Q* 假设:思维树推理、过程奖励模型,以及如何大幅提升合成数据的能力 [译]
紧急专题:要弄懂 Q*,我们需要的信息其实就在我们身边,只是网络流行语更比现实生活有趣。
编者按:这篇文章相当于下周的内容。由于时效性,我提前发布了,毕竟 RLAIF 和过程奖励模型本来就在我的计划列表里。我们拭目以待是否会有更多 紧急发布。
在我们都准备放假庆祝感恩节的星期三,路透社最后一次报道了 OpenAI 的动态,揭晓了 OpenAI 的一种新方法 Q* 的名字和高层评价,这种方法被含糊地描述为具有强大的能力:
路透社联系 OpenAI 后,该公司虽未公开评论,但在内部消息中向员工承认了一个名为 Q* 的项目...
OpenAI 的一些人士认为 Q*(读作 Q-Star)可能是这家初创公司在追求所谓的人工通用智能(AGI)方向上的一大突破。一位消息人士向路透社透露,OpenAI 将 AGI 定义为在大多数具有经济价值的任务中超越人类能力的自主系统。
据一位不愿透露姓名的人士透露,这个新模型在获得庞大计算资源的支持下,能够解决一些数学问题。尽管其数学解题能力仅限于小学生水平,但这样的成绩让研究人员对 Q* 的未来发展充满期待。
仅仅一个方法的名称就引起了广泛的猜测。虽然这次的名字相当简单,它并不只是《沙丘》系列中的又一个代号。如果 Q*(Q-Star)是真实存在的,它显然将强化学习文献中的两大核心主题——Q-值和A*(一种经典的图搜索算法)联系在了一起。当然,也有人认为 Q* 可能仅仅指代最优策略的价值函数,但这需要是一个捏造的泄露,这种情况似乎不太可能,毕竟 OpenAI 几乎把所有东西都泄露出去了,所以捏造这样的信息似乎并不合理。1
我的最初假设,我将其定义为一种“锡帽子”理论,是 Q-学习和 A* 搜索的混合。我没能回答的是,到底在搜索什么?我最初猜测的对话轮次搜索几乎可以肯定是错误的,原因在于我稍后会提到的基础设施方面的考虑。
通过深入研究,我越来越确信他们正通过思维树的语言搜索/推理步骤做着有影响力的工作,但其实这比大众所想象的要小一个层次。人们之所以夸大其词,是因为想把大语言模型的训练和应用与深度强化学习 (Deep RL) 的核心部分联系起来,后者是 AlphaGo 等成功案例的关键,比如自我对弈和前瞻性规划。
-
自我对弈 指的是通过与自己的不同版本对弈,智能体能提高其游戏技能,因为它会逐渐遇到更多挑战性场景。在大语言模型 (LLM) 领域,自我对弈很可能主要表现为 AI 反馈,而非竞争过程。
-
前瞻性规划 意味着利用世界模型来预测未来,从而做出更好的行动或产出。其中的两种方法分别是基于模型预测控制 (MPC) —— 通常应用于连续状态,以及蒙特卡罗树搜索 (MCTS) —— 适用于离散动作和状态。
为了理解这些元素如何相互结合,我们需要回顾 OpenAI 及其他机构最近发布的研究成果,这些研究将解答两个问题:
-
我们如何构建一个可以搜索的语言表示形式?
-
我们如何在语言的独立且有意义的部分(而不是整体)上建立价值观?
有了这些答案,我们就能清楚地看到如何使用现有的用于强化学习人机交互 (RLHF) 的强化学习方法。我们利用强化学习优化器来微调语言模型,并通过模块化的奖励(而不是现今的整个序列)来生成更高质量的结果。
用大语言模型打造思维树:一种新型的模块化推理方法
我们熟悉的“深呼吸”和“一步一步思考”的技巧,如今已经升级,融入了并行计算和启发式策略等先进方法,用于推动更复杂的推理过程,这些都源自于搜索技术的基本原理。
“思维树 (Tree-of-Thoughts, ToT)”正如其名,它引导语言模型构建一个推理路径树,这些路径可能最终汇集于一个正确的答案,也可能不会。论文中展示了它与其他大语言模型解题方法的对比:
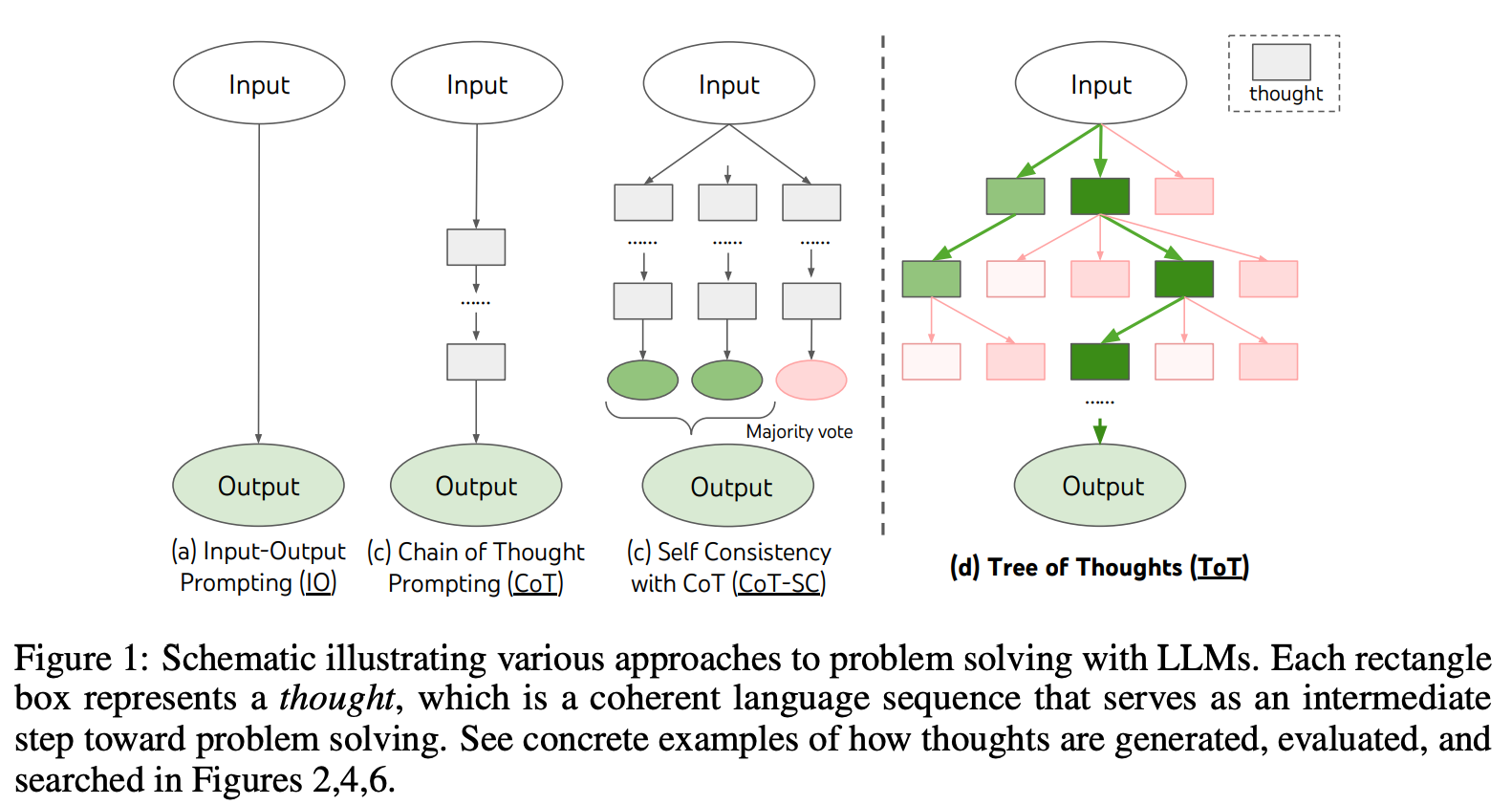
使思维树发挥作用的关键在于将推理步骤分解,并激发模型创造新的推理步骤。ToT 可能是第一个“递归式”的提示技术,用于增强推理能力,它与人工智能安全领域中对递归自我改善模型的关注不谋而合(虽然我不是这方面的专家)。
利用这种推理树,我们可以采用不同的方法来评估每个节点,或者选择最终的解题路径。这些方法可能基于简单的如最短路径选择,也可能涉及需要外部反馈的复杂策略,这又让我们回到了基于强化学习的人类反馈 (RLHF) 的思路上。
想了解更多?请阅读思维树论文:https://arxiv.org/abs/2305.10601
在生成过程中使用细粒度奖励标签:过程奖励模型 (Process Reward Models, PRM)
传统的强化学习人类反馈 (RLHF) 大多是对整个语言模型回应进行评分。对于熟悉强化学习的人来说,这种方式有些令人遗憾,因为它限制了深入挖掘文本每个细节部分价值的可能性。虽然有预测称未来将在多轮对话中实现此类多步骤优化,但这种做法因涉及人工或提示源而显得不太实际。
将此方法扩展到自我对话风格似乎简单,但难点在于为大语言模型 (LLM) 设定目标,使其适应持续改进的自我对话动态。大多数我们想要通过 LLM 实现的任务都是重复性工作,与围棋游戏相比,它们在性能提升上没有太高的上限。
然而,有一类 LLM 应用恰好适合分步骤理由,自然划分为多个文本段落,以解决数学问题为最佳例子。
我在过去半年里经常听到 RLHF 领域人士私下讨论过程奖励模型 (PRM)。虽然关于这些模型有大量文献,但关于如何将它们与强化学习结合使用的资料却寥寥无几。
PRM 的核心理念是对每个推理步骤进行评分,而不仅仅是整体信息。例如,OpenAI 的论文 Let’s Verify Step by Step 中展示了这样的一个案例:

此外,他们还展示了一种有趣的反馈界面(未来可能由 AI 取代),但这种界面对于理解概念颇有帮助:

此方法通过在最大平均奖励或其他指标上取样,而不仅仅依赖单一分数,实现了更细致的生成和推理问题的处理(在这一领域,标准的奖励模型被称为结果型奖励模型)。采用Best-of-N 抽样方式,本质上是多次生成并选用奖励模型评分最高的结果(这是 Llama 2 推广的拒绝抽样方法的推理阶段对应物),PRMs 在解决推理任务方面优于标准奖励模型。
迄今为止,大多数关于 PRMs 的资料主要展示了如何在推理阶段使用它们。真正的潜力在于将这一信号优化应用于训练过程。为了创造最佳的优化环境,能够生成多种推理路径进行评分和学习至关重要。这就是 Tree-of-Thoughts 的作用所在。ToT 提供的多样性提示,使得策略可以通过使用 PRM 学习并加以利用。
关于 PRMs 的更多资料,可参考以下内容:
-
Let’s Verify Step by Step:一份关于 PRMs 的优秀入门介绍。
-
Solving math word problems with process- and outcome-based feedback:2023 年所有 PRM 和推理工作的经典文献。
-
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models:一篇研究大语言模型在数学推理学习中应用拒绝抽样方法等多方面贡献的论文。
-
Let's reward step by step: Step-Level reward model as the Navigators for Reasoning
另外,有一个受欢迎的公开数学模型据说是通过 PRMs 训练的:Wizard-LM-Math。此外,OpenAI 今年早些时候公布了他们的细致奖励标签,来自于 Verify Step by Step 论文,用于训练 PRM released their fine-grained reward labels。
整合理解:Q* 可能指的是什么
Q* 似乎采用了个性化排名模型(PRM)来对思考树(Tree of Thoughts)的推理数据进行评分,并通过离线强化学习(Offline RL)进行优化。这种方式与当前那些使用如动态政策优化(DPO)或迭代学习 Q 学习(ILQL)这类离线算法的强化学习人类反馈(RLHF)工具类似,这些工具在训练过程中并不需要从大语言模型(LLM)生成数据。在这种方法中,强化学习算法观察的“轨迹”是一系列推理步骤,因此我们最终以多步骤方式进行 RLHF,而不再是单纯的上下文带状策略。
考虑到我听说的传闻,OpenAI 已在 RLHF 中使用离线 RL(这本身并不具有太多信息量),这对我来说并不是一个惊人的飞跃。这种方法的难点在于收集合适的提示,构建能够生成高质量推理步骤的模型,最关键的是:准确评估成千上万个完成的任务。
最后一步则利用了所谓的“巨大计算资源”:用 AI 而不是人类来为每个步骤打分。在这里,合成数据显得尤为重要,相较于单一的连续思考路径,树状结构提供了更多选择,帮助我们最终找到正确答案。
大量的计算资源与我所听闻的大型科技公司(如 Google、Anthropic、Cohere 等)正在使用过程监督或类似于现实生活人工智能反馈(RLAIF)的方法来创建大规模的预训练数据集的传言相符,这无疑需要大量的 GPU 时间。这与目前公开模型在该领域的差距令人担忧。
虽然这些核心概念对我来说相对清晰,但要实现这些概念需要极高的模型操作技巧,这是很少人拥有的。从分布控制到大规模推断,再到 RL 的挑剔性,这些都远远超出了我的知识和经验范围。这些信息看似自然而然。ToT 和 PRM 的所有评估都集中在数学等推理问题上,这与最近新闻报道的这种泄露方法的内容完全吻合。即便这不是 Q*,也绝对是一个值得尝试的有趣实验。
超级规模的 AI 反馈数据及未来展望
正如我之前所写,AI 反馈和宪政 AI 在公众意识中的关注度不足。合成数据是迅速扩展数据集的最佳途径。短期来看,我们显然能够借此创造一些有用的数据。但目前尚不明确的是,这种方法能扩展到何种程度 — 也就是说,它能否完全替代互联网规模的数据?