高效大语言模型推理 [译]
论量化、蒸馏及效率提升
近来,我频繁地探究如何高效地运用大语言模型 (LLM)。设想这样一个场景:你的老板对你说:“嘿,Finbarr,我们快破产了,因为我们把所有投资者的钱都花在了支持我们那个 300 亿参数、模仿 John Kenneth Galbraith 风格说唱的模型的 GPU 上。我们该怎么办?”
总的来说,你可以采取以下三种主要措施:
-
量化模型参数(量化 (quantization)),即在保持模型结构不变的前提下,降低每个参数的精度。
-
提炼出模型的一个更小版本(蒸馏 (distillation)),复制模型的架构以使其更小、更高效,然后训练这个新的小模型来模拟原始大模型的输出。
-
花费大量时间对代码进行性能分析,以减少开销,而不改变架构或参数(优化)。
首先应该考虑的显然是优化。许多程序的开销都非常大,而通过仔细分析代码性能,你通常能发现意想不到的大量开销。例如,我有一个同事曾求助于优化他的代码。他正在训练一个用于执行复杂计算的神经网络,并实施了许多性能优化措施,但他同时也在一个性能关键的循环中使用列表进行查找。我把列表换成了字典,使代码速度提升了 200 倍。
这并非罕见。每次我进行代码性能分析,总会对分析结果感到惊讶。所以,如果你遇到性能问题(别担心,这是很正常的),你首先应该做的就是对代码进行性能分析。
对于大多数人而言,这样已经足够。只需简化代码,批量处理请求,你就能以经济高效的方式响应请求,尤其适用于拥有传统软件利润空间的情况。但假如你已经深入优化,接下来的挑战是在 Triton(一种高级编程框架)中实现复杂的内核功能,这可能需要挖来 Nvidia 的资深 CUDA(一种并行计算平台和编程模型)专家。那么,接下来你该如何有效利用 GPUs 呢?
现在,你的选择主要是量化和蒸馏。量化是指在不改变其他神经网络部分的前提下,使用更低精度的权重。最近,量化技术被广泛讨论,例如 Llama.cpp 就通过这种方式将存储 llamas 权重的内存需求减少了四倍。
相比之下,蒸馏虽然关注度不高,但在大规模部署模型时历来非常重要。通常,蒸馏比量化效果更好,如果条件允许,它应该是你的首选方法。
关键在于:如果你有足够的资源。
回到我们的假设场景。你是 CoherentOpenStability 的一名勤奋的机器学习工程师,正在努力减少你的最新大语言模型 StableClaudius-4 的推理成本。你已经对代码进行了全面优化,消除了所有可能的多余部分。现在,你面临几个选择:
-
你发现了一个研究突破,以更低成本达成相同的目标,比如开发了一个效果出色的新型稀疏注意机制。
-
你缩小了模型规模。
在这些选择中,第一个显然更有优势。如果你能提出一个能显著改进模型的新研究成果,那当然是最好不过的。如果你能做到这一点,那就不要再读这篇文章了,赶快去撰写论文,申请 OpenAI、Anthropic 或 DeepMind,准备享受成为大语言模型专家的高薪。但大多数人可能做不到这一步,只能尝试开发一个规模更小、功能相同的模型。
那么,我们该如何开发一个更小的模型呢?有几个方案:
-
你可以按照原模型的方式训练一个规模更小的模型。
-
你可以将大模型蒸馏成一个小模型。
-
你可以对现有模型进行量化处理。
根据我的理解,现有文献清楚地指出了一个事实:模型蒸馏(distillation)绝对优于训练一个较小的模型,而模型量化(quantizing)则很可能 也比训练小型模型更有效。
虽然我希望看到更多关于模型蒸馏的研究,但目前显著的两篇论文分别是 DistilBERT 和 Hinton 等人的 最初的模型蒸馏研究。在 DistilBERT 的研究中,作者们成功地将模型的大小削减了 40%,同时只让性能下降了 3%。
在 Hinton 等人的研究中,他们通过一个单独的蒸馏模型达到了 10 个模型集成的性能,并且准确率仅从 61.1% 微降至 60.8%(保持了原始性能的 99.5%,而模型大小仅为原来的 10%)。虽然这项研究是与模型集成相比较,后者在增大模型尺寸方面较为低效,但这样的成果仍然相当显著,远胜于从零开始训练一个新模型来完成相同任务(后者的准确率仅为 58.9%)。
然而,模型蒸馏的挑战在于,它不仅需要从零开始训练一个更小的模型,还要利用大型模型对整个数据集进行推断处理。例如,处理一个与 GPT-3 相当的大型数据集(500B),按照公共 API 的价格,这可能需要花费高达 100 万美元(5e11 tokens * 2e-6 1e6),即使考虑到 OpenAI 可能有 60% 的利润率,成本也在 40 万美元左右。鉴于最初训练 GPT-3 的成本约为 500 万美元,这意味着需要增加额外的 10-20% 成本。虽然不至于禁止性,但这个成本并不低。
如果你有足够的经济能力承担这个成本,那就大胆去做吧!这几乎可以肯定地为你带来最佳性能。如果你在寻找更经济的方案,你可能会在从头开始训练一个较小模型和对一个现有模型进行量化之间做出选择。为了帮助你理解,我们发表了一篇论文 k-bit inference scaling laws。其核心思想是,从推理性能的角度来看,无论是运行 30B 模型的某一精度级别,还是运行 60B 模型的两倍精度级别,效果是相同的。因为大多数 GPU 在处理半精度的模型时,其运行速度会加倍(例如 A100s)。

此图展示了不同模型大小和精度水平之间的权衡。让我们比较一下 OPT 研究线的两个数据点。
模型精度 位精度 平均零样本准确率 8 0.675 16 0.65 8 0.725 16 0.7
从图中可以看出,在总模型位数相同的情况下,具有更少位数的模型更受青睐。这是因为,我们并没有发现使用双精度(fp64)训练参数数量减半的模型,相比于单精度(fp32)会有任何显著优势。
再看一张来自 OPT 论文 的图表,我们可以分析性能如何随着参数数量的增加而变化。OPT 使用的是 FP16,每个参数占用 2 字节(16 位),所以 1e11 个参数相当于 1.6e12 位。当参数数量减少 10 倍,即从 1.6e12 位降至 1.6e11 位时,OPT 的平均准确率从 0.7 下降到 0.65,这意味着成本降低了 10 倍,但准确率仅下降了 8%。虽然这个准确率与模型大小的权衡不如我们在模型蒸馏中看到的那样理想,但我认为大多数企业都会认真考虑这种权衡。
在讨论量化时,有一点非常重要:进行量化的成本极低!目前最先进的量化方法是 GPTQ,它能在 4 个 GPU 小时内(大约消耗 4 美元的云服务成本)量化一个拥有 1750 亿参数的模型。而从头开始训练这样的模型则代价高昂;例如,训练一个 GPT-3 风格的模型大约需要 500 万美元,且成本会随参数数量线性增长。因此,一个 200 亿参数的模型大约需要 50 万美元,并且需要大量数据(大约 1000 亿个 Token 才能达到 Chinchilla 最佳状态)。
量化的好处显而易见。但量化到底是什么,它是怎样工作的呢?
量化的基本原理其实很简单。由于计算机是离散的,它们无法直接存储浮点数(floating point numbers)。数字的表示基于 bits(位元),即 1 或 0。这些 bits 被编排成 binary(二进制)。在二进制整数的表示方法中,你可以使用一个有符号整数来表示以下范围:
这里的 n 是 bits 的数量。其中一个 bit 被用来表示数字是正还是负,而剩下的 n - 1 个 bits 用来表示数值的大小。
这种方法效率相当高。但问题出现在表示实数时,实数是指可以取整数之间任何值的数字。最常见的方法是:保留 1 个 bit 表示数字的正负,m 个 bit 表示数字的大小(即 指数(exponent)),以及剩下的(n - m - 1)个 bit 表示数字的精度(即 有效数字(significand))。

有效数 (significand) 是一个 (n-m-1)-位的无符号整数,可以表示的最大值为 2^{n - m - 1}。
在一个 32 位的浮点数 (单精度) 中,1 位用于标记正负号,8 位用于指数,23 位用于有效数。
在一个 16 位的浮点数 (半精度) 中,1 位用于标记正负号,5 位用于指数,10 位用于有效数。
在一个 64 位的浮点数 (双精度) 中,1 位用于标记正负号,11 位用于指数,52 位用于有效数。
注意附加位的用途——它们主要用于增加有效数的位数,这样做是为了提高精度而不是数值范围。也就是说,这让我们能够区分更小的数字,而不是表示更大的数字。
一般来说,大多数主要的张量编程框架默认使用 32 位精度来存储可训练参数。32 位精度通常是个不错的选择,因为只有少数应用(主要是科学计算应用)会从更高精度中受益。然而,在实际应用中,大多数前沿的研究现在都采用 16 位精度。
那么,既然你已经了解了浮点数精度的基本知识,我们来讨论一下如何选择合适的精度级别。如何实际上降低权重的精度呢?一种简单的方法是在给定的精度级别上直接截断权重。例如,如果你的权重是 0.534345,简单的截断处理会把它变成 0.534。
用于将数据量化至 4 位或更低的 SOTA 模型 是 GPTQ。其他的一些方法包括 LLM.int8() 和 ZeroQuant。我打算在未来的文章中对它们进行深入探讨,但此处我主要关注 GPTQ。GPTQ 的核心理念是,尽管减少比特数量必然会降低网络中的信息量,但我们可以通过训练权重来直接最小化这种降低对推理准确度(inference accuracy)的影响:

我们来看一个例子。假设 x = 0.323,而 w = 0.534345。保持所有数值为 float32 格式,其激活输出计算如下:
将结果四舍五入至小数点后六位(float32 的精度),得到的输出是 0.172593。
如果我们简单地进行四舍五入,输出变为
这里的差异是 1.114e-4。采用 GPTQ 方法,我们会这样计算:
得到的结果是
将这个结果四舍五入至小数点后三位(float16 的精度),我们得到的答案和简单四舍五入的结果完全相同,尽管过程更为复杂。
可能在其他场景中,这会更加重要吗?我目前还没有找到一个简单的例子来展示 GPTQ 的有效性。但在真实的部署环境中,GPTQ 显示出了明显的优势(这里的 RTN 是指“最接近的数值舍入”):
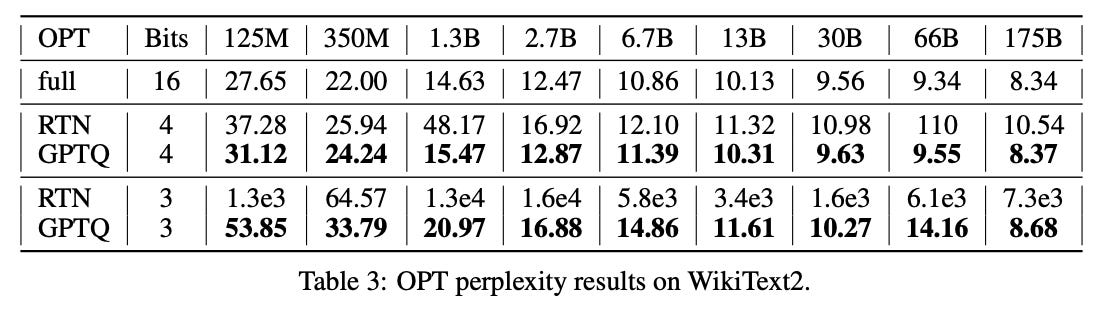
因此,这种方法明显优于简单的四舍五入,并且成本较低。
升级到付费版本以获取更多信息。
结论
量化技术并不像魔法那样神奇。本质上,你总在用准确度的牺牲换取性能的提升。可能损失不多,但永远不会提高准确度,顶多维持原状。
量化是否值得,这还不是很确定。可以参考 Tim Dettmers 关于量化的缩放法则。如果你只用了一半的精确度,可能更值得的做法是保持原有精度,减少一半权重,在更多的数据上训练时间翻倍。这就是 replit 实施的方法。对许多实践者来说,模型的部署成本远超训练成本。如果你也是这样,那么你可能不太关心量化一个模型。
即便你关心,模型蒸馏(将复杂模型的知识转移到更简单模型的过程)通常会比量化表现得更好。因此,如果你有能力蒸馏模型,你可能应该这样做。只有在你没有这样做的资源时,量化才确实值得。
最后,量化能带来线性速度提升,这已经很好了,但我们理想中的是能看到更大幅度的提升。或许引入某种稀疏性会有更好的效果。
这里甚至不需要使用复杂的 GPU 性能分析工具,只需使用你所用编程语言的基本分析工具就能对整个程序进行评估!