深入探索:AI 驱动的 PDF 布局检测引擎源代码解析 [译]
2023 年 12 月 10 日 • Shrijith Venkatramana
上周,PDF 转 Markdown 的工具 Marker 成为 Hacker News 首页的热门话题。作为一个对机器学习(ML)充满好奇的学生,我觉得这是一个绝佳的机会,深入了解这款出色的文档 AI 工具的内部机制。
Marker 是什么?
用一个形象的比喻,Marker 就像一个高智能的抄写员,它能够阅读那些复杂的书籍和科学论文 PDF,并将它们转化为清晰、易读的 Markdown 文档。它就像是帮助你进行文档数字化的智能小助手。
官方对这款工具的描述更加专业,具体如下:
Marker 能够将 PDF、EPUB 和 MOBI 文件转换成 Markdown 格式。它的转换速度比 nougat 快 10 倍,准确度更高,且几乎没有误解风险。
-
支持多种类型的 PDF 文档(尤其适用于书籍和科学论文)
-
能够去除文档中的页眉、页脚和其他无关内容
-
将大部分数学公式转换为 Latex 格式
-
格式化代码块和表格
-
支持多种语言(主要测试语言为英语)。更多语言设置可在 settings.py 中查看。
-
可在 GPU、CPU 或 MPS 上运行
工作流程概览
Marker 主要通过以下六个阶段来工作:
-
准备阶段: 利用 PyMuPDF 工具,可以把各种格式的文档转换成 PDF 文件。
-
文本识别(OCR): 使用 Tesseract 或 OCRMyPDF 进行文字识别;也可以选择用 PyMuPDF 进行基本的文字抓取。
-
布局识别: 运用专门定制的 LayoutLMv3 模型 来识别文档中的表格、图表、标题、图说、页眉和页脚。
-
列的检测和排序: 再用一个定制的 LayoutLMv3 模型来识别文档中的列,并按照正确的顺序(上到下,左到右)进行排列。
-
公式/代码处理: 通过 Nougat 工具,把公式图片转换成对应的 latex 代码,并利用启发式方法准确识别和调整代码及表格内容。
-
文本清理与优化: 使用定制的 T5ForTextClassification 模型进行文本清理,比如去掉不必要的空格和奇怪的字符,确保以一种保守且保留原意的方式进行优化。
借助这六个阶段,Marker 能够把任何文档转化为格式整洁的 Markdown 文件。
实例展示
示例:简单教科书
转换前(PDF 格式)

转换后(Markdown 格式)

双栏布局的转换
转换前(PDF 格式)

转换后(Markdown 格式)

科研论文中的数学公式
转换前(PDF 格式)

转换后(Markdown + Latex 格式)

标记工具的直观工作原理解析
从宏观视角来看,这个转换过程结合了众多手动策略和四个专门的人工智能/机器学习模型来完成任务。
文档会在不同阶段被不同程序多次扫描,每个阶段都会对页面增加有用信息或注释,或者去除多余的元素。
第一步:准备阶段
使用工具:PyMuPDF
标记工具能够接受 epub、mobi 和 PDF 文件作为转换流程的输入。它利用 PyMuPDF 将 epub 或 mobi 文件转换成 PDF,作为准备阶段的一部分。整个流程接下来完全基于 PDF 格式内容进行。
第二步:光学字符识别(OCR)
例如,在第一步中增加的信息是 OCR,它能够为我们提取文档中的文字行。标记工具在这一步骤中会使用 OCRMyPDF 或 Tesseract 来进行文字识别。
第 3 步:布局检测
工具:LayoutLMv3(定制模型 - layout_segmenter)
通过使用 LayoutLMv3,我们增加了一个识别不同布局块的功能。Marker 能够识别以下类型的布局块:
{"id2label": {"0": "Caption","1": "Footnote","2": "Formula","3": "List-item","4": "Page-footer","5": "Page-header","6": "Picture","7": "Section-header","8": "Table","9": "Text","10": "Title"}}
第 4 步:排序
工具:LayoutLMv3(定制模型 - column_detector)
本步骤运用一系列规则来排除诸如页眉和页脚等多种元素类型。
第 5 步:公式和方程式的转化
工具:Nougat
接下来,我们利用 nougat 模型将图像中的公式和方程式转换成 latex 代码。
第 6 步:后处理与优化
工具:T5(定制模型 - pdf_postprocessor_t5_base)
最后一步,我们使用一个模型对处理后的文本进行清理和优化,将其转换成 Markdown 格式,并保存到磁盘上。
如何开始使用?
您可以在 GitHub 页面 上找到 Marker 的官方安装指南。
要将 PDF 文件转换为 markdown 格式,您可以执行以下命令:
python convert_single.py --parallel_factor 2 --max_pages 10 input.pdf output.md
项目中引入的有趣模型、库和工具
Ray: 扩展人工智能工作的利器
Ray 的官方定义是这样的:
Ray 是一个旨在扩展人工智能和 Python 应用的统一框架。它由一个核心的分布式运行环境和一系列用于加快机器学习工作的 AI 库组成。
如果你觉得这个定义有些晦涩,那你并不孤单。我深入研究了一番,才弄清楚为何在构建 AI/ML 驱动的软件时会用到 Ray。
最能说明 Ray 用途的例子,出自《用 Ray 扩展 Python》这本书。

简而言之,Ray 是一种加强版的多进程处理库。它不仅能并行处理数据列表,还能在多台远程机器上执行操作。因此,当你的 AI/ML 代码开始处理更多数据或追求更快的处理速度时,只需向系统中增加更多机器,就能将计算能力扩展到更多的机器和进程。
PyMuPDF: PDF 文件的多功能工具包
PyMuPDF 是一个快速且功能强大的用于创建和处理 PDF 文件的库。在 Marker 项目中,PyMuPDF 被用作初步处理的第一步。
如果输入的文档格式是 epub 或 mobi,我们会用 PyMuPDF 把它转换成 PDF 文件。
每一页都通过 PyMuPDF 的数据结构来访问和展现。
如果文档不需要进行 OCR,且已经包含了嵌入式文本,我们还会用 PyMuPDF 直接从 PDF 中提取文本内容。
Nougat:科学文献中方程式的探测器
Nougat 是一款基于 Transformer 技术的生成式 AI 模型,专门用于将扫描版和数字原生的 PDF 文件转化为文本格式。
这里所说的数字原生 PDF,指的是那些虽以 PDF 形式存在,但其实质是图像形式展现的文本或内容,而非直接可被机器读取的文字。
Nougat 在识别文档中的方程式图像并将其转换为有效的 LaTeX 代码这一任务上表现出色。
以这张图为例:
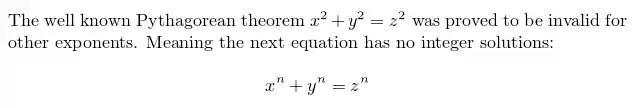
Nougat 能够将这样的图像精准地转换成如下 LaTeX 代码:
The well known Pythagorean theorem $x^2 + y^2 = z^2$ wasproved to be invalid for other exponents.Meaning the next equation has no integer solutions:$ x^n + y^n = z^n $
Nougat 还能用流行的 Markdown 格式来构建文档的整体结构,同时将公式部分精确转换成 LaTeX 代码。
LayoutLMv3:书籍与文件布局检测
LayoutLMv3 是一种基于 Transformer 技术的视觉模型 (ViT),是 LayoutLMv2 和 LayoutLM 的升级版。
这一新版采用了基于 Transformer 的多模态设计,这意味着,它可以同时理解图像和文本,使用诸如 Patch Embedding,Masked Image Modeling 和 Word-Patch 对齐等技术。在本文中,我们不会深入讨论如何进行训练的技术细节。
首先,重要的是要理解 LayoutLMv3 是一个功能强大的框架,它能够处理众多与文本和图像相关的任务,包括:
-
表单理解
-
文档摘要
-
文档分类
-
文档问题解答
-
场景理解
-
文档内的对象检测
-
列检测
-
以及更多
在 Marker,我们特别利用 LayoutLMv3 来识别各类文档元素,如段落、图表、表格、公式等,并用于文档中列顺序的确定。
T5: PDF 后处理模型
T5,又名 文本到文本转换 Transformer(Text-to-Text Transfer Transformer),是 Google AI 研发的一款强大的 AI/ML 模型。它专门设计用于文本间的转换任务,非常适合我们进行文本内容的后期处理。
T5 和 LayoutLMv3 一样,是一个用于处理文本操作任务的统一框架。Marker 利用其专门开发的 PDF 后处理模型对提取的完整文本进行细致的优化:
-
清除之前阶段的干扰字符: 通常 OCR 等步骤会引入不必要的噪声字符,这些字符与原文内容无关。
-
内容美化或整理: Markup 功能能去除无用的缩进、空格等,使元素周围更整洁。
-
保留原始含义: Marker 在进行修改时非常谨慎,只对最显而易见的错误进行更正,以维护原始文件的完整性。
性能简介
详细的 性能基准测试结果 可以在 Marker 的仓库中找到。以下是关于速度、准确性和内存使用情况的快速概览:
准确性
Marker 的准确性与 nougat 相当。 虽然 nougat 在处理科学论文方面略胜一筹,但总体上,nougat 和 marker 的准确性分别为 65% 和 63%。相比之下,原生的 get text 方法的准确性仅为 28%。
速度
在处理页面/文档方面Maker 的处理速度是 nougat 的大约 10 倍。nougat 处理每页大约需 3 秒,而 Marker 仅需大约 0.3 秒。
内存使用
Marker 平均每项任务需要大约 2 GB VRAM。 假设使用 A6000 GPU,平均可以同时处理 24 个文档。
结论
对于数字原生的 PDF 文件,Marker 展现出了极佳的处理能力。这里所说的“数字原生”,指的是通过 latex 制作的 PDF 文件。同样,在处理各种高品质的扫描文档方面,它也有不俗的表现。但在尝试阅读来自 archive.org 的一本古老书籍时,它似乎遇到了难题。与之形成对比的是,像 Amazon Textract 或 Azure Document AI 这样的商业级解决方案几乎可以完美处理这类文档。
虽然明显地,像 Marker 这样的开源文档 AI 要想赶上商业级解决方案,还有很长的路要走,但与过去的方案相比,Marker 为自由开源软件(FOSS)的文档 AI 领域做出了重要贡献。因此,我们应该对 Marker PDF 的创作者Vikas Paruchur表示感谢。谢谢你,Vikas!