Claude Code 源码泄漏了,但我不打算写源码分析分析文章
宝玉
Claude Code 源码泄漏了,满屏都是“深度分析”文章。也有朋友让我写一篇分析文章,但代码才泄漏十几个小时,50 多万行代码,想深度分析清楚还是有难度的。不过授人以鱼不如授人以渔,我更想聊聊:拿到一份开源代码,怎么把它真正学到手。
这套方法不只适用于 Claude Code,任何大型开源项目都一样。
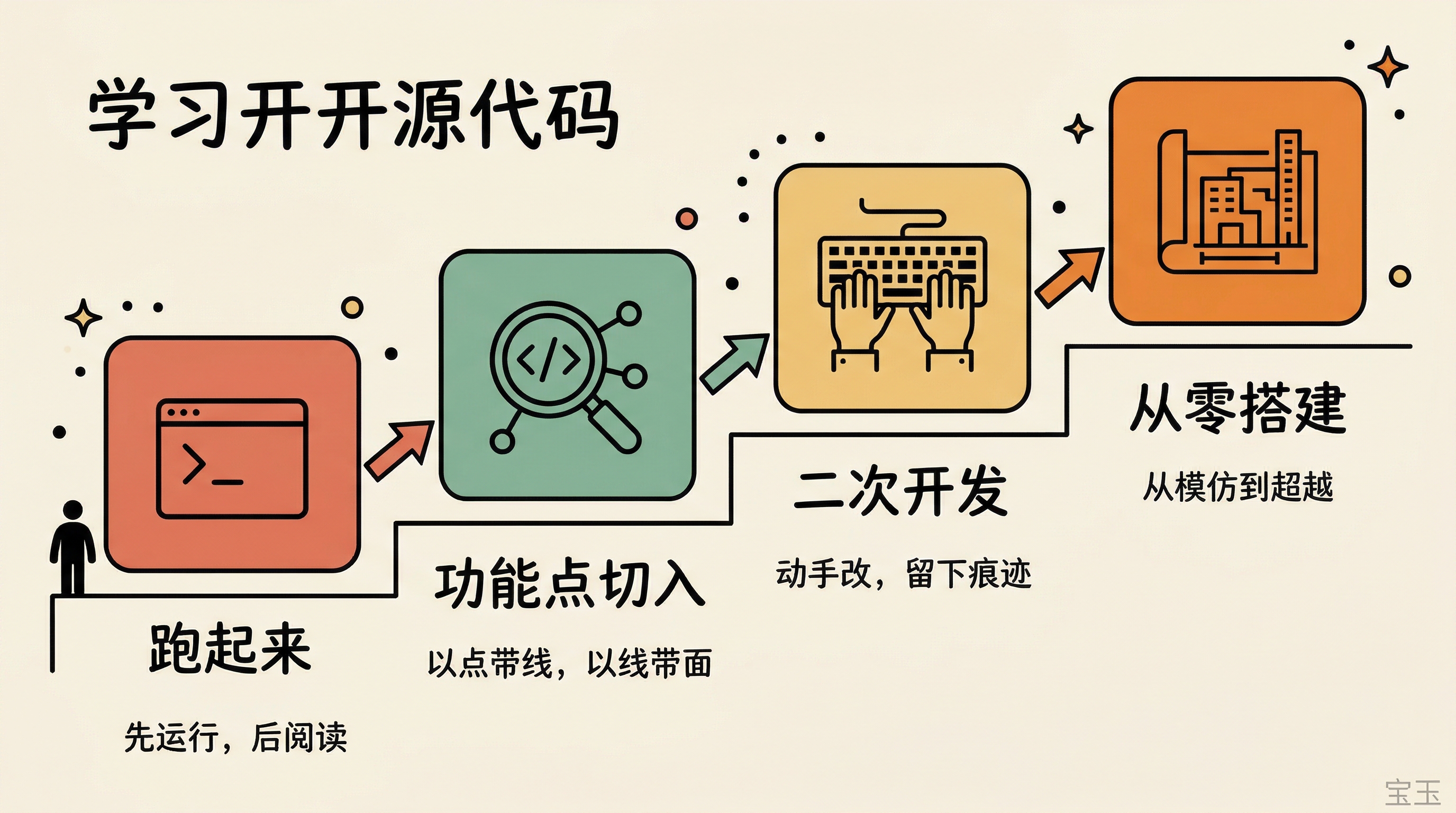
第一步:先跑起来
拿到源码之后,大部分人的第一反应是打开文件开始读。
别急。先跑起来。
这次泄漏的 Claude Code 代码是 source map 还原后的结果,缺了很多脚手架和私有 package,没法直接运行。我本来打算自己折腾一下,结果发现已经有人搞定了(https://github.com/claude-code-best/claude-code),直接用就好。
注:这个项目作者我不认识,只是我可以正常下载运行,所以推荐,后续项目如何发展我并不清楚,而且被下架的可能性很大。有兴趣的可以尽早把代码下载到本地,并让 AI 分析一下代码有无安全问题后再运行。
为什么一定要跑起来?两个原因。
一是你能直观看到运行结果。代码是死的,运行起来才是活的。 你读代码时觉得“这个函数大概是做这个的”,跑一遍就知道你猜对了没有。
二是你可以打日志、设断点。后面分析具体功能的时候,这是核心手段。光用眼睛在几万行代码里找逻辑,跟大海捞针差不多。跑起来之后加个 console.log,代码自己会告诉你它在干什么。
第二步:以点带线,以线带面
项目跑起来了,下一步很多人会犯一个错误:试图从入口文件开始,把整个项目从头读到尾。
几万行代码,这么读下去三天就放弃了。
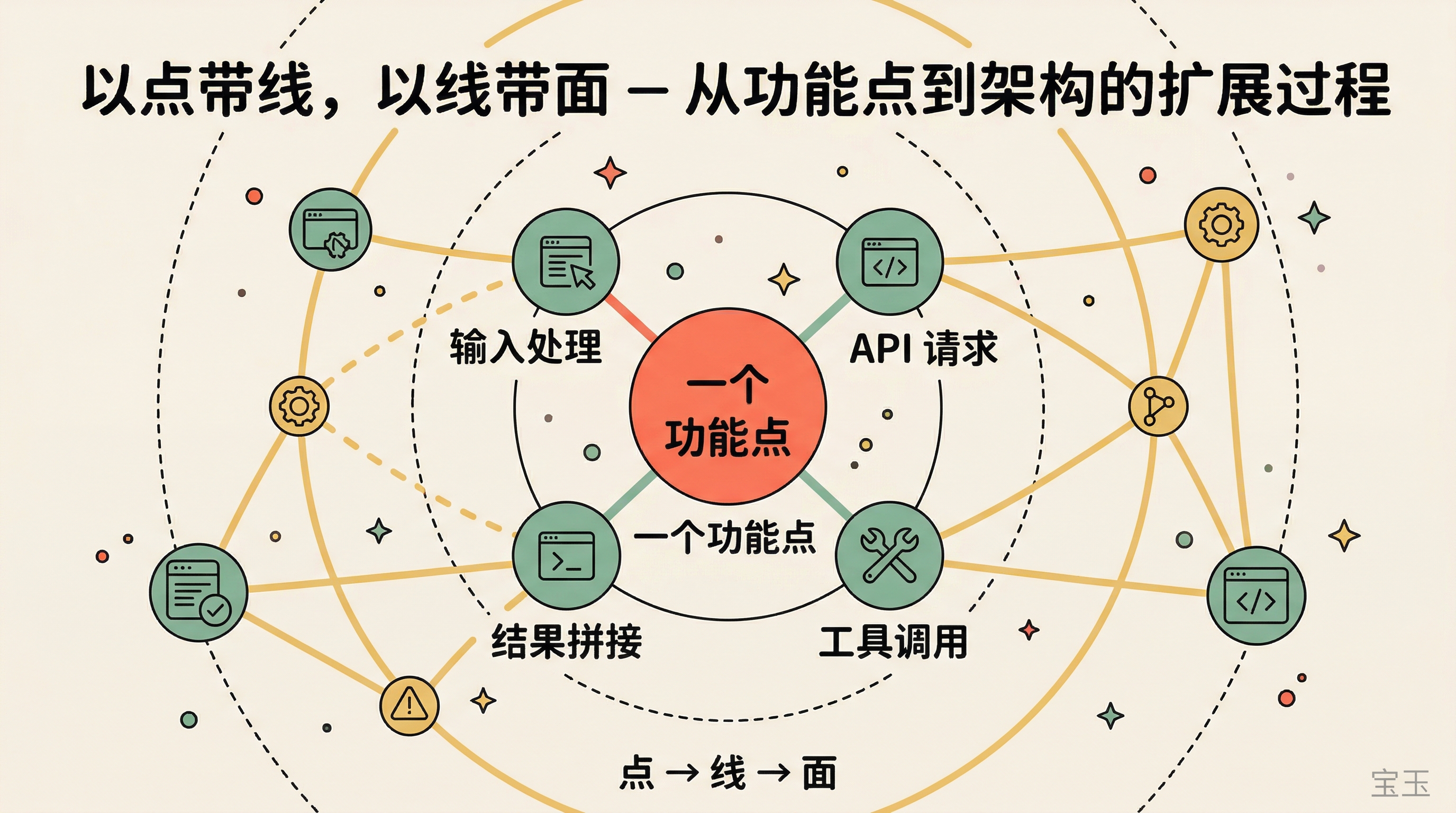
更好的做法是从一个具体的功能点入手。
比如你对 Agent Loop 感兴趣。那就打印或者收集所有的 API 请求,看它发给模型的 Prompt 长什么样,模型返回了什么,Claude Code 拿到返回之后又做了什么。一轮对话下来,你对“一个 Agent 怎么拆解任务、怎么调用工具”就有了直观的认识。
以前我用 claude-trace 做过类似的事情,可惜后来用不了了。现在有源码了,自己加日志能做得更细。
当你搞清楚一个功能点之后,自然会接触到它经过的模块:输入怎么进来的,经过了哪些处理,工具调用怎么触发的,结果怎么拼回去的。模块之间的关系,就这样一个一个串起来了。
别贪多。搞透一个功能点,比走马观花看十个模块有用得多。
第三步:动手改,在代码上留下你的痕迹
光看代码,学到的东西很容易变成“感觉自己懂了”。一动手就原形毕露。
但从零写一个也没必要。对于一个已经成熟的项目,最好的练手方式是二次开发。
举个例子,Claude Code 刚发布了一个 /buddy 命令,会给你养一只小宠物。你可以试着自己实现一个类似的斜杠命令,或者给它加点新花样。再比如 Claude Code 的记忆功能,你可以研究它是怎么存储和读取记忆的,然后试着自己实现一套记忆机制。它的架构已经相对稳定了,你只需要在现有框架里填充逻辑,入门门槛其实不高。
做二次开发的时候,尽量别用 AI 辅助。
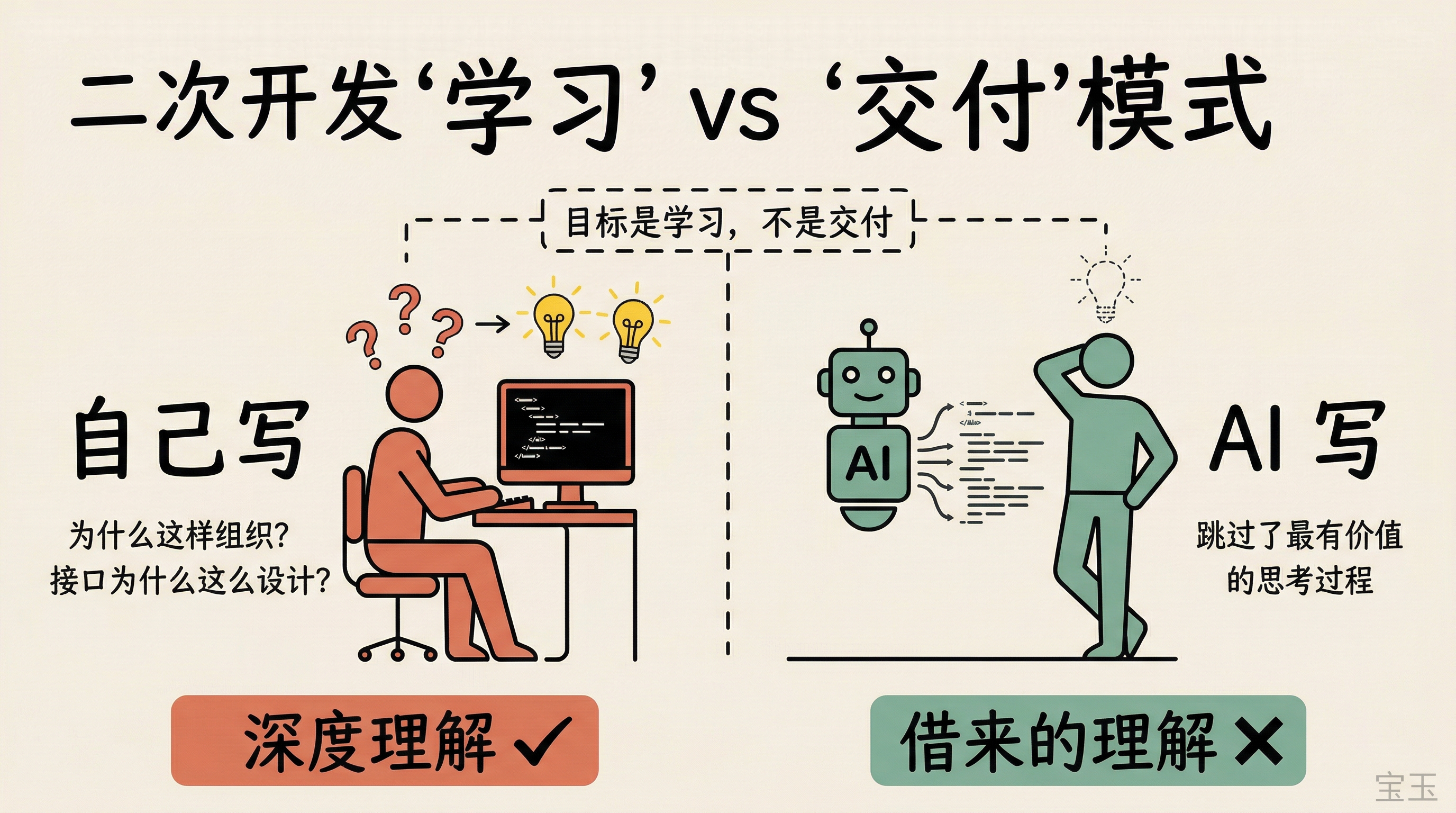
我知道这听起来很反直觉。用 AI 写代码效率高这么多,为什么不用?因为目的不一样。你的目标是学习,不是交付。让 AI 帮你写了,你跳过的正好是最有价值的思考过程:为什么要这样组织代码?这个模块为什么放在这里?接口为什么这么设计?
当你能从头到尾靠自己把一个功能开发出来,你对这个项目的理解就从“看过”变成了“做过”。
多做几个功能之后,你会越来越熟悉它的整个架构,甚至开始觉得有些地方可以做得更好。
这就对了。
第四步:从模仿到超越
通过二次开发你熟悉了项目架构,知道它“是什么样的”。但有一个问题一直留着:当初为什么要这么设计?
架构决策的背后往往有很多你看不到的东西:历史包袱、团队规模、时间压力、当时的技术限制。你站在结果面前,看到的是“选择了 A”,但看不到“为什么没选 B 和 C”。
想搞清楚这些,最好的办法是自己从零搭一个。
不需要功能完整,不需要面面俱到。按照你自己的想法,参考原来的架构,重新做一遍设计决策。你会发现那些你以为“显然应该这样做”的地方,一动手就出问题了。然后你就理解了原作者为什么那样选。
这一步是最难的,但也是收获最大的。
走到这一步,你已经不只是“读懂了”这个项目,而是有能力做出自己的架构方案了。
最后
这四步说起来简单:跑起来 → 从一个功能点切入 → 二次开发 → 从零搭建。但我观察到一个有意思的现象:大多数人卡在第一步和第三步之间,也就是“看了很多,但没动手写过”。
AI 时代更容易出现这个问题。让 AI 帮你分析代码太方便了,几秒钟就给你一份“架构全景图”。但这种理解是借来的,经不起追问。
你用过什么方法学开源代码?有没有哪个项目是你真正“啃”下来的?
附:聊几句这次 Claude Code 代码泄漏本身
泄漏代码的价值,有限。
有人从泄漏的代码里逆向了 Claude Code 的相关逻辑,做出了开源的 SDK。思路挺好,但这份代码是静态的,Claude Code 一更新你就跟不上了。拿来学习可以,拿来做产品基础不太现实。
对行业的影响也没有一些人渲染得那么大。普通开发者用不着看这些,大厂该逆向的早就逆向了。真正受益的是一小部分有兴趣深入研究的开发者和小团队,从里面确实能学到一些有价值的技术细节。
有人问既然都泄漏了,Anthropic 为什么不干脆开源? 我觉得不可能。闭源的好处太多了:
代码质量不用太讲究。一个 React 文件写了几千行,闭源没人知道,开源出来会被喷死。
可以暗搓搓加料。防蒸馏的逻辑、用户标识的记录,甚至“不小心”导致第三方 prompt caching 失效的 bug,闭源不用担心被抓包。
可以控制发布节奏。这次就发现了不少隐藏功能,比如 /buddy 早就开发好了,就等愚人节开启。开源的话这种惊喜就藏不住了。
快速迭代不用走复杂的代码审查流程,开源的顾忌多得多。
有一件事值得一提。 Anthropic 正面回应了这次泄漏,Boris 说得很好:
工作中,犯错总是在所难免。但作为一个团队,最重要的是要达成一种共识:出了问题绝不该怪罪到某个人头上。真正的“罪魁祸首”往往是我们的流程设计、团队文化,或者是底层的基础设施。
这次的问题出在一个本该自动化、却还是人工手动操作的部署环节上。没有怪到个人头上,也没有因此开除谁。那些号称“刚加入 Anthropic 搞出这事被开除了”的都是蹭热度的营销号,别信。
直面问题,改进流程。这才是一个工程团队该有的样子。