字幕翻译、书籍翻译的福音,如何借助 ChatGPT 得到高质量的翻译结果?
过去几个月里,我独立翻译了一百多部视频(http://t.cn/A6OHJzs0),可以说绝大部分翻译质量还是相当不错的。
如果完全靠自己的英文和中文水平,要达到这样的翻译速度和质量那是不太可能的,主要还是得益于 ChatGPT 的帮助,首先用 GPT-4 的 API 粗翻,再用 ChatGPT Plus 精翻。
很多人都用过 ChatGPT 翻译,但翻译出来的结果比起 Google 翻译和 DeepL 这种,似乎翻译质量并没有好太多,但其实是你没有最大化的利用大语言模型的优势,如果你能善用 ChatGPT(尤其是 GPT-4)这样的大语言模型,可以让你的翻译质量提升一个大台阶。
那么大语言模型相对于传统的翻译工具有什么优势呢?
- 可以根据 Prompt 产生不同的结果
使用大语言模型的时候,借助 Prompt 你可以提出很多个性化的要求,比如说:
- 可以提供不同的翻译风格,比如你可以将翻译的结果更加口语化
- 你可以将某些专有名词使用特定的翻译(不会闹笑话把“LLM”翻译成“法学硕士”)
- 你可以提供上下文让翻译更有针对性,比如说这是一篇 AI 相关的技术文章,尽可能翻译成专业术语
- 你可以让它识别错别字,比如在语音转文字时,经常会产生错别字,或者翻译完成也可能会有错别字,这些错误人工纠正很容易疏漏,可以让 AI 帮你纠正,又快又准
- 可以提供背景解释,大语言模型背后有一个超级庞大的知识库,几乎囊括了互联网所有的公开信息,有时候我们在翻译时,遇到一些因为文化背景不一样的内容,很难理解其中的含义,这时候就可以让大语言模型帮你解释,帮助你更好的理解
- 等等
当然缺点也有:
- 价格高(如果是 API 比较贵,包月的 ChatGPT Plus 其实性价比还是挺高)
- 速度慢,比谷歌翻译和 DeepL 这些速度要慢
这里分享一下我使用 ChatGPT 帮我翻译字幕的经验。
一、写好 Prompt
用 ChatGPT 的第一条就是写好 Prompt,如果你只是写“请将我翻译以下内容为中文”,也能得到一个还不错的结果,但这样只是把 ChatGPT 当 DeepL 来用了。
但如果你能写一个高质量的 Prompt,那么就能得到更好的结果。一个好的 Prompt 的结构(参考 http://t.cn/A6OHJzsO): ✅ 角色、技能、个性 ✅ 目标、任务 ✅ 生成规则 ✅ 输入输出格式 ✅ 示例
比如我通常会给它先设定一个角色: “你是一位精通简体中文的专业翻译,写作风格是短小精悍、通俗易懂。”
然后给它的任务: “现在你要帮我将以下英文字幕翻译成中文”
再加上一些规则:
- 忽略错别字或者拼写错误
- 翻译时结合上下文意译而不是直译
- 译文通俗、简洁、易懂
- 英文单词前后加上空格
在有些情况下给出示例,比如说: “英文单词前后加上空格,例如"中 English 文"”
有时候会说明输出格式: “提供 5 种不同类型的翻译风格:意译、直译、口语化翻译、创意翻译、文学翻译”
二、提供足够的上下文,但一次只翻译一段,并且提供多个翻译结果选择
使用 ChatGPT 时,如果提供足够的上下文,那么有助于 ChatGPT 更好的理解要翻译的内容,给出更好的结果。
所以我在翻译字幕时,会尽可能将完整字幕一次性输入,这样 ChatGPT 可以看到完整的内容,能更好的纠正错别字、给出更好的翻译结果。
但我每次只让 ChatGPT 翻译一段,因为输出结果太长的问题在于:
- 很容易超出最大上下文长度,比如我输入完整英文字幕,让 ChatGPT 完整翻译,通常最后一部分会无法正常输出,产生“幻觉”,因为超出了最大上下文长度。
- 输出内容长的话质量要低一些,参考论文《Lost in the Middle: How Language Models Use Long Contexts》http://t.cn/A60wosaI
但是一次翻译一段的话,缺点就是速度慢一些,翻译完一段又要输入一段。但是对于精翻来说还可以接受,因为本来就需要慢工出细活,逐句斟酌。
另外还有一个很重要的技巧,就是翻译的时候,让 ChatGPT 一次提供 3-5 个不同风格的翻译结果,然后你就可以得到很多不同角度的翻译结果,大部分时候,你只要从这几种不同翻译结果里面选一个就可以了。
ChatGPT 这类大语言模型是一种概率模型,根据概率生成内容,有时候很难一次就得到一个很好的结果,所以要得到好的生成效果,可以让它一次多生成几种结果,然后你可以从中选一个最好的,甚至于你可以让它自己帮你选一个。
有的时候,它能随机出来相当不错的翻译结果,所以大部分时候就只要从几个翻译选项中选一个最好的,或者组合一下。
三、追问,帮助更好的理解原文
有时候就算它提供了若干翻译选项供选择,但还是很难理解什么意思,这时候就可以在 ChatGPT 中追问。
比如上一次我在翻译 Sam Altman 一段关于授权的回复时,他说:“setting the training wheels at the right height and increasing them over time as people learn more and I build up more trust.”,然后 ChatGPT 的翻译结果是:“适当地设置“训练轮”,并随着人们学到更多知识和我对他们的信任增加而逐步提高。”。
说实话我是没看懂,如果我直接就这么翻译,从字面上理解也没问题,但是肯定有很多人像我一样看不懂什么意思。于是我就继续问 ChatGPT:“能不能详细解释一下这里的"setting the training wheels at the right height"?”
于是 ChatGPT 给我详细解释了这里的意思:
“设置合适高度的训练轮”这个短语可以理解为在团队管理和人员培养方面,为新员工或团队成员提供适当的支持和指导,而不是一开始就给予他们太多的责任和压力。这里的“训练轮”可以比喻为在员工成长和学习的初期阶段提供的辅助工具或支持,而“合适的高度”则意味着这种支持和指导应该是适度的,既不能太少也不能太多,以便他们能够逐步学习和适应,最终能够独立完成任务和承担更多的责任。随着时间的推移,这些“训练轮”会逐渐提高,意味着给予员工更多的自由和责任,让他们有更多的机会来展示他们的能力和潜力。
我继续问:“请按照上面的解释重新翻译”,于是我得到了一个新的翻译结果: “我们要像调整孩子自行车上的辅助轮那样,为他们设定合适的支持和指导,随着他们的学习和我对他们的信任逐渐增加,我们可以逐步提高这个“辅助轮”的高度。”
这样就容易理解多了,因为“training wheels”是特指自行车的辅助轮,其实去年教孩子学自行车我就知道这单词,但是没有那么熟悉,尤其是一开始被翻译成“训练轮”,我很难将它和自行车的辅助轮联系起来,但是你一追问,那么 ChatGPT 就能从多个角度帮你分析解释,这样译者就能更好的理解原文的意思和背景,从而提供更为准确的翻译。
我觉得现在很多著作的中文翻译很晦涩难懂,很多时候是因为译者自己都没看懂,只能按照字面意思翻译,如果他们借助 ChatGPT 理解背后的意思,那么就能提供更好的翻译结果。
四、使用时避免上下文超长
ChatGPT 这类 LLM 有个天然缺陷,就是上下文窗口无法太长,比如 ChatGPT Plus,按我的经验,GPT-4 大约 8K 的 Token 就是上限了,差不多~6000 英文、~4000 中文的样子。如果超出这个长度,后面的内容会出现幻觉,也就是胡说八道,出来的结果跟你输入的完全不相关。
避免这个问题有两个小技巧:
-
优先使用 Advanced Data Analysis(以前叫 Code Interpreter)模型,这个模型上下文窗口明显能长一些
-
多用 ChatGPT 的编辑功能
如果你在 ChatGPT 中不停地回复新内容,那么每次生成的时候都会把历史消息都加入发送过去,这样越到后面占用的 Token 越多,一会就会超出上限。
但是如果你每次只是编辑消息的话,它就只修改,不新增。所以我通常第一条消息发 Prompt,第二条消息用来编辑,不停的变更要翻译的段落,这样每次都只有 2 条消息,基本不会超过上下文长度上限。
所以我每次翻译字幕的时候,都把完整字幕输入给 GPT,然后告诉它,先不要翻译,只回复 OK,后面等我发新的了,你就按照我的 XX 要求去翻译,提供 5 个选项。
这样我后面只要一直编辑第二条消息(参考图 4),将我要翻译的段落放进去,不需要再写 Prompt,然后保存发送后就自动给我翻译这一段内容,提供 5 个选项。
并且第一条消息有完整的字幕内容,这样就算后面我发送的只有一段,它也能从第一条消息找到完整的上下文。
五、帮找原文中的错别字
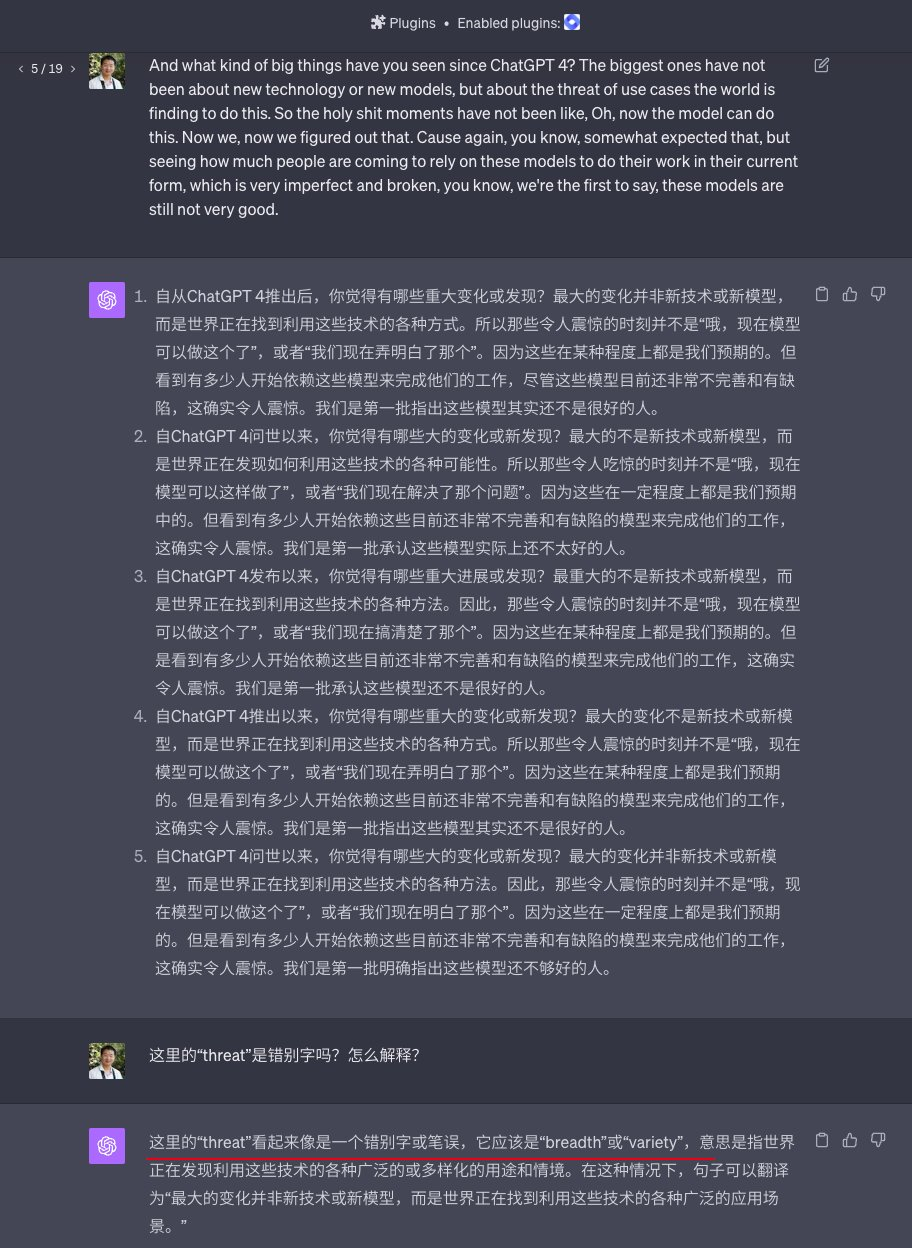
另外有时候 Whisper 识别字幕的时候,会产生错别字,可以直接问 ChatGPT 是不是有错误,它可以指出是不是有问题。
总结
一、根据你的使用场景写好你用来翻译的 Prompt 二、提供足够长的上下文,但是每次只翻译一段,并且提供多种翻译风格供选择参考 三、借助追问,帮助你更好的理解原文 四、避免上下文超长 五、翻译完成后,善用 ChatGPT 帮你做校验,找出错别字
以上就是我使用 ChatGPT 进行翻译的经验总结,希望对大家有所帮助。
附:


图三:不同翻译风格的结果

图四:使用编辑功能避免上下文超长

图五:帮找原文中的错别字
