每家大语言模型公司都在挑战搜索技术:未来的大语言模型检索系统展望 [译]
搜索技术是计算机科学中极具挑战性的领域之一,仅有少数产品如 Google、Amazon 和 Instagram 能够做到出色。
直至不久前,大多数产品并不依赖高效的搜索功能——它并非用户体验的关键部分。
然而,随着大语言模型及其检索系统的迅猛发展,每个大语言模型公司都迫切需要将顶尖的搜索功能融入产品中,以确保其正常运作。
面对这种新兴的需求,新一代 AI 公司将如何解决搜索问题?
检索功能是大语言模型系统不可或缺的组成部分,这一点未来也不会改变。
检索增强生成 (retrieval-augmented generation, RAG) 系统为大语言模型提供必要的信息,帮助其回答问题。这种方式确保了生成的内容既真实又贴切。
设想一下,当大语言模型在回答历史考试问题时,没有 RAG 就像是闭卷考试,需要依靠记忆;而有了 RAG,就仿佛是开卷考试,模型会同时得到包含答案的教科书段落。显然,后者更为简单。
在大量数据中寻找正确的信息绝非易事。试想在庞大的代码库中寻找特定代码片段,或是在数千份发票中找到关键项,检索系统正是为解决这些问题而设计的。
随着新型大语言模型采用更长的上下文窗口,它们能够一次性处理更多数据。如果可以整本书载入,何必只寻找单一段落呢?
即使在拥有超过一百万 token 的上下文窗口时,我们认为检索功能仍将存在:
- 公司可能拥有多个版本的相似文档,一次性呈现可能会导致信息冲突。
- 多数复杂的应用场景需要基于角色和环境的访问控制,以确保安全。
- 即便计算效率得到极大提升,也无需承担处理大量不必要数据的时间和成本。
随着大语言模型原型开发的兴起,人们迅速采用了基于语义的相似度搜索方法。
这种方法已经应用了几十年之久。首先,将数据分成若干块,如一个 Word 文档中的各个段落。然后,每一块数据都通过一个文本嵌入模型进行处理,该模型会输出一个向量,这个向量包含了该数据块的语义意义。在检索过程中,系统会先嵌入搜索查询,然后找出与查询语义最接近的数据块。
尽管构建语义相似性模型相对简单,它通常只能提供平庸的搜索结果。这种方法的主要局限性包括:
- 它可能会遗漏那些语义与查询不同的重要内容。用户有时无法明确自己的需求,或者他们的查询缺乏足够的上下文(如,客户对产品的描述不够具体,或未提及近期的购买)。
- 此方法对所使用的嵌入模型非常敏感,一般的文本嵌入模型可能不适合特定领域的需求。
- 系统对数据的处理方式极为敏感,不同的解析、转换和分块方式会导致系统的运作效果各异。处理不同类型的数据(如表格)也相当复杂。
- 即使进行了优化,计算文本嵌入也非常耗费资源,这限制了对数据摄取和嵌入流程进行迭代的能力,以及提供几乎实时数据的应用的能力。
值得一提的是,这种方法仅根据查询的语义意义进行搜索。观察那些搜索表现出色的公司,你会发现语义相似性只是他们解决方案的一部分。
搜索的真正目的是提供最佳的结果,而不仅仅是最相似的结果。
例如,YouTube 将搜索查询的含义与根据全球受欢迎程度及你的观看历史所作出的视频向量化预测相结合。而亚马逊则确保在搜索结果中优先显示你之前购买过的商品,因为它知道这些是你可能想要重新购买的。
检索系统未来的发展方向
谷歌最初是基于 PageRank 算法建立的,这是一种简单的网页排名方法。然而,如果让创始团队见到今天的谷歌搜索,他们可能都会感到陌生,因为现在的谷歌搜索系统已经变得极其复杂,采用了多种方法来确保搜索结果的优质性。
类似地,初步构建 RAG(Retrieval Augmented Generation)系统的团队从简单的语义相似性搜索起步。我们认为,这些系统将逐渐演进,最终演变为类似于当今的搜索或推荐系统。这些系统在核心问题上没有太大差异:即从大量可能的选择中筛选出最有可能帮助实现特定目标的少数几个选项。
现在,大部分检索系统的外观如下:

将来的系统可能会是这样的:
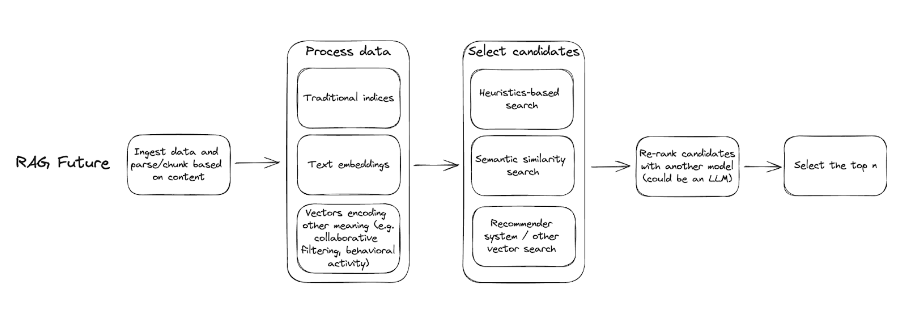
检索系统将极大地提升大语言模型的应用效能,包括它们的有效记忆力、响应质量、可靠性以及性能和响应速度。我们认为,对于许多应用程序来说,这些系统将比大语言模型本身更能够提升其核心能力。
正因如此,我们相信大多数公司会把这些系统作为其核心竞争力并在内部自行开发。这些开发者将依靠一系列全新的基础设施来打造适应其特定应用需求的检索系统。
迄今为止,大部分的投资都流向了用于存储向量并检索最近邻的数据库。然而,在未来的技术架构中,数据库仅是解决方案的一部分。
为了构建这些新型系统,我们需要更完善的工具:
- 创建、操作并利用能够编码不同信号类型的多种向量(如将语义搜索与推荐或行为向量相结合)。Superlinked(一个属于 Theory 的公司)正在开发这类工具。
- 输入、解析和处理各类输入数据。
- 构建并实时执行检索系统;这些操作(特别是生成嵌入向量的过程)成本较高,许多应用无法接受长时间的延迟。
- 对检索系统进行观测和监控。
虽然大部分公司倾向于自建检索系统,但未来这些系统可能通过几种方式合并:
- 基础设施服务商可能扩大其服务范围,包括数据摄取、处理及存储等基础设施层面。
- 企业可能会开发针对特定场景的“检索即服务”产品,比如专为电商网站或聊天应用设计的检索系统。
我们对检索及搜索技术作为产品推动力的进步感到期待。如果您正在开发检索系统的基础设施或为新应用打造检索系统,我们非常希望与您交流!