向 OpenGPTs 注入长效记忆功能 [译]
LangChain
三周前,我们发布了 OpenGPTs——一种基于开源理念实现的 OpenAI GPTs 和 Assistant API。OpenGPTs 能够构建对话型 AI 智能体,这是一种既灵活又前瞻性的技术架构。在这些智能体中,记忆扮演着至关重要的角色。目前,无论是 GPTs、OpenGPTs 还是 Assistants API,它们都仅仅支持基础的对话记忆功能。而长期记忆则是一个尚未深入探索的领域。在本篇博客中,我们将简要探讨我们对记忆的看法,分析为何这一领域研究不足,然后展示我们如何在 OpenGPTs 中实现并应用特定记忆机制,打造出一位“龙与地下城”游戏的地牢主。
大语言模型的无状态特性
大语言模型(LLM)本质上是无状态的,即它们处理第二个输入时,不会记得之前的第一个输入。因此,几乎所有的大语言模型也都没有记忆功能。这就意味着,如果你想让模型有记忆能力,就需要用户在将信息传递给大语言模型之前自己维护这些状态。
OpenAI 不久前推出的 Assistants API 打破了这一局限。该 API 允许追踪一连串的信息,你可以让一个 AI 智能体(即大语言模型)处理这些信息,它会将新信息添加到这个信息序列中。尽管大语言模型本身依然是无状态的,但通过这个 API,它似乎具备了记忆功能。
即便如此,目前主要利用的还是基于对话的短期记忆。
对话记忆
对话记忆指的是在对话中记住之前的信息。这一过程是通过记录之前的消息,然后将这些消息作为输入内容加入到提示中,进而传递给大语言模型(LLM)来完成的。
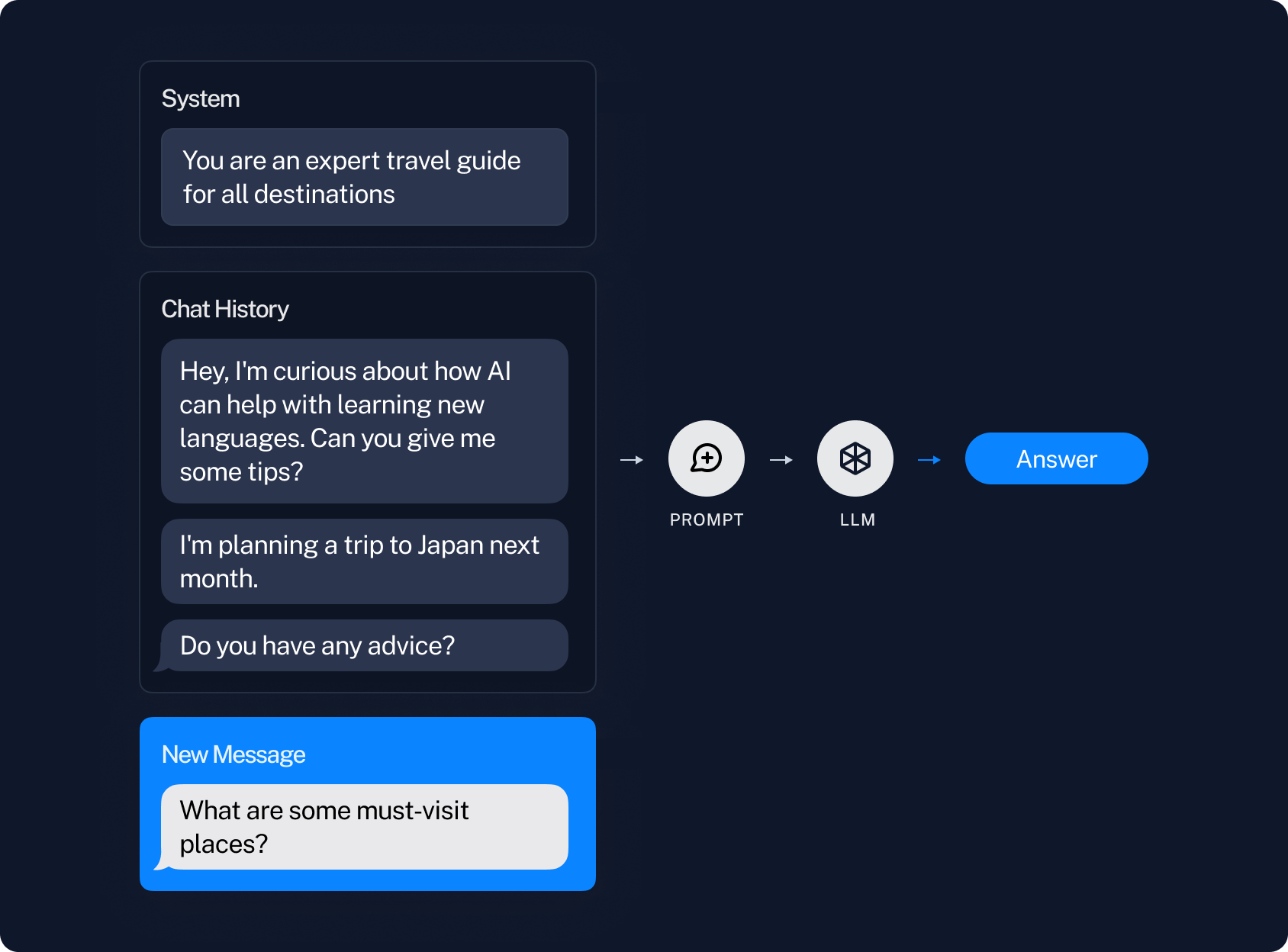
当记录的消息数量变得很多时,就会出现问题。首先,如果记录的消息过多,可能会超出大语言模型处理的文本范围。其次,即便没有超出处理范围,过多的消息也可能让大语言模型难以有效处理所有信息(详见 Greg Kamradt 的研究,关于长文本处理的局限性)。
解决这个问题的一个直接方法是仅使用最近的几条消息。但这样做的缺点是缺乏长期记忆能力——机器人可能会忘记你之前说的话。
那么,如何解决这个问题呢?
语义记忆
语义记忆是另一种常用的记忆类型。它指的是寻找与当前消息内容相似的消息,并将这些消息以某种方式融入到当前的提示中。
这通常是通过为每条消息创建一个“嵌入向量”(一种信息的数学表示),然后寻找与之相似的其他消息来实现的。这个原理与所谓的“检索增强生成”(Retrieval-Augmented Generation, RAG)类似,不过它是在消息中进行搜索,而不是在文档中。
比如,如果用户问“我最喜欢的水果是什么”,我们可能会找到一条类似的旧消息,如“我最喜欢的水果是蓝莓”(因为它们在信息表示上是相似的)。然后,我们可以将这条旧消息作为上下文信息加入进来。
不过,这种方法也存在一些问题。
挑战
首先:信息或见解若分布在多条消息中,可能难以准确地检索到关键消息。例如,假如出现这样的消息序列:
AI: 你最喜欢哪种水果?
人类:蓝莓
要获取完整的信息,就必须同时检索这两条消息。
其次:这种方法没有考虑时间因素。随着时间的推移,偏好或事实可能会改变。我的最爱水果也可能会变。仅凭语义相似性来检索,并没有考虑到这一点。
第三:这种方式对所需记忆类型的界定相对模糊。这对于通用人工智能 (AGI) 可能是好事,但对于那些需要更专注、具体的应用来说则不太理想。
生成式智能体
生成式智能体 是一篇不到一年前发表的杰出论文,它在高级记忆领域做了一些极具创新性的工作。深入了解这篇论文,你会发现它是如何应对上述挑战的。
在《生成式智能体》一文中,研究者们采用了多种技巧来构建记忆:
- 最近性:他们根据最新的消息来获取记忆(这是对话记忆与基于时间戳的消息加权的结合)。
- 相关性:他们获取与话题相关的消息(语义记忆)。
- 反思:他们不仅仅提取原始消息,而是利用大语言模型 (LLM) 对这些消息进行深思,然后提取这些深思后的内容。
通过反思可以解决前述的第一个问题:如果信息分散在多个消息中,通过对这些消息的反思可以生成一个综合概念。
第二个问题通过最近性加权得到了部分解决,但可能还未彻底解决。
至于第三个问题,则没有得到实质性的解决,因为这依然是一种较为通用的记忆形式(但这也符合其目标所在)。
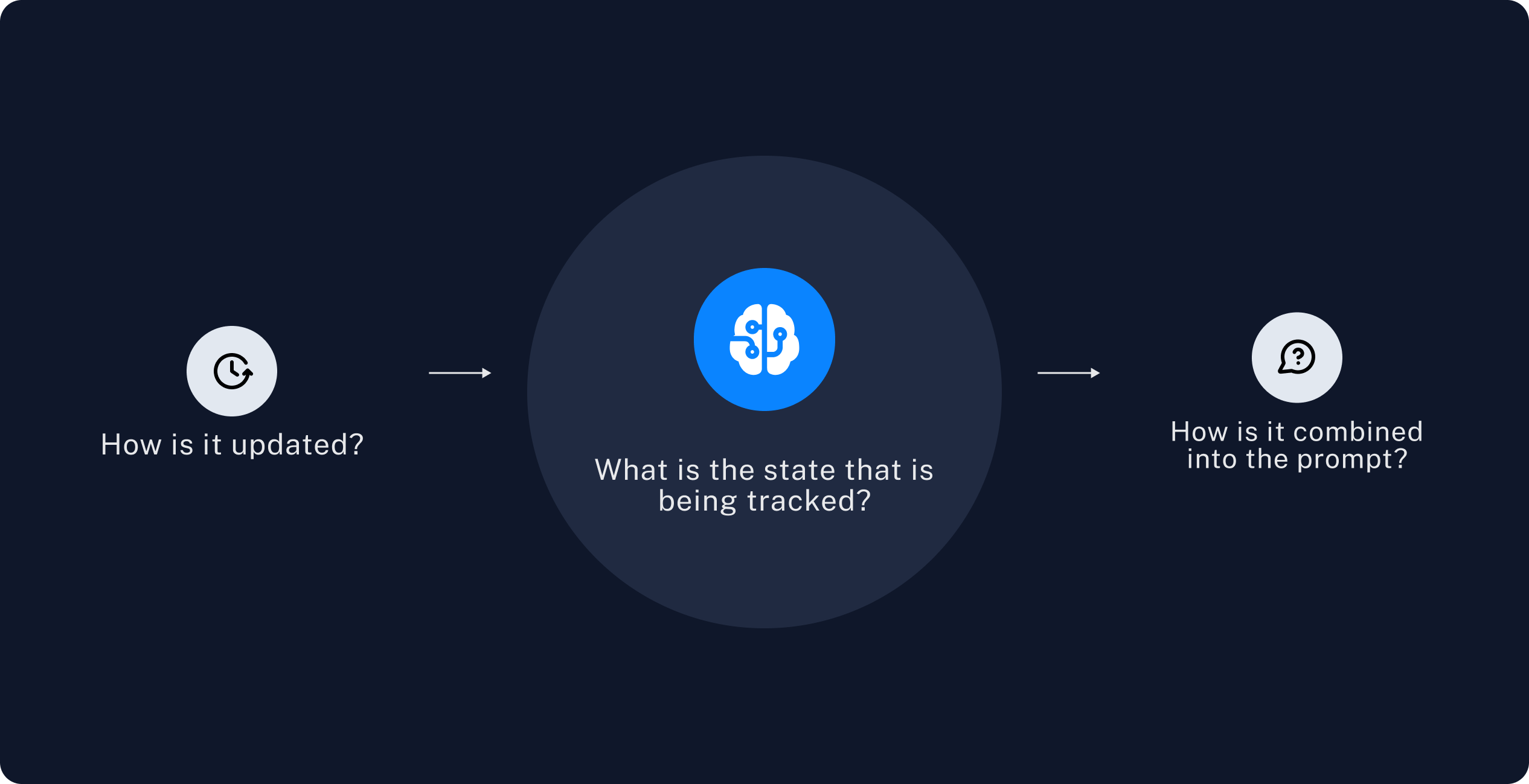
长期记忆的抽象理解
当我们探讨长期记忆时,一个通用的抽象概念是:
- 存在一种随时间变化并被持续追踪的信息
- 这些信息会在特定时期进行更新
- 这些信息会以某种方式融入到输入文本中
那么,我们关注的问题便是:
- 被追踪的信息是什么?
- 这些信息是如何更新的?
- 这些信息是如何被应用的?
接下来,让我们来具体了解上述三种记忆类型的实际应用。
对话记忆
- 被追踪的信息是一系列消息
- 通过在每次对话后追加新消息来更新这些信息
- 通过将这些消息融入到输入文本中来运用这些信息
语义记忆
- 被追踪的信息是消息的向量存储(vectorstore)
- 通过在每次对话后对消息进行向量化处理并加入存储来更新这些信息
- 通过在每次对话后查询类似消息来融入这些信息
生成式智能体
- 被追踪的信息包括记忆的向量存储和最近记忆的列表
- 更新这些信息的方式有多种。首先,每次对话后,新的记忆会被加入最近记忆列表。接着,为这个记忆计算一个嵌入。最后,在经过 N 次对话后,会对这些最近的记忆进行整理并同时加入列表和向量存储中。
- 通过基于最近性和相关性的权衡选择记忆(或记忆的整理)来融入到输入文本中。
针对特定应用的记忆机制
所有这些记忆机制形式都是相当通用的。如果你正在尝试构建通用人工智能 (AGI),这是非常有利的。但如果你的目标是开发更专门的应用程序,这些机制就显得不那么可靠和高效。
💡
记忆是认知架构的一部分。正如我们在实际应用中发现的那样,针对特定应用的记忆形式可以极大地提升应用程序的可靠性和性能。
因此,在你构建应用程序时,我们强烈建议你思考以下问题:
- 追踪哪些状态?
- 如何更新这些状态?
- 这些状态将如何被利用?
当然,这说起来容易做起来难。即便你能回答这些问题,如何具体实施构建呢?
我们决定在 OpenGPTs 中尝试这个想法,并构建一个具有特定记忆机制的特殊类型的聊天机器人。
龙与地下城聊天机器人
我们决定打造一个能够可靠地扮演龙与地下城游戏主持人的聊天机器人。我们需要哪种特定的记忆机制呢?
追踪哪些状态?
我们首先要确保跟踪游戏中涉及的角色信息。包括他们是谁、他们的特征等等。我们将这称为 角色 记忆。
接下来,我们还想跟踪游戏本身的进展状态。比如到目前为止发生了什么、角色所处的位置等。我们将这称为 任务 记忆。
我们决定将这些信息分成两个独立的部分,因此实际上我们在同时跟踪和更新两种状态:角色 和 任务。
如何更新这些状态?
对于角色描述,我们希望只在开始时更新一次。因此,我们希望我们的聊天机器人能够一次性收集所有相关信息,更新这个状态,之后不再进行更改。
之后,我们希望我们的聊天机器人能够在每个回合尝试更新任务的状态。如果判断不需要更新,则保持现状;否则,我们会用大语言模型(LLM)生成的新状态来替换当前的任务状态。
这些状态将如何被利用?
我们希望无论是角色描述还是任务的当前状态都能够始终被嵌入到聊天提示中。这个过程相对直接,因为它们都是文本形式,只需通过一些提示设计技巧,将这些变量作为占位符加入即可。
技术架构
在这个聊天机器人的开发中,我们采用了与一般 AI 智能体稍有不同的技术架构。具体来说,我们采用了状态机的一个版本。这个聊天机器人处于以下两种状态之一:
- 角色构建状态:这一阶段主要是收集用户角色的相关信息。
- 任务模式状态:在这个状态下,机器人主导一个任务。
当大语言模型 (LLM) 判断已经收集到足够的玩家角色信息时,就会发生从角色构建状态到任务模式状态的转换。此时,它会更新 character 内存。character 内存的存在意味着聊天机器人应转换到讲述任务的状态。
实际操作中的展示
要想实际看到这一切,你可以访问 OpenGPTs 的线上版本。你可以在这里找到一个已经创建好的机器人。源代码可以在这里查看。
如果你想自己从头开始创建一个带有记忆功能的“龙与地下城”(一款角色扮演游戏)聊天机器人,在创建新机器人时选择 dungeons_and_dragons 类型。
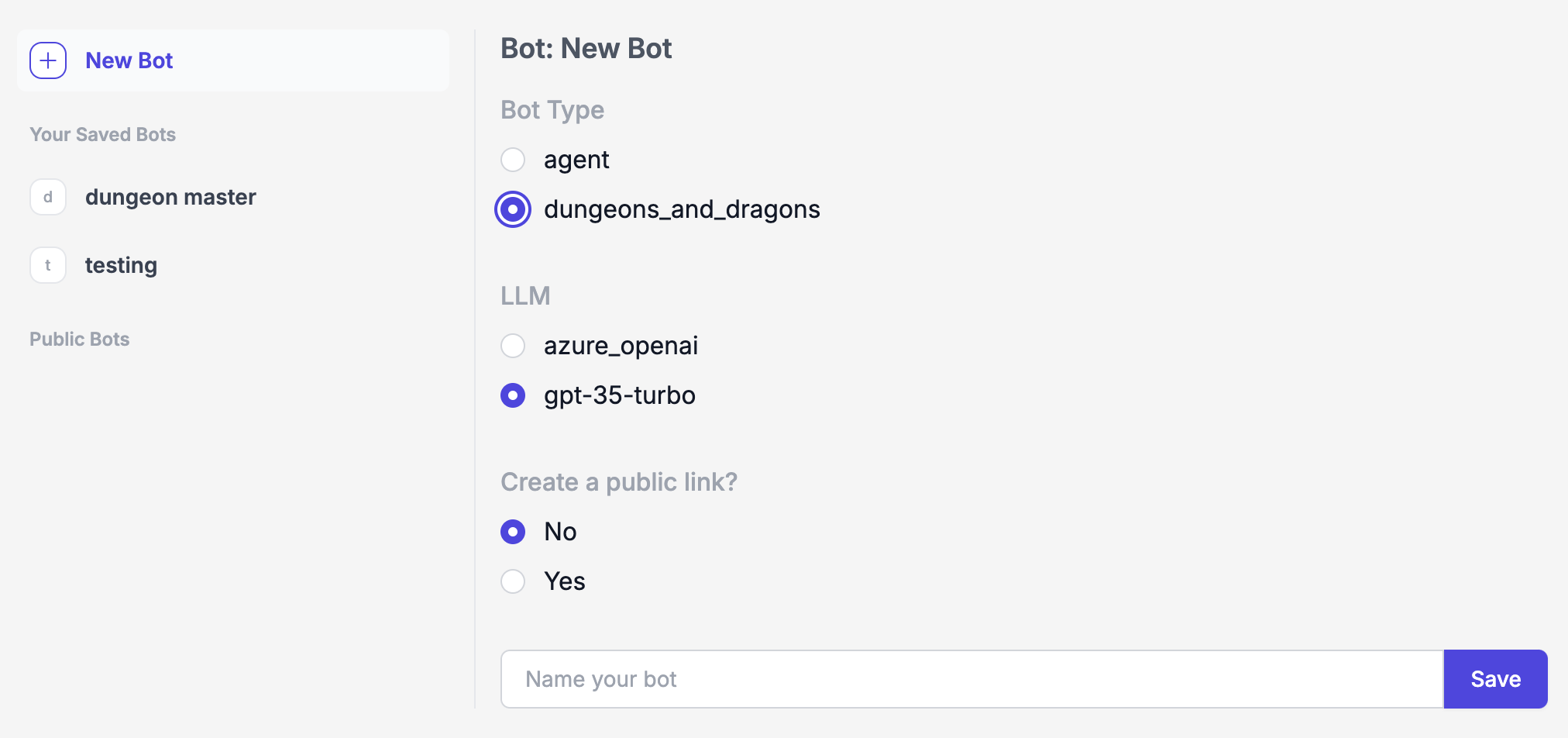
与它对话时,它会首先与你进行互动,收集你的角色信息。

一旦它收集了足够的信息,就会把这些信息保存在 CharacterNotebook(我们用来存储角色信息的记忆系统)里。
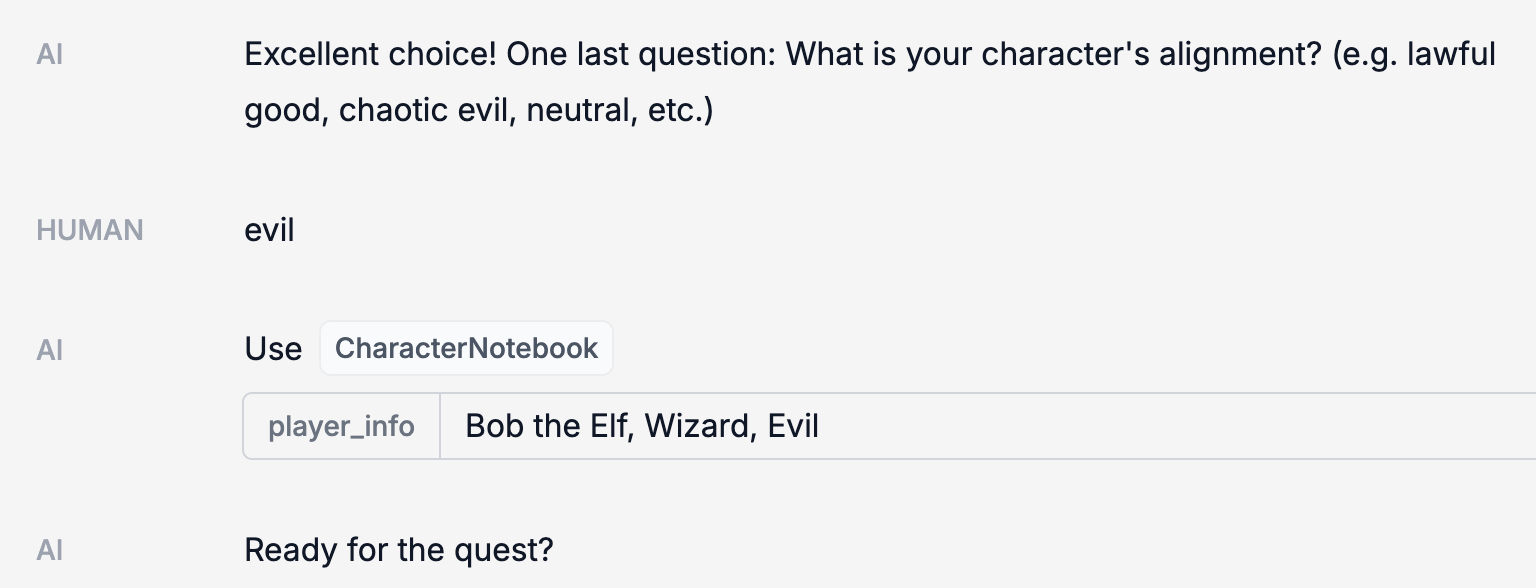
接下来,它会引导你进行一场冒险。在不同的阶段,StateNotebook(我们用来记录冒险状态的记忆系统)会进行更新。
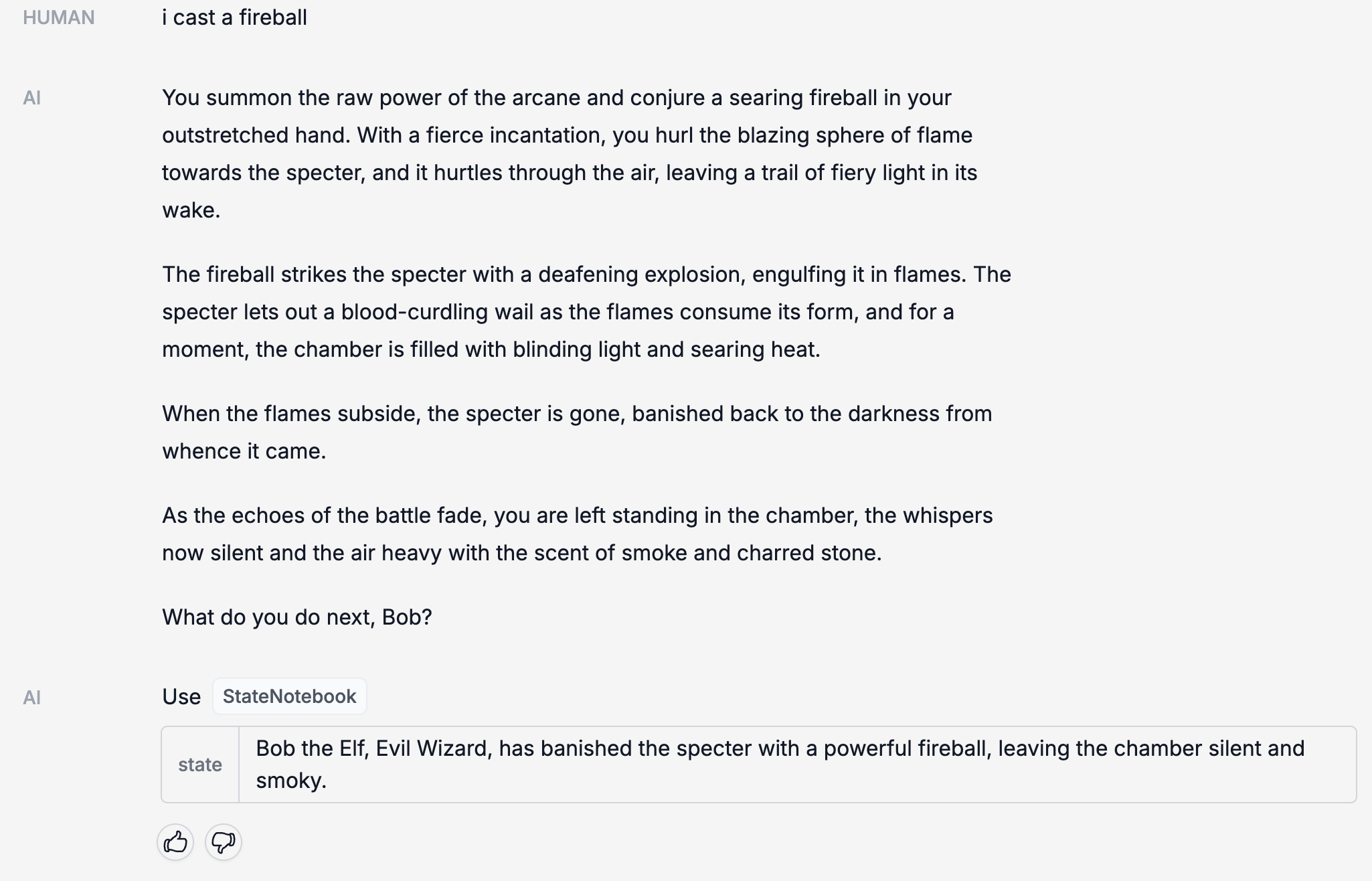
所有的活动都会在 LangSmith 中记录下来,这样我们就能看到幕后的情况:
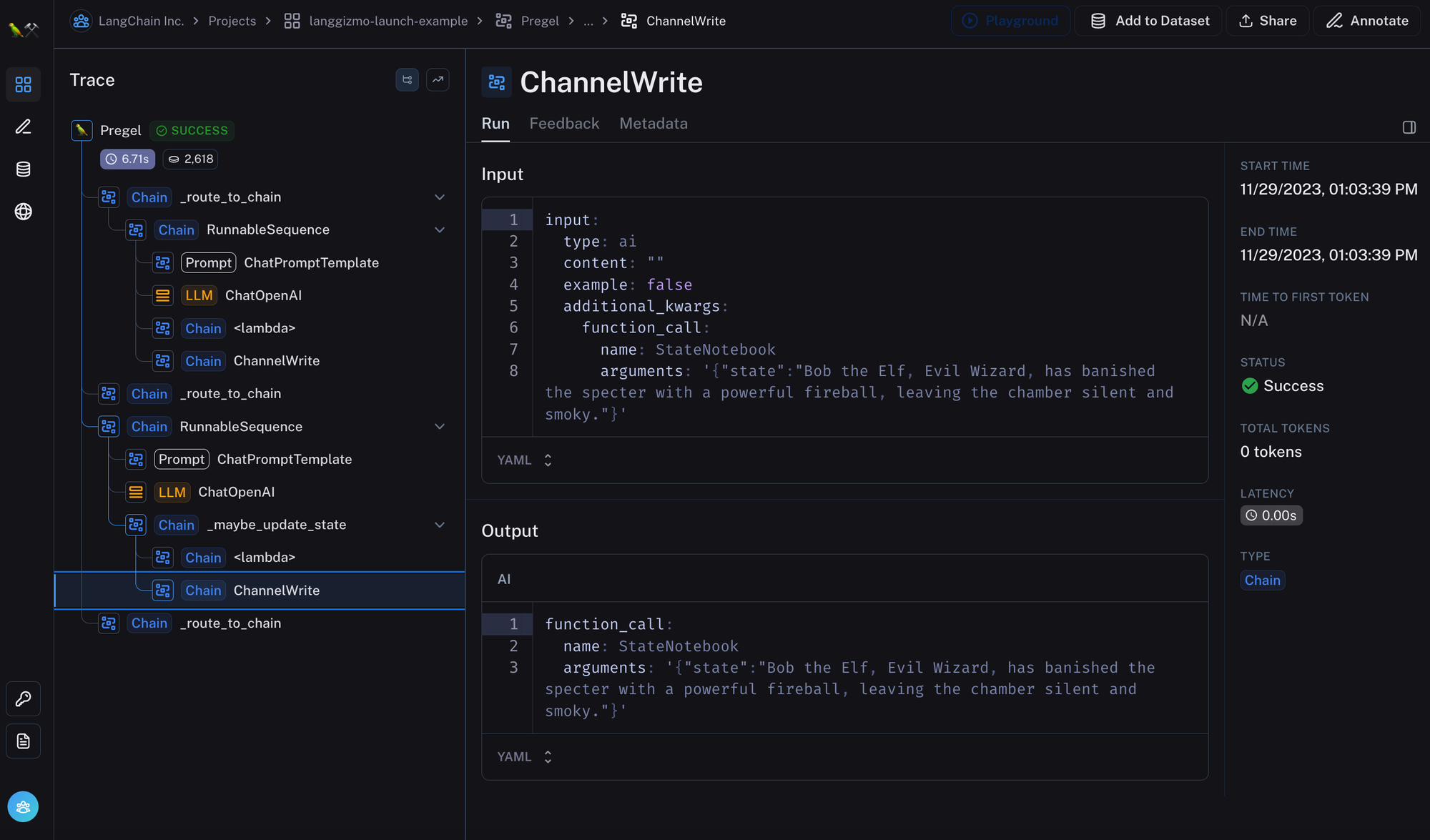
请注意,这个过程并不是完美无缺的!为了随着时间的推移改善冒险的更新过程,肯定还需要进行一些智能提示的优化。尽管如此,我们希望这能作为我们如何理解长期记忆,以及一个具体的定制化实施案例的展示。
结论
长期记忆作为研究领域,还远未被充分探索。这可能是因为它或者太泛化,倾向于研究通用人工智能 (AGI),或者过于特定于某些应用,难以进行通用化讨论。
在 LangChain,我们认为,大多数需要长期记忆功能的应用更适合采用针对特定应用设计的记忆机制。在这个前提下,我们需要深入思考以下几个问题:
- 追踪的状态是什么?
- 这些状态如何得到更新?
- 如何利用这些状态?
为了简化这个过程,我们正在开发一个框架(及相关工具),即 LangChain, OpenGPTs, LangSmith。但由于这些工具需要针对特定应用设计,因此在抽象层面上的开发颇具挑战。如果您的公司正在开发需要长期记忆功能的应用,并且需要帮助,请随时通过 [email protected] 与我们联系。