将机器学习转化为创造学习的机器 [译]
作者:
Kevin Wong
对每位软件工程师的挑战
在技术日新月异的世界里,软件工程师持续面对吸收海量新技术信息的挑战。本文介绍了一种利用机器学习技术辅助软件工程师更高效地整理和学习这些资料的创新方法。
本文旨在指导读者如何使用 OpenAI 来概括大量文档,并自动制作出高效的学习教程。特别例证的是,如何为 LeetCode 编制深入的教程。
面向人类的 Leetcode 学习工具
在一个长周末里,我开发了一个程序,它能够自动从网络收集 LeetCode 的题目,并应用机器学习技术为每个题目生成一个“嵌入向量”(embedding vector)。这些向量用于根据题目之间的相似性进行分类。
然后,根据这些分类结果,我们可以逐日制作密集训练材料,这对技术面试的准备特别有帮助。这个方法让软件工程师在限定时间内,能够高效且迅速地掌握尽可能多的 LeetCode 题目。
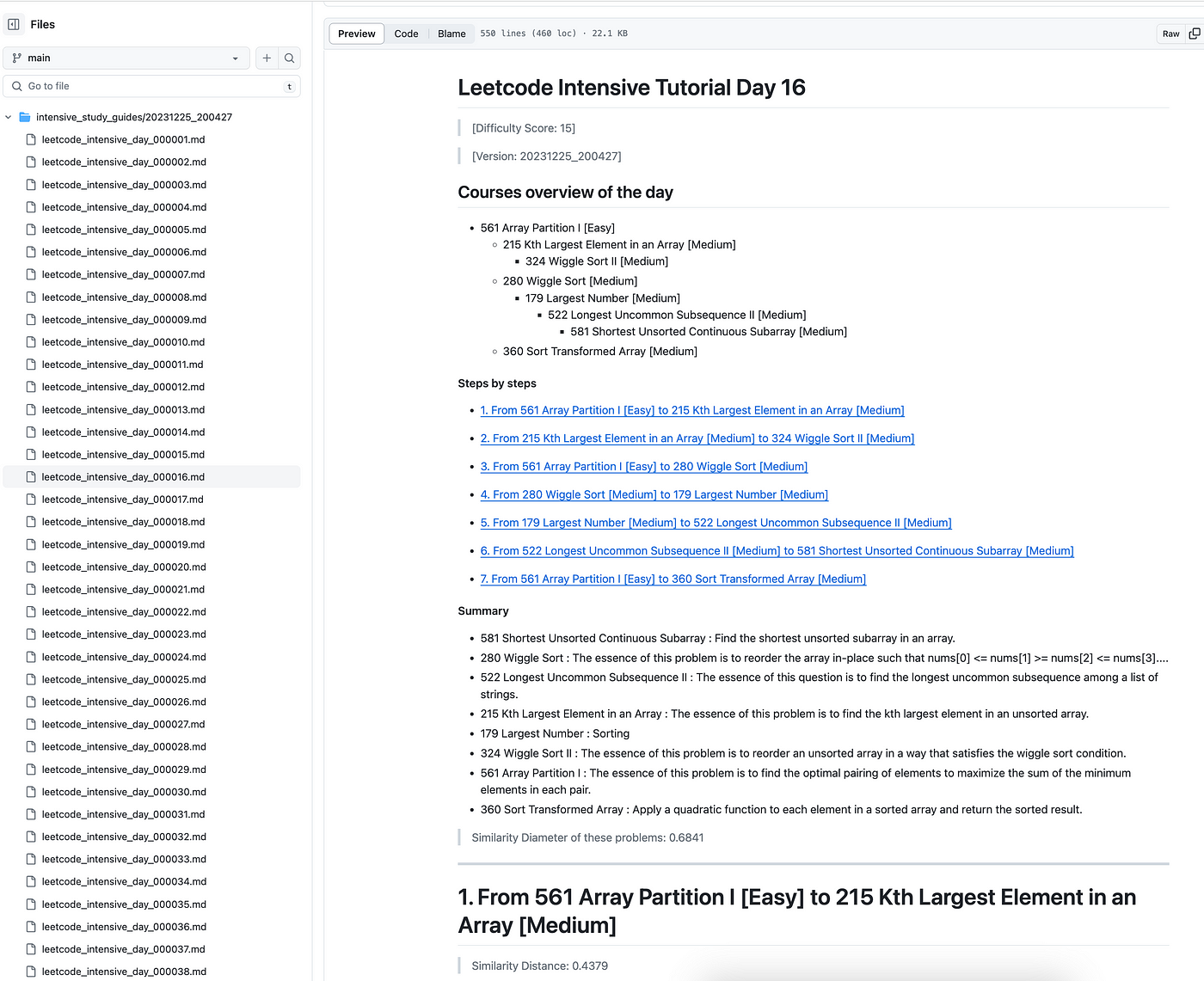
示例:生成的学习材料
这里是我们生成的 Leetcode 密集教程的截图,我已经上传到了这个 GitHub 链接:

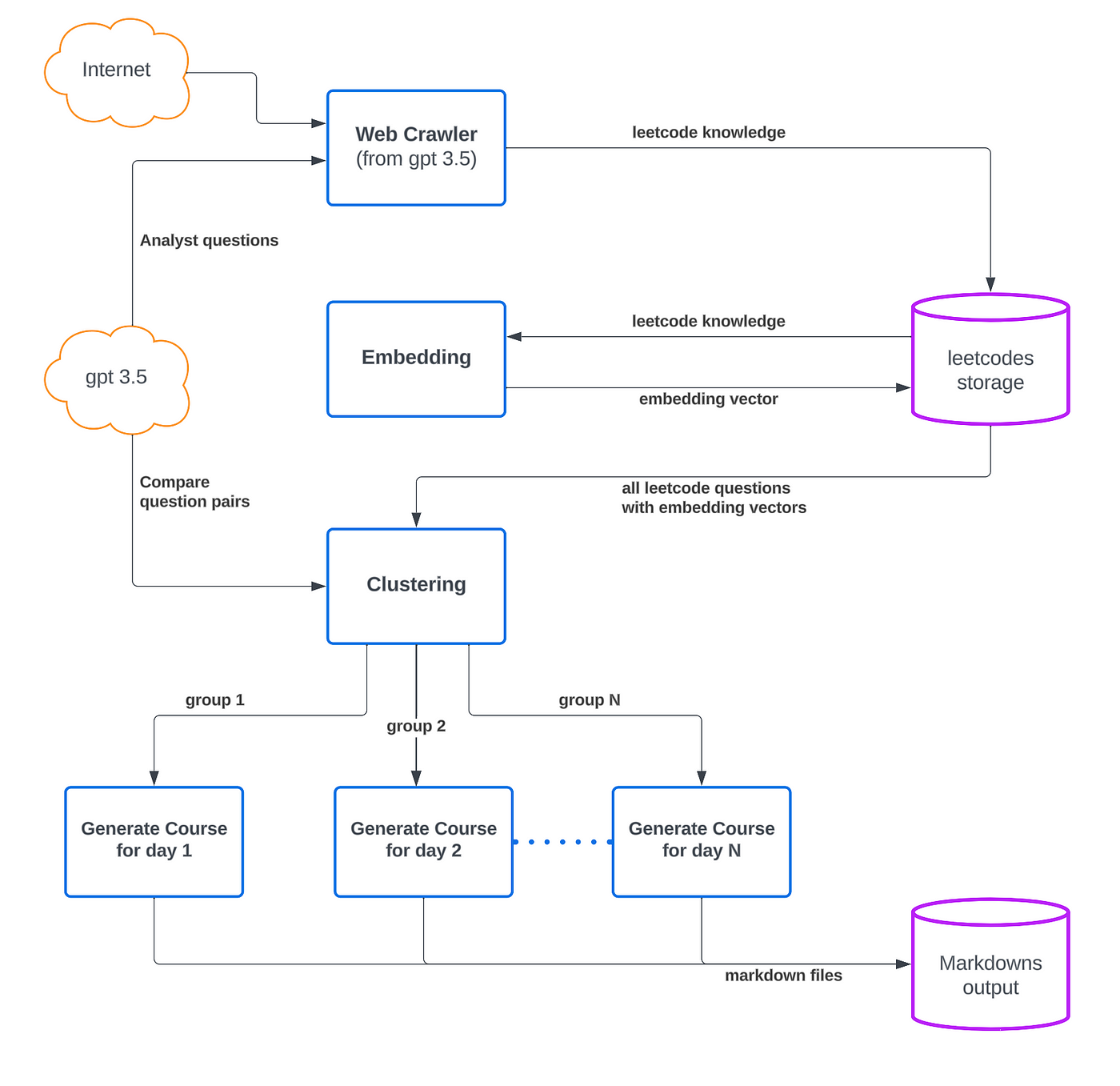
我们学习工具的技术架构
以下是我们学习机器的技术栈:
1. Llama Index
用途:
- 结合 OpenAI,增强对 LeetCode 题库的深入理解。
- 使用成本效益高的嵌入模型处理大量数据。
- 根据题目的代码解释摘要,为每个 LeetCode 题目生成独特的嵌入向量。
from llama_index.embeddings import HuggingFaceEmbeddingdef refresh_embedding_json(embed_model: Any, path: str = DEFAULT_PATH_TO_LEETCODE):for filename in os.listdir(path):with open(os.path.join(path, filename), "r") as json_file:data = json.load(json_file)for q in data["questions"]:pickup = {}pickup["code_explanation_summary_in_less_than_5_lines"] = q["code_explanation_summary_in_less_than_5_lines"]json_embedding = embed_model.get_text_embedding(str(pickup))q["embedding"] = json_embeddingwith open(os.path.join(path, filename), "w") as outfile:json.dump(data, outfile, indent=4)print(f"> Done embedding {filename}")embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")refresh_embedding_json(embed_model=embed_model)
2. SciKit-Learn
用途:
- 对 LeetCode 题目进行分类,提供个性化的学习体验。
- 使用机器学习算法(如聚类算法 AgglomerativeClustering)根据相似性将知识归类。
- 把类似的问题聚集在一起,以缩小不同问题间的学习差异。
- 用户可以根据特定的学习领域或难度,选择输入样本,并设定学习时间,从而定制自己的学习计划。
from sklearn.cluster import AgglomerativeClustering# Methods for Grouping Leetcode Questionsdef get_agglomerative_clustering(distance_threshold: float = 0.5):return AgglomerativeClustering(n_clusters=None,metric="euclidean",memory=None,connectivity=None,compute_full_tree="auto",linkage="ward",distance_threshold=distance_threshold,compute_distances=True,)def group_leetcodes_by_embeddings(leetcodes_array: list,leetcodes_embeddings_nparray: np.ndarray = None,distance_threshold: float = 0.8,) -> List[List[str]]:if not leetcodes_embeddings_nparray:leetcodes_embeddings_nparray = get_leetcodes_embeddings_nparray(leetcodes_array)cluster = get_agglomerative_clustering(distance_threshold=distance_threshold)cluster.fit(leetcodes_embeddings_nparray)print(f"> cluster Counter:{Counter(cluster.labels_)}")results = {}for i, label in enumerate(cluster.labels_):if label not in results:results[label] = []if leetcodes_array[i].get("leetcode_number"):results[label].append(leetcodes_array[i]["leetcode_number"])return list(results.values())
3. NetworkX
用途:
- 简化学习者的学习路径。
- 力图找出与当前问题最为相似的下一题,减少整体的学习难度。
- 构建最小成本生成树,揭示不同问题间的关联。
- 运用深度优先搜索(DFS)算法,帮助用户按逻辑顺序深入相关主题,制定高效的学习顺序。
import networkx as nx# Find a Minimum cost Spinning Tree, cost = similarityG = nx.cycle_graph(len(leetcodes_array))for i in range(len(leetcodes_array)):for j in range(i + 1, len(leetcodes_array)):G.add_edge(i,j,weight=calculate_similarity(leetcodes_array[i]["embedding"], leetcodes_array[j]["embedding"]),)MST = nx.minimum_spanning_tree(G)# Get the easiest question as the root# Find the study path by tracing the DFS from root.easiest_root = get_the_easiest_question_id(leetcodes_array)T = nx.dfs_tree(MST, source=easiest_root)dfs_list = list(nx.dfs_preorder_nodes(T, source=easiest_root))study_path = []for i in dfs_list:parent = list(T.pred[i].keys())if parent:parent = parent[0]similarity = calculate_similarity(leetcodes_array[i]["embedding"], leetcodes_array[parent]["embedding"])study_path += [{"q1": leetcodes_array[parent]["leetcode_number"],"q2": leetcodes_array[i]["leetcode_number"],"pair_similarity": similarity,}]
4. Pydantic
用途:
- 将 Open AI API 聊天响应从无结构转换为结构化的 JSON 格式。
- 结合 Pydantic 模型和 OpenAI API,便捷地将深入的响应直接整合到特定字段中。
- 确保数据准确无误,并简化问题信息的处理和获取过程。
from llama_index.program import OpenAIPydanticProgramfrom pydantic import BaseModelfrom llama_index.llms.openai import OpenAIclass LeetCodeQuestionItem(BaseModel):"""Data model for a leetcode question."""leetcode_number: Optional[str]title: Optional[str]question_type_group: Optional[Union[str, List[str]]]difficultity: Optional[str]question_summary: Optional[Union[str, List[str]]]sample_input: Optional[Union[str, List[str]]]sample_output: Optional[Union[str, List[str]]]optimal_python_solution: Optional[Union[str, List[str]]]keywords: Optional[Union[str, List[str]]]questions_to_ask_to_clarify_requirements: Optional[Union[str, List[str]]]interviewer_questions: Optional[Union[str, List[str]]]key_points: Optional[Union[str, List[str]]]time_complexity: Optional[str]space_complexity: Optional[str]trickys: Optional[Union[str, List[str]]]avoids: Optional[Union[str, List[str]]]studies: Optional[Union[str, List[str]]]concerns: Optional[Union[str, List[str]]]explainations: Optional[Union[str, List[str]]]code_explaination_summary_in_less_than_5_lines: Optional[Union[str, List[str]]]programming_tips: Optional[Union[str, List[str]]]essence: Optional[str]class LeetCodeQuestions(BaseModel):"""Data model for a leetcode questions."""questions: List[LeetCodeQuestionItem]def get_leetcode_questions_json(start_leetcode, end_leetcode) -> list:"""Get leetcode questions json."""output = []api_key = os.environ["OPENAI_API_KEY"]llm = OpenAI(api_key=api_key, model="gpt-3.5-turbo-0613", temperature=0.0)prompt_template_str = """Give me Leetcode questions with leetcode number from {start} to {end},All text MUST be escaped, especially in {escaped_fields}:Code example MUST be python, easy to understand, optimized, and runable.Output MUST be less than 3500 tokens."""for i in range(start_leetcode, end_leetcode + 1, BATCH_SIZE):start = iend = i + BATCH_SIZE - 1print(f"> Processing leetcode {start} to {end}")for retry in range(2):try:program = OpenAIPydanticProgram.from_defaults(output_cls=LeetCodeQuestions,llm=llm,prompt_template_str=prompt_template_str,verbose=False if retry == 0 else True,)sub_output = run_process(start, end, program)if sub_output:output.extend(sub_output)breakexcept Exception as e:logging.error(f"Exception:{e}")continuereturn output
成本控制策略
为了提高成本效益,我们采取了多项策略,使得这个项目对预算有限的个人和小企业更加可行:
- 选择 OpenAI 版本:我们选择了成本更低的 GPT-3.5,而不是更新但更贵的 4.0 版本。这一决定显著降低了运营成本,同时并没有影响项目的有效性。例如,在这篇文章末尾附上的学习指南中,我们仅使用 GPT-3.5,成本不足 3 美元。在实际运用中,成本会更低,因为重复运行主要是为了调试。
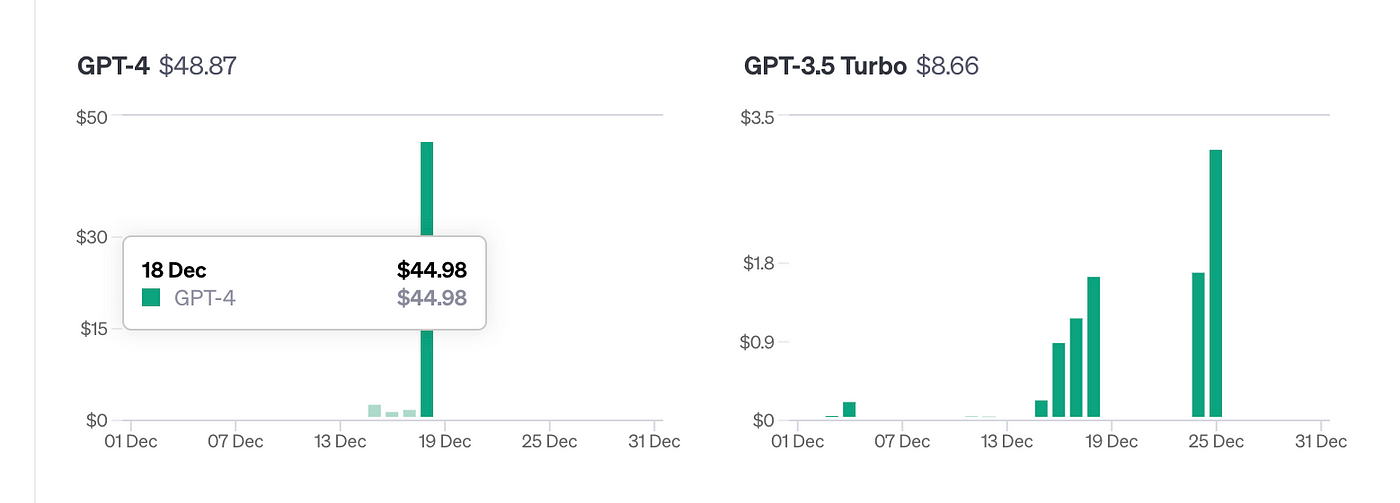
- 本地缓存策略:通过实施本地缓存,我们减少了对网络资源的依赖,大大降低了重复获取互联网数据的需要,从而节约了数据访问费用。
- 本地嵌入模式:为了进一步降低成本,我们选择在本地生成嵌入向量(embedding vectors),而非使用 OpenAI API。我们可以从 Hugging Face 下载 "BAAI/bge-small-en-v1.5" 嵌入模型,并在个人电脑上直接部署。这种方式避免了使用 API 所产生的费用。
- 高效数据处理:我们精心管理每次下载或 API 访问的数据。比如,下载的 LeetCode 题库会被储存在本地。当我们从 GPT 查询更多题目时,使用本地模型重新计算嵌入向量不会产生额外成本。这样不仅避免了重复整个过程的费用,还大幅减少了总成本。
市场分析与可达性
此外,我们还分析了当前市场对此类技术的需求和竞争环境。通常,软件工程师入门课程的费用高达数千美元一个人。与此相反,我们的技术可以帮助软件工程师或学生几乎免费地制作个性化的 LeetCode 强化学习指南。
结论与未来展望
本程序实际演示了机器学习技术在日常任务中的应用,为软件工程师提供了一种更高效的学习方式。
这种方法的应用远不止于编码面试的准备。它帮助软件工程师紧跟最新技术动态,深入理解系统设计的精髓,并在研究及其他相关领域进行探索。
未来计划包括进一步优化此工具,并探索其在其他领域的应用潜力。
感谢您的阅读!
如果这篇指南帮助您更好地理解了 Python 和机器学习:
- 请通过鼓掌 👏 或多次鼓掌来表示支持!
- 您的鼓掌能够支持我为我们充满活力的 Python 或 ML 社区创造更多有价值的内容。
- 欢迎将这篇指南分享给其他 Python 或 ML 爱好者。
- 您的反馈对我非常重要,它是我未来文章创作的灵感和指南。