 Token,并将它们的输出结果进行加法组合。
这种技术让模型在增加参数数量的同时,有效控制了成本和延迟,因为模型每处理一个 Token 只会使用部分参数。具体来说,Mixtral 总共有 467 亿参数,但每个 Token 只用到了其中的 129 亿。因此,它在处理输入和生成输出时,无论是速度还是成本,都相当于一个 129 亿参数的模型。
Mixtral 的预训练是在开放网络提取的数据基础上完成的,其中专家和路由器的训练是同时进行的。
性能对比
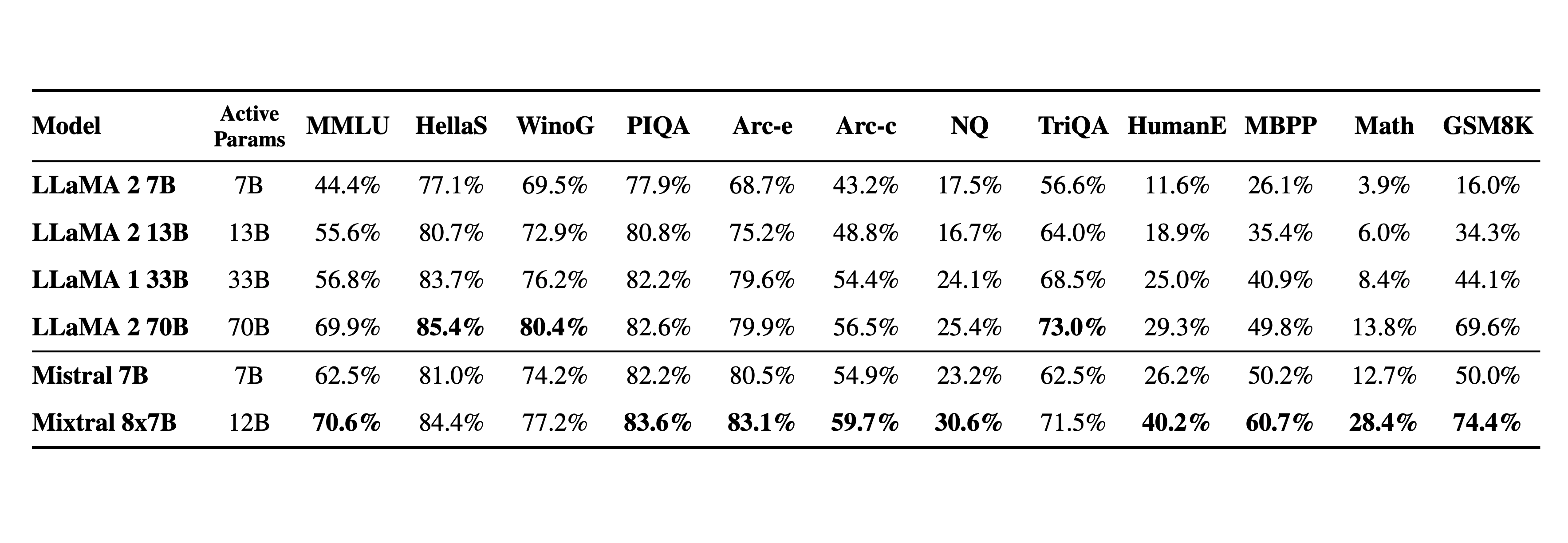
我们把 Mixtral 与 Llama 2 系列和 GPT3.5 的基础模型进行了比较。在大部分的性能测试中,Mixtral 不仅达到了 Llama 2 70B 的水平,甚至在很多方面超越了它和 GPT3.5。
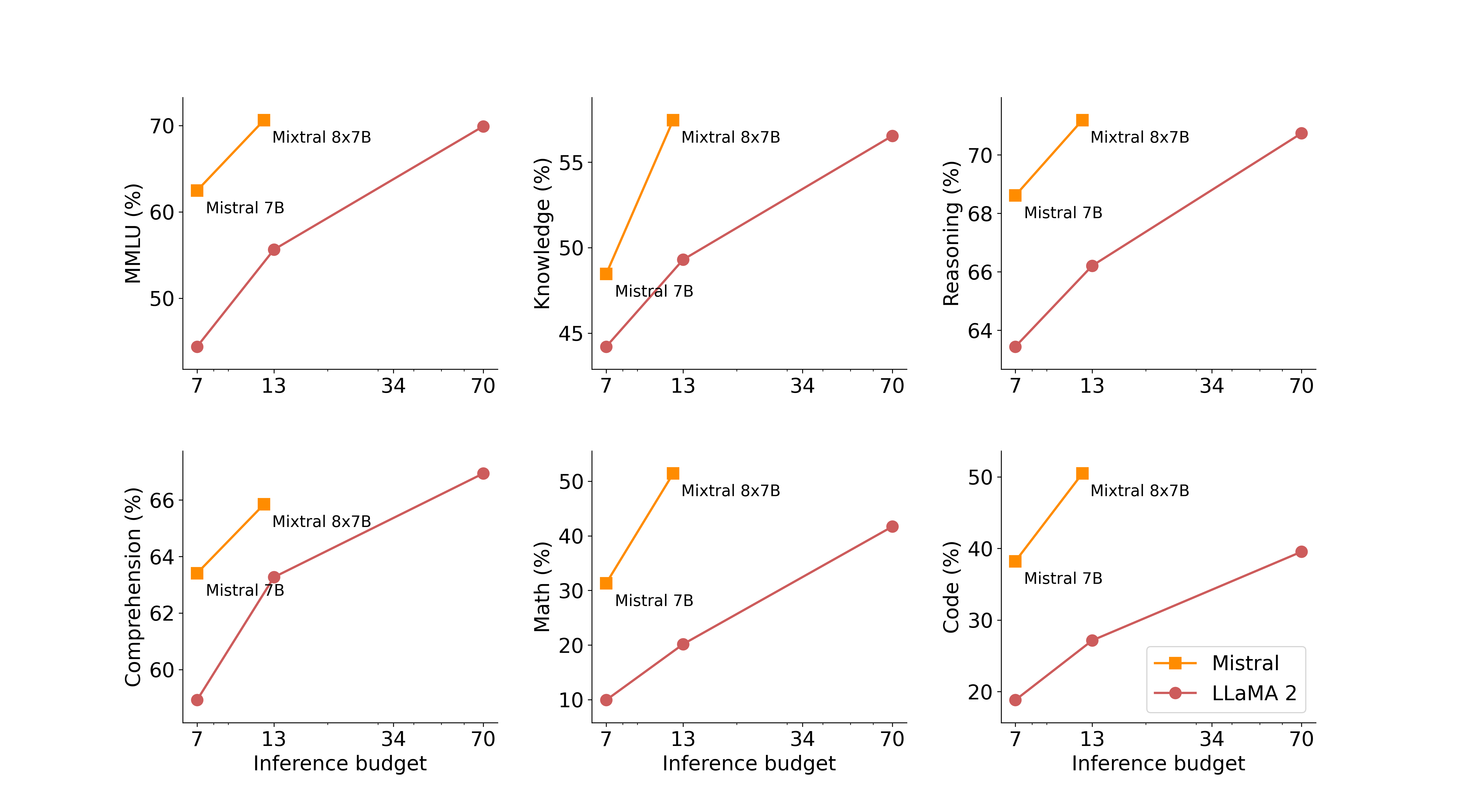
接下来的图表展示了模型在质量和计算成本之间的平衡。不论是 Mistral 7B 还是 Mixtral 8x7B,都是相比 Llama 2 系列更加高效的模型家族成员。
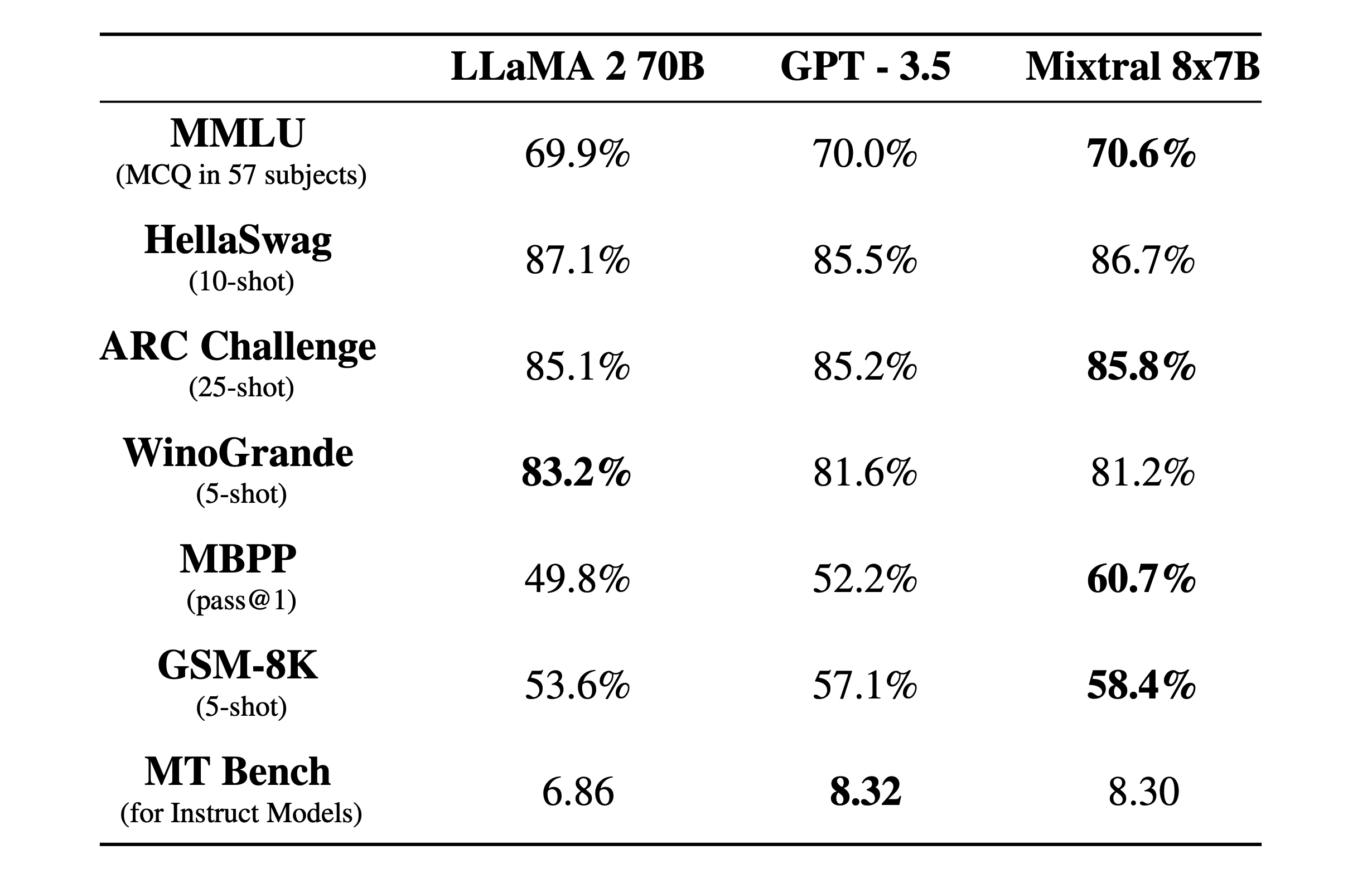
下面这个表格详细列出了上图的测试结果。
关于幻觉和偏见。 为了发现并通过微调或偏好建模修正潜在问题,我们对基础模型在 TruthfulQA、BBQ 和 BOLD 上的表现进行了评估。
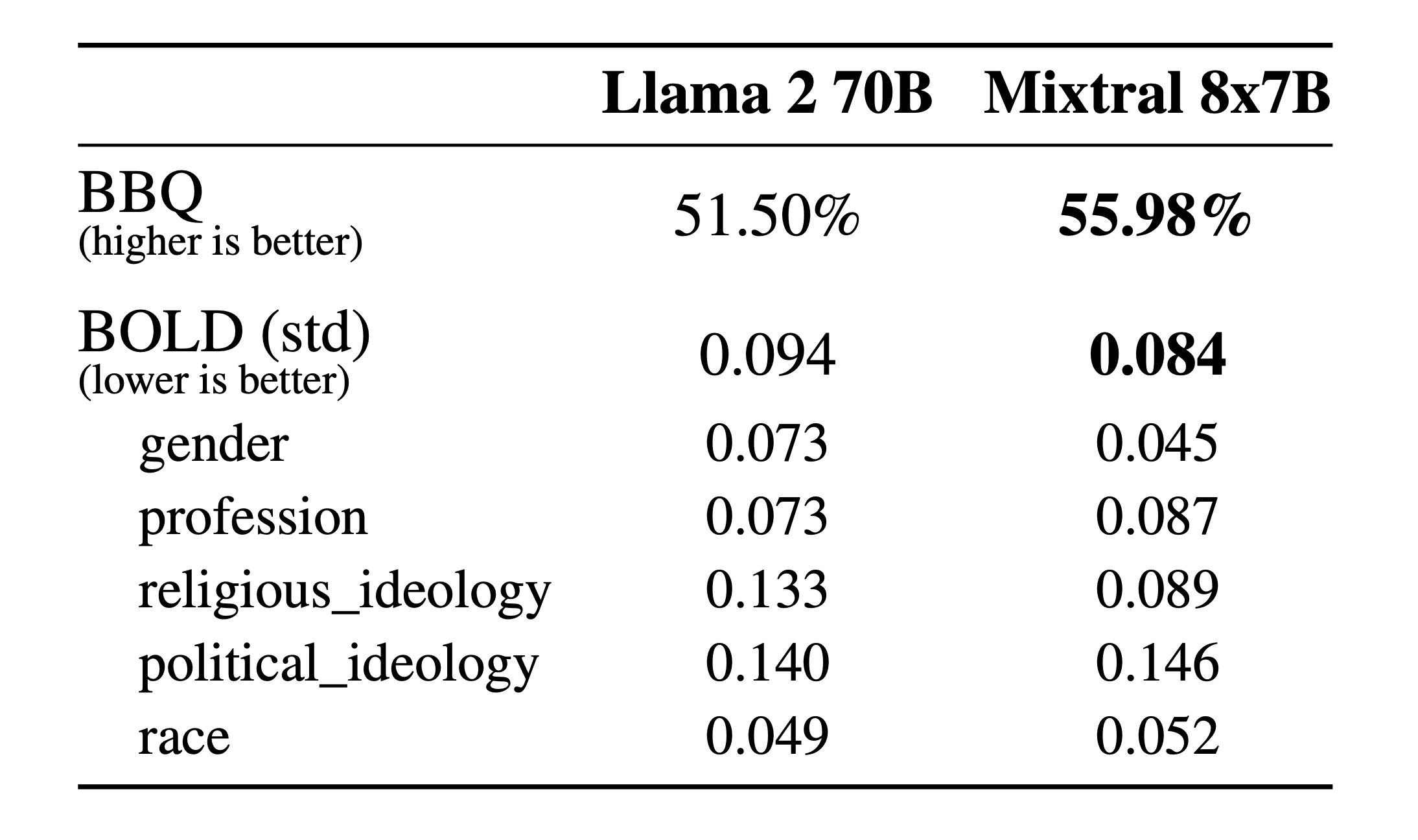
相较于 Llama 2,Mixtral 在 TruthfulQA 测试中更加真实(73.9% 对比 50.2%),并且在 BBQ 测试中显示出更少的偏见。总的来说,与 Llama 2 相比,Mixtral 在 BOLD 测试中展现了更多的正面情绪,且各方面的波动程度相似。
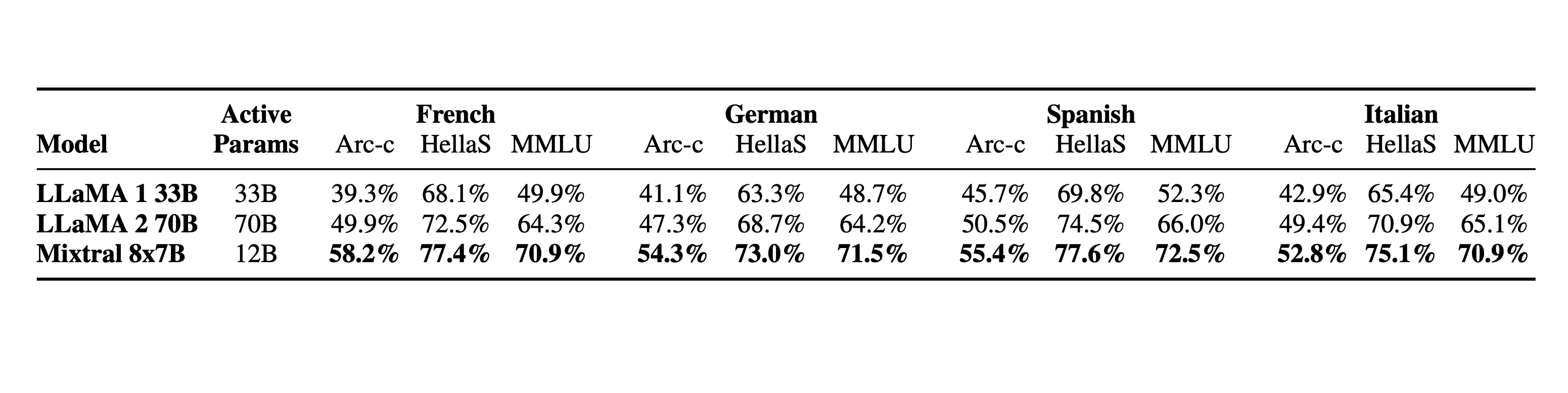
语言能力。 Mixtral 8x7B 精通包括法语、德语、西班牙语、意大利语和英语在内的多种语言。
指导模型
我们推出了专门优化的 Mixtral 8x7B Instruct 模型,它通过监督式微调和直接偏好优化(DPO)被训练以更准确地遵循指令。在 MT-Bench 测试中,该模型得分高达 8.30,成为目前最优秀的开源模型之一,其性能可与 GPT3.5 媲美。
需要注意的是,Mixtral 可以通过特定提示来排除一些输出,这在需要严格内容控制的应用构建中非常有用,具体示例可见这里。恰当的偏好调整同样可以达到这一目的。但请记住,如果没有这样的提示,模型将按照给定的指令行事。
利用开源部署栈推广 Mixtral
为了使社区能够通过全开源的技术栈运行 Mixtral,我们向 vLLM 项目提交了改进,该项目融合了 Megablocks CUDA 核心技术,以便高效进行推理计算。
通过 Skypilot,用户可以在云端的任何实例上部署 vLLM API 端点。
在我们平台上体验 Mixtral
目前,我们的 mistral-small API 端点正在使用 Mixtral 8x7B 版本,现已在 beta 测试版中提供。您可以注册以抢先体验所有的生成式 AI 和 Embedding 功能。
-
下载 Mixtral-8x7B-v0.1 Base model: https://huggingface.co/mistralai/Mixtral-8x7B-v0.1
-
下载 Mixtral-8x7B-v0.1 Instruct model: https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1
致谢
我们要感谢 CoreWeave 和 Scaleway 团队在我们模型训练过程中给予的技术支持。