我的隐私信息会被大语言模型拿去训练吗?
隐私问题是一个大家都很关注的问题,以前搜索时代,大家担心搜索引擎会泄露自己的身份信息,私密聊天记录等。现在大语言时代,同样有类似担心,担心自己的隐私信息会被大语言模型拿去训练,从而一不小心泄露自己的隐私信息。
现在大家对于搜索引擎的隐私问题已经有了一定的认识,比如搜索引擎只会检索互联网的公开信息,不会检索未公开的信息。就像我在百度网盘存的私密文档,百度搜索应该是不会去检索的。另外大家的隐私意识也有很大提升,不会随便把自己的隐私信息放到公网上。
由于大语言模型还是新事物,所以大家对于大语言模型的隐私问题还是有一定的担忧。常见的问题包括:
- 大语言模型会不会把用户的隐私信息拿去训练?输入我的名字是不是就能推断出我的隐私信息?
- 我和大语言模型的对话会不会被记录下来?会不会被拿去训练?
- 我还没发表的小说,会不会被大语言模型拿去训练,甚至生成类似的小说?
- 会不会关联我的实名信息,让我在不同平台的小号被关联起来?
大模型数据的训练来源,以及对数据的要求
大语言模型的训练数据主要来源于互联网的公开数据,比如维基百科,新闻网站,公开的论坛等。正规大公司是不会拿用户的隐私信息或者自己平台的用户私密数据去训练,一方面因为是违法法律的,另一方面从技术角度来说收益不大。
隐私数据不代表高质量数据,模型训练要想高质量,还是需要大量高质量的数据。使用用户隐私数据训练,对正规公司来说,收益比较低,风险比较高。
即使是公开数据,在训练前也需要对数据进行处理,比如脱敏,去标识化等。大模型在训练后还需要对齐,在对齐阶段也会让大语言模型在生成时,不会生成用户的隐私信息。
所以到目前为止,在用户使用大语言模型过程中,鲜有听说用户隐私信息被大模型泄露的情况。
为什么用户觉得自己的隐私信息被大语言模型泄露了?
在互联网上有一些“人肉高手”,通常能根据一些简单信息,就能“人肉”出一个人的很多信息。而这些信息其实就是这些高手通过网上的公开信息,只是他们善于搜索和关联数据。而普通人并不会去主动寻找这些信息的关联性,但现在随着 AI 搜索的流行,大语言模型会帮助用户对信息进行归类整理,从而让用户发现了一些自己没有发现的信息,这种情况下,用户会觉得自己的隐私信息被泄露了。
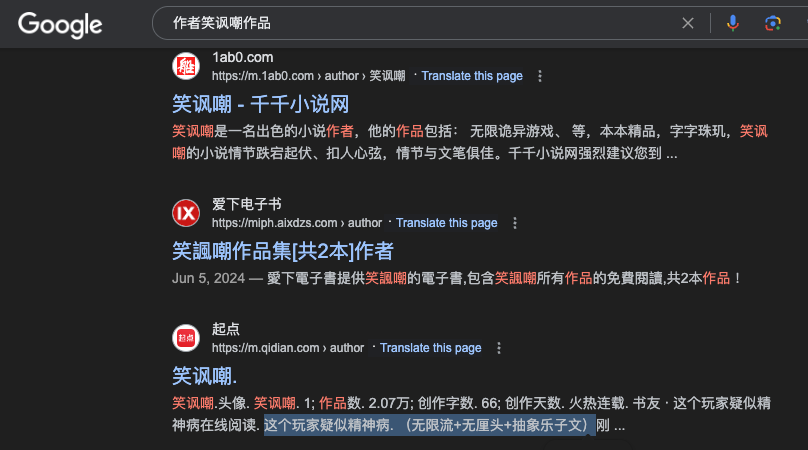
就像有位网友通过豆包搜索自己的作品,结果发现了自己小号的作品也被列出来了,以为是自己后台实名信息被大模型训练导致关联的,实际上是作者大号是“笑讽嘲”而小号是“笑讽嘲.”,只差一个点号,所以被 AI 归类在了一起也是正常的。
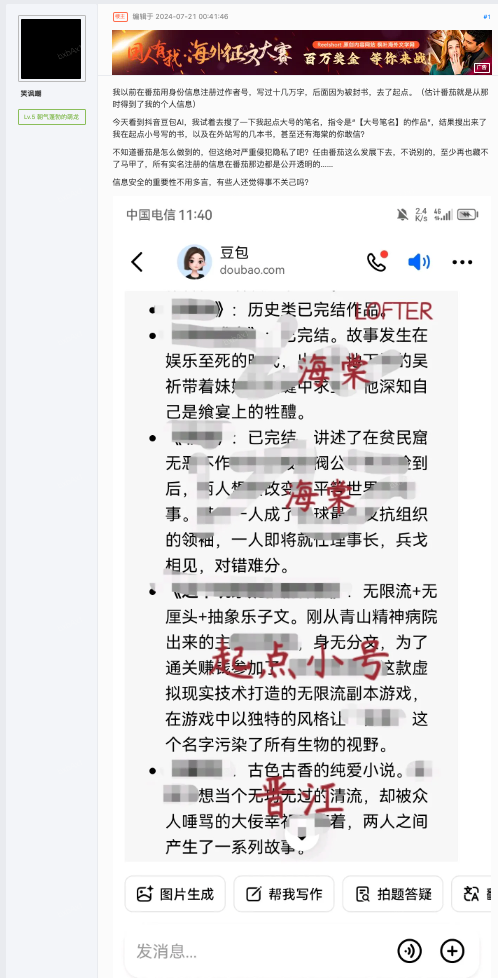
遇到这种情况可以通过搜索引擎搜索去验证一下,如果正常通过搜索也能得到类似结果,那么可能只是因为公开信息本身就有关联性。
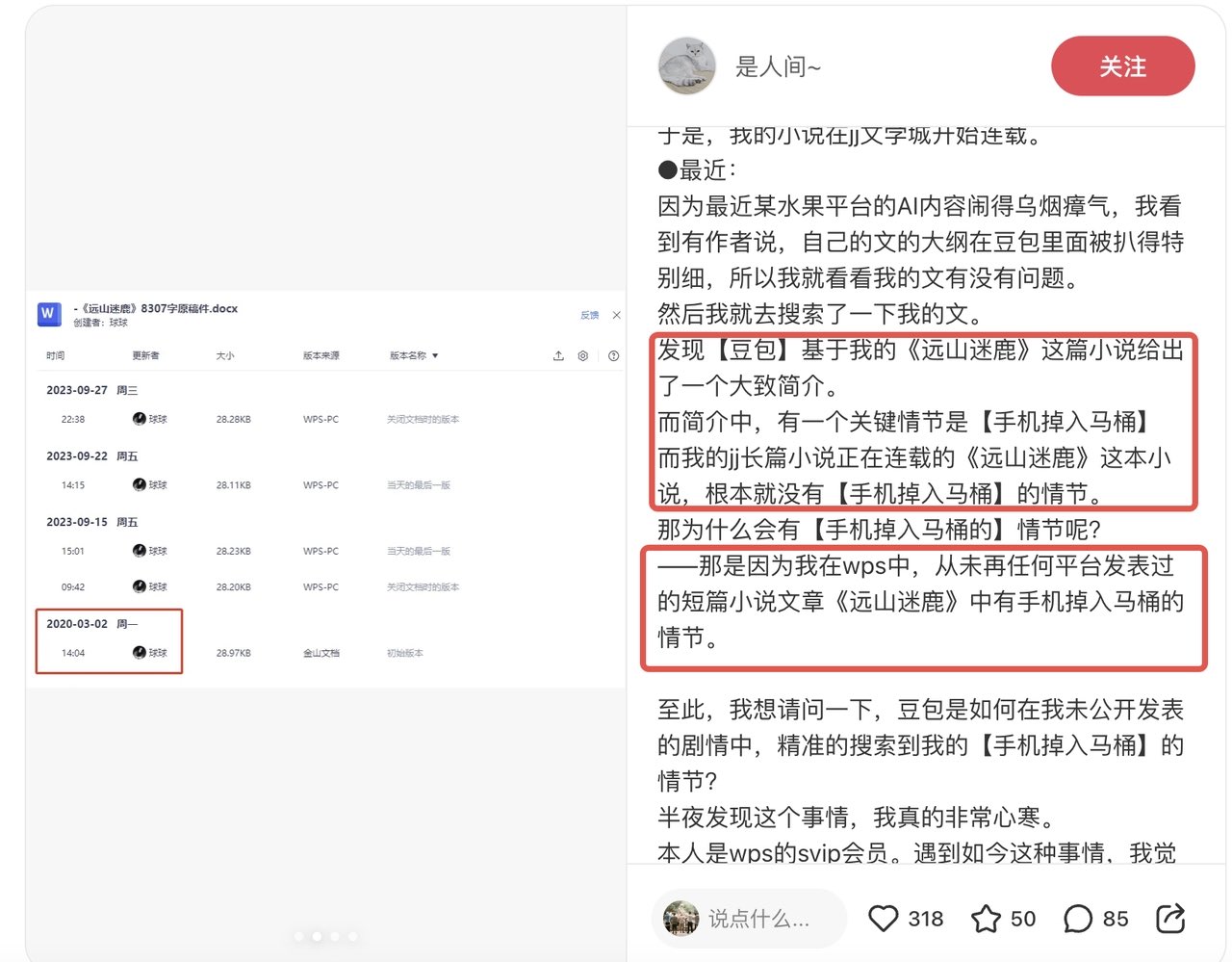
还有的网文作者,发现自己连载中的小说,WPS 上还未发布的部分,使用 AI,能列出没发布部分的大纲。这种情况,去推测 WPS 上的数据被泄露而被 AI 拿去训练,不是说绝对没可能,当你怀疑自己的隐私信息被泄露时,可以通过一些方法来验证,也许可以打消自己的疑虑。
比如在使用 AI 搜索时,AI 搜索的原理是先根据问题检索,然后大语言模型按照检索出来的做信息整理,再生成答案。在生成的答案中,AI 都会列出信息来源,可以点开看看,这些信息的内容是不是和生成的内容相关,是不是和自己的隐私信息相关。如果都只是公开信息,那么就不用担心是自己的隐私信息被泄露了。
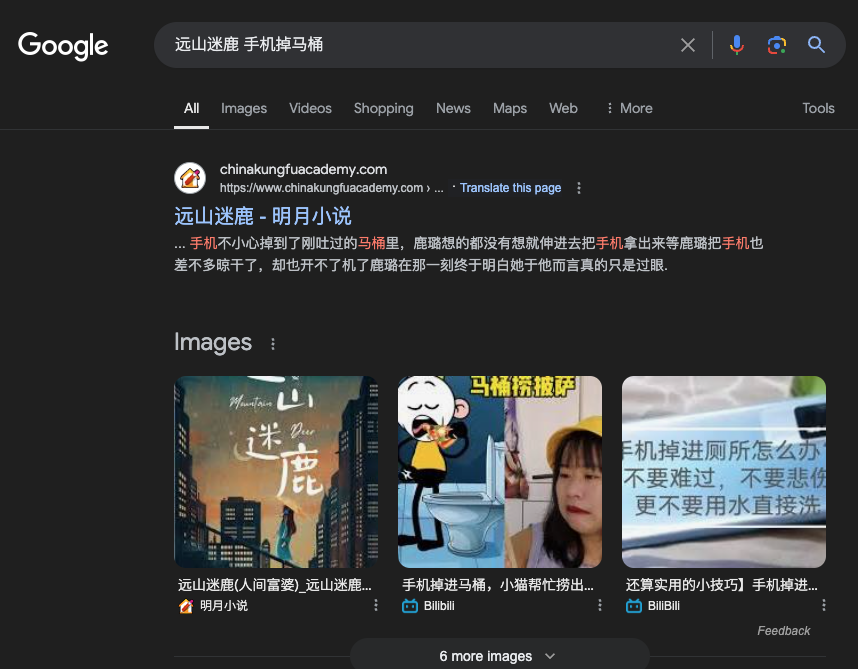
比如有位作者说,豆包写出了她还没公开发表的“手机掉在马桶里”情节。
同样可以通过搜索引擎搜索,看看这个情节是不是已经被公开发表过了。如果是,那么就不用担心是自己的隐私信息被泄露了。
多试几种不同的 AI,是否都有相似的地方,那么大概就只是大语言模型和你思路比较接近,而不是你的隐私信息被泄露了。
以起点的《深海余烬》为例,如果用不同的 AI 来列出目录大纲,你可以看到列出来的结果差不多,因为本质上都是根据公网搜索出来的结果进行二次总结的。
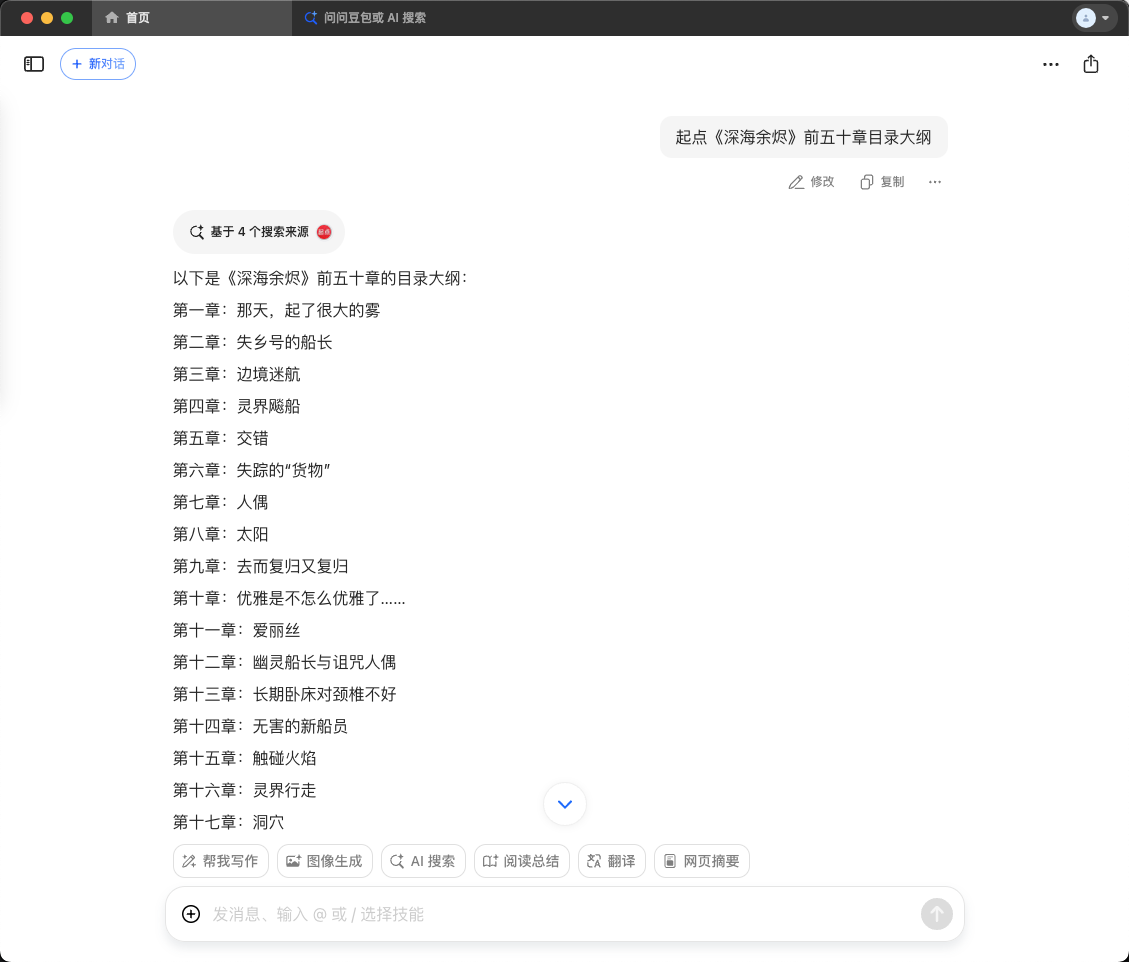
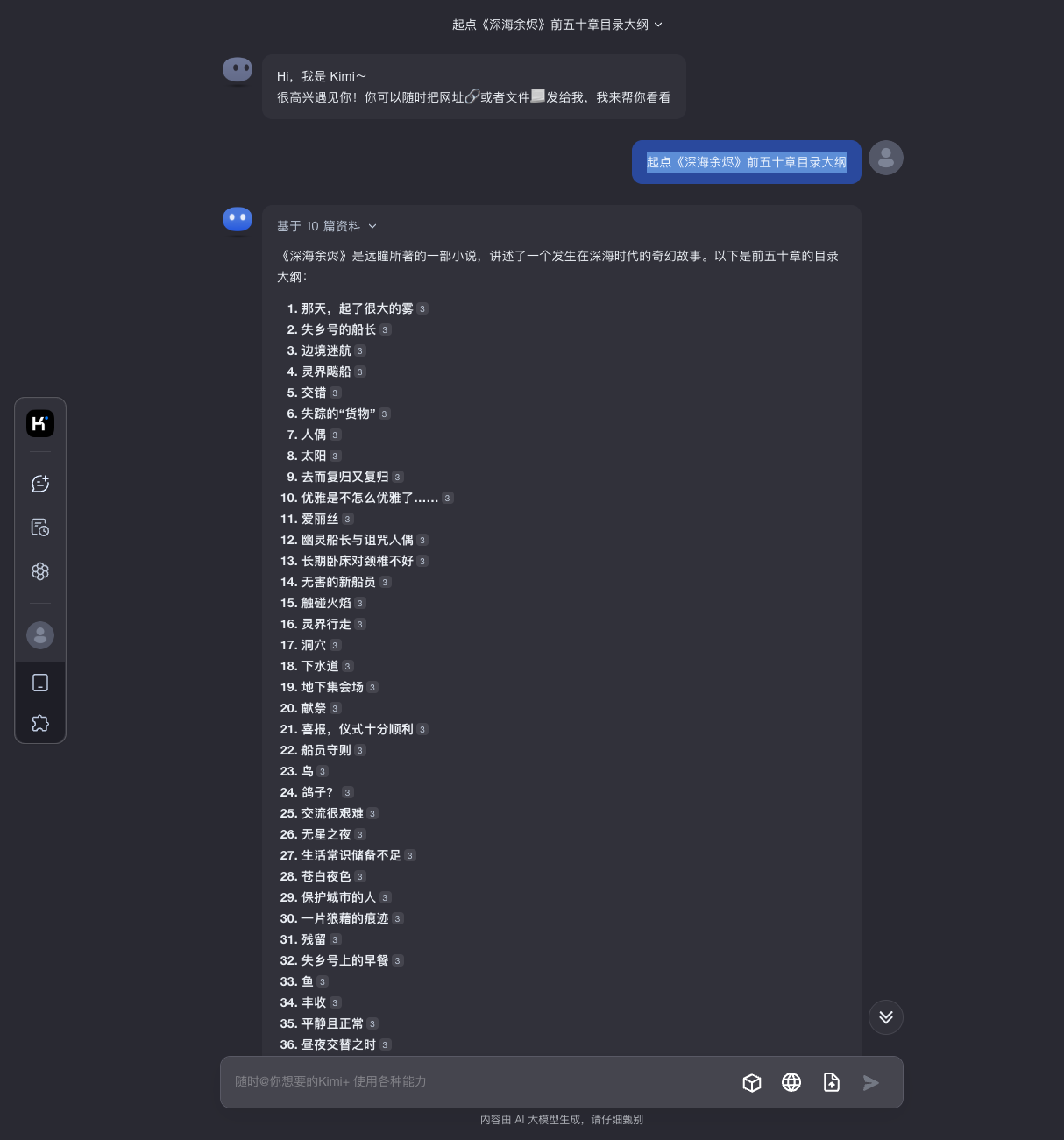
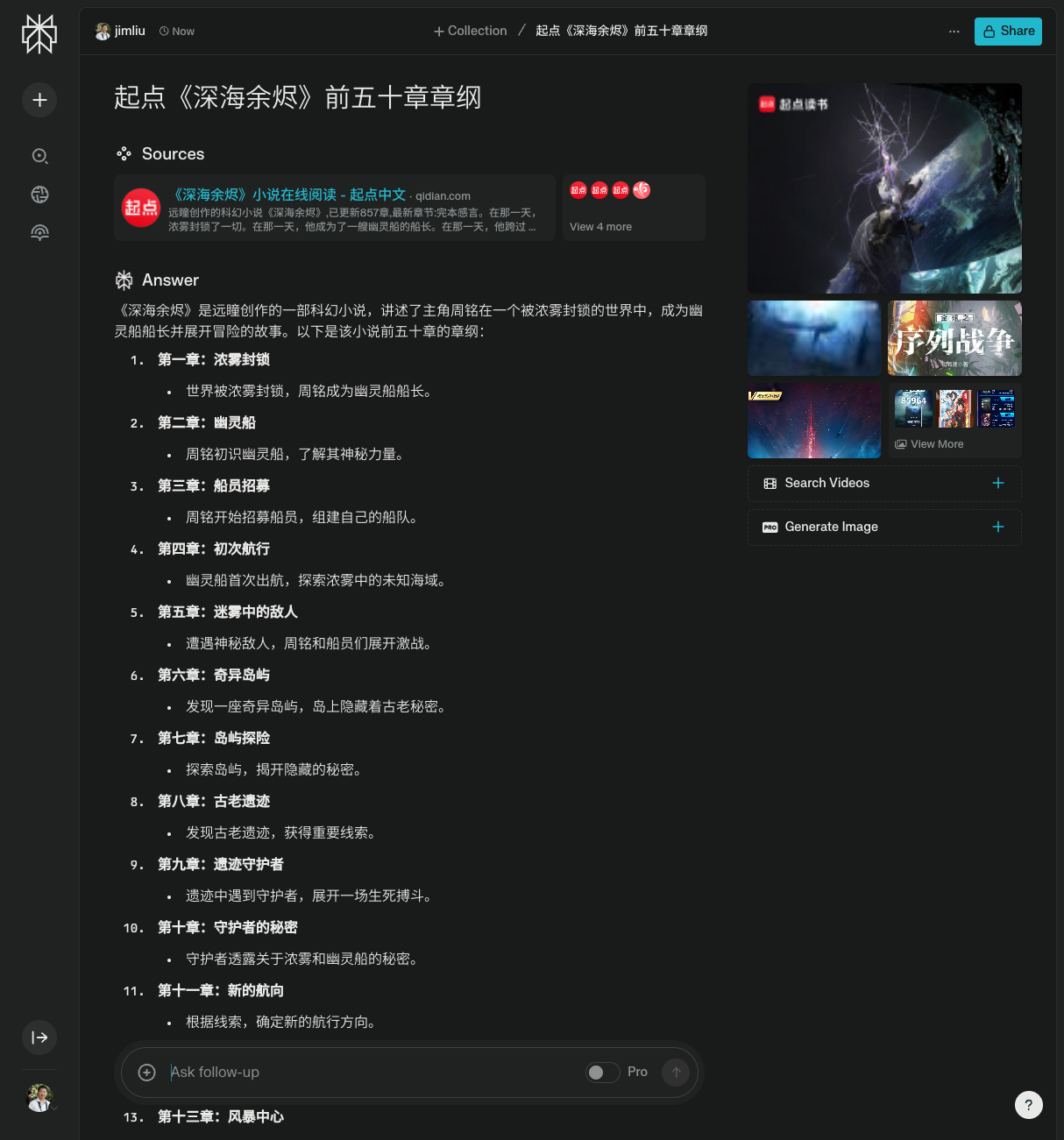
多试试不同的提示词,如果是输出大纲目录,这种公开信息比较多,被预测的可能性也比较大,可以尝试用一些文章内容片段,并且公网肯定检索不到的,如果能出来大片相同的没发表的内容,那就真的有可能是隐私信息被泄露了。
怎么保护自己的隐私信息?
- 不要随便把自己的隐私信息放到公网上,比如自己的身份证号,银行卡号等。
- 在使用 AI 的时候,检查隐私设置,尽可能不允许自己的对话被训练。
- 和 AI 对话时,涉及机密的文档,建议不要直接上传到 AI 平台,先自行脱敏处理,或者使用离线模型。虽然大语言模型不一定会拿去训练,但是在信息传输的过程中还是有泄露的风险和可能。
- 如果确实发现隐私信息被泄露,建议截图录屏取证,向相关部门举报。
在使用大语言模型时,不必过于担心自己的隐私信息会被泄露,了解大语言模型是如何训练的,了解隐私信息泄露的可能途径,可以帮助我们更好的保护自己的隐私信息。如果有疑虑,可以通过交叉对比、还原细节内容等方法进行验证,打消自己的疑虑。如果确实是隐私信息被泄露,建议通过法律手段维权。