第 1 章:AI 研发 —— 2024 年人工智能指数报告 [译]
本章关注于 AI 研究和开发的动向。起初,本章回顾了 AI 相关的论文和专利发布情况,随后探讨了重要 AI 系统和基础模型的发展趋势。最终,章节通过审视 AI 会议参与情况及开源 AI 软件项目的情况来进行总结。
章节亮点
-
产业界继续主导前沿 AI 研究。 在 2023 年,产业界制造了 51 个显著的机器学习模型,而学术界只贡献了 15 个。此外,2023 年还有 21 个由产业界和学术界合作产生的显著模型,这是一个新高。
-
更多基础模型和更多开源基础模型。 在 2023 年,共发布了 149 个基础模型,是 2022 年的两倍多。在这些新发布的模型中,65.7% 是开源的,相比之下,2022 年只有 44.4%,2021 年为 33.3%。
-
前沿模型的成本大幅上涨。 根据人工智能指数报告的估计,最先进 AI 模型的训练成本已达到前所未有的水平。例如,OpenAI 的 GPT-4 的估计使用了价值 7800 万美元的计算资源来训练,而 Google 的 Gemini Ultra 的计算成本为 1.91 亿美元。
-
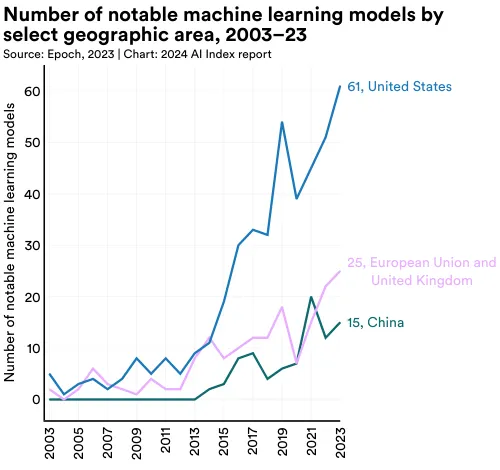
美国领先于中国、欧盟和英国,成为顶尖 AI 模型的主要来源地。 在 2023 年,来自美国的机构开发了 61 个显著 AI 模型,远超欧洲联盟的 21 个和中国的 15 个。
-
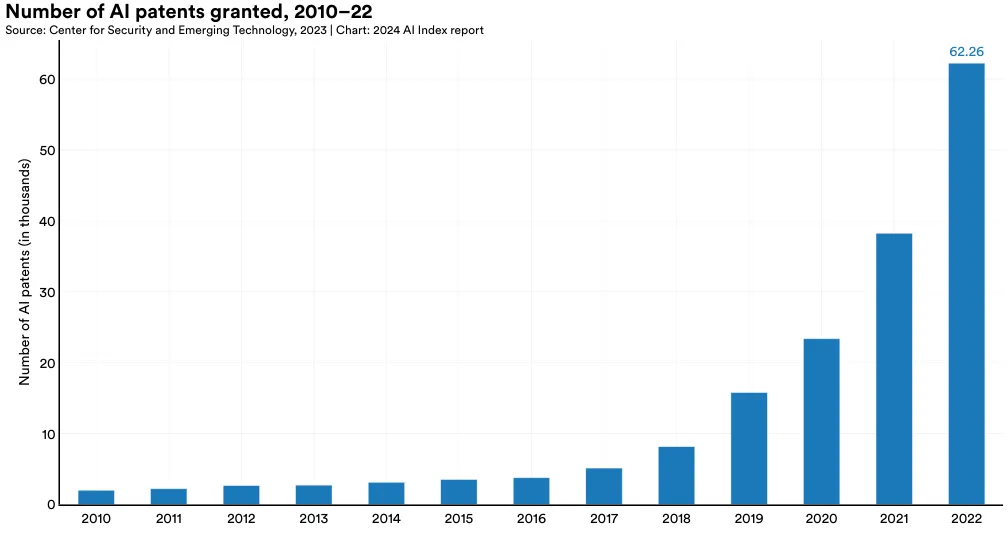
AI 专利数量激增。 从 2021 年到 2022 年,全球 AI 专利授权数量急剧增加了 62.7%。自 2010 年以来,授权的 AI 专利数量已增加超过 31 倍。
-
中国在 AI 专利方面占据主导地位。 2022 年,中国在全球 AI 专利领域以 61.1% 的占比位居首位,远超美国的 20.9%。从 2010 年开始,美国在 AI 专利的比例已从 54.1% 逐渐下降。
-
开源 AI 研究迅速增长。 从 2011 年的 845 个到 2023 年的约 180 万个,GitHub 上的 AI 相关项目数量持续上升。尤其是 2023 年,这一数量猛增了 59.3%。同时,这些项目的总星级数也在同年增至 1220 万,比前一年增加了三倍以上。
-
AI 发表文献数量稳步提升。 在 2010 至 2022 年间,AI 相关的发表文献数量近乎增加了三倍,从约 88,000 篇增至 240,000 篇以上,而最近一年的增长仅为 1.1%。
1.1 论文发表
概览
以下图表展示了 2010 至 2022 年全球英文和中文 AI 论文发表的统计,分按隶属类型和跨部门合作进行了分类。同时,本节还详细介绍了 AI 期刊文章和会议论文的相关数据。
AI 论文发表总量
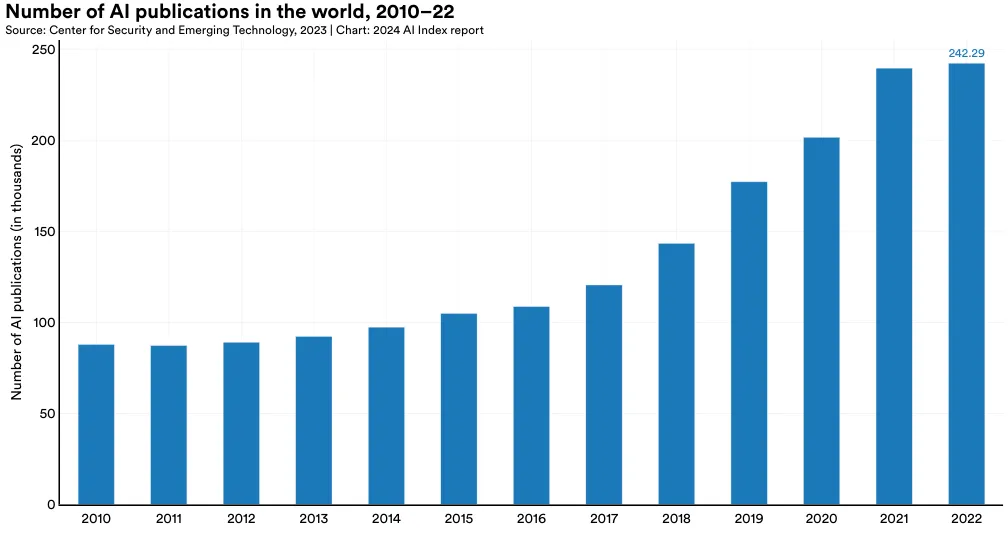
本年度的数据来自 CSET,其分类 AI 论文发表的方法及数据来源已与去年相比有所变化,使得本年度与去年的数据有所不同。另外,AI 相关的最新发表数据只能追溯到 2022 年,因为数据更新通常有较大的延迟。建议读者对这些数字持保留态度。
论文发表类型分布
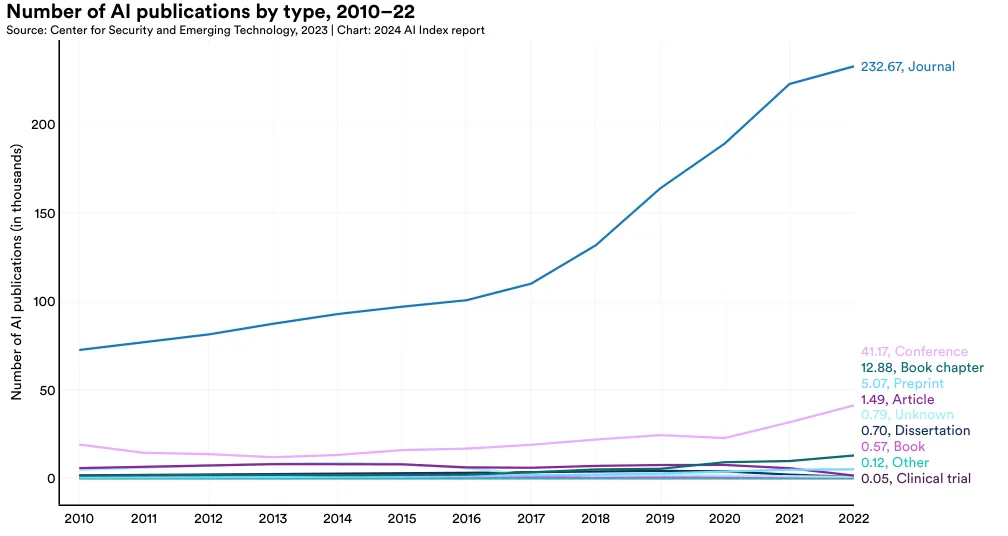
一个 AI 论文发表可能被归入多个类别,因此图 2 中的总数与图 1 中的总数不完全对应。
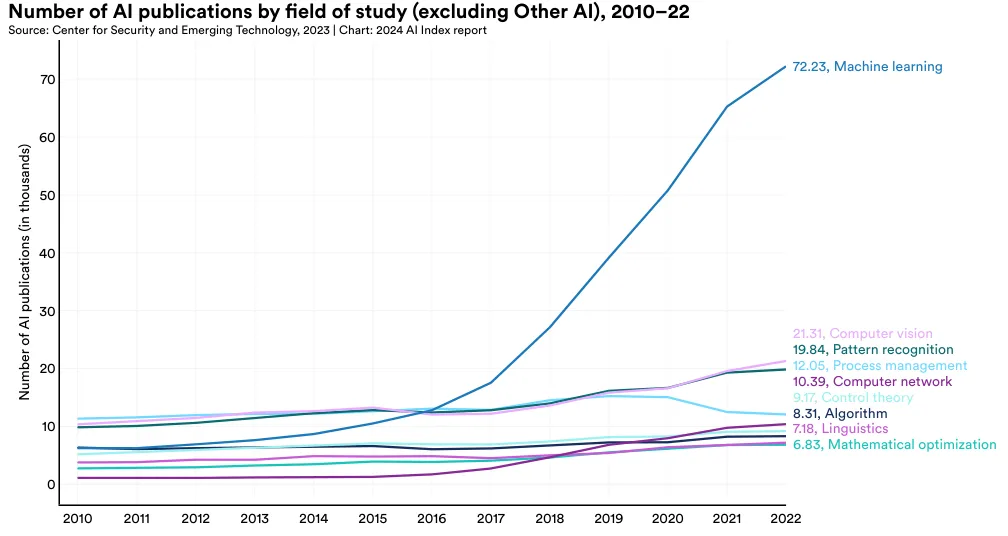
按研究领域
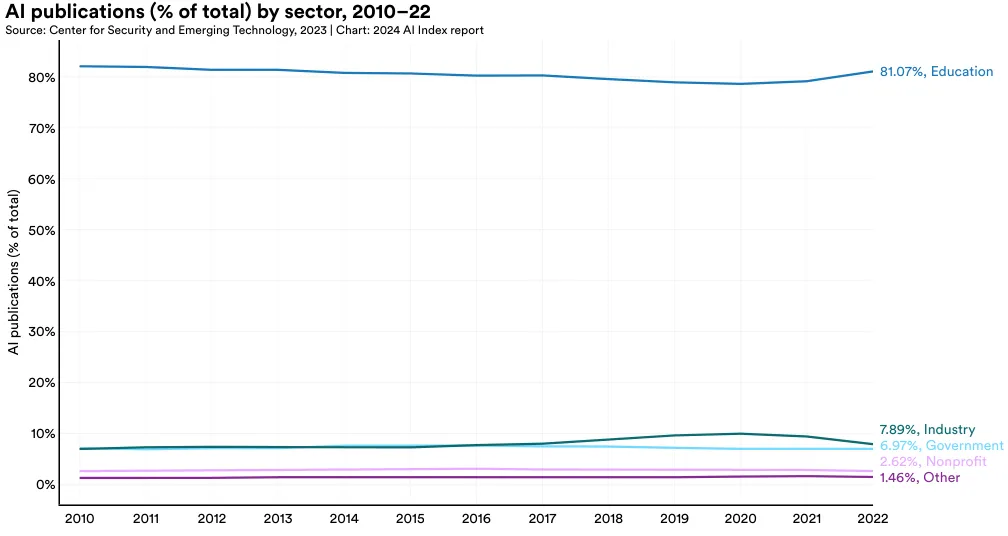
按部门
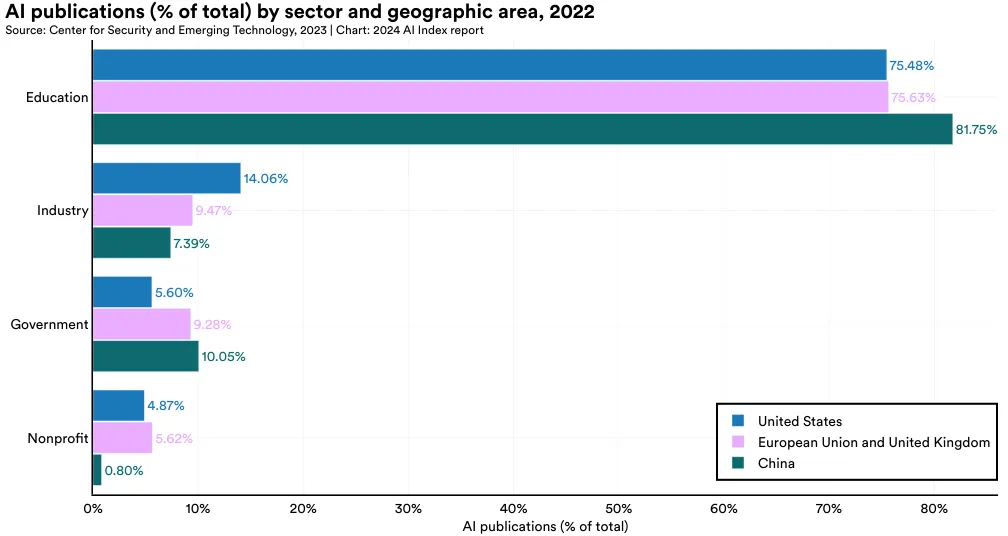
本节呈现了 AI 发表的部门分布情况,覆盖全球以及特别聚焦美国、中国和欧洲联盟及英国。2022 年,学术界以 81.1% 的贡献率领先,是过去十年全球各地区 AI 研究的主力军(图 1.1.4 和 1.1.5)。美国的工业界在 AI 发表上最为活跃,其次是欧洲联盟和英国、中国。
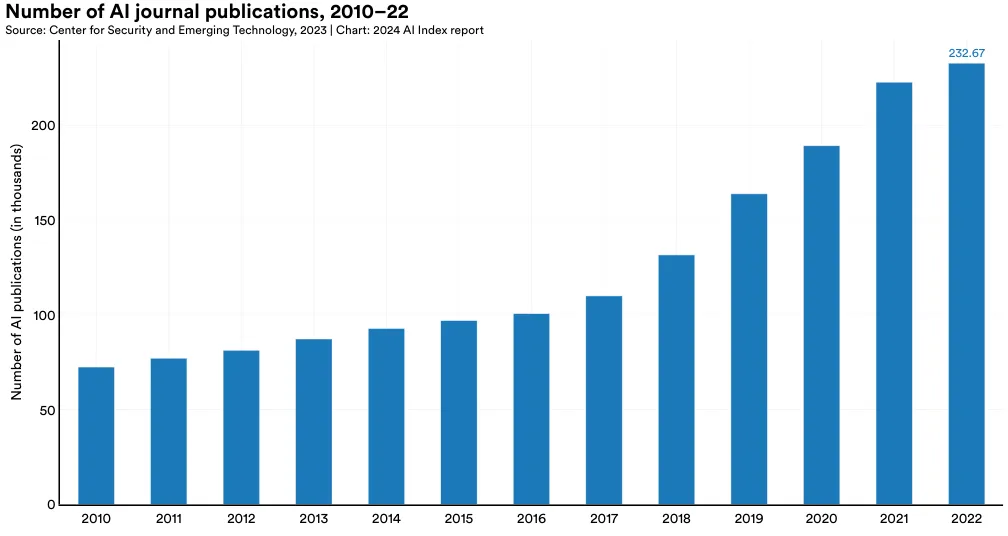
AI 期刊发表
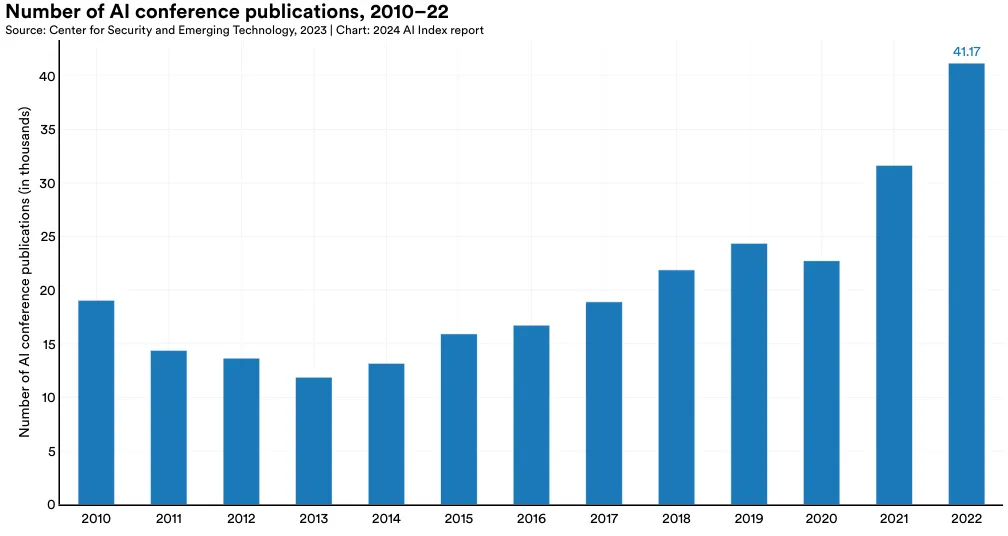
AI 会议论文发表情况
专利
AI 专利
概览
按照申请状态与地区划分
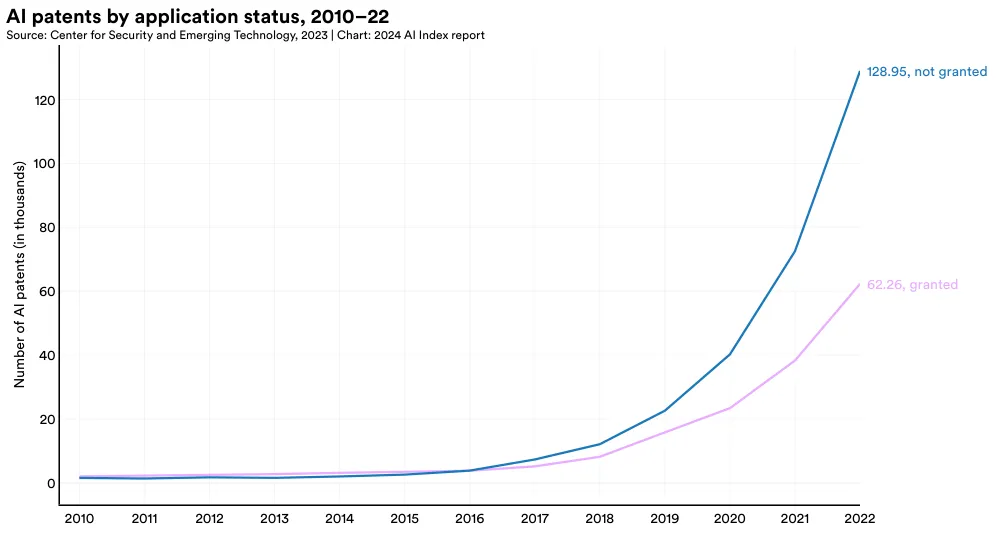
在这一部分,我们将 AI 专利根据其申请状态(是否获得授权)和发表地区进行分类。图 1.2.2 展示了全球各地 AI 专利的申请情况对比。截至 2022 年,未获授权的 AI 专利数量 (128,952) 是获授权者 (62,264) 的两倍多。AI 专利的批准情况在过去几年中发生了明显的变化。在 2015 年之前,大部分提交的 AI 专利都能成功获得授权。但从那时起,未获授权的情况成为了主流,且未获授权的比例逐年增大。比如,2015 年时,有 42.2% 的 AI 专利申请未获授权,而到了 2022 年,这一比例增至 67.4%。
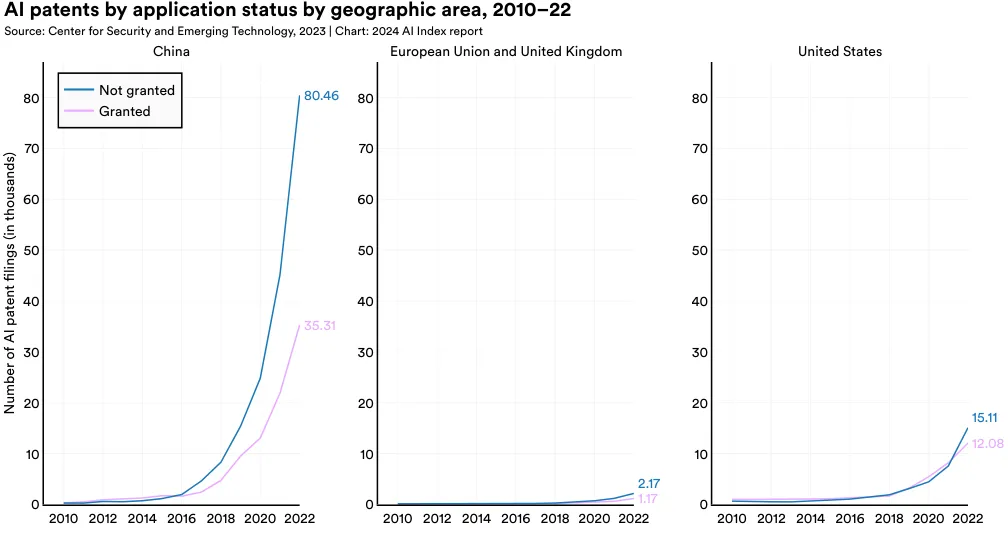
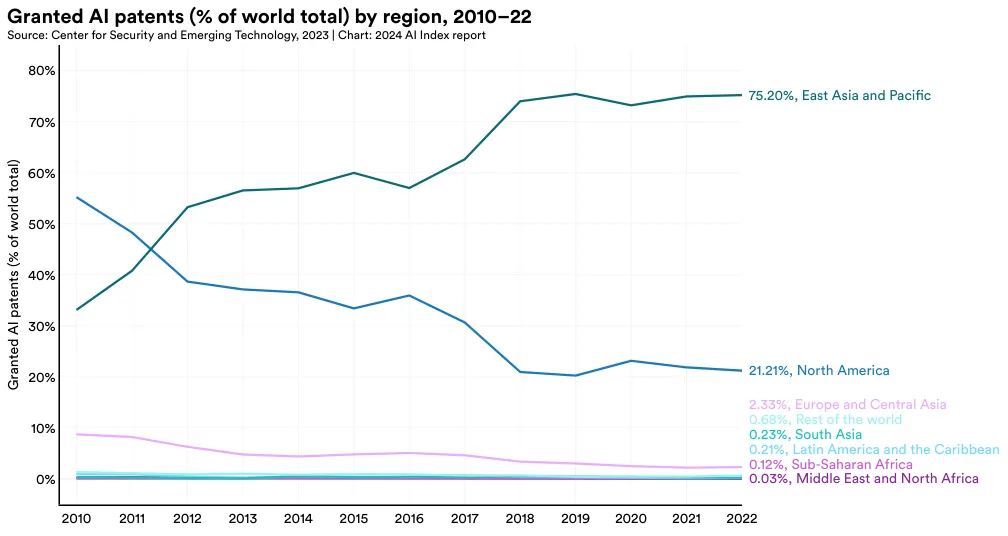
在全球范围内,大多数授权的 AI 专利来自中国 (61.1%) 和美国 (20.9%) (图 1.2.5)。从 2010 年的 54.1% 开始,来自美国的 AI 专利比例持续下降。
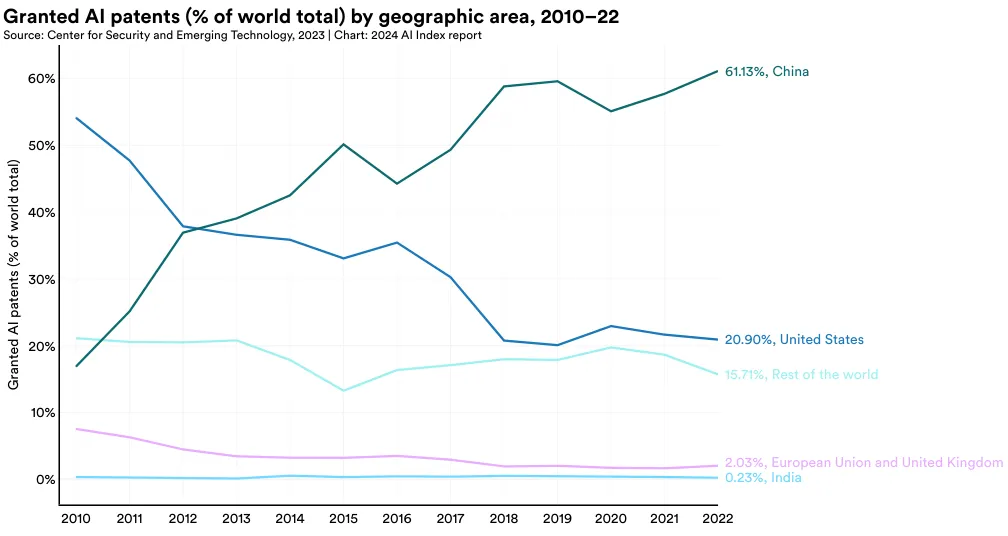
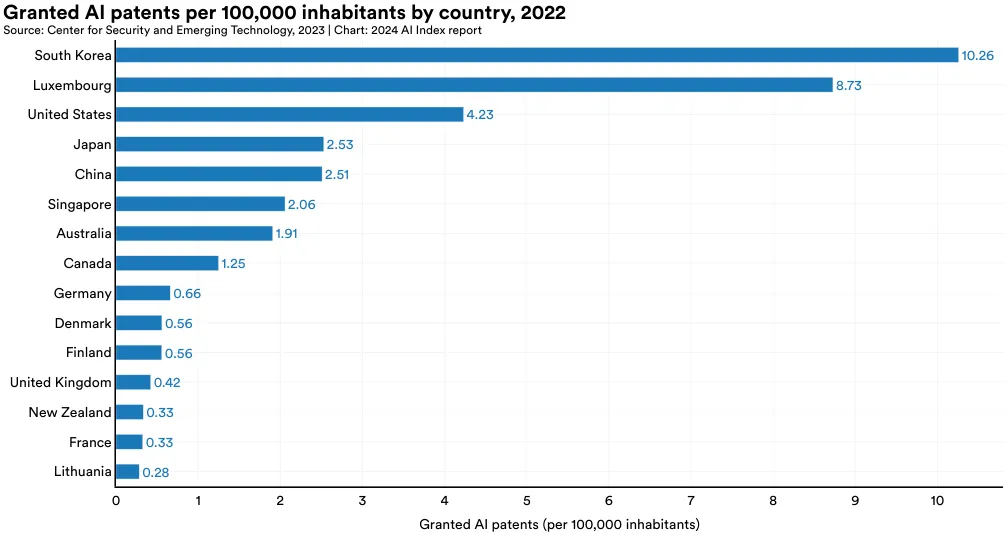
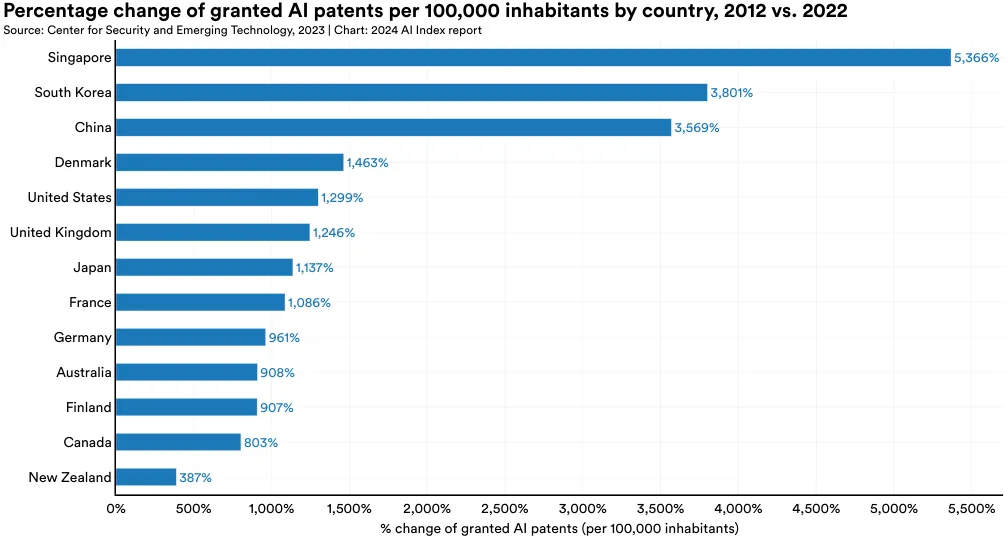
图 1.2.6 和 图 1.2.7 显示了各国在人均 AI 专利数量上的领先情况。2022 年,韩国 (10.3) 人均拥有的 AI 专利数量位居全球首位,其次是卢森堡 (8.8) 和美国 (4.2) (见图 1.2.6)。图 1.2.7 则突出了 2012 年至 2022 年间,新加坡、韩国及中国在人均 AI 专利增长上的显著提升。
本节深入探索 AI 研究的最前沿。尽管每年都有大量新 AI 模型被推出,只有极少数能代表最尖端的研究。何为尖端研究,这一定义有其主观性:可能是一个模型在某个基准测试中创下新高,或是引入了创新的架构,抑或展现出了新的、令人瞩目的能力。
AI 指数追踪了两类尖端 AI 模型的动态:“突出模型”和基础模型。数据提供商 Epoch 将具有重大影响力的模型定义为“突出机器学习模型”,这些模型在 AI/机器学习领域内有着特别的地位。相较之下,基础模型则是那些在庞大数据集上训练得到的大型 AI 模型,它们能够执行多种任务,如 GPT-4, Claude 3, 和 Gemini 等。虽然很多基础模型也被视为突出模型,但并非所有突出模型都属于基础模型类别。
在本节中,AI 指数从多个维度分析了突出模型和基础模型的趋势,包括模型的来源机构、原产国、参数数量以及计算资源的使用情况。分析最后审视了机器学习的训练成本。
1.3 前沿 AI 研究
通用机器学习模型
概述
Epoch AI 是一个专注于研究并预测高级 AI 进展的研究团队。他们建立了一个 数据库,收录了从 1950 年代起发布的各种 AI 和机器学习模型,其中包括 1.3 项顶尖 AI 研究,选取标准涉及技术前沿、历史影响力或高引用次数。这些分析帮助全面了解机器学习领域的发展轨迹,覆盖近年及过去数十年的变化。尽管有些模型可能未被纳入,数据集依然能够展示出相关的发展趋势。
3“AI 智能体” (AI system) 通常指基于 AI 的程序或产品,例如 ChatGPT;而“AI 模型” (AI model) 是指训练过程中学习其参数值的一组参数,例如 GPT-4。随着新旧模型持续加入 Epoch 数据库,因此本年度 AI Index 报告中统计的模型数量可能与去年的报告有所不同。
行业分析
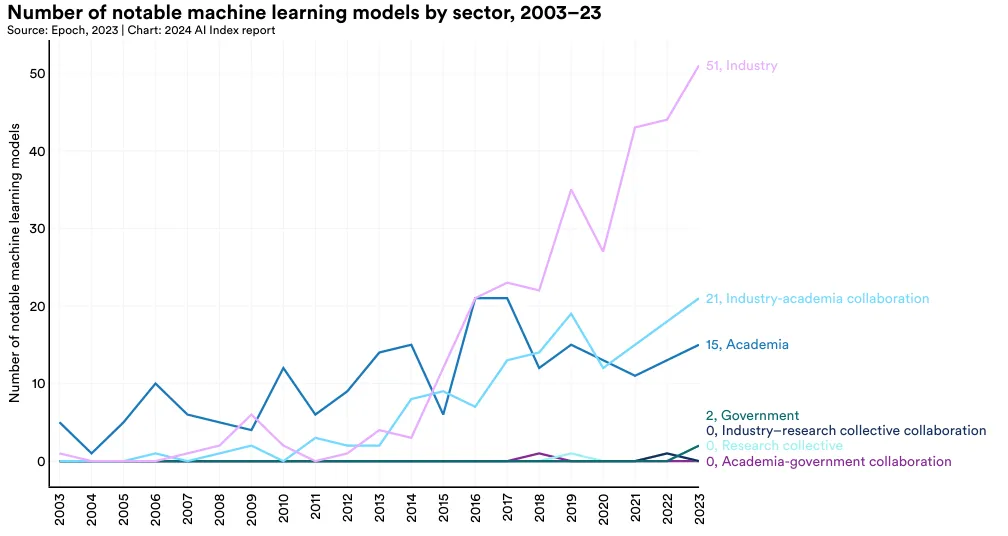
2014 年以前,机器学习模型的发布主要由学术界领衔。从那年起,产业界开始崭露头角。在 2023 年,产业界共发布了 51 个重要机器学习模型,而学术界仅发布了 15 个 (图 1.3.1)。值得注意的是,同年产业与学术界的合作也创下了 21 个重要模型的新记录。目前,制造顶级 AI 模型需要大量数据、计算资源及资金支持,这些通常是学术界所不具备的。这一转变趋势首次在去年的 AI Index 报告 中得到强调,并且尽管今年差距有所减小,这一趋势依旧存在。
国家影响力
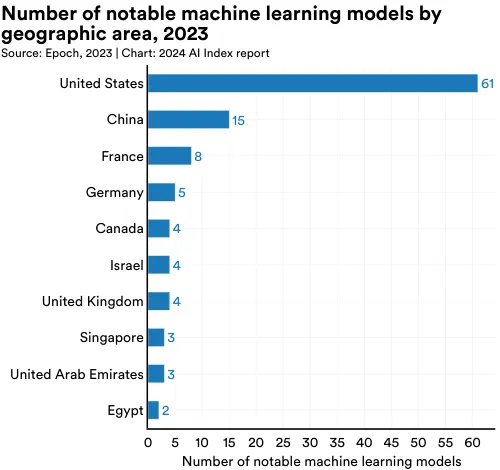
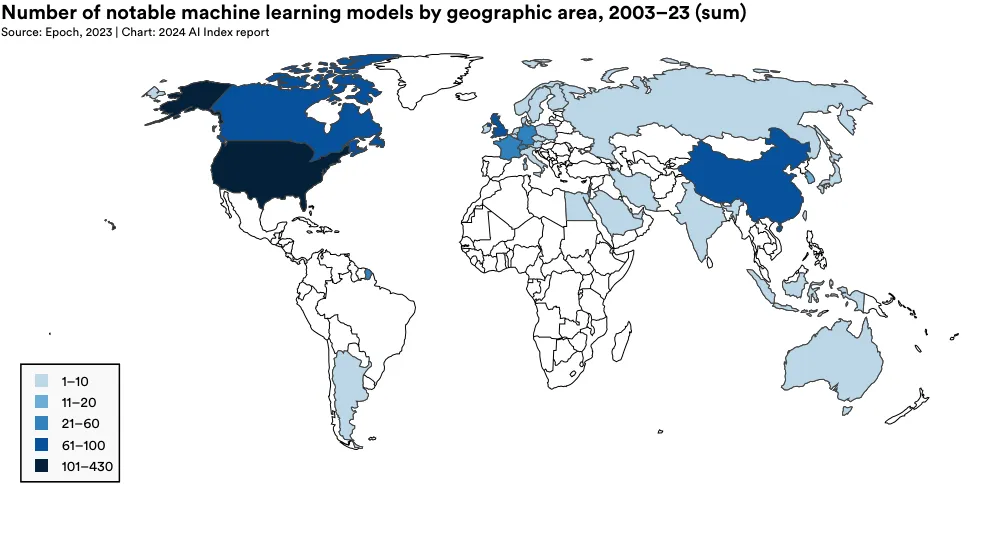
为揭示人工智能领域地缘政治的变化趋势,AI Index 研究团队研究了影响深远的模型的原产国。图 1.3.2 展示了研究者所在机构位置所归属的重要机器学习模型 (Machine Learning Models) 的总数。5 2023 年,美国以 61 个重要机器学习模型领先,中国 15 个,法国 8 个。自 2019 年以来,首次欧洲联盟和英国的总和超过了中国在重要 AI 模型的产出(图 1.3.3)。从 2003 年开始,美国的模型产出数量一直领先于英国、中国和加拿大等其他主要地区(图 1.3.4)。
5 一个机器学习模型如果其论文的至少一位作者与某国的研究机构有关,则该模型被视为与该国有关。若模型的作者来自多个国家,会有重复计数的情况。
参数趋势解析
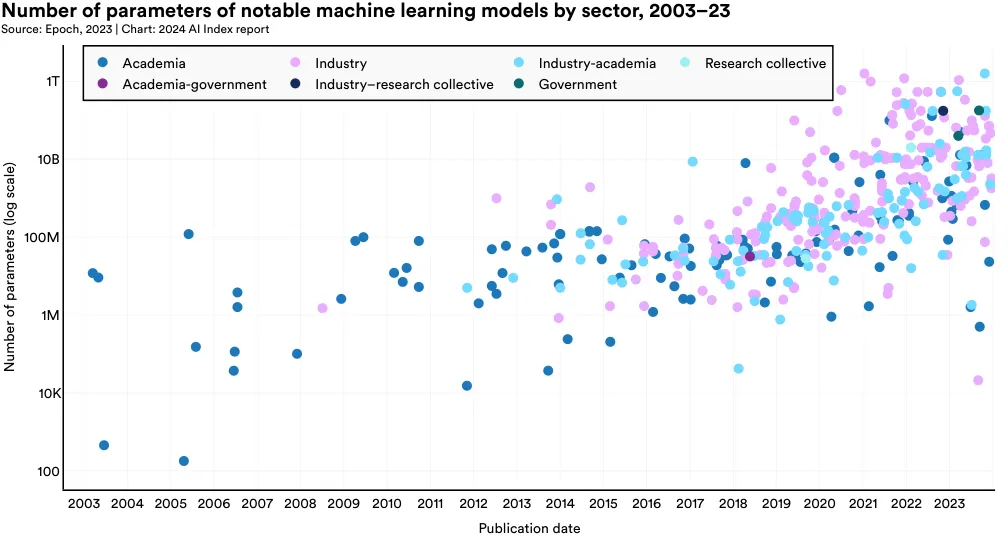
机器学习模型的参数是在训练过程中学习到的数值,这些数值定义了模型对输入数据的解读及预测方式。一般来说,使用更多数据训练的模型拥有更多的参数。同理,参数更多的模型往往表现更佳。
图 1.3.5 显示了来自不同行业的机器学习模...odels 的参数统计,分类依据它们的行业来源。自本世纪十年之初以来,参数的数量显著增长,这反映了 AI 模型所面临的任务越来越复杂,数据获取更为便捷,硬件性能提升,以及大模型的有效性得到验证。特别是在工业领域,高参数模型特别突出,显示了像 OpenAI、Anthropic 以及 Google 等公司能够应对巨大数据训练所需的计算成本。
AI 算力趋势解析
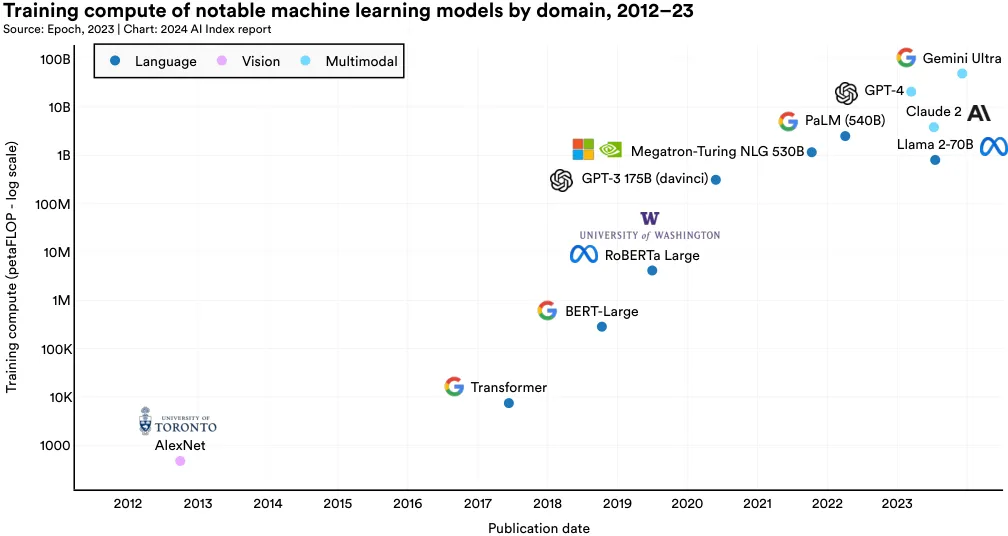
在 AI 领域,"算力" (compute) 是指训练及运行机器学习模型需要的算力资源。模型复杂度和数据量是影响算力需求的两大因素:复杂度和数据量越高,需要的算力也就越大。如图 1 (图 1.3.6) 所示,过去 20 年里,许多知名的机器学习模型在训练过程中的算力需求有了显著的增长。近年来,这种需求呈现出指数级的增加,尤其是在最近五年内。算力资源的快速增长不仅对环境产生了较大影响,而且在资源获取上,企业通常比学术界更有优势。
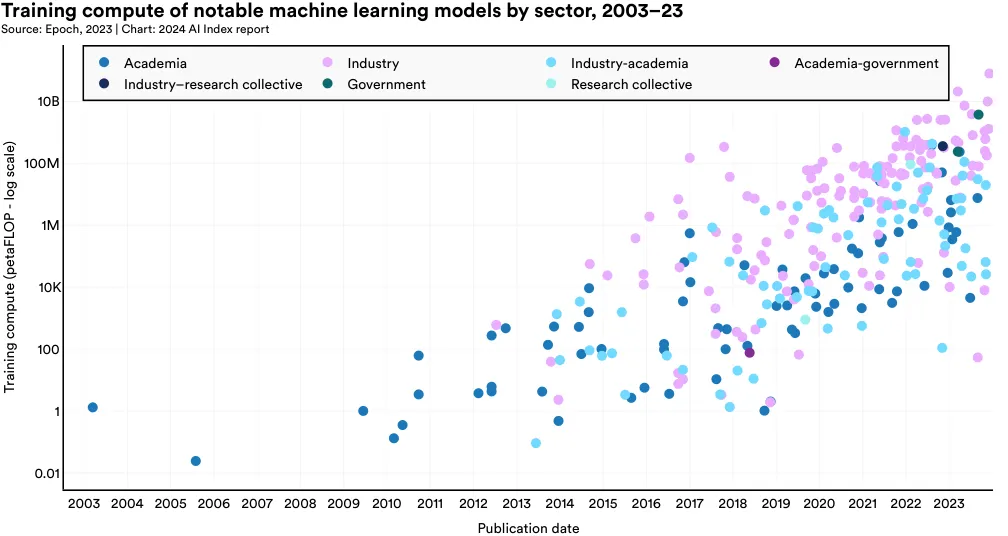
图 1.3.7 显著地标出了自 2012 年以来,重要机器学习模型的训练算力需求。例如,AlexNet 这一研究推广了使用 GPU 提升 AI 模型效率的做法,其训练估计消耗了 470 petaFLOPs。首个 Transformer 模型在 2017 年推出时,大约需要 7400 petaFLOPs 的算力。而最近的顶尖模型,Google 的 Gemini Ultra,则需约 500 亿 petaFLOPs。
主题突出:模型的数据会用尽吗?
正如上文所述,包括强大大语言模型(LLM)取得的进展在内,最近的算法进步很大一部分是通过在更大数据量上训练模型实现的。Anthropic 的共同创始人兼 AI Index 指导委员会成员 Jack Clark 最近指出,基础模型的训练涵盖了互联网上绝大部分现有数据。
AI 模型对数据的依赖日益增强,这让人担心未来的计算机科学家可能没有足够的数据来扩展和提升系统。Epoch 的研究显示,这种担忧不是没有道理。研究者依据历史数据增长率和计算能力预测,提出了可能数据耗尽的时间表。
例如,研究者预测,到 2024 年,高质量语言数据可能就会被用尽,二十年后低质量语言数据也将耗尽,而图像数据可能在 2030 年代末到 2040 年代中被完全用光(图 1.3.8)。理论上,使用 AI 自产的合成数据可以解决数据不足的问题。比如,可以用一个大语言模型生成的文本来训练另一个模型。使用合成数据作为训练资料,在数据缺乏时生成所需数据,这一方法不仅能解决数据枯竭的问题,还能为罕见病症或较少代表性的群体创造数据。尽管如此,直到近期,人们对使用合成数据训练生成式 AI 的有效性和可行性还知之甚少。但是,最新研究指出,这种方法在实践中有其局限性。

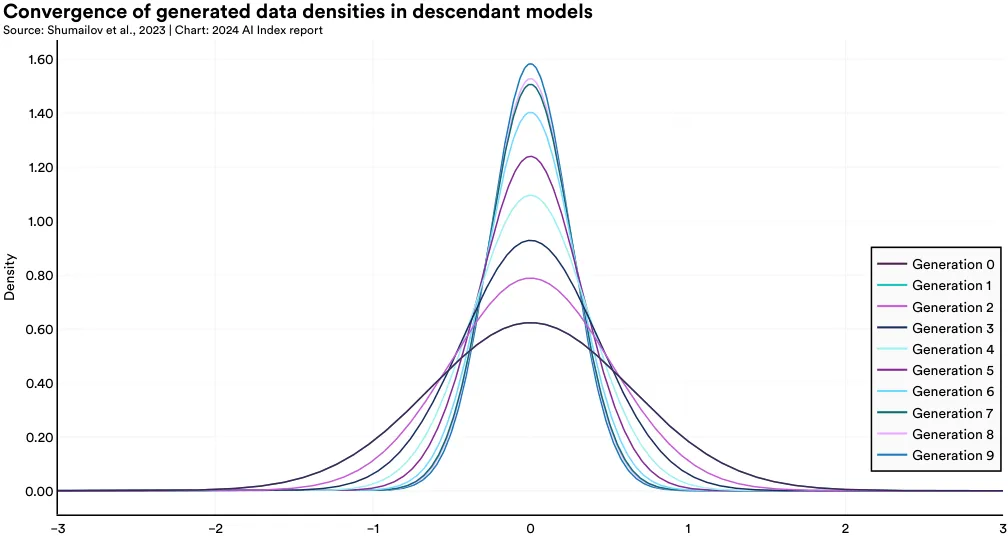
例如,来自英国和加拿大的研究团队发现,主要依靠合成数据训练的模型会出现所谓的“模型崩溃” (model collapse) 现象,即随时间推移,这些模型逐渐失去对原始数据分布的记忆力,只能生成范围极限的输出。图 1.3.9 显示了一个变分自编码器 (VAE)——一种常用的生成式 AI (generative AI) 架构——中的模型崩溃过程。每一代模型在接触更多合成数据后,能生成的输出类型也愈发有限。如图 1.3.10 所示,从统计角度看,随着合成数据代数的增加,输出分布的两端逐渐消失,而中心密度趋向平均化。这说明,依赖合成数据的模型,其输出多样性和分布广度随时间减少。
研究表明,无论是高斯混合模型还是大语言模型 (LLMs),这种现象都普遍存在。这强调了人类生成数据在培养能够创造丰富内容的大语言模型中的重要性。

7 生成模型中的“密度”指的是 AI 模型生成输出的复杂性和多样性。高密度模型能创造更多高质量的输出,而低密度模型的输出则简单且单一。
2023 年的一项研究指出,在生成图像模型中使用合成数据时,如果没有足够的真实人数据支持,模型的输出质量会明显下降。研究者将这一状况命名为“模型自噬症” (Model Autophagy Disorder, MAD),这个名字是借鉴了疯牛病的情况。
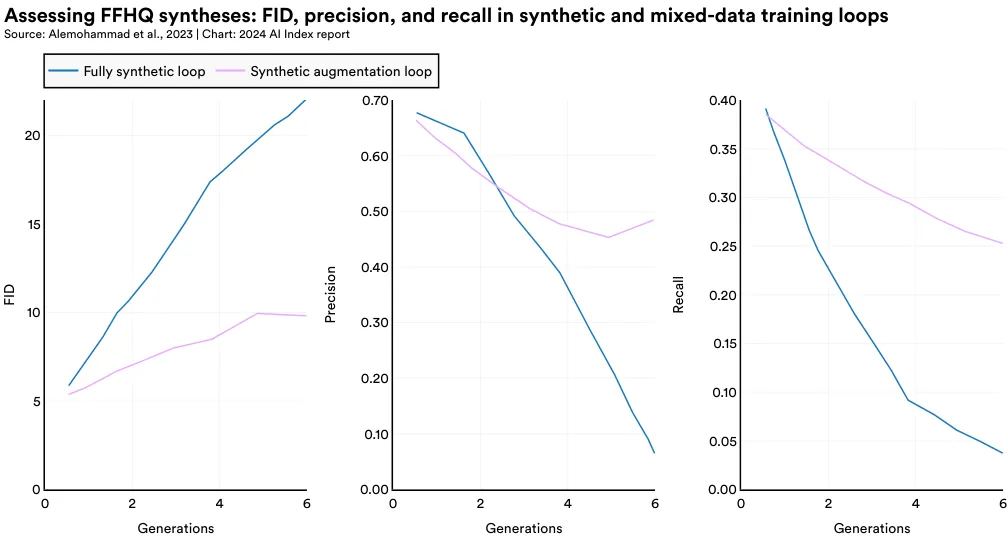
本研究探讨了两种类型的训练方法:一种是完全合成 (fully synthetic) 方式,即模型仅使用合成数据进行训练;另一种是合成增强 (synthetic augmentation) 方式,即模型通过合成数据与真实数据的组合进行训练。在这两种方法中,随着训练次数的增加,生成图像的质量逐渐下降。图 1.3.11 展示了在合成增强下,图像生成的逐步退化,如在训练的第 7 和第 9 步中,生成的人脸图像出现了越来越多的不规则散点。从统计角度看,这些使用合成数据和合成增强方法的图像,其 FID 分数较高,意味着与真实图像的差异增大;精确度和召回率分数较低,表明图像的真实感和多样性都有所下降 (见图 1.3.12)。尽管添加了部分真实数据的合成增强方法比完全合成方法在图像退化上有所改善,但两者在进一步训练后都显示出效果递减的趋势。

基础模型
基础模型是当前 AI 领域中快速发展并广受欢迎的一个类别。这些模型基于大型数据集训练,适用于多种下游任务。例如 GPT-4, Claude 3, 和 Llama 2 等基础模型已经展现了出色的能力,并正在逐步投入实际应用中。Stanford 在 2023 年推出的 Ecosystem Graphs,是一个新的社区资源,旨在监测基础模型生态系统的动态,包括数据集、模型及其应用。本节内容借助 Ecosystem Graphs 的数据,分析了基础模型发展的趋势。
模型发布详解
我们可以通过不同的方式访问基础模型。例如,像谷歌的 PaLM-E 这样的无访问模型,只允许其开发者使用。而像 OpenAI 的 GPT-4 这种有限访问模型,则通过公共 API 提供部分访问权限。再如 Meta 的 Llama 2,这类开放模型不仅公开了模型权重,还允许用户自由地修改和使用这些模型。
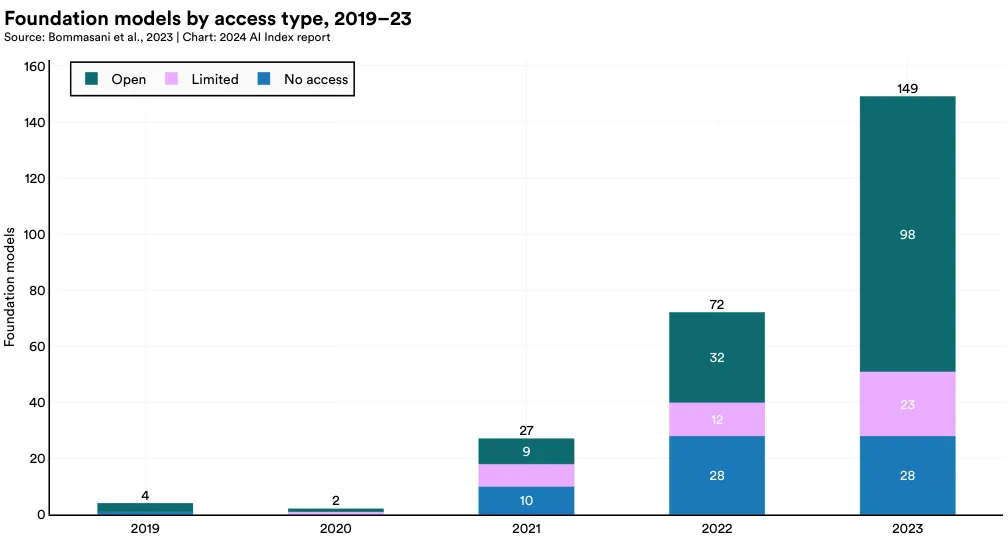
图 1.3.13 描绘了从 2019 年至今,基于访问类型的基础模型总数的变化。近几年,基础模型的数量激增,自 2022 年起翻了一番,从 2019 年起增加了将近 38 倍。2023 年,共有 149 款基础模型面市,其中开放模型 98 款,有限访问模型 23 款,无访问模型 28 款。
8 在全球 AI 生态系统的广泛调查中,生态系统图尽管做了大量工作,但报告中对于来自如韩国和中国等国家的模型可能还不够全面。
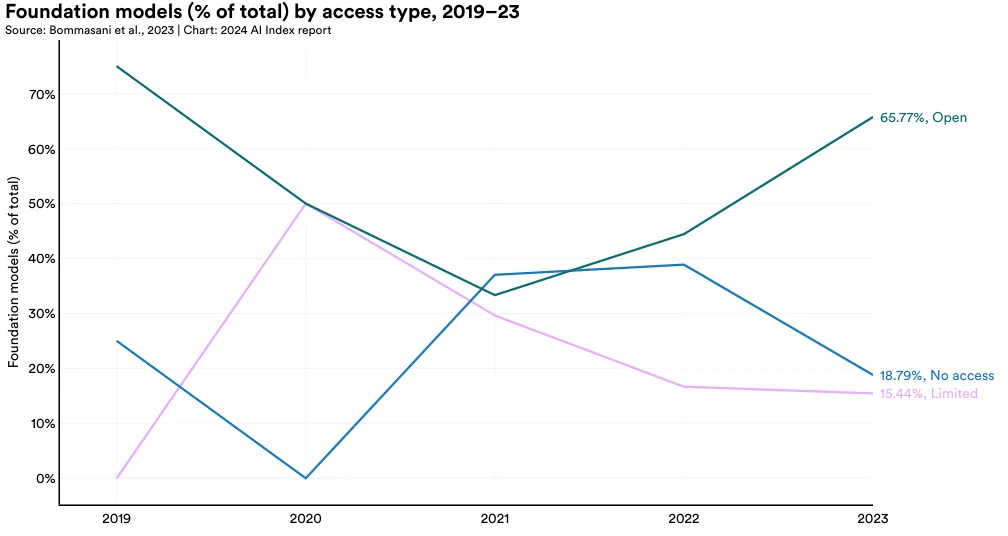
2023 年,大部分的基础模型(65.8%)实行了开放访问政策,18.8% 的模型是非公开的,15.4% 提供了有限访问(如图 1.3.14)。从 2021 年开始,开放访问的模型比例有了显著的提升。
组织归属
图 1.3.15 描绘了自 2019 年起基础模型的开发来源。到了 2023 年,有 72.5% 的基础模型是由工业界开发的。相比之下,只有 18.8% 的基础模型出自学术界。近年来,来自工业界的基础模型数量呈上升趋势。
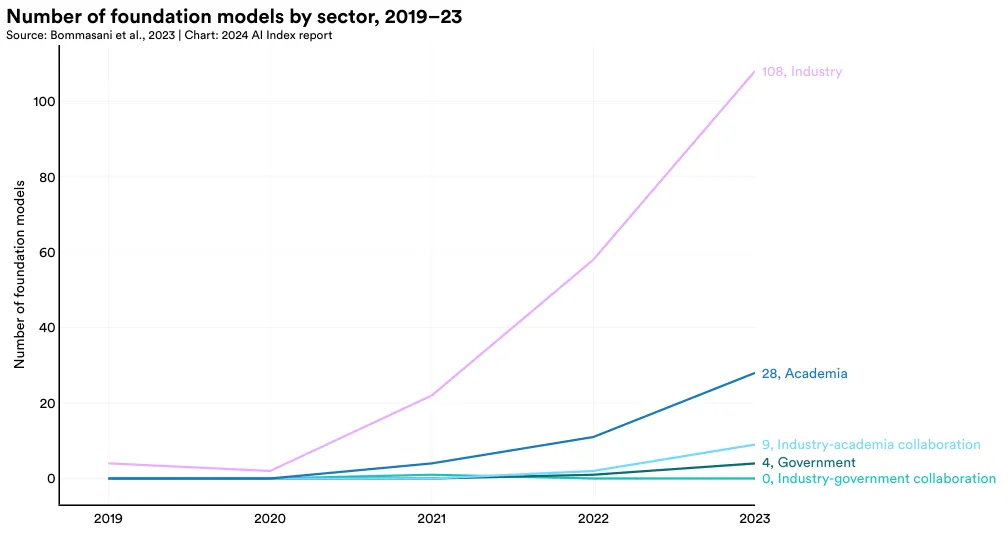
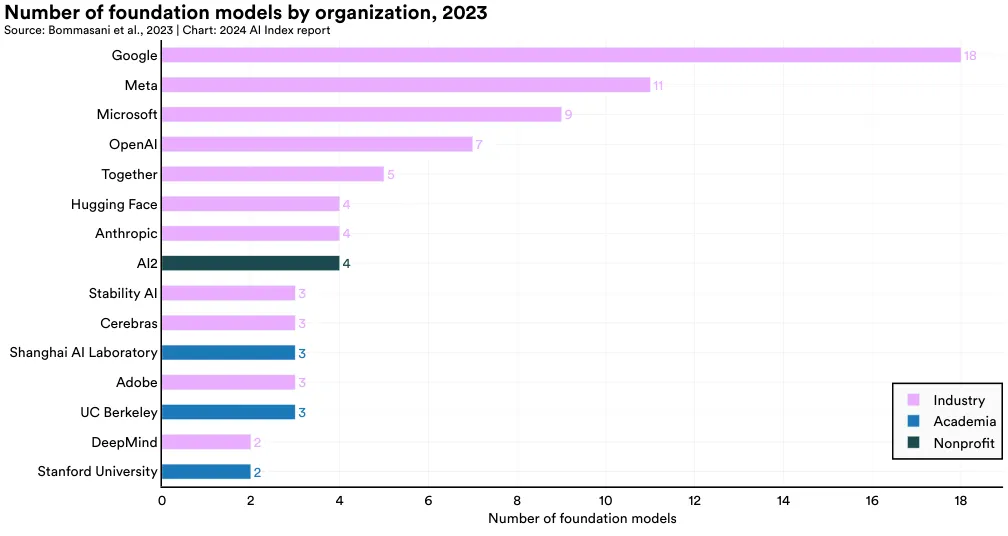
图 1.3.16 突出显示了 2023 年推出的各类基础模型的来源。Google 以 18 个模型领先,Meta 紧随其后,发布了 11 个,Microsoft 发布了 9 个。UC Berkeley 是 2023 年发布模型最多的学术机构,共发布了 3 个。
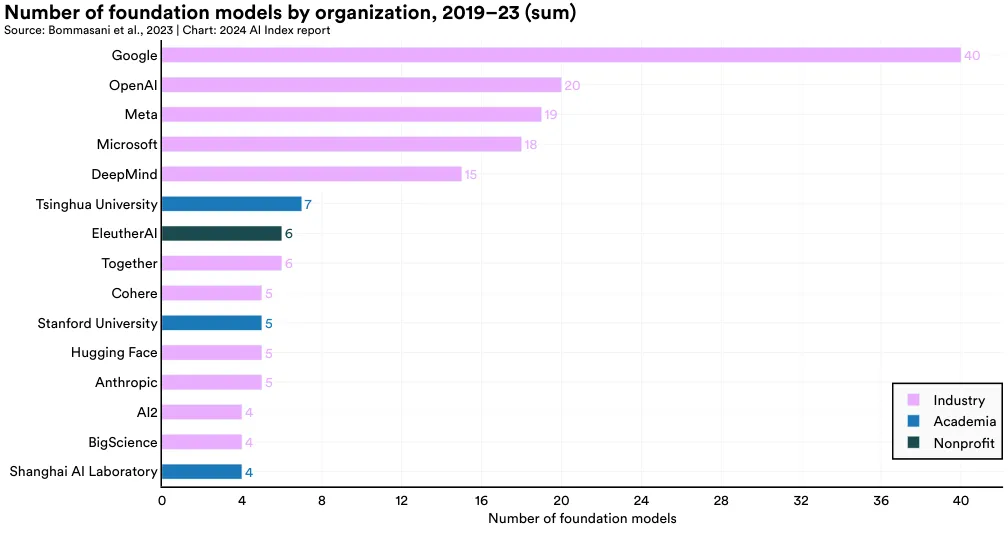
从 2019 年开始计算,Google 在基础模型发布数量上位居首位,总共发布了 40 个模型。OpenAI 以 20 个模型位列第二。在非西方地区,清华大学以 7 个发布的基础模型领先,而在美国,斯坦福大学以 5 个模型位居首位。
国家归属
考虑到基础模型在前沿 AI 研究中的重要地位,从地缘政治视角了解这些模型的国家归属显得尤为关键。图 1.3.18, 1.3.19, 和 1.3.20 显示了不同基础模型的国家归属情况。与本章早先的著名模型分析相似,一个模型如果有研究者与某个国家的总部机构有关联,则认为该模型属于该国。
2023 年,大多数的基础模型都起源于美国,数量达到 109,其次是中国的 20 个,以及英国(图 1.3.18)。从 2019 年起,美国就持续领先,成为大多数基础模型的发源地(图 1.3.19)。
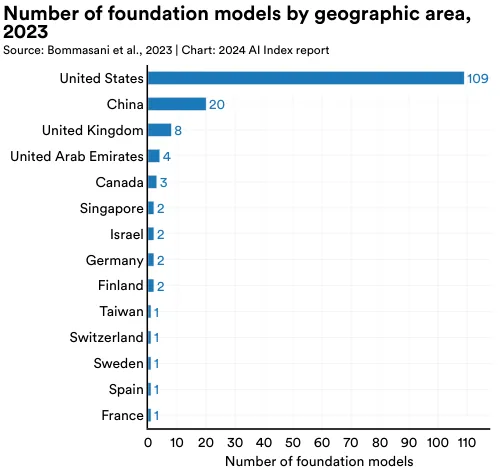
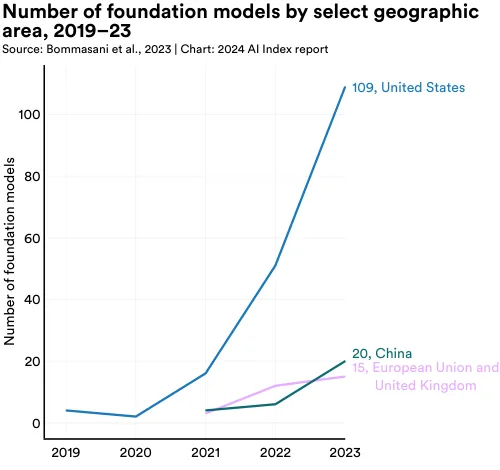
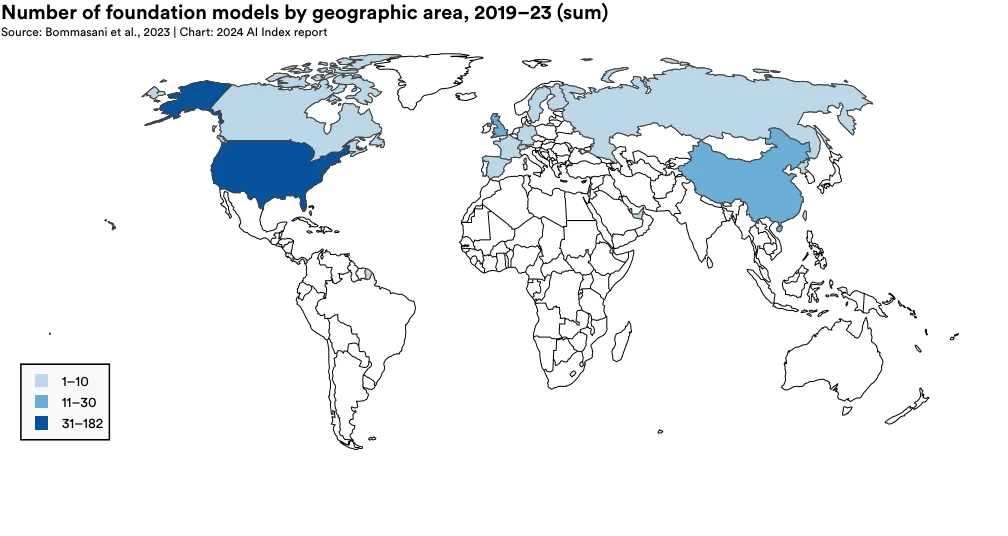
图 1.3.20 详细标示了自 2019 年以来,各国发布的基础模型的累计数量。在这段期间,美国以 182 个模型领先,中国和英国分别有 30 和 21 个。
训练成本
在关于基础模型的讨论中,一个突出的话题是它们的预计成本。虽然 AI 公司很少透露训练模型的费用,但普遍认为这些成本达到数百万美元,并且在上升。例如,OpenAI 的 CEO, Sam Altman 提到 GPT-4 的训练成本超过 1 亿美元。这种训练费用的上升实际上已经排除了大学,这些传统的 AI 研究中心,从开发自己的前沿基础模型。作为回应,政策倡议,如 President Biden 的关于 AI 的行政命令,已经试图平衡工业界和学术界之间的竞争环境,通过创建一个国家 AI 研究资源,这将授予非工业行为者进行更高级 AI 研究所需的计算和数据。
了解训练 AI 模型的成本是重要的,但关于这些成本的详细信息仍然稀少。AI Index 是最早提供基础模型训练成本估计的机构之一,在去年的出版物中。今年,AI Index 与 Epoch AI, 一个 AI 研究院,合作,大大增强和巩固了其 AI 训练成本估算的稳健性。为了估计前沿模型的成本,Epoch 团队分析了训练持续时间,以及训练硬件的类型、数量和利用率,使用来自模型相关的出版物、新闻发布或技术报告的信息。
图 1.3.21 展示了根据云计算租赁价格选择的 AI 模型的预计训练成本。AI Index 的估计证实了近年来模型训练成本显著增加的猜测。例如,在 2017 年,最初的 Transformer 模型,引入了几乎支持现代所有大语言模型的架构,训练成本约为 900 美元。RoBERTa Large, 于 2019 年发布,在许多权威理解基准测试如 SQuAD 和 GLUE 上取得了最好的成绩,其训练成本约为 16 万美元。快进到 2023 年,OpenAI 的 GPT-4 和 Google 的 Gemini Ultra 的训练成本预计分别约为 7800 万美元和 1.91 亿美元。
9 Ben Cottier 和 Robi Rahman 在 Epoch AI 领导了模型训练成本研究。 10 关于估算方法的详细描述在附录中提供。 11 本节报告的成本数字已经进行了通货膨胀调整。
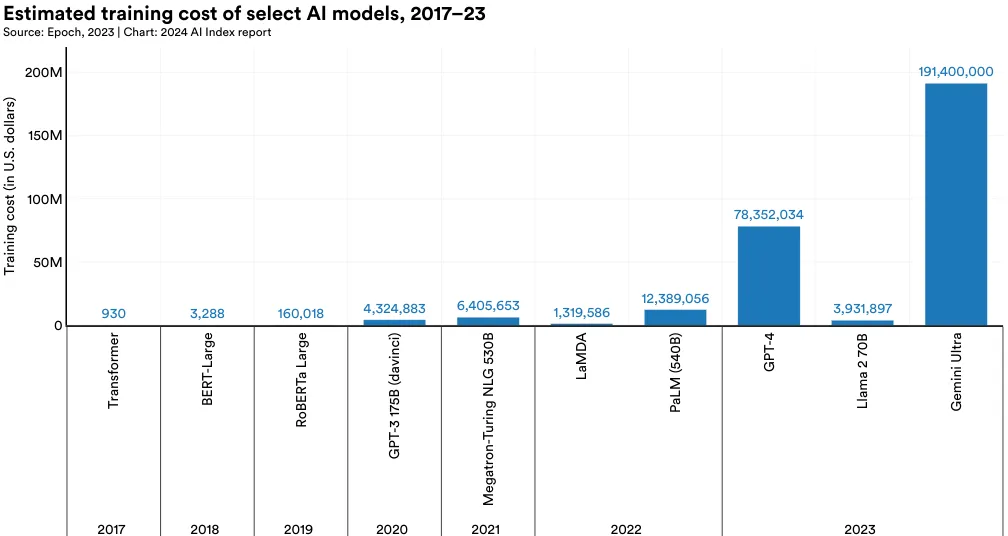
图 1.3.22: 该图显示了 AI Index 估计的各 AI 模型训练成本。如图可见,这些成本随时间急剧上升。
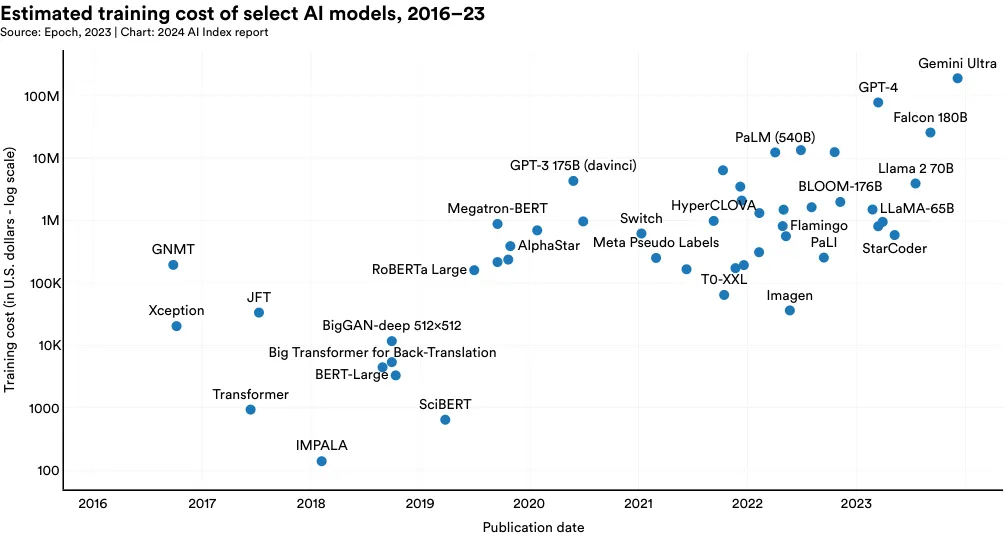
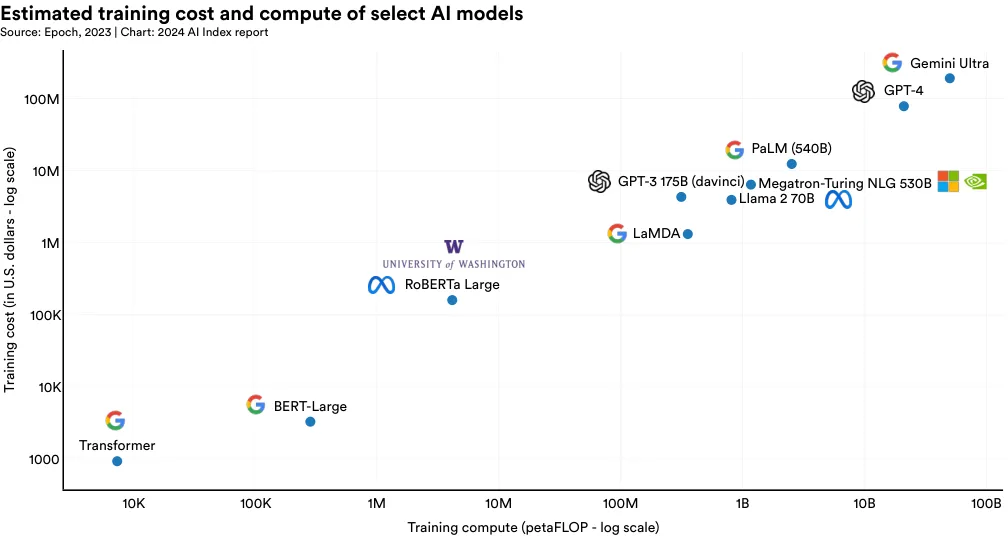
图 1.3.23: 先前 AI Index 报告已证实,AI 模型的训练成本与其计算需求之间存在直接关系。如图所示,需更多计算资源的模型,训练成本也相对更高。
AI 会议是研究者们展示研究成果和建立专业联系的关键场所。在过去二十年里,这些会议在规模、数量和声誉方面都有显著的增长。
会议出席情况
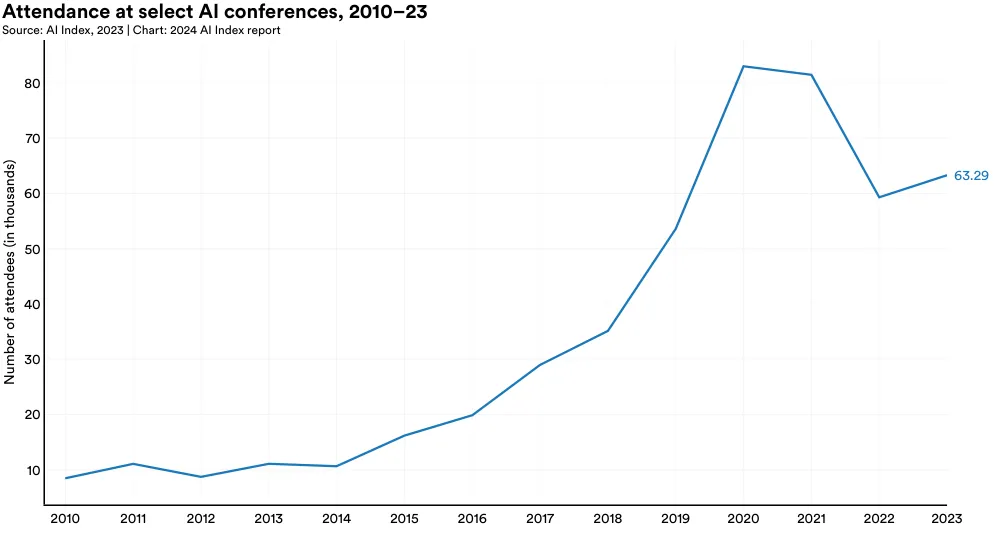
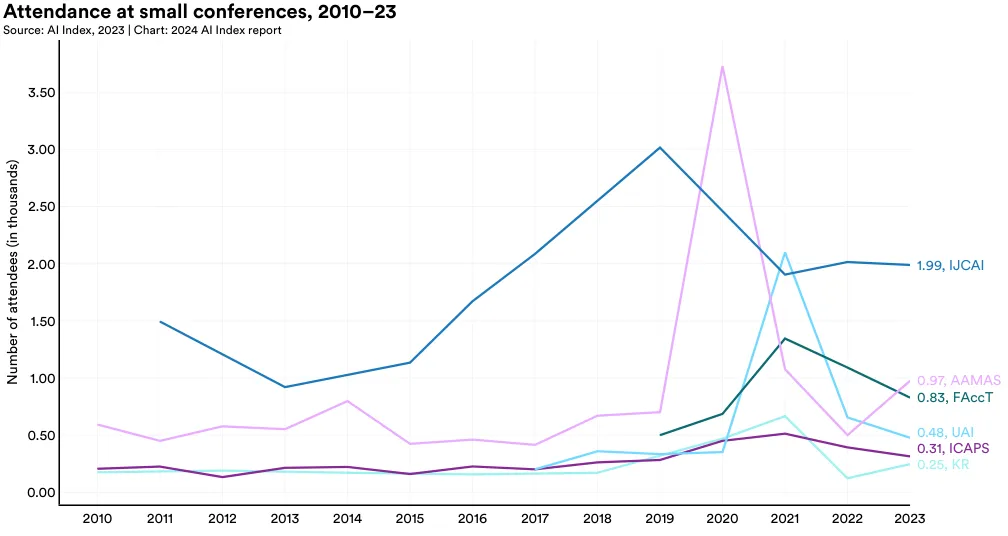
图 1.4.1 记录了自 2010 年起多个 AI 会议的参与情况。先是因为全面回归面对面会议模式导致出席人数下降,但 AI Index 的数据显示,从 2022 到 2023 年,参会人数反弹增加。[12]
具体而言,最近一年的参与总数增长了 6.7%。从 2015 年开始,每年的会议参与者平均增加了 50,000 名,这既表明了公众对 AI 研究的日益关注,也反映了新兴 AI 会议的增多。
12 近年很多会议采用虚拟或混合方式举办,相关的参与数据需谨慎对待。组织者指出,虚拟会议使全球研究者能更易参与,但确切数字难以精确统计。AI Index 跟踪的会议包括 NeurIPS、CVPR、ICML、ICCV、ICRA、AAAI、ICLR、IROS、IJCAI、AAMAS、FAccT、UAI、ICAPS、KR。
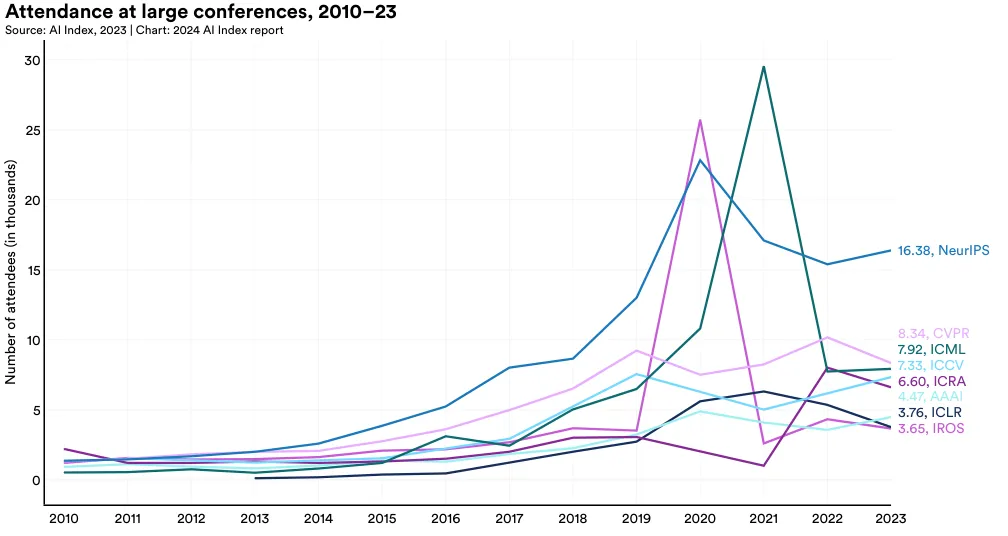
神经信息处理系统(NeurIPS)依旧是人气极高的 AI 会议之一,2023 年吸引了约 16,380 名参加者(图 1.4.2 和 图 1.4.3)。在众多重要的 AI 会议中,NeurIPS、ICML、ICCV 和 AAAI 的参与人数持续增长。但在过去一年中,CVPR、ICRA、ICLR 和 IROS 的参会人数则略有下降。
GitHub 是一个网络平台,让个人及团队可以托管、审查以及协作代码库。作为软件开发者广泛使用的工具,GitHub 助力于代码管理、项目协作及开源软件的支持。本节内容根据 GitHub 的数据,揭示了一些学术出版物未涉及的开源 AI 软件开发的趋势。
1.5 开源 AI 软件
项目
GitHub 上的项目通常包括源代码、文档、配置文件和图像等多种文件,这些文件共同组成一个完整的软件项目。图 1.5.1 显示了从 2011 年到 2023 年 GitHub 上 AI 项目数量的增长趋势。2011 年只有 845 个 AI 项目,而到了 2023 年这一数字已经达到了近 180 万个。去年 alone AI 项目数量的增长率达到惊人的 59.3%。[13]
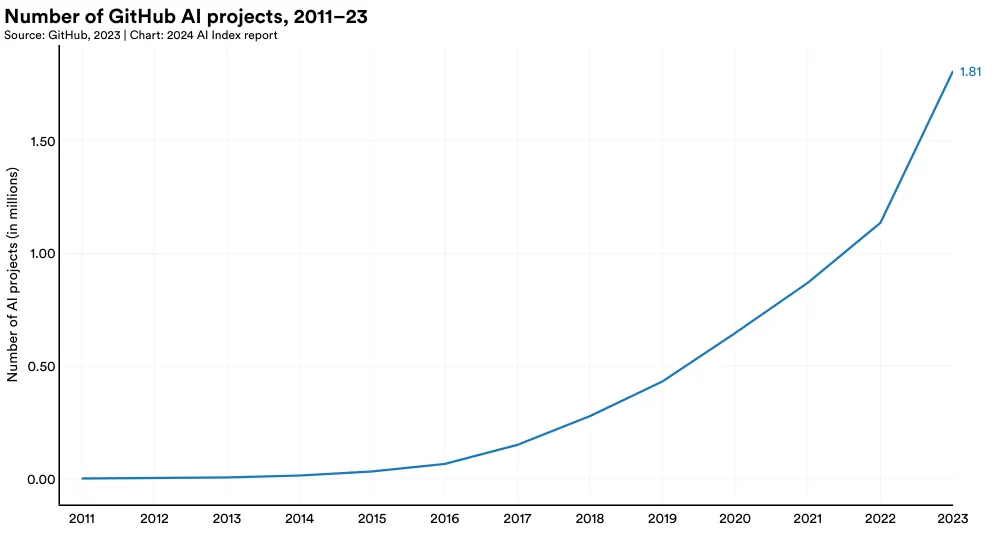
13 在过去一年里,GitHub 更新了他们识别 AI 项目的标准,开始使用一篇新发表的研究论文中的生成式 AI 关键词来分类 AI 项目。这是 AI 指数报告中首次使用这种新方法。同时,GitHub 停止使用 OECD 的国家级项目映射,转而使用基于服务器数据的地理映射,使得数据覆盖更全面。因此,本报告中的数据与前几版可能有所不同。
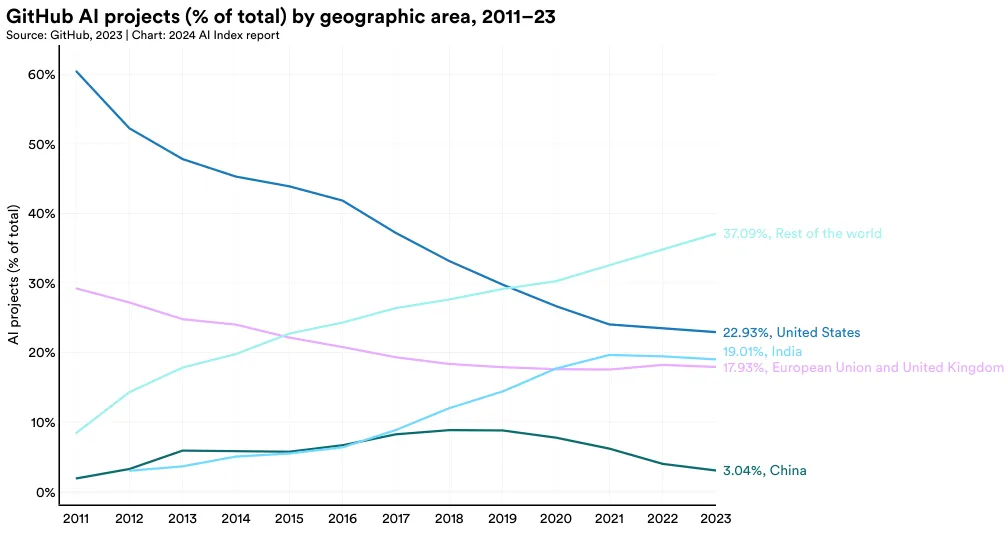
图 1.5.2 绘制了 2011 年以来 GitHub 上的 AI 项目在各地区的分布情况。2023 年,美国的 AI 项目占总量的 22.9%,居首位,印度以 19% 的比例紧随其后,欧盟和英国则共占 17.9%。从 2016 年开始,美国在 GitHub 上的 AI 项目比例持续减少。
星标功能
在 GitHub 上,用户可以通过“星标”功能来表达对某个开源项目的喜爱和支持,这类似于我们在社交网络上给帖子点赞。在 AI 编程社区中,一些著名的编程库如 TensorFlow, OpenCV, Keras, 和 PyTorch 尤其受到欢迎,经常收到大量星标。例如,TensorFlow 是一个广泛使用的库,专门用于开发和部署机器学习模型,而 OpenCV 提供了多种计算机视觉工具,包括对象识别和特征分析。
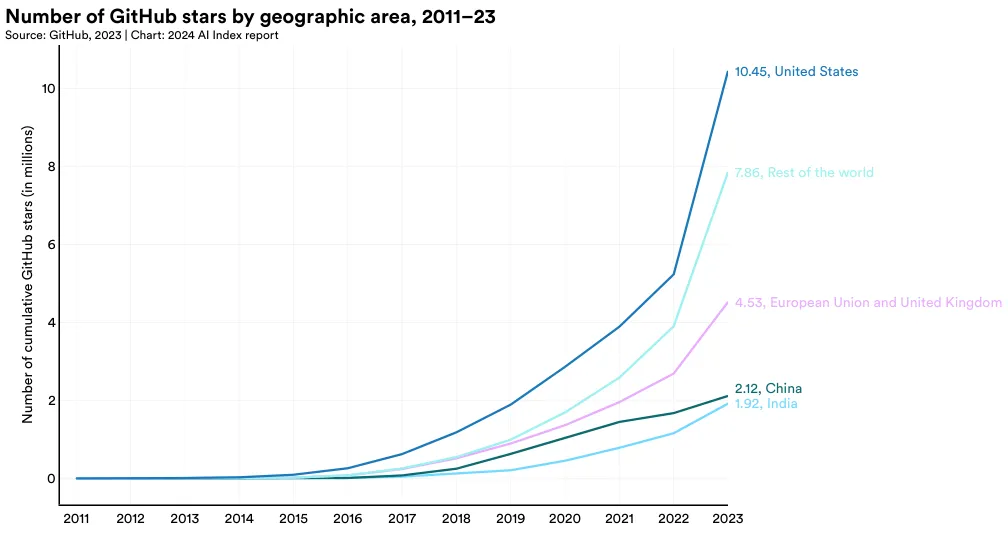
过去一年中,AI 项目的星标总数在 GitHub 上有了大幅增长,从 2022 年的四百万增至 2023 年的一千二百二十万(图 1.5.3)。这一显著增长不仅反映了项目数量的增加,也标志着开源 AI 软件开发的快速进展。
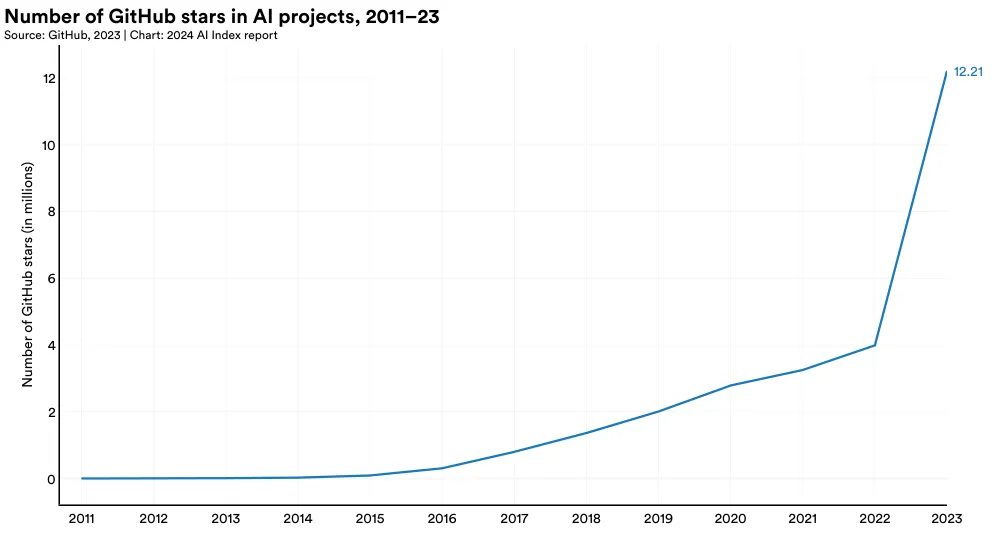
在 2023 年,美国在这方面表现尤为突出,获得了约一千零五百万的星标(图 1.5.4)。包括欧洲联盟、英国、中国和印度在内的各大地区都在这一年里看到了他们的项目星标数的增加。
附录
致谢
我们感谢 Ben Cottier 和 Robi Rahman 在 Epoch 公司对 AI 训练成本进行深入分析的领导作用,Robi Rahman 在全球重要 AI 系统国籍归属研究中的领导,以及 James da Costa 在基础模型国籍及行业分析中不可或缺的编码工作。
AI 会议出席
AI 指数今年联系了多个 AI 会议的主办方,询问他们的总参与人数。对于 those conferences that publicly shared their attendance figures, we simply used these numbers and did not make further inquiries.
由 Autumn Toney 编撰
位于乔治城大学沃尔什外事学院的安全与新兴技术中心 (CSET) 是一个专注于政策研究的机构。它通过在安全和技术的交汇点上进行数据驱动研究,向政策制定者提供客观中立的分析见解。
更多关于 CSET 如何处理书目和专利数据的信息,可以查询新兴技术观察站网站上的国家活动追踪器 (CAT) 相关文档。1 通过使用 CAT,用户可以直接操作国家级的书目、专利以及投资数据。2
从 CSET 合并的学术文献语料库的出版物
来源
CSET 的合并学术文献语料库结合了来自 Clarivate 的 Web of Science, OpenAlex, The Lens, Semantic Scholar, arXiv 和 Papers With Code 的不同出版物。
更新:CSET 的合并学术文献语料库的来源列表已从之前的年份更改,包括 OpenAlex, The Lens 和 Semantic Scholar 的加入,以及 Digital Science 的 Dimensions 和中国国家知识基础设施 (CNKI) 的排除。
方法论
为了创建合并语料库,CSET 使用出版元数据在列出的来源之间进行了去重,然后合并了链接出版物的元数据。为了分析 AI 出版物,CSET 使用了自 2010 年以来发布的该语料库的英语子集。CSET 研究人员开发了一个分类器,通过利用 arXiv 仓库来识别与 AI 相关的出版物,其中作者和编辑按主题标记论文。3
更新:AI 分类器已从以前年份使用的版本更新;Dunham, Melot, 和 Murdick4 描述了之前实施的分类器;Schoeberl, Toney, 和 Dunham 描述了在此分析中使用的更新分类器。
CSET 将分析语料库中的每一篇出版物与来自 Microsoft Academic Graph (MAG) 的研究领域模型的预测相匹配,该模型提供描述已发布研究领域的层次化标签和相应的分数。5 CSET 研究人员识别了自 2010 年以来我们的 AI 相关出版物语料库中最常见的研究领域,并记录了所有其他领域的出版物为“其他 AI”。然后,英语 AI 相关出版物按其最高得分领域和出版年份进行统计。 更新:分配 MAG 研究领域的方法已从以前年份使用的方法更新。Toney 和 Dunham 描述了在此分析中使用的研究领域分配流程;以前的年份使用了原始的 MAG 实现。
CSET 还提供了与每个国家相关的 AI 相关工作的出版数量和逐年引用情况。如果一篇出版物至少有一个作者的组织隶属地位于该国,那么这篇出版物与一个国家相关。如果没有观察到国家,出版物则被标记为“未知/缺失”国家标签。并非所有出版物都有引用计数;那些没有计数的不包括在引用分析中。2010 年至 2022 年间超过 70% 的英语 AI 论文有可用的引用数据。
此外,如果数据可用,还提供了按年份和出版类型(如学术期刊文章、会议论文等)分类的出版数量。这些出版类型是按照前文描述的国家归属来分类的。
CSET 还介绍了出版物的归属部门,这里的部门分类是根据作者的归属进行的,类似于之前的国家归属分析。不是所有的归属都明确指出了所属部门;主要是因为 CSET 研究人员大多使用 ROR 来确定这些信息,而不是所有机构都能在 ROR 中被找到或关联。6 当可知的归属部门信息存在时,相关的论文按照部门和年份进行统计。
CSET 对于每篇论文中不同部门的作者之间的合作关系也进行了统计,这种合作关系被视为不同部门之间的独立组合。每种合作关系只被统计一次:例如,一篇论文如果由两位学术界人士和两位工业界人士合写,这将被算作一次学术与工业的合作。
来自 CSET 的 AI 和机器人相关专利数据集 来源说明
CSET 和 1790 Analytics 共同创建了一个涵盖 AI 和机器人的专利数据库。这个数据库包含了来自 The Lens、1790 Analytics 和 EPO 的 PATSTAT 的数据,并通过专利的 CPC/IPC 编码及关键词来识别与 AI 和机器人相关的专利。
使用方法
在这项分析中,根据年份和国家对专利进行了分类,并使用“专利家族”作为分类标准。Schoeberl, Toney 和 Dunham 介绍了这种新的分类方法。
CSET 用一个基于 Microsoft Academic Graph (MAG) 分类系统的模型来预测每项研究的领域,这个模型可以提供研究领域的层级标签和评分。从 2010 年开始,CSET 识别了在 AI 相关出版物中最常见的研究领域,并把其他领域的出版物归类为“其他 AI”。这些出版物按照得分最高的研究领域和出版年份进行了统计。
更新信息:与过去相比,分配 MAG 研究领域的方法已经更新。Toney 和 Dunham 详细描述了这一新的流程。
CSET 同时提供了各国在 AI 领域的相关研究发表数量和每年的被引次数。一篇研究若有作者所在的机构位于某国,则认为该研究与此国相关。若无法确定研究归属的国家,则此研究标记为“未指定的国家”。并非所有研究都有被引数据,未包含被引数据的研究不会出现在引用次数的统计中。从 2010 年到 2022 年,超过 70% 的英文 AI 研究论文都提供了被引数据。
此外,CSET 根据年份和发表形式(如学术期刊文章、会议论文等)提供了发表数量的统计,这些统计按研究所属国家的细节进行分类。
CSET 也记录了研究的所属领域,这些领域通过作者的机构归属来确定。不是所有的机构归属都被明确标注领域,CSET 的研究依赖于 ROR 数据库,但并非所有机构都能与之对应。在已知领域的情况下,相应的论文被归类计算。
CSET 还统计了跨领域的合作,这种合作以不同领域内的作者组合计算。每种合作形式只被计算一次:比如,一篇论文如果有两名来自学术界的作者和两名来自工业界的作者,这将只被记为一次学术与工业的合作。
人工智能与机器人专利分析报告来自 CSET 数据库
来源说明
由 CSET 与 1790 Analytics 合作开发的人工智能专利数据集,涵盖了 The Lens、1790 Analytics 与 EPO 的 PATSTAT 数据库中的信息。这些专利都是根据特定的分类代码 (CPC/IPC) 和关键字筛选出来,专注于人工智能和机器人技术的发展与应用。
研究方法
在这项分析中,研究人员将专利按照申请年份和国家进行分类,并在“专利家族”级别进行统计。专利的年份信息是从该家族中首次公布的日期中获取的。专利的国家归属是根据其最初的申请地点决定的 (例如,若专利首次在美国专利商标局 (USPTO) 提交,随后在德国专利局提交,则该专利归为美国发明者所有)。值得注意的是,如果一项专利在同一天在多个国家申请,它可能同时被多个国家拥有。
此外,向世界知识产权组织 (WIPO)、欧洲专利组织 (EP) 和不属于欧盟的西班牙特别地区 (EA) 提交的专利,都统一列入“世界其他地区”类别。
全球 AI 基础模型分布追踪
为了精确追踪全球各国在 AI 基础模型方面的发展状况,AI Index 团队执行了以下步骤:
- 2024 年初,团队制作了一份生态系统图的快照。
- 通过分析相关论文和技术文档,将模型作者根据其所属机构的国家进行分类。如果涉及国际机构,作者通常归属于该机构的总部所在国,除非有更明确的指定。
- 收集各个重要时间节点的代表性公开发表物,按国家进行汇总,从而计算出每个国家在每个时间段内对 AI 重大研究的贡献。
- 分析各国在 AI 研究上的贡献变化趋势,以识别发展动态。
重要模型分析时代
AI 预测研究小组 Epoch 维护了一个包含标志性 AI 和 ML 模型的数据库,这些模型的详细信息包括创作者、出版情况、(合)作者名单、引用次数、完成的 AI 任务类型及训练所用的计算资源。
这些论文的作者国籍对于预测 AI 在全球地缘政治中的影响至关重要。随着各研究机构和科技企业纷纷推出高级 ML 模型,全球 AI 发展的地理分布可能出现新的集中或分散趋势,这将直接影响到地缘政治格局,因为 AI 将成为近未来经济与军事力量的核心。
为追踪不同国家在标志性 AI 研究出版物上的贡献,Epoch 数据集按以下方法进行标记:
-
数据集的快照在 2024 年 1 月 1 日完成,涵盖了选定的标志性模型论文。这些论文是根据其重要性、相关性及独特性来选取的,具体标准详见计算趋势数据集的文档。
-
论文中的作者按其所在机构的国家归属进行标记。对于国际组织的作者,归属国是该组织的总部所在地,除非有更具体的说明。
-
将所有标志性论文按时间段(如每月或每年)聚集,并计算各国在每个时间段内的研究贡献总和。
-
分析不同国家的研究贡献,以识别发展趋势。
GitHub
识别 AI 项目
在哈佛商学院、微软研究院及微软 AI for Good 实验室的合作下,GitHub 使用 Gonzalez、Zimmerman 和 Nagappan 在 2020 年以及 Dohmke、Iansiti 和 Richards 在 2023 年提出的方法识别公开 AI 项目库。这些项目库标记有 AI/ML 和生成式 AI 的相关主题标签,或是“机器学习”、“深度学习”和“人工智能”。此外,GitHub 还包括了那些依赖 Python 的 PyTorch、TensorFlow 或 OpenAI 库的项目库。
将 AI 项目映射到地理区域
公共 AI 项目通过使用 IP 地址地理定位技术来确定项目所有者每年的模式位置 (mode location) 映射到地理区域。每个项目所有者都根据他们与 GitHub 互动时的 IP 地址被分配一个位置。如果项目所有者在一年内改变位置,那么该项目的位置将由其所有者在那一年中每天抽样的模式位置确定。此外,即使项目所有者在那天没有进行任何活动,项目所有者的最后已知位置也会每天被带入。例如,如果一个项目所有者在美国进行活动,然后六天未活动,那么这个项目所有者将被认为在那七天内一直在美国。
训练成本分析
为了创建成本估算的数据集,Epoch 数据库被筛选出在大规模 ML 时代 [9] 发布且在以发布日期为中心的两年窗口内训练计算超过中位数的模型。这样筛选出了最大规模的 ML 模型。根据这些标准,有 138 个符合条件的系统。在这些系统中,48 个有足够的信息来估算训练成本。
对于选定的 ML 模型,从相关的出版物、新闻稿或技术报告中确定了训练时间以及训练硬件的类型、数量和利用率。这些模型所使用的计算硬件的云租用价格是从云服务商网站的在线历史档案中收集的 [10]。
训练成本是通过将小时云租用成本率 (在训练时) [11] 与硬件小时数相乘来估算的。这样计算出的成本是用作者在训练时使用的同样的硬件训练每个模型的成本。然而,一些开发者选择购买硬件而不是租用云计算机,因此开发者实际承担的成本可能会有所不同。
在估算这些模型的训练成本时遇到了各种挑战。开发者经常不公开训练的持续时间或使用的硬件。在其他情况下,对于所使用的硬件,云计算定价可能不可用。这项关于训练成本趋势的调查将在即将发布的 Epoch 报告中继续,包括一个扩展的数据集,其中包括更多的模型和硬件价格。
1 https://eto.tech/tool-docs/cat/\ 2 https://cat.eto.tech/\ 3 Christian Schoeberl, Autumn Toney, 和 James Dunham 的论文“Identifying AI Research” (安全与新兴技术中心,2023 年 7 月), https://doi.org/10.51593/20220030.\ 4 James Dunham, Jennifer Melot, 和 Dewey Murdick 的预印本“Identifying the Development and Application of Artificial Intelligence in Scientific Text,”arXiv:2002.07143 (2020).
5 这些评分根据学科领域与论文的相似度得出,详情可参考 Autumn Toney 和 James Dunham 的《跨领域和语言的科研文献多标签分类》,发表于 2022 年第三届学术文件处理研讨会 (计算语言学会): 105–14, https:// aclanthology.org/2022.sdp-1.12/.
6 更多关于 ROR 数据集的信息,请访问 https://ror.org/。\ 7 分析专利时,我们以“专利家族”为单位而非单一“专利文件”,因为一个“专利家族”可能包含多个由同一发明者或指派者提交的相关专利。这样可以有效避免因多个文件或多区域申请而导致的数据膨胀。
8 在 2022 年的 CSET AI 指数分析中,我们初步选择使用专利家族最新的公布日期来获取更新信息,如专利修正等。但为了与其他数据产品如国家活动追踪器(访问 https://cat.eto.tech/ 查看)保持一致,我们后来决定使用首次文件提交的年份作为分析基准。
9 根据《机器学习三时代的计算趋势比较》(Epoch, 2022),我们设置的数据截止日期为 2015 年 9 月 1 日。
10 我们从互联网档案馆的 Wayback Machine 中获取的 Amazon Web Services, Microsoft Azure, 和 Google Cloud Platform 的价格目录存档中收集了历史价格数据。
11 在开发这个模型时,所选择的租赁成本标准是根据模型开发者所用的硬件和云服务商最近公布的价格来确定的,具体是按照三年的租期承诺来计算的价格,同时还需要从公布的日期起往回推两个月,再减去训练用时。如果没有找到这样的具体价格,就选择一个相似时间点的相同硬件和服务商的价格,或者相同硬件但不同云服务商的价格。如果没有相应的三年租期承诺的价格,那么会根据这家云服务商通常的折扣率来估算一个价格。如果找不到完全一样的硬件型号,比如说“NVIDIA A100 SXM4 40GB”,就会用一个相似的型号来代替,例如“NVIDIA A100”。\