通用型基础模型能否超越专用调整模型?医学领域的案例研究 [译]
Harsha Nori*‡,
Yin Tat Lee*,
Sheng Zhang*,
Dean Carignan,
Richard Edgar,
Nicolo Fusi,
Nicholas King,
Jonathan Larson,
Yuanzhi Li,
Weishung Liu,
Renqian Luo,
Scott Mayer McKinney†,
Robert Osazuwa Ness,
Hoifung Poon,
Tao Qin,
Naoto Usuyama,
Chris White,
Eric Horvitz‡
摘要
像 GPT-4 这样的通用型基础模型在众多领域和任务中表现出惊人的能力。但人们普遍认为,除非经过专业知识的深度训练,这些模型无法达到专家级别的性能。例如,到目前为止,大多数针对医学能力基准的探索都采用了特定领域的训练,如 BioGPT 和 Med-PaLM 的研究。我们的研究延续了之前对 GPT-4 在医学领域的专业能力进行的探索,但我们并没有对其进行特别训练。不同于仅使用简单的提示来展示模型的即插即用能力,我们系统地探索了如何通过精妙的提示设计来提升模型性能。我们发现,创新的提示方法能够激发更深入的专家级能力,并证明 GPT-4 在医学问答数据集上轻松超越了以往的最佳成绩。我们研究的提示设计方法是通用的,无需特定领域知识,省去了专家定制内容的需求。在实验设计中,我们特别注意控制过拟合现象。研究的重点是我们推出的 Medprompt,它结合了多种提示策略。Medprompt 极大地提升了 GPT-4 的性能,在 MultiMedQA 套件的九个基准数据集上均取得了最佳成绩。该方法在调用模型次数少得多的情况下,大幅超过了如 Med-PaLM 2 这类先进的专业模型。在 MedQA 数据集(USMLE 考试)上,使用 Medprompt 的 GPT-4 相比以往使用专业模型取得的最好方法,错误率降低了 27%,首次实现了超过 90% 的分数。除了医学领域,我们还展示了 Medprompt 在其他领域的泛化能力,并通过在电气工程、机器学习、哲学、会计、法律、护理和临床心理学等领域的能力考试上的应用,证明了这一方法的广泛适用性。
1 引言
人工智能研究长期以来一直致力于开发计算智能的核心原理,并应用这些原理来打造能够处理多种任务的学习与推理系统 [21, 22]。为了达成这个目标,如 GPT-3 [3] 和 GPT-4 [24] 等大语言模型(亦称基础模型)在众多任务中展现了令人惊叹的能力,而且无需经过大量特定训练 [4]。这些模型遵循“文本到文本”转换的原则 [31],通过对大量公共网络数据的广泛吸收,借助强大的计算能力和数据资源实现了大规模学习。其中部分模型经过特定的学习目标调整,使其能够根据提示执行各种通用指令。
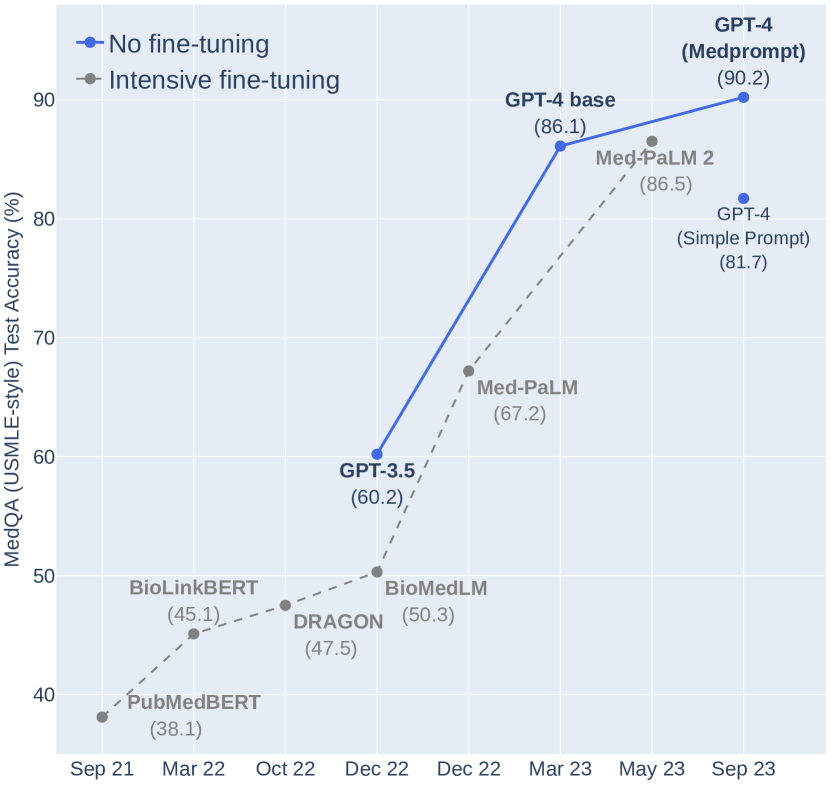
在评估基础模型(foundation models)的性能时,一个关键指标是预测下一个词的准确性。研究发现,随着训练数据、模型参数和计算能力的增加,下一个词预测的准确性也相应提高,这与通过实证研究得出的“神经模型缩放定律”(neural model scaling laws)一致 [3, 12])。但除了基础度量如下一个词预测外,基础模型在不同的规模阈值上还突然展现出许多解决问题的能力 [33, 27, 24]。
尽管我们看到了通用能力集的出现,但在没有对这些通用模型进行大量专业培训或微调的情况下,它们是否能在医学等专业领域挑战中取得卓越表现,这仍是一个疑问。大多数探索基础模型在生物医学应用上的能力的研究,都高度依赖于针对特定领域和任务的微调。例如,第一代基础模型中,PubMedBERT [10] 和 BioGPT [19] 这样的流行模型表明,领域特定预训练具有明显优势。然而,对于在更大规模下预训练的现代基础模型,这一点是否仍然适用尚不明确。
本文的重点是利用提示工程(prompt engineering)来指导大型基础模型(foundation model)在一系列医疗领域的挑战性基准测试中取得卓越表现。Med-PaLM 2 在 MedQA 和其他医学挑战问题上获得了具有竞争力的成绩,这得益于对 PaLM 这一通用大型基础模型进行了针对性的、成本较高的任务专用微调 [6] [29, 30]。此外,Med-PaLM 2 在医学基准测试上取得的成绩,还归功于运用了专家精心设计的复杂且高级的提示策略。比如,许多答案是基于一个复杂的 44 次调用的两阶段提示方案生成的。
在 GPT-4 于 2023 年 3 月公开后不久,本研究的几位合著者证明了这一模型在医学挑战基准测试中展现出的卓越生物医学能力是即刻可用的。为了展现 GPT-4 在专业医学领域的潜力,合著者特意采用了一种基本的提示策略 [23]。尽管那项研究展示了令人瞩目的成果,但关于 GPT-4 在没有经过额外专业训练或调整的情况下,其在特定领域能力的深度仍有待进一步探究。
我们在这里介绍了一项案例研究的成果和方法,主要聚焦于如何通过创新的提示策略引导 GPT-4 回答医学挑战问题。研究中,我们采用了最佳实践,考虑到评估环节的需求,特别是留出了一个独立的离线评估数据集。研究发现,通过创新提示,GPT-4 能展现其深层的专业能力。这一成就得益于我们系统地探索各种提示策略。作为设计原则,我们选择的策略成本低且未专门针对我们的基准测试定制。我们最终确定了一种针对医学挑战问题的顶尖提示策略,命名为 Medprompt。Medprompt 能在无需专家精心设计的情况下,激发 GPT-4 在医学领域的专家级技能,轻松超越所有标准医学问答数据集的现有基准。这一策略不仅超过了采用简单提示策略的 GPT-4,也大幅领先于如 Med-PaLM 2 这样的最先进专家模型。在 MedQA 数据集(美国医学执照考试)上,Medprompt 提高了绝对准确率 9 个百分点,首次使得这一基准的准确率超过 90%。
在我们的调查中,我们进行了全面的消融研究,揭示了 Medprompt 各组成部分的相对重要性。我们发现,结合上下文学习和思维链等方法,可以产生协同效果。最引人注目的发现是,要引导 GPT-4 这样的通用模型在专业医学任务上取得卓越成绩,最好的策略是使用通用提示。我们还发现,GPT-4 在设计自己的提示时,尤其是在构思用于上下文学习的思维过程时,能显著提高性能。这一发现与其他报告相呼应,表明 GPT-4 通过内省具有自发的自我改进能力,例如自我验证 [9]。
我们发现,自动化的思维逻辑推理减少了对特殊人类专业知识和医疗数据集的依赖性。因此,虽然这个项目被命名为 Medprompt,但其实它并不包括任何专门针对医学的成分。这一点源自于我们调查 GPT-4 在医学挑战问题上的能力时采用的研究方法和框架。如我们在 第 5.3 节 所讨论,这种方法也可以轻松应用于其他领域。我们提供 Medprompt 的详细信息,以便于未来的研究者指导通用的基础模型,使其能够提供专家级的建议。
2 背景
2.1 在医学挑战问题中的基础模型应用
在第一代基础模型时代,由于模型大小和计算资源有限,因此专注于特定领域的预训练显得更为重要。像 PubMedBERT [10]、BioLinkBERT [37]、DRAGON [36]、BioGPT [19] 和 BioMedLM [2] 等模型,都是利用领域特定数据源,如 PubMed 语料库和 UMLS 知识图谱,进行自监督学习目标 (self-supervised objectives) 的预训练。虽然这些模型规模较小,计算能力有限,但它们在生物医学自然语言处理 (NLP) 任务中展现出了卓越的性能。更为强大的通用领域基础模型,在医学挑战中展现了显著的性能提升,而且无需进行特定领域的预训练。
许多研究已经探讨了通用基础模型在医学领域挑战问题上的表现。例如,在 [17] 中,ChatGPT-3.5 被用来评估针对美国医学执照考试 (USMLE) 的问题,并在未接受特殊训练的情况下,表现达到或接近及格标准。而在 [23] 中,GPT-4 则通过简单的少样本 (5-shot) 提示,超过了 USMLE 及格分数 20 分以上。还有其他研究探讨了专门用医学知识微调过的基础模型的应用。
其他研究则着眼于结合明确的调整和医学知识的有效性。Med-PaLM 29 和 Med-PaLM 2 30 通过对拥有 5400 亿参数的 Flan-PaLM 进行精细调整,采用了指令提示的方法。在 Med-PaLM 的研究中,作者们让五位临床医生来准备他们指令提示微调的数据集。而 Med-PaLM 2 基于 PaLM 2,采用了全面的指令遵循微调方法,在医学问答数据集上取得了领先水平的表现。
我们重新评估了不依赖大量微调的通用基础模型的能力。我们探索了各种提示策略,旨在最有效地引导这些强大的通用基础模型在专业领域发挥出卓越性能。
2.2 提示策略
在大语言模型的应用中,提示 指的是我们提供给模型的输入信息,用来指导模型产生相应的输出。实证研究显示,所谓的基础模型(foundation models)在特定任务上的表现很大程度上受到提示方式的影响,而这种影响通常是出乎意料的。比如,最近的研究显示,在 GSM8K 基准数据集上,即使模型的学习参数不变,其表现也能有超过 10% 的波动 [35]。而提示工程 指的是设计有效的提示方法,让这些基础模型能更好地解决特定的问题。在这里,我们简要介绍几个关键概念,这些是我们所提出的 Medprompt 方法的基石。
上下文学习(ICL)是这类基础模型的一项核心能力,它使模型能够仅通过几个示例就解决新的任务 [3]。举个例子,我们可以通过在一个测试问题之前放置几个问题和期望的答案示例来创建一个 ICL 提示。这种方式无需更新模型的参数,但可以达到类似微调的效果。在少样本提示中选择的示例会大大影响模型的表现。在我们之前对 GPT-4 在医学问题挑战上的性能研究中 [23],我们专门采用了基本的上下文学习方法,比如固定的一次性和五次性提示,来展示 GPT-4 如何能被轻松引导以达到出色的表现。
思维链条(Chain of Thought, CoT)是一种提示方法,通过在给出样例答案前使用中间推理步骤来解决问题 [34]。它通过把复杂问题拆分成若干更小的步骤,有助于基础模型(如 GPT-4)给出更精准的回答。在 CoT 的增量式学习(ICL)提示中,我们把这些中间推理步骤直接融入到少样本演示当中。例如,在 Med-PaLM 项目中,一组临床医生被邀请制定专门针对复杂医疗问题的 CoT 提示 [29]。基于此,我们在本文中探讨了利用 GPT-4 自身,不依赖于人类专家,自动生成 CoT 提示的可能性。我们发现,通过使用来自训练集的[问题, 正确答案]配对,GPT-4 能够独立生成针对最复杂医疗挑战的高质量、详尽的 CoT 提示。
集成(Ensembling)是一种技术,通过结合多个模型运行的输出来获得更稳定或更准确的结果。这种技术通常采用平均、共识或多数投票等方法。采用自洽性(self-consistency)技术的集成方法 [32] 会通过采样生成多个结果,再将这些结果合并以找到一个共识。通过调节模型生成设置中的“温度”参数(代表随机性程度),可以控制输出的多样性,其中更高的“温度”意味着引入更多随机元素。此外,通过重排或打乱少样本提示的各部分,集成技术还能解决基础模型常见的顺序敏感问题 [26, 39],进而提高模型的鲁棒性。
虽然集成方法能够提升性能,但同时也会增加计算需求。举个例子,Med-PaLM 2 的“集群精炼”方法在回答一个问题时,需要进行多达 44 次的模型推理过程。考虑到这样的计算负担,我们在设计时遵循了一个原则,即采用更简单的技术来降低过度的推理成本。在第 5.2 节中,我们进行了一项消融研究,探讨了在增加计算负担的情况下进一步提升性能的可能性。
3 实验设计
我们首先对医疗挑战问题的数据集进行了概览,接着介绍了我们的测试方法。这种方法旨在避免由于在固定评估数据集上进行密集迭代而导致的过拟合问题。
3.1 数据集
我们在第5节报告的基准测试主要评估了 GPT-4 在 MultiMedQA 基准测试套件中包含的九个生物医学多项选择题数据集的表现 [29]。具体而言,这些基准测试包括:
-
MedQA [14] 包含风格类似于美国、中国大陆和台湾用于测试医学专家资质的医学执业考试题的多项选择题。为了与先前研究进行公平比较 [29, 30, 23],我们关注数据集中的美国部分,包含的问题都是用英文,且风格符合美国医学执照考试 (USMLE)。该数据集共包含 1273 个问题,每个问题都有四个选择答案。
-
MedMCQA [25] 展示了模拟和历史考题,风格与印度两所医学院的入学考试——AIIMS 和 NEET-PG 相似。我们报告的是数据集“开发”子集的基准测试结果(与之前的研究保持一致),该子集包含 4183 个问题,每个问题同样提供四个选择答案。
-
PubMedQA [15] 包含的测试要求根据提供的 PubMed 摘要上下文,对生物医学研究问题作出“是”、“否”或“可能”的回答。在 PubMedQA 的两种测试设置中,“需要推理”和“无需推理”各有不同的特点。在无需推理的设置中,会提供包含详细摘要解释的长答案。我们这里报告的是“需要推理”设置下的结果,在这一设置中,模型仅依据摘要中的上下文来回答问题。该数据集共包含 500 个问题。
-
MMLU [11] 是一个涵盖科学、技术、工程、数学(STEM)、人文学科和社会科学等领域的多任务基准套件,包括 57 个不同的数据集。根据先前的研究 [29],我们选取了 MMLU 中与医学相关的子集进行基准测试,包括临床知识、医学遗传学、解剖学、专业医学、大学生物学和大学医学等领域。
如第 5.3 节所述,我们可以通过测试 Medprompt 方法在医学挑战问题以外的其他领域,如护理能力考试等,来检验其在广泛应用中的有效性。我们将此方法应用于两个专注于国家护士执照考试(NCLEX)问题的护理数据集,以及 MMLU 中的其他六个包括会计和法律等主题的数据集。这些数据集的具体详情在第 5.3 节中有详细介绍。
3.2 有效的测试方法论
在进行提示引导和上下文场景学习时,尽管这不会改变模型参数,但特定的提示策略选择可视为整个测试过程的一个重要配置或超参数 (hyperparameter)。因此,在训练和测试过程中,我们必须小心避免过拟合 (overfitting),以确保结果不仅局限于当前的训练和测试集,而能普遍适用于其他场景。这种对基础模型性能研究中过拟合问题的关注,与传统机器学习在超参数优化过程中的类似担忧不谋而合 [8]。我们的目标是避免在提示工程 (prompt engineering) 过程中产生类似的过拟合现象。
直观上,比如说通过特定基准问题查找表来设计提示,这样的方法在这些问题上的表现自然会比未遇到的问题要好得多。在传统机器学习中,解决这一问题的常用方法是创建“测试集” (test sets),这些测试集只在模型选择过程结束后进行评估。我们采纳了这种在机器学习研究中重要的稳健测试方法,从每个基准数据集中随机划分出 20% 作为“不可见”分割,直到最终测试阶段前完全不予考虑。也就是说,这部分“不可见”数据一直保持隐藏,直到测试的最后阶段才予以揭示。在提示工程过程中,我们不会对这些数据进行检查或优化。为了简化操作,我们对 MultiMedQA 中的每个数据集都采用了同样的方法,尽管许多数据集在发布时并没有指定专门的训练/测试分割。在第 5.1 节,我们展示了 Medprompt 在 MultiMedQA 数据集的“可见”与“不可见”分割上的分层表现。我们发现两者之间的表现非常相似,而且 GPT-4 结合 Medprompt 在“不可见”、被保留的数据上的表现甚至略有提升,这表明我们的方法有望在“开放世界”的类似问题上表现良好。到目前为止,我们还没有看到以往研究中采用过类似的“不可见”测试方法。
4 提示技术的威力:探究与成果
在本节中,我们将详细介绍 Medprompt 采用的三项核心技术:动态选择少样本(Dynamic few-shot selection)、自我生成的思考过程链(self-generated chain of thought)以及选择性混合集成(choice shuffle ensembling)。我们将分别讨论这些技术,并审视我们如何将这三种方法融合,创造出综合的 Medprompt 方法。
4.1 动态选择少样本(Dynamic Few-shot)
少样本(Few-shot)学习 [3] 被认为是最有效的上下文学习方法之一。在这种方法中,通过展示少量示例,基础模型能迅速调整自身以适应特定的领域,并学会按照任务的格式进行操作。为了简化操作和提高效率,通常会在针对某个特定任务的提示过程中使用固定的少样本示例;这些示例在不同的测试中保持不变。因此,选择的这些示例必须具有广泛的代表性,并能涵盖多种文本示例。一种实现这一目标的方法是让领域专家精心挑选出具有代表性的典型示例 [29]。但这种方法无法保证挑选出的固定少样本示例能够全面代表每一种测试情境。另一方面,如果条件允许,任务训练集可以成为获取少样本示例的经济且高效的来源。如果训练集规模足够大,我们可以针对不同的任务输入选择不同的少样本示例。这种方法被称为动态少样本示例法。这种方法运用了一种机制,根据案例的相似性来挑选示例 [18]。在 Medprompt 项目中,我们采取了如下步骤来挑选代表性的少样本示例:对于一个给定的测试案例,我们选取了 个在嵌入空间中与之语义上最接近的训练案例,这是通过 -NN 聚类实现的。具体来说,我们首先使用 text-embedding-ada-00211 将训练和测试问题转化为向量表示。然后,对于每个测试问题 ,我们会从训练集中找出与之最接近的 个问题 (基于 text-embedding-ada-002 嵌入空间的距离)。
在使用余弦相似度等预定义的相似度度量时,邻居的排序方式是:当 时,满足 。与传统的微调方法相比,动态少样本学习 (Dynamic few-shot learning) 利用了训练数据,但不需要对模型参数进行亿级别的更新。
4.2 自生成的思考链
![图 2:比较了专家设计的和 GPT-4 生成的思考链(CoT)提示。利用训练集中的 [问题,正确答案] 对,GPT-4 能够生成适用于少样本 CoT 示范的详尽解释。](https://ar5iv.labs.arxiv.org/html/2311.16452/assets/x3.png)
思考链 (Chain-of-thought,CoT) [34] 采用像“让我们逐步思考”的自然语言陈述,明确引导模型逐步进行中间推理。这种方式极大地提高了基础模型在复杂推理任务上的表现。大多数思考链方法都是由专家手动编写含思考链的少样本例子进行提示[30]。与此相反,我们探索了一种自动创建思考链示例的方法,而不是依赖人类专家。我们发现,仅需通过以下方式提示 GPT-4,就能为训练样本生成思考链:

自我生成的思考链模板
## 问题:{{问题}}
{{答案选项}}## 答案
模型生成的思考链解释因此,答案是[最终模型答案(如 A、B、C、D)]
图 3:用来自动提示基础模型生成思考链解释的模板(详见第 4.2 节)。
这种方法面临的一个关键挑战在于,自我生成的思维链 (CoT) 推理过程可能隐含错误或虚构的推理链条。为了缓解这种担忧,我们让 GPT-4 生成推理理由,并估计这一推理链最可能得出的答案。如果这个答案与真实答案标签不一致,我们就会完全丢弃这个样本,因为我们认为这种推理是不可靠的。虽然错误或虚构的推理有时也能得出正确的最终答案(即误判的情况),但我们发现,这种简单的答案核实步骤有效地过滤了误判。
我们还发现,与 Med-PaLM 2 中使用的 CoT 示例相比 [30],GPT-4 生成的 CoT 推理理由不仅更长,而且提供了更细致的逐步推理逻辑。这些由临床专家手工编写。与此同时,最新的研究 [35, 7] 也表明,基础模型生成的提示比专家撰写的更为出色。
4.3 选项洗牌集成法
虽然 GPT-4 在处理多项选择题时的偏见问题不如其他基础模型那么严重,但它仍然倾向于在无关答案内容的情况下偏爱某些选项,即存在位置偏见现象 [1,16,40]。为了降低这种偏见,我们提出一种策略:对选项进行洗牌,然后检验在不同选项排序下答案的一致性。我们采用了选项洗牌和自我一致性提示的方法。自我一致性提示 [32] 指的是在一定温度值 下多次提示时,用多种推理路径替换掉传统的单一路径或贪婪解码方式,这样做能在回答中引入一定的随机性。通过选项洗牌,我们在生成每条推理路径前改变答案选项的顺序。然后,我们挑选出最为一致的答案,也就是对选项顺序变化最不敏感的答案。选项洗牌还能增加每条推理路径的多样性,进一步提升最终结果的质量,超越了仅靠温度抽样所能达到的效果 [5]。在生成训练样本的中间链式推理 (CoT) 步骤时,我们也采用了这种技术。对每个样本,我们改变选项顺序,为每种情况生成一个链式推理。我们最终只保留那些得出正确答案的样本。
4.4 整合一切:Medprompt
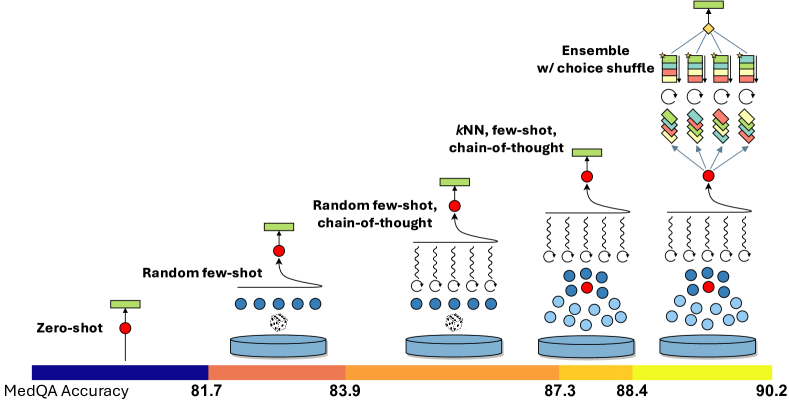
Medprompt 结合了智能挑选的少量样本示例、自主生成的思考步骤,以及基于多数票决定的综合策略。这些方法的结合构成了一个适用于多种情境的高效提示策略。图 4 显示了 Medprompt 在 MedQA 基准测试上的整体表现,以及每个单独部分如何增强这一策略的效果。我们在算法 1 中提供了这种策略的具体算法描述。
Medprompt 分为两个阶段:预处理阶段和推理步骤。在推理步骤中,会对测试案例生成最终预测。预处理阶段包括使用一个轻量级的嵌入模型(embedding model),对训练数据集中的每个问题进行处理,生成一个嵌入向量(见算法 1 的第 4 行)。我们采用 OpenAI 开发的 text-embedding-ada-002 模型来创建这些嵌入向量。针对每个问题,GPT-4 负责生成一条推理链和对最终答案的预测(第 5 行)。如果生成的答案正确并且与真实答案相符,我们就会保存该问题及其嵌入向量、推理链和答案;如果答案错误,我们则将该问题从检索池中剔除,因为我们认为如果最终答案错误,那么模型的推理过程不可靠(第 6-7 行)。
在推理阶段,给定一个测试问题,我们会使用与预处理阶段相同的嵌入模型对测试样本进行再嵌入,并通过 NN 算法从预处理池中寻找相似问题(第 12-13 行)。这些问题及其由 GPT-4 生成的推理链被用作 GPT-4 的上下文(第 14 行)。接着,测试问题和相关的答案选项被添加到最后,作为最终的提示信息(第 17 行)。遵循之前的少数示例(few-shot exemplars),模型接着生成一条推理链和一个候选答案。最后,我们进行一个集成过程,即重复上述步骤多次,通过打乱测试问题的答案选项来增加答案的多样性(第 15-16 行),具体细节见第 4.3 节和图 4。为了确定最终的预测答案,我们会选择出现频率最高的答案(第 20 行)。
算法 1 描述了 Medprompt 的算法规范,与图 4 中展示的策略视觉表现形式相对应。
1: 输入:开发数据集 ,测试问题
2: 预处理步骤:
3: 对于数据集 中的每个问题 执行以下操作:
4: 为问题 生成一个嵌入向量 。
5: 利用大语言模型 (Large Language Model, LLM) 产生思维过程 和相应答案 。
6: 如果答案 正确,则:
7: 保存嵌入向量 、思维过程 和答案 。
8: 结束该步骤
9: 结束所有问题的处理
10:
11: 推理阶段:
12: 为测试问题 计算嵌入向量 。
13: 使用 K-最近邻算法 (KNN) 和余弦相似度函数,从预处理的训练数据中选取 5 个与测试问题 最相似的实例 ,其中余弦相似度计算为:。
14: 将这 5 个实例整理成大语言模型 (LLM) 使用的上下文 。
15: 执行以下步骤 5 次:
16: 随机排列测试问题的答案选项。
17: 借助大语言模型 (LLM) 和上下文 ,生成思维过程 和答案 。
18: 结束重复步骤
19: 计算所有生成答案 的多数票结果:
其中 代表集合 中出现频率最高的元素。 20:输出:最终答案 。
我们报告的 Medprompt 研究结果采用了 5 个 NN 选定的少样本 (few-shot) 示例和 5 个并行 API 调用,作为我们的选择-洗牌 (choice-shuffle) 集成策略的一部分。我们发现这种策略在降低推理成本和提高准确度方面取得了良好的平衡。
我们的深入分析(详见第 5.2 节)表明,通过增加这些超参数值,我们能够进一步提高性能。例如,将少样本示例增至 20 个,集成项目增至 11 个,我们在 MedQA 上的表现进一步提高了 ,达到了新的行业领先水平,即 。
值得一提的是,尽管 Medprompt 在医学领域的基准数据集上表现出色,但这种算法的用途是通用的,不仅限于医学领域或多项选择式的问答。我们认为,结合精心选择的少样本示例、自生成的思维链条推理步骤,以及基于多数投票的集成方法这一通用框架,可以广泛应用于其他问题领域,包括更开放的问题解决任务(关于如何将这个框架应用到多项选择问题之外的更多细节,请参见第 5.3 节)。
5 结果
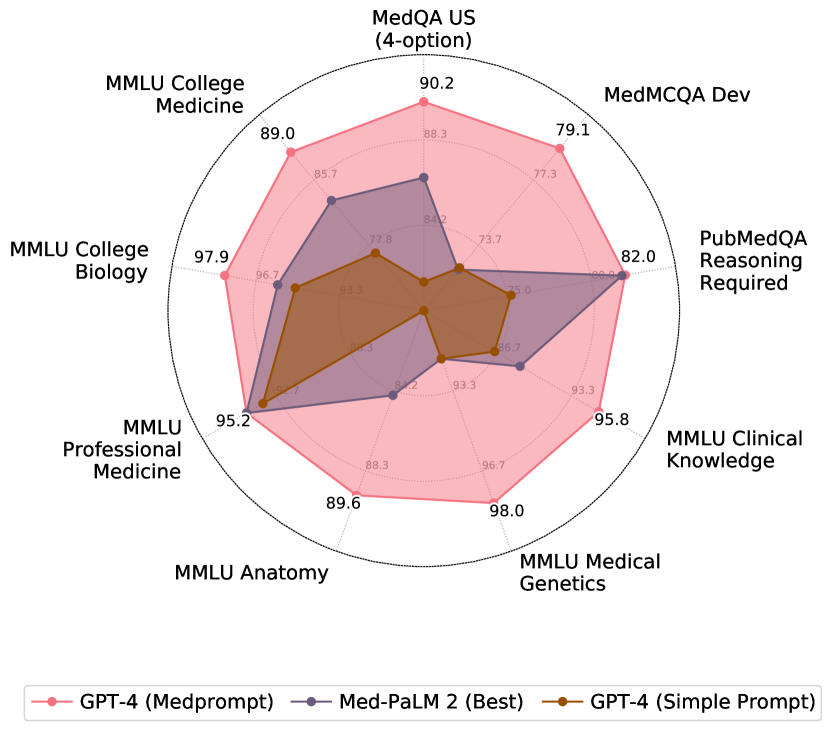
表 1: 不同基础模型在 MultiMedQA 多项选择题部分的性能对比 [29]。GPT-4 配合 Medprompt 在所有评测中均优于其他模型。
| 数据集 | Flan-PaLM 540B* | Med-PaLM 2* | GPT-4 | GPT-4 (Medprompt) |
| (选取最优) | (选取最优) | (少样本 (Few-shot)) | (使用 Medprompt) | |
| MedQA | ||||
| 美国医学考试 (4 选项) | 67.6 | 86.5 | 81.4 | 90.2** |
| PubMedQA | ||||
| 需要逻辑推理 | 79.0 | 81.8 | 75.2 | 82.0 |
| MedMCQA | ||||
| 开发集 | 57.6 | 72.3 | 72.4 | 79.1 |
| MMLU | ||||
| 临床医学知识 | 80.4 | 88.7 | 86.4 | 95.8 |
| 医学遗传 | 75.0 | 92.0 | 92.0 | 98.0 |
| 解剖学 | 63.7 | 84.4 | 80.0 | 89.6 |
| 专业医学知识 | 83.8 | 95.2 | 93.8 | 95.2 |
| 大学生物学 | 88.9 | 95.8 | 95.1 | 97.9 |
| 大学医学 | 76.3 | 83.2 | 76.9 | 89.0 |
* 本段落内容源自于 [29] 和 [30]。所谓的“选择最佳”策略,是指在 Med-Palm 研究中采用的一种方法:执行多种不同的策略,并从中挑选出对每个数据集表现最优的方法。Flan-PaLM 540B 和 Med-PaLM 2 也同样对这些基准数据集的子集进行了专门调整(fine-tuned)。与此相反,GPT-4 在所有数据集中均采用了一种统一且一致的策略。
** 如第 5.2 节 所讨论,我们通过设置 并采用 11 倍集成步骤,实现了 90.6% 的成绩。90.2% 则代表了采用 的少样本 (few-shot) 示例和 5 倍集成的“标准” Medprompt 性能。
利用第 4 节 中描述的提示工程 (prompt engineering) 方法及其有效组合作为 Medprompt,GPT-4 在 MultiMedQA 的所有九个基准数据集上均实现了领先水平的表现。
5.1 在未见数据上的表现
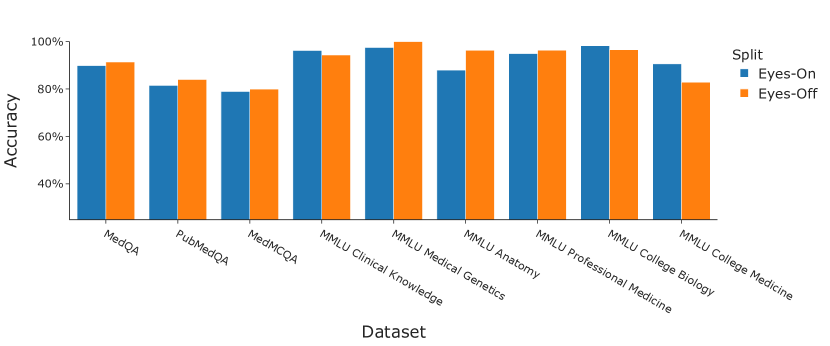
如第 5.1 节 所述,我们对 Medprompt 的提示策略在各个基准数据集中独立的未见子集上进行了评估,以此检验是否存在过拟合的风险。在已见数据上,GPT-4 结合 Medprompt 的平均效果为 90.6%,而在未见数据上这一数字为 91.3%,这暗示了我们的提示策略很可能没有在 MultiMedQA 数据集上造成过拟合。作为额外证明,我们在 9 个基准数据集中的 6 个上,发现在未见数据上的表现有所提升(见图 5)。
5.2 通过削减实验洞察 Medprompt 组件的影响
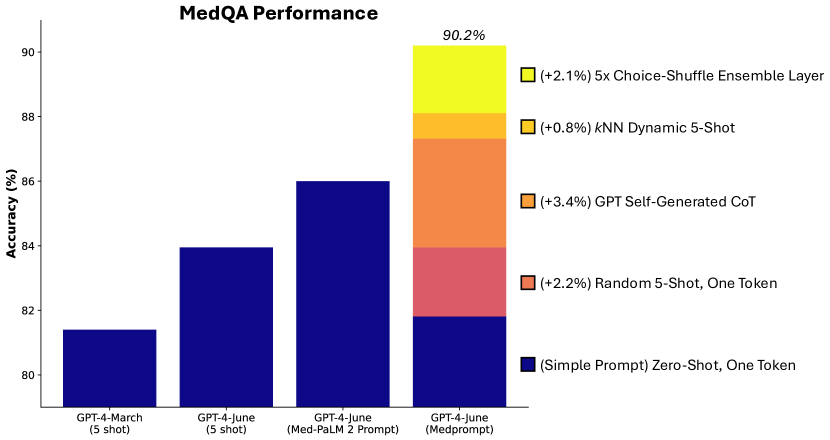
图 6 显示了在 MedQA 数据集上进行的削减实验的结果,目的是理解 Medprompt 中每个技术的相对重要性。蓝色条形图代表以前的研究 [23],为 Medprompt 方法设定了基准。接着,我们逐一加入每种技术,并测量每次增加的技术对性能的相对提升。正如第 4.4 节 所述,我们的初始 Medprompt 策略采用了 5 个基于 kNN 的少样本 (few-shot) 示例,并整合了 5 次 API 调用。我们还试验了最多 20 个少样本示例和多达 11 步的整合方法。我们发现,随着更多少样本示例和更多整合步骤的增加,性能确实略微提高至 90.6%,这意味着在基准测试上可能还有进一步改进的空间,但相应地会增加推理时间的成本和复杂度。正如第 4 节 所述,引入思考链条步骤对性能贡献最大 (),其次是少样本提示和选项随机整合 (每个 )。
我们采用的技术方法并不是统计上彼此独立的,因此检验每项技术的贡献所采用的顺序非常关键。在这项技术削减分析中,我们所选择的顺序带有一定的主观性,主要是基于每项技术引入的复杂程度。如果从理论上更加严谨地进行削减分析中的功劳分配,应当考虑计算博弈论中的沙普利值 (Shapley values) [28],这意味着需要进行大量的模型评估,以测试所有可能的技术组合顺序。我们将这部分工作留给未来,并鼓励读者把这些削减研究中的数据视为对各技术相对贡献的合理估算。
| MedQA | |
| US (4-option) | |
| 来自 [30] 的专家设计的 CoT 提示 | 83.8 |
| GPT-4 自产生的 CoT 提示 | 86.9 (+3.1) |
表 2: 对比专家设计和 GPT-4 自动产生的思路链 (CoT) 的削减分析。两者均采用固定的 5-shot 示例,不结合其他技术。
除了一系列逐步的改进之外,我们还对比了在 Med-PaLM 2 中应用的专家设计的思路链 (Chain of Thought,CoT) 提示和 GPT-4 自动生成的 CoT 提示(见第 4.2 节)。我们评估了 GPT-4 使用这两种提示的效果,均为固定的 5-shot 示例,且未采用任何增强技巧。表 2 显示了它们在 MedQA 数据集上的准确率表现。GPT-4 自动生成的 CoT 在准确率上比专家设计的 CoT 高出了 3.1%,表现更为出色。我们发现,与 Med-PaLM 2 中的专家设计的 CoT 相比,GPT-4 生成的 CoT 在推理过程中更加详尽,展现出更精细的分步逻辑。这可能是因为 GPT-4 生成的 CoT 更贴合模型自身的优势和局限,从而在与专家设计的 CoT 的比较中表现更佳。另一个可能的原因是,专家设计的 CoT 可能隐含了一些假设或偏见,这些可能不适用于 MedQA 数据集中的所有问题,而 GPT-4 生成的 CoT 则可能更加中立,更适用于多种不同的问题。
5.3 普适性: 跨领域探索 Medprompt
我们认为,Medprompt 所使用的提示工程技术,结合了动态的少样本 (few-shot) 选择、自我产生的思考链路、以及选择洗牌式的集成方法,具有广泛的应用前景。这些技术并非专门为 MultiMedQA 基准数据集设计。为了证明这一点,我们将 Medprompt 的最终方法应用于 MMLU 基准套件中的六个其他多样化数据集,这些数据集涉及电气工程、机器学习、哲学、专业会计、专业法律和专业心理学等领域的挑战性问题。我们还引入了两个额外的数据集,这些数据集中包含的是美国国家理事会执业考试 (NCLEX) 风格的问题,这是成为美国注册护士所必须通过的考试。
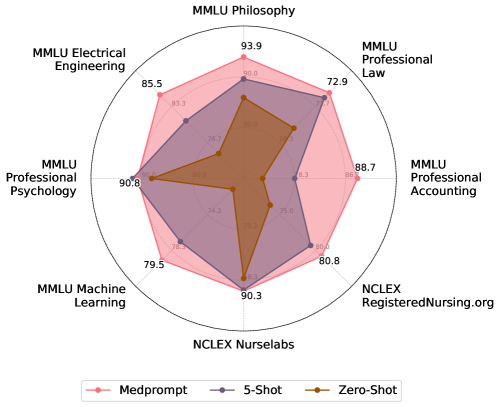
图 7 显示了 GPT-4 在多样化的领域外数据集群中,结合 Medprompt 进行零样本 (Zero-shot) 和五样本 (Few-shot) 方法的表现(采用随机示例选择)。在这些数据集群上,Medprompt 在零样本基准方法上平均实现了 的性能提升。作为对比,在本文研究的 MultiMedQA 数据集上,Medprompt 相对于相同的零样本基准实现了 的提升。我们特别强调,这种跨不同分布数据集的一致提升,展示了 Medprompt 方法的广泛适用性。虽然超出本文讨论范围,我们相信 MedPrompt 的基础框架——结合少样本学习和思维链推理,嵌入到集成层中——在轻微的算法调整后,能够广泛适用于多种场景,超出多项选择问题/答案格式的限制。例如,在开放式文本生成场景中,集成层可能不会简单地依靠多数投票,而可能采用基于嵌入空间的答案接近度来进行答案聚合。另一种方法是将 个生成的文本片段以结构化方式组合,让模型从中选择最可能的选项,类似于 Ensemble Refinement 方法 [30]。将这些算法在其他场景中的适用性探索留作未来的研究方向。
6 限制与风险
我们的研究突显了通过系统性的提示设计,如何有效地指导通用型的大语言模型 (Large Language Model),提升 GPT-4 在医学挑战问题上的专业能力。接下来,我们将分享我们的评估中发现的局限性和未来的发展方向。
由于大语言模型是在庞大的互联网规模数据集上进行训练的,它们在基准测试问题上的出色表现可能源于记忆或信息泄露效应,即测试样本可能在训练期间已被模型接触过。在我们之前的研究中,我们评估了 GPT-4 在本文研究的数据集上的表现,并使用了基础提示方法 [23]。我们采用了黑盒测试算法 (MELD),但未能发现记忆的迹象。然而,像 MELD 这样的黑盒测试方法无法完全确保数据之前未被模型见过。我们还对 GPT-4 在美国医学执照考试(USMLE)的问题上进行了评估,这些问题是受付费保护的,不在公开互联网上,结果同样显示了出色的表现 [23]。在本研究中,我们遵循了机器学习的标准最佳实践,以控制在提示设计过程中的过拟合和信息泄露(参见章节 5.1)。尽管如此,训练过程中基准测试数据可能被污染的问题仍然引起关注。
进一步地,我们注意到,尽管 GPT-4 在 Medprompt 测试中表现出色,但这并不意味着它在现实世界的医疗领域任务中同样有效 [23]。虽然我们对于能够将基础模型引导成为各个基准测试中的顶尖专家感到兴奋,但我们对于仅凭提示策略和模型输出的表现就认为这些方法在实际医疗实践中(不论是自动化还是辅助医疗专业人员处理行政任务、临床决策支持或患者互动)有实际价值还持保留态度。要明确的是,我们和其他研究者所研究的医学挑战问题主要是为了检验人类在特定领域的能力而设计的,通常这些能力测试是以多项选择题的形式出现的。虽然这类挑战问题是一种常见的评估方法,涵盖了广泛的主题,但它们并不能完全反映医疗专业人员在实际工作中所面临的医疗任务的范围和复杂性。因此,将这些测试视作实际能力的代理以及专注于多项选择题式的答案,在将特殊基准上的卓越表现转化为现实世界的实际表现时存在局限性。此外,虽然我们认为 MedPrompt 策略可以适用于非多项选择题的环境,但在本研究中我们并未对这些可能的适应性进行具体测试。
我们还要指出,基础模型可能产生错误信息(有时称为“信息幻影”),这可能影响其生成的内容和建议的质量。尽管通过改进提示策略可能减少信息幻影并提高整体准确度,但这也可能使剩余的信息幻影更难被察觉。值得期待的发展方向包括对生成内容进行概率校准,为最终用户提供可靠的输出信心度量。在我们之前的研究中,我们发现 GPT-4 在多项选择题测试中的校准表现良好,能够提供可信的信心度量 [23]。
我们还必须警惕基础模型输出中存在的偏见问题。目前,我们尚不清楚在追求顶尖性能的优化过程中,这些偏见如何影响到其他目标,比如公平表现。要平衡追求整体准确性和不同子群体中的公平表现至关重要,以免加剧现有医疗领域的不平等。之前的研究已经强调了理解和解决 AI 系统中偏见的重要性。在模型优化、微调和构建有效提示(prompt engineering)的过程中,偏见和公平性的问题依然紧迫且相关 [13, 20, 38]。
7 总结与结论
本研究探讨了通过提示机制激发 GPT-4 在医学领域挑战中的专家级能力,无需特别微调或依赖人类专家为提示构建提供专业知识。我们分享了评估性能的最佳实践,特别强调了在非实时监控的数据集上评估模型能力的重要性。我们回顾了一系列的提示策略,并展示了如何通过系统化探索结合这些策略。我们发现,通过采用高效和强大的提示策略来引导 GPT-4,可以显著提升专家级性能。
我们介绍了如何将一系列提示方法组合成 Medprompt,这是我们发现的用于在医学领域挑战中引导 GPT-4 的最佳策略。我们展示了 Medprompt 如何引导 GPT-4 在所有标准医学问答数据集中取得领先成绩,超越了通过专业医学数据微调并由专家临床医生编写提示的专家模型 Med-PaLM 2 的表现。Medprompt 在 MedQA 上释放了专业技能,实现了精确度的显著提升,首次在该基准测试上超过了 90%。
在我们的探索中,我们发现 GPT-4 能够创建定制的“连续思考提示”(chain-of-thought prompts),其效果超过了专家手工制作的提示。我们通过“消融研究”(ablation studies)深入了解 Medprompt 策略各个组成部分的独特贡献,这些研究显示了每个部分的相对重要性。为了避免过拟合,我们特别设立了“闭眼评估案例库”(eyes-off evaluation case libraries),结果显示 Medprompt 的卓越表现并非由于过拟合。我们还研究了 Medprompt 在医学之外的六个领域——电气工程、机器学习、哲学、会计、法律、护理和临床心理学——的通用性,通过能力评估证明了其在各个领域的适用性。不同领域的发现表明,Medprompt 及其衍生产品在释放基础模型(foundation models)的专业能力方面具有重要价值。我们看到了进一步精炼提示的潜力,尤其是将通用的 MedPrompt 策略应用于非选择题的领域。例如,我们认为有机会利用 GPT-4 创作强大的连续思考示例,并在提示过程中使用这些示例。未来的研究方向包括进一步探索基础模型在反思和创作“少样本”(few-shot)示例方面的能力,并将其融入提示中。
尽管我们的研究主要探讨了通用模型的提示能力,我们认为微调和对基础模型进行其他参数更新是探索的重要方向,这些方法可能与提示工程协同作用,共同提升性能。我们认为,在医疗等高风险领域,充分发掘基础模型的潜力需要谨慎地探索这两种方法。
致谢
我们感谢 Sébastien Bubeck、Peter Durlach、Peter Lee、Matthew Lungren、Satya Nadella、Joe Petro、Kevin Scott、Desney Tan 和 Paul Vozila 提供的讨论和反馈。