深入分析 GPTs 在机器翻译中的上下文学习[译]
摘要
最近,人们在使用如 GPT-3 这样的大语言模型进行机器翻译时,主要关注如何选择少量的示例进行提示。在这项研究中,我们对一些高质量的示例进行了微调,来深入探讨在实际翻译中,这些示例是如何起作用的。我们的发现是,当我们对输入和输出进行不同的微调时,会得到非常不同的翻译效果。特别是,改变输入部分对翻译的影响非常小,但是改变输出部分可能会大大降低翻译的质量。这意味着,翻译的输出内容是决定翻译质量的关键因素。基于这一发现,我们提出了一种新方法,叫做 Zero-Shot-Context,它可以在没有任何示例的情况下,自动提高翻译的质量。我们的实验结果显示,使用这种方法,GPT-3 的翻译效果得到了明显的提升,甚至可以与有示例提示的翻译相媲美。
1 引言
近期,学界对于大语言模型 (LLMs) 的示范准确性在引导过程中的重要性提出质疑 (Min et al., 2022)。有研究指出,LLMs 的实际应用潜力可能远超我们现在所观察到的 (Min et al., 2022; Kojima et al., 2022)。要最大化这一潜力,我们需要更好地理解示范的各个属性对任务性能的影响,并模拟这种学习环境。本研究主要关注了如何通过上下文学习来提高机器翻译 (MT) 的质量。我们并不是要找出最佳的学习示例,这一话题已经被深入探讨,并为 LLMs 提供了更好的翻译建议 (Vilar et al., 2022; Agrawal et al., 2022)。我们的主要贡献有:
-
我们深入研究了 GPT 系列 LLMs 中的示范属性,尤其关注了输入与输出之间的关系。研究结果显示,目标文本的内容对学习过程影响最大,而原始文本则影响较小。
-
基于以上发现,我们提出了一种新方法 Zero-ShotContext 提示,能够更高效地提供学习信号,而不依赖于传统的输入 - 输出示例。这种方法极大提升了 GPT-3 的性能,使其能够与其他方法相媲美。
2 相关研究
我们的研究涉及到两个主要方向:LLMs 的翻译提示技术以及上下文学习的分析。下面,我们将深入探讨这两个方向的相关研究。
LLM 在机器翻译中的提示:LLM 在少量示例提示的情况下,已经达到了与最前沿技术相媲美的翻译效果 (Hendy et al., 2023; Lin et al., 2022)。在机器翻译的提示技术中,大部分研究都集中于选择哪些实例作为提示的示例。Vilar 等人 (2022) 对 PaLM 进行了实验 (Chowdhery et al., 2022),发现示例的质量是影响少量示例提示效果的关键。Agrawal 等人 (2022) 对 XGLM 进行了研究 (Lin et al., 2021),得出了翻译的质量和示例的领域都至关重要。与此不同,我们的研究目标是探索如何改变高质量、领域相关的示例,以更好地理解示例属性在翻译中的上下文学习效果。

表 1:我们对四种不同的扰动方式进行了研究。这些扰动方式主要应用在抽象的源 - 目标示例序列上。有趣的是,尽管 "Jumbled Source" 和 "Jumbled Target" 都对源 - 目标的关系产生了影响,但它们在实际的学习过程中产生的效果是不同的。
探索上下文学习:对上下文学习进行深入探索是目前的研究热点 (Xie et al., 2021; von Oswald et al., 2022; Akyürek et al., 2022; Dai et al., 2022)。Min 等人 (2022) 提到,在开放式分类任务中,示例中的标签准确性并不那么重要,但 Yoo 等人 (2022) 指出否定的标签确实很关键。与此同时,我们的实验在任务选择和示例扰动方式上与上述研究有所不同,我们专注于翻译这一任务,它有着复杂的输出空间,并探索了不同的示例扰动方法。
3 为何示范很重要
当我们要求 LLMs 完成特定任务时,它们会根据示范(与任务相关的示例)和测试输入来给出答案。我们的观点与 Min 等人 (2022) 保持一致,认为翻译任务的示范有四个重要方面:输入与输出的关系、输入的内容、输出的内容以及格式。为了更好地理解这些,我们研究了如 GPT3 这样的 LLMs 在翻译时如何使用示范。我们对示范的内容、输出内容以及它们之间的关系进行了对比。
模型:我们主要关注 text-davinci-002,这是当前公认的最强大的 LLM 模型 (Liang 等,2022)。同时,我们也探讨了其他几个版本,如 text-davinci-001、text-curie-001 以及较新的 text-davinci-003。
数据来源:我们选择了 WMT’21 的新闻翻译数据 (Barrault 等,2021) 进行实验,涵盖了英德、德英、英俄和俄英四种语言组合。在这些实验中,text-davinci-002 的表现与 WMT-21 的最佳模型相当 (Tran 等,2021),只需要八个示范。在 Table 2 中,我们列出了两种模型在 8 个示范的测试结果,而在每个测试集中,我们都选择了 100 个样本来进行特别的实验。
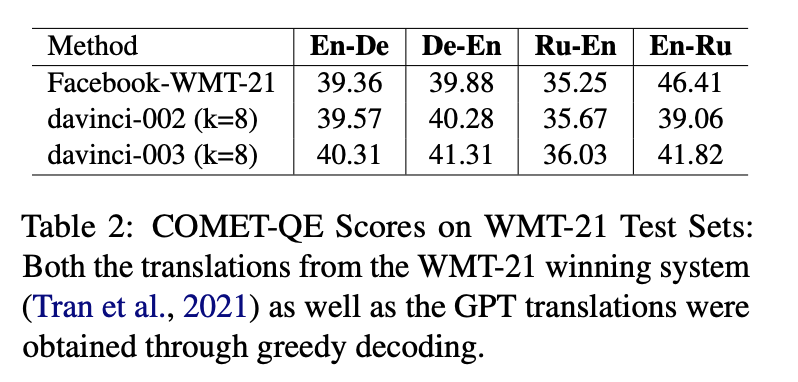
表 2:在 WMT-21 的测试集上,我们对 COMET-QE 的得分进行了评估。无论是 WMT-21 获胜的系统(由 Tran 等人于 2021 年提出)还是 GPT,其翻译都是通过一种叫做贪婪解码的方法获得的。
如何提示:Vilar 等人 (2022) 认为,对于少数提示的翻译任务,格式选择并不重要。因此,我们采用了一个常用的格式,即 [Source]:ABC (\n) [Target]:DEF,其中 Source 和 Target 分别代表不同的语言。同时,我们还选取了一些高质量的示范对,这些示范对都来自于开发数据集。
评估方式:为了避免在评估时受到参考资料的偏见影响,我们使用了一种先进的评估方法 COMET-QE,这种方法被证明在评估翻译质量时非常有效。但这个方法有个小问题,如果翻译的内容和原文是同一种语言,它会认为翻译是正确的。为了解决这个问题,我们使用了一个工具来检测翻译的语言,如果翻译和原文是同一种语言,我们就认为这个翻译是错误的。
实验 1:我们对原文进行了四种修改,并看看这些修改会对翻译产生什么影响。我们把原文和翻译的对应关系打乱、把原文的词序打乱、把翻译的词序打乱、以及把翻译的词序完全反过来。
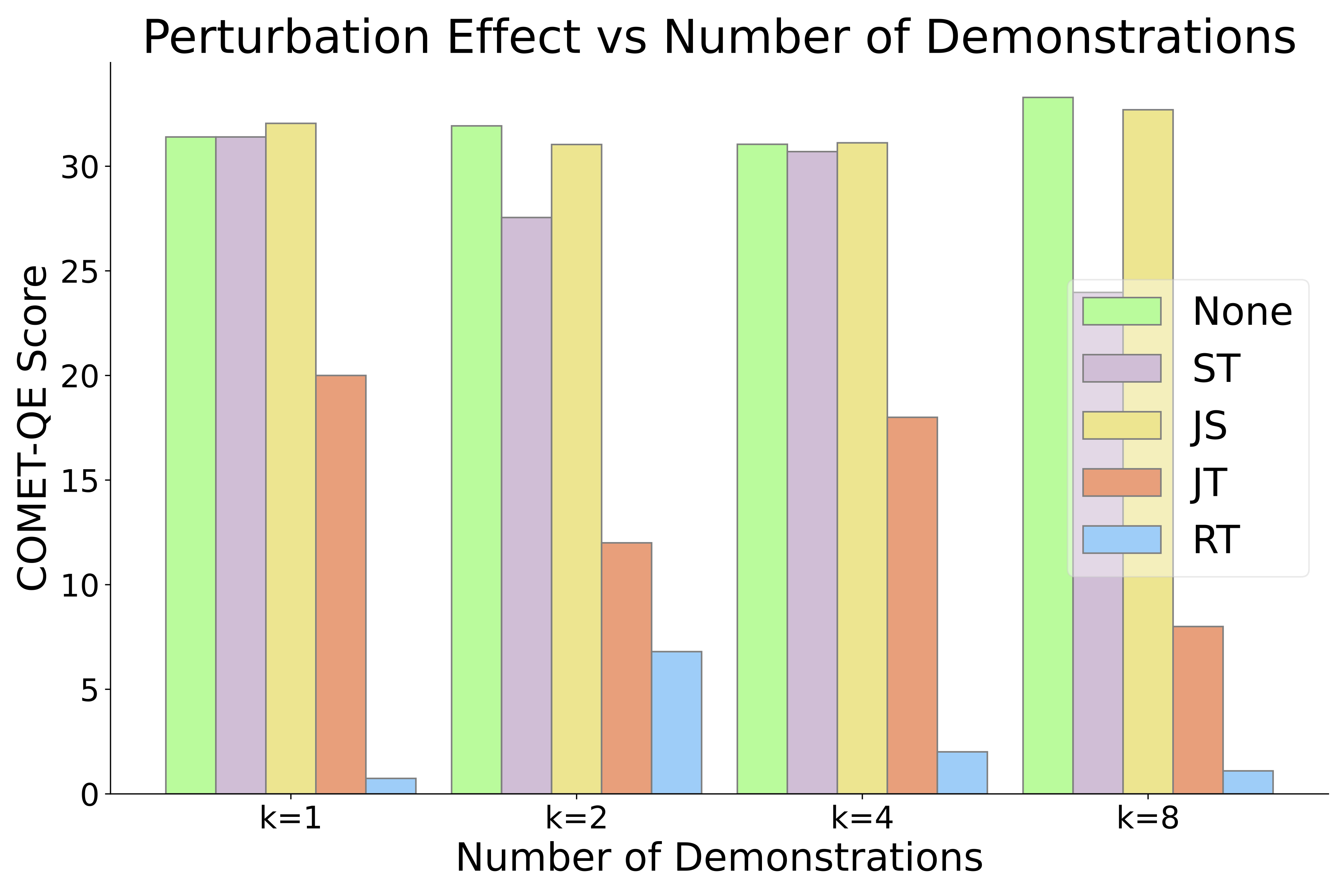
图 1:对 WMT-21 英德测试集进行的扰动实验。发现源语言和目标语言的扰动影响是不对称的,尽管两种情况下的输入 - 输出关系都受到很大的影响。
实验结果:我们发现,打乱原文和翻译的对应关系,以及打乱翻译的词序,都会对翻译质量产生很大的影响。尤其是打乱翻译的词序,这种影响随着我们修改的次数增加而增大。但是,如果只是打乱原文的词序,对翻译的质量几乎没有影响。
实验 2:我们又做了一个类似的实验,但这次我们用了四种不同的语言对。
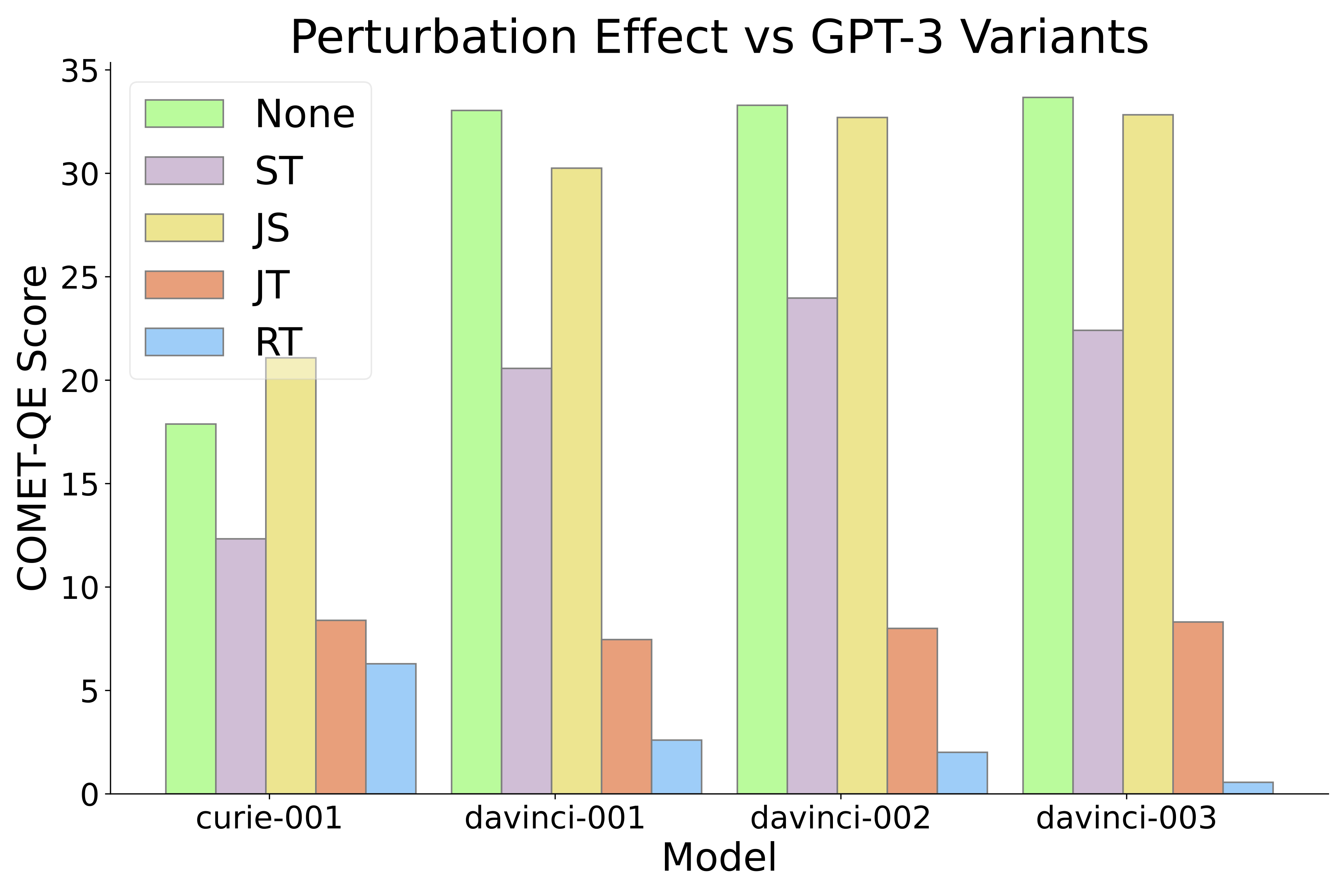
图 2:在 WMT’21 的多种语言组合中,针对 text-davinci-002 进行的扰动实验,实验在 k=8 的少量提示下进行。结果显示,无论是哪种语言组合,源和目标的扰动效应都表现出不对称性。
实验结果:我们发现,不同的语言对对翻译质量的影响趋势都是类似的。打乱原文的词序对翻译的影响很小,但打乱翻译的词序会大大降低翻译质量。
实验 3:我们再次进行了实验,这次固定 En-De 语言对,但更改了模型。在图 3 中,我们选择了 GPT 系列中的其他三个模型,即 textcurie-001、text-davinci-002 和 text-davinci-003,进行了实验。
结果展示:不同的模型中,JS 和 JT 对翻译效果的影响是不均衡的,这与之前的实验结果相吻合。
深入分析:与 Min 等人在 2022 年的研究相比,他们认为输入和输出之间的随机关系会带来更好的效果,而我们的发现则不同。我们注意到,根据不同的干扰类型,翻译效果可能大相径庭。为了解释这一现象,我们推测这种差异可能是因为翻译中的搜索过程更为复杂,需要更明确的输出指导。
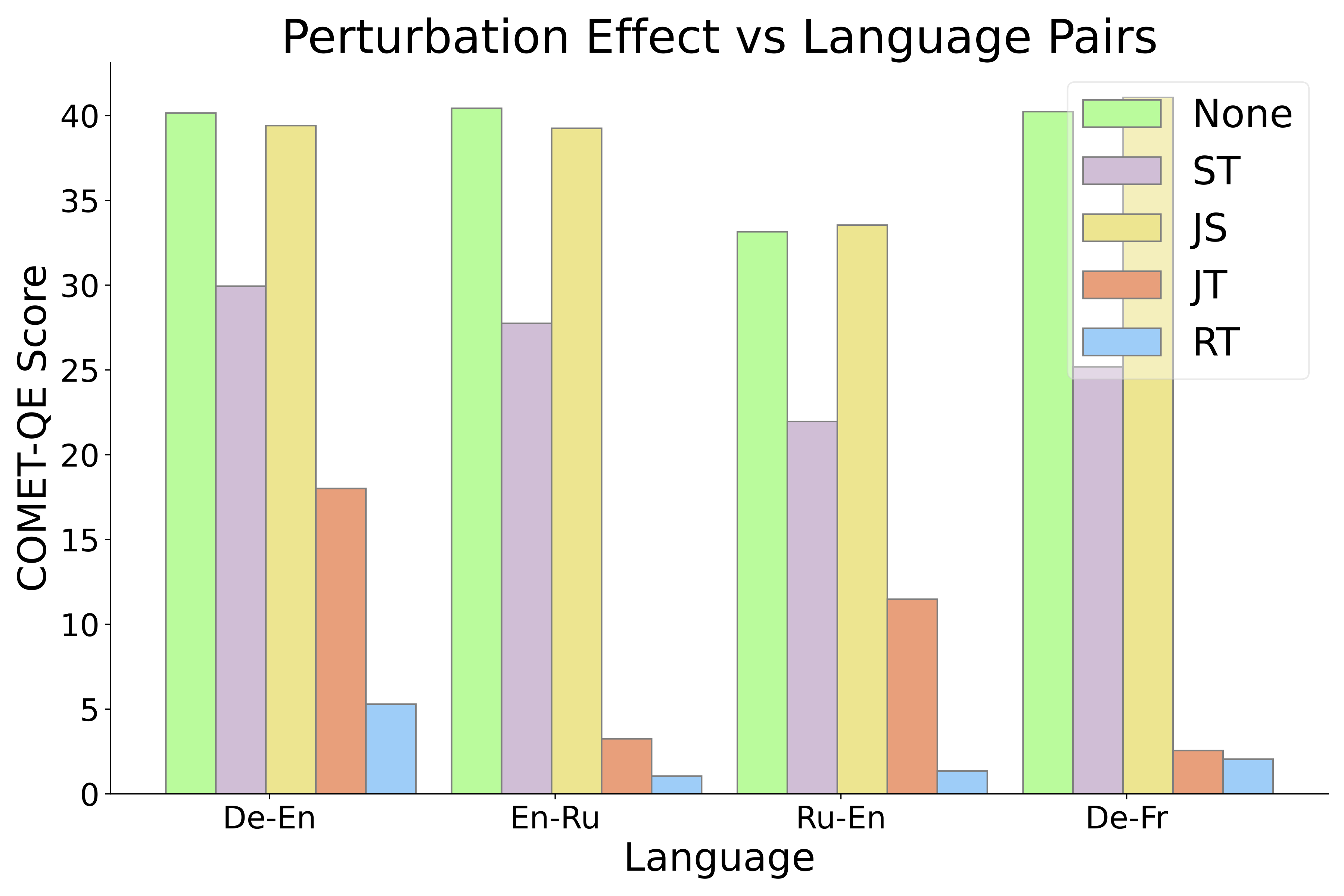
图 3:在 WMT-21 英德测试集中,针对不同的 GPT-3 模型进行的扰动实验。实验结果显示,不同模型中的源和目标扰动效应都表现出不对称性,这意味着 in-context 学习机制具有这一固有特性。
此外,图 2 & 3 的数据还表明,源和目标之间的关系在示例中也很关键,这与以前的研究结果一致。但我们发现,即使是源词的顺序对于翻译来说也不是那么重要,这意味着只需要大致上的输入文本模式就能有效地学习。
普及性分析:我们还测试了 GPT 系列中的两个新模型 gpt-3.5-turbo-instruct 和 gpt-3.5-turbo-instruct-0914。无论是哪种评估方式,我们的研究结果都相当稳健。
研究意义:我们的研究表明,在翻译学习中,输出数据可能是最关键的部分。这也为未来的研究指明了方向,即目标数据可能比原始数据更有研究价值。对于这些问题,我们期待未来的进一步探讨。
4 针对翻译的无监督学习
我们之前提到,当涉及到上下文学习翻译时,输出文本的分布是最重要的。在这里,我们要分享一个特别的方法,可以在没有任何前置条件的情况下进行学习。这次的实验和第 3 部分恰好相反:我们在这里加入了有助于无监督学习的信号,而不是像之前那样移除。我们介绍了一个叫作“无监督背景”的新技巧,它让 GPT-3 的无监督学习效果有了显著的提升,与少示例学习的效果相当。当然,这只是无监督学习中的一种尝试,未来可能会有更多方法来提高效果,例如更针对性地进行翻译任务调整。但现在,我们主要关注这个新的尝试和它的效果。
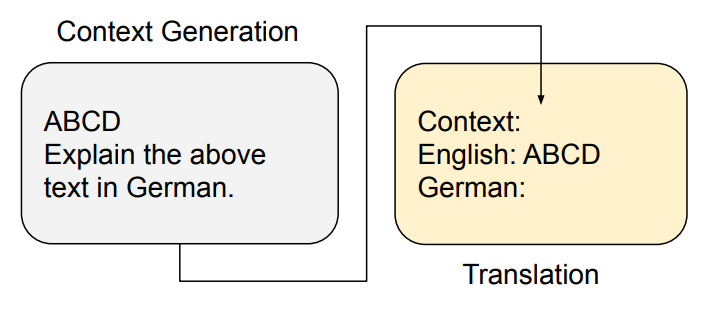
图 4:Zero-Shot-Context 的设计图:这一设计可以自动为 LLM 提供关于输出文本特性的学习信息,仿真了最为关键的演示特点。
新方法简介:我们推出了一个全新的方法,叫做 Zero-Shot-Context(图 4),它可以自动地从 LLM 中获取学习信号,并利用这个信号进行翻译。
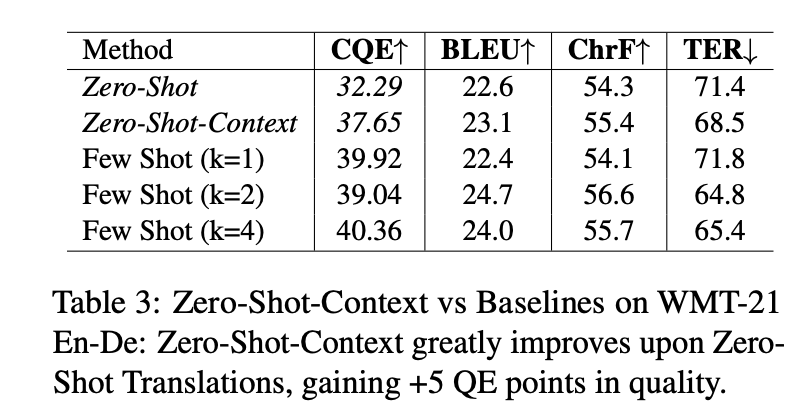
表 3:在 WMT-21 的英 - 德测试中,我们发现 "Zero-Shot-Context" 相对于传统的 "ZeroShot" 翻译表现得更好,其质量得分甚至提高了 5 个 QE 点。
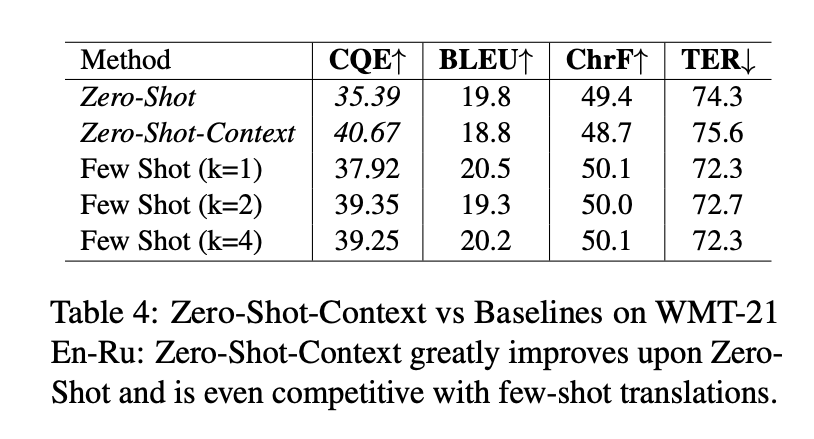
表 4:在 WMT-21 的英 - 俄测试中,"Zero-Shot-Context" 不仅明显优于 "ZeroShot",甚至还能与少数的优秀翻译相媲美。
实验数据:我们在表 3 里展示了与传统方法的比较,包括无监督提示和少示例提示(k=1, 2, 4),这些数据都是从开发集中选取的高品质样本。从 En-De WMT-21 的测试数据和 text-davinci-002 的对比中可以看出,Zero-Shot-Context 显著提高了翻译的质量,这一点从 COMETQE (CQE) 的评分中可以得到证实。但要注意,传统的 BLEU 和 ChrF 评估方法并没有显示出这一点,这也是文献中所提到的一些评估方法的局限性 (Freitag 等,2022)。而表 4 则是在 WMT-21 En-Ru 测试集上的数据对比。
关于无需预先学习的背景的实验:我们尝试了一个实验:从开发数据中随机选择一句话,然后用这句话替换现有的上下文生成步骤。想象一下,一个高质量的相关句子应该能够帮助我们更好地理解输出的内容。实验结果证明,即使使用随机句子,我们的方法在 WMT-21 En-De 测试集上达到了 36.10 的评分,而在 WMT-21 En-Ru 测试集上达到了 37.86。但这些成绩还不如 Zero-Shot-Context,说明上下文还是很关键。
深入探究:我们发现,使用 GPT-3 进行无预先知识的翻译可能比我们预期的要好。并且,我们不必手动选择例子,直接使用计算就可以提高翻译的质量。例如,我们发现一个简单的输出信号就可以提高 text-davinci-002 的翻译质量。有研究指出,这种方法有时会输出错误的语言,但 Zero-Shot-Context 方法可以大大减少这种情况,从而提高性能。但是,我们需要更多的数据来进一步分析这种现象。
5 结论
我们研究了 GPT 系列的 LLM 在翻译中的表现。关键是,学习的信号来自于输出文本的分布。我们基于这个发现提出了 Zero-Shot-Context 方法,这种方法在 GPT3 中大大提高了翻译的质量。我们希望这项工作能为人们更好地理解 LLM 如何学习翻译提供帮助。
6 存在的问题
我们的研究主要是使用高质量的例子。但是,不同质量的例子可能会有不同的效果。而我们提出的方法虽然不需要手动选择例子,但需要两次传递 LLM,这可能会带来一些问题。我们认为有更简单的方法可以实现这一目标,但这还需要进一步的研究。