在 Character.AI 的提示词设计 [译]
![在 Character.AI 的提示词设计 [译]](https://research.character.ai/content/images/size/w960/2024/07/promp-poet-2-1.webp)
作者:James Groeneveld Github: https://github.com/character-ai/prompt-poet PyPi: https://pypi.org/project/prompt-poet/
在 Character.AI,掌握提示词工程的艺术与科学至关重要。在实际应用中构建提示词需要考虑广泛的数据和因素:当前的对话模式、正在进行的实验、所涉及的角色、聊天类型、各种用户属性、固定记忆、用户角色、整个对话历史等等。鉴于我们每天构建数十亿条提示词、需要最大化利用不断扩展的大语言模型(LLM)上下文窗口,以及我们的用例多样性,一个强大且可扩展的提示词设计方法是必不可少的。我们倡导从传统的“提示词工程”转向“提示词设计”——这种转变使我们远离繁琐的字符串操作,转而设计精确且引人入胜的提示词。这篇文章介绍了我们开发的 Prompt Poet,一个专门解决提示词设计问题的工具。
简要概述
Python f-strings(及其相关工具)现在是 Prompt Engineers 的行业标准。使用 f-strings 可以像将用户查询直接添加到字符串中一样简单,但也可能变得非常复杂,涉及大量手动字符串操作。这使得提示迭代对非技术人员不友好,因为需要编写代码。
我们相信有更好的方法。这就是为什么我们创建了 Prompt Poet(Github / PyPi),一个允许开发人员和非技术用户高效设计和管理生产提示的工具。它节省了在字符串操作上的工程时间,使每个人都能更多地专注于为用户打造最佳提示。
借鉴 UI 设计的思路,我们将提示视为运行时状态的函数——包括提示模板、数据、Token 限制等。

提示是状态的函数。
基本用法
import osimport getpassfrom prompt_poet import Promptfrom langchain import ChatOpenAI# Uncomment if you need to set OPENAI_API_KEY.# os.environ["OPENAI_API_KEY"] = getpass.getpass()raw_template = """- name: system instructionsrole: systemcontent: |Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.- name: user queryrole: usercontent: |{{ username}}: {{ user_query }}- name: responserole: usercontent: |{{ character_name }}:"""prompt = Prompt(raw_template=raw_template,template_data={"character_name": "Character Assistant","username": "Jeff","user_query": "Can you help me with my homework?"})prompt.messages>>> [{'role': 'system', 'content': 'Your name is Character Assistant and you are meant to be helpful and never harmful to humans.'}, {'role': 'user', 'content': 'Jeff: Can you help me with my homework?'}, {'role': 'user', 'content': 'Character Assistant:'}]model = ChatOpenAI(model="gpt-4o-mini")response = model.invoke(prompt.messages)response>>> AIMessage(content='Of course, Jeff! I’d be happy to help you with your homework. What subject are you working on, and what do you need assistance with?', response_metadata={'token_usage': {'completion_tokens': 31, 'prompt_tokens': 47, 'total_tokens': 78}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0f03d4f0ee', 'finish_reason': 'stop', 'logprobs': None}, id='run-5fff6ab5-5dee-40d8-b11c-7a9637406c36-0', usage_metadata={'input_tokens': 47, 'output_tokens': 31, 'total_tokens': 78})
提示模板
使用 Prompt Poet,您可以将原本用于提示工程的时间转为用于提示设计,使您能够迭代模板而非代码。这些模板使用 YAML 和 Jinja2 的混合,使其既灵活又易于组合。这种方法使开发人员和非技术用户都能高效地创建和管理提示。模板处理分为两个主要阶段:
- 渲染:最初由 Jinja2 处理输入数据。在这个阶段,控制流逻辑被执行,数据被验证并绑定到变量,模板中的函数被评估。
- 加载:渲染后,输出的是一个结构化的 YAML 文件。这个 YAML 结构由重复的块或部分组成,每个部分被封装为一个 Python 数据结构。这些部分具有以下几个属性:
- 名称:部分的清晰易读标识符。
- 内容:提示的实际字符串内容。
- 角色(可选):指定参与者的角色,帮助区分不同的用户或系统组件。
- 截断优先级(可选):确定必要时的截断顺序,具有相同优先级的部分按其出现顺序截断。
示例:基础问答机器人
- name: system instructionsrole: systemcontent: |Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.- name: user queryrole: usercontent: |{{ username}}: {{ user_query }}- name: responserole: usercontent: |{{ character_name }}:
一个问答机器人模板的基本示例。
插值列表
{% for message in current_chat_messages %}- name: chat_messagerole: usercontent: |{{ message.author }}: {{ message.content }}{% endfor %}
如果您有列表中的元素(如消息),可以将它们解析到模板中。
截断旧消息
{% for message in current_chat_messages %}- name: chat_messagerole: usertruncation_priority: 1content: |{{ message.author }}: {{ message.content }}{% endfor %}
由于上下文长度有限,无法始终容纳整个聊天历史,因此我们可以在消息部分设置截断优先级,Prompt Poet 将按出现顺序截断这些部分(从最旧到最新)。
根据用户模式调整
{% if modality == "audio" %}- name: special audio instructionrole: systemcontent: |{{ username }} is currently using audio. Keep your answers succinct.{% endif %}
根据用户的当前模式(音频或文本)定制指令。
针对特定查询
{% if extract_user_query_topic(user_query) == "homework_help" %}{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}- name: homework_example_{{ loop.index }}role: usercontent: |{{ homework_example }}{% endfor %}{% endif %}
必要时可以包括例如作业帮助的上下文特定示例。
处理空白
- name: system instructionsrole: systemcontent: |Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.- name: user queryrole: usercontent: |<|space|>{{ username}}: {{ user_query }}
Prompt Poet 默认去除多余的空白字符以避免在最终提示中出现不必要的换行。如果您想包含明确的空格,请使用专用空格标记符“”以确保格式正确。
将所有内容组合在一起
- name: system instructionsrole: systemcontent: |Your name is {{ character_name }} and you are meant to be helpful and never harmful to humans.{% if modality == "audio" %}- name: special audio instructionrole: systemcontent: |{{ username }} is currently using audio modality. Keep your answers succinct and to the point.{% endif %}{% if extract_user_query_topic(user_query) == "homework_help" %}{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}- name: homework_example_{{ loop.index }}role: usercontent: |{{ homework_example }}{% endfor %}{% endif %}{% for message in current_chat_messages %}- name: chat_messagerole: usertruncation_priority: 1content: |{{ message.author }}: {{ message.content }}{% endfor %}- name: user queryrole: usercontent: |{{ username}}: {{ user_query }}- name: reply_promptrole: usercontent: |{{ character_name }}:
组合能力是 Prompt Poet 模板的核心优势,能够创建复杂的、动态的提示。
分解成部分
{% include 'sections/system_instruction.yml.j2' %}{% include 'sections/audio_instruction.yml.j2' %}{% if extract_user_query_topic(user_query) == "homework_help" %}{% include 'sections/homework_examples.yml.j2' %}{% endif %}{% include 'sections/chat_messages.yml.j2' %}{% include 'sections/user_query.yml.j2' %}{% include 'sections/reply_prompt.yml.j2' %}
为了在模板中保持 DRY(Don't Repeat Yourself)原则,将它们分解成可重用的部分,可以跨不同模板应用,例如在 A/B 测试新提示时。
这只是 Prompt Poet 模板的开始,我们很期待看到你们的创作!
设计选择
Prompt Poet 库
Prompt Poet 库提供了各种功能和设置,包括提示属性。关键功能如分词和文本截断有助于高效缓存和低延迟响应,详见优化推理。
prompt.tokenize()prompt.truncate(token_limit=TOKEN_LIMIT, truncation_step=TRUNCATION_STEP)# Inspect prompt as a raw string.prompt.string: str>>> "..."# Inpsect the prompt as raw tokens.prompt.tokens: list[int]>>> [...]# Inspect the prompt as LLM API message dicts.prompt.messages: list[dict]>>> [...]# Inspect the prompt as first class parts.prompt.parts: list[PromptPart]>>> [...]
模板语言
Jinja2 和 YAML 结合提供了一种非常可扩展和表达力强的模板语言。Jinja2 支持直接的数据绑定、任意函数调用和基本的模板内控制流。YAML 为我们的模板提供结构(深度为 1),使我们在达到 token 限制时能够执行复杂的截断。这种 Jinja2 和 YAML 的组合并不独特——最显著的是被 Ansible 使用。
提示的可移植性
在 Character.AI,我们不断改进我们的模型以更好地与用户偏好对齐。为此,我们需要在离线过程中重新构建我们的生产提示,例如用于评估和后训练工作负载。通过这种方式模板化我们的提示,简化了团队之间共享模板文件的过程,而无需将不断演变的代码库的不同部分拼凑在一起。
模板内函数调用
Jinja2 的一个突出功能是能够在模板运行时直接调用任意 Python 函数。这一功能对于即时数据检索、处理和验证非常重要,简化了提示词的构建过程。比如,extract_user_query_topic 可以对用户查询进行任意处理,并用于模板的控制流,例如,通过与主题分类器进行一次往返通信。
{% if extract_user_query_topic(user_query) == "homework_help" %}{% for homework_example in fetch_few_shot_homework_examples(username, character_name) %}- name: homework_example_{{ loop.index }}role: usercontent: |{{ homework_example }}{% endfor %}{% endif %}
使用 extract_user_query_topic 进行模板内函数调用的示例。
自定义编码函数
默认情况下,Prompt Poet 将使用 TikToken 的“o200k_base”分词器,但用户也可以在顶层通过 tiktoken_encoding_name 提供其他编码名称。或者,用户可以提供自己的编码函数 encode_func: Callable[[str], list[int]]。
from tiktoken import get_encodingencode_func = get_encoding("o200k_base")prompt = Prompt(raw_template=raw_template,template_data=template_data,encode_func=encode_func)prompt.tokenize()prompt.tokens>>> [...]
传递自定义编码函数以构建提示词。
截断
如果你的 LLM 提供商支持 GPU 亲和和前缀缓存,请利用 Character.AI 的截断算法来最大化前缀缓存率。前缀缓存率是指从缓存中检索到的提示词 token 数量占提示词 token 总数的比例。为你的使用场景找到最佳的截断步长和 token 限制值。随着截断步长的增加,前缀缓存率也会增加,但从提示词中截断的 token 也会更多。
TOKEN_LIMIT = 128000TRUNCATION_STEP = 4000# Tokenize and truncate the prompt.prompt.tokenize()prompt.truncate(token_limit=TOKEN_LIMIT, truncation_step=TRUNCATION_STEP)response = model.invoke(prompt.messages)
具有指定 token 限制和截断步长的缓存感知提示词截断示例。
缓存感知截断解释
我们的截断策略通过优化消息从提示词中截断的方式,帮助我们实现了令人印象深刻的 95% 缓存率。简而言之,每次截断时,我们都会在一个固定的截断点进行截断,平均每 k 次才移动一次这个截断点。这使我们能够最大限度地利用 优化推理 中描述的 GPU 前缀缓存。相反,如果我们只是截断直到达到 token 限制 (L),这个截断点每次都会移动。这种方法的权衡在于我们经常截断的部分比实际需要的更多。
简单截断
考虑以下交替示例,其中 M1…M10 是当前聊天中的消息。如果我们简单地截断到刚好低于 token 限制,我们的截断点每次都会移动,只留下前缀的一小部分从缓存中检索,从而导致显著的重新计算开销。
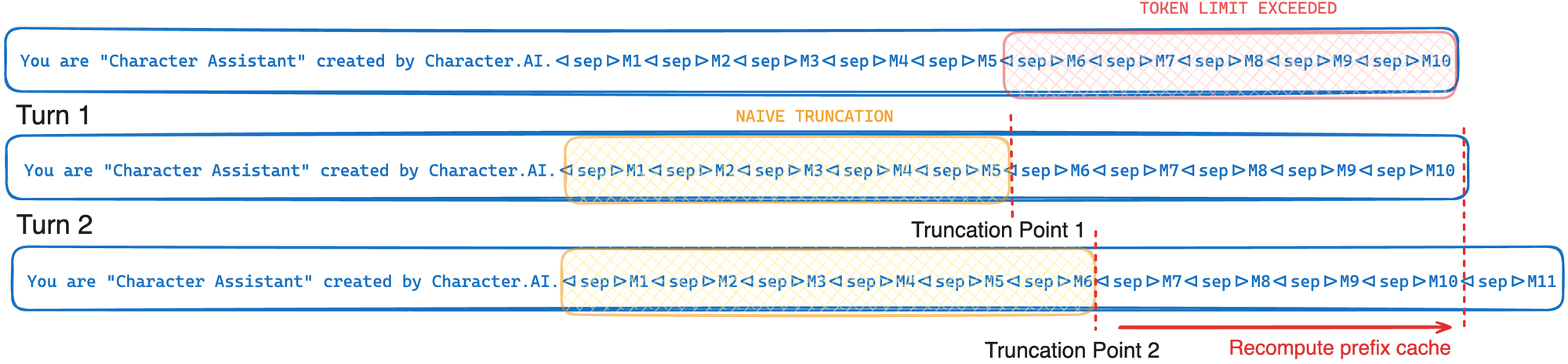
缓存意识截断
Character.AI 的缓存意识截断算法在每 k 次循环中截断到相同的固定截断点。这意味着直到最近的消息,token 序列保持不变,从而使我们能够重用前一轮 GPU 前缀缓存中存储的计算。请注意,k 不是直接可控的,而是截断步骤和每条消息被截断的平均 token 数的函数。
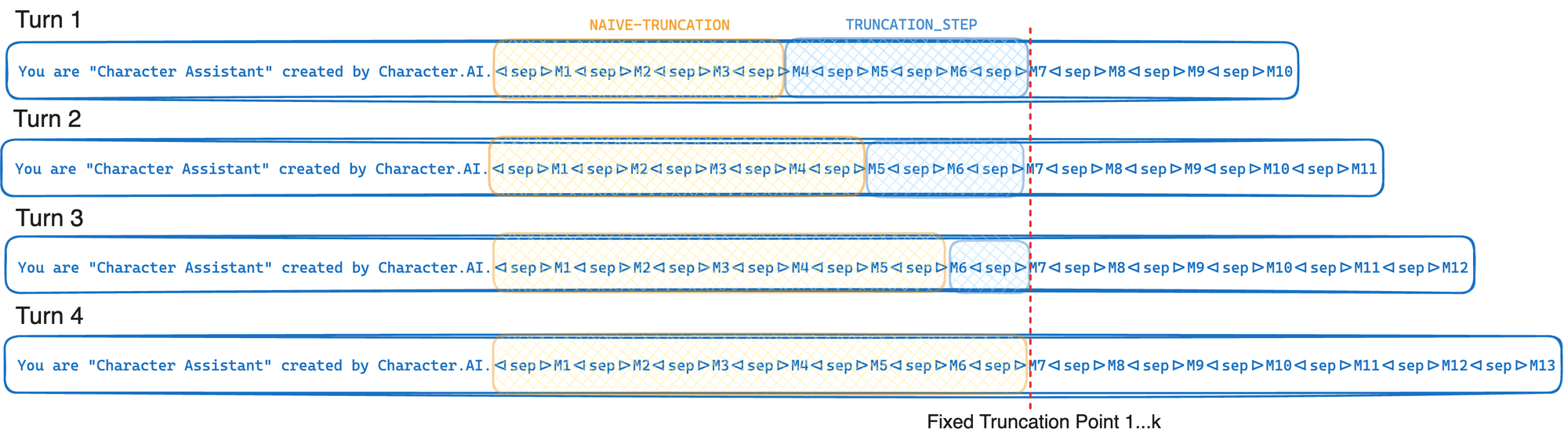
结论
Prompt Poet 在提示词工程领域代表了显著的进步,将重点从繁琐的手动字符串操作转移到更简化和直观的设计导向方法。通过借鉴 UI 设计原则并将其应用于提示词构建,这个工具简化了复杂和个性化提示词的创建,提高了用户和 AI 模型之间互动的质量。
借助 Prompt Poet,开发人员和非技术用户都能更多地关注提示词设计而不是提示词工程。这种设计优于工程的转变有可能重新塑造我们与 AI 的互动方式,使这些互动更高效、更直观、更符合用户需求。随着我们继续探索大语言模型的能力并扩大其应用范围,像 Prompt Poet 这样的工具将在以用户为中心的方式充分利用其潜力方面发挥关键作用。
相关工作
- Priompt: Priompt(优先级 + 提示词)是一个基于 JSX 的提示词库。它通过优先级来决定在上下文窗口中包含的内容。这个项目达到了类似的目标,即将模板层与逻辑构建层分离,并且与 TypeScript 的用法兼容。
- dspy: 提供了一种自动优化不同模型提示词的好方法,但缺乏对提示词的确定性控制,这对于缓存和高吞吐量、低延迟的生产系统来说非常重要。
- Prompt Engine: 这个 TypeScript 包源于一个常见问题,即生产提示词工程需要大量代码来操作和更新字符串。它为提示词模板化过程增加了结构,尽管看起来有些主观,基于使用场景做出了一些假设。由于最后一次提交是在两年前,似乎这个包没有在积极开发中。
- llm: 允许在 YAML 中定义基本提示词,并启用像动态控制流、函数调用和数据绑定等 Jinja2 特性。
- 原生 Python f-strings:有几个项目通过包装 f-strings 采取了不同的提示词模板化方法:
- LangChain: LangChain 的范围远大于提示词模板化,虽然它确实提供了一些基本的模板抽象。适用于简单的模板化使用场景,但随着提示词复杂性的增加会变得难以管理。
- LlamaIndex: 类似 LangChain,LlamaIndex 的范围也远大于提示词模板化,尽管它也提供了一些基本的模板抽象。
- Mirascope: 通过将所有内容封装在一个 Python 类中,并使用类的文档字符串作为绑定数据的 f-string,实现了一种新颖的提示词模板化方法。