如何使用 ChatGPT Api 和 Node.js 对 Youtube 视频内容进行摘要 [译]
Marco Moauro
使用 ChatGPT Api 和 Node.js 如何简化 Youtube 视频内容
大家好,我是 Marco,欢迎阅读我的专栏!
作为一名软件工程师,我开设了这个专栏,旨在分享我个人对编程世界的深入见解。每篇文章都会探讨一些能够提供实用知识的话题,希望能够激发并帮助大家在技术旅程中不断前进。
本期,我将介绍一个教程,告诉你如何利用 Node.js 构建一个系统,该系统能够通过 Youtube 视频链接,利用 OpenAI 提供的 completions api(也就是 ChatGPT 所基于的 API)来生成视频内容的摘要。
您可以从我的 Github 仓库直接下载本教程中提到的所有代码:https://github.com/marcomoauro/youtube-summarizer
1)🏰 系统架构
本系统的架构主要包括两个部分:
-
从 YouTube 视频中提取文本
-
生成文本摘要
1) 📝 提取 YouTube 视频文本
该过程包括从视频中提取文本,并将其用于生成摘要。我们考虑了多种方案,包括:
-
采用付费的第三方 API,例如 Deepgram,来从视频中提取文本。
-
使用 Microsoft Azure 的 Speech-to-Text API,该方法需要音频文件。
-
利用 OpenAI 的 Speech-to-Text API,同样需要音频文件。
-
抓取 YouTube 视频中的自动字幕。
我们选择了抓取字幕的方式,尽管这是所有选项中最具挑战性的。这样做的原因是,独立完成整个过程不会产生使用第三方 API 提取文本的费用。而且,作为一个热衷于个人项目的开发者,我更偏好这种自给自足的方法。
如果您想了解关于网页抓取的最佳实践,敬请关注,我将在不久的将来发布一篇专题文章。
2) 📄 生成文本摘要
在获得标题后,我们把它们输入到 OpenAI。我遇到的首个难题是处理文本的最大长度限制,这个限制因模型而异;对于 3.5 turbo 模型来说,上限是 4000 个词符。
为了突破这一限制,我使用了分而治之的策略。将文本切分成小块,各个块独立进行摘要,然后再合并;这个过程不断重复,直至形成一个综合性的最终摘要。
2)👨💻 实战演练
要跟随本教程,你需要安装 Yarn 和 Node.js,我这里使用的是长期支持(LTS)版本 20.9.0。如果你还没安装 Node.js,可以从官网下载。
1) 项目设置
从我的工作区文件夹出发,我创建了项目文件夹及 npm 包:
mkdir youtube-summarizercd youtube-summarizernpm init -y
加入“type: module”以启用 ES6 语法:
{"name": "youtube-summarizer","version": "1.0.0","type": "module","description": "","main": "index.js","scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"keywords": [],"author": "","license": "ISC"}
2) 安装依赖项
我们需要的库包括 Axios(进行 HTTP 请求的库),he 和 striptags(用于处理 HTML),p-queue(管理承诺队列,以便在同一时间最多发起 X 次 OpenAI 调用),以及 yargs(创建交互式命令行工具)。
可以通过以下命令进行安装:
yarn add axiosyarn add heyarn add striptagsyarn add p-queueyarn add yargs
3) 提取字幕
首先,我们需要创建一个名为 getSubtitleFromVideo.js 的文件:
touch getSubtitleFromVideo.js
我们要编写的首个功能是利用网页爬虫技术抓取 YouTube 视频页面的 HTML 代码。我们把这个功能命名为 getHTML。
const getHTML = async (video_id) => {const {data: html} = await axios.get(`https://youtube.com/watch?v=${video_id}`);return html}
获取 HTML 代码后,我们可以通过 getSubtitle 功能来提取字幕信息:
const getSubtitle = async (html) => {if (!html.includes('captionTracks')) {throw new Error(`Could not find captions for video`);}const regex = /https:\/\/www\.youtube\.com\/api\/timedtext[^"]+/;const [url] = html.match(regex);if (!url) throw new Error(`Could not find captions`);const obj = JSON.parse(`{"url": "${url}"}`)const subtitle_url = obj.urlconst transcriptResponse = await axios.get(subtitle_url);const transcript = transcriptResponse.data;const lines = transcript.replace('<?xml version="1.0" encoding="utf-8" ?><transcript>', '').replace('</transcript>', '').split('</text>').filter(line => line && line.trim()).map(line => {const startRegex = /start="([\d.]+)"/;const durRegex = /dur="([\d.]+)"/;const startMatch = startRegex.exec(line);const durMatch = durRegex.exec(line);const start = startMatch[1];const dur = durMatch[1];const htmlText = line.replace(/<text.+>/, '').replace(/&/gi, '&').replace(/<\/?[^>]+(>|$)/g, '');const decodedText = he.decode(htmlText);const text = striptags(decodedText);return { start, dur, text };});return lines;}
=> 视频的 HTML 代码中包含了一个链接,这个链接指向 YouTube 的 timedtext API,可以从中获取到一个包含自动生成字幕的 XML 文件(例如,这里有一个示例)。我们就是从这个 XML 文件中提取信息,以此来生成字幕摘要。
getSubtitleFromVideo.js 文件将提供 getSubtitleFromVideo 功能,这个功能可以外部调用,仅需提供视频链接,即可返回对应的字幕信息。
以下是 getSubtitleFromVideo.js 文件的内容:
import axios from 'axios';import he from "he";import striptags from "striptags";export const getSubtitleFromVideo = async (video) => {const video_id = await getVideoId(video)const html = await getHTML(video_id)const subtitle = await getSubtitle(html)return subtitle;}const getVideoId = async (video) => {// video can be an ID or a link like https://www.youtube.com/watch?v=fOBN8OR8YZA&t=10slet video_id;if (video.startsWith('http')) {const url = new URL(video);// https://www.youtube.com/watch?v=0chZFIZLR_0// https://youtu.be/0chZFIZLR_0?si=-Gp9e_RKG3g1SdVGvideo_id = url.searchParams.get('v') || url.pathname.slice(1);} else {video_id = resource;}return video_id}const getHTML = async (video_id) => {const {data: html} = await axios.get(`https://youtube.com/watch?v=${video_id}`);return html}const getSubtitle = async (html) => {if (!html.includes('captionTracks')) {throw new Error(`Could not find captions for video`);}const regex = /https:\/\/www\.youtube\.com\/api\/timedtext[^"]+/;const [url] = html.match(regex);if (!url) throw new Error(`Could not find captions`);const obj = JSON.parse(`{"url": "${url}"}`)const subtitle_url = obj.urlconst transcriptResponse = await axios.get(subtitle_url);const transcript = transcriptResponse.data;const lines = transcript.replace('<?xml version="1.0" encoding="utf-8" ?><transcript>', '').replace('</transcript>', '').split('</text>').filter(line => line && line.trim()).map(line => {const startRegex = /start="([\d.]+)"/;const durRegex = /dur="([\d.]+)"/;const startMatch = startRegex.exec(line);const durMatch = durRegex.exec(line);const start = startMatch[1];const dur = durMatch[1];const htmlText = line.replace(/<text.+>/, '').replace(/&/gi, '&').replace(/<\/?[^>]+(>|$)/g, '');const decodedText = he.decode(htmlText);const text = striptags(decodedText);return { start, dur, text };});return lines;}
4) 文本分块
在获得字幕之后,我们的目标是将它们分组成文本块,进而进行内容摘要。正如之前提到的,不同的模型对于可处理的上下文量有不同的限制;对于 3.5 turbo 模型来说,上限是 4000 个词元。这里,我们假设一个词元相当于一个字符。
接下来,我们需要创建一个名为 splitInChunks.js 的文件:
touch splitInChunks.js
在这个文件里,我们会提供一个同名的函数 splitInChunks,该函数负责把视频帧的字幕分组成最多不超过 4000 词的文本块。下面是具体的实施方法:
const CHUNK_SIZE = 4000export const splitInChunks = (subtitles) => {const chunks = []let chunk = ''for (const subtitle of subtitles) {if (chunk.length + subtitle.text.length + 1 <= CHUNK_SIZE) { // +1 for the spacechunk += subtitle.text + ' '} else {chunks.push(chunk)chunk = ''}}if (chunk) chunks.push(chunk)return chunks}
5) 利用 OpenAI 进行层层深入的内容总结
在这个阶段,我们已经准备好了需要处理的内容块,下一步是进行内容的精简总结。
首先,我们创建一个新的文件名为 summarizeChunks.js:
touch summarizeChunks.js
接下来,我们要做的第一件事是设置一个方法,这个方法专门用于向 OpenAI 的接口发送请求:
const OPEN_AI_API_KEY = ''assert(OPEN_AI_API_KEY, 'Please define OPEN_AI_API_KEY, you can create it from https://openai.com/blog/openai-api');const _computeSummaryByAI = async ({text, language}) => {const body = {model: "gpt-3.5-turbo",messages: [{role: "system",content: `You are a brilliant assistant, and your task is to summarize the provided text in less than 200 wordsin the language ${LANGUAGE_CODE_TO_LANGUAGE[language]}.Ensure that the sentences are connected to form a continuous discourse.`},{role: "user",content: text}],temperature: 1,top_p: 1,frequency_penalty: 0,presence_penalty: 0};try {const {data} = await axios.post('https://api.openai.com/v1/chat/completions', body, {headers: {'Content-Type': 'application/json','Authorization': `Bearer ${OPEN_AI_API_KEY}`},});const summary = data.choices[0].message.contentreturn summary} catch (error) {console.error('_computeSummaryByAI', error)throw error}}
我们会向 OpenAI 的完成任务 API 提交一个包含两部分的请求:一部分是“系统”指令,告诉它我们需要什么服务;另一部分是“用户”指令,里面包含了需要被总结的文本。很重要的一步是在 OpenAI 的开发者平台上创建一个 API 密钥,操作很简单,只需按照这个链接的指引操作即可。密钥创建好后,就将其填入到 OPEN_AI_API_KEY 这个常量中。
这个函数被我用下划线 (_) 前缀命名,是因为我们还会定义另一个名为 computeSummaryByAI 的函数,它将作为我们使用 OpenAI 服务的主入口。这个函数利用了一个名为 p-queue 的库来控制同时运行的 Promises 的最大数量,这样做是为了避免触发请求频率限制和减缓响应速度。
import PQueue from 'p-queue';const pq = new PQueue({concurrency: 5});const computeSummaryByAI = async ({text, language}) => {const summary = await pq.add(() => _computeSummaryByAI({text, language}));return summary;}
设置 concurrency: 5 表示我们最多可以同时向 OpenAI 发起 5 个请求,这是通过 Promise.all 来实现的,它允许我们并行处理多个调用。
现在,让我们深入到总结机制的核心部分,这个部分的函数如下所示:
export const summarizeChunks = async ({chunks, language}) => {// summarizes the subtitles by making sense of themchunks = await Promise.all(chunks.map((chunk) => computeSummaryByAI({text: chunk, language})))let summaryif (chunks.length > 1) {summary = await recursiveSummaryByChunks({chunks, language})} else {summary = chunks[0]}return summary}
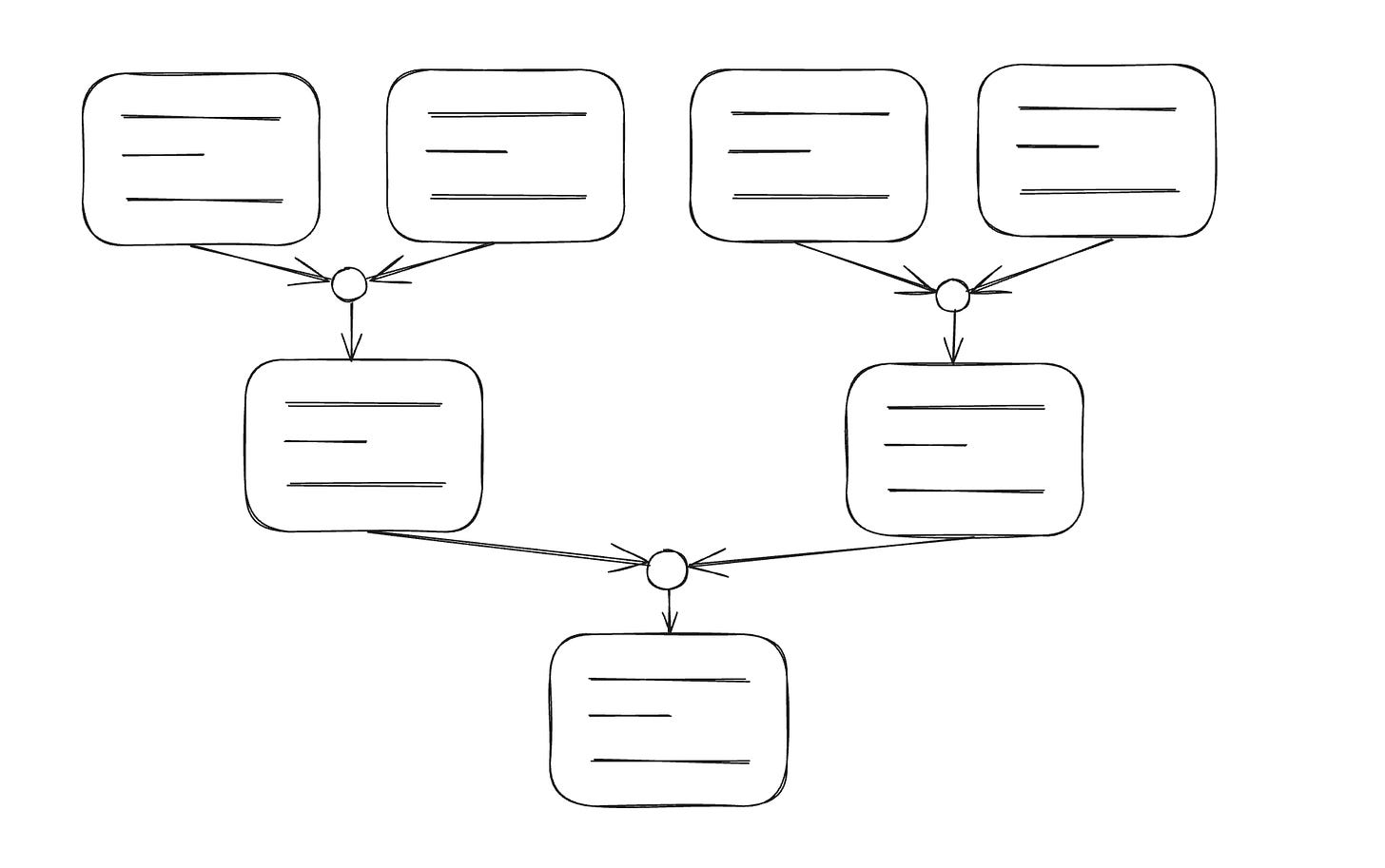
这个函数的职责是为每一块内容生成一个初始的概览,帮助我们理解其中的信息,特别是考虑到这些内容块可能包含了 YouTube 自动生成的字幕。一旦为每块内容做出了总结,如果只有一块内容,那么我们的任务就完成了,结果也随之产生。但如果内容块不止一个,那么我们就需要采用递归算法继续处理。
下面,我们定义了递归函数:
const recursiveSummaryByChunks = async ({chunks, language}) => {if (chunks.length <= 5) {return computeSummaryByAI({text: chunks.join(' '), language});}const groups_chunks = chunkArray(chunks, 5)const groups_chunks_summary = await Promise.all(groups_chunks.map((group_chunk) => computeSummaryByAI({text: group_chunk.join(' '),language})))const result = await recursiveSummaryByChunks({chunks: groups_chunks_summary, language});return result;}const chunkArray = (array, size) => {const chunks = []for (let i = 0; i < array.length; i += size) {const chunk = array.slice(i, i + size);chunks.push(chunk)}return chunks}
这个递归函数的处理逻辑如下:
-
如果内容块少于 5 块,我们就直接将这些块合并成一段文本进行总结。需要注意的是,我们在请求中指定了最多 200 个词的限制。对于 5 块内容,总词数应该控制在 1000 词以内。但根据我的实验,OpenAI 给出的响应经常超出了这个限制。因此,我设置了一个较低的阈值,以确保系统能够顺利运行,避免因为文本过长而导致的错误。
-
如果内容块超过 5 块,我们将它们分成每组 5 块,然后将每组合并成一段文本并进行总结。这些总结请求会并行执行,以提高效率。
-
完成上述步骤后,函数会将递归步骤的结果作为新的输入再次执行自身,直到所有内容块都被有效地总结并合并。
通过这种方法,我们不仅能够有效地处理大量的信息块,还能确保即使是庞大的数据量也能被迅速且准确地总结,最终得到一个内容丰富且紧凑的总结结果。这个过程展示了如何利用 OpenAI 的强大能力来处理复杂的信息处理任务,同时也体现了现代编程技术在解决实际问题中的实用性和灵活性。
你可以在这里找到所有展示的代码:https://github.com/marcomoauro/youtube-summarizer
3)📟 命令行界面 (CLI)
我开发了一个命令行工具,它允许用户通过输入 YouTube 视频的链接和想要的摘要语言代码,来快速生成视频摘要。以下是启动该工具的示例:
yarn cli --video="https://www.youtube.com/watch?v=3l2wh5K_WLI" --language en
*请确保你已经在项目根目录下,并且按照如下步骤正确安装了所有必需的依赖:
yarn install
4)✨ 在 Quickview.email 上免费体验!
我把这项服务整合到了我的网站 quickview.email 上。你只需提供接收摘要的电子邮箱地址、YouTube 视频链接以及你希望阅读摘要的语言,就可以轻松获得视频摘要。