DeepSeek 的 10 万亿美元大战略

DeepSeek 的 10 万亿美元宏伟战略
作者:GDP (@bookwormengr)
标题:DeepSeek's 10 trillion USD grand strategy
你有没有想过,DeepSeek 到底打算怎么赚钱,而且是赚大钱?
他们没有像智谱(GLM)、月之暗面(MoonShot)和 MiniMax 那样推出有竞争力的编程订阅计划。他们没有多模态、语音或视频模型。时至今日,他们甚至连一个评测框架(Harness,用于测试和评估模型性能的基准测试工具)都没有(虽然最近听说他们开始招人做了)。而且,DeepSeek 还长期致力于开源,乐此不疲地分享自己的“独家秘方”。这难道是疯了吗?还是纯粹在烧钱?那些正准备给他们投资 100 亿美元的投资人们,难道是在把钱往水里扔吗?
不,在我看来,恰恰相反!!!
在这里,我想聊聊我对他们至今所作所为的观察,以及他们似乎正在践行的战略。DeepSeek 创始人梁文锋的眼光显然盯着一个大得多的终极奖杯——他们不仅自己能冲击 1 万亿美元的市值,还能顺便帮中国催生出一个高达 10 万亿美元的产业巨兽!

重新审视 DeepSeek 的“英雄之旅”
DeepSeek 总是逆风而行,他们不屑于去卷那种“比别人好一点点”的微调模型,也不急着去卖当下的应用(比如各种编程套餐)。我在 2025 年 1 月 27 日发过一条疯传的推文,谈到了我所看到的景象,而现在的剧情正变得越来越精彩。
-
当大家都在死磕稠密模型(Dense Models,所有参数都参与计算的传统大模型结构)时,DeepSeek 却迎难而上,选择了极难训练的混合专家模型(MoE, Mixture of Experts)。
-
他们从“第一性原理”(First Principles)出发,发明了全新的 GRPO 算法,取代了在强化学习(RL, Reinforcement Learning)中虽然占据统治地位、但实现成本极高的 PPO 算法。
-
他们摸索出了基于验证奖励的强化学习(RLVR, Reinforcement Learning from Verified Rewards),并将其作为提升模型推理能力的杀手锏。
-
他们通过“多 Token 预测”(MTP, Multi-Token Prediction)提出了一种绝妙的投机解码(Speculative Decoding,一种通过预判后续单词来加速大模型生成速度的技术)策略,同时还让训练信号变得更加密集。
-
他们完美打造了“零气泡”(Zero-Bubble)流水线并行技术,把有限的 GPU 资源压榨到了极致。
-
他们开源了专家负载均衡器(Expert Load Balancer),让所有人都能轻松部署混合专家模型。特别是通过“宽专家并行”(Wide Expert Parallel)策略,模型可以在大批次下运行,使得服务成本大幅降低。
-
他们发明了 MLA、DSA、CSA 和 HCA 等一系列魔改注意力机制的技术,极大地缩减了 KV 缓存(KV Cache,大模型推理时用于存储历史对话记忆的显存空间)的需求,让计算需求在面对无限拉长的上下文时几乎保持恒定。
-
他们发明了 Engram(印迹模块),实现了用内存换算力的神奇操作。
-
他们发明了 mHC(修正超连接),解决了模型体量暴增时的训练稳定性难题。这个创新清单还能一直列下去……
在英雄之旅这个最经典的叙事结构里,主角一开始并不知道自己的终极使命是什么。他是在一路上摸爬滚打,逐渐领悟了伟大的天命,然后排除万难去完成它。在这个过程中,他会遇到无数的冷嘲热讽,但他选择无视;他会遇到不怀好意的对手;他本身也有致命的弱点或短板——但他最终战胜了自我,达成了使命。他直面那些看似无法逾越的难关,却总能巧妙地结盟、精明地整合宝贵的资源。这就是为什么观众会不自觉地为英雄摇旗呐喊。这也是为什么 DeepSeek 在赢得全球无数粉丝狂热追捧和尊敬的同时,也招来了不少争议。
接下来我将为你详细拆解,DeepSeek 在这条路上已经走得足够远,并且已经窥见了他们的终极宿命:他们的格局根本不是卖什么编程订阅,而是去撬动一个价值 10 万亿美元的中国 AI 硬件生态圈,并以此顺理成章地让自己斩获 1 万亿美元的市值。在这个过程中,他们甚至还会顺手帮一把西方硬件生态中的一众新玩家。
欢迎大家探讨与指正。

先来算一笔好玩的 KV 缓存账:
来看看知名半导体分析机构 @SemiAnalysis_ 发布的这条非常及时的推文:

我们先来做点有趣的 KV 缓存数学题。别担心,如果你讨厌数学,我们也只是用最近发布的 KV 缓存计算器,来看看 DeepSeek V4 Pro 到底能省下多少 KV 缓存,并把它跟最新的智谱 GLM 和阿里通义千问(Qwen)模型做个对比。
我以 100 万(1M)上下文长度为例进行计算,假设 KV 精度为 8 位(8-bit),索引器精度为 16 位(16-bit)。你自己也可以去这个网站上玩玩:
https://kvcache.ai/tools/kv-cache-calculator/
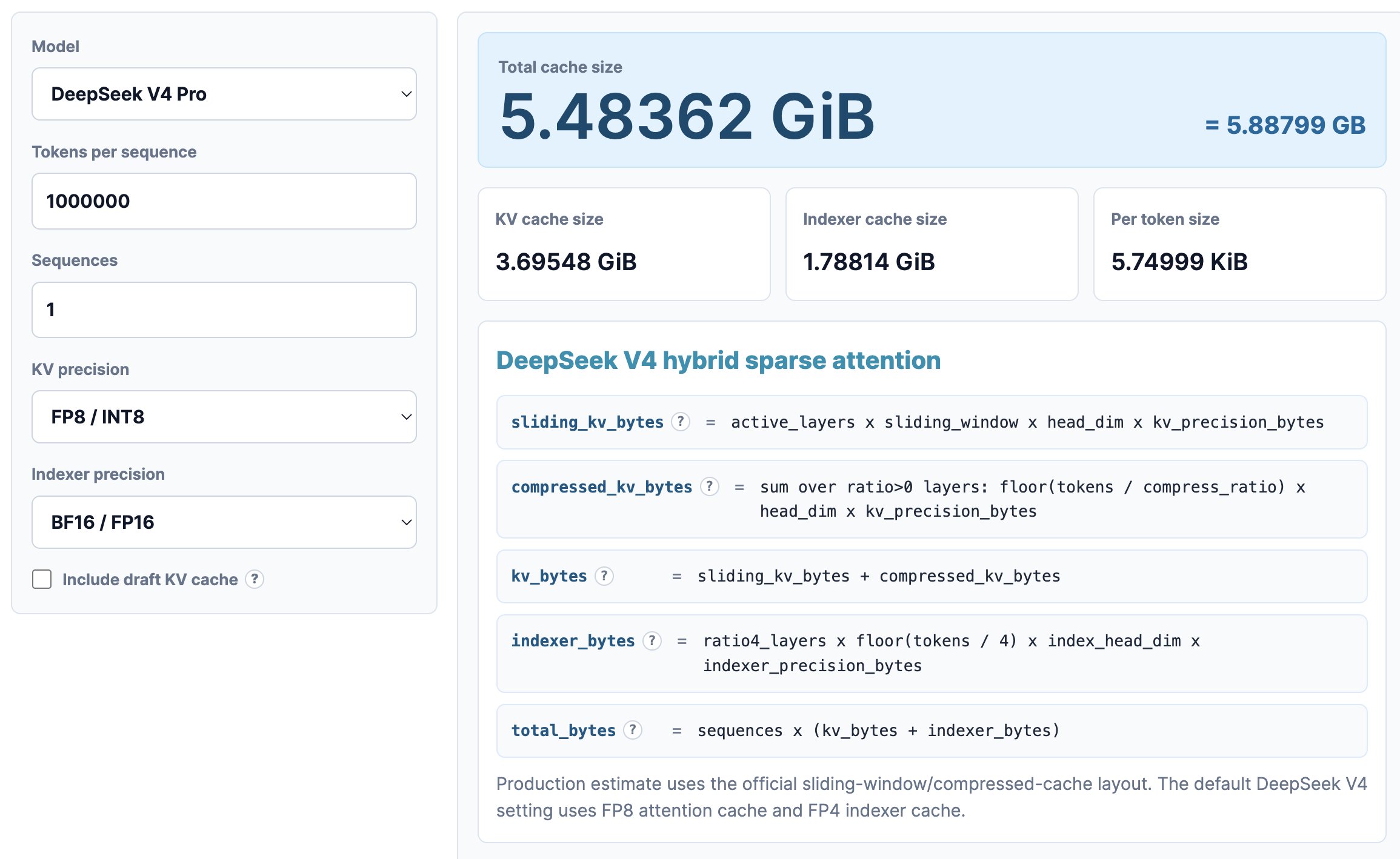
在 100 万上下文深度下:
-
DeepSeek V4 居然只需要 5.48 GB 的高带宽内存(HBM, High Bandwidth Memory,一种常用于顶尖 AI 显卡的高速显存)。
-
GLM5 需要 60 GB 的 HBM。
-
Qwen3-235B-A22B 则需要高达 89 GB 的显存!
请注意,这还是在以下前提下:
-
DeepSeek 是一个拥有 1.6 万亿(1.6T)参数的巨无霸模型。
-
GLM5 大约是 7000 亿(700B)参数,而且它已经借鉴了 DeepSeek 的 MLA 和 DSA 技术,只是还没用上最新的压缩注意力机制。
-
Qwen3-235B-A22B 只有 2350 亿参数,使用的是相对传统的 GQA(分组查询注意力机制)。
DeepSeek 在缓解显存压力方面做出了奠基性的贡献。如果这项创新被行业广泛采纳,将让那些需要处理超长任务的长程 AI 智能体(Long-horizon Agents)成本低到难以置信,从而彻底解锁下一代崭新的应用场景。
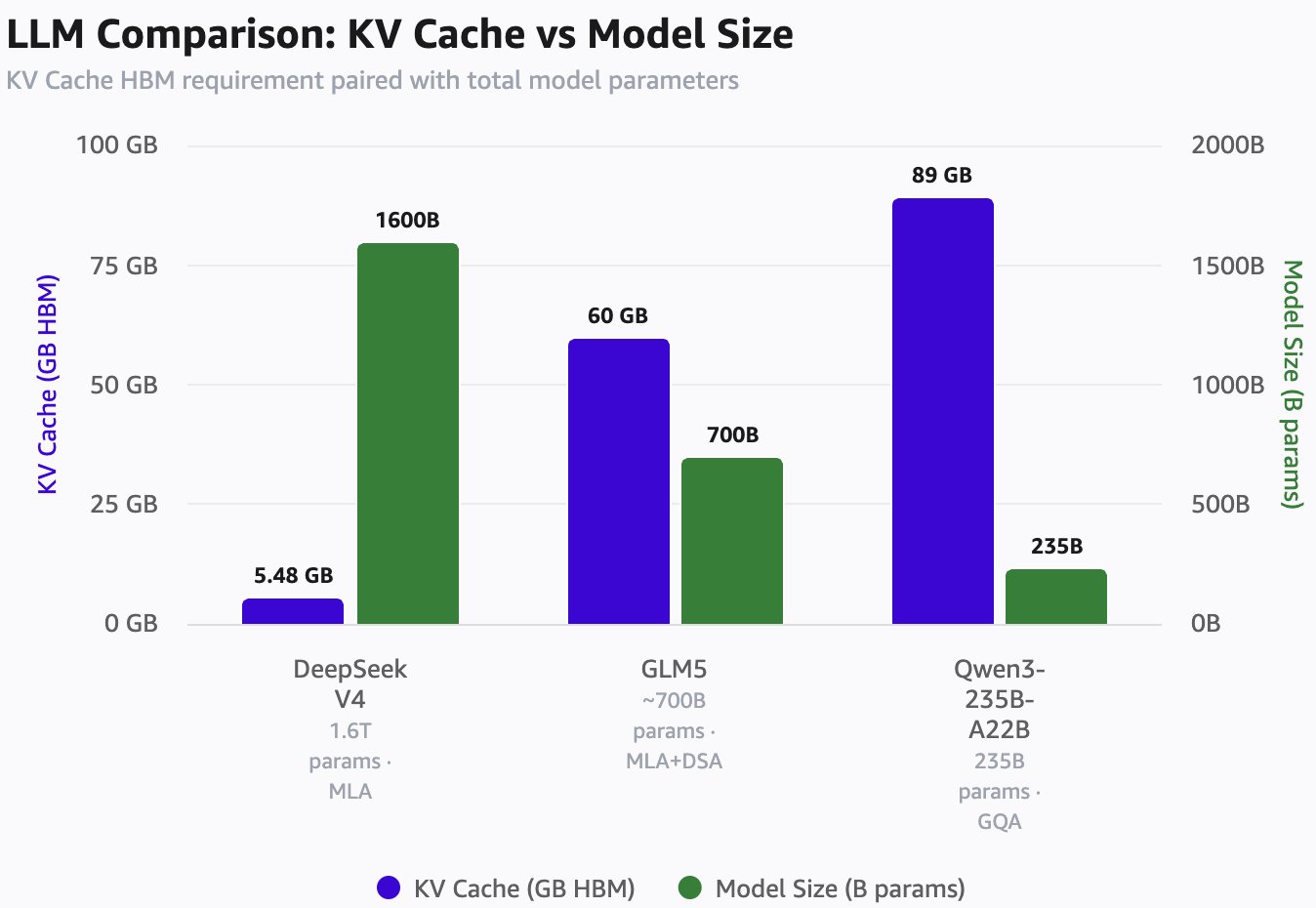
疯狂背后的精密章法:
能够在完全不牺牲模型质量的前提下,把 KV 缓存压缩得如此之小,正是他们敢把长时缓存(Long-held Cache)价格压到白菜价的底气所在——其价格甚至不到 Anthropic 旗下 Claude Sonnet 4.6 缓存命中价格的 3%,而且他们还能帮你免费保留好几个小时!
对于长程任务来说,由于缓存体量极小,将其“转存”(Offloading)到固态硬盘(SSD)并在需要时重新加载,就变得极为划算。这就大大降低了对 HBM 的依赖。要知道,HBM 目前全球严重短缺,而且从中国 AI 硬件产业的角度来看,这也是制造难度极高的核心痛点。更绝的是,DeepSeek 还开发了一套能从 SSD 中以极高速度重新加载 KV 缓存的技术,具体细节都在他们的论文里:https://arxiv.org/pdf/2602.21548
谁是这场“KV 缓存压缩战”的直接受益者?
谁在大量供应 SSD?别忘了长江存储(YMTC)正在崛起为全球 3D NAND 闪存巨头。闪存技术(NAND)让 DeepSeek 能够直接读取缓存,从而避免了每次都重新计算 KV 的巨大算力浪费。反过来,DeepSeek 正在为 NAND 闪存和固态硬盘创造一个无比庞大的新市场——这不仅让长江存储受益,也让整个产业链所有玩家跟着大赚。

然而,格局绝不仅仅局限于 NAND 和 SSD:
低功耗内存(LPDDR)同样蕴藏着巨大的潜力,可以用作存放模型权重(Weights)的“大后方”,并在需要时源源不断地“流式传输”到 HBM 中,从而进一步减轻 HBM 的容量压力。你可以参考这篇博客:https://www.lmsys.org/blog/2025-09-25-gb200-part-2/ 。下面我用一张图来解释这套方案是如何运作的:
虽然 DeepSeek 并没有专门针对这一方案做特殊开发,但他们那拥有庞大专家数量、并且支持 4 位(4-bit)权重的混合专家模型架构,完美契合了这套方案,使得其实施起来易如反掌。
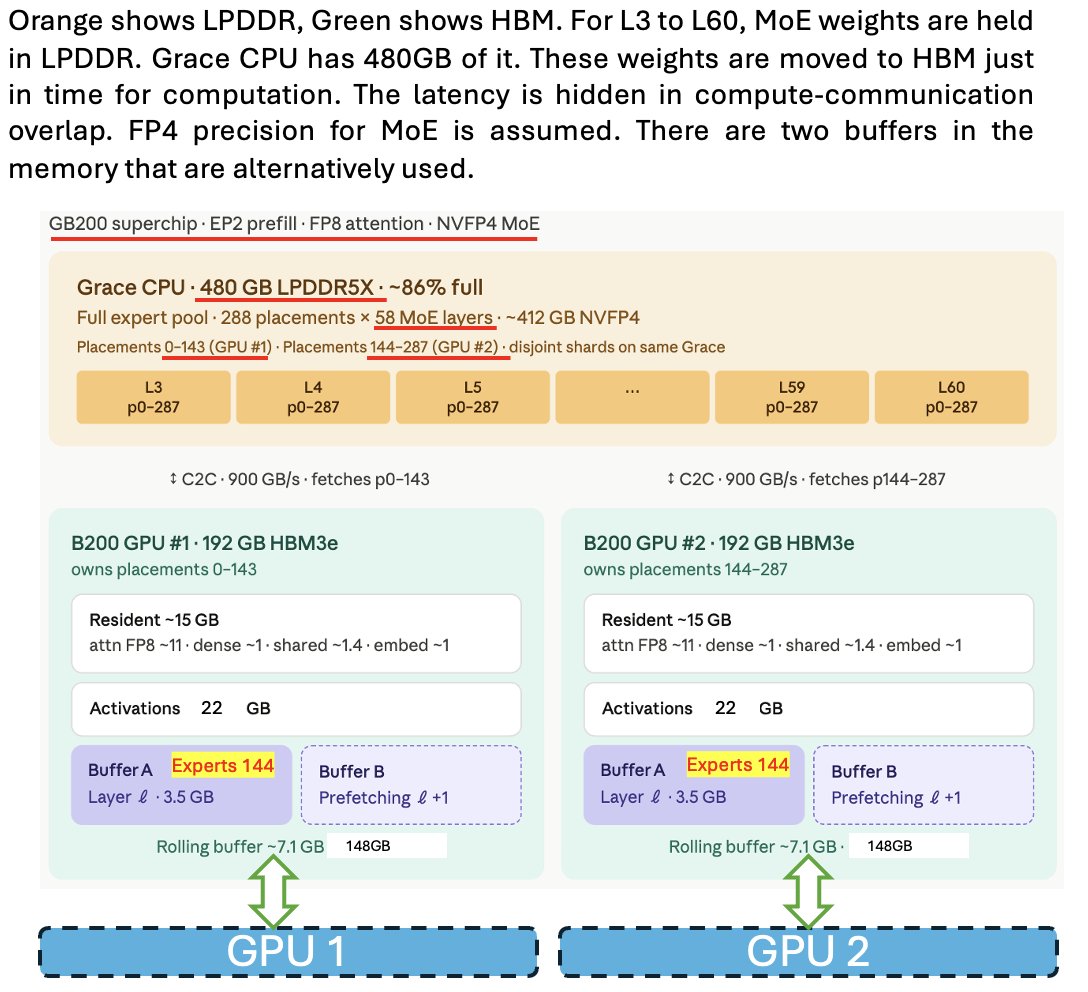
这种创新配合上他们那堪称逆天的无损超紧凑 KV 缓存技术,让系统对 HBM 的吞吐和容量需求出现了断崖式下跌。
中国谁在做 LPDDR?长鑫存储(CXMT)。目前他们在 LPDDR 的速度上仅落后国际顶尖水平半代,在容量密度上仅落后一代。差距非常小!这意味着在不久的将来,除了管够的 NAND 闪存,中国本土生态还将迎来铺天盖地的 LPDDR 内存。那这能缓解算力芯片的压力吗?答案是:绝对能。请接着往下看……

聪明地玩转存储,还能顺手给 GPU 和 ASIC 减负
道理很容易理解:用 NAND 闪存来存放 KV 缓存,不仅能延长缓存的保存时间、减轻 HBM 的压力,还能免去重复计算的烦恼,这等于变相给 GPU 和 ASIC(专用集成电路,即各类定制化 AI 算力芯片)的计算单元松了绑。那么,除了作为模型权重的“即时流式传送带”之外,LPDDR 还能以其他方式帮上忙吗?答案同样是:可以。
LPDDR 可以用来存储海量的“Engram”(印迹模块)。DeepSeek 在他们的论文(https://arxiv.org/pdf/2601.07372)中指出,虽然混合专家模型架构可以通过条件计算(Conditional Computation)来扩充模型的容量,但传统的 Transformer 架构缺乏一种天然的知识检索机制,只能笨拙地通过高昂的“计算”去模拟“检索”。为此,他们引入了 Engram 模块,将经典的 N-gram 嵌入技术升级为基于哈希、时间复杂度为 $O(1)$ 的瞬间查找,创造了一个他们称之为“条件内存”(Conditional Memory)的全新稀疏维度。这极大地省下了计算量,但代价是需要巨大的内存空间来存放这个庞大的嵌入表。这是一次经典的“用空间(存储)换时间(计算)”,其高明之处在于,读取“存储”的成本远比进行计算要便宜得多(在 LPDDR 里查一下,可比让大模型整整跑一轮前向传播省钱太多了)。在大规模部署时,这是一笔划算到家了的买卖。这就是他们如何通过狂砸内存来省下算力的秘密!!!
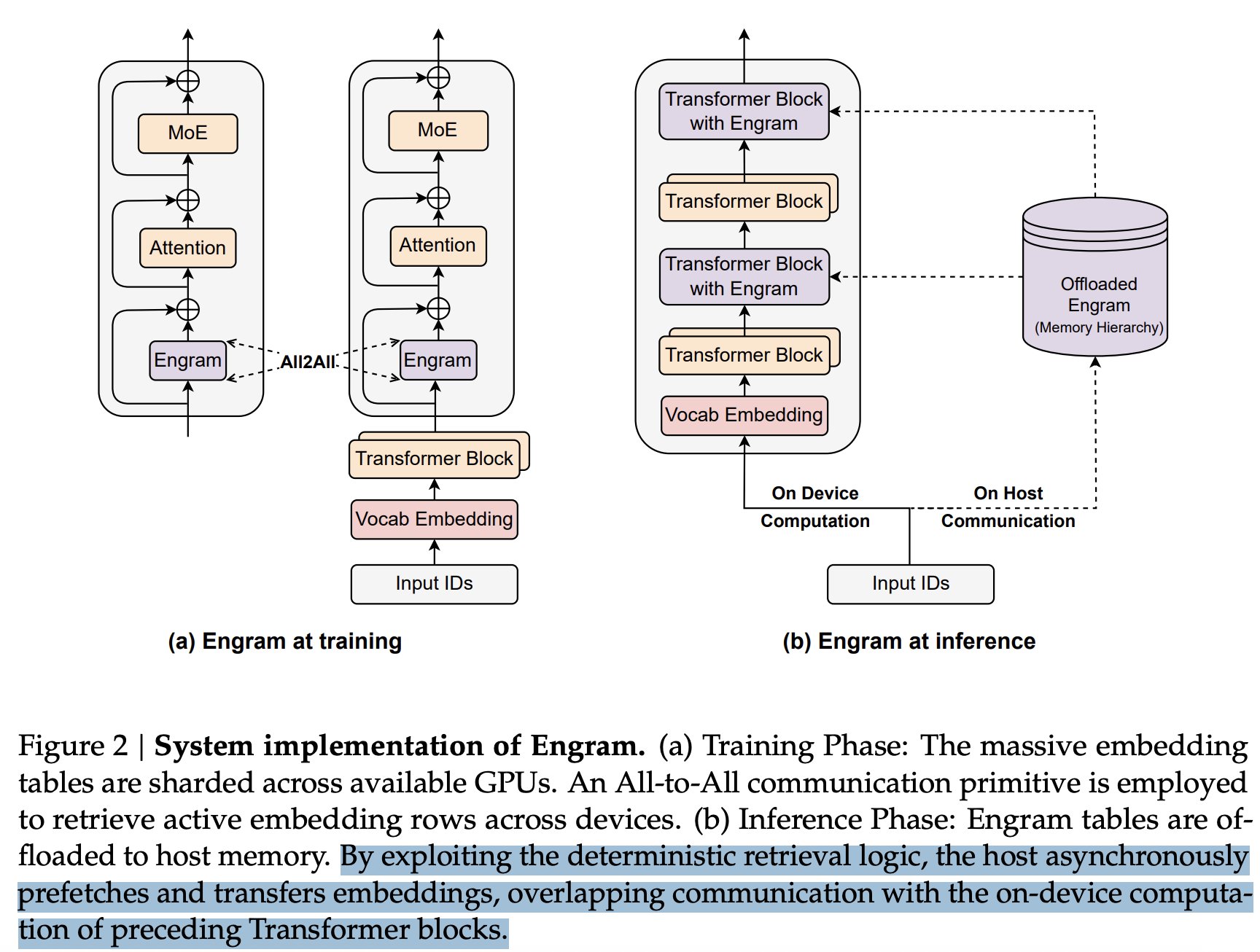
这种取舍简直太值了:由于缺乏极紫外光刻机(EUV),无法在单个芯粒(Chiplet)上做到同等的晶体管密度,中国的 GPU 和 ASIC 在纯粹的原始浮点运算能力(FLOPs)上,注定会长期落后于西方顶尖显卡。同时,国内在先进封装技术上也处于追赶状态。因此,如果能利用国内产能充足、成本低廉的 NAND 和 LPDDR 内存来弥补算力的劣势,这种“扬长避短”的打法简直是绝配。
盘点 DeepSeek 的一盘大棋:
纵观这些令人眼花缭乱的创新和他们做出的种种抉择(至今不做多模态、不做语音模型,至于视频生成?那是什么东西?),DeepSeek 的野心显然不是眼前那区区几亿美元的蝇头小利。他们正在极有耐心地下一盘 10 万亿美元的大棋,目的是亲手扶持起一套独立于西方之外的“备选硬件生态”。
这不仅让中国的存储芯片厂商在全球 AI 硬件舞台上跃升为主力军,更从根本上降低了大模型训练和推理的资源门槛。当运行 AI 模型的成本降下来后,原本性能稍逊的国产 GPU/ASIC 芯片以及网络交换芯片也将全部变成“够用、好用”的切实选项。而且,这些开源创新也将反哺西方的开源社区,并给西方那些试图挑战英伟达的芯片初创企业带来一线生机。
所有的蛛丝马迹都对上了。让我们来逐一细数他们抛出的那些震撼行业的创新:
- 在 DeepSeek V2 中引入混合专家模型(MoE)和 MLA:MoE 让训练一个极度聪明的模型减少了 40% 到 50% 的算力消耗;而多头潜在注意力机制(MLA, Multi-head Latent Attention)更是把 KV 缓存直接砍掉了 90%,使得将缓存转存到 SSD 变得极为高效。这些理念最早在他们 2024 年 5 月的论文(https://arxiv.org/pdf/2405.04434)中提出。正是凭借这些绝活,他们后来才能仅仅用 2048 张被阉割过的 H800 GPU,就硬生生训练出了媲美顶级闭源模型的 DeepSeek V3。
- DSA(密集跳跃注意力机制):在论文(https://arxiv.org/pdf/2512.02556)中推出,旨在削减长上下文场景下的计算量,同时缓解 HBM 的带宽压力。它确保了计算量不会随着上下文的拉长而发生爆炸式增长。看看下面的图表——DeepSeek-v3.2 的处理时间在上下文拉长时依然稳如泰山。
- mHC(修正超连接):在 2025 年 12 月的论文(https://arxiv.org/pdf/2512.24880)中首次亮相。mHC 是 DeepSeek 在宏观架构上的一大创新,它彻底颠覆了大模型各层之间传统的信号传输方式。过去大家都在用自 ResNet 时代流传下来的标准残差连接($x + F(x)$),而 mHC 则把这条残差流扩展成了多条并行的“信息高速公路”,并允许模型自主学习如何进行混合。最为关键的是,它通过数学手段(将混合矩阵通过 Sinkhorn-Knopp 投影约束在 Birkhoff 多胞形上)强制让这些混合矩阵满足双随机性,从而在数学上完美确保了信号强度在穿过任意深度的网络层时都不会衰减。
-
这彻底解决了此前困扰无约束超连接(Hyper-Connections,最早由字节跳动发明)的灾难性不稳定难题——此前在 270 亿(27B)参数规模下,信号放大系数会疯狂飙升到 3000 倍,导致整个训练彻底崩盘。
-
而它的计算成本却微乎其微:由于它完全没有改变注意力层或前馈网络(FFN, Feed-Forward Network)层的原始浮点运算量,仅仅改变了输出在各层之间的路由方式,因此它只增加了区区 6.7% 的实际训练时间开销。
-
然而它带来的性能提升却极为震撼:在同等模型大小和几乎完全相同的算力预算下,27B 规模的模型在 mHC 的加持下,在复杂的 BIG-Bench Hard 推理测试中暴涨了 7.2 分,DROP 评测提升 3.2 分,GSM8K 数学测试提升 2.8 分,MMLU 综合学科知识提升 1.4 分。
简而言之,mHC 通过给网络赋予一套更丰富、更有表现力的跨层信息路由拓扑结构,在几乎不需要额外多花一丁点算力的情况下,让单位参数发挥出了显著更高的“智商”。
- CSA 与 HSA:在 2026 年 4 月发布的 DeepSeek V4 Pro 技术文档(https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf)中亮相。它们通过对 KV Token 进行深度压缩,把本来就已经很小的 KV 缓存需求又砍掉了 90%!同时大幅降低了所需的浮点运算量,一举帮 HBM 和 GPU/ASIC 彻底解套。
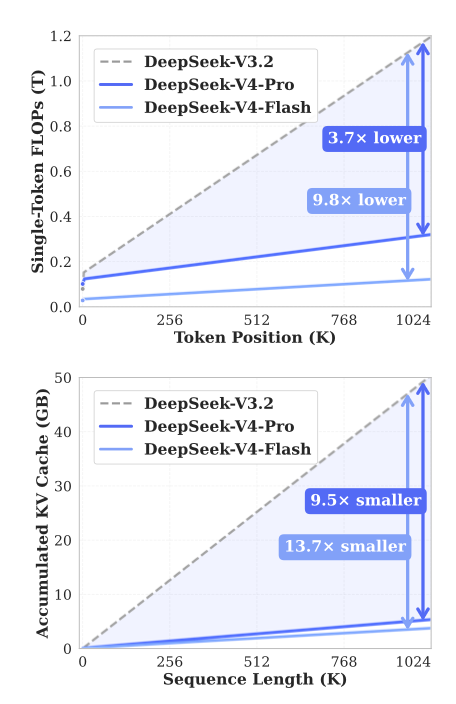
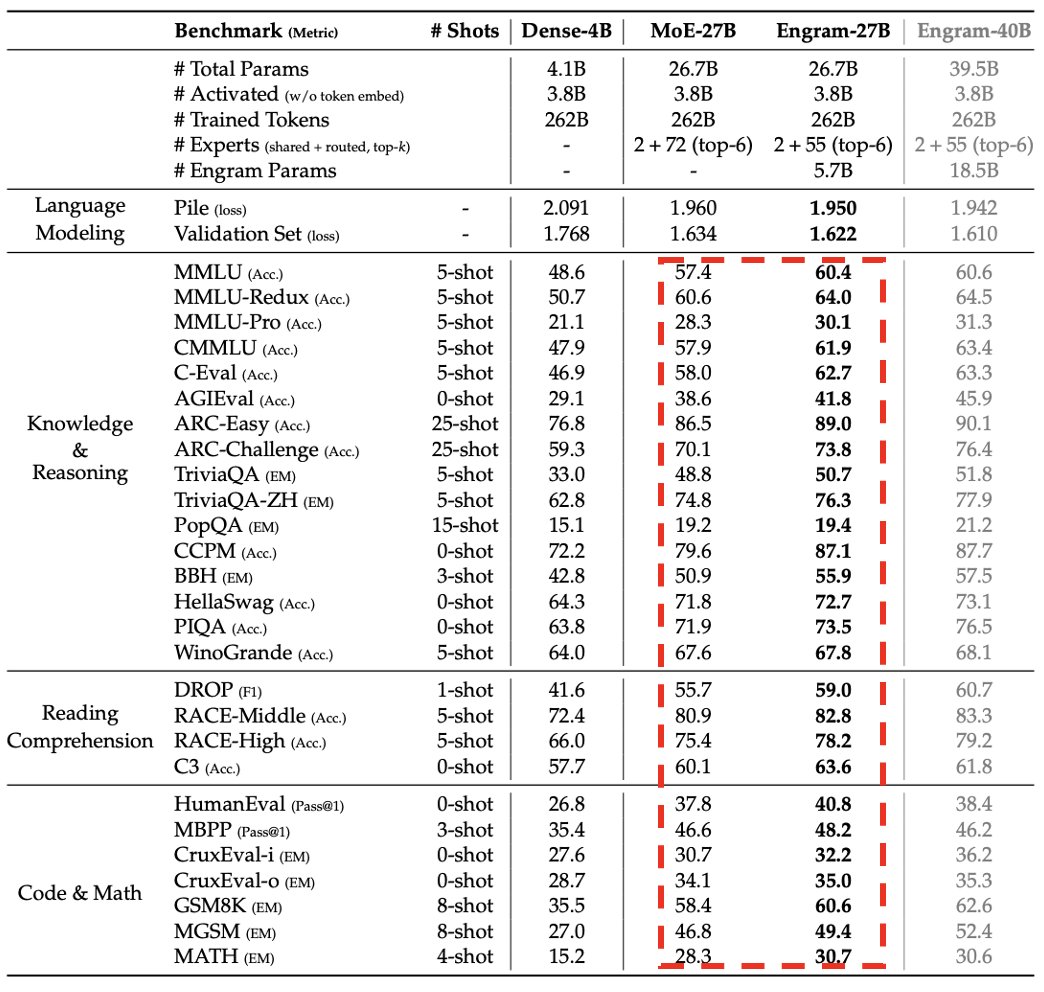
- 论文(https://arxiv.org/pdf/2601.07372)于 2026 年第一季度推出,正如前面所说,它在某种意义上实现了“用内存(LPDDR)换算力”。下面的详细图表展示了在总体参数预算完全一致的情况下,Engram 带来的巨大性能跃升。
- 将计算与通信的重叠压榨到极致:诸如“双路径”(Dual Path)这样的底层魔改,表面上看是为了绕过硬件资源的封锁而被迫进行的闪转腾挪。但 DeepSeek 更进一步,甚至开始反过来对芯片硬件厂商的 ASIC 架构设计指点迷津,告诉他们如何设计芯片才能避免浪费哪怕一丝一毫宝贵的硅片资源。以下截图正是出自 DeepSeek V4 Pro 的官方文档:

- 对 TileLang 的重度投入:这明确无误地表明,他们的目光早已超越了自家算力紧缺的困境,而是致力于让整个中国硬件生态具备与西方掰手腕的竞争力。有了 TileLang(一种用于编写高性能算力内核的开源编程语言),工程师只需要编写一次算力内核代码,就能在任何适配了 TileLang 后端的不同硬件平台上无缝跑起来。我预计国内其他 AI 实验室很快也会纷纷加入这个阵营——这将合力帮助中国硬件厂商从侧面解围,绕开英伟达坚不可摧的“CUDA 壁垒”(CUDA Moat,英伟达苦心经营数十年的专用并行计算架构生态,是其最宽的护城河)。同时,这也能顺便解放 AMD 等西方的其他硬件厂商。 注:国内许多 AI 硬件平台本身也提供 CUDA 兼容性或 CUDA 编译转换层。其中,摩尔线程、沐曦、壁仞和天数智芯是通过转换层实现与 CUDA 兼容度最高的几家中国芯片公司,理论上它们不需要 TileLang 的协助。

大规模强化学习与自动化科学研究:
随着计算需求的断崖式下降,以及可供选择的本土硬件变得越来越多,DeepSeek 终于能够放开手脚,去挑战那些此前让人望而却步的宏大训练计划——尤其是强化学习阶段的后训练(Post-training)。强化学习需要生成海量的思考轨迹(Trajectories),动辄就会产生数万亿的 Token,这在过去烧钱速度极其恐怖。此外,要训练出支持 100 万上下文的模型,你就必须生成同样长度的思考轨迹。只有让模型在这种超长轨迹中经受锤炼,才能真正解锁解决复杂长程任务的能力。
不仅如此,硬件选择的多元化将让 DeepSeek 拥有富余的算力去冲击“自动化人工智能研究”(RSI, Research on Silicon Intelligence,即让 AI 充当科学家,自己设计并执行算法实验的自主进化技术)。这种让 AI 左右互搏、自主进化的模式伴随着大量的试错,耗资极度高昂。但如果想要彻底探寻整个算法设计的未知空间,RSI 是必经之路。在通往通用人工智能(AGI)乃至超级人工智能(ASI)的道路上,DeepSeek 必须先点亮 RSI 这颗科技树。
DeepSeek 今日的试金石,行业明天的教科书:
如今,DeepSeek 围绕混合专家模型、MLA、DSA 的一连串疯狂创新,早已被中国乃至全球的各大 AI 实验室奉为圭臬并争相抄作业。
比如,打造了 GLM 系列模型的智谱 AI 已经用上了 MLA 和 DSA;月之暗面(Kimi)也大方承认自家的最新架构正是基于 DeepSeek 的演进。作为礼尚往来,DeepSeek 在大规模训练中也采用了 Muon 优化器,而该优化器在超大规模训练中的威力,正是被 Kimi 团队首先发掘并证明的。
(注:
-
- 混合专家模型(MoE)架构最早由顶尖学者在 2017 年的经典论文(https://arxiv.org/pdf/1701.06538)中提出,而 DeepSeek 的功劳在于成功将其推向了前所未有的庞大规模,并融入了大量自研的独门绝技。*
-
- Muon(基于牛顿 - 舒尔茨动量正交化)优化器由机器学习研究员 Keller Jordan 于 2024 年底发明,而 Kimi 团队则是全球第一个将其应用到超大规模模型训练中的吃螃蟹者。)*
说了这么多,那到底怎么赚大钱呢?
我们可以看看 OpenAI 一个非常有趣的经典案例。OpenAI 曾与 AMD 以及 Cerebras(一家挑战英伟达的晶圆级超大芯片初创公司)达成协议:随着 OpenAI 采购并消耗这两家公司的芯片达到特定里程碑,OpenAI 就能以极低的价格获得这两家公司的股票认股权证(Warrants)或期权。这对于 AMD 和 Cerebras 来说是一笔双赢的绝妙交易——有了 OpenAI 这头吞噬算力的巨兽深度绑定,它们在长跑中胜出的概率大增。
根据 AMD 官方发布的新闻稿(https://www.amd.com/en/newsroom/press-releases/2025-10-6-amd-and-openai-announce-strategic-partnership-to-d.html):“作为协议的一部分,为了深度绑定双方的战略利益,AMD 已向 OpenAI 授予了高达 1.6 亿股 AMD 普通股的认股权证。这些股权将随着特定里程碑的达成而逐步解锁。第一阶段将在初始部署达到 1 吉瓦(GW)算力中心时解锁,随后的份额将随着采购规模扩大至 6 吉瓦而陆续解锁……”

我大胆预测,DeepSeek 目前正在与国内一众存储、ASIC 算力芯片、CPU 以及网络协议栈厂商签署类似的对赌与利益绑定协议。通过深度联合调优,DeepSeek 将帮助这些本土硬件在运行全球最顶尖的 AI 核心工作负载时,真正做到平替、甚至超越西方硬件。
眼下,西方(包括其东亚盟友)所有 AI 概念股的总市值早已突破了 10 万亿美元。通过这种“用技术换股权、用生态扶持分蛋糕”的精妙商业模式,DeepSeek 不仅能在中国复制出一个同样体量惊人的超级硬件产业,还能在其中切下最肥美的一块蛋糕,进而将自己送入 1 万亿美元市值的超级俱乐部。
这不仅能让他们赚到比卖什么订阅软件多得多的真金白银,还能顺便实现他们口中“让通用人工智能惠及每一个人”的宏伟愿景。梁文锋作为传奇量化大师詹姆斯·西蒙斯(Jim Simons)的铁杆粉丝,绝对是一位顶级聪明的资本家,他绝不可能漏掉这盘大棋!
只要你回过头把 DeepSeek 至今为止所有的反常举动串联起来,这就是唯一能完美解释一切的底层逻辑……
关于这些底层技术创新的详细拆解长文将在本周末发布,感兴趣的朋友欢迎关注我的 Substack 专栏:https://polymath707.substack.com/ ...