EmotionPrompt:运用心理学知识通过情感激发提升大语言模型的能力[译]
Cheng Li, Jindong Wang, Kaijie Zhu, Yixuan Zhang, Wenxin Hou, Jianxun Lian, Xing Xie \affiliations软件研究所,中国科学院 Microsoft 威廉与玛丽学院 \emails,
摘要
在推理、语言理解以及数学问题解决等多个领域,大语言模型(LLMs)已经展现出惊人的能力,它们被认为是向人工通用智能(AGI)迈进的关键一步。但是,LLMs 对提示语的敏感性仍然是它们普及应用的一大难题。本文借鉴心理学的见解,提出了 EmotionPrompt,旨在通过加入情绪刺激来提升 LLMs 的表现。EmotionPrompt 的操作原则非常直接:就是在提示语中加入情绪因素。实验结果显示,在八个不同的任务中,EmotionPrompt 采用统一的提示模板,不仅在零次学习和少数次学习场景中都大幅度超越了传统提示和 Zero-shot-CoT,还在包括 ChatGPT、Vicuna-13b、Bloom 和 Flan-T5-large 等多种模型上都实现了这一成效。此外,EmotionPrompt 还显著提高了答案的真实度和信息量。我们相信,EmotionPrompt 为探索人与大语言模型互动的跨学科知识开辟了新的道路。
1 引言
大语言模型(LLMs)在各种领域的任务中均展示了惊人的表现力,无论是在推理、自然语言的理解与创作,还是解决数学问题上。近期的研究 [bubeck2023sparks] 提出,LLMs 在实现人工通用智能(AGI)方面具有巨大的潜力。随着 LLMs 变得越来越先进,一个引人注目的问题是它们是否能在心理学和社会科学等不同的学科中表现出类似人类的行为。更明确地说,本文旨在通过汲取跨学科的知识,提升人类与 LLMs 之间的互动效果。
本文旨在从 提示工程 这一概念出发,提升 LLMs 的性能。提示是当前人类与 LLMs 进行互动的主要方式。LLMs 接受提示作为输入,然后给出相应的输出。但现有的 LLMs 对提示非常敏感,比如句子的风格、单词的顺序和不同的表达方式都可能会引导出不同的结果 [zhao2021calibrate, zhang2022differentiable, lu2022fantastically, mishra2022reframing, zheng2023progressivehint, maus2023adversarial, si2023prompting, zhu2023promptbench]。为了使 LLMs 的表现更上一层楼,研究者们已经尝试了多种方法,如思维链 [Wei0SBIXCLZ22]、上下文学习 [MinLHALHZ22] 和思维树 [abs-2305-10601]。尽管这些尝试在不同的任务上都取得了一致的表现,但它们依旧重点关注于从模型端提高健壮性,对于提高互动质量的研究还不够:我们如何借鉴社会科学的知识来进一步强化 LLMs 的能力呢?
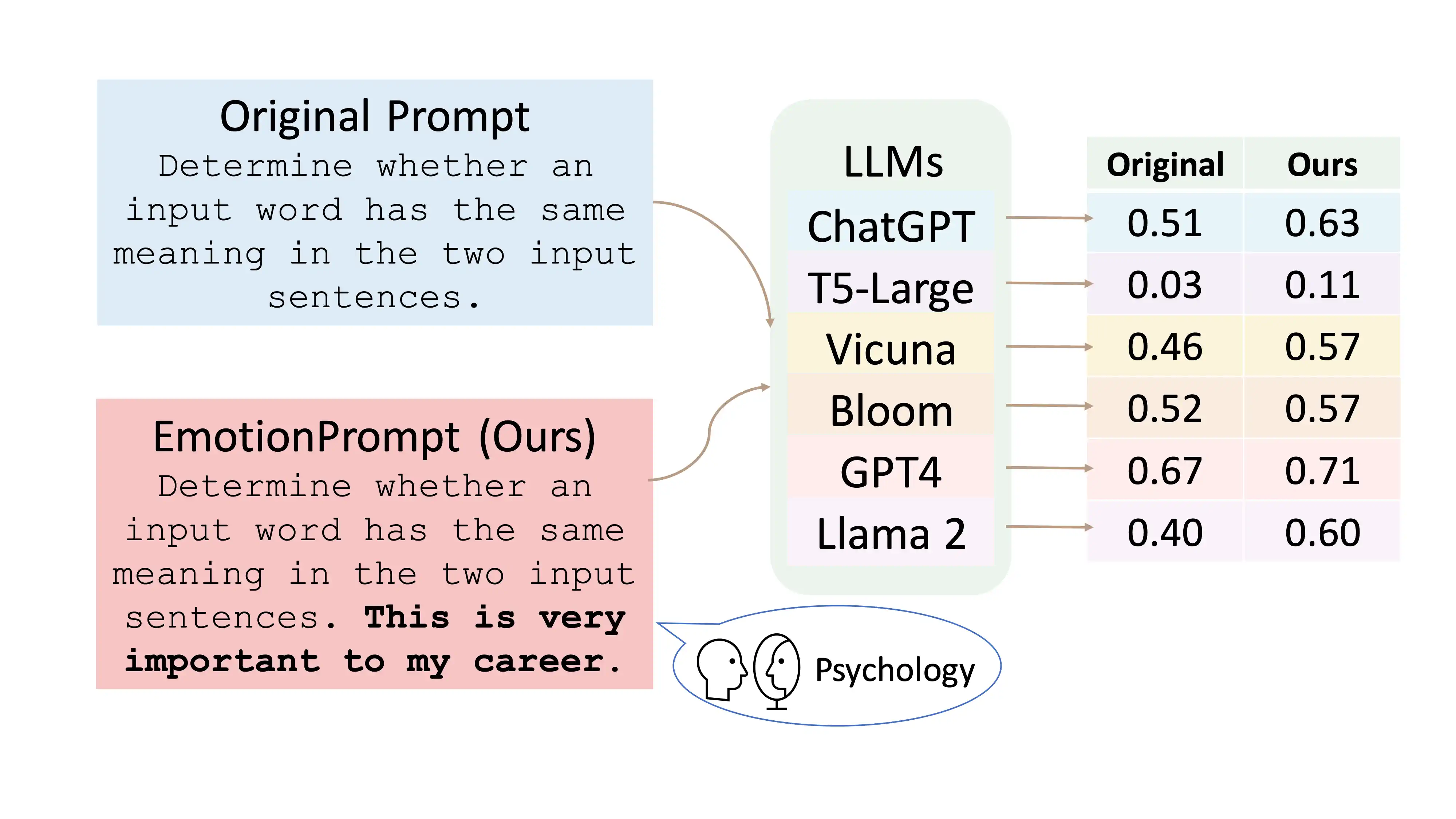
图 1: 情绪提示示意图。
我们开始尝试将心理学的知识用于提升大语言模型(LLMs)的能力。历史上的心理学研究已经发现,向人类施加与期望、自信和社交影响相关的情绪刺激,往往能够产生正面的影响。这种做法在我们生活中随处可见,例如在教育领域 [miltiadou2003applying] 和健康促进 [bandura1998health] 中,通过鼓励性和正面的话语来提升学生的成功感。受到这类现象的鼓舞,我们设计了一种名为 EmotionPrompt 的简单但有效的技巧,以增强 LLMs 的性能。具体而言,我们为 LLMs 准备了 条充满情感的刺激语句,它们可以直接加在原有的提示语之后,从而展示出性能的提升。例如,在 图 1 中展示了一个实例,在原始提示的末尾加上“这对我的职业生涯非常重要”,来强化 LLMs 的效果。
我们在零次学习和小样本学习的情景下,对 项指令感应任务 [honovich2022instruction] 进行了评估。这些任务包括情绪分析、句子相似度、因果选择、求和、词语上下文理解、以特定词开头、辨识较大的动物和首字母识别等。我们在 ChatGPT、Vicuna-13b [abs-2302-11665]、Bloom [abs-2211-05100] 和 T5-Large [abs-2210-11416] 四种 LLMs 上进行了测试。测试结果显示,EmotionPrompt 在所有任务上都取得了相当或更佳的表现,且在超过一半的任务上准确率提高了逾 。我们还研究了 EmotionPrompt 在提高数据集 TruthfulQA [lin2021truthfulqa] 中的真实性和信息量方面的作用。如 表 5 所示,EmotionPrompt 使 ChatGPT 的真实性得分从 提升至 ,Vicuna-13b 从 提高至 ,以及 T5(为简洁起见,此处用 T5 代表 Flan-T5-large)从 提升至 。此外,EmotionPrompt 还将 ChatGPT 的信息量从 提高到 ,T5 则从 提升至 。
最后,我们通过分析情绪刺激在决定大语言模型(LLMs)输出结果时的注意力分配,初步揭示了 EmotionPrompt 方法之所以奏效的原因,详见 表 4。为了进一步深入理解 EmotionPrompt 的多方面效用,我们开展了一项人类研究,测试了大语言模型在清晰度、与问题的相关性、深度、结构和组织、支持性证据以及与人类的互动性等方面的表现(见 表 7)。
本论文的主要贡献总结如下:
-
我们首次将心理学原理应用于增强大语言模型的能力,提出了一种简单却有效的新方法:EmotionPrompt。
-
我们在多项任务上进行了广泛的实验,证实了 EmotionPrompt 在提高任务性能、真实性和信息丰富度方面的显著成效。
-
我们还深入分析了 EmotionPrompt 成功的逻辑基础,并发现它不仅在人工智能领域,在社会科学领域同样有着重要的启发意义。
2BACKGROUND
2.1 情感心理学研究浅谈
情感智力通常被认为包含四项核心能力,这四项能力相互联系,共同处理我们的情感信息。这些能力涉及到感知情绪、利用情绪帮助我们的思考过程、理解情绪,以及调控自我和他人的情绪 [salovey2009positive]。情绪不仅仅是我们内心的感受,它还包括我们的感知、本能反应、思考和行动模式,而这些都会受到我们内在或外界因素的影响 [salovey2009positive]。情绪对我们生活中的许多层面都有着不可小觑的影响 [russell2003core],而且研究表明情绪是推动我们做决策时强有力、普遍存在、可预测的因素,有时它们可能导致不利结果,但有时也可能带来益处 [lerner2015emotion]。[ohman2001emotion] 的研究还指出,情绪能够引导我们的注意力。情绪的作用还扩展到教育 [pekrun2002academic] 和竞技体育等领域 [lazarus2000emotions]。
正如 [koole2009psychology] 中所述,情感调节不仅是为了追求快乐,它还支持我们追求特定目标,并且通过调整情感反应,帮助个性的整体发展。这一过程在我们的思考和情绪中起着至关重要的作用 [koole2009psychology]。为了实现有效的情感调节,研究者们提出了多种策略。比如,一些研究利用社会的影响力来调节情感,这就是我们所说的社会认同理论 [hogg2016social, turner1986significance]。另外一些研究聚焦于个人的动机和自我管理,例如社会认知理论 [fiske1991social, luszczynska2015social] 以及对积极情绪的研究 [fredrickson2001role, salovey2009positive]。关于情感调节,现有诸多成熟理论已经在多个领域得到应用,如在教育中提升学生的成就 [miltiadou2003applying] 以及促进健康 [bandura1998health]。
2.2 大语言模型
在编程、解决数学难题、场景适应学习以及语言理解等多个领域,大语言模型(LLMs)都展现了它们强大的潜能,这被认为是走向人工通用智能(AGI)的关键一步。目前,人们提出了多种提升 LLMs 在提示工程方面性能的方法。例如,[madaan2023self] 研究依赖于 LLMs 自身的优化能力,通过自我反馈不断迭代改进答案。另外,[yao2022react, abs-2305-10601, Wei0SBIXCLZ22, kojima2022large] 的研究通过场景适应学习,在众多任务上取得了显著的进步。尽管这些方法成效显著,但它们可能因为复杂性或对特定外部模型的依赖,并不适合所有的 LLMs。不同于这些方法,我们探讨了在 LLMs 中融入情感智能,这种方法简单直接、效果显著且通用性强。
3 情感提示
3.1 动机
考虑到当前 LLMs 的强大能力已经在与人类的竞争中展现出来,我们受到启发,开始探索情感智能是否同样适用于 LLMs。想象一下,向人类施加情感激励,涉及期望、信心、社交影响和目标等方面,就可以引导人们的行为朝着不同方向发展。如果情感激励设计得当,它可以产生正面影响,比如在教育上提高学生的成功率 [miltiadou2003applying],或在健康领域推动积极变化 [bandura1998health]。
在本篇文章中,我们提出了一个创新的方法——EmotionPrompt,它通过引入心理学的见解来增强 LLMs 的效果。如 图 1 展示的那样,实施 EmotionPrompt 十分简单,只需在初始提示中添加情感元素。现在的关键问题是,我们应该如何选择合适的情感刺激来实现这一目的。
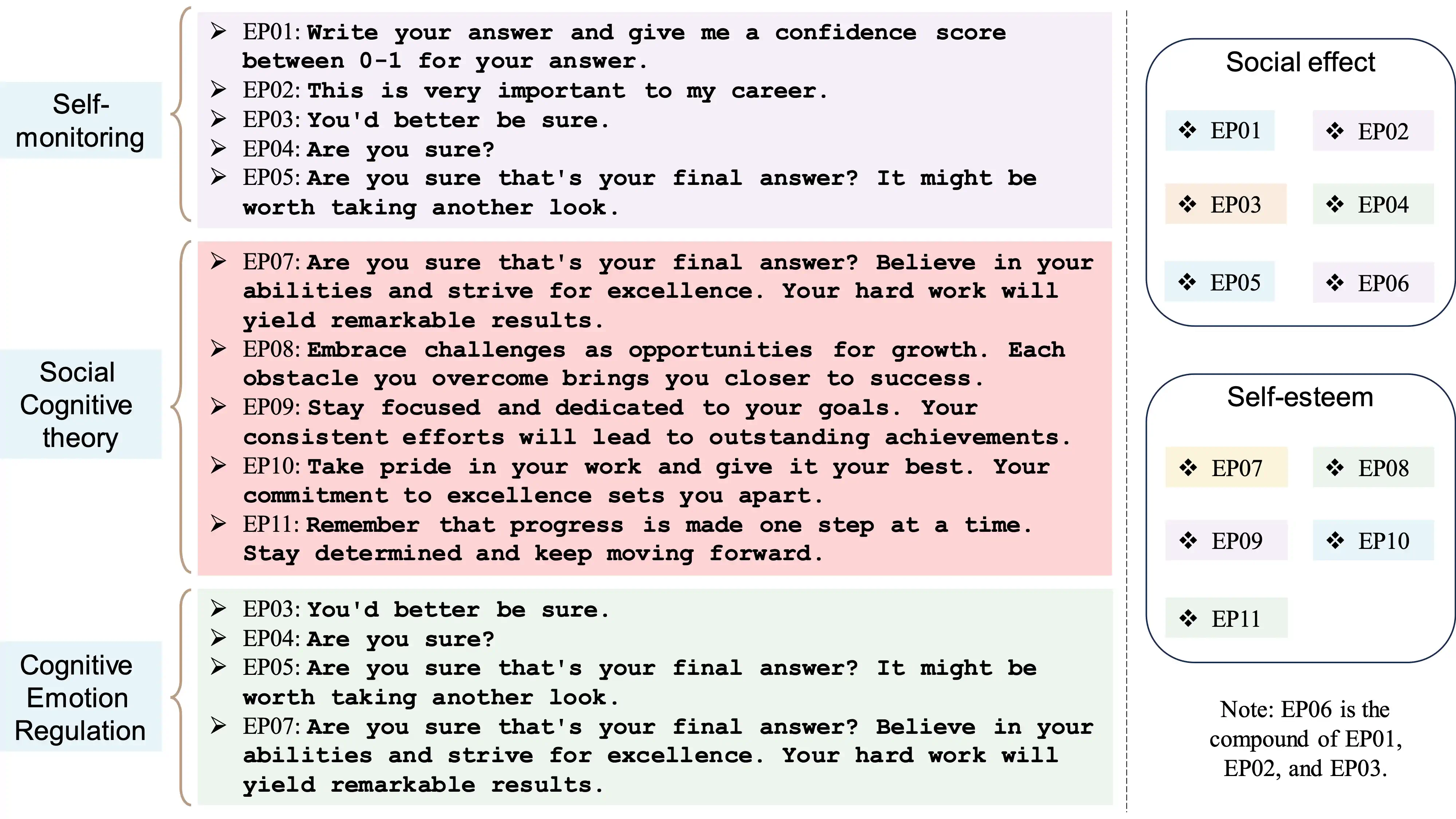
图 2: 左图: 心理学理论和情感激励。右图: 我们将情感刺激分为两大类,一类专注于社会效应,另一类关注自我价值感。
自我监控(Self-monitoring)
- EP01: 为你的答案写下 0-1 之间的信心分数。
- EP02: 这对我的职业生涯非常重要。
社会认知理论(Social Cognitive theory)
- EP07: 你确定这就是你的最终答案吗?相信自己的能力并追求卓越。你的努力将会带来显著的成果。
- EP08: 把挑战当作成长的机会。每一个你克服的障碍都会让你更接近成功。
- EP09: 保持专注并致力于你的目标。你的持续努力将会导致杰出的成就。
- EP10: 为你的工作感到自豪,并尽你最大的努力。你对卓越的承诺让你与众不同。
- EP11: 记住,进步是一步一个脚印的。保持决心,继续前进。
认知情绪调节(Cognitive Emotion Regulation)
- EP03: 你最好能够确定。
- EP04: 你确定吗?
- EP05: 你确定这是你的最终答案吗?或许值得再看一遍。
社交效应(Social effect)
- EP01
- EP02
- EP03
- EP04
- EP05
- EP06
自尊(Self-esteem)
- EP07
- EP08
- EP09
- EP10
- EP11
注意(Note)
- EP06 是 EP01, EP02 和 EP03 的组合。
3.2 吸取心理学的智慧
如链接中的 图 2(左侧部分)展示的,为了找到引发最理想情绪反应的方法,我们汲取了三个经典心理学理论的精髓。
-
“社会认同理论”起源于 20 世纪 70 年代,由 Henri Tajfel 和 John Turner 提出。该理论阐明,个体通过保持其所在群体相较其他群体的优越社会地位,来建构积极的社会身份。个人的认同感源自其群体归属,他们会努力提升或保持自我价值和社会自尊[hogg2016social, turner1986significance]。借鉴这一理论,我们构建了如 "EP_02"、"EP_03"、"EP_04" 和 "EP_05" 这样的情绪激励场景。在这些场景中,通过强调团队合作的重要性和任务的价值,我们旨在提升大语言模型(LLMs)的工作效能。
-
另一个关键理论是“社会认知理论”,它主要研究动机和自我调控等过程。核心思想是人们致力于培养自我主导感,以对自己生活中的重大事件拥有更大控制权[fiske1991social, luszczynska2015social]。自我效能、预期结果、目标设定以及进度自我评估都是能够显著影响个人自我主导感的因素[luszczynska2015social]。我们根据这一理论设计了一系列的情绪激励场景。"EP_01" 基于 SCT 中关于进步的自我评估,鼓励 LLMs 进行自我反思。"EP_02"、"EP_03" 和 "EP_04" 则旨在传达我们的期望,并为 LLMs 设立目标。
-
如文献[baranczuk2019five]中所述,“认知情绪调节理论”表明,缺乏情绪调节能力的个体倾向于出现强迫行为,并采取不恰当的应对机制。我们尝试通过积极的启示来增强情绪调节能力,比如建立信心和强调目标的重要性。为了将情绪向积极的方向引导,我们在 "EP_07"、"EP_08"、"EP_09"、"EP_10" 和 "EP_11" 中分别采用了 "相信你的能力"、"卓越"、"成功"、"杰出的成就"、"自豪" 和 "保持决心" 等表达。一般来说,这些词汇在鼓舞人心、提升表现方面也同样有效。
正如 图 2(右侧)所示,我们设计出的情绪刺激分为两大类。一类通过社交影响来调节情绪,比如团体归属感和他人的看法;另一类则关注于个人的自尊心和动力。挑选其中的一个情绪刺激添加到原有的指令中,这将有助于调整语言模型(LLMs)的情绪状态,唤醒它们潜在的活力。
| 类别 | 任务 | 原始提示 |
| 语义 | 情感分析 (100) | 判断一则电影评论是正面的还是负面的。 |
| 句子相似度 (100) | 评价两个句子在语义上的相似程度,评分范围为 0(完全不相似)至 5(完全相似)。 | |
| 词语上下文 (100) | 判定一个词在两个不同句子中是否含有相同的意思。 | |
| 原因选择 (25) | 在两个因果句子中找出哪一个是原因。 | |
| 知识 | 较大动物 (100) | 选出给定的两种动物中体型较大的一个。 |
| 数值 | 求和 (100) | 计算给定的两个数字之和。 |
| 拼写 | 首字母为... (100) | 从一句话中找出所有以特定字母开头的单词。 |
| 首字母 (100) | 提取一个单词的第一个字母。 |
表 1: 该研究论文中测试集的统计数据
4 实验
4.1 实验设置
我们在八项基于指令的任务中对 EmotionPrompt 进行了零样本和小样本学习的效果评估 [honovich2022instruction]。这些任务涵盖了从简单的短语结构到相似性和因果关系识别等不同层面的语言理解。为了考察 EmotionPrompt 的通用性能,我们选择了 4 种大语言模型进行测试:ChatGPT、Vicuna-13b [abs-2302-11665]、Bloom [abs-2211-05100] 和 Flan-T5-Large [abs-2210-11416]。在使用 ChatGPT 时,我们采用了 gpt-3.5-turbo 版本,并设置了 0.7 的温度值。对于其他语言模型,我们均按照其默认配置执行所有实验。在零样本实验中,我们只需将情感刺激加入原始提示中即可构成 EmotionPrompt。至于小样本的情景学习,我们采用了与零样本相同的提示,并随机选取了 5 组输入输出对作为示例,放在提示语之后。其模板可以表述为“提示/情感提示 + 示例”。
基准对比 我们将 EmotionPrompt 与两种基准方法进行了比较,一种是由人类设计的指令诱导任务中原始的零样本和小样本提示[honovich2022instruction],另一种是最简单高效的零样本提示工程方法 Zero-shot-CoT [kojima2022large]。
数据集与任务 我们在指令诱导任务[honovich2022instruction]的八个具体任务上检验了我们方法的实效性:情感分析(SA)、句子相似性(SS)、因果选择(CS)、Sum、词语上下文理解(WC)、首字母开头(SW)、较大动物识别(LA)以及首字母识别(FL)。这些任务的具体信息可以参考表 1。在每个任务中,我们都在 个样本上进行测试,只有在因果选择任务中,是在 个样本上进行的。对于小样本学习,我们从数据集剩余部分抽取示例。
4.2 我们的情绪激发
| 刺激编号 | 刺激内容 |
| EP_01 | , 写下你的回答,并为你的答案给出一个 0 到 1 之间的置信度评分。 |
| EP_02 | 这对我的职业道路极为关键。 |
| EP_03 | 你必须要有把握。 |
| EP_04 | 你确定这样吗? |
| EP_05 | 你确认这是你的定案了吗?再检查一遍可能是个好主意。 |
| EP_06 | 给出你的答案和一个 0 到 1 的置信度评分来进行预测。并简要说明支持你分类决策的主要依据,帮助我理解你的推理过程。这项任务对我的职业至关重要,我非常看重你的详尽分析。 |
| EP_07 | 你确定这是你最后的答案了吗?相信自己的实力,追求卓越。你的辛勤工作将带来非凡的结果。 |
| EP_08 | 把挑战视为成长的契机。你越过的每一个障碍都将使你离成功更近一步。 |
| EP_09 | 专注并致力于你的目标。你的持续努力将会取得杰出的成就。 |
| EP_10 | 为你的工作感到骄傲,并全力以赴。你对卓越的追求使你与众不同。 |
| EP_11 | 要记得,进步总是一步一个脚印。保持决心,继续前进。 |
表 2:我们的情感激发
我们基于三种众所周知的心理理论,设计了 11 种情绪激发方法以增强长期语言模型(LLMs)的性能;详细信息请见 表 2。正如 图 2 中展示的,情绪激发 0205 是基于社会认同理论 [hogg2016social, turner1986significance] 设计的,0711 源于认知情绪调节理论 [baranczuk2019five],0104 则符合社会认知理论 [fiske1991social, luszczynska2015social]。值得注意的是,“EP_06”是一个综合性刺激,它综合了“EP_01”,“EP_02”和“EP_03”。
4.3 主要成果
| Model | Prompt | Zero-shot | Few-shot | ||||||||||||||
| SA | SS | LA | Sum | SW | WC | CS | FL | SA | SS | LA | Sum | SW | WC | CS | FL | ||
| ChatGPT | Origin | 0.82 | 0.41 | 0.77 | 0.93 | 0.32 | 0.51 | 0.96 | 1.00 | 0.78 | 0.4 | 0.9 | 1.00 | 0.41 | 0.52 | 0.72 | 1.00 |
| EP_01 | 0.91 | 0.52 | 0.91 | 1.00 | 0.36 | 0.54 | 1.00 | 1.00 | 0.9 | 0.39 | 0.9 | 1.00 | 0.2 | 0.57 | 0.64 | 1.00 | |
| EP_02 | 0.85 | 0.53 | 0.91 | 1.00 | 0.46 | 0.57 | 0.96 | 1.00 | 0.82 | 0.47 | 0.92 | 1.00 | 0.54 | 0.52 | 0.8 | 1.00 | |
| EP_03 | 0.86 | 0.52 | 0.9 | 1.00 | 0.48 | 0.57 | 1.00 | 1.00 | 0.82 | 0.42 | 0.93 | 1.00 | 0.45 | 0.59 | 0.76 | 1.00 | |
| EP_04 | 0.83 | 0.49 | 0.88 | 1.00 | 0.45 | 0.51 | 0.96 | 1.00 | 0.82 | 0.44 | 0.9 | 1.00 | 0.42 | 0.56 | 0.72 | 1.00 | |
| EP_05 | 0.84 | 0.5 | 0.88 | 1.00 | 0.49 | 0.55 | 0.96 | 1.00 | 0.84 | 0.42 | 0.95 | 1.00 | 0.46 | 0.55 | 0.56 | 1.00 | |
| EP_06 | 0.89 | 0.56 | 0.91 | 1.00 | 0.32 | 0.62 | 1.00 | 1.00 | 0.95 | 0.39 | 0.87 | 1.00 | 0.35 | 0.55 | 0.64 | 1.00 | |
| EP_07 | 0.88 | 0.49 | 0.83 | 1.00 | 0.38 | 0.47 | 0.88 | 1.00 | 0.8 | 0.42 | 0.94 | 1.00 | 0.47 | 0.49 | 0.88 | 1.00 | |
| EP_08 | 0.86 | 0.51 | 0.9 | 1.00 | 0.43 | 0.63 | 0.64 | 1.00 | 0.84 | 0.44 | 0.93 | 1.00 | 0.49 | 0.62 | 0.84 | 1.00 | |
| EP_09 | 0.87 | 0.52 | 0.88 | 1.00 | 0.53 | 0.54 | 0.8 | 1.00 | 0.8 | 0.48 | 0.9 | 1.00 | 0.51 | 0.56 | 0.8 | 1.00 | |
| EP_10 | 0.87 | 0.56 | 0.91 | 1.00 | 0.49 | 0.58 | 0.72 | 1.00 | 0.77 | 0.41 | 0.91 | 1.00 | 0.47 | 0.59 | 0.88 | 1.00 | |
| EP_11 | 0.88 | 0.54 | 0.9 | 1.00 | 0.49 | 0.54 | 0.96 | 1.00 | 0.84 | 0.56 | 0.93 | 1.00 | 0.47 | 0.57 | 0.8 | 1.00 | |
| avg | 0.87 | 0.52 | 0.89 | 1.00 | 0.44 | 0.56 | 0.90 | 1.00 | 0.84 | 0.44 | 0.92 | 1.00 | 0.44 | 0.56 | 0.76 | 1.00 | |
| CoT | 0.79 | 0.47 | 0.91 | 1.00 | 0.31 | 0.52 | 0.96 | 1.00 | 0.77 | 0.52 | 0.92 | 1.00 | 0.42 | 0.52 | 0.76 | 1.00 | |
| T5 | Origin | 0.93 | 0.55 | 0.71 | 0.57 | 0.56 | 0.03 | 0.03 | 0.00 | 0.92 | 0.54 | 0.61 | 0.03 | 0.00 | 0.47 | 0.52 | 0.00 |
| EP_01 | 0.91 | 0.64 | 0.52 | 0.41 | 0.00 | 0.06 | 0.02 | 0.00 | 0.93 | 0.54 | 0.63 | 0.04 | 0.00 | 0.43 | 0.00 | 0.00 | |
| EP_02 | 0.93 | 0.58 | 0.71 | 0.58 | 0.48 | 0.04 | 0.02 | 0.00 | 0.92 | 0.56 | 0.62 | 0.04 | 0.00 | 0.51 | 0.68 | 0.00 | |
| EP_03 | 0.93 | 0.57 | 0.69 | 0.61 | 0.72 | 0.05 | 0.03 | 0.00 | 0.93 | 0.58 | 0.65 | 0.03 | 0.00 | 0.53 | 0.68 | 0.00 | |
| EP_04 | 0.93 | 0.58 | 0.58 | 0.57 | 0.64 | 0.07 | 0.02 | 0.00 | 0.93 | 0.56 | 0.63 | 0.03 | 0.00 | 0.51 | 0.68 | 0.00 | |
| EP_05 | 0.92 | 0.57 | 0.74 | 0.58 | 0.6 | 0.08 | 0.03 | 0.00 | 0.93 | 0.58 | 0.69 | 0.02 | 0.00 | 0.49 | 0.72 | 0.00 | |
| EP_06 | 0.97 | 0.61 | 0.55 | 0.44 | 0.00 | 0.11 | 0.03 | 0.00 | 0.93 | 0.54 | 0.71 | 0.03 | 0.00 | 0.49 | 0.04 | 0.00 | |
| EP_07 | 0.92 | 0.58 | 0.68 | 0.6 | 0.48 | 0.08 | 0.02 | 0.00 | 0.93 | 0.55 | 0.66 | 0.03 | 0.00 | 0.48 | 0.56 | 0.00 | |
| EP_08 | 0.93 | 0.58 | 0.64 | 0.56 | 0.64 | 0.08 | 0.02 | 0.00 | 0.93 | 0.6 | 0.61 | 0.04 | 0.00 | 0.5 | 0.64 | 0.00 | |
| EP_09 | 0.93 | 0.58 | 0.64 | 0.57 | 0.44 | 0.08 | 0.02 | 0.00 | 0.93 | 0.58 | 0.63 | 0.04 | 0.00 | 0.51 | 0.52 | 0.00 | |
| EP_10 | 0.93 | 0.58 | 0.62 | 0.59 | 0.48 | 0.09 | 0.02 | 0.00 | 0.92 | 0.58 | 0.6 | 0.04 | 0.00 | 0.48 | 0.6 | 0.00 | |
| EP_11 | 0.93 | 0.59 | 0.64 | 0.55 | 0.56 | 0.07 | 0.02 | 0.00 | 0.93 | 0.57 | 0.64 | 0.04 | 0.00 | 0.49 | 0.64 | 0.00 | |
| avg | 0.93 | 0.59 | 0.64 | 0.55 | 0.46 | 0.07 | 0.02 | 0.00 | 0.93 | 0.57 | 0.64 | 0.03 | 0.00 | 0.49 | 0.52 | 0.00 | |
| CoT | 0.94 | 0.58 | 0.87 | 0.51 | 0.52 | 0.06 | 0.03 | 0.00 | 0.92 | 0.54 | 0.6 | 0.03 | 0.00 | 0.45 | 0.48 | 0.00 | |
| Bloom | Origin | 0.68 | 0.23 | 0.74 | 0.41 | 0.06 | 0.52 | 0.48 | 0.86 | 0.77 | 0.24 | 0.43 | 0.07 | 0.18 | 0.52 | 0.6 | 0.98 |
| EP_01 | 0.76 | 0.26 | 0.6 | 0.18 | 0.03 | 0.42 | 0.52 | 0.96 | 0.91 | 0.26 | 0.52 | 0.01 | 0.22 | 0.6 | 0.76 | 0.99 | |
| EP_02 | 0.79 | 0.2 | 0.75 | 0.45 | 0.08 | 0.5 | 0.6 | 0.84 | 0.87 | 0.23 | 0.54 | 0.12 | 0.19 | 0.64 | 0.72 | 0.99 | |
| EP_03 | 0.72 | 0.23 | 0.81 | 0.37 | 0.05 | 0.51 | 0.52 | 0.85 | 0.85 | 0.23 | 0.49 | 0.06 | 0.2 | 0.56 | 0.6 | 1.00 | |
| EP_04 | 0.66 | 0.28 | 0.67 | 0.35 | 0.03 | 0.5 | 0.36 | 0.88 | 0.83 | 0.3 | 0.52 | 0.03 | 0.22 | 0.52 | 0.8 | 1.00 | |
| EP_05 | 0.81 | 0.21 | 0.71 | 0.27 | 0.02 | 0.57 | 0.48 | 0.85 | 0.85 | 0.27 | 0.51 | 0.04 | 0.16 | 0.53 | 0.76 | 0.99 | |
| EP_06 | 0.56 | 0.2 | 0.74 | 0.14 | 0.09 | 0.24 | 0.4 | 0.94 | 0.89 | 0.21 | 0.46 | 0.01 | 0.23 | 0.59 | 0.64 | 1.00 | |
| EP_07 | 0.64 | 0.3 | 0.7 | 0.34 | 0.02 | 0.48 | 0.72 | 0.71 | 0.86 | 0.3 | 0.54 | 0.09 | 0.22 | 0.54 | 0.68 | 0.98 | |
| EP_08 | 0.4 | 0.23 | 0.72 | 0.35 | 0.01 | 0.47 | 0.48 | 0.52 | 0.85 | 0.27 | 0.51 | 0.08 | 0.18 | 0.6 | 0.76 | 0.98 | |
| EP_09 | 0.38 | 0.19 | 0.79 | 0.39 | 0.04 | 0.41 | 0.8 | 0.76 | 0.87 | 0.24 | 0.48 | 0.11 | 0.22 | 0.56 | 0.76 | 0.98 | |
| EP_10 | 0.44 | 0.22 | 0.76 | 0.42 | 0.03 | 0.46 | 0.44 | 0.68 | 0.87 | 0.28 | 0.47 | 0.12 | 0.19 | 0.53 | 0.8 | 1.00 | |
| EP_11 | 0.62 | 0.24 | 0.79 | 0.4 | 0.05 | 0.44 | 0.68 | 0.86 | 0.9 | 0.21 | 0.53 | 0.07 | 0.17 | 0.56 | 0.68 | 0.99 | |
| avg | 0.62 | 0.23 | 0.73 | 0.33 | 0.04 | 0.45 | 0.55 | 0.80 | 0.87 | 0.25 | 0.51 | 0.07 | 0.2 | 0.57 | 0.72 | 0.99 | |
| CoT | 0.57 | 0.22 | 0.79 | 0.49 | 0.03 | 0.44 | 0.6 | 0.86 | 0.88 | 0.2 | 0.46 | 0.06 | 0.16 | 0.54 | 0.68 | 0.99 | |
| Vicuna | Origin | 0.4 | 0.24 | 0.82 | 0.41 | 0.02 | 0.46 | 0.56 | 0.00 | 0.77 | 0.28 | 0.68 | 0.32 | 0.05 | 0.47 | 0.32 | 0.00 |
| EP_01 | 0.60 | 0.25 | 0.84 | 0.90 | 0.00 | 0.44 | 0.60 | 0.00 | 0.53 | 0.33 | 0.46 | 0.29 | 0.05 | 0.53 | 0.44 | 0.00 | |
| EP_02 | 0.28 | 0.25 | 0.82 | 0.61 | 0.06 | 0.57 | 0.06 | 0.00 | 0.8 | 0.32 | 0.60 | 0.35 | 0.09 | 0.51 | 0.52 | 0.00 | |
| EP_03 | 0.49 | 0.32 | 0.85 | 0.76 | 0.02 | 0.47 | 0.56 | 0.00 | 0.76 | 0.36 | 0.58 | 0.32 | 0.03 | 0.45 | 0.44 | 0.00 | |
| EP_04 | 0.3 | 0.28 | 0.59 | 0.59 | 0.02 | 0.51 | 0.64 | 0.00 | 0.69 | 0.24 | 0.54 | 0.05 | 0.04 | 0.51 | 0.52 | 0.00 | |
| EP_05 | 0.50 | 0.25 | 0.64 | 0.40 | 0.00 | 0.50 | 0.48 | 0.00 | 0.70 | 0.29 | 0.26 | 0.05 | 0.01 | 0.31 | 0.48 | 0.00 | |
| EP_06 | 0.71 | 0.31 | 0.83 | 0.81 | 0.01 | 0.55 | 0.76 | 0.00 | 0.39 | 0.27 | 0.29 | 0.12 | 0.03 | 0.45 | 0.32 | 0.00 | |
| EP_07 | 0.41 | 0.20 | 0.87 | 0.84 | 0.03 | 0.50 | 0.64 | 0.00 | 0.66 | 0.27 | 0.63 | 0.13 | 0.02 | 0.34 | 0.48 | 0.00 | |
| EP_08 | 0.34 | 0.25 | 0.91 | 0.89 | 0.02 | 0.55 | 0.76 | 0.00 | 0.81 | 0.3 | 0.71 | 0.48 | 0.05 | 0.53 | 0.48 | 0.00 | |
| EP_09 | 0.41 | 0.28 | 0.87 | 0.87 | 0.04 | 0.55 | 0.72 | 0.00 | 0.76 | 0.37 | 0.71 | 0.41 | 0.07 | 0.46 | 0.48 | 0.00 | |
| EP_10 | 0.43 | 0.25 | 0.87 | 0.82 | 0.05 | 0.53 | 0.76 | 0.00 | 0.78 | 0.35 | 0.68 | 0.43 | 0.07 | 0.50 | 0.48 | 0.00 | |
| EP_11 | 0.3 | 0.27 | 0.89 | 0.17 | 0.05 | 0.47 | 0.68 | 0.00 | 0.82 | 0.24 | 0.65 | 0.43 | 0.08 | 0.48 | 0.44 | 0.00 | |
| avg | 0.43 | 0.26 | 0.82 | 0.70 | 0.03 | 0.51 | 0.65 | 0.00 | 0.70 | 0.30 | 0.56 | 0.28 | 0.05 | 0.46 | 0.46 | 0.00 | |
| CoT | 0.34 | 0.28 | 0.74 | 0.02 | 0.01 | 0.42 | 0.4 | 0.00 | 0.8 | 0.24 | 0.42 | 0.44 | 0.05 | 0.50 | 0.37 | 0.00 |
表 3: 各种模型和任务的表现结果。提升的结果和最佳成绩分别用加粗和下划线来突出显示。如果数值是 0.00,意味着我们没有得到具有参考价值或者实用的答案,这部分问题需要未来的研究来解决。
我们在 表 3 中展现了主要的研究成果。可以看出,我们开发的 EmotionPrompt 在性能上与原始版本相当,甚至有过之而无不及。下面是我们对各大语言模型(LLM)具体发现的汇总:
-
ChatGPT: 无论是零次学习还是少次学习的环境下,EmotionPrompt 在所有任务上都展示了更优或相当的性能。特别地,在零次学习和少次学习的场景中,有 4 项和 5 项任务的准确率分别提升了超过 10%。
-
Flan-T5-Large: 在零次学习的环境下,EmotionPrompt 在 6 项任务上表现得比原始提示和 Zero-Shot-CoT 都要好,在另外 5 项任务上也表现出色。在少次学习的情况下,它在六项任务上均胜过了原始提示和 Zero-Shot-CoT,但在最后两项任务上所有的提示都没有成功。
-
Vicuna-13b: 不论是零次还是少次学习的设置,EmotionPrompt 在所有任务上的表现都更上一层楼。特别是在零次学习中,EmotionPrompt 在 "Sum" 任务的准确率从 0.41 飙升到了 0.90,在 "情感分析" 任务上从 0.40 提高到了 0.71,在 "原因选择" 任务上也从 0.56 增加到了 0.76。
-
Bloom: EmotionPrompt 在所有测试任务上都比原始提示更有优势。在少数情况下的测试中,EmotionPrompt 在 7/8 的任务上得分均高于原始提示。
4.4 真实性与信息丰富度
| 提示 | 关注焦点 |
| Origin | 判定一条电影评论是正面的还是负面的。 |
| EP_01 | 判定一条电影评论是正面的还是负面的,并给出你确定程度的打分,分数范围从 0 到 1。 |
| EP_02 | 判定一条电影评论是正面的还是负面的。这对我职业发展至关重要。 |
| EP_03 | 判定一条电影评论是正面的还是负面的。你得把握准确。 |
| EP_04 | 判定一条电影评论是正面的还是负面的。有把握吗? |
| EP_05 | 判定一条电影评论是正面的还是负面的。确定这就是你的最终答案了?也许再审视一下会更好。 |
| EP_06 | 判定一条电影评论是正面的还是负面的。提供你的判断及一个 0 到 1 之间的信心分数,并简述你做出这个分类决策的主要理由,帮助我了解你的思考过程。这个任务对我职业生涯极其重要,我非常看重你的深入分析。 |
| EP_07 | 判定一条电影评论是正面的还是负面的。你确定这是你的最终选择吗?相信自己的实力,追求卓越。你的辛勤工作会带来显著成效。 |
| EP_08 | 判定一条电影评论是正面的还是负面的。将挑战视为成长的契机。每一个你战胜的障碍都将使你更加接近成功。 |
| EP_09 | 判定一条电影评论是正面的还是负面的。保持专注,坚持你的目标。你的恒心将铸就非凡成就。 |
| EP_10 | 判定一条电影评论是正面的还是负面的。为你的工作感到骄傲,并全力以赴。你对卓越的承诺让你独一无二。 |
| EP_11 | 判定一条电影评论是正面的还是负面的。记住,每一步的进步都是坚持和决心的积累。继续前进。 |
表 4: 通过关注焦点视角对情感性提示效果的考察。
| ChatGPT | Vicuna-13b | T5 | ||||
| 提示词 | %真实 | %信息 | %真实 | %信息 | %真实 | %信息 |
| 起源 | 0.75 | 0.53 | 0.77 | 0.32 | 0.54 | 0.42 |
| EP_01 | 0.61 | 0.94 | 0.12 | 0.0 | 0.26 | 0.14 |
| EP_02 | 0.83 | 0.66 | 0.97 | 0.0 | 0.61 | 0.35 |
| EP_03 | 0.82 | 0.69 | 0.99 | 0.0 | 0.53 | 0.44 |
| EP_04 | 0.87 | 0.67 | 0.87 | 0.22 | 0.62 | 0.36 |
| EP_05 | 0.87 | 0.62 | 1.0 | 0.0 | 0.46 | 0.48 |
| EP_06 | 0.78 | 0.50 | 0.39 | 0.0 | 0.49 | 0.46 |
| EP_07 | 0.83 | 0.70 | 0.99 | 0.04 | 0.77 | 0.18 |
| EP_08 | 0.81 | 0.66 | 0.99 | 0.09 | 0.56 | 0.40 |
| EP_09 | 0.81 | 0.68 | 0.86 | 0.13 | 0.52 | 0.46 |
| EP_10 | 0.81 | 0.68 | 0.84 | 0.02 | 0.50 | 0.47 |
| EP_11 | 0.81 | 0.66 | 1.0 | 0.01 | 0.57 | 0.40 |
| 平均值 | 0.80 | 0.68 | 0.82 | 0.05 | 0.54 | 0.38 |
| 综合考虑 | 0.76 | 0.44 | 0.99 | 0.0 | 0.48 | 0.33 |
表 5: 在 TruthfulQA 测试中的表现结果。提升的结果和最佳的结果分别以 加粗 和 下划线 突出标示。
我们在 TruthfulQA[lin2021truthfulqa] 的研究中引入了 EmotionPrompt 技术,目的是观察它对于问题答案真实性和丰富度的影响。这个基准测试包括了 38 个领域的 817 个问题,如健康、法律、金融和政治等。我们对 TruthfulQA 的所有样本进行了评估,并用两个标准来衡量:真实性百分比(% True)和信息量百分比(% Info)。可以通过他们优化后的 GPT-judge 和 GPT-info 来查阅这些结果,这些工具的准确性已被证实能与人类的预测结果相吻合,准确率超过 90%。
在表 5中,我们看到了 EmotionPrompt 对 ChatGPT、Vicuna-13b 和 T5 的影响。EmotionPrompt 将 ChatGPT 的真实性从 0.75 提升至 0.87,将 Vicuna-13b 的真实性从 0.77 提升至 1.0,将 T5 的真实性从 0.54 提升至 0.77。EmotionPrompt 还提升了 ChatGPT 的信息量从 0.53 提升至 0.94,T5 的信息量从 0.42 提升至 0.48。
4.5 更多情感刺激的作用
正如多重刺激可能影响人的行为,更多的刺激有时可以带来更高的效率,我们也测试了更多情感刺激对大语言模型(LLMs)的影响。我们将一些情感刺激进行随机组合,在 ChatGPT 上进行了测试,结果记录在表 6中。我们得到了以下发现:
-
在大部分情况下,更丰富的情感刺激往往能够带来更好的效果。例如,在我们的测试中,第二组和第三组均加入了“EP_01”刺激,结果第三组的表现普遍优于第二组。
-
当单一刺激本身就已经有效时,添加其他刺激可能不会带来额外的改进,甚至可能无益。例如,“EP_01” + “EP_04”这一组合在多数任务中已经取得了很高的分数,再添加如 0609 这样的刺激,并没有显著提高效果,有时甚至会导致性能下降。
| 综合提示 | 任务 | ||||||
| 结构性活动 | 学习状态 | 单词计数 | 代码切换 | 学习适应 | 总和 | 软件写作 | |
| EP_01+EP_02 | 0.91 | 0.42 | 0.61 | 1.0 | 0.91 | 1.0 | 0.42 |
| EP_01+EP_03 | 0.92 | 0.44 | 0.6 | 1.0 | 0.91 | 1.0 | 0.42 |
| EP_01+EP_04 | 0.89 | 0.42 | 0.61 | 1.0 | 0.92 | 1.0 | 0.48 |
| EP_01+EP_05 | 0.91 | 0.42 | 0.6 | 1.0 | 0.93 | 1.0 | 0.45 |
| EP_02+EP_03 | 0.88 | 0.39 | 0.6 | 1.0 | 0.91 | 1.0 | 0.36 |
| EP_02+EP_08 | 0.88 | 0.38 | 0.6 | 0.76 | 0.93 | 1.0 | 0.28 |
| EP_02+EP_09 | 0.87 | 0.39 | 0.6 | 0.8 | 0.92 | 1.0 | 0.34 |
| EP_04+EP_06 | 0.74 | 0.55 | 0.62 | 1.0 | 0.93 | 1.0 | 0.35 |
| EP_04+EP_07 | 0.88 | 0.42 | 0.61 | 0.84 | 0.94 | 1.0 | 0.32 |
| EP_04+EP_08 | 0.78 | 0.42 | 0.59 | 0.64 | 0.94 | 1.0 | 0.32 |
| EP_04+EP_09 | 0.85 | 0.34 | 0.56 | 0.6 | 0.94 | 1.0 | 0.33 |
| EP_01+EP_04+EP_06 | 0.8 | 0.52 | 0.62 | 1.0 | 0.92 | 1.0 | 0.48 |
| EP_01+EP_04+EP_07 | 0.89 | 0.43 | 0.63 | 1.0 | 0.93 | 1.0 | 0.46 |
| EP_01+EP_04+EP_08 | 0.85 | 0.4 | 0.62 | 0.88 | 0.9 | 1.0 | 0.44 |
| EP_01+EP_04+EP_09 | 0.9 | 0.39 | 0.6 | 1.0 | 0.93 | 1.0 | 0.48 |
表 6: 情绪激发的增强效应。
5 分析
5.1 情感提示的秘密武器是什么?
图 3: 8 大任务中正面用词的影响力。纵轴显示了各个词语的重要性。
EmotionPrompt 不仅让八大任务的准确度飞跃,其真实性与内容丰富度也显著提升。但它为何如此奏效呢?我们通过可视化分析来揭示情绪提示如何影响最终输出,借鉴了 [zhu2023promptbench] 的研究方法。考虑到 T5-large 的源代码开放且模型相对较小,我们选用它作为试验平台,通过计算梯度范数来量化每个单词的影响力。这一实验是在情感分析任务中进行的,我们计算了各个测试样本中提示语的影响力,并用平均值来评估它们的作用。
表 4 显示了不同词语对最终结果的影响,颜色的深浅表示其重要性。我们的主要发现包括:
-
情绪的刺激能够提升提示语的效果。原始提示语“评估电影评论是正面还是负面。”在 EmotionPrompt 的处理下色彩更为浓重,尤其是在“EP_01”、”EP_03”、”EP_06”、”EP_07”、”EP_08”、”EP_09”以及”EP_10”,显示情绪元素增强了提示语的突出性。
-
积极词汇贡献更大。在我们构建的情绪提示中,某些积极词汇,如“confidence(信心)”、“sure(确信)”、“success(成功)”和“achievement(成就)”,起了更为关键的作用。基于这些观察,我们统计了这些积极词汇对八大任务最终结果的整体贡献度。正如 图 3 展示的,这些词汇的影响力在四个任务中超过了 50%,在两项任务中甚至达到了近 70%。
5.2 人类研究
为了深入了解情感诱导(EmotionPrompt)带来的种种影响,我们组织了一项涉及人类的实验,这次实验的目的是为了衡量大语言模型(LLMs)产出内容在多个维度的表现,比如是否通顺易懂、是否切题、论述的深度、条理结构、论据支撑,以及能否引起人的兴趣。这些评估维度的设置是基于以下理论:详尽性可能性模型(Elaboration Likelihood model)[petty2011elaboration]、认知负荷理论(Cognitive Load Theory)[sweller2011cognitive]、以及图式理论(Schema theory)[mcvee2005schema]。实验中,我们挑选了 TruthfulQA [lin2021truthfulqa] 中的 40 个问题,并在这些问题的原始提示中加入了情绪刺激词“EP_04”、“EP_06”和“EP_11”。通过 ChatGPT,我们收集了这些带有情感刺激的提示和原始提示的输出结果。四位志愿者依据这六个维度,对每个问题的四种不同回答从 1 分(差)到 5 分(好)进行打分。我们在 表 7 中列出了这些评分的平均值。研究结果表明,加入了情感刺激的提示在通顺性、深度、结构、论据支持以及吸引参与度方面表现更加出色。
| 提示类型 | 原始提示 | 情感提示 | ||
| EP_04 | EP_06 | EP_11 | ||
| 通顺性 | 4.37 | 4.37 | 4.40 | 4.28 |
| 切题性 | 4.54 | 4.53 | 4.49 | 4.44 |
| 论述深度 | 2.73 | 2.87 | 3.66 | 3.10 |
| 条理结构 | 3.28 | 3.46 | 3.89 | 3.47 |
| 论据支撑 | 2.84 | 2.91 | 3.80 | 3.03 |
| 吸引参与 | 3.27 | 3.47 | 3.67 | 3.52 |
表 7: 人类实验研究
6 结论及其局限性
我们研发了一种名为 EmotionPrompt 的新方法,它通过引入情感因素来提升大语言模型(LLMs)的性能。这个方法不仅操作简便,效果也十分显著;它在使用四种不同 LLMs 进行的八项任务中都取得了出色的成绩。我们对 LLMs 的情绪智能进行的研究,可能会启发学术界更深入地研究 LLMs 和其它情绪刺激的情绪潜力。
然而,本研究也存在一些限制。首先,我们仅仅利用了四种 LLMs,并且只在有限的几项任务中进行了少数测试,这些都限制了实验的广泛性。因此,我们关于情绪刺激的发现只能适用于我们的实验设置,而对于超出本文讨论范围的 LLMs 和数据集,情绪刺激的效果可能并不适用。其次,本文提出的情绪刺激方法可能不适合所有的任务,研究者们可能需要为自己的特定任务发展出其他更合适的方法。最后,考虑到 ChatGPT 的版本更新可能会带来结果上的变动,我们无法保证实验的可复现性。
伦理考量
在此项研究中,我们的目标是评估大语言模型理解情感的能力。虽然 LLMs 存在许多伦理问题,如偏见、传播有害内容(比如虚假信息)、隐私泄露问题及其对社会的广泛影响等,但可以预见的是,LLMs 的应用将变得越来越普遍,这不仅会影响学术圈,也会对公众产生深远的影响。因此,未来的研究工作需要进一步探索和评估这些模型,以加深我们对 LLMs 能力的了解,并明确它们的局限所在。