Chess-GPT 的内部世界模型 [译]
Chess-GPT 的线性递进世界观
引言
在机器学习 (ML) 的众多近期进展中,有两个特别吸引我的。第一个是 gpt-3.5-turbo-instruct 在国际象棋中达到 1800 ELO 水平。一个大语言模型 (LLM) 能够仅凭网络上随机抓取的文本就学会下好棋,这似乎不可思议。第二个是 Kenneth Li 的论文《生成世界表示》。The Gradient 上有一篇精彩的摘要,以及 Neel Nanda 的后续分析。他们训练了一个含有 2500 万参数的 GPT,用于预测奥赛罗游戏中的下一步棋。它不仅能在训练数据集未覆盖的游戏中准确落子,而且通过线性和非线性的探测发现,这个模型能准确追踪棋盘的状态。
然而,这一成果仅限于使用奥赛罗游戏树上均匀采样得到的合成数据集训练的模型。当他们尝试将相同的技术应用于使用人类对弈数据训练的模型时,结果并不理想。在我看来,这是该论文发现的一个重要限制,可能会影响其在现实世界的应用性。比如,我们无法仅通过从代码树均匀采样来生成代码。
因此,我对此进行了深入研究。我训练了一些国际象棋游戏模型,并对这些训练好的模型进行了线性探测。我的研究结果非常正面,解答了我之前的所有疑问(当然,这也带来了更多新的问题)。
一款拥有 5000 万参数的 GPT 模型,在 4 块 RTX 3090 显卡上训练了一天后,通过分析 500 万局国际象棋对局,达到了约 1300 ELO 的棋力。这个模型仅被训练来预测国际象棋的 PGN(便携式游戏记谱法)字符串中的下一个字符(例如“1.e4 e5 2.Nf3 …”),而不需要了解棋盘的具体状态或国际象棋的具体规则。然而,为了更准确地预测下一个字符,它学会了如何计算游戏中任意时刻的棋盘状态,并且掌握了多种国际象棋规则,如“将军”、“将死”、“王车易位”、“吃过路兵”、“升变”和“受限制的棋子”等。此外,为了更好地预测下一步棋,它还能估计游戏中的隐性因素,比如玩家的 ELO 等级。
所有相关代码、数据和模型都已公开。
训练国际象棋 GPT
我最初的假设是,Othello-GPT(一款基于大语言模型的 AI 智能体)之所以在模仿人类下奥赛罗游戏时表现不佳,是因为缺乏足够的训练数据。该模型仅使用了 13 万局人类奥赛罗游戏的数据,而另一个采用人工合成数据的模型则是基于 2000 万局游戏训练的。为了创建我的数据集,我采取了两种方法:首先,我让高级别的 Stockfish ELO 3200(一款国际象棋 AI)作为白方,与等级从 1300 到 3200 不等的 Stockfish 黑方下了 500 万局。我希望这个包含高水平机器人国际象棋对局的合成数据集能提供比人类对局更高质量的数据。其次,我从 Lichess 的公共国际象棋游戏数据库中获取了 1600 万局游戏记录。我分别在这些独立的数据集及它们的各种组合上训练了不同的模型(更多细节见附录)。
起初,我尝试对开源模型如 LLama 7B 或 OpenLlama 3B 进行微调(fine-tuning),但为了控制 GPU 成本(我用的是 runpod 提供的 RTX 3090),我不得不放弃这个方法。转而使用 Andrej Karpathy 的 nanogpt 仓库,从头开始训练模型。我尝试了拥有 2500 万和 5000 万参数的模型。
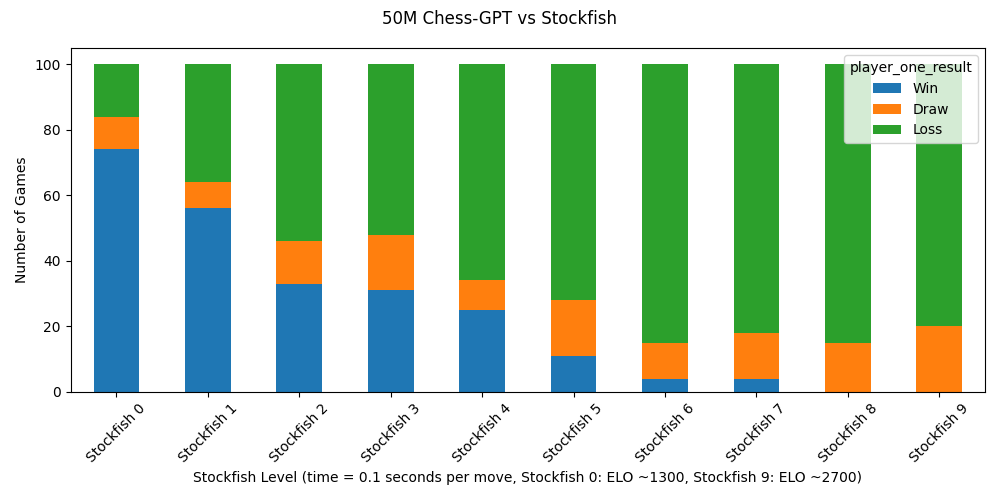
结果出乎意料地好。在训练一天后,拥有 5000 万参数的模型以 1300 ELO 级别(ELO 是一种评估国际象棋选手水平的系统)进行对局,其中 99.8% 的走棋合法。一个只有 8 层结构的模型能在比赛进入到第 80 回合时仍能正确做出合法走棋,这令我印象深刻。我让其中一个模型继续训练几天,它的 ELO 评分达到了 1500。我还在探索不同数据集组合的效果,并相信还有进步的空间。
因此,gpt-3.5-turbo-instruct 的高效表现并非神奇之举。如果你向大语言模型 (LLM) 提供几百万盘棋局数据,它就能学会下棋。我的 50M 参数模型远小于对 gpt-3.5 规模的任何合理估计,但它的棋力仅比 ELO 评分低 300 分。此外,我们最近证实 GPT-4 的训练数据包括了 1800 ELO 分以上玩家的 PGN 格式棋局集合。
我还特别调查了它是否能下出不在其训练数据集中的新颖棋局。通常有观点认为,大语言模型似乎能泛化,仅仅是因为它们记忆了大量互联网内容。由于我能够访问训练数据集,我轻松地对此进行了验证。在我随机抽查的 100 局棋中,每一局到第 10 轮(即 20 步)时都是全新的,不曾出现在训练数据中。考虑到可能的棋局远超宇宙中的原子总数,这个结果并不意外。
Chess-GPT 的内部世界模型
我接下来想探索的是,我的模型是否能够准确地追踪棋盘的状态。首先简要介绍一下线性探针(linear probe):当模型在预测下一个 Token 时,我们可以获取它的内部激活情况,并基于这些激活情况训练一个线性模型,来预测棋盘的状态。由于线性探针结构简单,我们可以相信它反映的是模型自身的知识,而非探针的处理能力。我们也可以使用一个小型神经网络来训练非线性探针(non-linear probe),但这可能会受到数据噪音的干扰。作为验证,我们还对一个随机初始化的模型进行了测试。
在原始的奥赛罗(Othello)研究中,研究人员发现只有非线性探针能够准确地构建出“这个方格是黑子/白子/空”的棋盘状态。为此,探针会在模型的每次移动时基于激活情况进行训练。然而,Neel Nanda 发现,线性探针实际上能够准确地构建出“这个方格是我的棋子/对方的棋子/空”的状态。这是通过仅在模型预测黑色或白色移动时,基于激活情况训练线性探针实现的。Neel Nanda 推测,非线性探针可能仅仅是学会了将“我在下白子”和“这个方格是我的颜色”进行逻辑异或(XOR)操作。
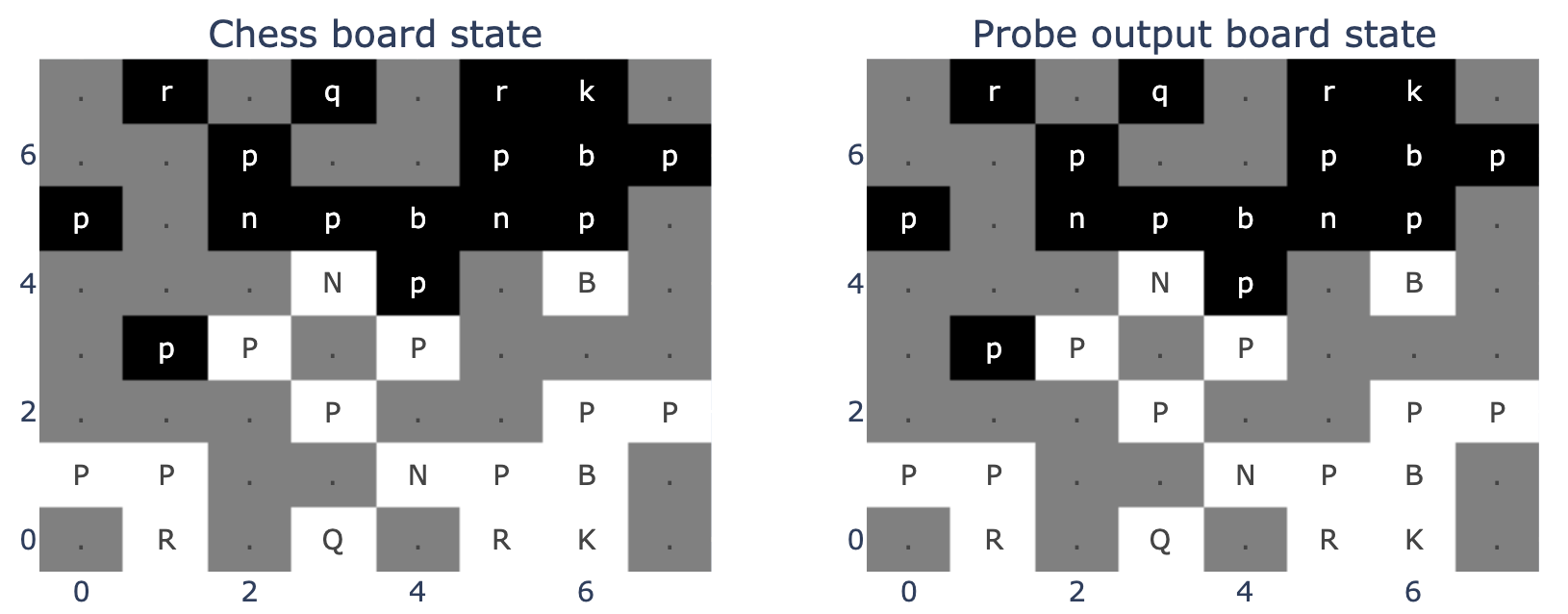
基于这些发现,我对我的模型进行了一些线性探针的训练。结果令人欣喜,它在第一次尝试中就基本上成功了。我还发现,我的 Chess-GPT 更倾向于使用“我的棋子/对方的棋子”的棋盘状态,而不是传统的“黑子/白子”状态。我猜测这是因为模型学习了一套“程序”,用于预测基于特定棋盘状态的下一步棋,并且这套“程序”被两方玩家共同使用。线性探针的任务是将每个方格分类为 13 个类别之一,包括空格、白棋/黑棋的兵、车、象、马、王、后。在 10,000 场游戏中,线性探针成功地对 99.2% 的方格进行了准确分类。
为了更好地理解我的模型的内部预测机制,我制作了一些视觉化的热力图。这些热力图是基于探测器的输出制作的,探测器被训练来根据独热编码(one-hot encoding)目标预测棋盘上特定格子是否有棋子,如黑王(存在为 1,不存在为 0)。第一张热力图展示了黑王在棋盘上的实际位置。第二张热力图显示了探测器对结果的置信度,其中输出值超过 5 的被限制为 5。这种限制使探测器的输出更趋向于非此即彼的判断,就像图中白色方块在黑色背景上的对比。第三张热力图则展示了探测器的原始输出,揭示了不同的置信度级别。从中可以看出模型非常确信黑王不在棋盘的白方区域。
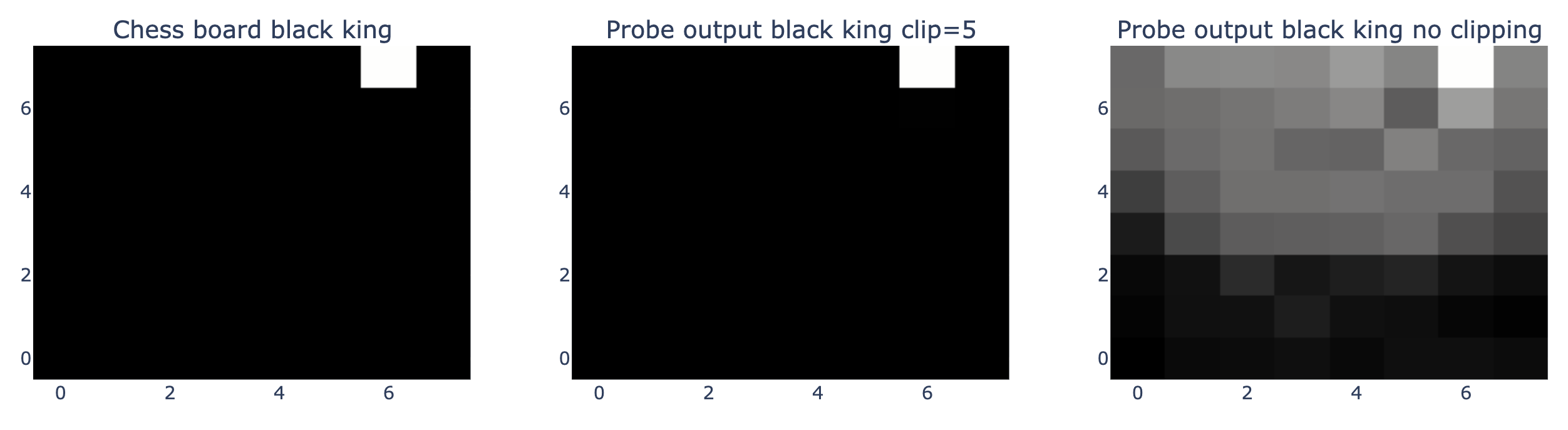
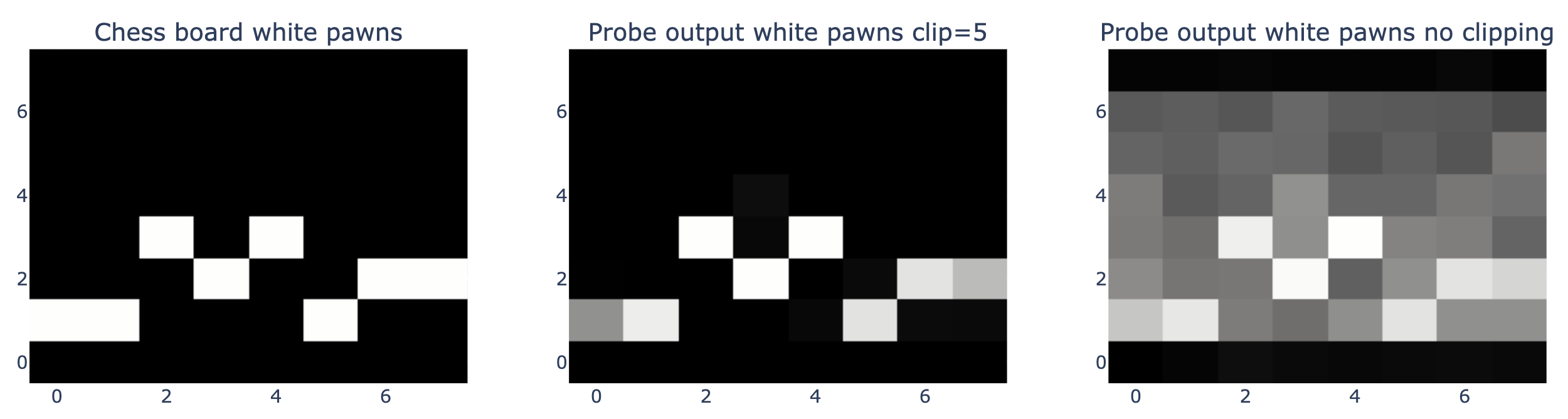
对于白色兵的位置,我们看到了类似的结果,但模型对此的置信度稍低。这种棋盘布局是从一盘国际象棋比赛的第 12 步获取的,模型极其确信任何一方的后排都没有白色兵。
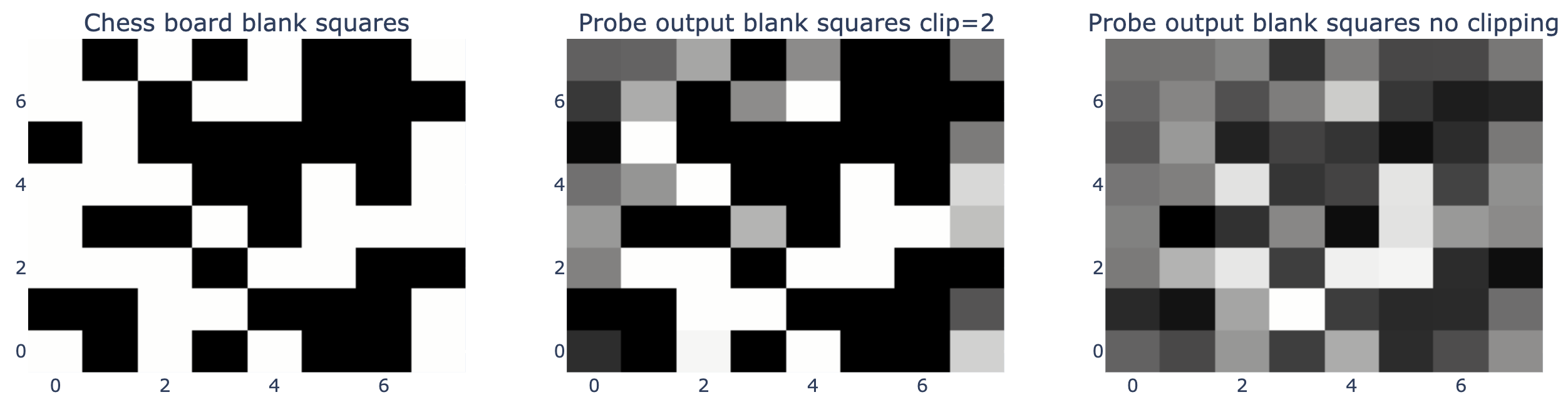
尽管模型能够识别出空白格子的位置,但它对此的置信度同样不高。
在这盘国际象棋游戏的这一步,线性探测器完美地重构了棋盘的状态。探测器的任务是将每个格子分类为 13 种可能的类别之一,每种类别代表一种不同的棋子或空白格。要创建这样的图,我们仅需选择每个格子上预测值最高的作为探测器的输出结果。
探寻潜在变量
Chess-GPT 之所以引人关注,是因为它学会了预测竞技国际象棋比赛中的下一步,而非从一个规则的游戏树中均匀采样的走法。这让我们有机会探查一些有趣的潜在变量。我特别猜测,为了更准确地预测下一个棋步,Chess-GPT 可能会学习估算参与游戏的玩家的技能水平。
起初,我对一个探针进行了回归任务的训练,它的任务是预测白方玩家的等级评分(ELO)。这种训练是在模型处理第 25 到第 35 步棋时的内部活动数据上进行的,因为在游戏早期阶段预测玩家的技能水平极其困难。但问题在于,Lichess 数据集中大多数游戏的玩家等级评分介于 1550 至 1930 ELO 之间,这个范围相对较窄1。在 Chess-GPT 上训练的线性探针(linear probe)的平均误差为 150 ELO,乍看之下成绩不错。然而,一个在随机初始化模型上训练的线性探针的平均误差为 215 ELO。大多数游戏的 ELO 范围狭窄,使得难以判断模型真正的知识水平。要区分 1700 与 1900 ELO 的玩家实际上是一项颇具挑战性的任务。
因此,我随后对探针进行了分类任务的训练,让它区分 ELO 低于 1550 或高于 2050 的玩家。在这种情况下,探针的表现大为改善。一个在随机初始化模型上训练的探针能正确分类 66% 的玩家,而在 Chess-GPT 上训练的探针则能正确分类 89% 的玩家。
这个结果在某种程度上并不让人意外。这让我想起了 OpenAI 2017 年的论文《情感神经元》(Sentiment Neuron)。在这篇论文中,他们训练了一个长短时记忆网络(LSTM)来预测亚马逊评论中的下一个字符。当他们使用仅 232 个标注样例在模型内部训练一个线性探针时,它成了当时最先进的情感分类器。OpenAI 当时指出:“我们相信这种现象不是特定于我们的模型,而是某些训练用于预测输入中的下一步或维度的大型神经网络的普遍特性。”有了这样的背景,这个结果几乎是意料之中的。
警告
如果我进一步对这些探针在模型上执行因果干预操作,那么我们的证据会更加充分。比如,我可以改变模型对棋盘状态的内部理解,并观察它在新棋盘状态下是否仍能做出合规的移动。或者,我可以对模型对玩家技能的理解进行干预,看它的表现是提高还是降低。遗憾的是,我的时间已经用完。这只是一个圣诞假期的小项目,现在该回去工作了。
尽管如此,我仍然认为这些发现是有价值的。线性探针虽然能力有限,但它们是公认的评估模型学习成果的方法。我遵循了培训探针的通用最佳实践:在训练集上进行训练,并在独立的测试集上进行测试。特别是对棋盘状态的探测,这是一个非常具体且实际的任务。虽然探测技能水平时,存在一定的可能性即模型可能学习到了与技能高度相关的某些特征,但在国际象棋游戏中,在 25 步之后判断玩家的 ELO 等级这一难题上,达到了 89% 的好成绩,这已经是非常出色的表现了。
潜在的未来研究方向
正如 Neel Nanda 所探讨的,解读在特定、限定任务(例如奥赛罗或国际象棋)上训练的模型具有许多益处。但要理解像 Llama 这样的大语言模型(LLM)在无特定限制的领域(如诗歌)中预测 Token 时其内部是如何处理和建模的,这是一个挑战。人们已经成功解释了在简单的玩具任务(如排序列表)上训练的模型。在游戏上训练的模型是一个既实际又引人入胜的中间步骤。
我首先想到的是寻找一种内部的树状搜索机制。当我下棋时,我会进行树状搜索,先考虑多种可能的移动,然后预测对手对这些移动的反应。Chess-GPT 在预测下一个字符时,是否也进行了类似的内部计算?考虑到它比我棋艺更佳,这种可能性似乎相当大。
其他可能的研究方向包括:
- 利用这些线性探测工具对模型进行因果干预。
- 研究模型有时为何不能做出合法移动或准确模拟棋盘的真实状态。
- 模型是如何计算棋盘的状态,或者特定棋子的位置的?
- 我对 GPT-2 进行了微调,让它同时学习 OpenWebText 和国际象棋游戏的内容,结果它既学会了下棋,又能继续生成看似合理的文本。或许在这方面有一些值得探索的有趣内容?
如果您对讨论或合作感兴趣,欢迎通过电子邮件与我联系。此外,还有一个 Twitter 线程 供公众讨论使用。
附录
技术探测细节
Neel Nanda 和我都将我们的探测工具训练成预测“我的棋子/对手的棋子”而非“白棋/黑棋”。要预测“白棋/黑棋”,只需在模型每一步的活跃信号上训练线性探测器。而预测“我的棋子/对手的棋子”,则需在模型针对每个白方或黑方步骤的活跃信号上训练。
在 Othello-GPT 中,模型有 60 个 Token 的词汇表,对应 60 个合法的放棋位置。所以,Neel Nanda 只在每个偶数字符位置进行白方“我的棋子/对手的棋子”探测,而在每个奇数字符位置进行黑方“我的棋子/对手的棋子”探测。在我的案例中,Chess-GPT 的输入是像“1.e4 e5 2.Nf3 …”这样的字符串。
因此,我在模型预测下一个字符时,每个“.”的位置上训练了白方“我的棋子/对手的棋子”探测器。比如,探测器会针对“1.”和“1.e4 e5 2.”这样的输入进行训练。对于黑方“我的棋子/对手的棋子”探测器,我则在每个偶数的“ ”字符位置上进行训练。我还针对“白棋/黑棋”目标训练了一个线性探测器,它达到了 86% 的分类准确率。
Neel Nanda 在训练探测器时排除了游戏的前 5 步和最后 5 步。我发现,无论是训练全部步骤还是除了前 5 步的步骤,我的线性探测器的准确率都没有变化。
模型训练详情
这些大语言模型(LLM)采用的是字符级别的建模,而非字节对编码(byte-pair encoding)和 Token 化处理。通过手动检查 gpt-3.5 的 Token 化过程,可以发现,对于 PGN(Portable Game Notation,便携式棋谱表示法)字符串来说,标准 Tokenizer 处理后,每个 Token 平均略多于 1 个字符,这里不包括空格。我的模型只使用了 32 个 Token 的词汇量,因此相比使用一个包含 50,257 个 Token 的标准 Tokenizer,我减少了约 2500 万个参数,有效缩小了模型规模。在训练过程中,我确保每个批次都以“;1.”开始,这是一个新游戏开始的分隔符 Token。我也尝试过训练模型,通过随机选取通常从棋局中间开始的数据段。虽然这种方法的上下文长度为 1024,通常也能涵盖到游戏的开局部分,但模型最终还是学会了下棋。我很好奇,这个模型究竟学到了什么样的启发式规则,可以在接收到从棋局中间开始的输入时,正确推断出棋盘状态。
开源代码、模型和数据集
我们提供的所有代码、模型和数据集均为开源。想要训练、测试或者对大语言模型(LLM)进行线性分析和可视化,可以访问这个网址:https://github.com/adamkarvonen/chess_llm_interpretability
如果你想尝试使用我们的 nanoGPT 模型来挑战强大的国际象棋程序 Stockfish,请访问:https://github.com/adamkarvonen/chess_gpt_eval/tree/local_llama
对于有兴趣从零开始自行训练 Chess-GPT 的朋友,可以访问:https://github.com/adamkarvonen/nanoGPT
所有经过预训练的模型都可以在这个链接中找到:https://huggingface.co/adamkarvonen/chess_llms
所有相关数据集也可在此链接获取:https://huggingface.co/datasets/adamkarvonen/chess_games
此外,关于模型训练过程中的损失变化曲线和模型配置的详细信息,可以通过以下链接查看:https://api.wandb.ai/links/adam-karvonen/u783xspb
模型规模和数据集对比
| 模型名称 | 目标探测层 | ELO 分类准确度 | 棋盘状态分类准确度 | 合法移动率 |
|---|---|---|---|---|
| 8 层随机初始化模型 | 第 5 层 | 65.8% | 70.8% | 0% |
| 16 层随机初始化模型 | 第 12 层 | 66.5% | 70.6% | 0% |
| 在 Lichess 游戏数据上训练的 8 层模型 | 第 7 层 | 88.0% | 98.0% | 99.6% |
| 在 Lichess 游戏数据上训练的 16 层模型 | 第 12 层 | 89.2% | 98.6% | 99.8% |
| 在 Stockfish 游戏数据上训练的 16 层模型 | 第 12 层 | 不适用 | 99.2% | 99.7% |
关于下面的图表有几点需要说明:不幸的是,我不小心删除了一部分 Stockfish 游戏数据训练的 16 层模型的日志,但据我估计它处理了约 1200 亿个字符。所有其他模型处理了总计 600 亿个字符。这些模型经历了数个训练周期,数据集的大小从 40 亿到 70 亿个字符不等。图表中的标签表示了模型训练所用的 hugging face 数据集以及模型的层数。在这个图表中,每场游戏中的胜利记为 1 分,平局记为 0.5 分,失败记为 0 分。与层叠式柱状图相比,这样的表示虽然丢失了一些信息,但更加简洁明了。
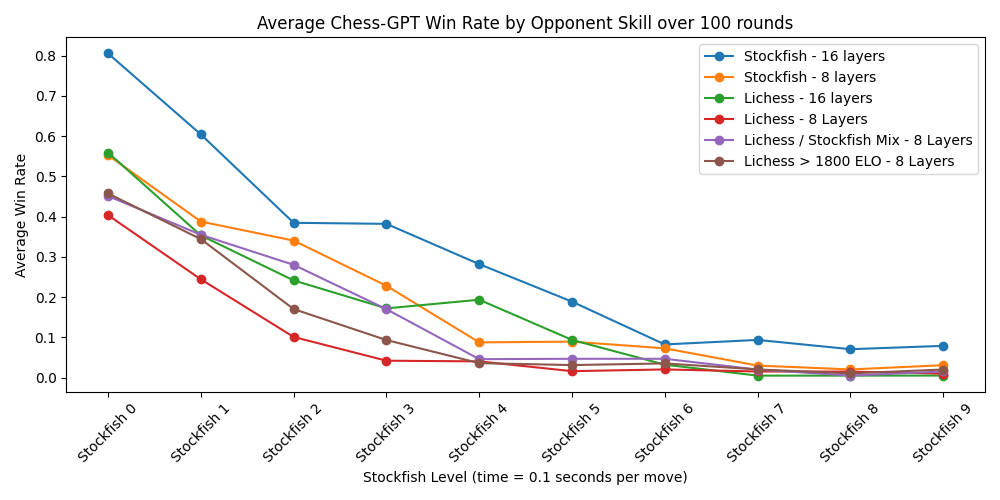
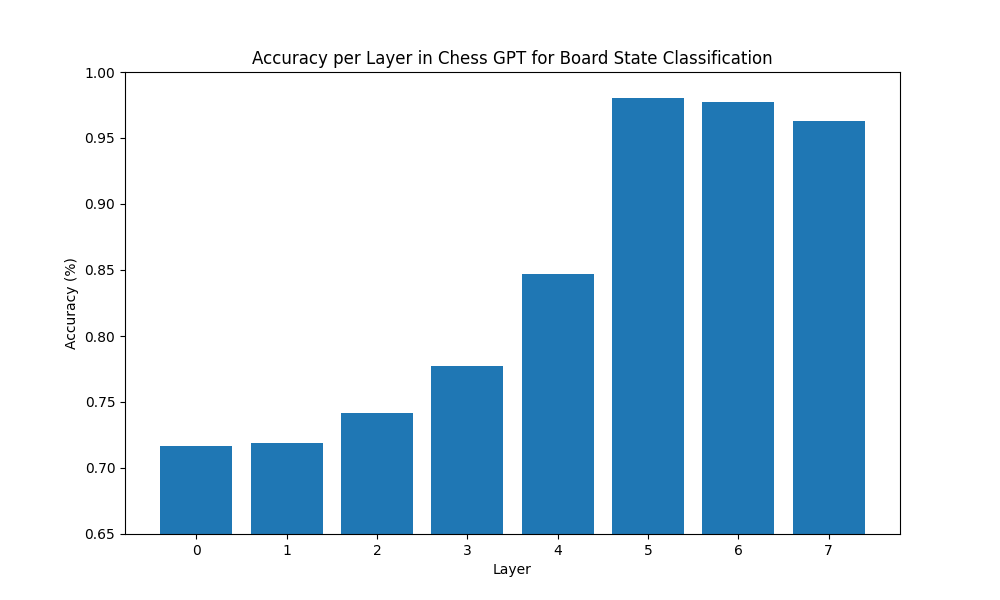
8 层网络中每层的准确率探测

- Lichess 的 ELO 等级通常比较高。chess.com 的平均 ELO 等级约为 800。通过快速进行 Google 搜索可以发现,许多人认为 Lichess 的 ELO 等级通常比其他网站的高几百分。 ↩