2023 年十篇值得关注的 AI 研究论文 [译]
Sebastian Raschka, PhD
今年的感觉特别不同。我已经在机器学习和人工智能领域工作、研究和实践了十多年,但我从未见过像今年这样,这些领域如此受欢迎且发展迅速。
为了总结 2023 年在机器学习和人工智能研究领域充满事件的一年,我非常兴奋地与大家分享我今年阅读过的十篇引人注目的论文。我的个人研究重点更倾向于大语言模型(Large Language Model, LLM),因此你会发现,我选的论文中,大语言模型的比计算机视觉的要多。
我没有将这篇文章标为“2023 年顶尖 AI 研究论文”,因为决定哪篇是“最佳”的标准太主观。我选择的论文是那些我特别喜欢或认为有深远影响和值得注意的。(这些论文的排序是我推荐的阅读顺序,并不是按照它们的质量或影响力来排序的。)
另外,如果你阅读到这篇文章的最后,你会发现一个小惊喜。感谢你的支持,祝你新年开始得美好!
1) Pythia — 大规模训练运行的洞见
在 Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling 这篇论文中,研究者们最初发布了从 70M 到 12B 参数不等的 8 个大语言模型(LLM),其权重和数据均为公开发布,这在业界是非常罕见的。
但我认为,这篇论文的亮点在于他们还公开了训练的细节、分析和洞见(一些被展示在下方的注释图表中)。
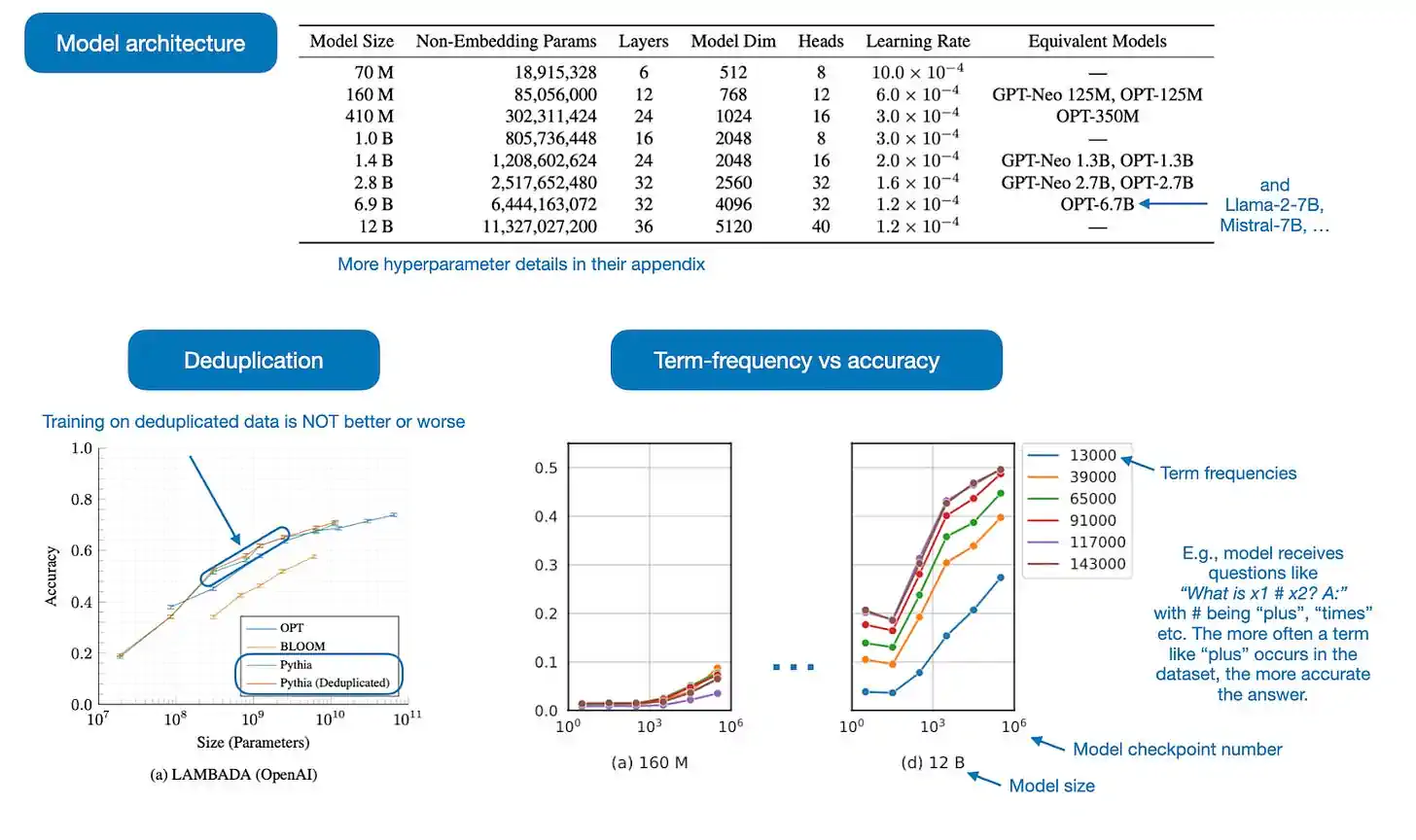
Pythia 论文探讨了以下几个问题:
-
在重复数据上进行多周期预训练是否有效果?研究发现,数据去重对模型性能既没有正面也没有负面影响。
-
训练顺序是否会影响模型的记忆能力?结果显示,并不会。这是一个遗憾,因为如果训练顺序真的有影响,我们可以通过调整数据顺序来减轻模型不必要的逐字记忆问题。
-
预训练中的词频是否会影响任务表现?答案是肯定的,对于频繁出现的术语,模型在少样本测试中的准确率通常较高。
-
增加批次大小是否会影响训练效率和模型的收敛?实验证明,增加批次大小可以缩短训练时间的一半,但不会影响模型的收敛。
现在,短短六个月后,这些大语言模型已不再具有颠覆性。然而,我引用这篇论文的原因是,它不仅试图回答关于训练设置的一些有趣问题,还在细节和透明度方面做出了积极的示范。此外,其中规模小于 1B 的 LLM 是进行小型研究和实验的理想模板,也是进行预训练实验的良好起点(这是他们的 GitHub 仓库链接)。
我对 2024 年的愿望是,我们能看到更多类似的研究和精心撰写的论文在未来一年中涌现!
2) Llama 2: 开源基础与微调聊天模型
Llama 2: 开源基础与微调聊天模型 是 Meta 首款广受欢迎的 Llama 论文的续作。
Llama 2 模型的参数数量从 70 亿到 700 亿不等,它们是这篇论文受到关注的原因之一:这些模型依然是目前最强大、使用最广泛的开源模型。值得一提的是,Llama 2 的许可证 也允许将这些模型用于商业应用(具体详情请参阅访问请求页面)。
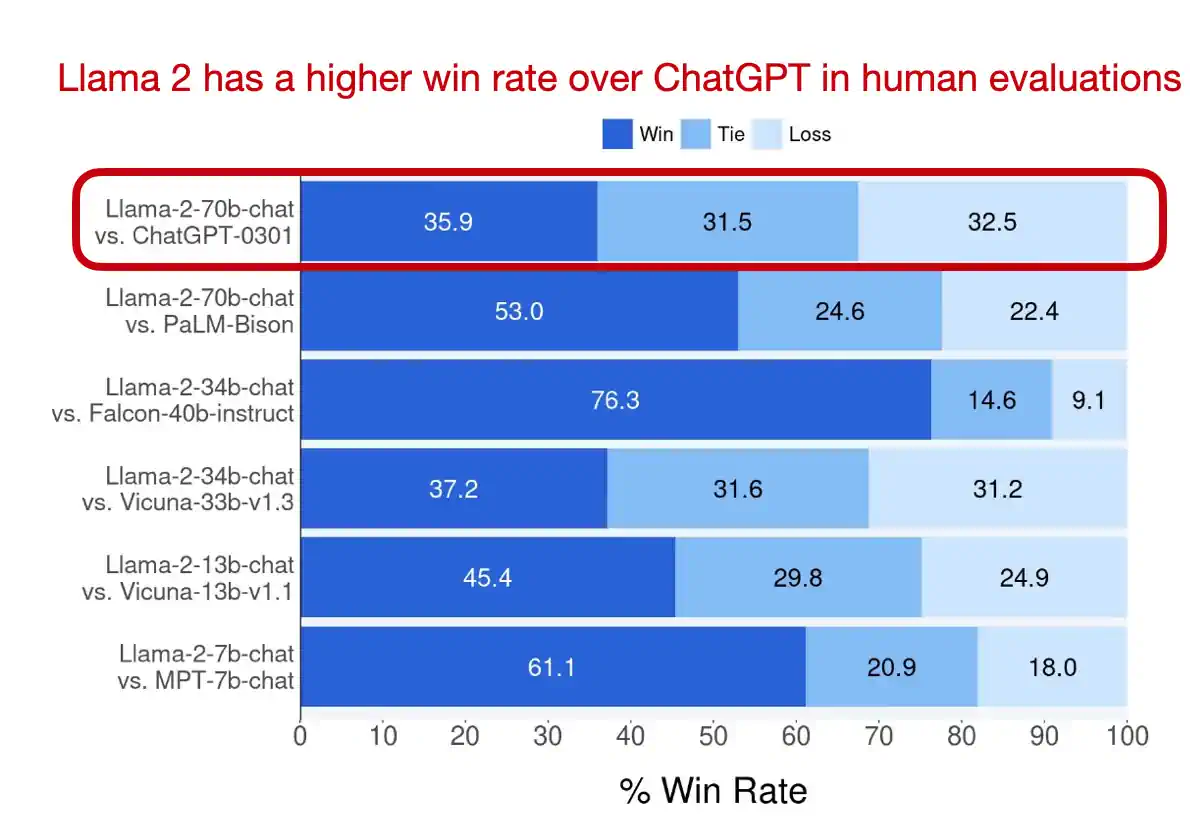
在模型方面,Llama 2 与众不同的地方在于,除了标准的预训练模型外,还包括了经过强化学习与人类反馈 (RLHF) 微调的聊天模型,这种方法也是打造 ChatGPT 的关键。这些经过 RLHF 微调,能够根据人类指令行动的模型依然非常罕见。
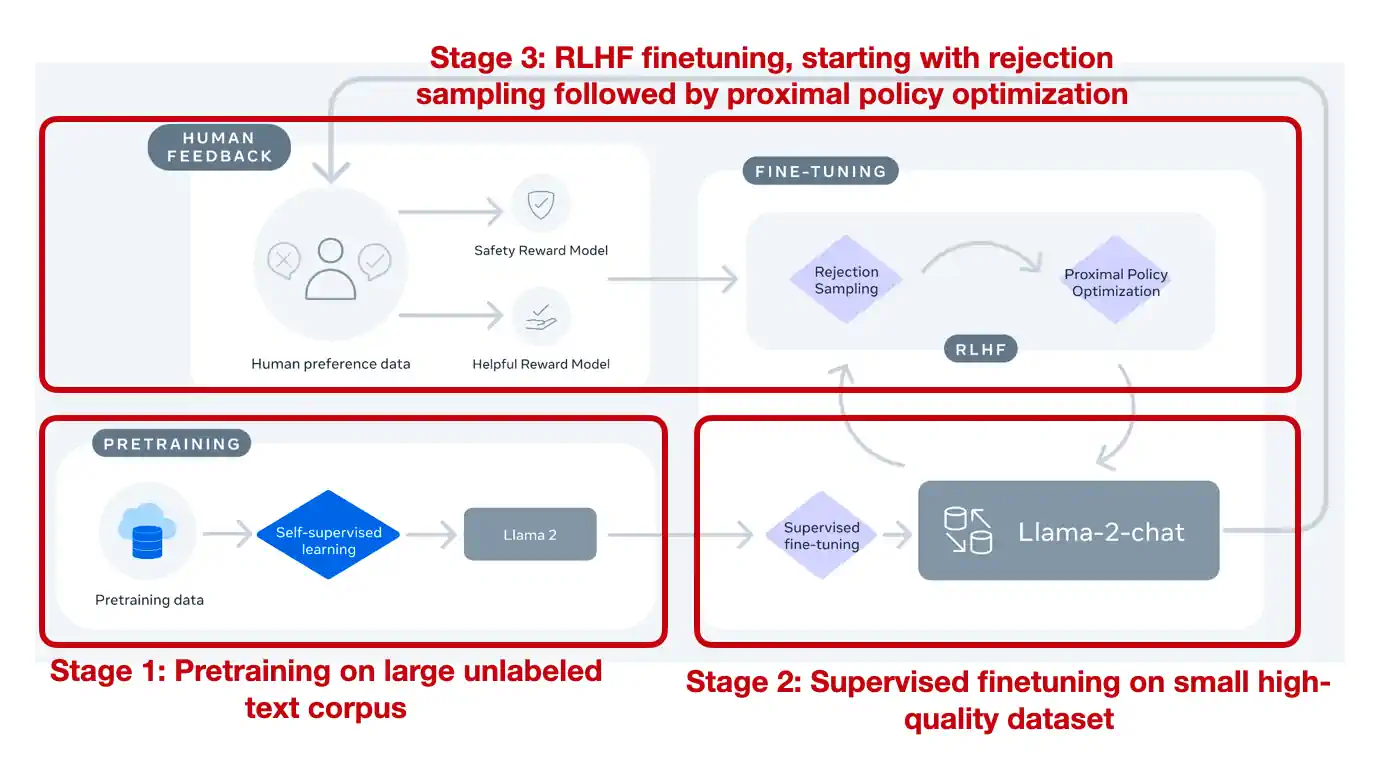
有关 RLHF 以及其在 Llama 2 中如何使用的更多细节,请参考我下面这篇更为全面的独立文章:
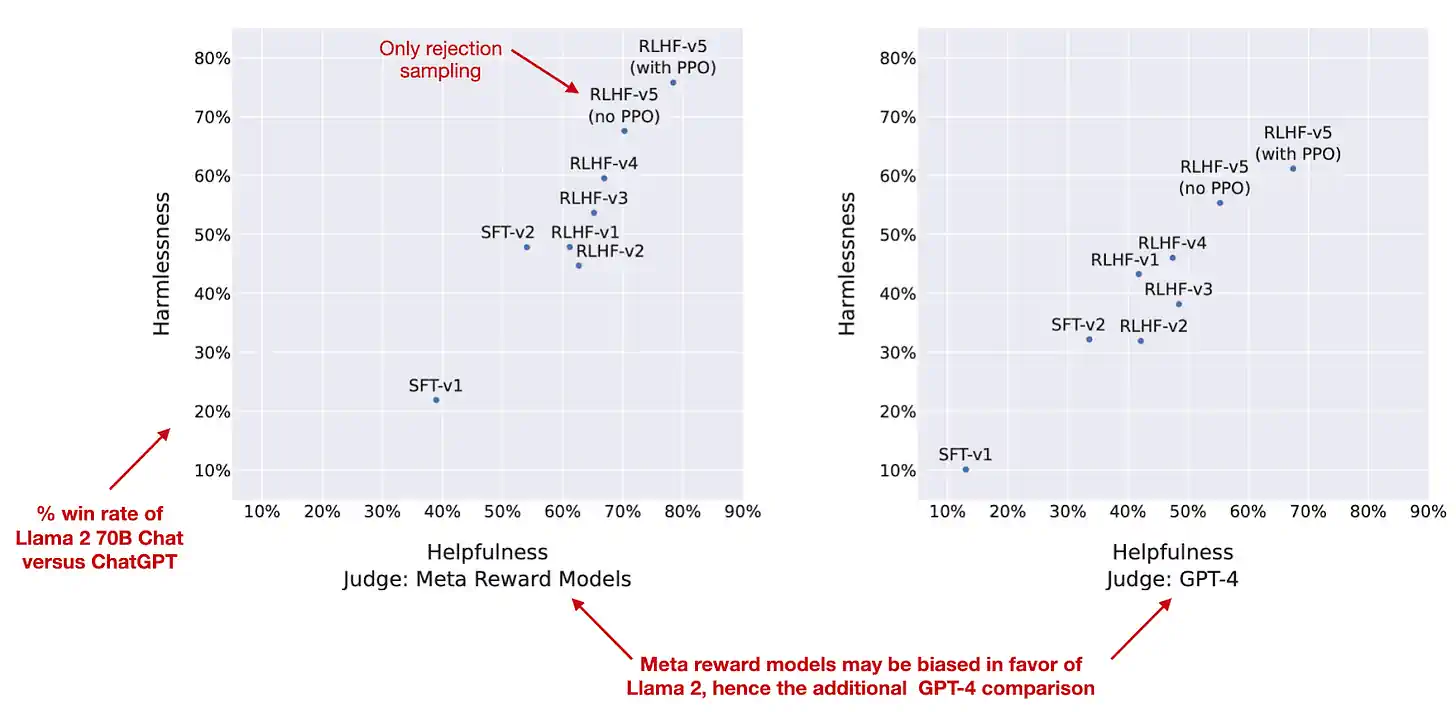
除了因为 Llama 2 模型被广泛使用且包含了经过基于人类反馈的强化学习 (RLHF) 指导细化调整的版本而备受关注外,另一个让我决定将这篇论文列入的原因是,它附带了一份深入详尽的 77 页研究报告。
报告中,作者详细展示了 Llama 2 70B 聊天模型的发展历程,从最初的监督式微调 (SFT-v1) 到使用比例策略优化 (PPO) 的最终基于人类反馈的强化学习微调阶段 (RLHF-v5)。图表清晰地反映了在无害性和实用性两个维度上的持续提升,如下方的注释图所示。
虽然像 Mistral-8x7B、DeepSeek-67B 和 YI-34B 这类模型在公共基准测试中表现优于更大的 Llama-2-70B 模型,但 Llama 2 依然是在公开可用的大语言模型和基于此开发新方法时的常见且受欢迎的选择。
此外,虽然一些基准测试显示可能有更优秀的模型出现,但今年一个主要问题是这些测试的可靠性。举个例子,我们怎样才能确信这些模型不是在这些基准测试上进行过特训,而且得分不是被人为提高的?在传统机器学习领域,当有人提出新的梯度提升(Gradient Boosting)模型时,我们很容易复现并验证其结果。然而,现在由于训练大语言模型(Large Language Model)不仅成本高,而且过程复杂,加上大多数研究者不愿透露模型架构或训练数据的细节,这种验证变得几乎不可能。
在总结中,虽然如今每个大公司都在推出各自的专利大语言模型(例如 Google 的 Bard 和 Gemini,Amazon 的 Q,Twitter/X 的 Grok,以及 OpenAI 的 ChatGPT),但看到 Meta 坚定不移地投身于开源领域,这一点让人感到振奋。
3) QLoRA: 高效微调量化大语言模型
QLoRA: 高效微调量化大语言模型 因其使流行的 LoRA(低秩适应)技术更节省内存而在今年的大语言模型研究和微调领域受到青睐。这项技术的简要要点是,它能让我们在更小容量的 GPU 上运行更大型的模型。
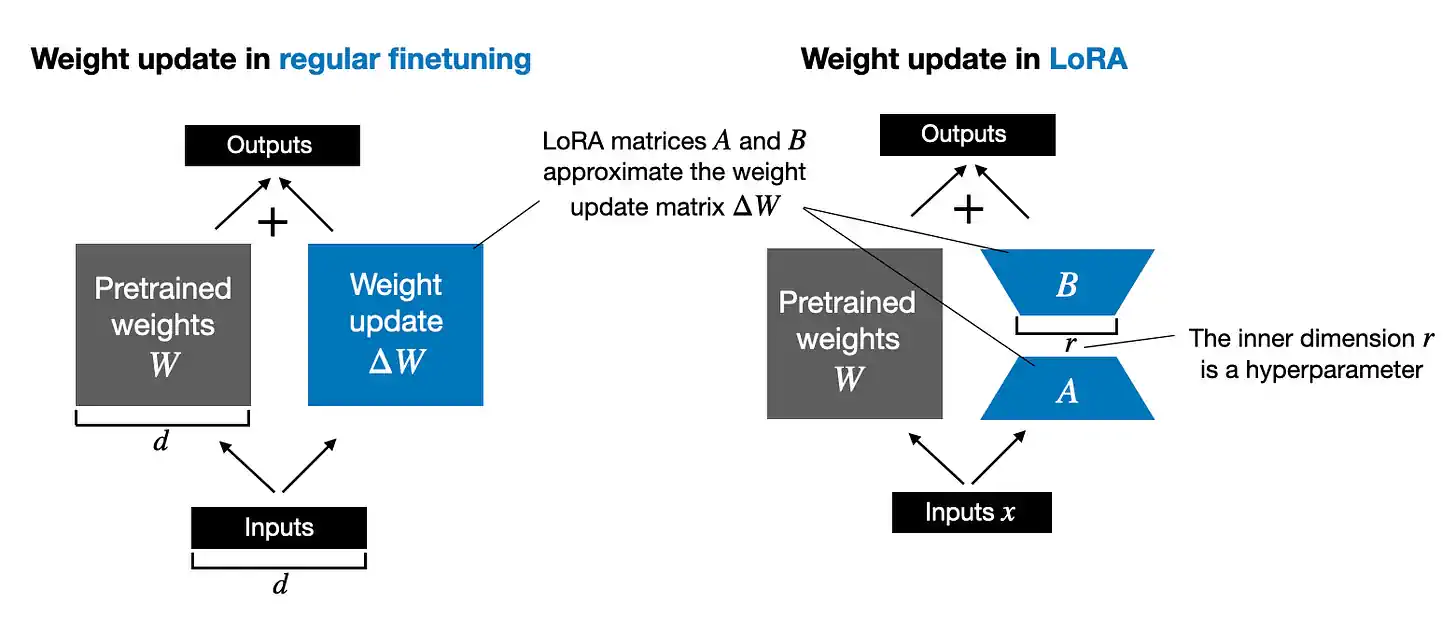
QLoRA 是量化 LoRA(低秩适应)的缩写。传统的 LoRA 方法是在预训练的大语言模型中添加低秩矩阵到模型层的权重中,使其在微调过程中的资源需求减少。
在 QLoRA 中,这些低秩矩阵经过量化处理,即降低它们的数值精度。具体来说,就是把矩阵中连续的数值转换为有限的离散级别。这种处理方式有效减少了模型对内存和计算资源的需求,因为处理精度较低的数字占用更少的内存。
根据 QLoRA 论文,QLoRA 技术能够显著减少 65B Llama 模型的内存需求,使其适用于单块 48 GB GPU(例如 A100)。经过量化 4 位训练的 65B Guanaco 模型,即使在全面维持 16 位微调 (finetuning) 任务性能的情况下,也能在仅仅 24 小时的微调后接近 ChatGPT 的性能,达到了 99.3%。
我今年进行了众多 QLoRA 实验,发现 QLoRA 在微调过程中有效减少 GPU 内存需求。但这种方法也有其代价:额外的量化步骤增加了计算负担,导致训练速度略低于常规 LoRA。

随着研究人员和从业者致力于创建定制的大语言模型 (LLM),LLM 微调的重要性日益凸显。我特别赞赏 QLoRA 这样的技术,它通过降低 GPU 内存需求门槛,使得这一过程变得更加易于操作和普及。
4) BloombergGPT:专注于金融领域的大语言模型
在今年发表的众多论文中,BloombergGPT:专注于金融领域的大语言模型 似乎是一个不太常见的选择,被列入前十大论文列表。其原因并非在于它带来了翻天覆地的新见解、方法论或开源模型。
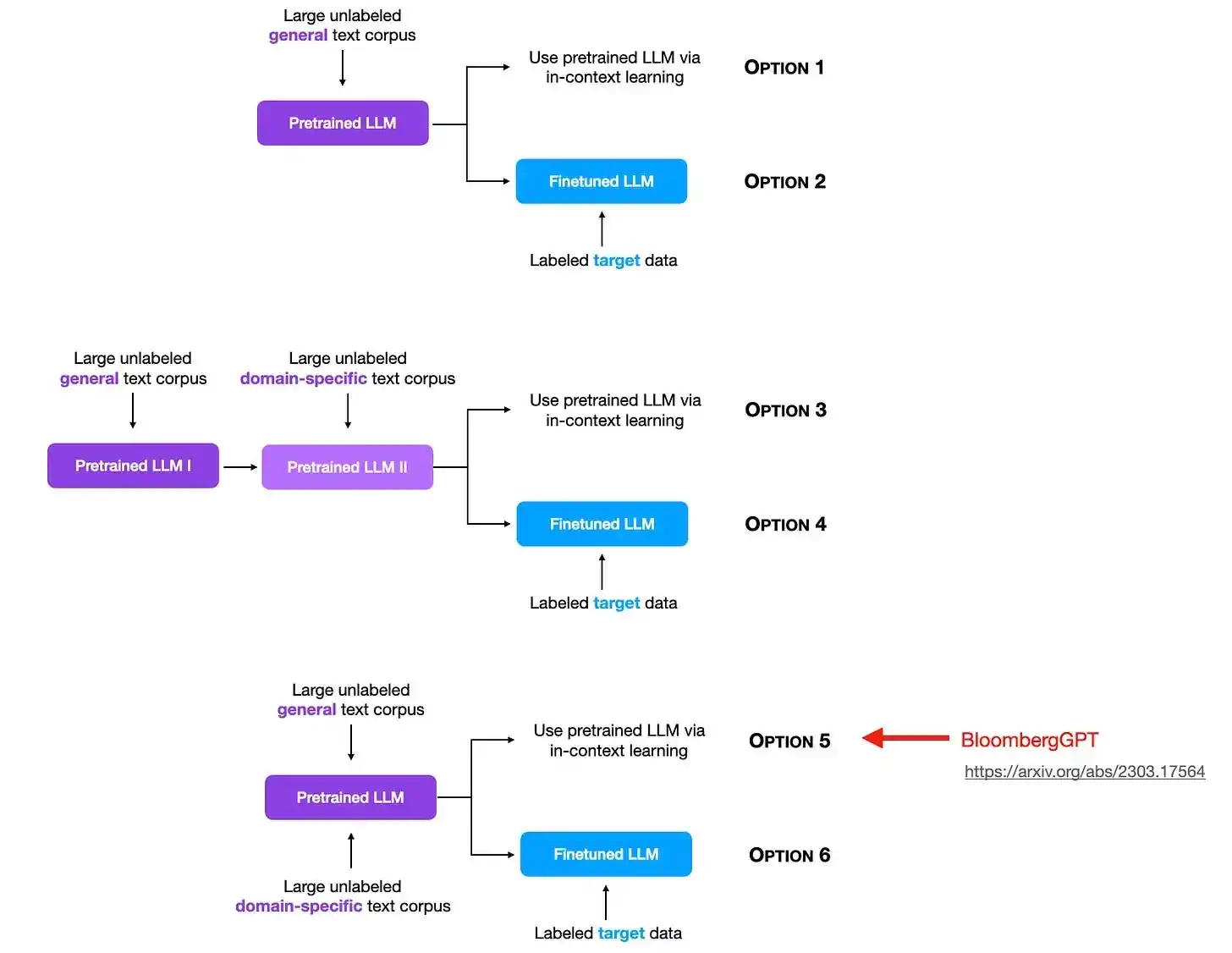
我之所以选中它,是因为它提供了一个颇具启发性的案例,展示了如何在特定领域数据集上预训练一个规模相对较大的大语言模型(LLM)。更值得一提的是,它的描述非常详尽,而如此细致的描述在当下越来越罕见。这一点在公司雇佣的论文作者中尤其明显——今年的一个趋势是,许多大公司为了保护商业秘密,在架构和数据集的细节上变得更加保密,尤其在这个竞争激烈的环境中(PS:我对此并不感到意外)。
此外,BloombergGPT 让我思考了我们可以如何利用特定领域的数据来预训练和微调模型的多种可能,正如下图所示(需要注意的是,这并不是 BloombergGPT 论文中探讨的内容,但未来的研究若能涉及这一领域,将会非常有趣)。
简单来说,BloombergGPT 是一款针对金融领域开发的、具有 500 亿参数的语言模型。它在 3630 亿个金融领域的 Token 和 3450 亿个来自公开数据集的 Token 上进行了训练。相比之下,GPT-3 的参数为 1750 亿,大约是它的 3.5 倍,但它训练的 Token 数量却少了 1.4 倍(共 4990 亿)。
那么,为什么作者不选择与 GPT-3 一样拥有更多参数的架构呢?答案其实很简单。他们基于 Chinchilla 缩放法则的研究,认为鉴于可用的金融数据规模,500 亿参数是一个合适的选择。
我们是否应该从头开始在一个合并的数据集上对大语言模型(LLM)进行(预)训练?根据这篇论文,该模型在其目标领域的表现非常出色。然而,我们尚未明确它是否优于以下两种方法:a) 对一个已经预训练过的模型在特定领域数据上进行进一步的预训练,或者 b) 对一个已经预训练过的模型在特定领域数据上进行微调。
虽然上述有一些批评意见,但总的来说,这是一篇引人入胜的论文。它不仅是特定领域大语言模型的一个有趣的案例研究和示例,而且还为未来在预训练和微调方面的研究留下了空间,旨在探讨如何将知识更有效地融入大语言模型中。
(附加信息:对于那些对微调进行比较感兴趣的人,正如 Rohan Paul 在这里分享 的,"小型" AdaptLLM-7B 模型在一个数据集上的表现超过了 BloombergGPT,并且在其他三个金融数据集上几乎达到了相同的水平。尽管 BloombergGPT 在整体上略显优势,但值得注意的是,训练 AdaptLLM-7B 的成本大约只有 $100,这与 BloombergGPT 数百万美元的投资形成了鲜明对比。)
5) 直接偏好优化:你的语言模型实际上也是一种奖励模型
在深入探讨 直接偏好优化:你的语言模型实际上也是一种奖励模型 这篇论文之前,我们先简要回顾一下它试图取代的技术——基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)。
RLHF 是支持 ChatGPT 和 Llama 2 聊天模型的核心技术。在我的 另一篇文章 中,我详细介绍了 RLHF 的多步骤过程:
-
监督式微调(Supervised finetuning):模型最初在一个包含指令和所需回应的数据集上进行训练。
-
奖励建模(Reward modeling):人类评估员对模型的输出进行反馈,用这些反馈来创建一个奖励模型,该模型学习预测哪些类型的输出更受青睐。
-
邻近策略优化(Proximal policy optimization, PPO):模型生成输出,奖励模型对每个输出进行打分。PPO 算法利用这些分数来调整模型策略,目的是产生更高质量的输出。这是一种用于细化模型策略的强化学习算法。

尽管 RLHF 在 ChatGPT 和 Llama 2 中表现出色,受到广泛欢迎,但它的实现过程复杂且容易出错。
直接偏好优化 (Direct Preference Optimization, DPO) 论文 提出了一种算法,这种算法优化了语言模型,使其更符合人类偏好,并且不需要显式的奖励建模或强化学习。DPO 采用了一个简单的分类目标来实现这一点。
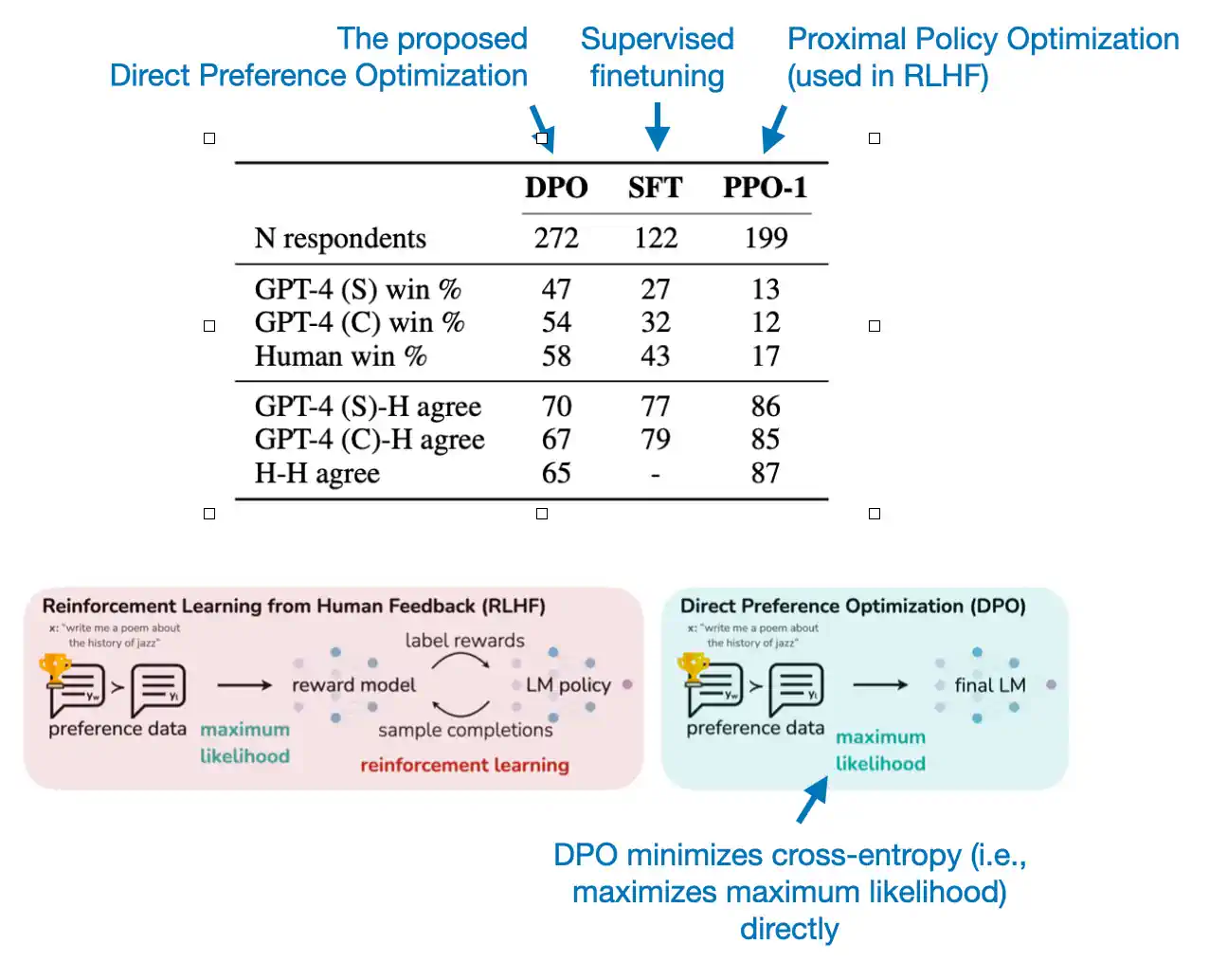
在 DPO 中,我们继续执行监督微调的初步步骤,但接下来的两步被替换为一个新的步骤,即在偏好数据上进一步微调模型。这意味着,与 RLHF 的要求不同,DPO 完全省略了创建奖励模型的过程,从而大幅简化了微调流程。
这种方法效果如何?直到最近,使用 DPO 训练的模型并不多(这也合理,毕竟 DPO 是个较新的方法)。但有一个近期的例子是 Zephyr: 直接提炼 LM 对齐 中介绍的 Zephyr 7B 模型。这个模型是在 Mistral-7B 基础大语言模型上,通过 DPO 微调而成的。关于 Mistral 的更多介绍将稍后提供。
正如下方的性能表所展示的,7B 参数的 Zephyr 模型在其发布时超过了同级别的所有模型。更值得注意的是,Zephyr-7B 在 MT-Bench 的对话基准测试中,甚至超越了参数数量是其十倍的 70B 参数 Llama 2 聊天模型。
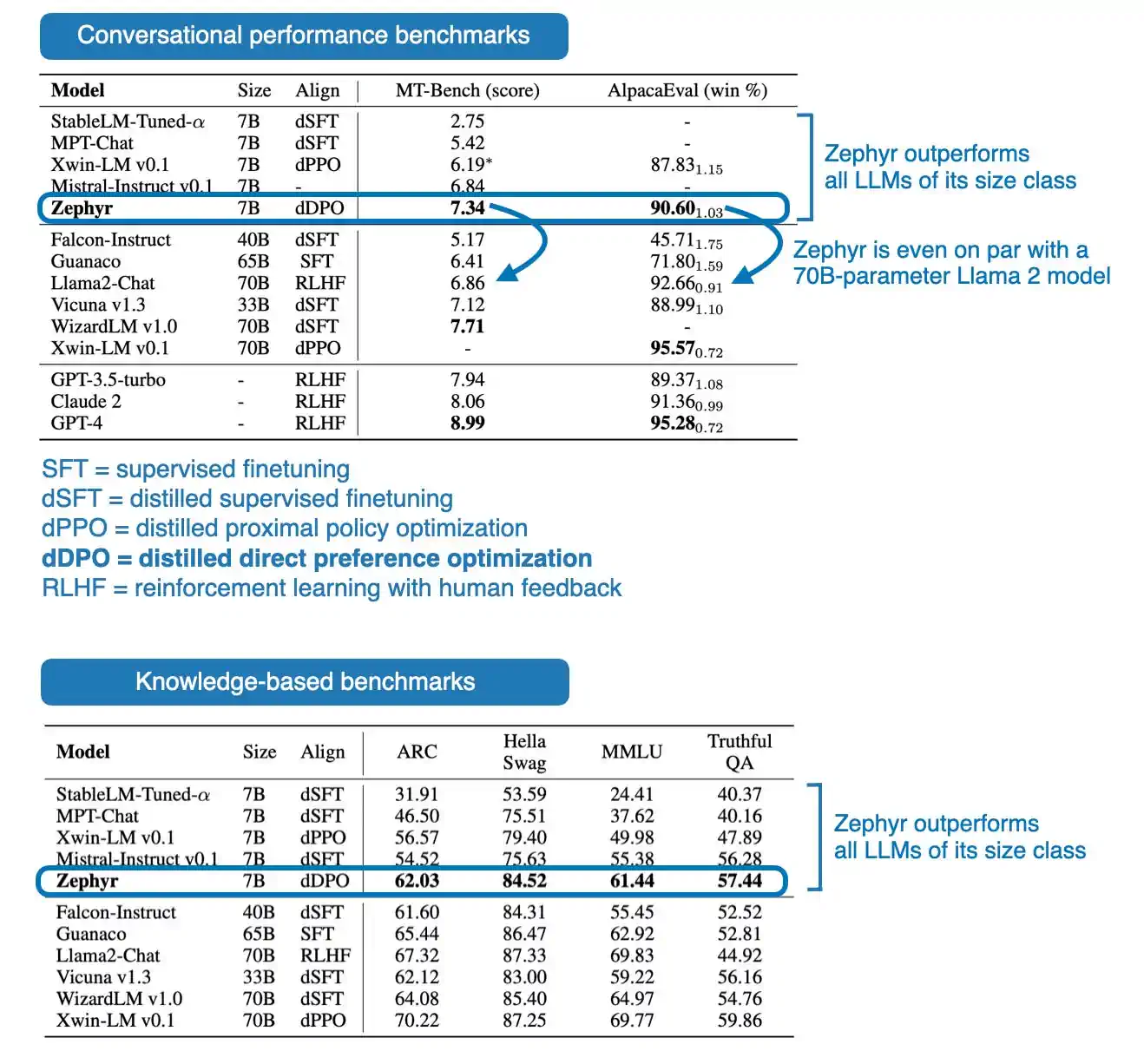
总结来说,DPO 论文吸引人之处在于其方法的简洁性。目前,采用 RLHF(强化学习与人类反馈)方法训练的聊天模型并不多见,Llama 2 是其中的杰出代表。这种情况很可能是因为 RLHF 方法本身的复杂性。因此,可以合理预见,在未来一年内,采用 DPO 方法的模型将会有所增加。
6) Mistral 7B
我得承认,Mistral 7B 论文 并不在我的偏好之列,主要是因为它的内容过于简洁。然而,它提出的模型影响深远。
我之所以选择将这篇论文列入这份清单,是因为 Mistral 7B 模型在发布时不仅受到广泛关注,而且还作为基础模型,促进了另外两个显著模型的发展:Zephyr 7B 和最新的 Mistral 混合专家 (MoE) 方法。这些模型是我预测的 2024 年初小型大语言模型 (LLM) 趋势的佳例。
在我们探讨 Zephyr 7B 和 Mistral MoE 模型之前,让我们先简单介绍一下 Mistral 7B 本身。
简单来说,Mistral 7B 论文呈现了一个体量适中但功能强大的语言模型。尽管它只有 70 亿个 Token,但在多个基准测试中表现优于规模更大的模型,比如 130 亿 Token 的 Llama 2 模型。(与体量是其两倍的 Qwen 14B 相比,Mistral 7B 还是今年 NeurIPS LLM 微调和效率挑战 中获胜方案使用的基础模型。)
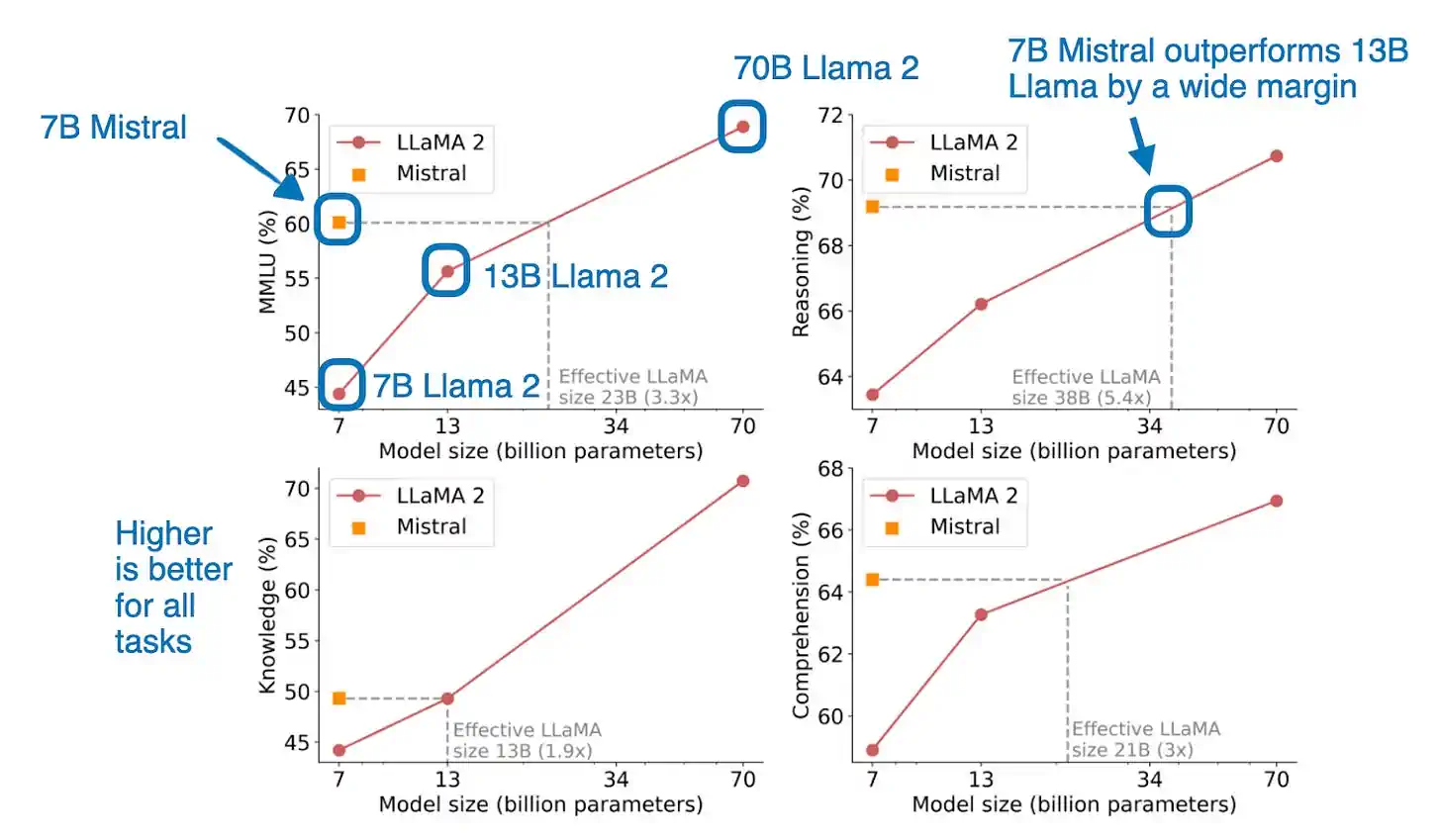
至于为何它表现如此出色,目前还不得而知,这可能与其训练数据有关。由于 Llama 2 和 Mistral 均未透露其训练数据,我们只能进行推测。
从架构角度来看,这个模型与 Llama 2 有着类似的 group-query 注意力机制。Mistral 架构的一个新特点是加入了滑动窗口注意力机制,这有助于节省内存并提高计算效率,加速训练过程。(滑动窗口注意力机制最初由 Child et al. 2019 和 Beltagy et al. 2020 提出。)
Mistral 使用的滑动窗口注意力机制,本质上是一个固定大小的注意力块。它仅允许当前 Token 关注一定数量的前置 Token,而非全部前置 Token,这一点在下方的图示中有所展示。
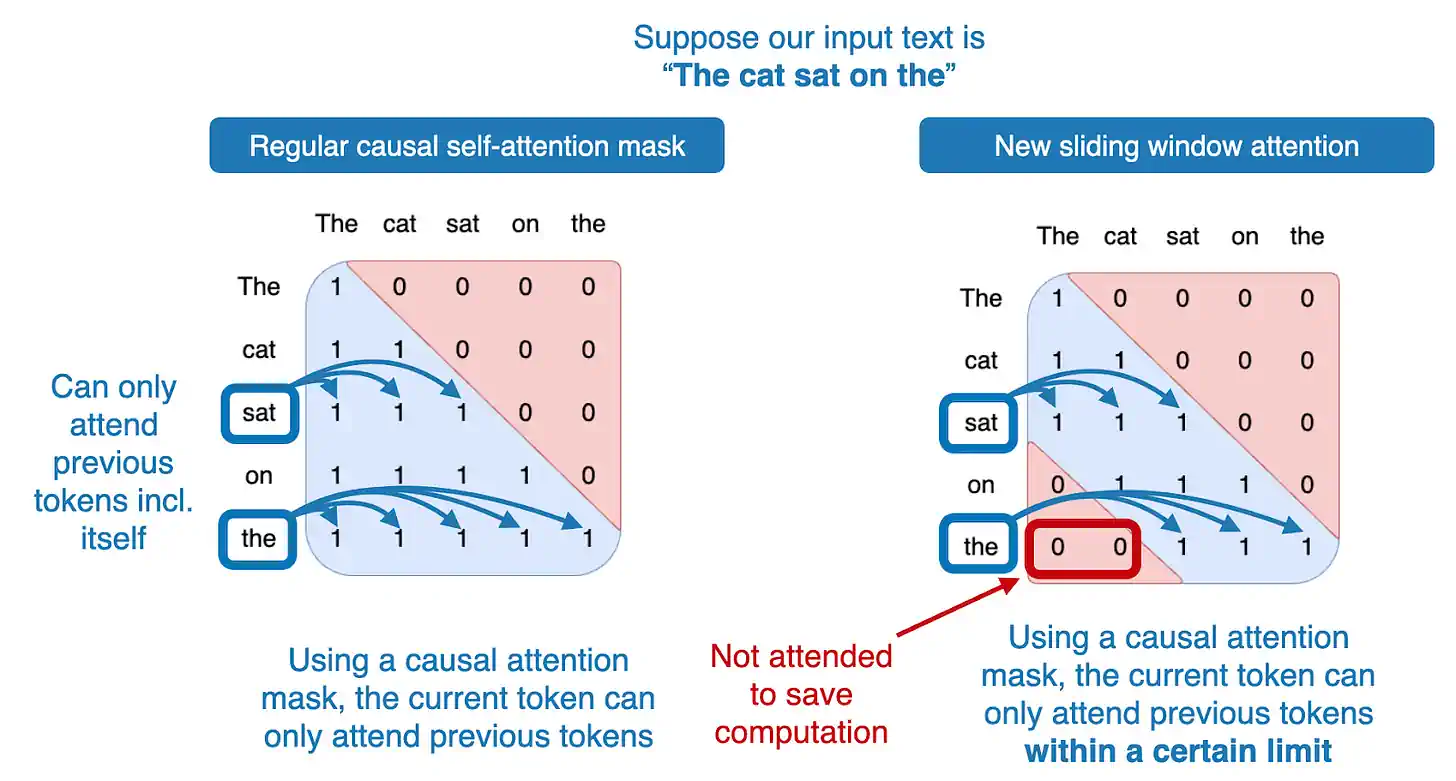
在 7B Mistral 模型的案例中,每个注意力块包含 4096 个 Token。研究人员在训练时,使用的是高达 100k Token 的上下文。比如,在传统的自注意力机制中,位于第 50,000 个 Token 的模型可以关注之前的所有 49,999 个 Token。而在滑动窗口自注意力机制中,Mistral 模型只能关注第 45,904 到 50,000 个 Token(50,000 - 4,096 = 45,904)。
尽管如此,滑动窗口注意力机制的主要目的是为了提升计算效率。Mistral 超越更大型的 Llama 2 模型,并不完全是因为引入了滑动窗口注意力,而是在采用该技术的同时还有其他优势。
Zephyr 和 Mixtral
Mistral 7B 成为一个具有影响力的模型,部分原因在于它作为 Zephyr 7B 的基础模型,这一点在之前的 DPO (动态程序优化) 部分已经提到。Zephyr 7B 是首个使用 DPO 训练并超越其他替代模型的受欢迎模型,它可能会让 DPO 在未来几个月成为聊天模型微调 (finetuning) 的首选方法。
另一个从 Mistral 7B 衍生出来值得关注的模型是最近发布的 Mistral Mixture of Experts (MoE) 模型,亦称为 Mixtral-8x7B。这个模型在多个公开基准测试中的表现不输于更大型的 Llama-2-70B。
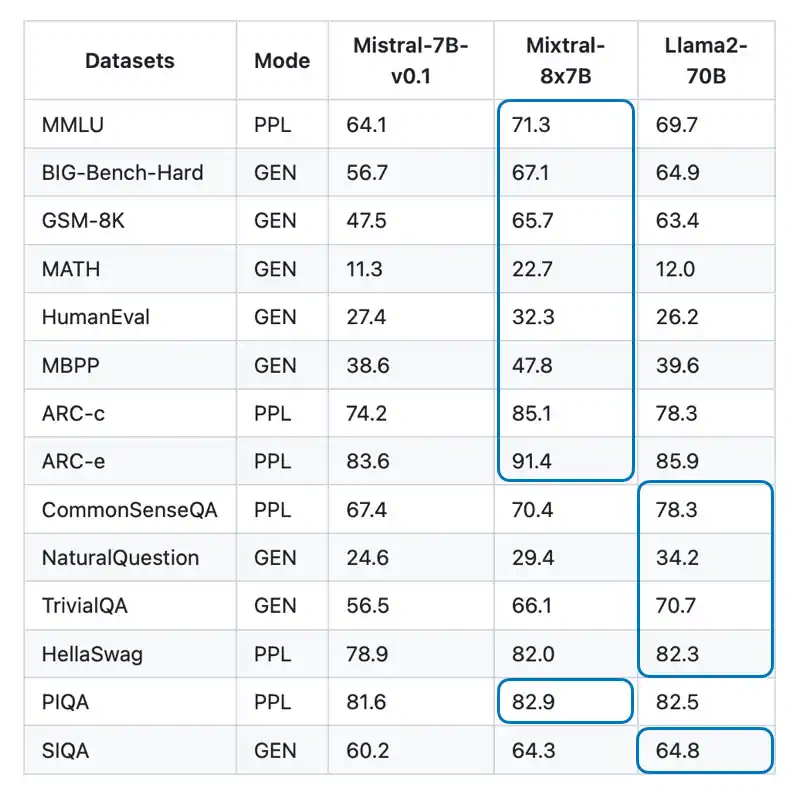
想了解更多基准测试,可参阅官方的 Mixtral 博客文章公告。该团队还发布了一个经过 DPO 微调的 Mixtral-8x7B-Instruct 模型,但截至目前,尚无基准测试将其与经过 RLHF (强化学习人类反馈) 微调的 Llama-2-70-Chat 模型进行比较。
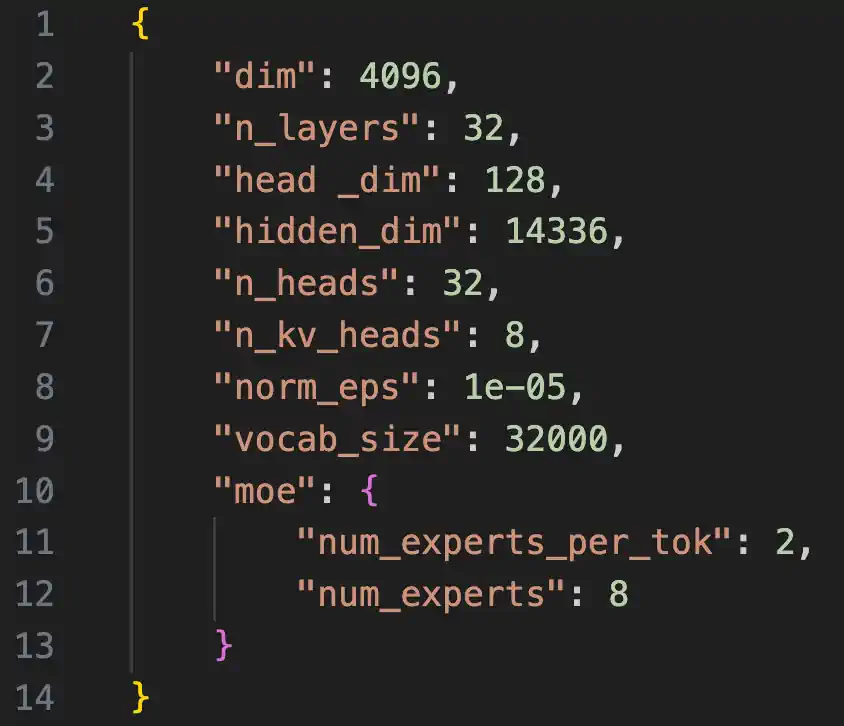
GPT-4 同样被传说是一个包含 16 个子模块的混合专家模型(MoE)。据称,这 16 个子模块中的每一个都具有 111 亿参数(作为对比,GPT-3 有 175 亿参数)。如果你大约两个月前阅读了我的《2023 年 AI 与开源》文章,你可能记得我提到,“很期待看到混合专家模型方法是否能在 2024 年把开源模型推向新高度。”现在看来,Mixtral 已经率先开启了这一趋势,我相信这只是个开始。
专家混合模型 101
如果你对 MoE(专家混合)模型不太了解,这里有一个简单的介绍。
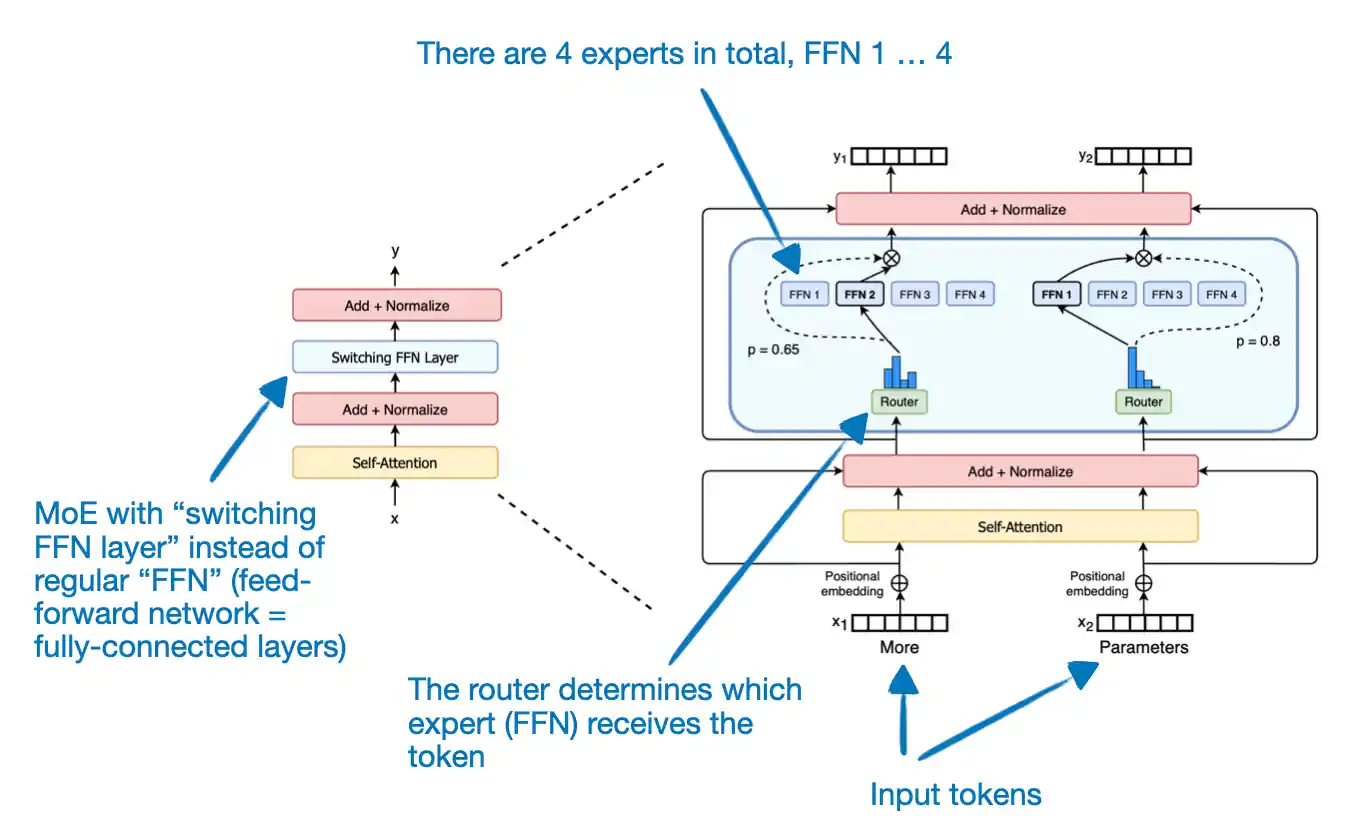
上图展示了 Switch Transformer 的结构。在这个模型中,每个 Token 分配给一个专家,总共有 4 个专家。而 Mixtral-8x-7B 则不同,它包含了 8 个专家,并且每个 Token 配置了 2 个专家。
为什么要用 MoE 模型呢?合起来,像 Mixtral 这样的 7B 模型中的 8 个专家大约有 56B 参数。但实际上这个数字还要少一些,因为 MoE 方法只用于 FFN(前馈网络,即全连接层),并没有用于自注意力(self-attention)权重矩阵。所以,整体参数量可能更接近 40-50B。
需要注意的是,路由器会调整 Token 的分配,使得每次前向传播只用到少于 14B 参数(2 倍不到 7B,而不是全部 56B 以下),这样训练(特别是推理过程)相比传统的非 MoE 方法会更快。
如果你对 MoE 模型感兴趣,这里有一个由 Sophia Yang 推荐的阅读列表:
此外,如果您有兴趣尝试 MoE 大语言模型 (LLMs),不妨访问 OpenMoE 仓库。该仓库在今年早些时候已经实施并分享了 MoE 大语言模型的相关成果。
其他小型但竞争力十足的大语言模型 (LLMs)
Mistral 7B、Zephyr 7B 和 Mixtral-8x7B 是 2023 年小型但功能强大的模型发展的典型例子,这些模型的算法权重公开可获取。另一个值得关注的例子是 Microsoft 的 phi 系列,它在我最喜欢的论文列表中名列前茅。
phi 系列的独特之处在于,它是在经过筛选的高质量网络数据(称为“教科书级质量数据”)上进行训练的。
phi 系列在 2023 年分阶段推出,包括 phi-1(拥有 13 亿参数)、phi-1.5(同样是 13 亿参数)和 phi-2(27 亿参数)。最新发布的 phi-2 在两周前面世,据说其性能不仅匹配,甚至超越了 Mistral 7B,尽管其参数数量仅为后者的一半。

比较 13 亿参数的 phi-1.5 模型和各种 70 亿参数模型(资料来源:phi-1.5 论文, https://arxiv.org/abs/2309.05463)
想了解更多关于 phi 系列模型的信息,可以参考以下资源:
-
Textbooks Are All You Need -- 关于 phi-1 的论文
7) Orca 2:如何训练小型语言模型进行推理
Orca 2: Teaching Small Language Models How to Reason 是一篇相对较新的论文,我们还需时间来观察它在未来几个月甚至几年内对大语言模型 (LLMs) 训练方法的影响。
之所以选择介绍这篇论文,是因为它融合了多个概念和创意。
其中一个创意是从功能强大的大型模型(例如 GPT-4)中提取数据,用以构建训练小型但同样强大的大语言模型的合成数据集 (synthetic dataset)。这一思路在去年发表的 Self-Instruct 论文中有所描述。今年早些时候,基于 ChatGPT 输出进行微调 (finetuned) 的 Llama 模型 Alpaca,使这种方法广为人知。
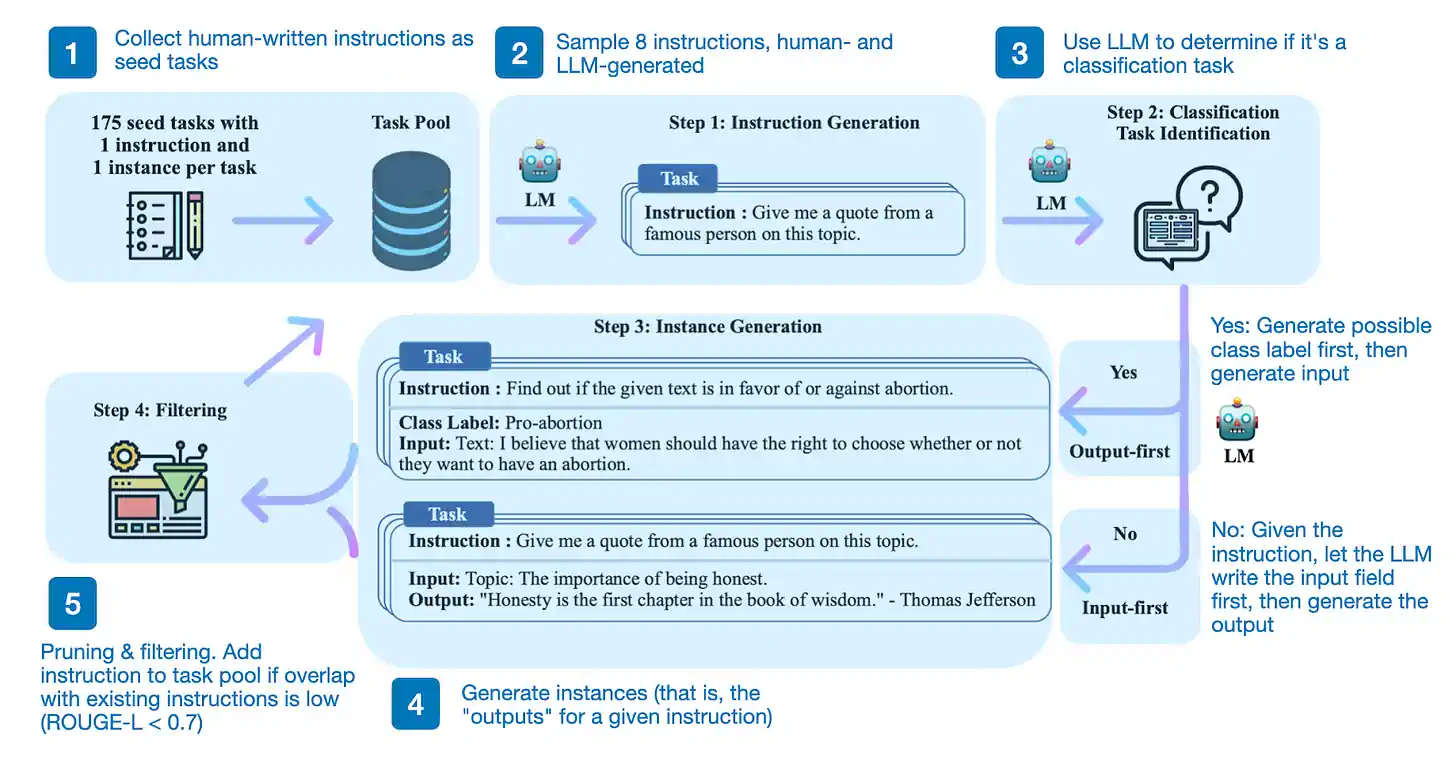
那么,这个过程是怎样的呢?简单来说,它包括四个步骤:
-
用一系列人类编写的指令(本例中为 175 条)及其样本指令,填充任务池;
-
利用一个预训练的大语言模型(如 GPT-3)来判断任务的类别;
-
针对新的指令,让预训练的大语言模型产生回应;
-
收集、筛选并过滤这些回应,然后将它们加入任务池。
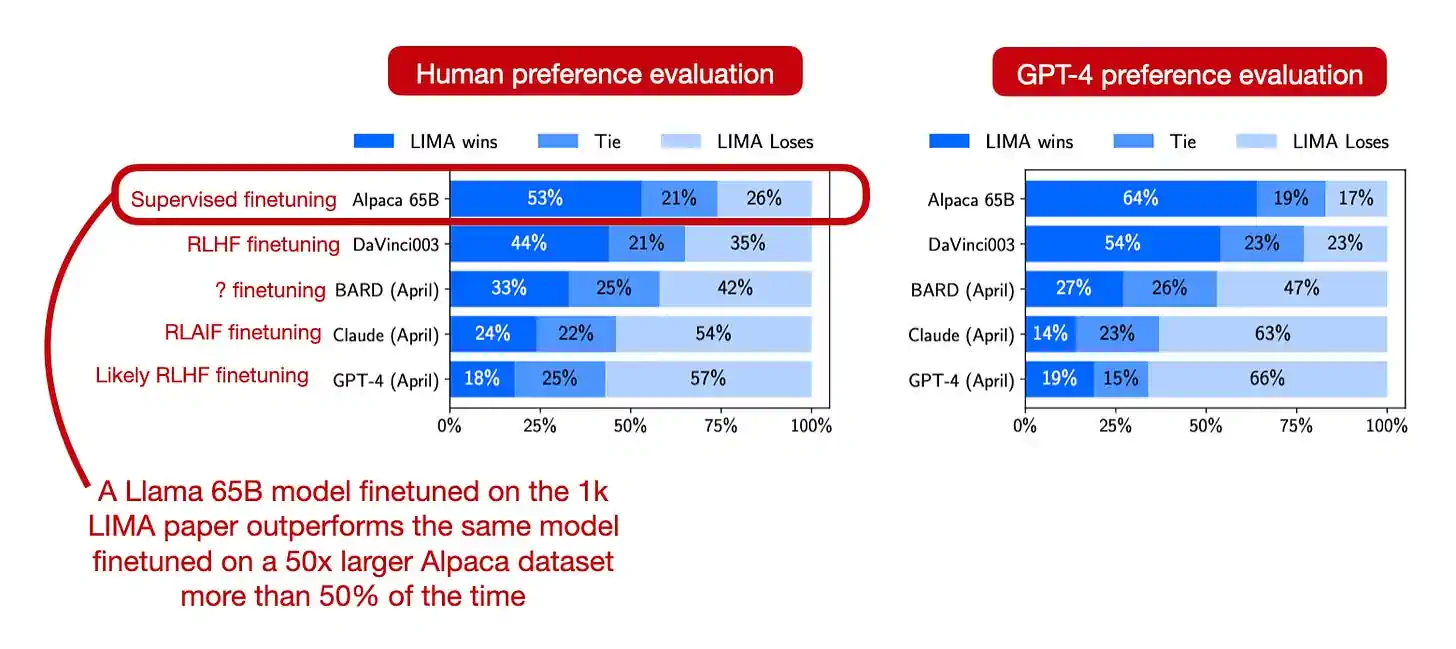
另一个值得一提的观点是:高质量数据对模型微调至关重要。例如,LIMA 论文 提出了一个仅包含 1000 个训练样本的高质量人工生成数据集,通过使用这个数据集进行微调,可以使模型的表现超越在 50000 个 ChatGPT 生成响应上进行微调的同一模型。
与过去大量依赖模仿学习来模拟大型模型的输出不同,Orca 2 的目标是教会容量较小(比如 7B 和 13B)的大语言模型多种推理技巧(例如逐步推理、先回忆再创造等),并辅助它们针对每项任务选出最有效的策略。这种新方法让 Orca 2 显著超越了体量相近的模型,甚至能够媲美体量是其 5 到 10 倍的大模型。
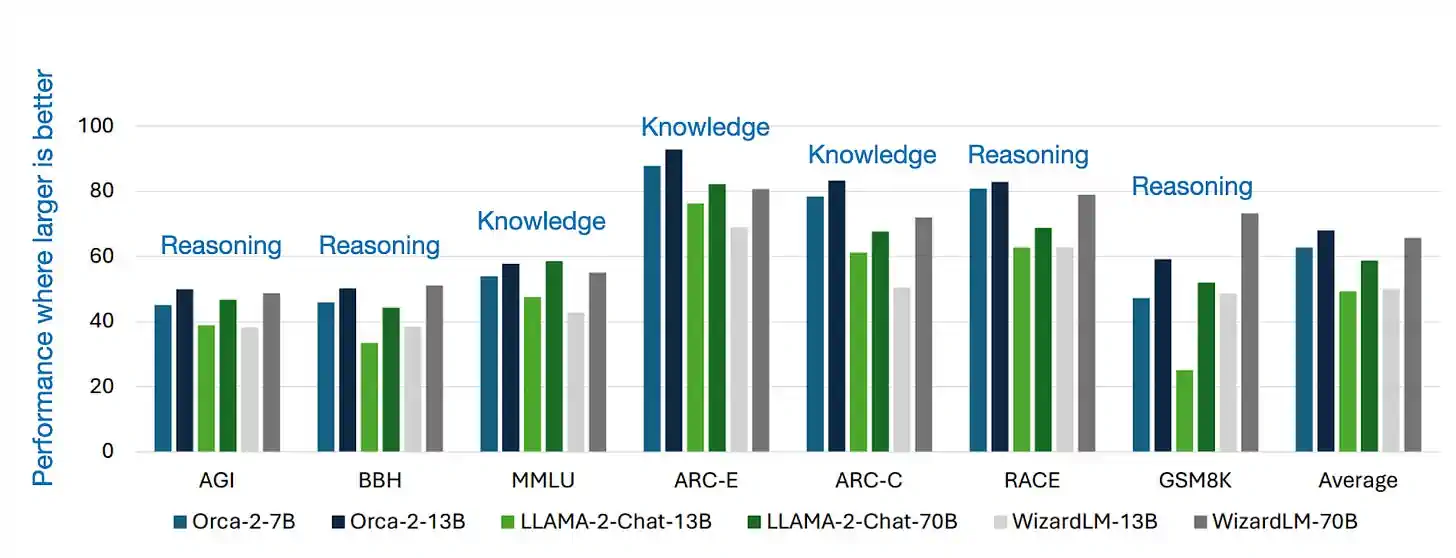
尽管目前还没有广泛的研究支持,但 Orca 2 的方法或许能解决《模仿专有大语言模型的虚假承诺》论文提出的使用合成数据问题。该研究调查了通过对较弱的语言模型进行优化调整,使其模仿如 ChatGPT 这样的强大专有模型的效果,案例包括 Alpaca 和 Self-Instruct。最初,这些模仿型模型展现出潜力,能够很好地遵循指令,并在众包评估中与 ChatGPT 相媲美。然而,随着更多深入的评估,这些模仿型模型虽然在人眼中表现不错,但实际上经常产生错误的答案。
8) ConvNets 在规模上匹配视觉 Transformers
近年来,由于表现出色,我几乎专门使用大型语言模型 (LLMs) 和视觉 Transformer(ViTs)。转换到计算机视觉领域的最后三篇论文中,我特别欣赏 Transformer 在计算机视觉方面的一个特点:预训练(pretrained)的 ViTs 比卷积神经网络(CNNs)更容易微调(fine-tune)。(我在今年早些时候的 CVPR 上做了一个简短的实操演讲,总结在这里:加速 PyTorch 模型训练)。
令我惊讶的是,我偶然发现了一篇论文 ConvNets 在规模上匹配视觉 Transformers,该论文表明,卷积神经网络(CNNs)实际上可以与 ViTs 竞争,条件是它们能够访问足够大的数据集。

在这项研究中,研究人员投入了高达 110,000 TPU 小时的计算资源,以公平比较 ViTs 和 CNNs 的性能。研究结果显示,当 CNNs 使用与 ViTs 相似的计算预算进行预训练时,它们的性能可以与 ViTs 相媲美。为此,他们在包含 40 亿标记图像的 JFT 数据集上进行了预训练,然后在 ImageNet 数据集上对模型进行了微调。
9) 分割任何事物
图像和视频中的对象识别和分割,以及分类和生成模型,构成了计算机视觉领域的核心研究方向。
这里简要阐述这两个任务的不同之处:对象检测是关于预测边界框和相应的标签;而分割则是将每个像素分类,以明确区分前景对象和背景。

Meta 的 分割任何事物 论文标志着开源及图像分割研究的重要进展。这篇论文提出了图像分割的新任务、新模型和数据集。论文中介绍的图像数据集是目前最大的分割数据集,包括超过 1 亿个遮罩,分布在 1100 万张图像中。
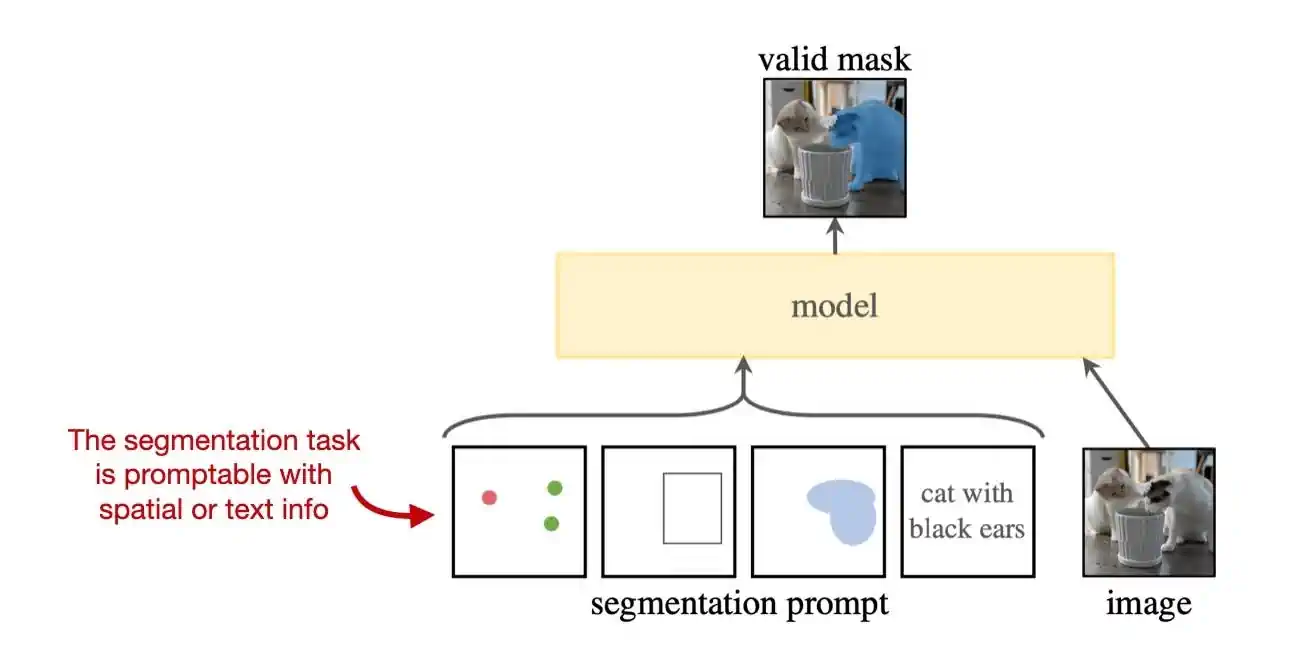
特别值得称赞的是,研究人员在这项研究中使用了经过授权和尊重隐私的图像,使得这个模型可以在避免重大版权问题的情况下进行开源。
Segment Anything Model (SAM) 主要由三个部分组成,如上图所示。
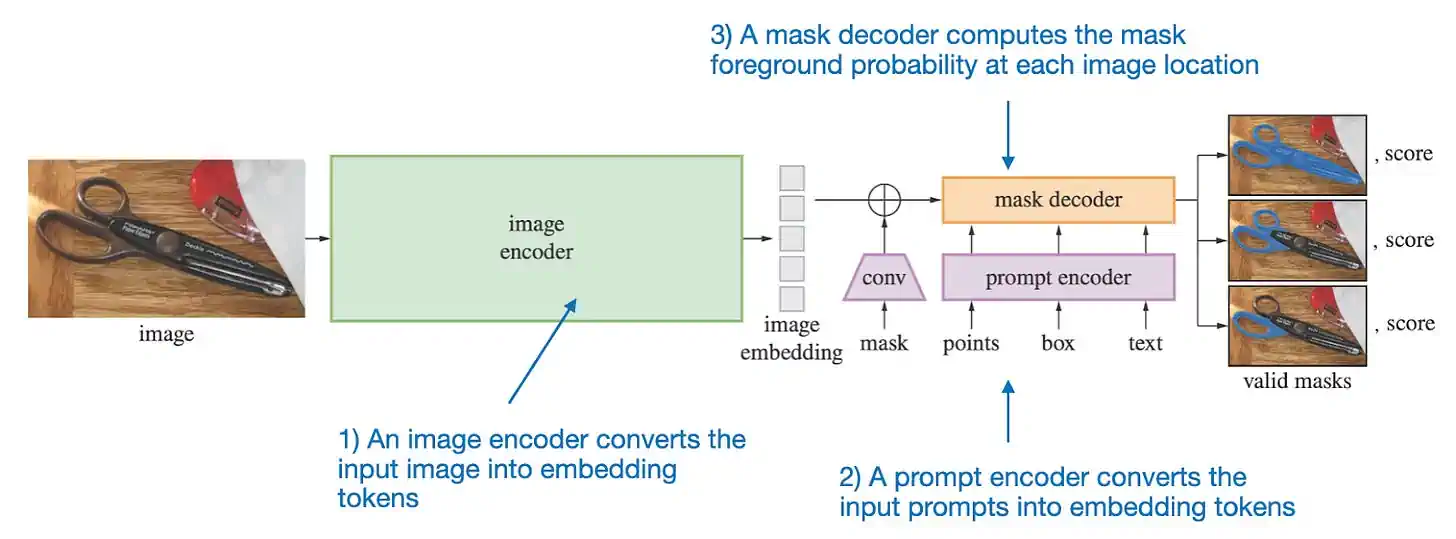
详细来说,这三个部分包括:
-
一个图像编码器,使用基于预训练的视觉 Transformer (即视觉处理的深度学习模型) 的掩码自动编码器来处理高分辨率图像。这个编码器对每张图像运行一次,并可在启动模型之前应用。
-
一个提示编码器,它处理两种类型的提示:稀疏(如点、框、文本)和密集(如掩码)。点和框通过位置编码和为每种提示类型专门学习的嵌入表示,而自由形式的文本使用现成的 CLIP 文本编码器。对于密集的提示,即掩码,采用卷积技术嵌入,并与图像嵌入进行元素级相加。
-
掩码解码器负责将图像嵌入、提示嵌入和一个输出标记转换成一个掩码。这是一种基于解码器的 Transformer 架构,用于计算图像每个位置的掩码前景概率。
图像分割在自动驾驶汽车、医学成像等多种应用中扮演着重要角色。这篇论文在短短六个月内已经被引用超过 1500 次,并且已经有许多基于此论文的项目被开发出来。
10) 潜在扩散模型在高清视频合成中的应用
Emu Video: 通过显式图像条件分解文本到视频的生成过程 是 Meta 研究部门的一个引人注目的计算机视觉项目。
Emu 是一款能够从文本提示生成完整视频的模型。
虽然它并非首个实现引人入胜的文本到视频生成的模型,但与先前的作品相比,Emu 表现出色。
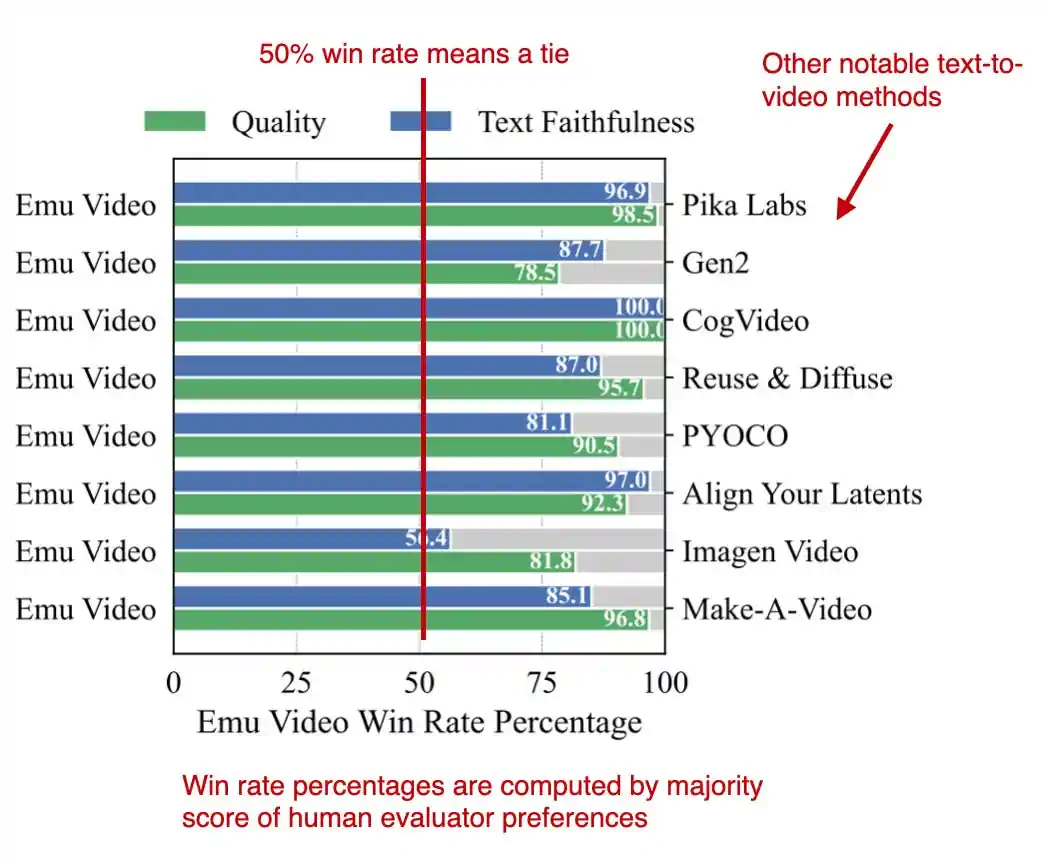
作者指出,Emu 的架构设计相比以往方法更为简洁。其核心思想在于将视频生成分为两个步骤:首先根据文本生成图像(利用扩散模型),然后在文本和生成的图像的基础上制作视频(运用另一种扩散模型)。
2022 年对于 DALL-E 2、Stable Diffusion 和 Midjourney 这样的文本到图像模型而言意义重大。尽管在 2023 年大语言模型成为主流焦点,但文本到图像模型依然广受欢迎。我认为,在未来一年内,文本到视频模型将在网络社区中变得越发流行。
作为非图像或视频设计师,我目前没有使用这些工具的实际需求;但作为计算机视觉进展的晴雨表,文本到图像和文本到视频模型的发展仍然值得持续关注。
打造一款大型语言模型(零基础入门)
自去年夏天起,我投身于编程和新书的撰写。现在,我非常激动地告诉大家:我的书的首几章已经可以通过 Manning 的提前阅读计划阅读了。

在我的新书 打造一款大型语言模型(零基础入门) 中,我会带领读者使用 PyTorch 逐步搭建一个大型语言模型,帮助你深入了解它的核心原理。
本书详尽介绍了从构建数据输入管道、亲手实现注意力机制到大型语言模型的预训练与微调等各个环节。每一环节都配有清晰的说明、图解和实例。
祝您新年伊始一切顺利!