MCP 和 Skills 到底什么区别?一篇文章说清楚
宝玉

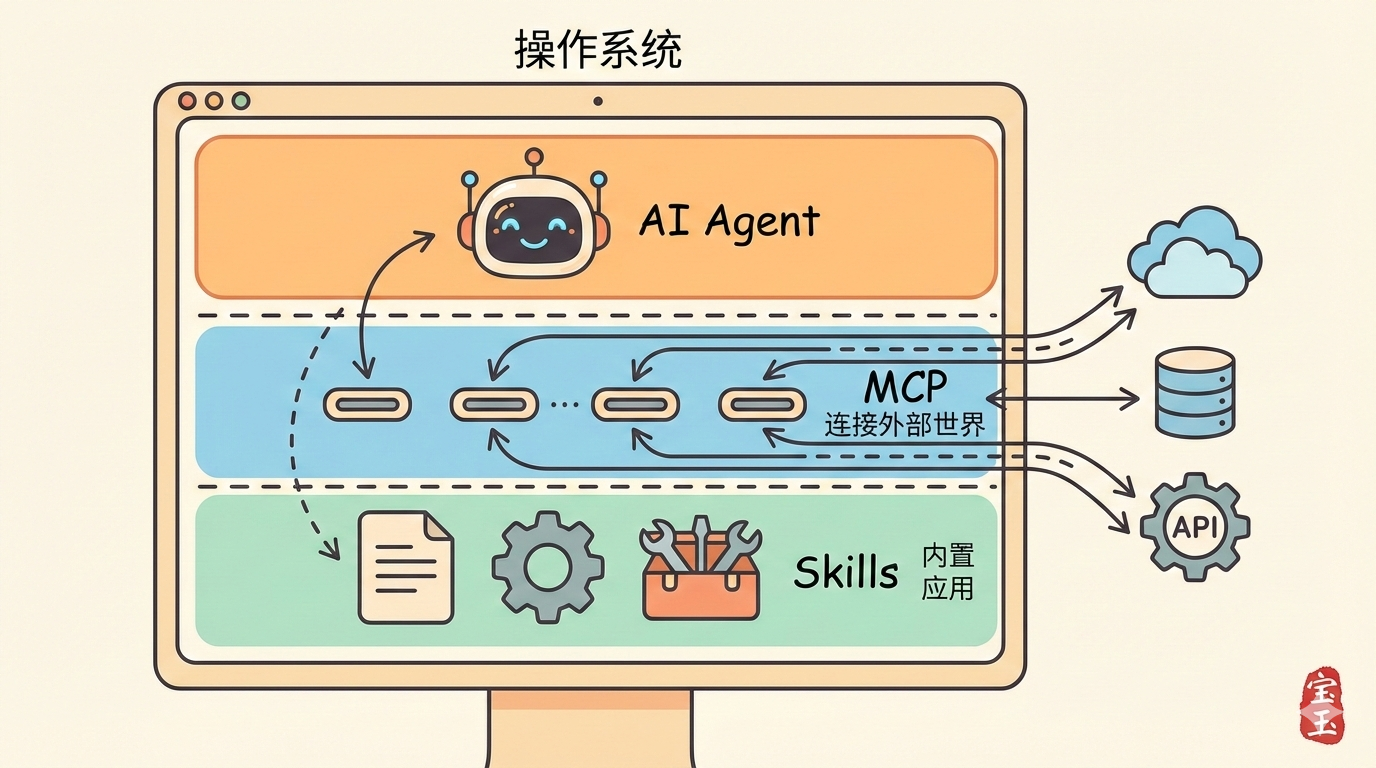
一句话解释 MCP 和 Skills 的区别:如果 AI Agent 是操作系统,MCP 就是 USB 协议,Skills 就是应用程序。
一位开发者的困惑
有位网友私信问我:“MCP 是不是已经过时了?现在应该全用 Skills?”
这个问题可能很多人都好奇。我理解这种焦虑。AI Agent 工具圈每隔两周就会冒出新东西,每次新东西出来,就有人喊旧的“已死”。
对于喜欢 Skills 的人可能会想:我写个脚本自己用,干嘛搞那么复杂?我就是要编码一下我的工作流程,让 AI 能理解我们团队的做事方式,Skills 写起来简单,放个文件就行,何必折腾 MCP Server?
喜欢 MCP 的人则会认为:我要做一个服务,让所有人都能用,不只是我自己,不只是我团队。我要让用户输入一个 URL 就能用,甚至未来什么都不用装,直接问 AI“帮我订机票”就行。
仔细看其实这两拨人的需求完全不一样。不是功能差异,是分发方式的差异。Skills 是给自己人用的,MCP 是给全世界用的。

想象你是一家卖服务的公司。你服务的安装说明怎么写?如果你是以 Skills 的方式发布,说明就要说清楚“把 SKILL.md 文件复制到特定目录”,可能还需要特定脚本的运行权限,用户都不一定敢安装。但如果是“输入这个 URL”或者“直接跟 AI 说帮我用这个服务”,也不需要你在本机安装个 nodejs/python,那就好多了。
但光理解定位还不够。这两个东西在技术层面有本质区别,直接影响你的使用体验和成本。
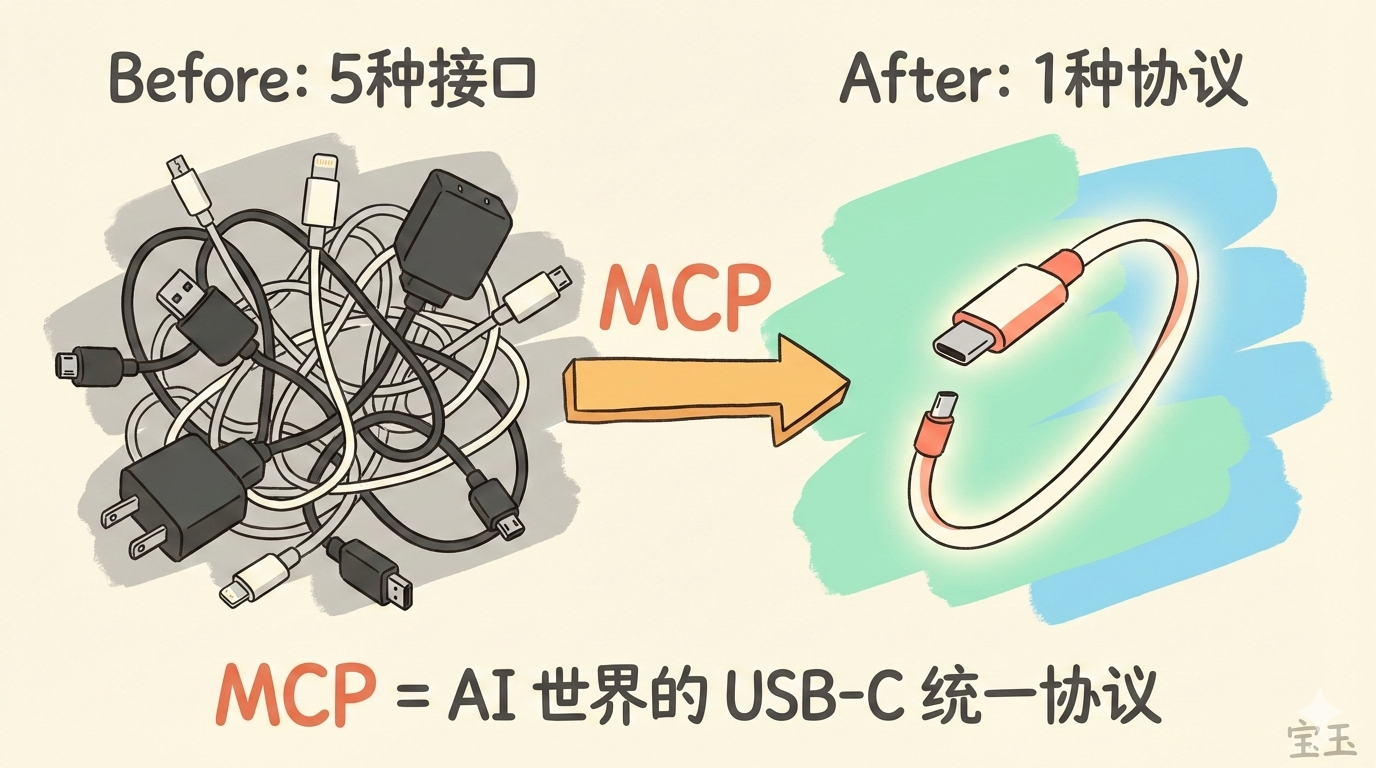
MCP:AI 世界的 USB 协议
还记得十年前的充电线吗?苹果用 Lightning,安卓用 Micro USB,笔记本用各种奇形怪状的电源头。出门一趟,包里塞满五六根线。
AI 行业在 2024 年之前也是这样。
你想让 Agent 读取 GitHub 仓库?写一套对接代码。想让 ChatGPT 查数据库?再写一套。想让 Cursor 发 Slack 消息?又是一套。10 个 AI 应用要连 20 个工具,理论上需要 200 个定制集成。每家都在重复造轮子,开发者苦不堪言。
2024 年 11 月,Anthropic 开源了 MCP(Model Context Protocol,模型上下文协议)。它做的事情,和 USB-C 统一充电接口一模一样:定义一套标准协议,让任何 AI 都能即插即用地连接任何工具。
有了 MCP,10 个 AI 应用 + 20 个工具 = 30 个 MCP 实现,而不是 200 个定制集成。数学上叫把 M×N 问题变成了 M+N 问题,实践中意味着开发成本断崖式下降。
MCP 的致命问题:上下文爆炸
但 MCP 有一个严重的副作用:吃掉你的上下文窗口。
每个 MCP Server 连接到 AI 时,必须把所有工具的定义(名称、描述、参数、示例)一次性塞进上下文。一个工具的定义大概 500-800 tokens,一个 MCP Server 通常有 10-20 个工具。
来看几个真实数据:
- GitHub MCP Server:27 个工具,消耗约 18,000 tokens
- Playwright MCP Server:21 个工具,消耗约 13,600 tokens
- mcp-omnisearch:20 个工具,消耗约 14,200 tokens
有开发者配了 7 个 MCP Server,还没开始对话,上下文就被吃掉了 67,000 tokens——占 AI 上下文窗口的 33%。更夸张的案例是 82,000 tokens,占 41%。
这意味着什么?你问 AI“2+2 等于几”,它回答“4”只需要 5 个 token,但工具定义已经消耗了 15,000 tokens。简单问题的成本被放大了 3000 倍。

更糟糕的是,当上下文被工具定义挤占后,AI 选错工具、传错参数的概率会显著上升。实践中,连接 2-3 个以上的 MCP Server,工具使用准确性就会明显下降。
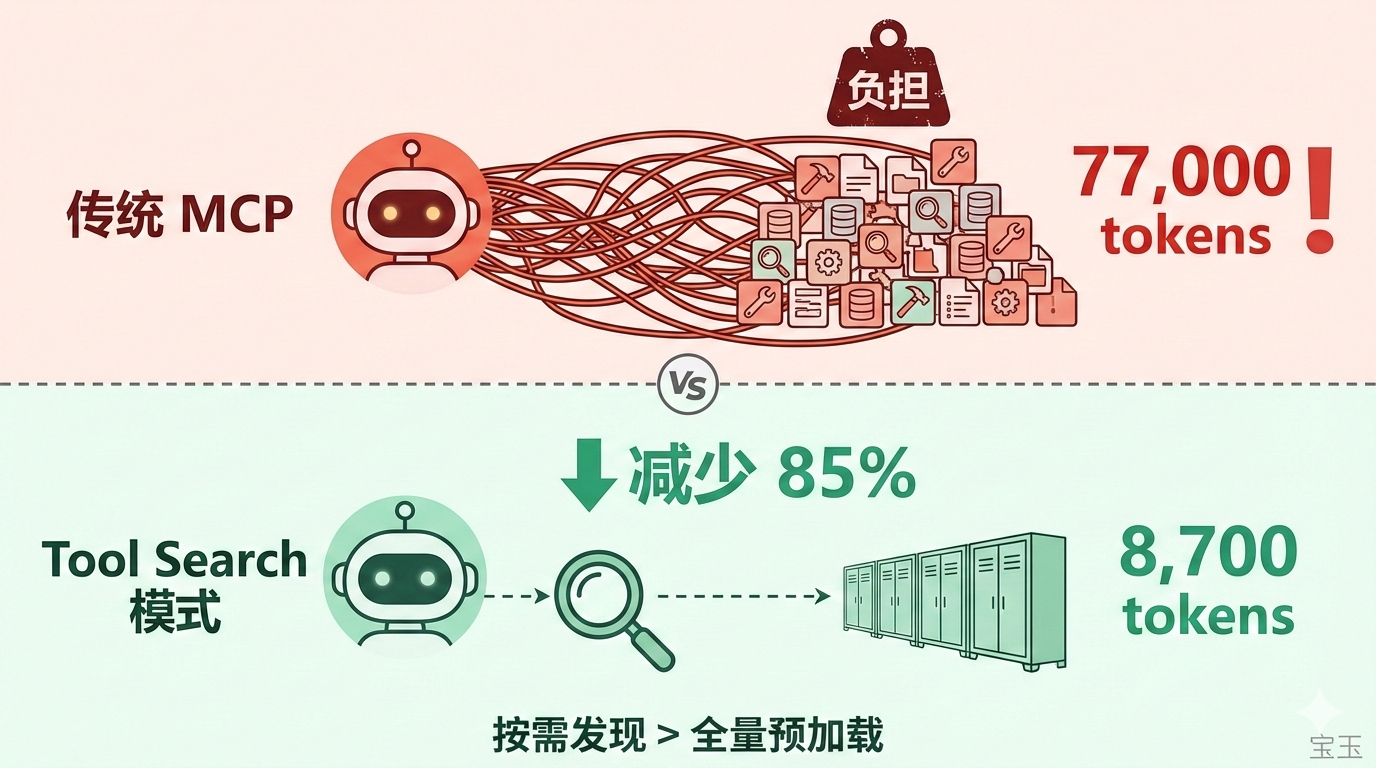
Claude Code 的解法:Tool Search
Anthropic 意识到了这个问题。2025 年 1 月,Claude Code 推出了 Tool Search 功能:
- MCP 工具不再预加载,而是按需发现
- 当工具定义超过上下文的 10% 时自动启用
- AI 需要用某个工具时,先搜索再加载
效果立竿见影:从 77,000 tokens 降到 8,700 tokens,减少 85%。
但这只是在给 MCP 打补丁。问题的根源在于:MCP 的设计假设是“把所有工具摆出来让 AI 挑”,这在工具数量少的时候没问题,工具多了就撑不住。
Skills:渐进式披露的操作手册
Skills 从一开始就采用了不同的设计哲学:渐进式披露(Progressive Disclosure)。
怎么理解呢?
想象你招了个新员工。传统做法是入职第一天把公司所有流程文档、规章制度、操作手册全部打印出来堆在他桌上,这就是 MCP 的做法。而 Skills 的做法是:先给一份简短的岗位说明,等他遇到具体问题时,再告诉他去翻哪本手册的哪一页。
技术上,Skills 是这样实现的:
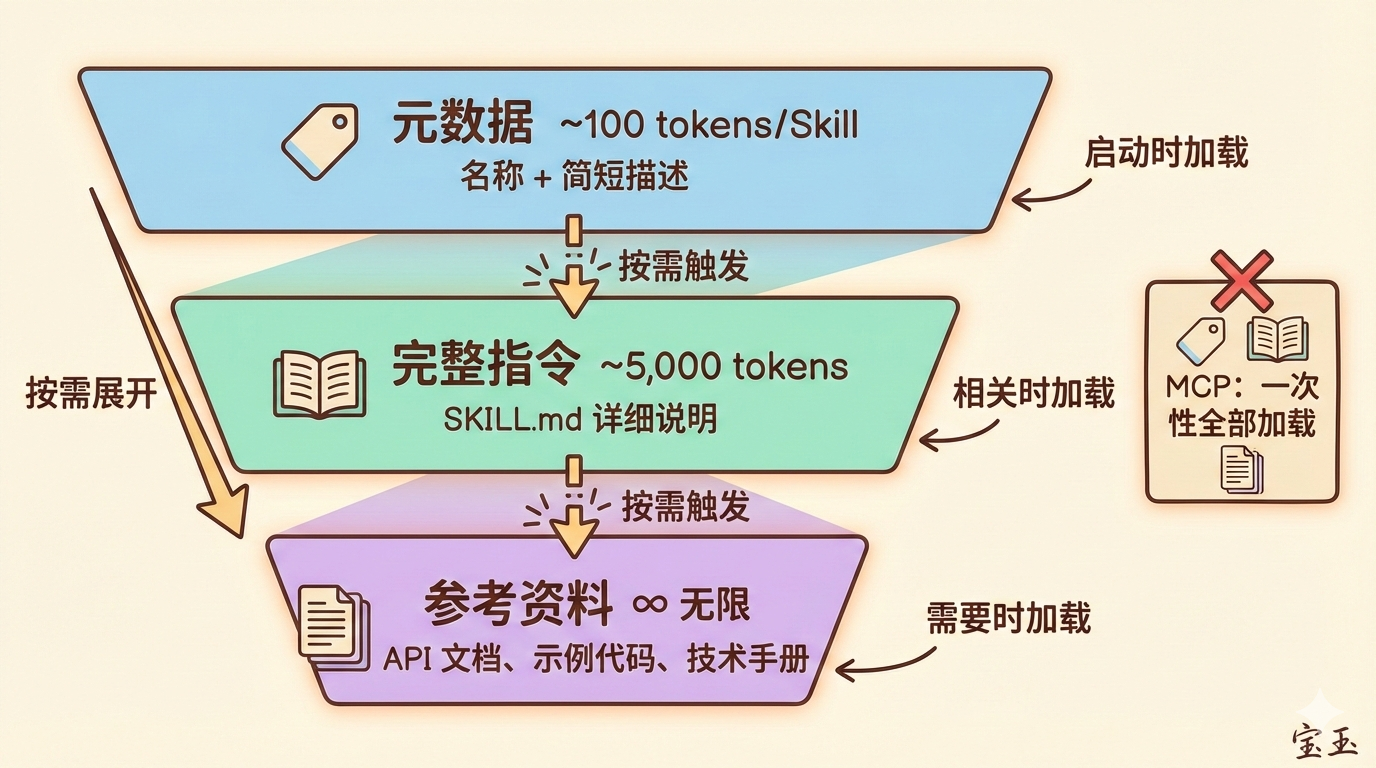
第一层:元数据(启动时加载)
- 只有名称和简短描述
- 每个 Skill 约 100 tokens
- 装 100 个 Skill 也只占 10,000 tokens
第二层:完整指令(相关时加载)
- 当 AI 判断某个 Skill 与任务相关时,才读取完整的 SKILL.md
- 建议控制在 5,000 tokens 以内
第三层:参考资料(需要时加载)
- 详细的技术文档、API 说明、示例代码
- 按需读取,用多少加载多少
- 理论上可以包含无限内容
这意味着:一个 Skill 可以打包整套 API 文档、完整的数据字典、几百页的参考手册,但只要任务不需要,这些内容就永远不会占用上下文。
Skills 的杀手锏:自带脚本
Skills 还有一个很多人忽略的能力:它可以自带可执行脚本。
一个典型的 Skill 文件夹结构是这样的:
my-skill/
├── SKILL.md # 核心指令
├── scripts/ # 可执行脚本
│ ├── validate.py
│ ├── generate.sh
│ └── process.js
├── references/ # 参考文档
└── assets/ # 模板、配置文件
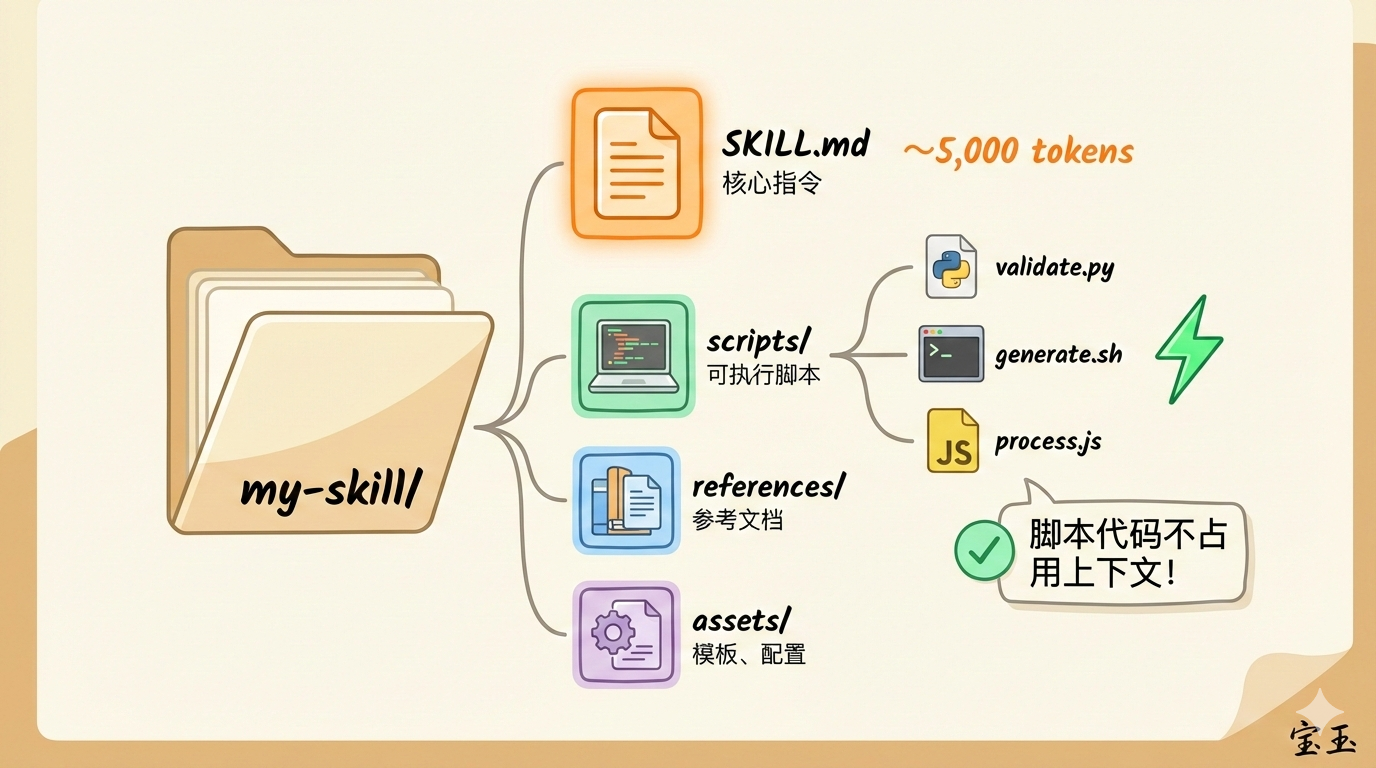
关键来了:当 AI 运行 scripts/validate.py 时,脚本代码本身不会加载到上下文,只有执行结果会返回。
这是什么概念?
假设你有一个 500 行的 Python 脚本,用来处理 PDF 表单。用传统方式,AI 要么自己写代码(消耗大量 tokens 生成),要么读取你的脚本再执行(脚本内容占用上下文)。而用 Skills,AI 直接运行预写好的脚本,整个过程可能只消耗 50 tokens 的输出结果。
脚本执行 = 零上下文成本 + 确定性结果
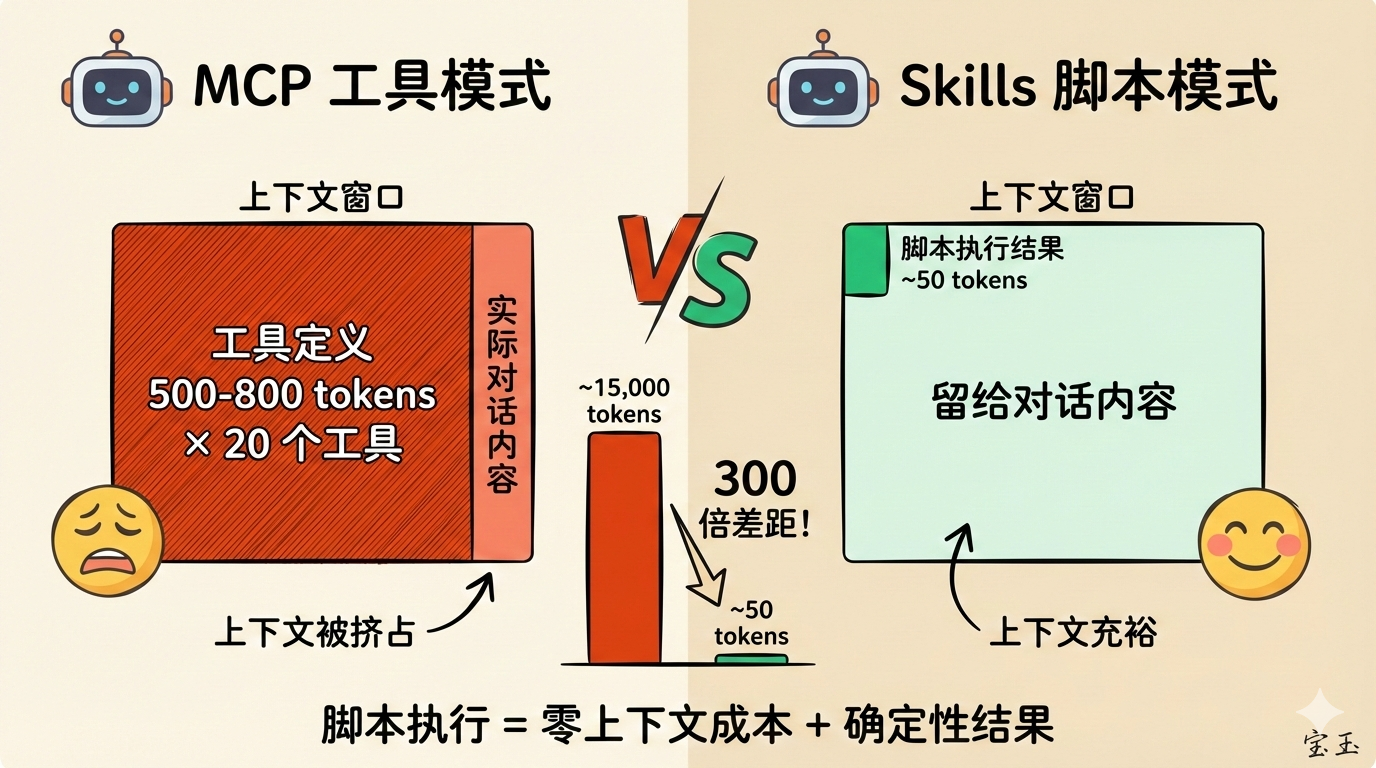
更重要的是:这些脚本通过 Agent 内置的 bash 工具执行,不需要 MCP。
Skills 支持的脚本语言包括 Python、Bash、JavaScript 等,基本上你系统能跑的都能用。这意味着:
- 文件读写?Skill 脚本搞定
- 数据处理?Skill 脚本搞定
- 格式转换?Skill 脚本搞定
- 本地 API 调用?Skill 脚本搞定
MCP vs Skills:什么时候需要什么?
现在我们可以重新审视这两个概念的定位了。
| MCP | Skills | |
|---|---|---|
| 类比 | USB 协议 | 应用程序 |
| 核心能力 | 连接外部系统 | 编码专业知识 |
| 工具来源 | 外部 MCP Server | 内置工具 + 自带脚本 |
| 上下文消耗 | 预加载,成本高 | 渐进式披露,按需加载 |
| 网络访问 | ✅ 支持 | ❌ 仅本地执行 |
| 分发方式 | URL 接入,面向外部用户 | 文件复制,面向内部团队 |
| 适用场景 | 远程 API、实时数据、对外服务 | 本地流程、专业方法论、内部工具 |
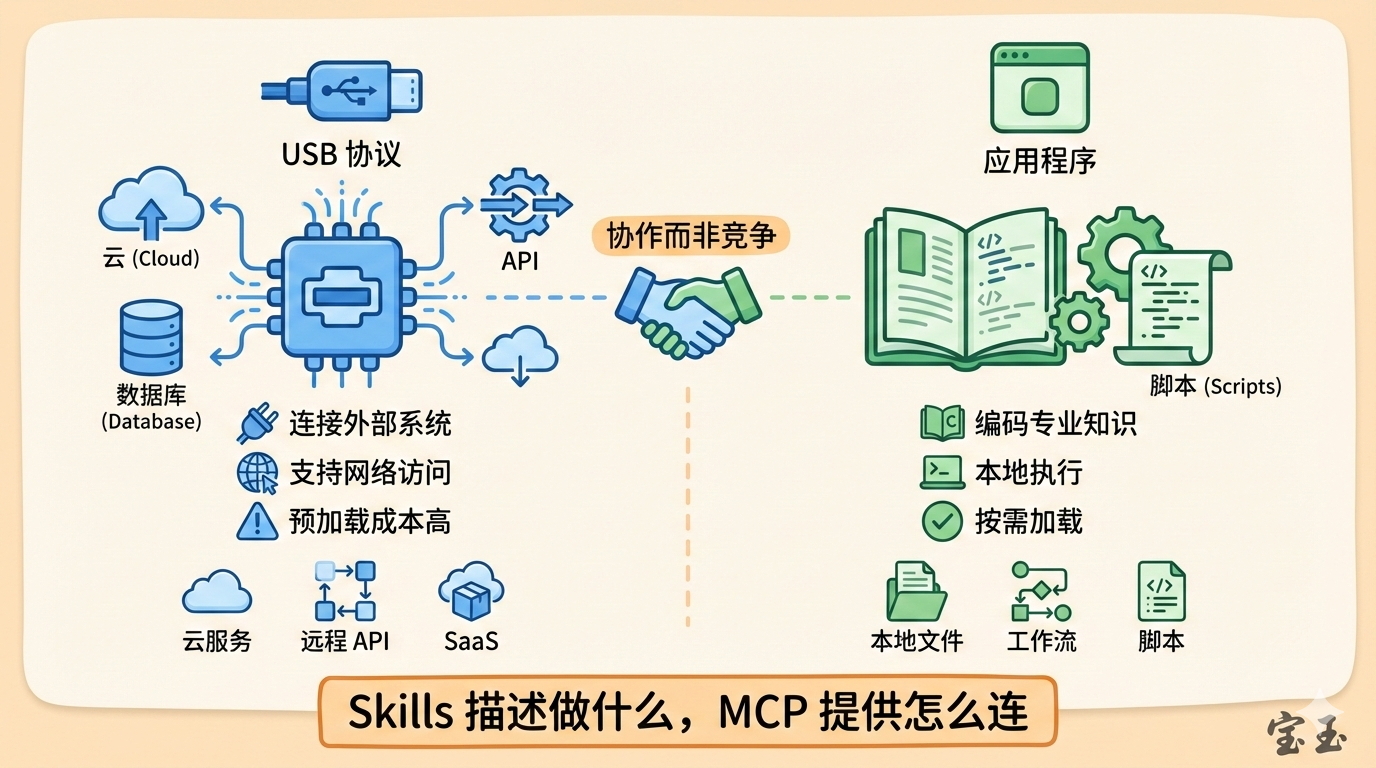
有一句话说得很精辟:
Skills 描述工作流程,MCP 提供执行引擎。但很多时候,操作系统自带的引擎就够用了。
这就像 GitHub Actions:工作流文件(相当于 Skills)定义了构建、测试、部署的步骤,但实际执行的还是 bash 命令。YAML 就像菜谱,写清楚先放油、再下葱、最后翻炒,但菜谱本身不会做菜,真正掌勺的是厨师。
问题是:Agent 这个“操作系统”本身就自带了 bash、read、write 等基础工具。对于大量本地任务,Skills + 内置工具就能完成,根本不需要额外的 MCP Server。
还有个类比我觉得很贴切:Skills 像 Slack 里的斜杠指令(slash commands)。你公司 Slack 里可能有几十个 slash commands,大部分你从来没用过,但对特定的人特定的场景很有用。这就是 Skills 的定位:内部工具,按需使用。
但你不可能把 slash commands 卖给外部用户。要对外,得用 MCP。
随着 Skills 普及,MCP 的需求会大幅减少
这是一个正在发生的趋势。
想想看,什么时候你真正需要 MCP?
需要 MCP 的场景:
- 连接远程 CRM 系统获取客户数据
- 调用第三方 SaaS API(Slack、Notion、Jira)
- 查询云端数据库
- 访问需要认证的外部服务
- 做一个服务让外部用户都能用
不需要 MCP 的场景:
- 读写本地文件 → bash + Skill 脚本
- 处理 PDF/Word/Excel → Skill 脚本
- 运行代码分析 → Skill 脚本
- 执行 Git 操作 → Skill 脚本
- 生成图表和可视化 → Skill 脚本
- 优化自己或团队的工作流
事实上,Anthropic 的工程博客提到:他们用“代码执行 + MCP”的方法,把一个 150,000 token 的工作流压缩到了 2,000 tokens——核心思路就是让 AI 写代码调用工具,而不是预加载所有工具定义。
这正是 Skills 的设计方向:用脚本封装能力,用渐进式披露管理知识,最大限度减少上下文消耗。
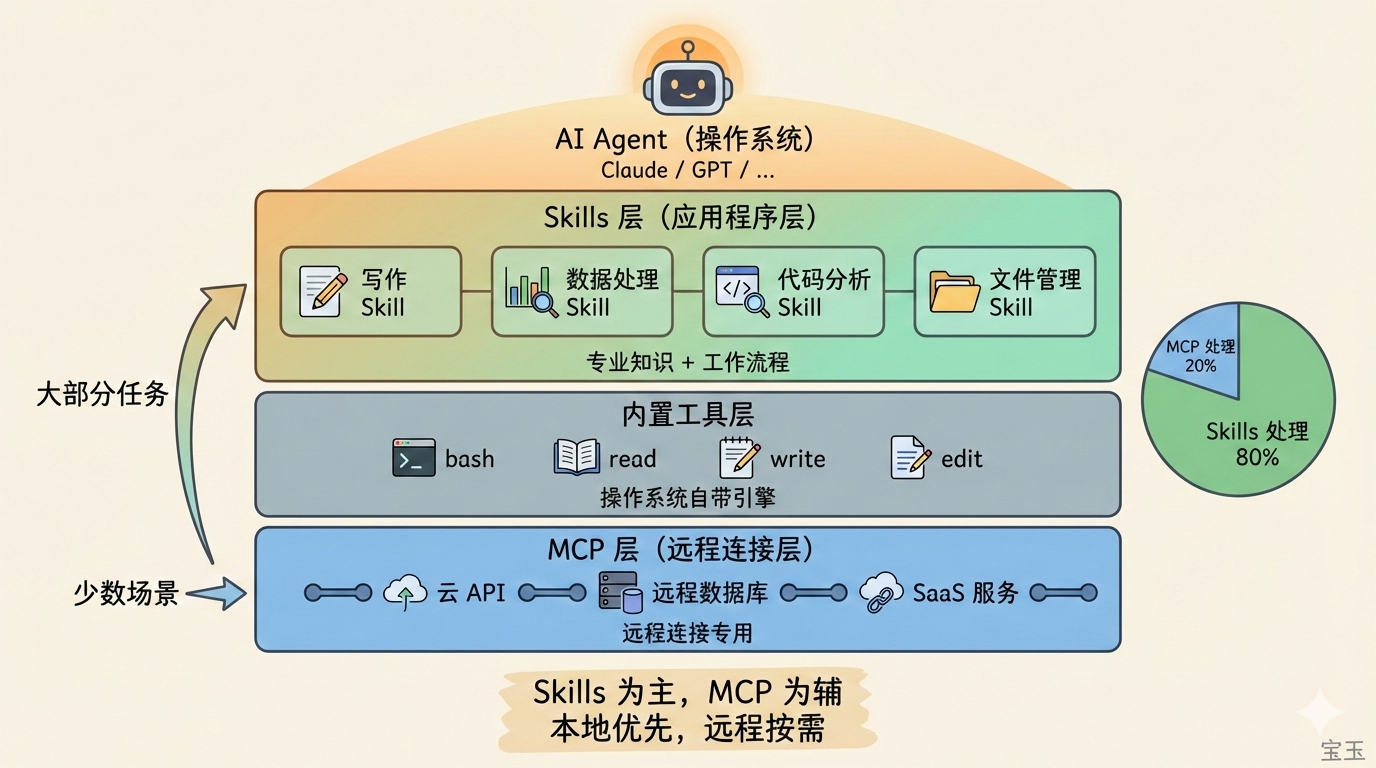
未来的格局可能是这样的:
- 少数通用 MCP Server 处理远程连接(数据库、云 API、SaaS 集成)
- 大量 Skills 编码专业知识和本地工作流
- 两者在必要时协作,但 Skills 会承担绝大部分“教 AI 怎么做事”的工作
一个真实案例:自动发布 X Article
这是一个真实发生的演进过程,完美展示了从 MCP 到 Skills 的转变。
需求: 把 Markdown 文章自动发布到 X(Twitter)的长文功能 X Article。
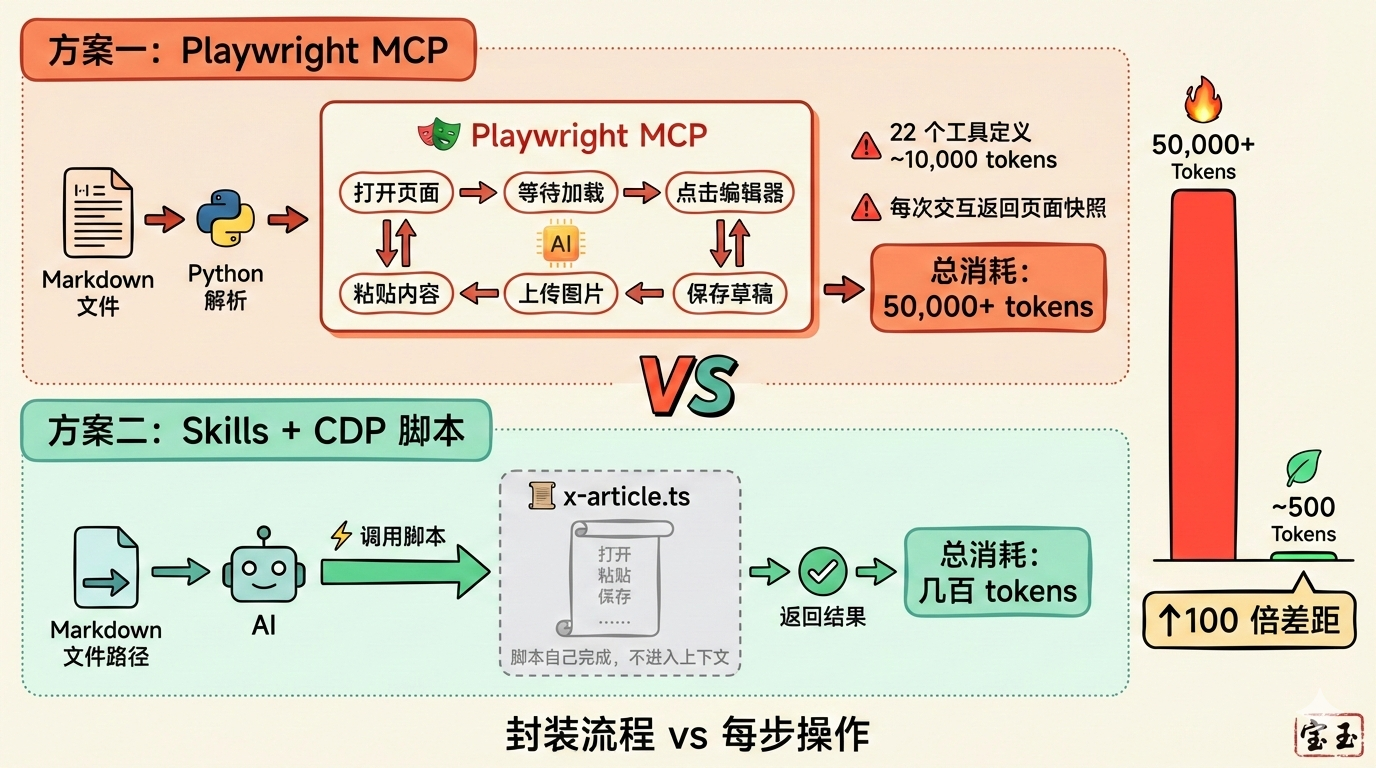
方案一:Playwright MCP
王树义老师开发了 x-article-publisher-skill,流程是这样的:
Markdown 文件
↓
Python 脚本解析(提取标题、图片位置、HTML)
↓
Playwright MCP 操作浏览器
↓
X Articles 编辑器(自动化填充)
↓
保存草稿
提示词很简洁,功能也很强大。但问题来了:上下文消耗得飞快。
Playwright MCP 有 22 个工具,光工具定义就占用约 8,000-10,000 tokens。更要命的是,每次浏览器交互,MCP 都要返回页面的 accessibility tree(无障碍树)快照——这是为了让 AI 理解当前页面状态。一个复杂页面的快照可能就是几千 tokens。
发布一篇文章,可能需要:打开页面、等待加载、点击编辑器、粘贴内容、上传图片、调整位置、保存草稿……每一步都是一次 MCP 交互,每一次交互都在消耗上下文。
结果:一篇文章发完,上下文可能已经用掉 50,000+ tokens。
方案二:Skills + CDP 脚本(我的改进版本)
我把 Playwright MCP 部分完全改成了脚本,做成了 baoyu-post-to-x:
baoyu-post-to-x/
├── SKILL.md # 简短的使用说明
└── scripts/
└── x-article.ts # 核心脚本,使用 Chrome CDP
核心变化:
- 脚本直接调用 Chrome CDP(Chrome DevTools Protocol),绕过 MCP
- 传入 Markdown 文件路径,脚本自己解析内容
- 脚本自己完成所有浏览器操作:打开页面、填充内容、上传图片、保存草稿
- 只返回最终结果给 Agent:“发布成功,草稿链接:xxx”
整个过程,AI 只需要做一件事:调用脚本,传入文件路径。
上下文消耗:可能只有几百 tokens。
为什么差距这么大?
| Playwright MCP | Skills + CDP 脚本 | |
|---|---|---|
| 工具定义 | ~10,000 tokens(22 个工具) | 0(脚本不需要工具定义) |
| 每次交互 | 返回页面快照(数千 tokens) | 无中间交互 |
| AI 参与度 | 每一步都要 AI 决策 | 只需调用一次脚本 |
| 总消耗 | 50,000+ tokens | 几百 tokens |
关键洞察:MCP 的设计是让 AI 一步步操作,每一步都要理解、决策、执行。而脚本的设计是把整个流程封装起来,AI 只需要说“开始”和“结束”。
这就是为什么即使 MCP 支持了 Tool Search(按需加载工具),上下文问题也没有根本解决——因为工具定义只是一部分,真正的大头是交互过程中产生的中间结果。
而 Skills 的脚本执行模式,天然避开了这个问题:脚本代码不进入上下文,中间过程不进入上下文,只有最终结果进入上下文。
写在最后:回到那个私信
所以我给那位读者的回复是这样的:
MCP 没死。Skills 也很有用。它们解决的是不同问题。
MCP 是 USB 协议,定义了 AI 与外部世界的连接标准;Skills 是应用程序,把专业知识和工作流程打包成 AI 能理解的操作手册。
Skills 的两大杀手锏——渐进式披露和脚本执行——让它能独立完成大量任务,不依赖 MCP。
渐进式披露解决了“知识太多”的问题:AI 不需要一次性加载所有信息,用到什么加载什么。
脚本执行解决了“交互太多”的问题:复杂流程封装成脚本,AI 只需要一次调用,中间过程不占用上下文。
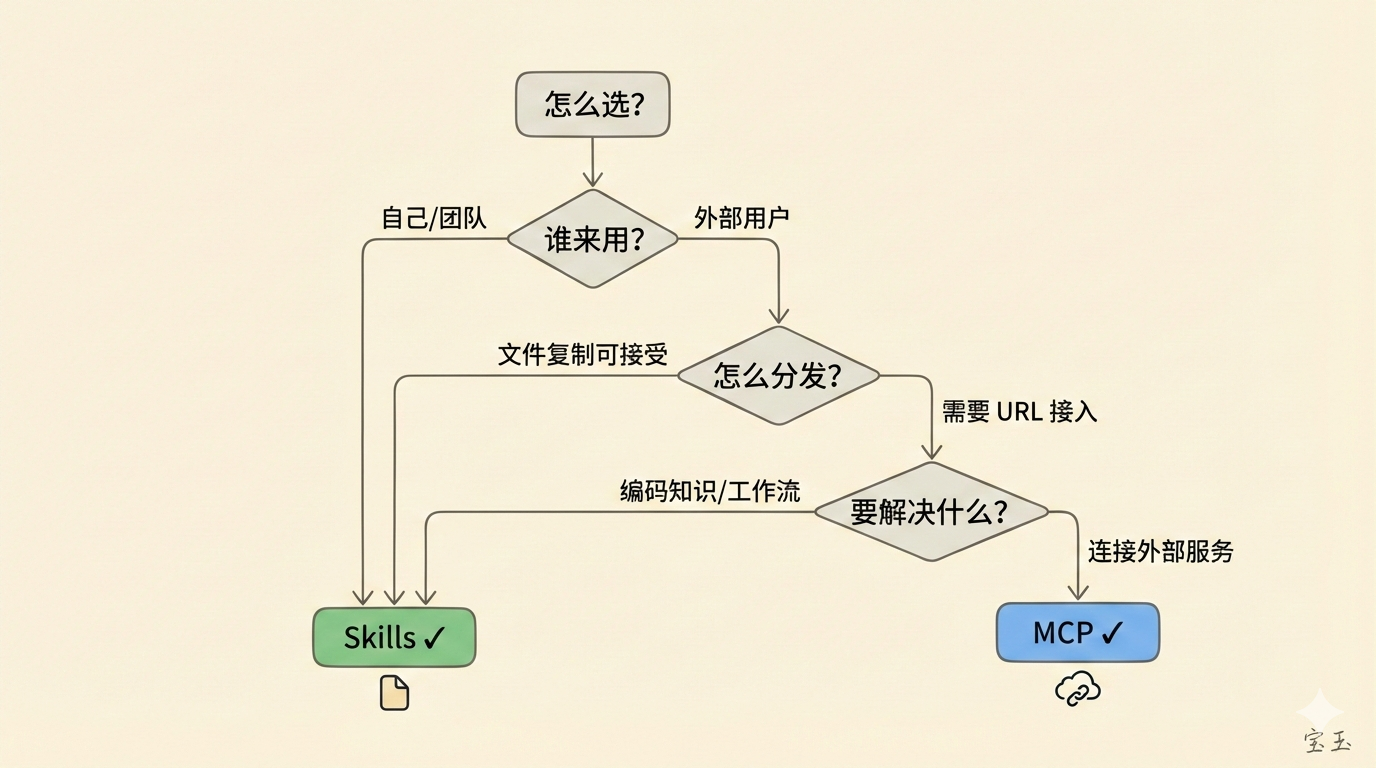
到底怎么选?问自己三个问题:
-
谁来用? 如果只有你自己或者团队内部用,Skills 就够了。如果要给外部用户或客户用,MCP 是必选项。
-
怎么分发? 如果可以接受“把文件放到某个目录”这种安装方式,用 Skills。如果希望用户输入 URL 就能用,用 MCP。
-
要解决什么问题? 如果是编码领域知识、定义工作流程,Skills 更友好。如果是连接外部服务、对外暴露 API,MCP 才能做到。
最佳实践是两者配合使用:用 Skills 编码你的领域知识,用 MCP 连接外部服务。 比如你们公司有一套特定的工作流程,先查这个系统,再查那个系统,按某个顺序处理。这种领域知识用 Skills 写出来,让 AI 理解。但具体连接那些系统的能力,靠 MCP 提供。两层配合,各司其职。
随着 Skills 生态成熟,MCP 的角色会收窄到“远程连接”这个核心场景——需要实时访问外部 API、需要认证的 SaaS 服务、需要跨网络的数据库连接。而本地文件操作、浏览器自动化、数据处理这些任务,Skills + 内置工具就能搞定,而且效率更高。
对于开发者:优先用 Skills 封装工作流程,复杂逻辑用脚本而非让 AI 一步步操作,只在必须连接远程系统时才用 MCP。
Skills 和 MCP 不是竞争关系,而是不同层次的能力。但如果你只能选一个先学,选 Skills。它更轻量、更高效、更容易上手,能解决日常遇到的大部分问题。
