我们如何构建 Townie——一个能够生成全栈应用的应用程序 [译]
Townie 在过去的几周内已经彻底重新设计。它在编写全栈应用方面非常厉害。这篇文章讲述了我几周前是如何为这个新版的 Townie 制作原型的。
The redesigned Townie, currently in beta at val.town/townie.
代码生成
最近在代码生成(“codegen”)领域取得的进展,尤其是 Claude 3.5 Sonnet 的创新,使得通过与大语言模型(LLM)对话来构建软件成为了一种全新的方式。
一些最成功的产品包括:
- Claude Artifacts:通过对话构建互动网站和其他代码,网站可以直接查看。
- Cursor:一个为 AI 设计的 VSCode 分支,可以在整个代码库中生成变更。
- Vercel v0:通过提示词构建网站用户界面。
- Websim:类似于 Claude Artifacts,但围绕“虚拟网站”设计,因此访问 catgifs.com 会即时生成一个有猫咪 GIF 的网站。
- VSCode Copilot:在较大的项目中智能自动完成代码,支持多种编程语言。
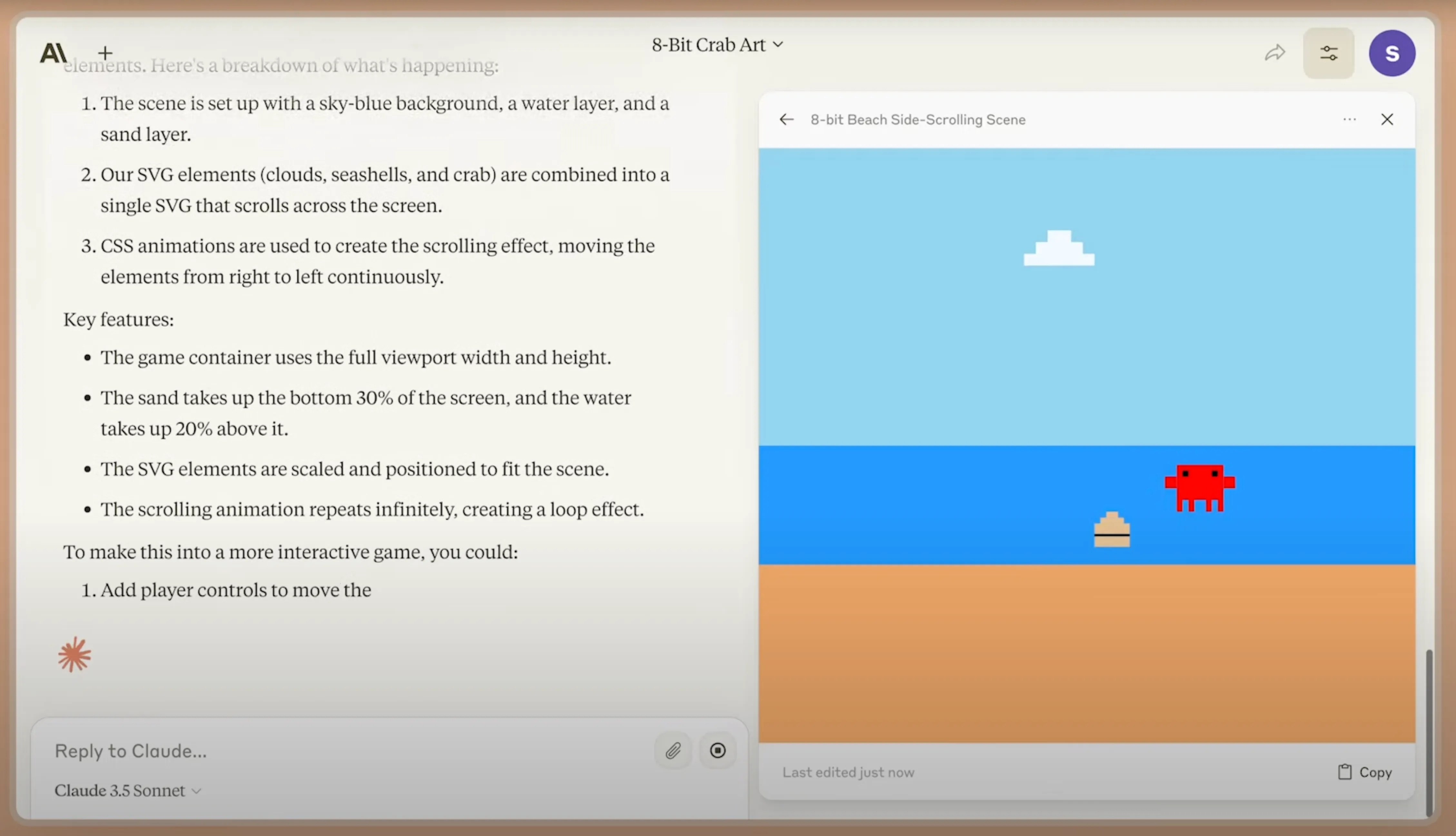
Claude Artifacts: making a game.
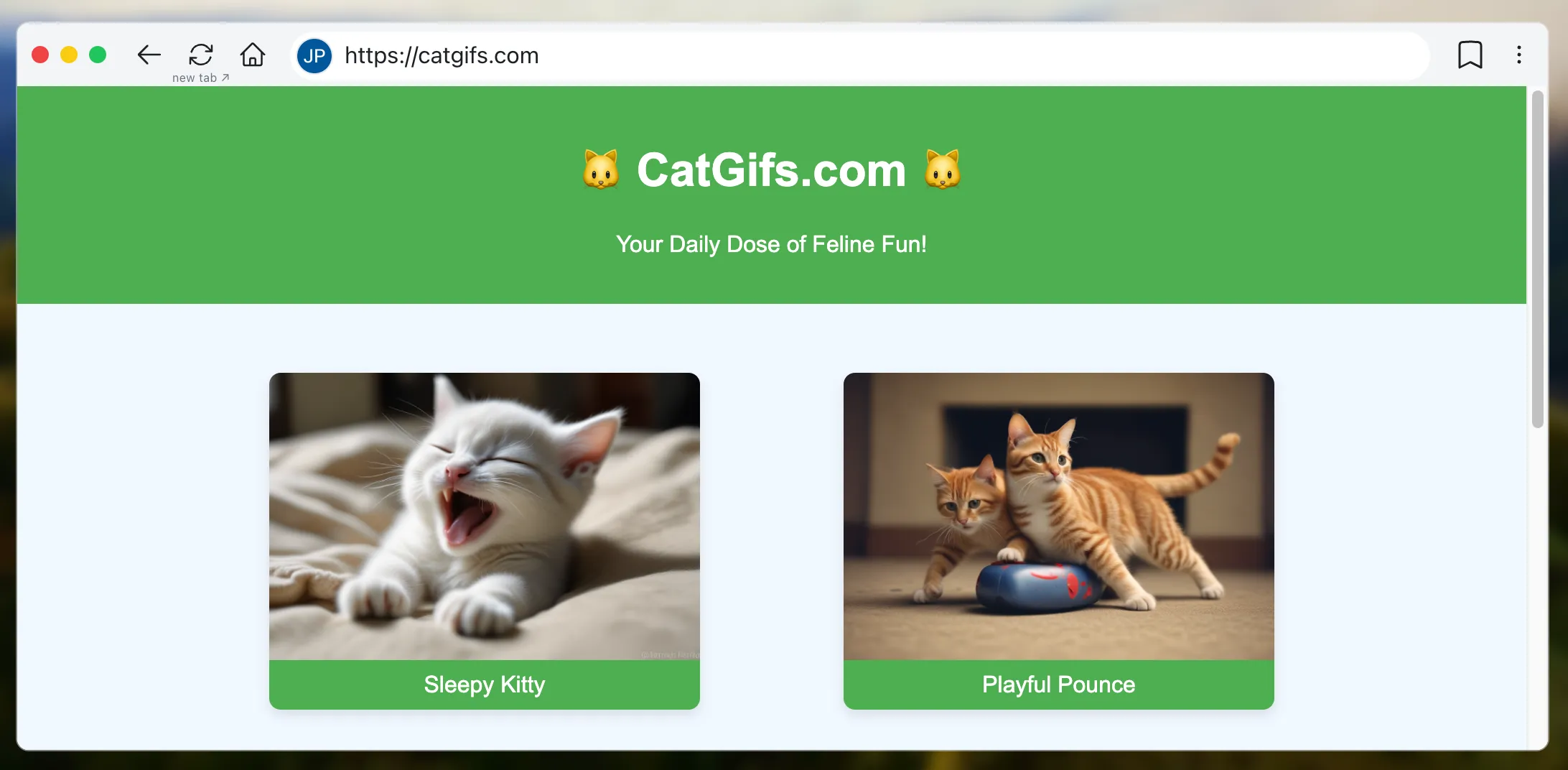
Websim: catgifs.com.
Vercel v0、Claude Artifacts 和 Websim 等产品的优势在于,即使你不了解编程,也能立刻获得一个可运行的程序!例如,在 Websim 中,你甚至不需要查看代码,只需看到生成的网站即可。
目前,这些 LLM 生成的程序主要用于前端开发,或者被复制粘贴到其他地方。虽然 VSCode Copilot 和 Cursor 等工具可以帮助你构建包含前端和后端的大型软件,但它们仍需要一个部署平台,对于非程序员来说,这构成了一个重大障碍,并且会减缓开发迭代速度。
我们注意到,许多 Val Town 用户在 LLM 中生成代码后会将其复制到 Val Town,因为我们的“vals”(微型全栈 Web 应用)可以即时部署。我们认为自己有优势,可以进一步缩短代码生成与全栈部署之间的反馈周期,最终实现终端用户编程的理想:
理想是让计算机的全部能力向所有人开放,让我们的数字世界如黏土般可塑。
这种愿景已经在前端应用逐渐成型,但如果我们真正谈论“计算机的全部能力”,那么这应该涵盖完整的应用程序,包括持久化、身份验证、外部 API 调用——总之,所有专业程序员通常构建的功能。
我花了 2024 年 7 月的大部分时间在 Val Town 中原型设计代码生成想法,并取得了显著的成果。在这篇博客中,我将向大家展示我构建的内容和学到的经验。而且由于所有内容都是在 Val Town 内部构建的,因此完全开源,你可以直接 fork 它们!
My prototype codegen with an instantly deployed backend and database.
生成带有后端和数据库的全栈应用
首先,我构建了一个基础版本的代码生成。我们只需 80 行代码(并且只依赖少量依赖项)就能实现。你可以 fork 它进行尝试。
我使用了 Vercel 的 AI SDK 来轻松地在不同模型之间切换。为了教会大语言模型如何在 Val Town 编写代码,我采用了极大化的方法:我下载了尽可能多的公共 val,并将它们放入 valleGetValsContextWindow。我还发现,将我们的文档(作为原始 markdown 页面)添加到上下文窗口中非常有帮助。
我让模型立即生成 Typescript 代码,这样它就会立刻开始编写代码。随后,我再去掉代码块标记。
这足以生成一个带有后端和数据库的基础 Hacker News 克隆版,并且会立即部署到它自己的子域上:
Hacker News clone with backend and database, generated with gpt-4o (generation is sped up).
高级原型
在接下来的几周里,我不断为这个原型添加各种功能:
- 带有代码和预览的侧边面板
- 用于语法高亮显示的 CodeMirror
- 用于迭代的后续提示词
- 每次迭代生成一个新的 val,这样你可以轻松回溯
- 生成多个 val(通过在提交表单时打开多个标签页)
- 加载现有的 val
- 手动编辑代码
- 在不同模型(Claude、OpenAI)和上下文窗口大小之间切换
我将这个原型命名为 VALL-E,你可以自己 fork 它。让我们来看看具体遇到了哪些问题。
数据库持久性
每个 Val Town 用户都有一个由 Turso 支持的 SQLite 数据库。在教大语言模型(LLM)适应 Val Town SQLite 的特殊要求时,我们遇到了一些问题。因此,我暂时搁置了 SQLite,而是让 LLM 将所有数据保存到 Val Town Blob Storage 中。Blob Storage 本质上类似于简化版的 S3,LLM 在理解上没有问题。
后来,Steve 通过引导 LLM 使用他的 LLM 安全垫片,解决了 SQLite 的问题。相比通过提示词来解决问题,编写一个将数据转换为 LLM 预期格式的 API 包装器效果更好。代码应适应 LLM,而不是让 LLM 适应代码。
实现现实
你可能已经看过 tldraw 的 "实现现实" 演示,演示中你可以在画布上绘制形状,并将其转换为 HTML。我制作了一个带后端的 "实现现实" 原型。为此,我将 tldraw 放在一个 val 中(你可以分叉此项目),并将我的 VALL-E 原型嵌入在一个 iframe 中。
"Make Real with Backend"
目前它仅支持文本提示词,但应能像原始的 Make Draw 演示一样,轻松将任意绘图的 SVG 传递给 LLM。
我修改了 VALL-E 原型,使其能够通过 postMessage API 将生成的 val 名称传递给 tldraw。这样,你可以使用之前生成的 val 作为新 val 的基础,例如在上方视频中,我通过输入“添加更多样例故事”来扩展现有的 val。
模型选择
目前,Claude Sonnet 3.5 无疑是写代码的最佳选择。然而,我们发现它的输出有时过于固定,所以适当调高它的 temperature 参数会有所帮助。
我们还测试了 gpt-4o 和 gpt-4o-mini。虽然 mini 版本便宜得多,但效果也明显不如前者,尽管在制作网站时,特别是给出一些示例时,它的表现还不错。不过,我们不想过度追求便宜的模型,因为今天的顶级模型很可能会成为明天的廉价选择。
整合起来
完成所有这些之后,我在 South Park Commons 举办的一次活动中做了一场快速演讲。内容是在 5 分钟内构建了许多小应用程序。
降低成本
起初,我采用了最大化的方法,将上下文窗口填满尽可能多的示例值和文档。Claude 3.5 Sonnet 具有 200k token 的上下文窗口,我在其中放入了数百个值。然而,一次使用完整上下文窗口的查询,仅输入 token 的费用就至少要 $0.60,成本相当高。
完整上下文窗口的查询速度也较慢,并且我更快遇到了访问频率的限制。虽然我从 Anthropic 那里获得了自定义的频率限制,但这并不是理想的解决方案。接下来让我们看看我是如何优化成本和速度的。
评估
在缩减上下文窗口之前,我想先评估一下我们的模型性能,以便了解较小的上下文窗口对性能的影响。
在大语言模型领域,这类测量通常被称为“评估”或“evals”(可能是因为大家忘记了“基准测试”这个词已经存在)。对我们而言,基本的思路是:生成多个网站,然后确保它们能够正常运行。为此,我开发了一个名为"E-VALL-UATOR"的工具:
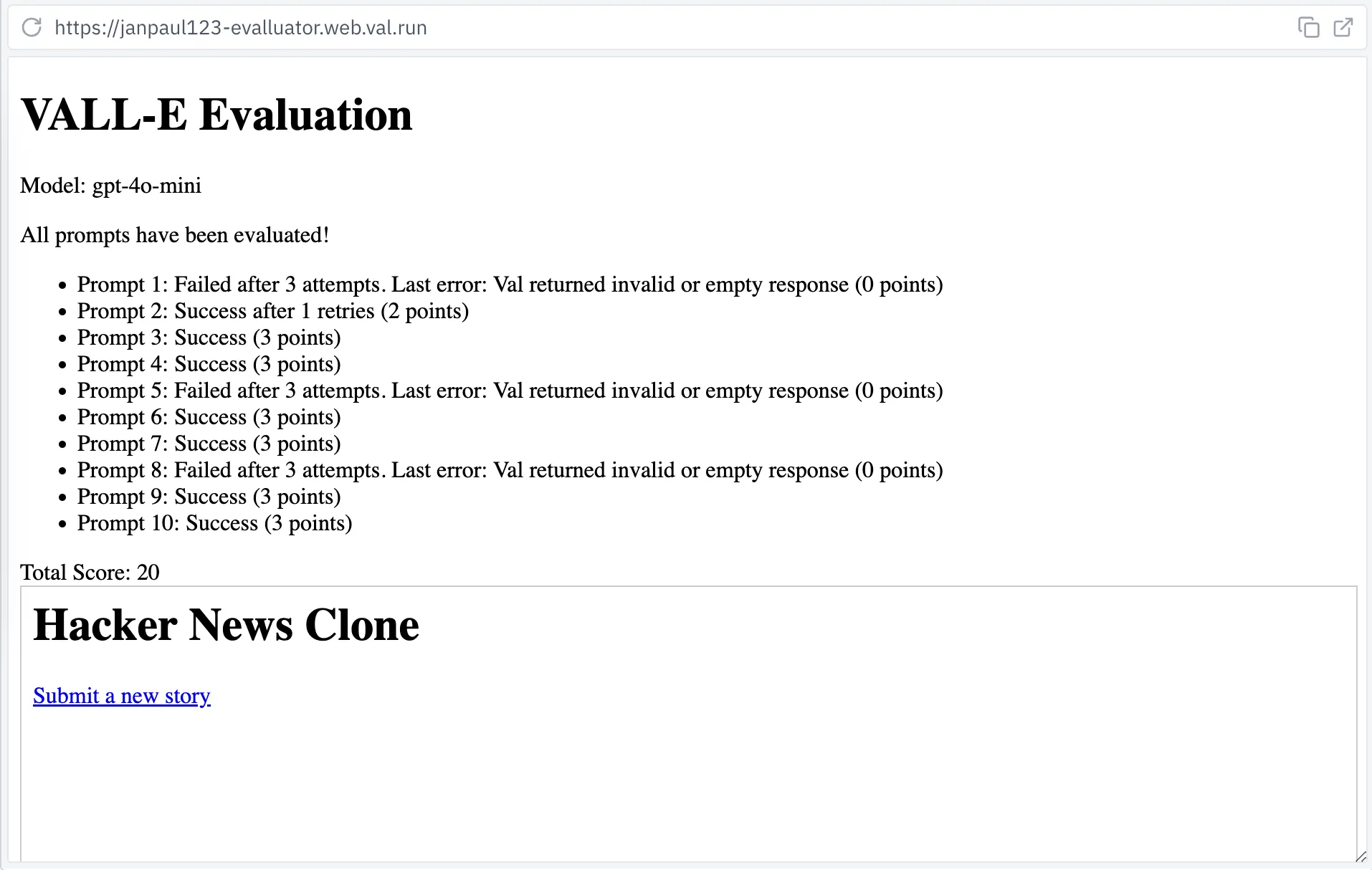
该工具会执行一些基本的提示词(prompt),比如“创建一个简单的待办事项应用”或“创建一个带有计分系统的问答游戏”,然后检查这些程序是否能无错误运行。如果没有错误,我们会给予 3 分。如果存在错误,我们会重试,但每次会扣 1 分。因此,10 个提示词的最高得分为 30 分。
我们如何判断生成的代码是否能够无错误地运行?下面是我们可以捕捉到的几类错误:
- 语法错误。
- Typescript 错误。
GET /请求中的后端错误。GET /请求中的前端错误。- 用户交互(点击内容)时出现的前端错误。
- 用户交互时出现的后端错误(如持久性问题、其他页面的错误)。
- 视觉问题(网站外观不佳)。
- 网站未按预期运行。
在这个原型中,我实现了第 1、3 和 4 点。我制作了一个val(实际上是 VALL-E 帮我生成的),它能够包装任意 HTTP val,并注入一个<script>标签,该标签通过postMessage将运行时错误传递给父 iframe。它还捕捉后端错误,并生成一个新的 HTML 页面,同样通过postMessage将错误信息传递给父页面。
在未来版本中,我们可以让提示词更加精确地描述预期行为,比如“添加待办事项的文本框应具有'class'为'todo-textbox',并且按下'回车'时应添加待办事项”,然后使用实际浏览器测试生成的代码。对于第 7 点(视觉问题),我们甚至可以使用截图服务,与参考图像进行视觉差异对比,或者请另一个大语言模型来为生成的设计打分。
E-VALL-UATOR 矩阵
在获得评估结果后,我开始缩小上下文窗口。我制作了另一个 val(实际上是 VALL-E 制作的),它在不同参数下通过 <iframe> 加载 E-VALL-UATOR,并且我修改了 E-VALL-UATOR,使其通过 postMessage 向父页面报告分数。
此时,我们的 iframes 嵌套了三层(矩阵 => E-VALL-UATOR => VALL-E => 预览),但一切都运行正常。
我将上下文窗口中的示例 vals 按照重要性排序,把最重要的放在最前面。这样我们可以轻松调整包含多少个示例。

在上下文窗口中包含 50 个示例是最佳选择,即使只有 10 个示例,效果也相当不错。(至于我们微调的模型,结果并不理想,可以忽略不计。)这表明,至少在这种基础评估中,我们可以大幅缩减上下文窗口,从而节省大量的 Token 成本。
团队后来进一步缩减了系统提示词,并取得了显著的效果。目前部署的 Townie 提示词几乎就是 Val Town 的一个简化快速入门教程,只包含一个 val 模板。
生成差异
在减少输入 Token 数量后,我还查看了输出 Token 的情况。输出 Token 通常成本更高,并且对总生成时间影响更大,因此减少输出 Token 数量能够显著降低成本并加快速度。
在对现有的 vals 进行迭代时,重新生成整个代码需要消耗大量的 Token,因此我开始研究如何生成差异。代码越长,生成差异的效果就越明显。我从 aider 中获得了灵感,它实现了多种差异生成的版本。
让大语言模型生成 SEARCH:… REPLACE:… 格式的差异相对简单,但这种方法需要重复整个需要替换的代码块。后来我设法让大语言模型仅输出“搜索”块的首行和末行,省略中间的部分。这种方法更快速且成本更低。你可以尝试使用 VALL-E 的“进行更改”模式来体验这一方法。

然而,这种方式对大语言模型来说并不自然,模型经常会偏离预期轨道。尤其是性能较弱的模型在这方面表现不佳,即便是 Claude 3.5 Sonnet 也偶尔会出错。
我还有很多想要尝试的方向,比如探索不同的差异语法和语义,或者引入行号以提供更明确的参考点,或者当模型出错时提前中止并重新尝试。
我们最近在统一差异上取得了一些进展,但仍在进行大量实验。我们也在关注 Anthropic 的 快速编辑模式,目前该模式处于私人测试阶段。
其他想法
UI 中的差异查看
在接受更改之前在 UI 中查看差异非常有用,尤其是在对大型变量进行增量更改时。这在某种程度上取决于受众:非程序员可能不知道如何处理这些差异,而对程序员来说,这些差异是至关重要的。
需要注意的是,“UI 中的差异查看”与 LLM 是否生成差异是完全独立的。无论哪种情况,你都可以立即将更改应用于变量,或者首先将差异显示给用户。
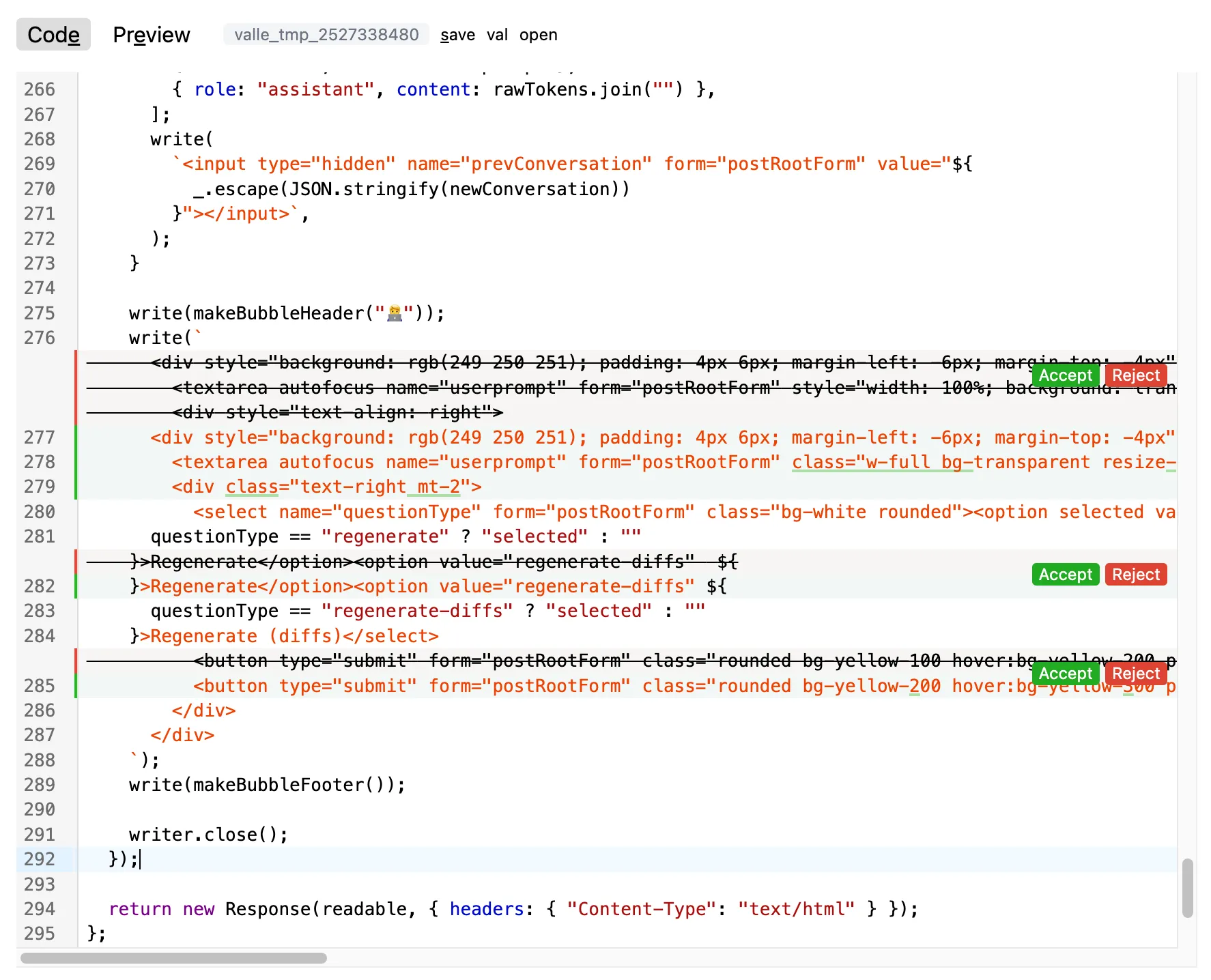
我使用了Codemirror 的合并视图实现了这个功能。你可以通过在 VALL-E 中选择“使用差异”来启用此功能。在 VALL-E 的开发过程中,我最终频繁使用了这种模式。
后端与前端代码
代码文件通常是一个包含前端和后端代码的文件。这可能会让 LLM 感到困惑。对人类来说,这也可能会造成困扰,一些对人类有效的解决方案同样适用于 LLM,例如明确区分前端和后端部分,或者使用更好的抽象。
然而,LLM 会面临一些独特的问题。它们无法看到语法高亮,有时它们喜欢将 HTML 放在用反引号包围的长字符串中。之后,它们可能会忘记自己已经在反引号字符串中,忘记转义内部的反引号。
我们当前部署的 Townie 提示是基于一个客户端的 React 模板构建的,该模板明确区分了前端和后端部分,因此 Claude 知道它需要通过在前端发起fetch调用,并在后端将其作为 API 调用进行处理来实现前后端的通信。
迭代
当我们检测到错误时,我们可以将其反馈给 LLM。这实际上是我制作的第一个原型:IterateGPT。它会在棘手任务上不断迭代,直到不再有错误。在这个例子中,我让它生成获取布鲁克林当前天气的代码,而没有提供进一步的信息——它甚至依靠记忆来想出使用哪些 API!这个过程仍然非常有效。
我们可以对之前提到的所有类型的错误(在谈到评估时)进行类似的操作。我们可以将语法、Typescript 或运行时错误反馈给 LLM;我们可以截取网站的屏幕截图并反馈给它;我们甚至可以让 LLM 自动生成自己的测试。
社会化编程
Vals 可以很容易地被其他 vals 引入,这鼓励人们编写专注于完成某个特定任务的小型 vals,然后许多人可以重复使用它。这就像为包或库进行实时部署。
大语言模型(LLM)还没有充分发挥这个优势。我们可以搜索相关的 vals(RAG),并鼓励模型引入它们,而不是从头开始生成所有内容。
结论
构建这一切真是非常有趣,而且都是在 Val Town 的“用户空间”中完成的。代码生成效果很好,尤其是在使用最新模型时——并且只会越来越好,想到这一点就让人感到兴奋。这是一个激动人心的时代。即使使用当前的模型,我也感觉自己只是触及了表面。
让我们回顾一下用户编程的梦想:
我们的梦想是让计算机的全部功能对所有人都可访问,让我们的 数字世界如粘土般可塑。
我们可能比预期更快实现这一目标。