DeepSeek 创始人梁文锋:颠覆AI世界的技术狂人,正威胁美国在 AI 竞赛中的主导地位
这家公司突然崛起,说明尽管华盛顿努力放缓中国脚步,但中国的行业依旧蓬勃发展。

梁文峰身材瘦削,作风谨慎,在会议上有时显得腼腆、甚至紧张。作为最近在全球人工智能领域掀起波澜的中国初创公司 DeepSeek 的创始人,他常常在说话时语速不快,也会出现长时间的沉默。然而,新入职的员工很快就会明白,他的低调思考并不代表胆怯。一旦梁理解了讨论的要点,他就会抛出那些关于模型架构、计算成本,以及 DeepSeek AI 系统各种细节的精准而难以作答的问题。
员工们称呼梁为“老板”(lǎo bǎn),这在中国是对商业上级的一种常见尊称。只不过,不常见的是,他这位“老板”让年轻研究人员,甚至实习生都能承担重大实验项目,并经常亲自到工位了解进展,鼓励他们探索各种非常规的工程思路。技术层面的交流越深入,他就越兴奋,尤其是那些能带来实际性能提升的突破——而梁会在内部的 Lark(飞书)聊天频道上亲自分享这些里程碑。“他是个真正的极客(nerd)。”一位前 DeepSeek 员工如此评价。与本文对话的大多数受访者都因未被授权公开发言而要求匿名。“有时,我觉得他对研究的理解程度比研究人员本身还要深。”
今年 1 月,DeepSeek 发布 R1,这家年轻公司一跃成为全球焦点。R1 的各项指标在多项常用于衡量 AI 性能的标准测试中击败了西方占主导地位的产品,而 DeepSeek 声称其基础模型的训练成本仅为 OpenAI 的 ChatGPT 所使用 GPT-4 估算成本的约 5%。
这些测试结果引发了美国市场 1 万亿美元的抛售风潮,并让美国试图以出口管制来放缓中国 AI 发展战略的效果产生了巨大疑问。亚马逊和微软争相将 DeepSeek 的模型纳入云端服务,与 Meta 和 Mistral AI 等公司的竞争产品并列。亚马逊公司语言模型市场负责人阿图尔·德奥(Atul Deo)表示:“差不多一夜之间,DeepSeek 就获得了如此大的关注度,我们立即行动了。”
DeepSeek 的出现,让美国人对中国 AI 领域“雾里看花”的印象得到改观:之前,这种模糊感常被用来轻视或夸大中国威胁,但其实它很可能比美国想象中更具挑战性。在 DeepSeek 崛起之前,美国许多企业和政策制定者都抱持一种舒适的观点:认为中国在技术上仍大幅落后于硅谷,美国依旧有时间来准备应对对方最终赶上,甚至阻止中国 AI 追平美国。
美国在 AI 投资中占据主导地位 ...
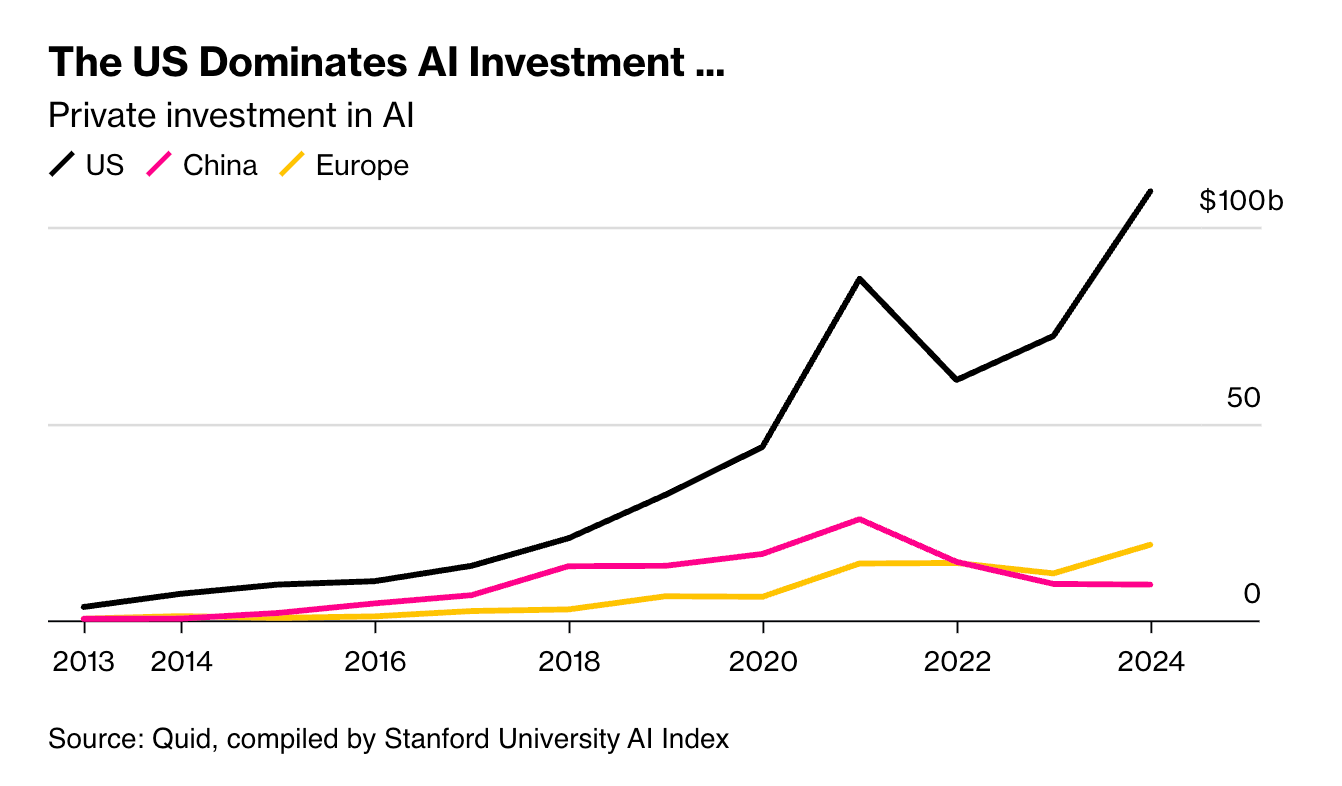
真正的情况是,DeepSeek 总部所在的杭州,以及其他中国高科技中心,都在孵化着“AI 小龙”(AI 初创公司在中国常被这样形容)。来自本土初创公司 MiniMax 和 Moonshot AI 等的高度智能化聊天机器人已在国内外(包括美国)迅速走红。阿里巴巴集团的 Qwen 系列大语言模型在各大榜单中一直位于领先位置,与谷歌和 Anthropic 的同类产品竞争;百度公司首席执行官李彦宏在 4 月宣称,凭借其新推出的自主研发芯片组成的超级计算机,百度可以训练出与 DeepSeek 同等水平,但成本更低 的模型。与此同时,华为公司在为其自主研发的与英伟达 GPU 相抗衡的设备上也颇受好评,这些 GPU 在欧美通常是驱动最顶尖 AI 模型的关键硬件。
... 但中国技术正在迅速赶上
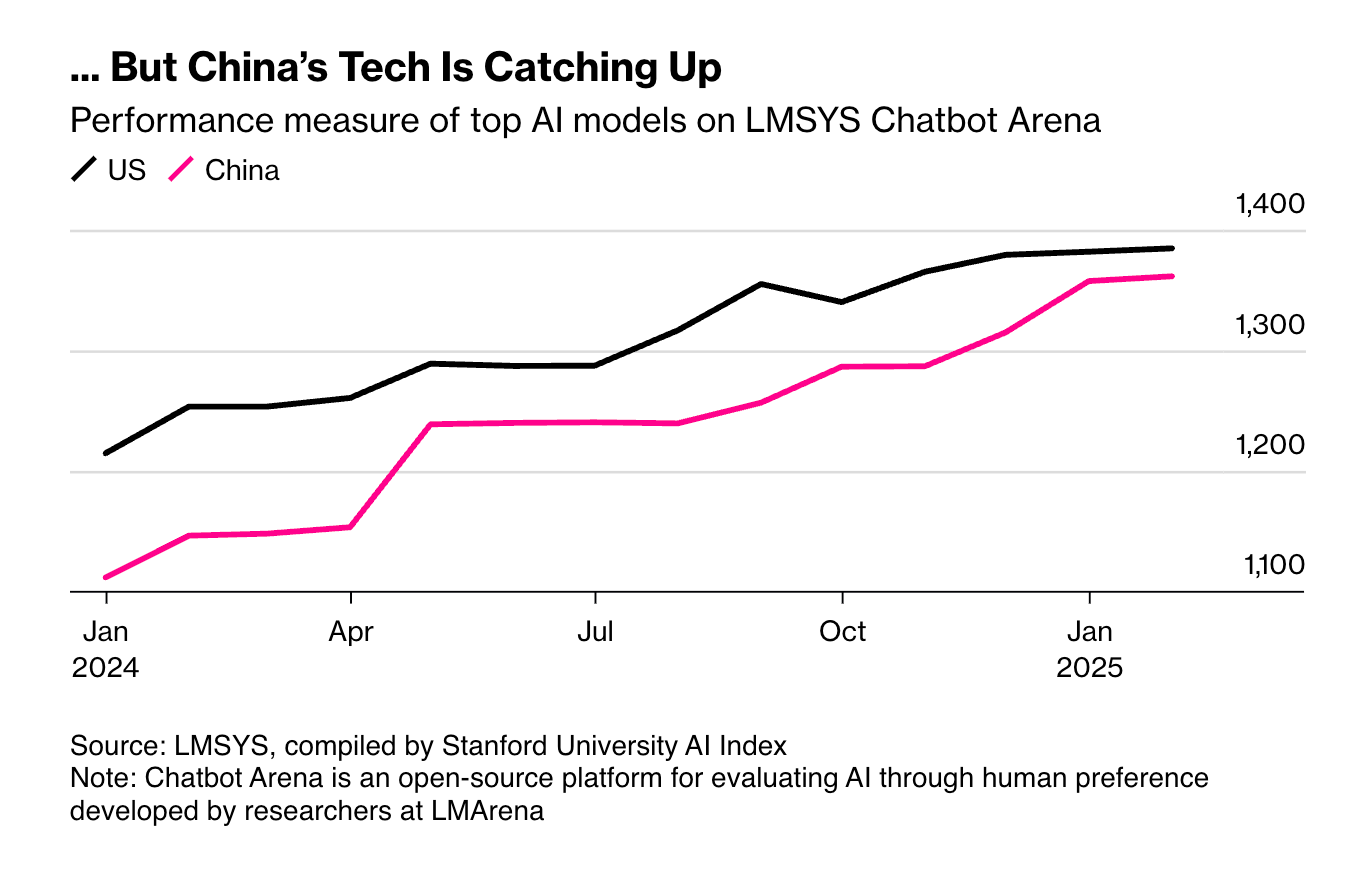
注:Chatbot Arena 是由 LMArena 研究人员开发的开源平台,用于通过人类偏好来评估 AI
不久之前,中国共产党还在整顿那些自认为失控的科技巨头,对它们进行反垄断调查和数据合规审查,像阿里巴巴联合创始人马云这样的知名人士一度淡出公众视野,并对社交媒体、零工经济以及游戏行业制定了新规则。然而,现在面临外部干扰之际,中共开始扶持国内科技产业。习近平主席在大力投入 AI 和半导体领域,号召打造“自主可控、协同高效”的软硬件生态。
令人意外的是,地缘政治的掣肘本想阻碍中国 AI 进展,却在一定程度上激发了技术突破。调研机构 Counterpoint Technology Market Research 的分析师孙伟(音)表示,美国与中国在 AI 领域的差距现已缩小到以“数月”为单位,而非“数年”。“中国在协同作战及高强度工作方面的集体精神非常突出,这带来了执行力上的优势,”他补充说,美国对英伟达芯片的出口管制导致了意料之外的创新。“在这种生存压力下,适者生存:能用更少资源做更多事的,就能胜出。”
在中国看来,自己在推动创新,而在美国许多人眼里,DeepSeek 依旧存在可疑之处。今年 4 月,美国众议院一个两党委员会在一份报告中声称 DeepSeek 与中国政府存在“重大”联系,指控其非法窃取 OpenAI 数据,对美国国家安全构成“深远威胁”。Anthropic 首席执行官达里奥·阿莫德(Dario Amodei)在一篇长达 3,400 字的博客文章中主张加强美国的出口管制,称 DeepSeek 必然是通过地下途径大规模购买英伟达 GPU,包括最先进的 H100。彭博新闻社此前也报道称,美国官员正在调查 DeepSeek 是否绕过出口限制,通过新加坡的第三方采购被禁止出口的芯片。

中国驻美国大使馆驳斥了众议院委员会的指控,称其“毫无根据”。英伟达则表示,为 DeepSeek 提供的芯片均符合出口规定,并警告更多的限制只会进一步推动中国企业自研芯片。英伟达的发言人称,若 DeepSeek 被迫更多使用本土芯片和服务,“这只会让华为等中国或其他地区的 AI 基础设施供应商受益。”
陷于争议中心的 DeepSeek 自己则像谜一样——它一方面宣称以开源方式共享其 AI 技术,另一方面又对其内部运作或意图讳莫如深。它在公开论文中会披露极为具体的技术细节,但对训练 AI 的总体花费、GPU 的具体配置或数据来源等基础信息却少有表态。
“我们并不知道 DeepSeek 的真实动机是什么,这公司是个十足的‘黑箱’。”
梁文峰本人以孤僻闻名,中国 AI 圈里有人私下称他“科技疯子”,类比用于形容那些拥有远大抱负、行事怪异的企业家。他近 10 个月几乎未接受过任何媒体采访,直到最近在与中国国务院总理李强会谈时拍到的一张合照,他那副带着眼镜、看起来仍带几分稚气的面孔才正式曝光。梁和他的同事并未回复本文采访请求,只有一名员工的自动回复称询问“正在处理中”,并在邮件末尾补上一句“感谢您对 DeepSeek 的关注与支持!”

为更好地理解这家公司如何运作,以及它在中国更广泛的 AI 抱负中扮演何种角色,《彭博商业周刊》采访了 11 位曾在梁麾下工作的人,以及三十多位与中国 AI 行业关系紧密的分析师、风投人士和高管。
梁对外界保持低调,也让 Anthropic 的阿莫德、OpenAI 的萨姆·阿尔特曼(Sam Altman)等人可以在美国受众心中塑造 DeepSeek 的阴影形象。但即便那些对 DeepSeek 保持怀疑的人也不得不承认它在 AI 技术上的强大实力。Perplexity AI Inc. 的首席商务官迪米特里·谢韦连科(Dmitry Shevelenko)表示,他们公司主要做 AI 搜索,没有任何人能与 DeepSeek 的相关人员取得联系,但 Perplexity 依旧在使用 DeepSeek 的技术,并将其部署在只位于美国和欧洲的服务器上,且在后期训练中屏蔽了可能的政治审查数据。Perplexity 将该版本称为 R1 1776(指美国建国年份),谢韦连科称这是对自由精神的致敬。“我们并不知道 DeepSeek 的真实动机,”他说,“这个公司就是个黑箱。”
DeepSeek 对海外可能出现的疑虑其实早有预料。2024 年 3 月,在英伟达开发者大会上的一次不太受关注的线上演讲中,DeepSeek 的深度学习研究员陈德力(音)就提到,要让价值观与大语言模型“脱钩”,以便适应不同社会环境。他展示了一页带有冰冷理性逻辑的 PPT,提到 DeepSeek 当时的一个原型如何能够针对不同人群快速配置聊天机器人内置的伦理标准。只需点几下按钮,就能设置包括赌博、安乐死、性工作、枪支所有权、大麻和代孕等各种议题在不同地区法律框架下的合法性。“开发者只需选取符合他们需求的选项,就能获得适合他们价值观的模型服务,”陈说道。
在 DeepSeek,寻找高效变通方法一直是文化常态。梁及其朋友在 2000 年代中后期就读于浙江大学,主修机器学习、信号处理、电子工程等专业,他们也曾为好玩(当然也为了赚钱)在全球金融危机期间开发股票交易程序。
中国 AI 革命的构建者
毕业后,梁继续独自研究量化交易系统,攒下了一笔不小的财富,后来与数名浙大校友在杭州合伙成立了后来被称为 High‑Flyer Quant 的量化基金公司,时间约在 2015 年。
早期招聘信息宣传,高薪吸引到谷歌与 Facebook 资深人才,目标是寻找具备谢尔顿(美剧《生活大爆炸》的主角)式“怪才”的数学及编程“极客”,承诺免费零食、Herman Miller 椅子、扑克之夜,营造一种穿 T 恤与拖鞋也被接纳的办公室文化,还带点金融圈的氛围:“你可以与 90 后软妹以及归国华尔街投资女神并肩共事”。

与如今的 DeepSeek 类似,High-Flyer 当时也带着一股神秘感——最初在社交媒体上仅称梁为“L 先生”——但同时又秉承“看我实力说话”的透明风格。每逢周五,High-Flyer 都会在微信上公开其最初 10 只基金的表现图表。直到 2016 年夏季开始仅向注册投资者提供,该基金当时平均年化收益达 35%。
随着大量资金涌入,High-Flyer 的资产管理规模达数十亿美元,研究团队也扩张到 100 多人。到 2019 年,梁开始大幅招聘 AI 人才,目标是通过挖掘庞大的数据集来选择价值被低估的股票,进行高频交易和宏观趋势判断——这类其他投资策略公司也常用的方式。但 High-Flyer 的关键在于它在疫情爆发前就建成了一个高性能计算集群,由多块 GPU 并行运行。该公司表示,为这个集群最初配备了 1000 块 Nvidia 2080Ti 和 100 块 Volta 系列 GPU(后者即 V100)。相比原先在更小集群上训练新经济模型需要两个月,这套新系统只需不到四天就可完成相同量的工作。
这些金融模型已经算出色,但与当时美国的 OpenAI 等致力于通用型模型的机构相比,规模还远远不够。梁推动再建更大规模的超级计算机集群,采用 Nvidia 当时新出的 A100 GPU(其对 V100 的升级版)。一名曾参与此项目的前 High-Flyer 工程师回忆,梁是使用该集群最频繁的人,估计 80% 的训练量都在他账户名下运行。这位工程师称,梁对深度学习“几近痴迷”,笑称这是他“烧钱的爱好”。一位量化基金老板往 AI 基础设施投入数亿美元或许有些“过度”,但梁显然有足够利润来支撑。“对他来说,算是小钱了,”工程师说,“算力越多,模型越好,交易收益越高。”
或许期待过高,High-Flyer 管理规模在 2021 年 12 月接近 141 亿美元时,该基金通过一封公开信向投资者道歉,承认业绩表现欠佳。公司解释,AI 系统虽然能挑到好的标的,但在疫情期间的市场波动中,卖出时机把握不够精确。即便如此,High-Flyer 仍然打算继续加大 AI 投入:2022 年 1 月,该公司在社交媒体上宣布自己拥有了 5,000 块英伟达 A100;到 3 月又宣布增加到 10,000 块,而当年 9 月英伟达就已警告美国政府或对中国出口该芯片施加新限制。
目前尚不清楚这些计算资源中有多少真正用于量化交易,多少其实是梁的“烧钱 AI 爱好”。在 ChatGPT 发布仅五个月后的次年春天,梁将 DeepSeek 独立拆分出来,成为一家专注于研究的实验室,办公地点分别设在杭州与北京,已与财务业务彻底剥离。在一篇未署名的宣言中,High-Flyer 宣称要拒绝平庸,攻克 AI 革命中最困难的挑战,目标直指通用人工智能(AGI)。

整个 2023 年,DeepSeek 实验室竞相研发 AI 辅助写代码工具、通用聊天机器人以及文本生成 3D 图像工具。梁将一些 High-Flyer 员工带到 DeepSeek,并从微软(北京)等国内科技公司和高校挖来更多工程师。2023 年 9 月加入的实习研究员刘博(音,英文名 Benjamin)表示,梁常把非常重要的任务交给实习生,这在其他地方通常会由资深员工承担。“就拿我来说:我去那儿的时候,还没人做 RLHF(基于人类反馈的强化学习)基础架构,他就让我上手干了。”刘说,“只要是没人干过的事,他就会信任你去做。”(这种信任对 DeepSeek 也有收益:实习生日薪大约 140 美元,另加 420 美元住房补贴——在中国算是不错,但只相当于美国 AI 公司实习生收入的三分之一,与硅谷全职工程师的收入更是天差地别。)
梁非常早就大力押注稀疏性(sparsity)技术,即把大语言模型分解为若干专门领域,以更高效率来训练和运行。据两名前 DeepSeek 研究员介绍,最初版本的 ChatGPT 在回应 2+2 这类简单问题,或提供馅饼食谱这样的问题时,都会调用其整个大语言模型的“全脑”,而一个稀疏模型只会调用最相关的“专家部分”,使资源利用更加高效。
稀疏化方法可以显著节约计算成本,但实现起来非常复杂。如果一个问题被分配到的“脑区”太少,或分配错误,就会导致答案质量下降。(比如数学专家知道如何运用圆周率 π,但并不掌握馅饼的烹饪配方。)梁从谷歌和法国初创独角兽 Mistral 的研究中看到这类进展。Mistral 在 2023 年 12 月发布了一个带有 8 个“专家”模块的稀疏模型,每个提问只调用与上下文最匹配的 2 个模块。他于是要求团队不断增大模型专家数量。然而,这种做法可能带来严重的混淆和知识分裂问题。“内部为此也争论了很久。”那位前员工如此回忆。
随后,DeepSeek 不断取得新突破——每次在公开场合分享,也越发引起中国业界注意。到 2024 年底,DeepSeek 发布了 V3——一个通用 AI 模型,规模比当时最大的开源大语言模型(Meta 的产品)还大约大了 65%。然而比起这个模型本身,更令谷歌、OpenAI、微软等管理层震撼的是 DeepSeek 同时发布的一篇冗长的 V3 研究报告。其中一个惊人的数据是:DeepSeek 暗示 V3 的整体开发成本仅约 560 万美元——很多人将这一数值理解成“从头到尾的总成本”,觉得不可思议。相比之下,欧美一些顶尖前沿大模型的累计训练费用高达上亿美元。Anthropic 的阿莫德(在 DeepSeek 出现前)甚至预测下一代模型的训练成本将在 100 亿到 1000 亿美元之间。
Hugging Face Inc.(一个流行 AI 平台)研究负责人利安德罗·冯·韦拉(Leandro von Werra)表示,DeepSeek 的“架构创新”并不是最让人意外的地方,他在那篇论文里看到的最大亮点是 DeepSeek 可能拥有非常优质的数据——无论是从网络巧妙筛选的,还是通过别的方式获取的——才可能让 V3 的性能如此突出。他说:“如果没有高质量的数据集,模型表现不可能这么好。可那篇报告只用 50 页中的半页来介绍它的数据集。”
DeepSeek 高调展示自己进展的动机,部分原因在于梁坚信开源思维对公司战略至关重要。他认为,美国顶尖实验室(OpenAI、谷歌等)那种封闭且收费的模式只会带来短期收益,不能带来更长远的成功。把自己的模型完整公开、免费提供给公众,才能最快地获得应用落地和开发者反馈,从而形成正向循环。DeepSeek 在两年前发布其首款公开大语言模型时就引用了 Linux 之父的名言:“少说废话,拿代码来。”
“简单来说,他们不缺钱。因为‘六小龙’吸足了眼球,各路人都在抢着投。”
四月一个阴天的周日,在杭州萧山国际机场繁忙的到达大厅里,阿里巴巴、字节跳动、华为等公司的 AI 广告屏目不暇接。一台留着蓝色头发的仿人机器人在航站楼迎接乘客,机场外有家初创企业正在测试小型无人驾驶货车,在停机坪运送行李。这就是当下杭州 AI 繁荣的缩影,而西方只聚焦 DeepSeek,却往往忽视这里还有很多“AI 小龙”。
在风景如画的西湖区,就有 Game Science 这样凭借《黑神话:悟空》 一炮而红的游戏公司,它在游戏中使用机器学习技术让角色更加逼真。附近还有两家机器人公司和一家 3D 空间软件独角兽企业。再者就是浙江强脑科技(BrainCo),在美国常被视作“中国版 Neuralink”,它可追溯到哈佛大学时期一位中国留学生韩壁成(音)的创业项目,如今在杭州也有一个实验室,主要研发仿生手臂与人脑活动操控计算机的技术。BrainCo 的 AI 驱动仿生手目前在位于“杭州中国人工智能小镇”某展馆中展出。
最近几周,BrainCo 领导们为一些参观团做了讲解,据知情者称,来访者纷纷想投资,可见他们也并不急需资金。“简单来说,他们不缺钱,”一位基金经理听完介绍后说,“‘六小龙’太火,投资人都挤破头想投。”
在这些初创公司背后,站着的是国家主席习近平领导下的中国政府。生成式 AI、机器人等尖端技术成了国家战略部署重点,核心是所谓的“自立自强”。官方新华社报道称,习近平在最近一次政治局会议上提到,要“坚定不移打好关键核心技术攻坚战”,他强调,“要正视差距,加快推动技术创新、产业发展和 AI 的赋能应用。”
至于这些“AI 小龙”们,早已开始行动,而且早已不是小规模。市值 3000 亿美元的阿里巴巴集团总部坐落在杭州一个广袤的园区,里面还有一个人工湖。该公司近日宣布未来三年将斥资 530 亿美元建设更多数据中心,同时表示其最新主打模型 Qwen3 在性能与成本效率上均可与 DeepSeek 一决高下。自 2022 年将云业务拆分成独立园区后,阿里巴巴在杭州西郊的办公楼里设有会议室,墙面大屏每 72 小时更新一次行业情报,包括 DeepSeek、OpenAI 等竞争对手的动态。甚至在卫生间里都能看到每周更新的“小黑板”,提醒从业人员:AI 竞赛无处不在。
中国的 DeepSeek 是如何挑战 AI 巨头的
今年 4 月,几乎淡出公众视野近五年的马云现身阿里巴巴园区,参加云计算业务成立 15 周年庆活动。他在罕见的讲话中称,希望 AI 成为人的帮手,而非统治者,据多位听过直播的人士表示,阿里香港和东京办公室也同时观看了。现场气氛热烈,大家都为马云的回归而兴奋。
这也暗示了中国政府对 DeepSeek 及马云这样的人才重新释出好感,而美国的科技领袖们则在国内面临越来越多质疑。中国正在形成一种民族自豪感,想向世界证明即便受到外部干扰也能突围。亚洲政策咨询机构 Asia Group LLC 驻香港董事总经理陈乔治(音)说,大批中国工程师从苹果、谷歌、微软等美国公司的海外岗位回流,部分因为特朗普政府对华态度强硬,也因为他们觉得“真正的风口”也许已在东方。“硅谷对中国人才而言,吸引力正在下降。”
另一家中国独角兽 01.AI 的创始人李开复则进一步表示,他本人曾在苹果、谷歌、微软都工作过,但现在的新一代中国工程师通常不会再走这条去美国公司历练、再回国创业的老路。“这些年轻 AI 工程师几乎都在国内培养,”李说,“DeepSeek 的成功和其他新兴 AI 公司一起,让更多年轻人更想加入中国 AI 的复兴浪潮。”

当下在中国,没有哪家科技企业比 DeepSeek 更能激发人们的热情。4 月时,加拿大华裔计算机科学家方克比(音,Kirby Fung)带着家人来到杭州旅游,特意前往梁就读的浙江大学参观。他曾在浙大交换过,想让爷爷奶奶和弟弟看看自己曾学习的地方,也是“DeepSeek 老板”的母校。“跟加拿大那边的朋友说,我和这个做 DeepSeek 的人在同一学校上过课,感觉很酷。”方说。
也有游客和自媒体博主不时造访 DeepSeek 的总部大楼,那是位于杭州城北一带的大运河边四栋塔楼综合体。他们会在大楼里的高级火锅店(DeepSeek 员工偶尔会去)尝试找梁,可惜餐厅服务员无奈地说,梁从未出现过。
熟悉梁的人说,他在杭州与北京两地办公室来回奔波。在北京,DeepSeek 办公室位于一幢玻璃幕墙大厦五层,周围也是高科技企业云集。那儿的年轻程序员们常常伏案于可升降的办公桌,茶水间摆满了能量饮料、康师傅方便面和辣条。白板上专门留给员工写想吃的新零食。“我在那里连续几个月每天都吃午饭和晚饭,胖了不少,”一位离职研究员笑称。
梁极少与外界接触,即使有时也会以全息影像的方式现身会议。他拒绝参加今年在巴黎举办的关键 AI 行动峰会,那场活动吸引了 OpenAI 的阿尔特曼、Alphabet/谷歌 CEO 桑达尔·皮查伊,以及一些国家总理和总统。
在中国,DeepSeek 被奉为创新典范;在美国,它却被视为在水源中突然出现的陌生有机物,人们在试图判断它是无害还是有毒。批评者指责 DeepSeek 受中共控制、窃取美国同行数据训练模型,或将它与更大规模的间谍或认知战联系起来。美国众议院调查 DeepSeek 的委员会发言人称:“DeepSeek 就像一道直通中国共产党监控系统的管道,不仅威胁美国公民隐私,也危及国家安全。”
而 DeepSeek 自我定位则跟一般初创公司并无不同——在 X(原推特)上自诩“纯正车库精神”,并指出它的北京办公室就在谷歌旁边,附近还有汉堡王和两家 Tim Hortons。有人说,之所以美国 AI 界先前没注意到 DeepSeek,只是因为“我们没看见不代表人家没进展”。Alpha Intelligence Capital(投资了 OpenAI 和商汤)合伙人阿尔诺·巴特勒米(Arnaud Barthelemy)说:“AI 世界不该对 DeepSeek 感到意外,他们的出现其实在意料之中。”
巴特勒米认为 DeepSeek 真正给行业上的启示在于:中国科技公司在受限环境下能将压力转化为研发动力。“有大量聪明大脑在中国,用更低的算力做出了更优的创新。”

英伟达 CEO 黄仁勋(Jensen Huang)在 2023 年 5 月接受《商业周刊》采访时就曾说,美国若在对华输出高科技上持续收紧,只会倒逼中国更加创新。他强调,经济影响力是国家安全有效工具,政府管控可能带来严重后果。“失去科技业三分之一的市场绝对是灾难性的,”他指的是限制对华出口的影响。“他们将会在没有竞争的环境里蓬勃发展,然后把产品出口到欧洲、东南亚。”
“你必须谨慎对待竞争强度,”黄继续说,“一旦把对手逼到无路可退,他们会采取不可预测的反击。那些‘一无所有’的企业会采取出乎意料的方式应对。”

有人仍怀疑 DeepSeek 训练模型的真实花费到底有多少。美国研究机构 SemiAnalysis 的报告 称,High-Flyer 与 DeepSeek 可能秘密拥有约 5 万块英伟达 H 系列顶级 GPU,总值约 14 亿美元,并且一直对外界保密。这其中包括美国允许英伟达向中国出售的经过性能限制的 H20、H800 等改版芯片,但该机构还声称 DeepSeek 另外拥有 1 万块英伟达最先进的 H100 芯片,而美国政府已禁止将 H100 销售给中国。
三位曾在 DeepSeek 工作的人士对此表示强烈否认,称 DeepSeek 的 GPU 数量不到 2 万,且主要是旧款芯片和少量受管制产品。“他们在散布谎言,”Ph.D. 学生刘博说。SemiAnalysis 坚称自己报告无误。
DeepSeek 是否渴望拥有美国科技公司那种规模的算力,这毫无疑问。这家公司似乎自信,假如真有那么强大的资源,自己能比硅谷做得更多。“大语言模型研究人员对计算资源的需求都非常庞大,如果我有数万块英伟达 H 系列 GPU,或许也会挥霍,做很多未必必要的实验,”一名前 DeepSeek 员工说。但对中国的技术人员来说,“资源不足”的问题解决后,也许能带来更多惊喜。“真希望我们中国公司哪天真能搞到 5 万块 GPU,”这位前员工表示,如今他已跳槽到北京另一家开源 AI 实验室。“到时候看我们能做出什么?”
——文:奥斯汀·卡尔(Austin Carr)、萨丽莎·莱(Saritha Rai) 和 黄哲苹(Zheping Huang),并有 Luz Ding、Claire Che、Matt Day 和 Jackie Davalos 贡献报道