多面性:大语言模型的语言回音室 [译]
这个话题非常有趣。
我花了很多时间仔细观察大语言模型(LLM)的输出。有一个现象引起了我的注意:LLM 生成的文本似乎带有一种特殊的…气息。这种气息很难具体描述,但在大语言模型的早期,当你阅读 AI 生成的文章时,通常可以明显地感受到。
一个我注意到的明显特征是这样一种表达方式:
“文化是一个复杂而多面的……”
“智力是复杂而多面的……”
“技术是一个复杂而多面的……”
从达尔文主义的真实含义来看,'复杂而多面' 这个短语已经变成了一个流行语。我在 GPT 的输出中反复看到了这个短语,为了进一步确认,我进行了一些 GPT-3.5 的生成实验(代码在此)。在生成“'复杂且……'”的提示时,我发现了以下结果:
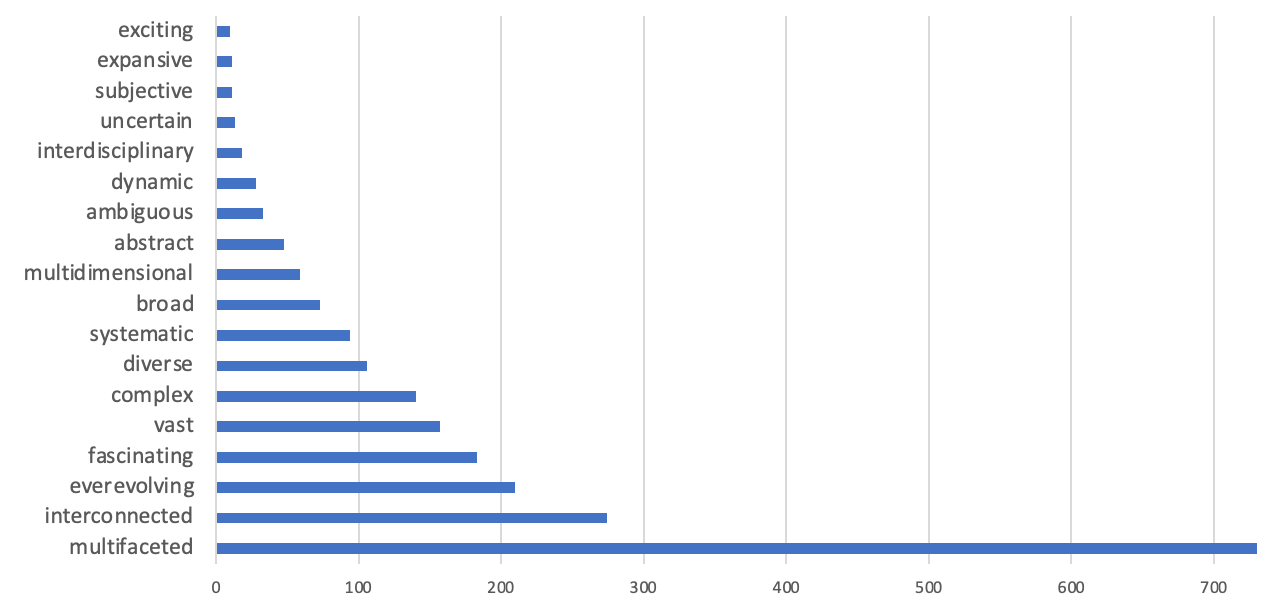
'多面性' (Multifaceted) 这个词语的频繁出现非常奇怪。这是为什么呢?
为了探究这个短语及其特定词语*'多面性'* 是否是近期变得流行,或者已有一段历史,我首先查看了 Google 趋势。我发现,在过去的一年中,这个词的搜索量出现了惊人的上升:
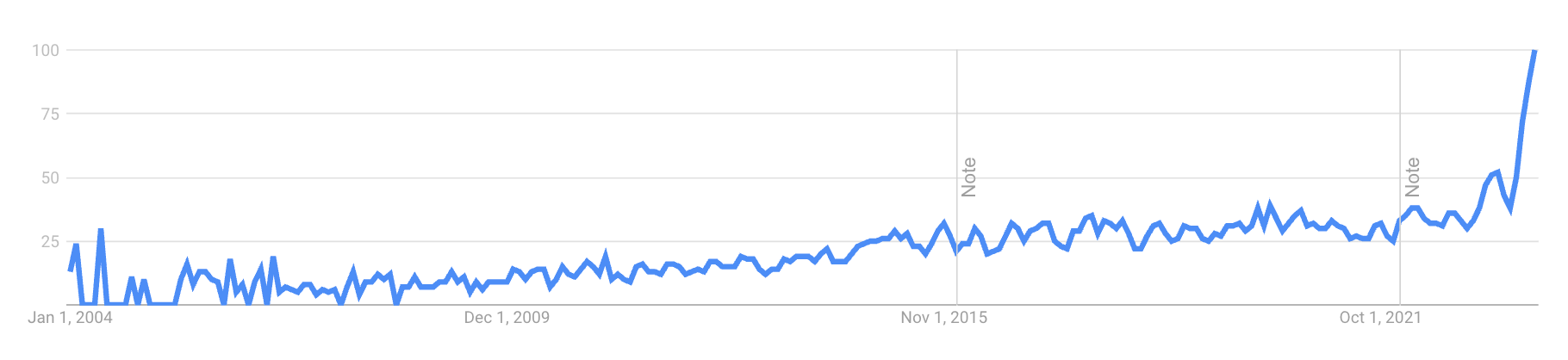
为了探究这个短语及其特定词语*'多面性'* 是否是近期变得流行,或者已有一段历史,我首先查阅了 Google 趋势。结果我发现,在过去的一年中,这个词的搜索量急剧上升:
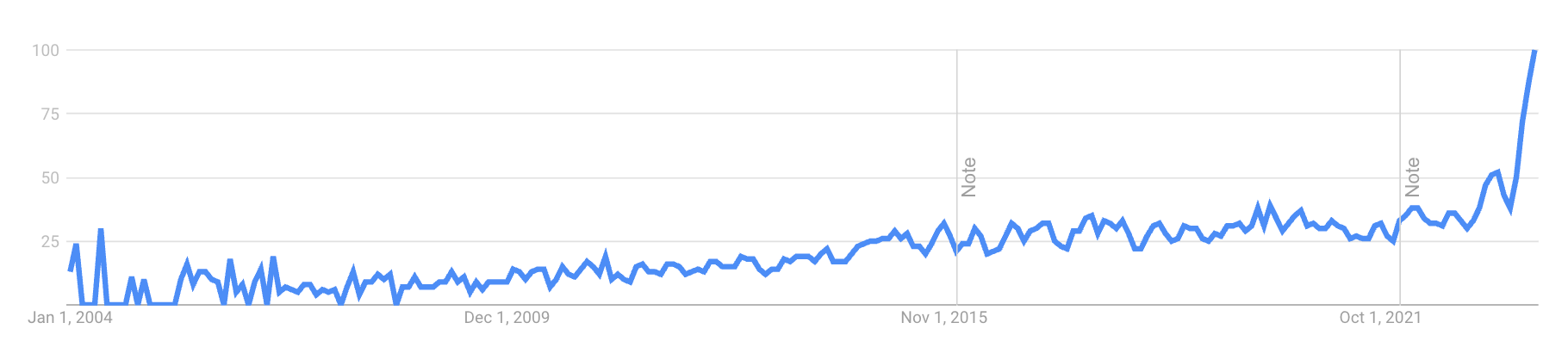
我此时想探究的是,这个趋势是否仅限于网络。虽然这很难确定,但我尝试了 Google Books 的 N-gram 查看器,希望能找到答案。果然如我所料,我们并没有看到明显的变化点,尽管随时间有轻微上升。
稍微岔开一下话题:我认为这是一个有点奇怪的说法。它其实是种重复,因为“复杂”和“多面性”几乎是同义的。这让我想到了法律中的双重表达,比如“无效与作废”和“停止与禁止”。不过,这种表达方式确实很好,给人一种肯定和智慧的感觉,这正是大语言模型(LLM)想要传达的氛围。
总之,我想进一步确认这确实是一种网络上新兴的流行表达。单凭 Google 趋势还不够说服人。因此,我寻找了其他可以查询长期语言趋势的地方。我发现网络档案馆保存了多年来的各种 PDF,从白皮书到网络上的参考资料,还可以搜索特定关键词。
我从 2006 年到 2022 年进行了一系列关键词搜索,包括“多面性”。同时,我也关注了另一个流行词汇“复杂”。为了保持科学的严谨性,我还将这些词与其他术语作为对照进行了比较。
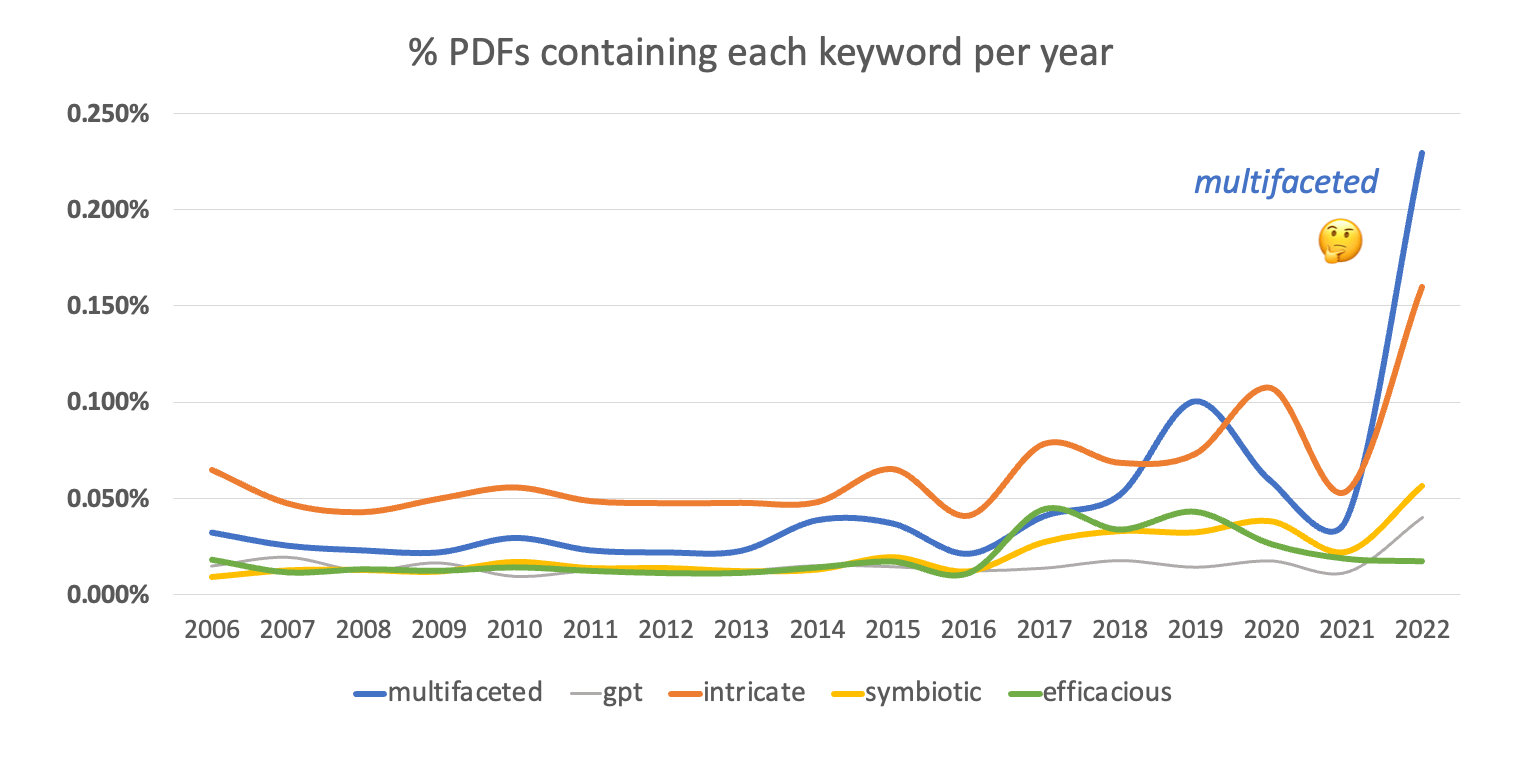
正如我们所见,从 2021 年开始,即大约在 GPT 和其他大语言模型 (LLM) 开始引起全球关注的时候,我们的关键词“多面性”的普及程度显著提高,从只在 0.05% 的 PDF 中出现增加到了 0.23%。
现在,让我们稍微放宽视角来看这个问题。我发现,“复杂而多面”(a complex and multifaceted)这个短语在网上大约有 800,000 个使用实例。
进一步细分,我们发现这个短语在以下一些特定网站上的使用频率高于其他地方:
Quora.com: 48,000LinkedIn.com: 30,700Facebook.com: 9,500Instagram.com: 7,330Medium.com: 6,250Reddit.com: 1,370CourseHero.com: 7,340jstor.org: 1,320wikipedia.org: 400twitter.com: 798classace.io: 842 (*特别是作为论文库的网站*)chegg.com: 930 (*特别是作为论文库的网站*)
令人惊讶的是,Quora 网站占据了这个短语在线出现次数的 5.7%!如果说它不是这个流行语的起源地,那至少也是它的繁殖地。
值得注意的是,我们还可以看到 Quora 在理论上 应该 占据的比例。例如,“系统性”(systemic)这个词在网上出现了 445 million 次,但在 Quora 上只出现了 272,000 次,占比仅为 0.06%。因此,Quora 对我们这个流行短语的 5.7% 占比完全是不成比例的。这一点并不令人意外,因为 Quora 因其垃圾信息机器人而闻名。它们现在就像是机械地重复着同样的句式:

另一个不容忽视的事实是,Quora 最近在几乎每个页面上都嵌入了一个 ChatGPT 小组件,这些小组件的内容是预先生成的、静态的,容易被搜索引擎抓取。因此,它们很可能被用作这种大语言模型和其他模型的额外训练材料。
ChatGPT 显然对“一个复杂而多面的[概念 | 理论 | 过程]”这个表达格外偏爱,频繁地用它来阐释复杂的高层次概念。最典型的用法是把某个[名词]描述为“一个复杂而多面的[概念 | 理论 | 过程]”。在 Quora 上,这样的用法及其数量如下:
- “一个复杂而多面的概念” -
4590 - “一个复杂而多面的问题” -
4420 - “一个复杂而多面的过程” -
3550 - “一个复杂而多面的现象” -
2230 - “一个复杂而多面的情感” -
1650 - “一个复杂而多面的特征” -
1560
(这些数字在不同地区有所不同)
如果我们选择其中一个短语,在网络上进行普遍搜索,我们会发现它们随着时间显著增长。例如,“一个复杂而多面的现象”在网上的出现次数达到 74,900,但在 2010 年前仅有 73 次。仅仅 13 年,增长了约 1000 倍。
可以看出,ChatGPT 把这个梗玩得不亦乐乎。这个有趣的大语言模型(LLM)把这个表达当成了我们语言的核心成分,尽管它原本只是个使用范围狭窄、有些生硬的短语。
那么,这个荒诞的探索究竟告诉我们了什么?
我们了解到,GPT 最初版本的训练资料大量来自于 Reddit,很可能还有其他少数网站被用来加强后续模型。
过分专注于特定网站的训练会导致明显的偏见。比如,过多关注学术内容或像 Quora 这样的网站,这些网站上的机器人会机械性地重复使用某些短语(这种情况甚至出现在大语言模型时代之前)。
此外,随着这些模型变得流行,人们开始将其输出内容重新发布到互联网上。这可能导致了一种反馈循环:大语言模型无意中在训练自己之前的输出内容。这种情况不可避免。
因此,最初的一些细微的训练决策,可能就由少数工程师启动了一连串不可逆转的语言进化链条。了解这些模型在改变语言本质方面的强大影响力,真是让人叹为观止。