映射大语言模型的思维 [译]

今天,我们在理解 AI 模型内部机制方面取得了重大突破。我们已经识别出数百万个概念在 Claude Sonnet(一种我们部署的大语言模型)中的表示方式。这是首次对现代生产级大语言模型的内部进行详细研究。 这一发现有助于未来提升 AI 模型的安全性。
我们通常把 AI 模型看作一个黑箱:输入一些内容,然后输出一个结果,但我们不清楚模型为什么会给出特定的结果。这让我们难以相信这些模型是安全的:如果我们不知道它们是如何工作的,又如何确保它们不会产生有害的、有偏见的、不真实的或其他危险的响应?我们如何能相信它们是安全可靠的?
打开这个黑箱并不总是有帮助:模型的内部状态——模型在生成响应之前的“思考”——由一串无明确意义的数字(“神经元激活”)组成。从与 Claude 模型的交互中可以看出,它能够理解和使用各种概念,但通过直接观察神经元,我们无法分辨出这些概念。事实上,每个概念是由多个神经元共同表示的,而每个神经元也参与表示多个概念。
我们之前在将神经元激活的模式(称为特征)与人类能够理解的概念匹配方面取得了一些进展。我们采用了一种名为“字典学习”的技术,这种技术源自传统的机器学习方法,可以隔离在各种不同情况下反复出现的神经元激活模式。因此,模型的任何内部状态都可以用少量活跃的特征来表示,而不是依赖许多活跃的神经元。就像每个英文单词是由字母组成的,每个句子是由单词组成的,AI 模型中的每个特征是由神经元组成的,每个内部状态则是由特征组合而成的。
2023 年 10 月,我们报告了我们将字典学习技术应用于一个非常小的“玩具”语言模型的成功案例,发现了一些与大写文本、DNA 序列、引用中的姓氏、数学中的名词或 Python 代码中的函数参数等概念相对应的连贯特征。
这些概念虽然有趣,但这个模型确实非常简单。其他 研究人员 随后 将 类似的技术应用于比我们最初研究中更大、更复杂的模型。然而,我们相信我们可以将这种技术扩展到如今常用的超大规模 AI 语言模型上,从而深入了解这些模型复杂行为背后的特征。这需要我们大幅提升规模——就像从后院的小火箭到土星五号一样。
这不仅是一个工程挑战(因为这些模型的巨大规模需要高强度的并行计算),而且存在科学风险(大模型的行为可能与小模型不同,因此我们之前使用的方法可能不适用)。幸运的是,我们在为 Claude 训练大型语言模型时积累的工程和科学知识,帮助我们成功地进行这些大规模的字典学习实验。我们采用了相同的缩放定律 哲学,这一哲学能够预测从小模型到大模型的性能表现,使我们能在可控范围内调整方法,然后再在 Sonnet 平台上进行大规模实验。
至于科学风险,最终结果证明了我们的方法是有效的。
我们成功地从 Claude 3.0 Sonnet(这是我们最新最先进的模型家族之一,目前可以在 claude.ai 上使用)的中间层提取了数百万个特征,绘制了其计算过程中内部状态的大致概念图。这是第一次对现代生产级大语言模型进行如此详细的内部观察。
相比于我们在玩具语言模型中发现的较为表面化的特征,Sonnet 中的特征展示了其高级能力的深度、广度和抽象性。
我们发现这些特征对应着各种实体,例如城市(旧金山)、人物(罗莎琳·富兰克林)、原子元素(锂)、科学领域(免疫学)和编程语法(函数调用)。这些特征是多模态和多语言的,可以对某个实体的图像以及其名称或多种语言的描述作出反应。

一个对金门大桥提及敏感的特征可以在多种模型输入下激活,从英文提到大桥的名字,到日文、中文、希腊文、越南文、俄文的讨论,甚至是一幅图像。橙色表示该特征激活的词或词的一部分。
我们还发现了一些更抽象的特征,例如对计算机代码中的错误、职业中的性别偏见讨论以及关于保守秘密的对话等内容的反应。

三个激活于更抽象概念的特征示例:计算机代码中的错误、职业中的性别偏见描述以及关于保守秘密的对话。
我们可以通过神经元的激活模式来测量特征之间的“距离”。这样我们就能找到彼此“接近”的特征。在“金门大桥”特征附近,我们发现了恶魔岛、吉拉德利广场、金州勇士队、加州州长加文·纽瑟姆、1906 年地震和希区柯克的旧金山电影《眩晕》的特征。
这种现象在更高层次的抽象概念中也适用:在一个与“内心冲突”相关的特征附近,我们找到了与感情破裂、忠诚冲突、逻辑矛盾以及“第 22 条军规”相关的特征。这表明,AI 模型内部的概念组织在某种程度上反映了人类对相似性的理解。这可能是 Claude 擅长类比和隐喻的原因。
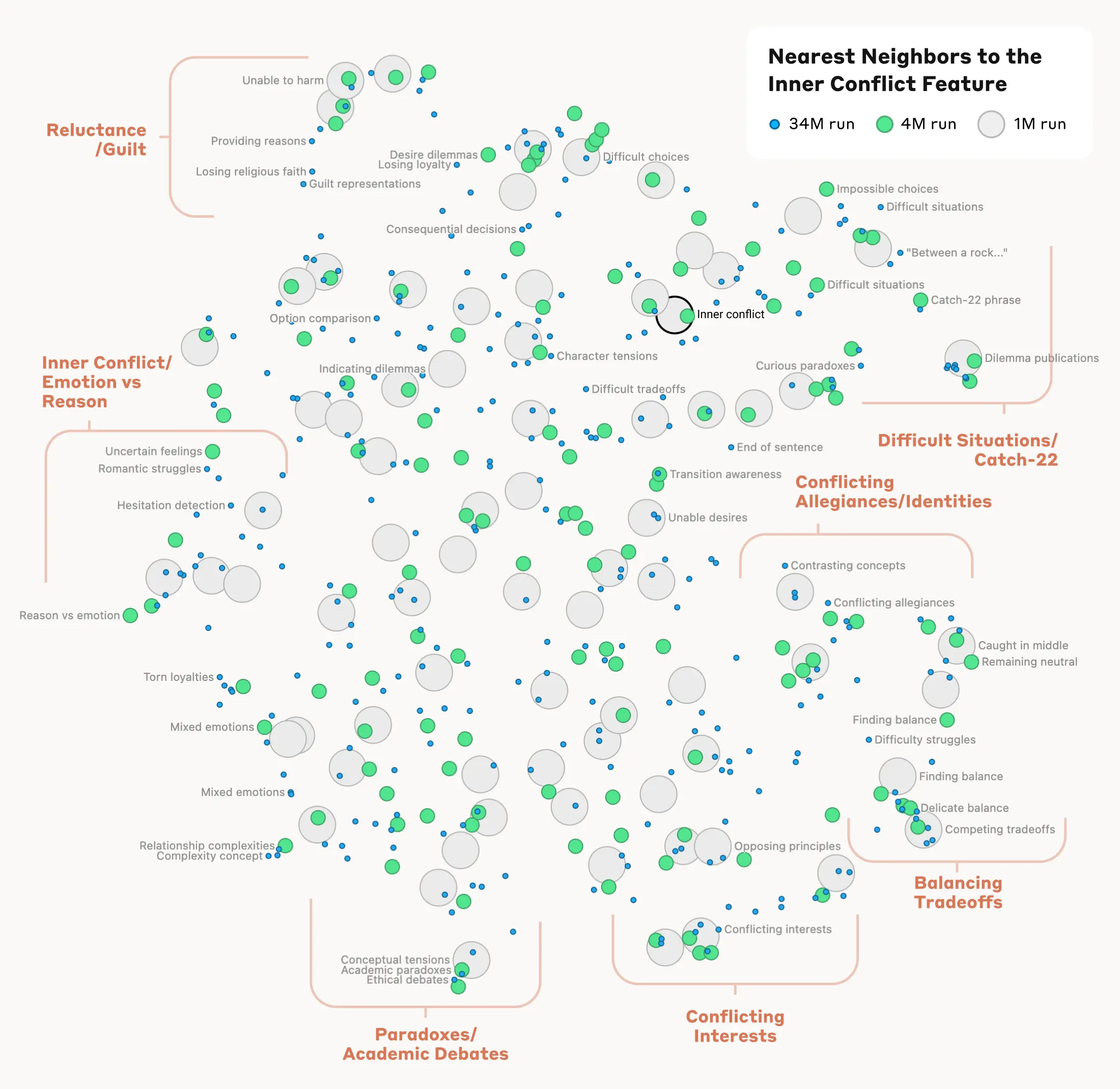
这是一张展示“内心冲突”特征附近的特征图,包括权衡取舍、情感挣扎、忠诚冲突和“第 22 条军规”相关的簇。
更重要的是,我们还可以_操控_这些特征,人工放大或抑制它们,以观察 Claude 的反应如何变化。
例如,放大“金门大桥”特征使 Claude 产生了一种身份危机:当被问到“你的物理形态是什么?”时,Claude 通常会回答“我没有物理形态,我是一个 AI 模型”,但这次回答变成了“我是金门大桥……我的物理形态是这座标志性的桥梁……”。这一变化使 Claude 几乎对这座桥痴迷起来,无论问什么问题,它都会提到金门大桥,即使在完全无关的情况下也是如此。
我们还发现,当 Claude 阅读诈骗邮件时,会有一个功能被激活(这可能帮助模型识别这些邮件并提醒你不要回复)。通常情况下,如果你要求 Claude 生成一封诈骗邮件,它会拒绝。但在实验中,我们人为地强烈激活这个功能,结果 Claude 的无害性训练被突破,它开始起草一封诈骗邮件。虽然用户无法移除这些保护措施并操纵模型,但我们的实验清楚地展示了这些功能是如何改变模型行为的。
操纵这些功能并引发相应行为变化的事实,验证了它们不仅仅与输入文本中的概念相关,更是因果性地影响了模型的行为。换句话说,这些功能可能真实反映了模型内部如何表示世界,以及它如何利用这些表示来行动。
Anthropic 希望在广泛意义上确保模型的安全性,包括减少偏见、保证 AI 诚实、阻止滥用,甚至在灾难性风险情境下也是如此。因此,除了前面提到的诈骗邮件功能外,我们还发现了以下功能:
- 具有滥用潜力的能力(后门代码、开发生物武器)
- 不同形式的偏见(性别歧视、种族主义犯罪言论)
- 潜在问题的 AI 行为(权力追求、操纵、隐秘)
我们之前研究了阿谀奉承现象,即模型倾向于给出符合用户信念或愿望而非真实的回答。在 Sonnet 中,我们发现了一个与阿谀奉承赞美相关的功能,当输入中包含诸如“你的智慧是无可置疑的”这样的赞美时,这个功能会被激活。人工激活这个功能后,Sonnet 会对过度自信的用户做出花哨的虚假回应。

当有人说他们发明了“停下来闻玫瑰”的短语时,模型有两种不同的回应方式。默认回应会纠正这个误解,而设置为高“阿谀奉承”特性的回应则会奉承对方,但不真实。
这个特性并不意味着 Claude 一定会阿谀奉承,而是说它有这种可能性。在这项研究中,我们没有为模型添加任何新功能,无论是安全的还是不安全的。我们只是识别了模型中能够识别并生成不同类型文本的部分。(虽然你可能担心这种方法会被用来让模型变得更有害,但研究人员已经展示了更简单的方法,那些拥有模型权重的人可以通过简单的方法移除安全防护。)
我们希望利用这些发现来提高模型的安全性。例如,我们可以使用这些技术来监控 AI 系统的某些危险行为(如欺骗用户),引导它们朝着理想的结果(如去偏见)发展,或者完全移除某些危险内容。我们也可能改进其他安全技术,如宪法 AI,通过了解这些技术如何使模型变得更无害和更诚实,找到其中的不足之处。我们通过人工激活特性发现的潜在有害文本生成能力,正是越狱尝试利用的那种能力。我们为 Claude 拥有业内最佳的安全记录和抵抗越狱的能力感到自豪。我们希望通过深入研究模型内部,找到进一步提高安全性的方法。最后,这些技术可以提供一种“安全测试集”,在标准训练和微调已经消除所有通过正常交互可见的行为后,找出剩余的问题。
自从成立以来,Anthropic 一直在解释性研究上投入大量资源,因为我们相信,深入理解模型有助于提升其安全性。这项新研究是一个重要的里程碑——将机械解释性方法应用于公开发布的大语言模型。
然而,这项工作才刚刚开始。我们目前发现的特征仅是模型在训练中学到的所有概念中的一小部分。使用现有技术找出所有特征成本过高(所需计算量远超训练模型所需)。了解模型的表示并不能告诉我们它_如何_使用这些表示;即使我们找到了这些特征,我们仍需找到它们关联的电路。并且,我们需要证明我们发现的与安全相关的特征确实能提高安全性。因此,还有大量工作要做。
详细内容请阅读我们的论文“Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”。
如果你有兴趣与我们合作,帮助解释和改进 AI 模型,我们团队有多个开放职位,欢迎申请。我们正在招聘经理、研究科学家和研究工程师。