再现亚马逊新的人工智能生成功能:产品评论摘要 [译]
如何使用 OpenAI 大语言模型 (LLM) 在 Weaviate 向量数据库中用 Python 生成摘要,运用所谓的“生成式反馈循环”概念
Leonie Monigatti 2023 年 11 月 21 日
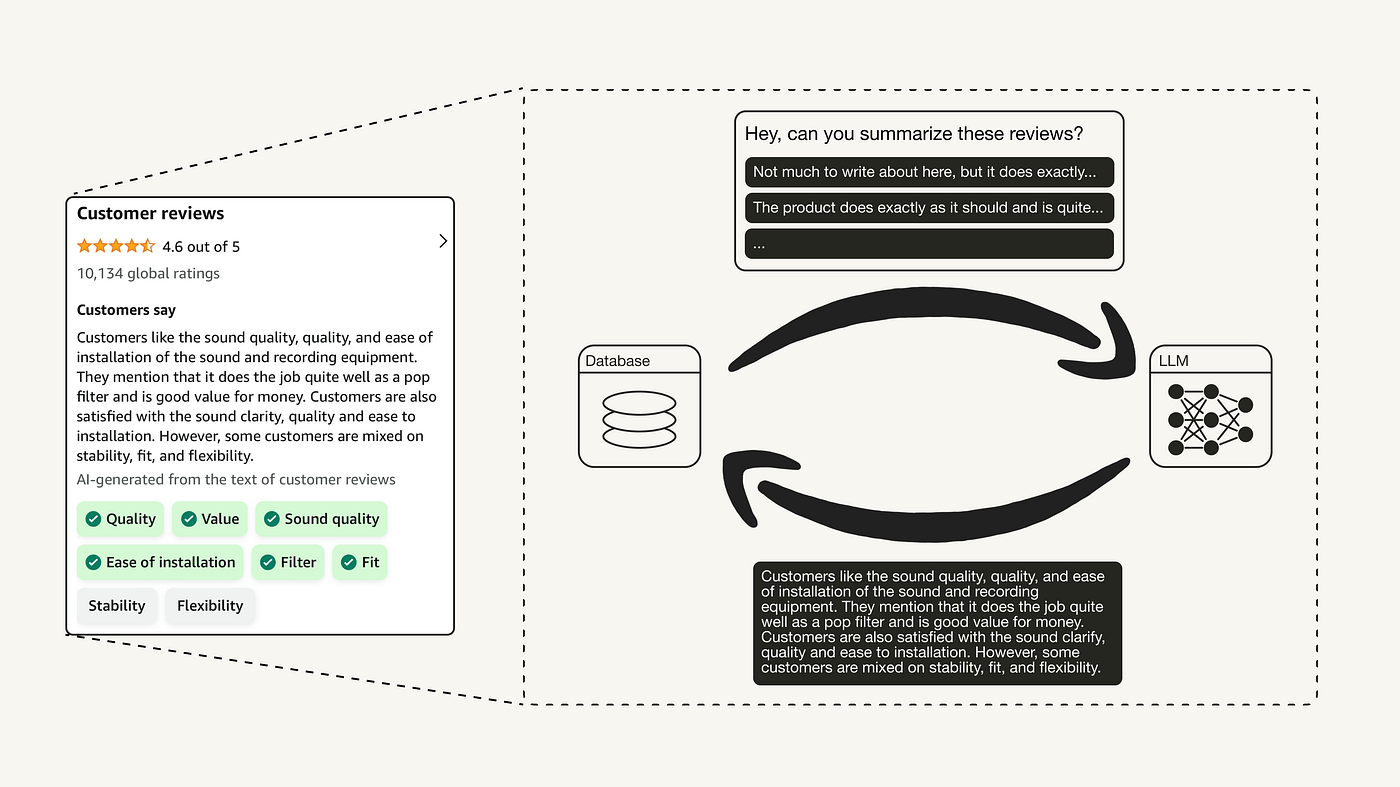
亚马逊新功能揭秘:智能摘要化商品评价
对于全球最大在线零售平台亚马逊来说,顾客评论一直是其重要的一环。人们总是乐于参考他人的购买体验,来决定自己是否购买。自 1995 年引入顾客评论机制以来 [1],亚马逊不断优化这一特色。
2023 年 8 月 14 日,亚马逊推出了一项采用生成式 AI 的重大创新:顾客评论智能摘要。亚马逊的数百万商品中,有的积累了成千上万的评论。2022 年,有约 1.25 亿顾客贡献了近 150 亿条评论和评分 [1]。这项新功能能够将成千上万条经过验证的用户评论,智能总结成一小段描述顾客感受的文字。
这项新功能位于商品评论区的顶部,标注为“顾客说”,并明确声明该段落是“根据顾客评论的文本由 AI 生成”。此外,功能中还包含了跨评论提及的 AI 生成产品特性,便于顾客筛选提及这些特性的特定评论。
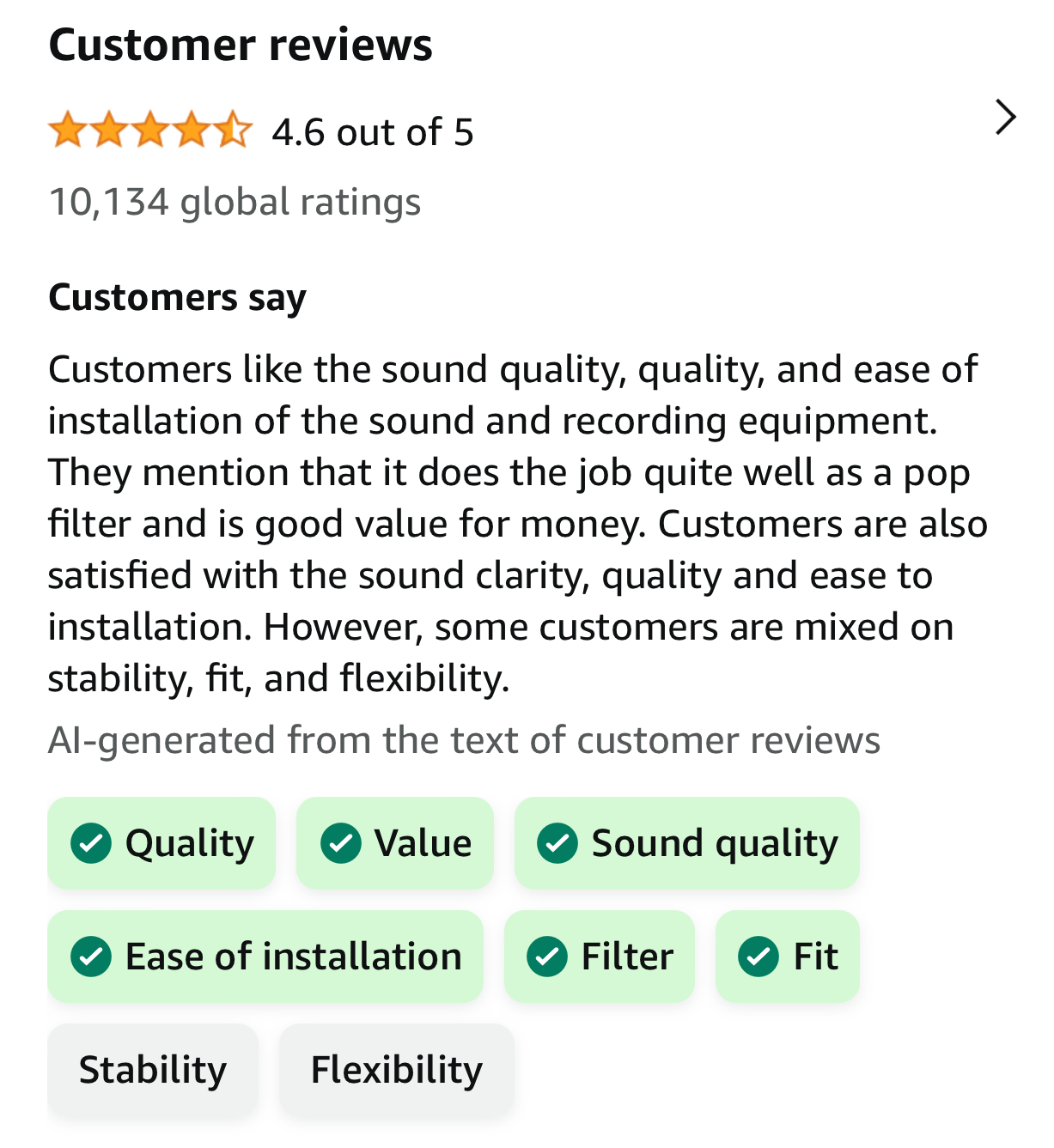
亚马逊对“Aokeo Professional Microphone Pop Filter Mask Shield” 的评论摘要(同事 Jonathan 授权使用的截图)
目前,这个革新性功能还在试验阶段,仅向美国部分移动端用户和选定商品提供。这一新功能的推出已经引发了关于 AI 生成信息的可靠性、准确性及可能的偏见问题的讨论。
在总结客户评论方面,生成式 AI 技术已成为一种明显的应用场景。像 Newegg 和 Microsoft 这样的公司已经推出了类似功能。虽然亚马逊尚未透露这一新功能的技术实现细节,但本文将探讨如何在你的项目中复现这一功能,并给出一个简单示例。
实现步骤
要复制评论摘要功能,你可以遵循一个称为 生成式反馈循环 的概念。这个概念是从数据库中提取信息,用以触发生成模型创造新数据,然后将这些数据存回数据库。
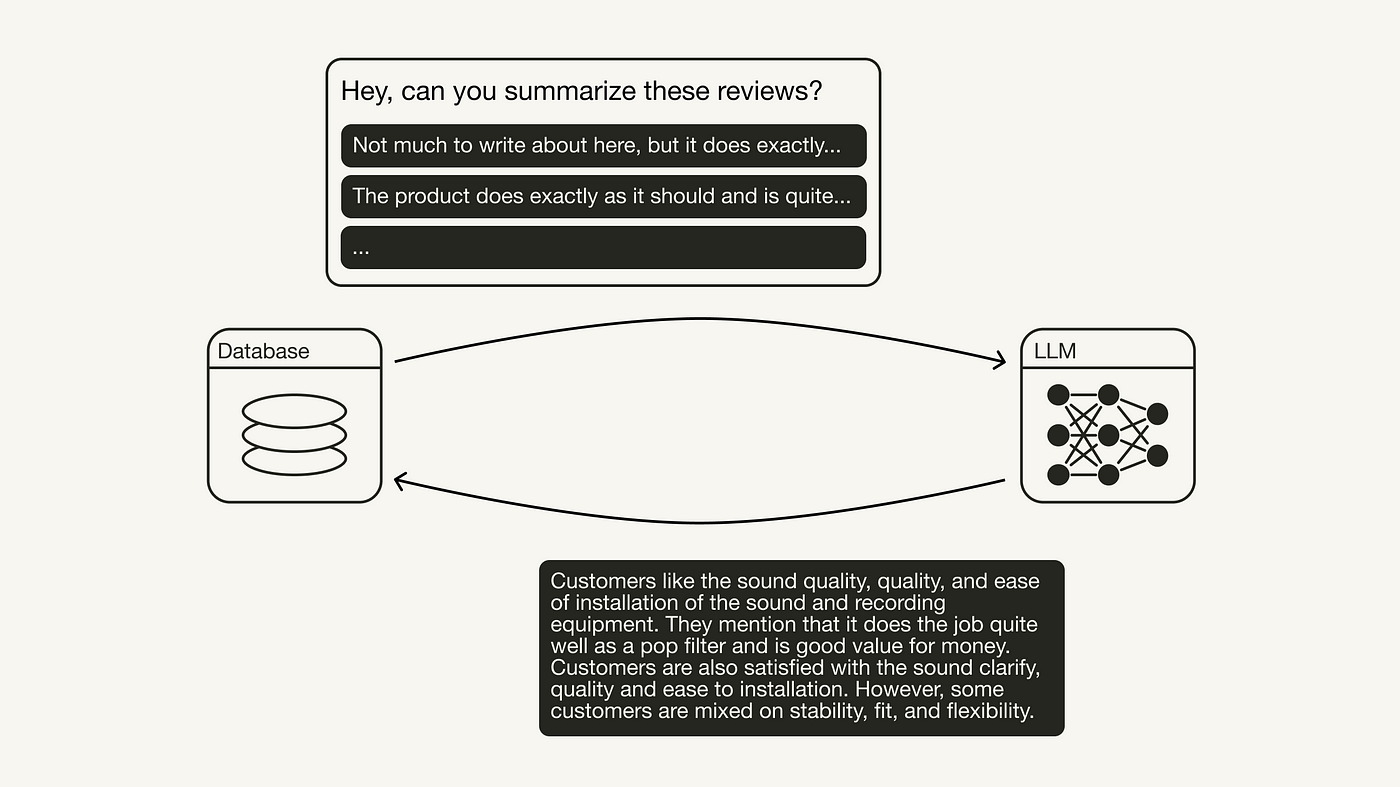
一个示例:生成式反馈循环
准备工作
如图所示,你需要一个用于存储数据的数据库和一个生成模型。对于数据库,我们将使用 Weaviate 的 向量数据库,它可以与多个不同的生成模块(如 OpenAI、Cohere、Hugging Face 等)集成。
!pip install weaviate-client - upgrade
对于生成模型,我们选择使用 OpenAI 的 gpt-3.5-turbo。使用此模型前,你需要设置你的 OPENAI_API_KEY 环境变量。要获取 API 密钥,首先需要注册 OpenAI 账户,然后在 API keys 页面上“创建新密钥”。由于 OpenAI 的生成模型已与 Weaviate 直接集成,无需安装额外软件包。
数据集简介
本示例中,我们选用了 Amazon Musical Instruments Reviews 数据集(授权许可:CC0: 公共领域),涵盖了 Amazon 上音乐器材类别的 10,254 条用户评论,覆盖 900 种产品。
import pandas as pddf = pd.read_csv("/kaggle/input/amazon-music-reviews/Musical_instruments_reviews.csv",usecols = ['reviewerID', 'asin', 'reviewText', 'overall', 'summary', 'reviewTime'])df = df[df.reviewText.notna()]

Amazon Musical Instruments Reviews 数据集展示
初始设置
首先,您需要搭建一个数据库。可以采用 Weaviate’s Embedded option 来进行实验,这个选项无需注册或配置 API 密钥。
import weaviatefrom weaviate import EmbeddedOptionsimport osclient = weaviate.Client(embedded_options=EmbeddedOptions(),additional_headers={"X-OpenAI-Api-Key": os.environ["OPENAI_API_KEY"])
然后,我们需要定义一个模式,用来将数据(包括 review_text、product_id 和 reviewer_id)导入数据库。这里我们选择跳过向量化处理,设置为 `"skip" : True",目的是为了尽量减少推理成本。如果您想进一步发展这一功能,比如实现评论内容的语义搜索,可以考虑开启向量化功能。
if client.schema.exists("Reviews"):client.schema.delete_class("Reviews")class_obj = {"class": "Reviews", # Class definition"properties": [ # Property definitions{"name": "review_text","dataType": ["text"],},{"name": "product_id","dataType": ["text"],"moduleConfig": {"text2vec-openai": {"skip": True, # skip vectorization for this property"vectorizePropertyName": False}}},{"name": "reviewer_id","dataType": ["text"],"moduleConfig": {"text2vec-openai": {"skip": True, # skip vectorization for this property"vectorizePropertyName": False}}},],"vectorizer": "text2vec-openai", # Specify a vectorizer"moduleConfig": { # Module settings"text2vec-openai": {"vectorizeClassName": False,"model": "ada","modelVersion": "002","type": "text"},"generative-openai": {"model": "gpt-3.5-turbo"}},}client.schema.create_class(class_obj)
接下来,您可以开始分批次地向数据库中添加数据。
from weaviate.util import generate_uuid5# Configure batchclient.batch.configure(batch_size=100)# Initialize batch processwith client.batch as batch:for _, row in df.iterrows():review_item = {"review_text": row.reviewText,"product_id": row.asin,"reviewer_id": row.reviewerID,}batch.add_data_object(class_name="Reviews",data_object=review_item,uuid=generate_uuid5(review_item))
生成新的数据对象(摘要)
现在,您可以开始为每个产品撰写总结性的评价摘要了。在这一过程中,您将使用到检索增强型生成这一技术:
首先,准备一个能够整合评价文本的提示模板,如下所示:
generate_prompt = """Summarize these customer reviews into a one-paragraph long overall review:{review_text}"""
接着,创建一个包含以下步骤的生成式搜索查询:
- 检索特定产品的所有评价(使用
client.query.get('Reviews')),并应用.with_where()进行过滤。 - 将收集到的评价文本嵌入到提示模板中,并输入到生成模型中进行处理(通过
.with_generate(grouped_task=generate_prompt)操作)。
summary = client.query\.get('Reviews',['review_text', "product_id"])\.with_where({"path": ["product_id"],"operator": "Equal","valueText": product_id})\.with_generate(grouped_task=generate_prompt)\.do()["data"]["Get"]["Reviews"]
生成摘要后,将其连同产品 ID 一起存入名为Products的新数据集中。
new_review_summary = {"product_id" : product_id,"summary": summary[0]["_additional"]["generate"]["groupedResult"]}# Create new objectclient.data_object.create(data_object = new_review_summary,class_name = "Products",uuid = generate_uuid5(new_review_summary))
如果您希望进一步扩展这一功能,您还可以在摘要类别和评价类别之间建立相互引用关系,详情可参考生成式反馈循环。
现在,重复上述步骤,为所有可用的产品生成摘要:
generate_prompt = """Summarize these customer reviews into a one-paragraph long overall review:{review_text}"""for product_id in list(df.asin.unique()):# Generate summarysummary = client.query\.get('Reviews',['review_text', "product_id"])\.with_where({"path": ["product_id"],"operator": "Equal","valueText": product_id})\.with_generate(grouped_task=generate_prompt)\.do()["data"]["Get"]["Reviews"]new_review_summary = {"product_id" : product_id,"summary": summary[0]["_additional"]["generate"]["groupedResult"]}# Create new objectclient.data_object.create(data_object = new_review_summary,class_name = "Products",uuid = generate_uuid5(new_review_summary))
以asin = 1384719342这一产品为例,您可以查看其五条评价:
reviews = client.query\.get('Reviews', ['review_text', "product_id"])\.with_where({"path": ["product_id"],"operator": "Equal","valueText": "1384719342"})\.do()
{"product_id": "1384719342","review_text": "Not much to write about here, but it does exactly what it's supposed to.filters out the pop sounds. now my recordings are much more crisp.it is one of the lowest prices pop filters on amazon so might as well buy it, they honestly work the same despite their pricing,"},{"product_id": "1384719342","review_text": "The product does exactly as it should and is quite affordable.I did not realized it was double screened until it arrived, so it was even better than I had expected.As an added bonus, one of the screens carries a small hint of the smell of an old grape candy I used to buy, so for reminiscent's sake, I cannot stop putting the pop filter next to my nose and smelling it after recording. :DIf you needed a pop filter, this will work just as well as the expensive ones, and it may even come with a pleasing aroma like mine did!Buy this product! :]"},{"product_id": "1384719342","review_text": "The primary job of this device is to block the breath that would otherwise produce a popping sound, while allowing your voice to pass through with no noticeable reduction of volume or high frequencies.The double cloth filter blocks the pops and lets the voice through with no coloration.The metal clamp mount attaches to the mike stand secure enough to keep it attached.The goose neck needs a little coaxing to stay where you put it."},{"product_id": "1384719342","review_text": "Nice windscreen protects my MXL mic and prevents pops.Only thing is that the gooseneck is only marginally able to hold the screen in position and requires careful positioning of the clamp to avoid sagging."},{"product_id": "1384719342","review_text": "This pop filter is great.It looks and performs like a studio filter.If you're recording vocals this will eliminate the pops that gets recorded when you sing."}
针对该产品的评价摘要如下所示:
res = client.query\.get('Products', ['product_id', 'summary'])\.with_where({"path": ["product_id"],"operator": "Equal","valueText": "1384719342"})\.do()
{"product_id": "1384719342","summary": "Overall, customers are highly satisfied with this pop filter.They praise its ability to effectively filter out pop sounds, resulting in crisp recordings.Despite its low price, it performs just as well as more expensive options.Additionally, customers appreciate the double screening and the added bonus of a pleasant aroma.The device successfully blocks breath pops without reducing volume or high frequencies, and the metal clamp mount securely attaches to the microphone stand.The only minor issue mentioned is that the gooseneck requires careful positioning to avoid sagging.Overall, this pop filter is highly recommended for vocal recordings as it effectively eliminates pops and performs like a studio filter."}
如您所见,这个生成的摘要很好地概述了原评价中的主要观点,包括成本效益比等因素。
摘要
将海量文本数据简化成摘要是生成式 AI 的一项相对简单的应用,Amazon、Microsoft 和 Newegg 等公司已经在这方面取得了进展。例如,你可以访问 Healthsearch demo,在这个网站上,你可以通过语义搜索找到各种补充品,并快速了解它们的用户评价摘要。
本教程主要介绍了如何基于生成式反馈循环构建自动生成摘要的功能及其基本概念。要让这个功能投入实际应用,你还需要做一些工作,比如改进提示的方式(提示工程),考虑当评论数量超出模型处理能力时的解决方案,以及如何挑选出可靠的评论等。
本文的重点在于说明如何生成评论的摘要,但并未介绍如何利用 AI 来突出评论的重点。如果你对这方面的后续内容感兴趣,请在评论区留言。