聊天机器人性能革新:探索三大 RAG 性能提升策略 [译]
![聊天机器人性能革新:探索三大 RAG 性能提升策略 [译]](/images/rag/revolutionizing-chatbot-performance-unleashing-three-potent-strategies-for-rag-enhancement/1_fZr0NbBkNtEIDTsi-LoYcQ.webp)
在我们深入 RAG 聊天机器人系列的最后几章之前,许多逐步构建聊天机器人的读者可能遇到了一些疑问。比如,在不追求快速反应、而更看重准确回答的情况下,比如医疗类聊天机器人,我们应该如何做?
今天,我们要介绍三种不同的技术,它们专注于在特定技能上提升聊天机器器人的整体性能。重要的是,本节我们将不采用任何开源库或工具。这一选择是刻意为之,主要是为了关注性能优化这一核心议题。尽管这些技术对于聊天机器人的功能来说是可选的,但它们对于对性能有特别要求的用户和企业而言却非常关键。
在本次讨论中,我会通过代码片段来详细说明每种技术。所有这些代码片段都可以轻松地融入之前文章中的代码,使得实施过程变得无比简单。如果您觉得这些示例对您的机器人项目有帮助,请随意使用。
以一个为最终用户提供棋盘游戏信息的聊天机器人为例,我们来具体看看这些技术是如何应用的。
为了帮助您更好地理解这些技术,本文底部提供了一个公开的 Google Colab 笔记本链接,其中包含所有相关代码片段。您可以利用这个资源来测试这些示例,并轻松地将它们应用到您的聊天机器人开发中。探索、调整并提升您的聊天机器人体验!
智能体

可以把智能体想象为一位全能的协调者,它拥有多种技术工具,能够根据不同的任务选择最适合的工具。智能体的运用大大提高了 RAG(检索增强生成)系统的响应质量。LlamaIndex 这个平台提供了多种智能体,包括 ReAct 智能体、OpenAI 智能体,以及自定义智能体。
在我亲自尝试这些智能体后,我发现目前最有效的要么是基础的 OpenAI 智能体,要么是先进的 ContextRetrieverOpenAIAgent。对于这些智能体的具体特点、优势和不足,我建议你查阅 Llama Index 的详细文档,那里有关于它们差异的全面介绍,帮助你根据自己的需求做出选择。
现在,我们来试试 ContextRetrieverOpenAIAgent。首先,我们将开始建立索引的步骤。这一次,我会选择一个快速的方法,尽管在前几章中我们已经探讨过使用不同技术建立索引的其他方法。
from llama_index import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.tools import QueryEngineTool, ToolMetadatadocuments = SimpleDirectoryReader("data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine();
在启动 ContextRetrieverOpenAIAgent 之后,下一步是定义 QueryEngineTool 数组。简单来说,这个数组就像是一个大盒子,你可以在里面整理和管理所有的索引。这个功能支持同时使用多个索引。
你可以把这些索引想象成智能体的工具箱,无论是处理查询还是参与对话,它都能从中选择最适合的工具来完成任务。这种动态选择方式使智能体能够根据每次互动的具体需要调整和优化它的表现。
通过使用 QueryEngineTool 数组,我们为智能体提供了一个多功能的工具包,使它能够在各种场景中更有效地导航和响应。这种对工具管理的精心设计有助于提升 RAG 系统的表现,确保用户体验流畅且具有强大的适应性。
query_engine_tools = [QueryEngineTool(query_engine=query_engine,metadata=ToolMetadata(name="basic_rules",description=("the basic game rules and description"),),),]
我们接下来要做的,是创建智能体。在这一步骤中,特别引入了“similarity_top_k”字段。这个字段使我们能够指示 RAG 在搜索时考虑与查询最匹配的前三个元素作为上下文。为了更深入地理解这个概念,我建议参考本系列的第一章,在那里我们详细讲解了 RAG 的架构。
在创建智能体的过程中,我们还引入了“verbose”字段,这个功能允许我们实现自动日志记录,从而清晰地看到每一个步骤的运行情况。这在了解智能体的行为和排查可能出现的问题时非常有价值。自动日志作为一项重要资源,能够让我们深入了解智能体的内部运作,有助于我们在开发和部署过程中更加顺利地解决问题。
from llama_index.agent import ContextRetrieverOpenAIAgentcontext_agent = ContextRetrieverOpenAIAgent.from_tools_and_retriever(query_engine_tools,index.as_retriever(similarity_top_k=3),verbose=True,)
接下来是最后一步,我们在这里生成响应:
response = context_agent.chat("What is the game about?")print(response)
太棒了!通过这种方法,我们不仅深入了解了智能体的基本概念,还快速了解了 LlamaIndex 中各种可用智能体的多样性。我们通过研究不同类型的智能体,例如 ReAct 智能体、OpenAi 智能体和自定义智能体,为做出明智的选择奠定了基础。
我们还探索了这些知识的实际应用,尤其是选择了我认为最合适的两个选项:基础的 OpenAi 智能体和创新的 ContextRetrieverOpenAIAgent。这为我们利用这些智能体来提升 RAG 系统的性能和响应质量打下了坚实的基础。
总之,这种方法为我们提供了一个宝贵的基础,使我们能够在智能体的世界中导航,做出明智的选择,并优化我们的 RAG 实现,以获得更优异的结果。请继续关注,因为我们将深入探索如何改善和微调我们聊天机器人的功能!
降低成本

RAGs(一种技术)在基础设施成本上的考量至关重要。随着我们应用用户数量的增长,相关费用也会急剧上升。为了应对这个挑战,我们采用了一种名为“提示压缩(Prompt Compression)”的策略。正如我们之前文章所述,为了使 RAGs 工作,我们需要向语言模型传递一个包含从 VectorStore 检索到的 top_k 节点的自定义提示。这其中,无论是输入的提示还是输出,都会产生成本,我们的目标是减少这两方面的成本。
为了减少输入提示的成本,我们使用了一个叫做 SentenceEmbeddingOptimizer 的类。这个类在缩减我们的 top_k 节点文本方面起到了关键作用。它是如何实现的呢?答案是利用了另一种语言模型!这里有多种选择,我推荐考虑经典的 Gpt-3.5 或者 LlmLingua 模型。前者成本效益高,速度快;而后者虽然是开源的,但在你的机器上设置和维护需要更多的工作。如果预计有大量用户,比如百万级别,选择 LlmLingua 可能会更划算。
但在这个案例中,我们将探讨 Gpt 的实现方法。其设置过程与之前类似,但需要添加一段关键的代码:
from llama_index.postprocessor import SentenceEmbeddingOptimizerquery_engine = index.as_query_engine(node_postprocessors=[SentenceEmbeddingOptimizer(percentile_cutoff=0.5)])query_engine_tools = [QueryEngineTool(query_engine=query_engine,metadata=ToolMetadata(name="basic_rules",description=("the basic game rules and description"),),),]context_agent = ContextRetrieverOpenAIAgent.from_tools_and_retriever(query_engine_tools,index.as_retriever(similarity_top_k=3),verbose=True,)response = context_agent.chat("Give me in a short answer how to play the first turn?")print(response)
这个策略的关键在于一个名为“percentile_cutoff”的参数。该参数对于指导语言模型如何有效地压缩上下文至关重要。在这个例子中,我们把它设定为 50%,从而把输入提示的成本减少了一半。这是一个有效的成本优化手段,但需要注意的是,将 percentile_cutoff 提高到 60-65% 可能会导致输出内容混乱或细节减少。因此,找到一个适当的平衡点,以保持模型输出的完整性和质量,是非常关键的。
输出
在输出方面,这方面相对比较直接。虽然没有直接降低成本的方法,但你可以通过控制模型响应的长度来间接影响。指导模型给出简短的答复,从而减少输出的 Token 数量,这有助于更高效的操作。这是一个细微但有效的手段,用于控制与 RAG 基础设施相关的开销。
response = context_agent.chat("Give me in a short answer how to play the first turn?")print(response)
我认识到,这种方法可能不是最终的解决方案,但它在实际操作中显示出了显著的效果。采用这种方法显著减少了语言模型的输出量,使操作更加高效和节省成本。有时候,简洁本身就是一种智慧。在这种情境下,引导模型进行更短的回应已被证明是一种行之有效的策略,达到了减少输出的目的。
重排
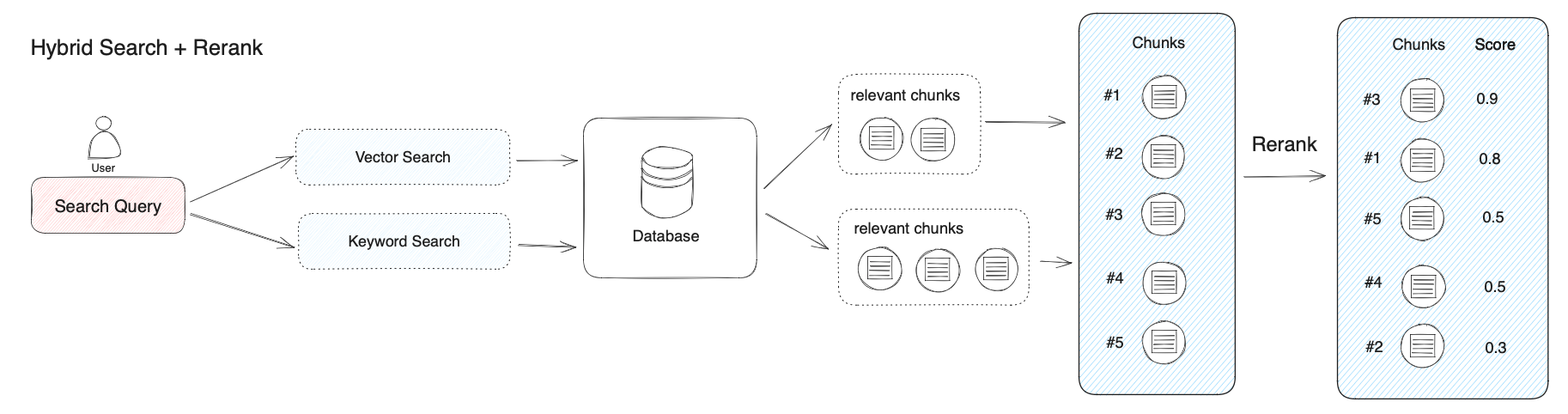
在许多领域,如信息检索、自然语言处理和机器学习中,重排(reranking)是一种基于特定标准或额外信息来调整一组项目顺序的技术。它的核心目标是通过引入额外的特性或优化初步排名,来提高项目的排名效果。
在自然语言处理领域,重排技术常用于机器翻译或语言生成系统。当系统生成了一系列可能的输出后,重排技术就会介入,帮助选择最合适、最流畅的结果,同时考虑语言特征和上下文因素。
例如,在我们之前的例子中,我们选取了前三个最可能的选项(top_k 3)并交给语言模型处理。但是在实施重排时,我们会扩大考虑的范围,比如评估前十个结果。在最终展示给语言模型之前,这些结果会经过一次重排过程,以提高回应的整体质量。
重排是一个非常强大的技术,尤其是当它与智能体结合使用时,可以显著提高回应的质量。有两种重排方法值得考虑:
- Cohere 重排:这是一个高效的工具,被认为是目前最佳之一。但它的成本较高,因为 Cohere 负责定制模型的训练和部署。如果预算允许,这是一个值得推荐的选择。
- 利用另一个大语言模型(LLM)进行重排:这是一个成本更低、效果同样出色的选择。它特别适合于处理非敏感数据的场景,比如不涉及医院数据的情况。
在本文中,我们将重点讨论第二种方法。实施这一方法的第一步,是重建索引并将上下文保存在服务中。这个上下文是为重排模型提供必要信息的基础。接下来,我们将介绍这一关键步骤。
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,ServiceContext,)from llama_index.llms import OpenAIdocuments = SimpleDirectoryReader("data").load_data()llm = OpenAI(temperature=0, model="gpt-3.5-turbo")service_context = ServiceContext.from_defaults(llm=llm, chunk_size=512)index = VectorStoreIndex.from_documents(documents, service_context=service_context)
在我们的重排策略中,我们选择了简洁而高效的 GPT-3.5-turbo 模型。但值得注意的是,基准测试显示 Ministral Experts 模型的表现更为出色。如果你已经在之前的文章中使用过 Ministral Experts 模型,为了保持一致性和最佳表现,建议继续使用该模型。
在选择了合适的语言模型之后,下一个步骤是定义重排器。这个过程涉及确定哪种语言模型最适合用于重排任务,并设置相关参数。例如,如果选择 GPT-3.5-turbo 模型,我们需要考虑如何调整模型以优化重排结果。而如果选择 Ministral Experts 模型,则可能需要考虑模型的特定优势,比如其在理解复杂语境方面的能力。不论选择哪种模型,目标都是确保重排过程既高效又准确,以提升最终输出的质量。
from llama_index.postprocessor import LLMRerankreranker = LLMRerank(choice_batch_size=5,top_n=3,service_context=service_context,)
如前所述,重新排列器的功能是对最初筛选出的前三项内容进行再处理,这些内容来源于一个更庞大的数据集。基于此,我们设计了一个查询引擎,能够检索超过 3 个的结果。具体检索多少数据要根据您的需求来定。重要的是要找到平衡 — 要避免处理过多的数据,因为这可能会增加成本。但通常,更多的数据能带来更佳的结果。在我们的测试中,我们选择分析前 10 名的结果:
query_engine = index.as_query_engine(similarity_top_k=10,node_postprocessors=[reranker],response_mode="refine",)
请特别注意 response_mode="refine" 这一字段 — 它标志着一种较慢但效果显著的方法。这种方式就像是一个重质量胜于速度的智能体。在本章节中,我们专注于提升响应的质量,这种方法正好符合我们的目标。
在这些配置完成后,我们将进行更多测试,来评估重新排列对响应质量的整体影响。
response = query_engine.query("What is the best strategy for the first turns?",)print(response)
好极了!事实证明,生成结果令人印象深刻,凸显了所实施战略的有效性。
在本文中,我们探讨了众多概念,并介绍了三种提升 RAG 性能的策略。现在,轮到你来选择 — 在这三种策略中,你想尝试哪一种?无论你之前是否已经熟悉这些技术,本文都为你提供了一个全面的探索资源。
对于那些想要深入了解代码并亲手尝试的读者,可以在此链接找到本文的代码:文章代码
如果你认为本文有见地且有所帮助,欢迎在社交平台上分享,并留下你的喜欢和支持!祝你实验愉快!