问答:有校对好的视频文稿如何用文稿纠正字幕错误?
问:我做了个讲解视频,手里有英文稿,但是 Whisper 或者 YouTube 生成的字幕有很多错误,我该如何用文稿纠正字幕错误?
答:
可以借助提示词工程,让 LLM(大语言模型)来修正字幕错误,并且保留时间轴不变。提示词并不复杂,主要是要让 LLM 明白你的输入格式和你期望的输出格式,并提供所有的上下文信息,甚至不需要 CoT(思维链)这样高级的提示词技巧。
但是要注意的是,要输入的内容不要太长,因为大语言模型容易出现幻觉,输出质量会下降,按我的经验,每次 800 左右单词是一个比较合适的长度。具体需要测试对比一下。
方法如下:
- 字幕需要用 srt/vtt 这样的简单文本格式,然后要将字幕分页,每一页包含原始文稿和字幕文件。
- 可以使用 API 或者 ChatGPT 都可以,如果使用 API,建议输出 XML 格式,方便代码解析,如果是 ChatGPT,可以将输出内容放在代码块中,方便复制出来。
参考提示词:
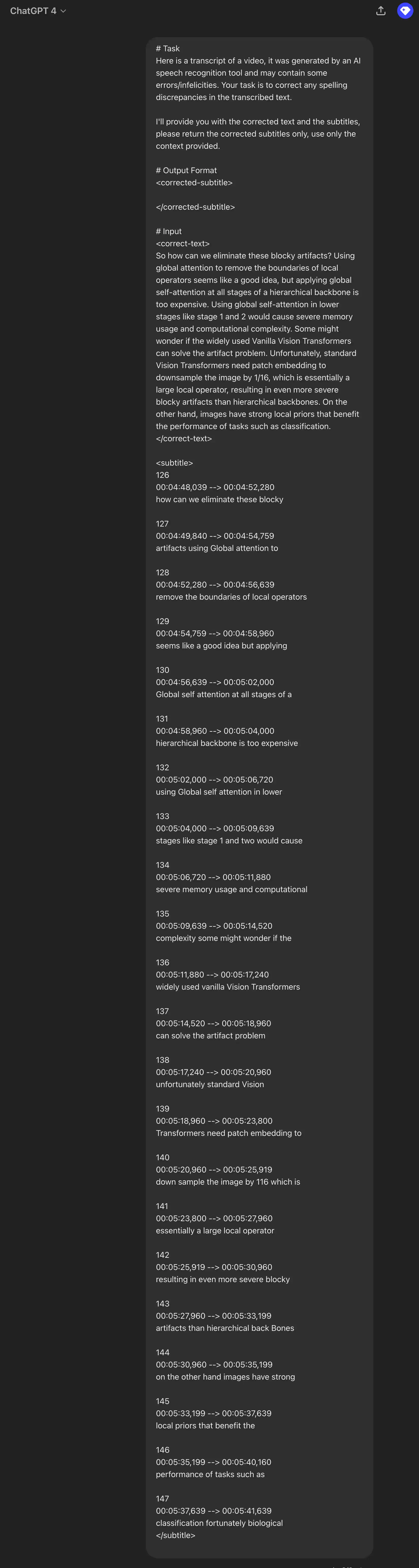
# TaskHere is a transcript of a video, it was generated by an AI speech recognition tool and may contain some errors/infelicities. Your task is to correct any spelling discrepancies in the transcribed text.I'll provide you with the corrected text and the subtitles, please return the corrected subtitles only, use only the context provided.# Output Format<corrected-subtitle></corrected-subtitle># Input<correct-text>「略」</correct-text><subtitle>「略」</subtitle>
这段提示词结构很简单,就是要求 LLM 完成的任务、期望输出的格式,然后是输入,由于输入部分包含两种不同类型的数据:文稿和字幕,所以需要用两个标签包裹起来,这样 LLM 就能有效区分你输入的内容。
提示词中文参考:
# 任务这是一段视频的转录文本,由 AI 语音识别工具生成,可能包含一些错误或不合适的地方。你的任务是纠正转录文本中的拼写差异。我会提供给你纠正后的文本和字幕,请仅返回纠正后的字幕,只使用提供的上下文。# 输出格式<corrected-subtitle></corrected-subtitle># 输入<correct-text>「略」</correct-text><subtitle>「略」</subtitle>
注意:这个提示词仅作为参考,在 GPT-4o 下测试效果很好,但是其他模型可能需要调整,对于能力弱的模型,可能要提供 1-2 个示例,让模型更好的理解你的任务。