我们真的变成巫师了:OpenAI API 负责人谈 AI 如何重塑软件工程
宝玉

Sherwin Wu 是 OpenAI API 和开发者平台的工程负责人。如果说每家 AI 初创公司都通过 OpenAI 的 API 构建产品,那 Sherwin 的团队就是这个巨大生态的基础设施提供者。他 2014 年从 MIT 毕业,先后在 Quora 负责信息流、在 Opendoor 做了五年多的房屋定价模型,后来加入 OpenAI 成为早期成员。

他最近在 Lenny's Podcast 上做了一次深度对话(视频地址:www.youtube.com/watch?v=B26CwKm5C1k),从 OpenAI 内部的 AI 编码实践谈到工程管理哲学,从“一人十亿美元公司”的连锁效应谈到 AI 部署为什么经常失败。以下是这次访谈的完整整理。
“95% 的工程师在用 Codex,100% 的 PR 由 Codex 审查”
Lenny 开门见山:你还写代码吗?你团队有多少代码是 AI 写的?
Sherwin 说,他自己作为管理者,所有代码现在都是 Codex 写的。对管理者来说,用 AI 工具写代码反而比手写更容易了。
但团队层面的数据更能说明问题:
95% 的工程师在日常使用 Codex。100% 的 PR 都由 Codex 审查,任何合入生产环境的代码,Codex 都会过目并提出改进建议。
而且这个趋势还在加速。Sherwin 分享了一个内部跟踪的数据:重度使用 Codex 的工程师,比用得少的工程师多提交了 70% 的 PR,而且差距在持续扩大。他认为这是一种“复利效应”,用得越多的人越能掌握工具的最佳实践,效率增益不断累积。
【注:OpenAI 在 2025 年 11 月发布 GPT-5.1-Codex-Max 时,官方博客引用了完全相同的数据:"95% 的 OpenAI 工程师每周使用 Codex,这些工程师的 PR 产出约增加了 70%",与 Sherwin 在播客中的说法相互印证。】

Lenny 追问:所以几乎所有代码的初始版本都是 AI 生成的,然后工程师来审查?
Sherwin 确认了这一点,但也补充说确实还有一些工程师对 Codex 的信任度相对较低。不过他几乎每天都会碰到有人被 Codex 的某个表现震惊到,然后对模型的信任度又上了一个台阶。
他引用了 OpenAI 首席产品官 Kevin Weil 的一句话:
“今天的模型是它们有史以来最差的时候。”
这是 AI 编程能力的起点,不是终点。
巫师、咒语和魔法师的学徒
Lenny 问:未来一两年,软件工程师这份工作到底会变成什么样?
Sherwin 先描述了当下的变化:IC(个人贡献者)工程师正在变成 tech lead,管理着成群结队的 agent。他团队里很多工程师同时拉着 10-20 个 Codex 线程,不是同时运行,但并行推进。他们的工作已经从“亲手写代码”转变为“检查 agent 在做什么,给它反馈,引导它的方向”。
然后他引用了一个比喻,来自他在大学时读过的 MIT 经典教材**《计算机程序的构造和解释》(SICP)**,程序员圈子里俗称“巫师书”。
这本写于 1980 年代的书在开篇就把编程比作巫术:程序员是巫师,编程语言是咒语,你需要找到正确的咒语来让程序做你想做的事。
Sherwin 认为这个比喻在 AI 时代变得格外贴切:
现在的咒语真的变成了自然语言。你告诉 Codex 或 Cursor 你想做什么,然后它就出去替你做了。这感觉真的像在施法,我们真的变成巫师了。
但他紧接着补充了另一个比喻,迪士尼《幻想曲》里的**"魔法师的学徒"**。米奇找到了巫师的帽子,开始疯狂施法让扫帚替他干活,结果水漫金山。
这是 vibe coding(只描述想法、不看代码的编程方式)的终极版本。米奇给扫帚下了一个任务,然后自己去睡觉了。
Sherwin 说,当他看到工程师们同时开着 20 个 Codex 线程时,确实需要相当的经验和判断力来确保模型不跑偏。你绝对不能像米奇那样完全放手不管。但对于真正熟练的工程师来说,这种杠杆效应是空前的,一个人能做的事情比以前多了太多。
移除逃生舱:100% Codex 代码库实验
Lenny 提到一个越来越多人在讨论的问题:当你的 agent 不工作的时候,那种焦虑感。你派出一堆 Codex agent,然后发现有一个卡住了,时间在浪费...
Sherwin 说他们内部也天天遇到这种情况。然后他分享了一个内部实验:
有一个团队正在 OpenAI 内部做一个实验,他们维护一个 100% 由 Codex 编写的代码库。不是说“AI 写了初稿然后人来改”,而是完完全全由 Codex 生成、全盘接受。
这个团队遇到了完全可以预料的问题:想让 agent 实现某个功能,但 agent 就是做不对。
通常在这种情况下,你会有一个“逃生舱”,撸起袖子自己写,或者切换到 tab 补全和 Cursor 这样的辅助工具。但这个实验团队刻意不给自己留这条退路。
Sherwin 说他们计划发布一篇关于这个实验的博客文章,因为从中产生了不少发现。其中一个关键发现是:
当 coding agent 不按你想的做时,问题往往不在模型的能力,而在于上下文。你要么描述得不够清楚,要么代码库里缺乏足够的信息来引导 agent。
解决方案?把你脑子里的**"部落知识"**编码到代码库中,通过代码注释、代码结构、Markdown 文件、skills 文件等各种形式,让模型能获取到做任务所需的背景信息。
移除逃生舱让他们不得不直面一个核心问题:如果我们真的要全面依赖 agent,到底需要解决什么?这个极端实验成了一个很好的“压力测试”。
AI 代码审查:从 10 分钟缩短到 2-3 分钟
PR 产量暴增自然带来代码审查的压力。Sherwin 分享了他们的解法。
他先用一个个人故事铺垫:他在第一份工作 Quora 时负责信息流的代码,每天早上登录就看到 20-30 个等待审查的 PR,拖延一下就变成 50 个。代码审查一直是他最讨厌的环节。
现在 Codex 审查所有 PR。他提到 5.2 版本的模型在代码审查上表现极好,尤其是当你给它一些引导方向的时候。
代码审查从原来的 10-15 分钟变成了 2-3 分钟,因为大部分建议已经提前准备好了。对于小的 PR,有时候甚至不需要人来审查,Codex 就是一双相当聪明的“第二双眼睛”。
Lenny 追问:Codex 写代码,Codex 审查自己的代码,这不是“自审”吗?
Sherwin 承认确实有循环性的问题,回到了魔法师学徒的比喻,你不能让扫帚完全失控。大多数工程师仍然会看 PR,只是注意力从 100% 降到了 30% 左右,这就够用了。他们也会用模型的不同内部变体来获取不同视角。
在代码审查之外,CI(持续集成)流程、lint 错误修复、部署前的各种琐碎工作也已经大量通过 Codex 自动化了。目标是把工程师在“写完代码到上线”之间的摩擦压缩到最小。
管理者的角色变化:外科手术团队
Lenny 把话题转向管理者:工作怎么变了?
Sherwin 说管理者的变化比工程师小,还没有“管理者版的 Codex”。但他看到了几个趋势。
第一个趋势是 AI 放大了个人能力差距。Codex 尤其放大了高绩效员工的产出,他们本来就能力强,再加上 AI 杠杆,差距急剧拉大。
这也是他一直坚持的管理哲学:
我一直把超过 50% 的时间花在排名前 10% 的员工身上,确保他们不被阻塞,确保他们开心,确保他们觉得自己有生产力并且被倾听。
Marc Andreessen 最近在 Lenny 的播客里说过一句类似的话:“AI 让好的人变得更好,让优秀的人变得卓越。”Sherwin 完全认同。
然后他展开了另一个比喻,来自 Frederick Brooks 的**《人月神话》**。这本 1970 年代的书预测软件工程会变成像外科手术一样:手术室里有一个人主刀,其他所有人都在支持这个人。
我不认为软件工程完全变成了这样,它更协作。但我把这个比喻用在了自己的管理方式上:让我团队里的人觉得自己是主刀医生,而我作为管理者就是那个“外科手术团队”,替他们提前准备好手术刀,替他们看到拐角后面的障碍。
他举了一个具体例子:当工程师们以飞快的速度产出 PR 时,真正的瓶颈往往是组织层面和流程层面的阻塞。如果管理者能提前看到这些阻塞并清除掉,效果就像主刀医生还没开口说“手术刀”,护士就已经递过来了。
关于 AI 对管理本身的辅助,Sherwin 提到他们正在做绩效评估,用连接了 GitHub、Notion 和 Google Docs 的 ChatGPT 来给每个人生成过去 12 个月的“深度研究报告”,非常好用。他预测管理者未来能管理更大的团队,超过目前普遍认为的 6-8 人上限。
Lenny 突然问:你有没有试过让 ChatGPT 连接公司的 Notion 和 Slack,主动告诉你“你团队里谁可能被什么东西卡住了”?
Sherwin 愣了一下:没试过,但这主意太好了。
Lenny 继续追:甚至可以问它“预判一下下个月可能出现什么阻塞”。
Sherwin 笑了:让 AI 做二阶、三阶推理,预判阻塞。我们刚刚发现了一个好点子。
一人十亿美元公司:你没“定价”进去的连锁效应
Lenny 问:人们对 AI 的影响,有什么还没充分意识到的?
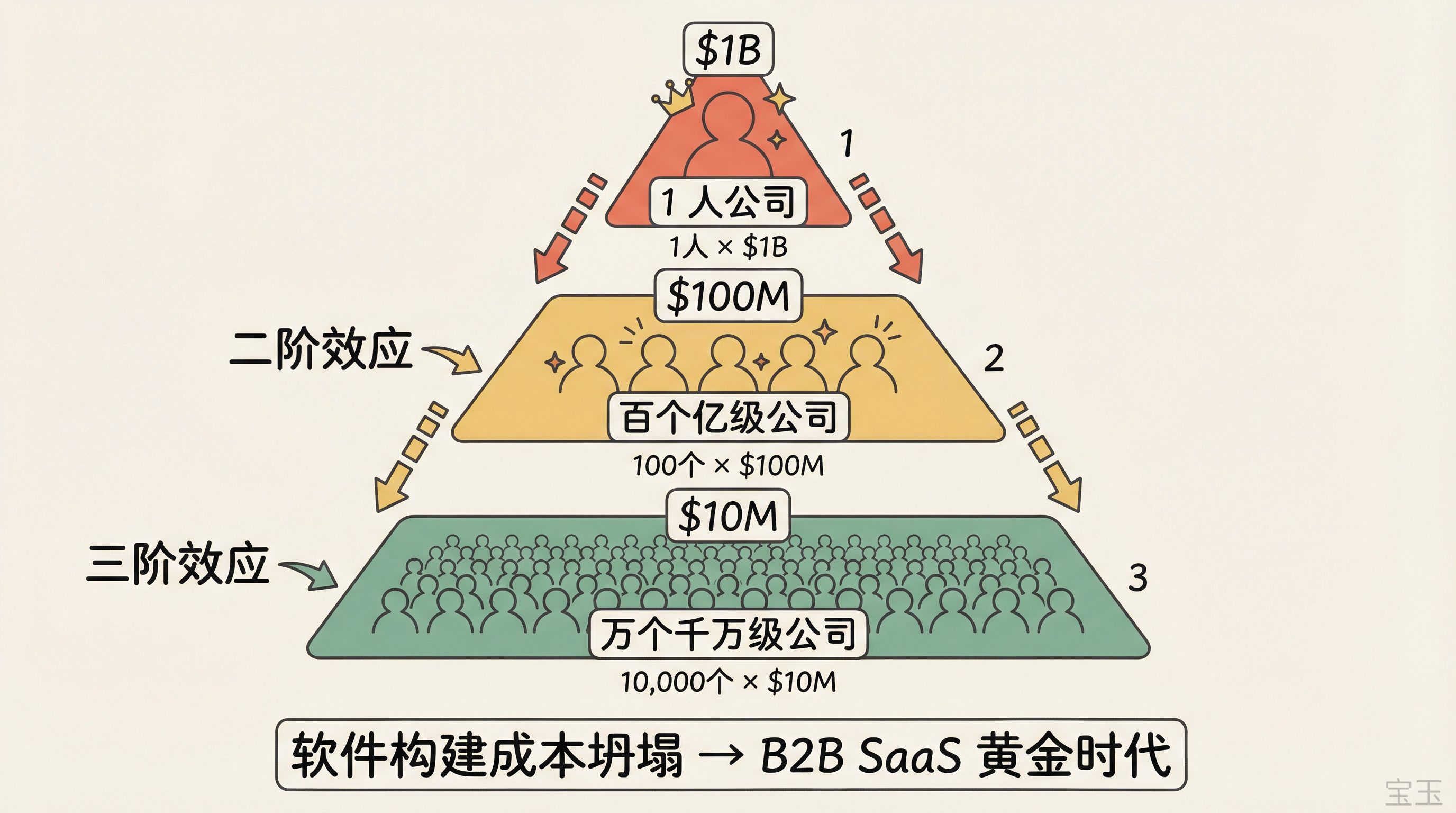
Sherwin 从“一人十亿美元公司”这个概念切入。他认为这是 AI 浪潮中最引人注目的想法之一,可能最早由 Sam Altman 提出。但他更感兴趣的是大家还没想到的二阶和三阶效应。
二阶效应:如果一个人能创建十亿美元的公司,那创建一般的公司就更容易了。他预测会出现一波巨大的创业潮,尤其是垂直化的 AI 软件公司。为了支撑一个“一人十亿美元公司”的运转,可能需要上百个小型公司提供定制化的配套软件。
可能会有一个一人十亿美元的公司,但也会有一百个一亿美元的公司,上万个一千万美元的公司。对个人来说,一千万美元的生意已经足够让你一生无忧了。
他认为这可能是 B2B SaaS 的黄金时代,因为软件构建的成本正在坍塌。
三阶效应:如果大量公司是“微型公司”(一两个人),VC 生态可能会改变。这些一千万到五千万美元的公司对创始人来说很好,但不适合风险投资追求的 100 倍回报。市场可能会分化成少数大平台加上海量小公司的格局。
Lenny 补充了他自己想到的**"第四阶效应"**:当选择如此之多时,分发能力变得越来越重要,有受众和平台的人会变得更有价值。
对于"一个人怎么处理客服"的质疑,Sherwin 说:你不需要亲自用 AI 解决客服问题。会有别的小型创业公司专门为你这类业务打造极度定制化的客服工具,比如"播客和 newsletter 专用客服软件"。因为构建软件的成本大幅下降,"自建还是外包"的平衡点会大幅偏向外包。
为什么这么多 AI 部署在亏钱
作为 API 平台的负责人,Sherwin 和大量企业客户打交道。他观察到很多 AI 部署可能实际上是亏钱的。
他首先强调了一个被反复低估的事实:
我们在硅谷生活在泡沫里。Twitter/X 是泡沫。软件工程是泡沫。世界上大多数人不是软件工程师,不是 AI 狂热者,不关注每个模型发布。
当他跟这些企业的实际员工交流时发现,他们对 AI 的使用极其基础,问最简单的问题,远远没有推到极限。
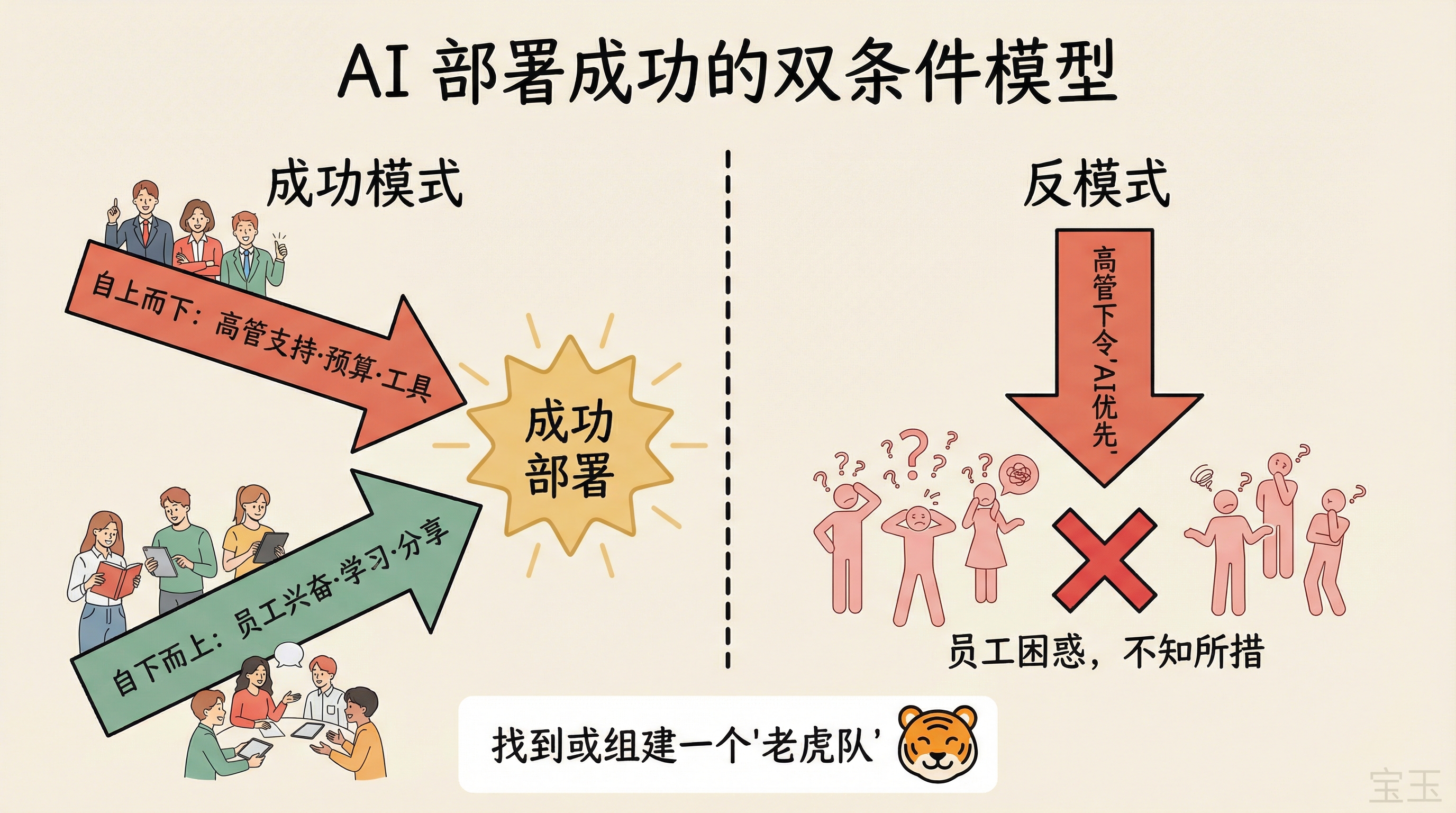
他认为 AI 部署成功需要两个条件同时满足:
自上而下的买入:高管层的支持、预算、工具采购
自下而上的传播:真正做事的员工对技术感到兴奋,愿意学习和分享
反模式是纯粹的自上而下:高管下令“我们要成为 AI 优先的公司”,甚至在绩效评估中加入 AI 使用指标,但员工不理解技术,周围也没人在用,结果就是一大群困惑的人不知道该做什么。
他的建议:
找到或专门组建一个**"老虎队"**,一个内部的全职团队,去探索 AI 能力在具体工作流中的极限,然后做知识分享,在内部点燃兴奋感。
Lenny 问这个老虎队应该由什么人组成。Sherwin 说:
往往不是软件工程师,因为很多公司根本没有软件工程师。通常是"技术相邻"的人,比如运营团队里那个不会写代码但是 Excel 奇才、对新技术特别有热情的人。这类人我见到过的反应最强烈。
“模型会在早餐前吞掉你的脚手架”
Sherwin 谈到了他在 AI 领域的一个观察。
他引用了 FinTool 创始人 Nicholas 在 X 上的一句话:
“模型会在早餐前吞掉你的脚手架。”
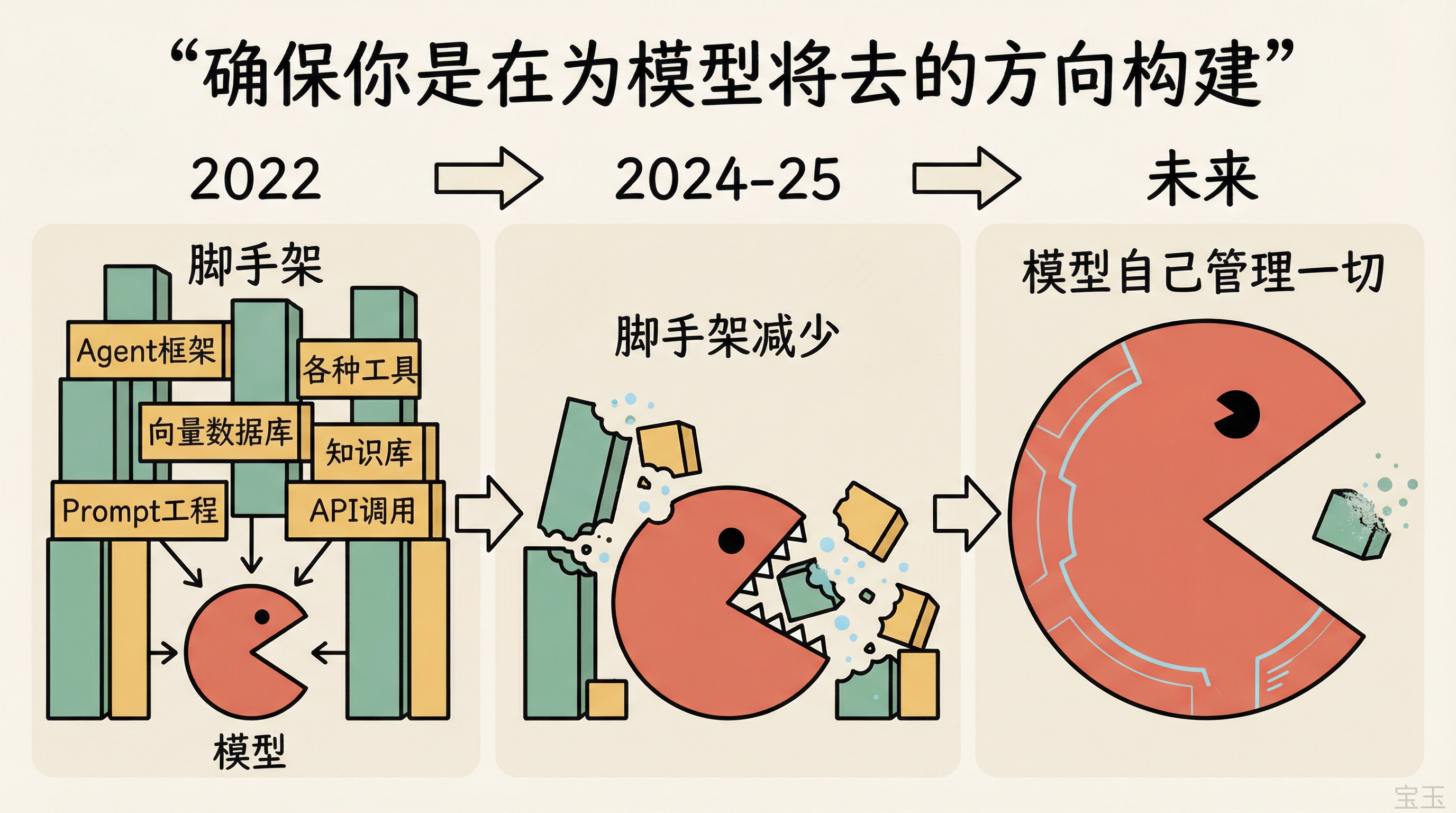
回看过去三年:2022 年 ChatGPT 刚发布时,模型还比较“生”,于是整个开发者生态建了大量的脚手架,agent 框架、向量数据库、各种试图驯服模型的工具。当时向量数据库是最热门的话题。
然后模型迅速进步,大量脚手架变得多余了。向量数据库不再是唯一的上下文管理方式,你可以直接把文件放在文件系统里,用 skills 文件和 agents.md 来引导模型。
Sherwin 甚至预测,当前流行的 skills 文件和基于文件的上下文管理方式也可能被未来的模型吞掉,因为模型可能学会自己管理这些。
他承认 OpenAI API 团队自己也在这个问题上犯过错:
我们也走了一些不该走的弯路。但模型变得更好了,我们都在日复一日地学习**"苦涩的教训"(The Bitter Lesson)**。
Lenny 提到了 Rich Sutton 的“苦涩的教训”:AI 研究的核心教训是不要过度设计,让模型自己去 scale。Sherwin 认为在“用 AI 构建产品”这件事上,存在完全相同的教训,我们精心架构了各种脚手架,结果模型都给吃掉了。
他给创业者的建议:
确保你是在为模型将去的方向构建,而非它们今天的能力。
他见过的最成功的初创公司,构建的产品可能在当下只有 80% 的模型能力支撑,看起来“差一点”。但当新模型出来,o3、5.1、5.2,突然就“点击到位”了,产品变得惊艳。
你可能需要等一等,但模型进步如此之快,通常不需要等太久。
未来 12-18 个月:多小时任务和被低估的音频
Lenny 问:API 和模型接下来会往哪里发展?
Sherwin 提了两个方向。
第一个是任务持续时间的延长。 他引用了 Meter Benchmark 的数据,这个基准测试追踪模型能在多长的软件工程任务上保持连贯。目前前沿模型能在多小时任务上达到约 50% 的成功率,在接近 1 小时的任务上达到约 80%。
他认为 12-18 个月内,模型可能能够连贯地执行 6 小时甚至一整天的任务。围绕它构建的产品形态会完全不同,你不再是分钟级地交互,而是“派出一个 agent,让它自己工作半天”。
第二个是音频和语音 AI。 这个领域他认为被严重低估了:
所有人都在谈编码,都是文本。但我们现在就在用音频对话。全球大量的商业活动是通过对话完成的。大量的服务和运营是通过语音进行的。
他预测在原生多模态模型(speech-to-speech)方面会有显著进步,尤其是在企业和商业场景中。
OpenAI 会和你的创业公司竞争吗?
这是每个在 OpenAI API 上构建产品的创业者最关心的问题。
Sherwin 说:
市场太大了,大到初创公司不应该过度纠结 OpenAI 或其他大公司会去哪里。
他跟很多初创公司打过交道,失败的和成功的都有。他见过的每一个失败的公司,原因都不是被 OpenAI 挤压,而是做了客户不喜欢的产品。而成功的公司,哪怕是在编码这样的激烈竞争领域,比如 Cursor,因为做了用户真正喜爱的产品,照样做大了。
这个机会空间大到什么程度呢?大到 VC 对投资竞争对手的容忍度完全变了,他们左手投一个右手投另一个,因为蛋糕实在太大了。
他强调 OpenAI 从创立之初就把自己定位为生态平台公司。API 是他们的第一个产品。每个在 ChatGPT 产品中发布的模型都会在 API 中提供。他们不封锁竞争对手,保持平台中立。
这背后的逻辑回到了 OpenAI 的使命:构建通用人工智能(AGI),并将其好处传播给全人类。
我们认为自己作为一家公司不可能触达全人类的每个角落。所以我们需要一个平台,让其他人来构建“播客和 newsletter 专用客服机器人”,因为我们自己做不到。
他提到 ChatGPT 目前有超过 8 亿周活用户,约占全球人口的 10%。配合即将上线的 ChatGPT 应用商店(由 ChatGPT 团队而非 API 团队主导),OpenAI 希望让这个生态进一步扩大。
【注:ChatGPT 8 亿周活的数据由 Sam Altman 在 2025 年 10 月的 Dev Day 上宣布,TechCrunch 等媒体有报道。OpenAI 2025 年全年的年化经常性收入超过了 200 亿美元,其中 API 业务在单月内就新增了超过 10 亿美元 ARR。】
“不要把这个时代当作理所当然”
访谈最后聊到了对当下的感受。
他 2014 年入行,觉得头几年挺好,但接下来有五六年科技行业没什么特别令人兴奋的事情。然后过去三年成了他职业生涯中最疯狂、最激动人心的时期。
接下来两到三年还会继续这样。我鼓励大家不要把这当作理所当然。总有一天这波浪潮会趋于平缓,变得更渐进。但在那之前,我们有机会探索很多很酷的东西,发明新事物,改变世界。
对于“怎么才能不错过”,他的建议很实际:不一定要是工程师,不一定要创业,但要动手用这些工具。安装 Codex CLI 玩一玩。把 ChatGPT 连接到你的 Notion、Slack、GitHub 上看看它能做什么。理解它现在的能力边界,这样当模型进步时,你能敏锐地捕捉到新的可能。
对于“信息过载”的焦虑,他也提供了安慰,虽然他承认自己是“X 上的重度瘾君子”不是好榜样:
大量信息其实是噪音。你不需要掌握 110% 的资讯。老老实实用好一两个工具、从小处开始,就已经足够了。
闪电问答
推荐书籍:
科幻小说:《There Is No Antimemetics Division》(Q&M 著),关于一个政府机构对抗“让人遗忘它的东西”的故事,两天读完
非虚构:Dan Wang 的《Breakneck》,美国是“律师社会”,中国是“工程师社会”,各有利弊
非虚构:Patrick McGee 的 Apple 与中国关系的书,大量 Apple 内部信息
喜欢的产品: Ubiquiti 的家庭网络和安防摄像头系统,“家庭网络里的 Apple”,硬件漂亮但真正出色的是软件和 app
人生格言: “永远不要自怜”,无论工作还是生活中遇到什么,始终提醒自己有能力把自己拉起来
在 Opendoor 学到的冷知识: 影响房价的意外因素包括高压电线(住在旁边嗡嗡响,有孩子的家庭避之不及)、户型(极难量化但影响巨大,“你走进去就是能感觉到”)、以及大门外观(Zillow 有数据显示换一扇前门是投资回报率最高的装修项目)。