谷歌 Deepmind 发布首个生成式交互环境模型 Genie [译]
我非常激动地分享 @Google DeepMind 开放创新团队的最新进展 🚀。我们推出了 Genie 🧞,这是一个从互联网视频中学习而来的创新世界模型,能够根据图像提示创造出无限种可操作的 2D 世界。
与其加入先验偏见,我们更加注重扩大规模。我们利用了一个包含超过 20 万小时的 2D 平台游戏视频的巨大数据集,训练出了一个拥有 110 亿参数的世界模型。Genie 能够以无监督的方式学习各种潜在动作,从而以一种连贯的方式控制角色。
我们的模型能够将任意图像转化为一个可以互动的 2D 世界。例如,Genie 能够赋予人类设计的草图新的生命,就像来自两位史上最年轻的世界创造者 Seneca 和 Caspian 的精美艺术作品一样。
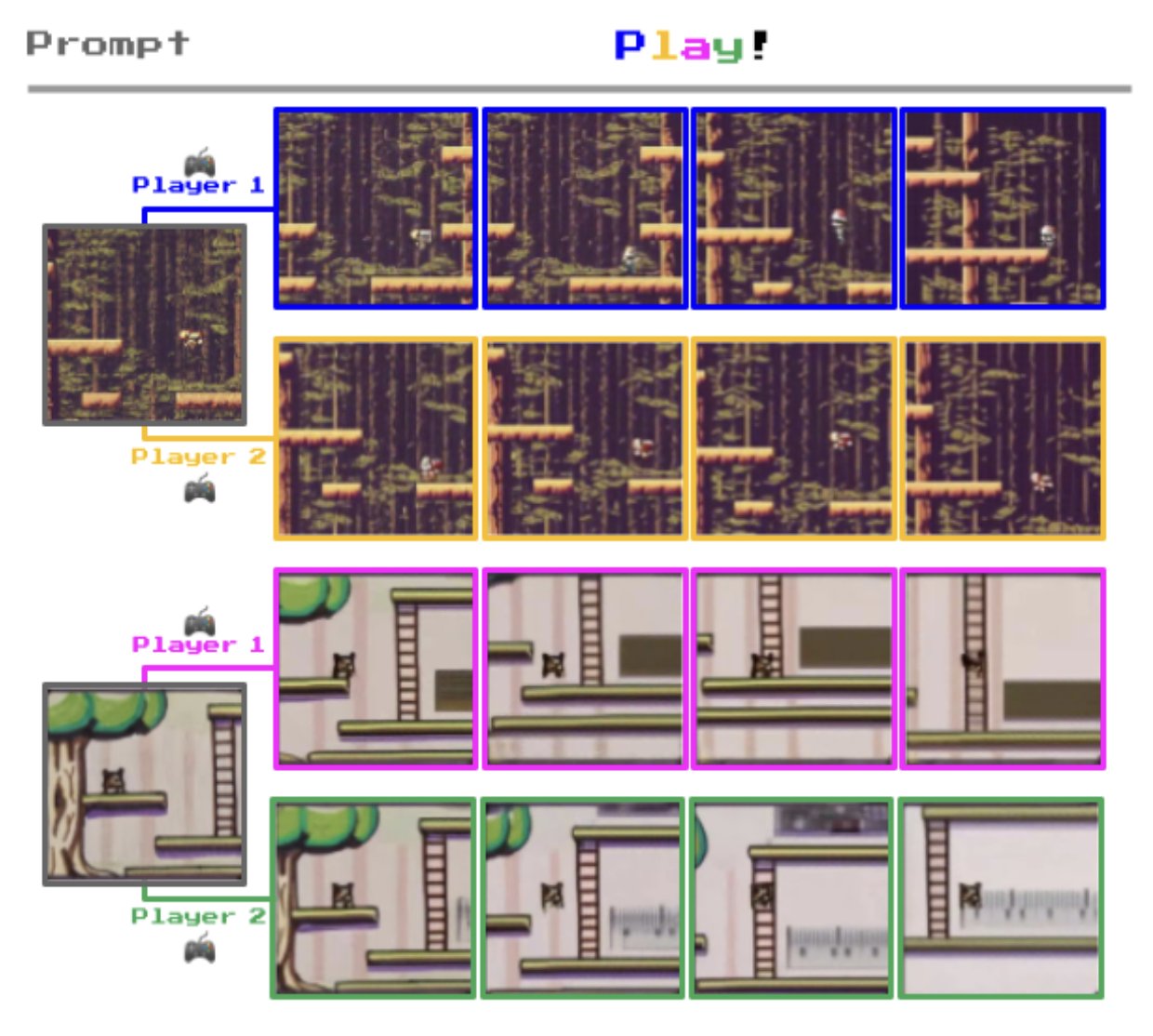
Genie 学习到的动作空间不仅丰富多彩、一致性强,还易于理解。人们在尝试几次后,通常能够将其与具有语义意义的动作(比如向左走、向右走、跳跃等)相对应。
必须承认,@OpenAI 的 Sora 实在是太震撼了,其视觉效果令人赞叹,但正如 @yanlecun 所强调的,一个世界模型必须要有“动作”才行。Genie 不仅是一个能够控制动作的世界模型,而且它是完全通过视频学习而来的,不依赖任何监督。那我们是怎么做到的呢?
关于什么是世界模型,人们有许多不同的理解。以下是我的定义:
考虑以下几点:
- 观测值 x(t)
- 对世界状态的先前估计 s(t)
- 行动建议 a(t)
- 潜在变量建议 z(t)
世界模型的计算过程如下:
- 表征:h(t) = 编码器 (Enc)(x(t))
- 预测:下一状态 s(t+1) = 预测器 (Pred)(h(t), s(t), z(t), a(t))
其中:
- 编码器 (Enc) 是一种编码功能(可训练的确定性函数,如神经网络)
- 预测器 (Pred) 负责预测隐藏状态(同样是可训练的确定性函数)
- 潜在变量 z(t) 代表能够精确预测未来发生事件的未知信息。它需要从一定的分布中采样或在一定集合中变动,为一系列可能的预测设定参数。
关键在于,通过观察三元组 (x(t), a(t), x(t+1)) 来训练整个模型,同时避免编码器退化到一个忽略输入的简单解决方案。
在自回归生成模型(如大语言模型 LLMs)中,情况稍微简单些,其中:
- 编码器是恒等函数:h(t) = x(t)
- 状态是过去输入的序列
- 不包含行动变量 a(t)
- x(t) 是离散的
- 预测器计算下一状态 x(t+1) 的可能结果,并利用潜变量 z(t) 从中选择一个具体值。
这种情况下的方程简化为:
s(t) = [x(t), x(t-1), ..., x(t-k)]
x(t+1) = 预测器 (Pred)(s(t), z(t), a(t))
在这种情况下,不会出现退化问题。-- BY Yann LeCun @ylecun https://twitter.com/ylecun/status/1759933365241921817
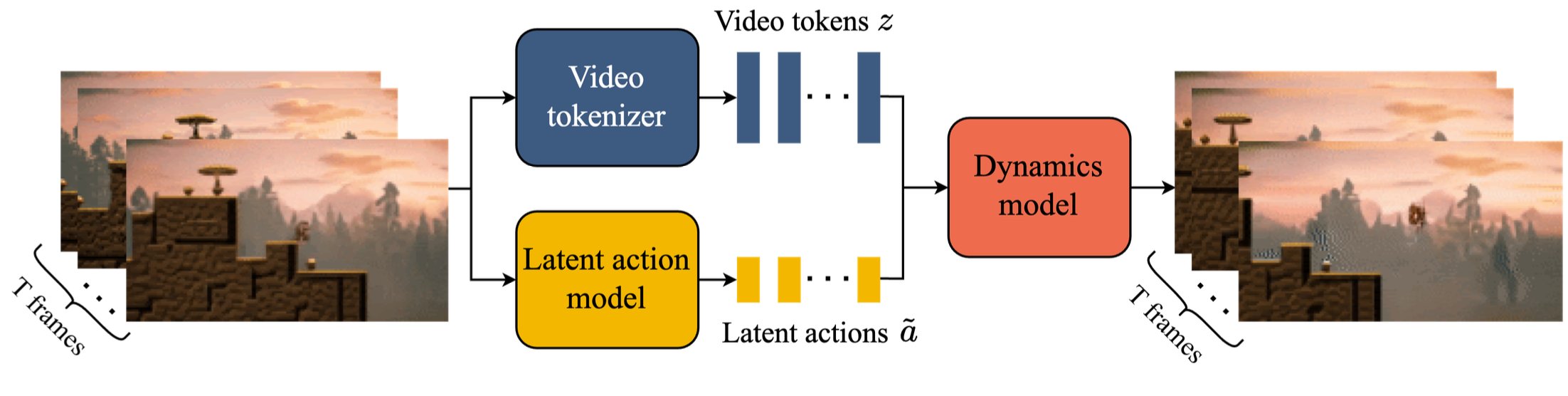
我们开发了一种具备时间感知能力的视频分词器,它能将视频压缩成离散标记,采用一个潜在行动模型来描述两帧之间的转换,这一转换被编码为八种潜在行动之一,以及一个 MaskGIT 动力学模型来预测未来的帧。
这里的关键还是数据和计算能力!我们训练了一个分类器,以筛选出高质量的视频子集,并进行了规模实验,结果显示模型性能随着参数数量和批次大小的增加而稳定提升。我们最终的模型达到了 110 亿参数量。

Genie 的模型具有广泛的通用性,不仅仅局限于二维空间。我们还对机器人数据集 (RT-1) 进行了 Genie 训练,尽管其中不包含任何具体的动作数据,我们也成功展示了如何学习到一个可以控制动作的仿真器。我们认为,这是向着为通用人工智能 (AGI) 构建全面世界模型迈出的一大步。
Genie 项目是一个由 Jake Bruce、Michael Dennis、Ashley Edwards、Jack Parker-Holder、Yuge Shi (Jimmy)、Edward Hughes、Matthew Lai、Aditi Mavalankar、Richie Steigerwald 等人共同努力的成果,是一个团队协作的典范。
特别感谢 Ashley、Jack 和 Jake 在项目中展现出的杰出领导力!如果您对 Genie 有进一步的兴趣,欢迎查阅我们的论文和官网。详见下方链接:
