在命令行中运行 Mistral 模型的多种方法 [译]
目前,Mistral AI 是最引人注目的 AI 研究实验室。他们最近发布了两种功能强大的小型大语言模型,这些模型遵循 Apache 2 协议授权,还有一个更大的模型可通过他们的 API 使用。
我一直在用我的 LLM 命令行工具 尝试他们的模型。以下是我迄今为止的一些发现:
- 如何通过 llama.cpp 和 llm-llama-cpp 来运行 Mistral 8x7B
- 如何通过 llm-llama-cpp、llm-gpt4all 或 llm-mlc 来运行 Mistral 7B
- 如何使用 Mistral API,包括新推出的 Mistral-medium
- 如何通过其他 API 服务商来接入 Mistral
- 如何使用 Llamafile 的 OpenAI API 端点
透过 llama.cpp 和 llm-llama-cpp 实现 Mixtral 8x7B 的运行
在 12 月 8 日的周五,Mistral AI 在 Twitter 上分享了一个神秘的磁力链接(BitTorrent)。这已经是他们第二次发布类似链接,第一次是在 9 月 26 日,他们发布了其杰出的 Mistral 7B 模型,也是通过磁力链接发布的。
最新发布的是一个 87GB 的文件,里面含有 Mixtral 8x7B——根据他们三天后发布的文章,这是一个“高品质的稀疏专家混合模型(SMoE),且开放权重”。
Mixtral 模型给人留下了深刻印象。长久以来,人们一直在传说 GPT-4 使用了专家混合架构,而 Mixtral 则是我所见过的第一个真正有说服力的、公开授权的该架构实现。它已经展现出了令人瞩目的基准测试成绩。
这个为 llama.cpp 提供的 PR 增加了对这一新模型的支持。llama-cpp-python 随后很快更新了这个补丁。
这意味着现在你可以在 Mac(以及其他平台,虽然我还未亲自测试)上,通过我的 llm-llama-cpp 插件 来运行 Mixtral。
操作步骤如下:
pipx install llm
- 安装插件:
llm install llm-llama-cpp
- 安装
llama-cpp-python——这个步骤需要手动操作,因为不同平台有不同的最佳实践方式。在苹果硅芯片 Mac 上,我推荐如下操作:
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-python
想要了解更多细节,请访问 llm-llama-cpp 的 README 文档。
- 为 Mixtral 8X7B Instruct v0.1 下载一个 GGUF 文件。TheBloke 在 huggingface.co 上提供了 8 种不同的选项,我选择了一个 36GB 的
mixtral-8x7b-instruct-v0.1.Q6_K.gguf:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true'
- 模型的运行方式如下:
llm -m gguf \-o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf \'[INST] Write a Python function that downloads a file from a URL[/INST]'
这里的 -m gguf 指的是使用 llm-llama-cpp 插件安装的 gguf 模型,这种模型需要你指定一个 path 选项——通过 -o path filename 来选择你想运行的模型。
[INST] 是 Instruct 模型所期望的提示格式。我打算更新 llm-llama-cpp 插件,以便更容易地自动创建正确的提示格式,具体可参见 这个问题。
以下是我对这个提示的回答:
好的,这里有一个示例,展示了如何使用
requests库从 URL 下载文件的 Python 函数:import requestsdef download_file(url, save_path):"""Download a file from a URL and save it to a local path.:param url: The URL of the file to download.:param save_path: The local path to save the file."""response = requests.get(url, stream=True)if response.status_code == 200:with open(save_path, 'wb') as f:for chunk in response.iter_content(1024):f.write(chunk)print(f"File downloaded successfully at {save_path}")else:print(f"Failed to download file from {url}. Status code: {response.status_code}")要使用这个函数,只需提供你想下载的文件的 URL 和你想存储它的本地路径即可。例如:
download_file('https://example.com/myfile.txt', '/path/to/save/myfile.txt')注意,这个函数在
requests.get()方法中使用了stream=True参数,允许文件分块下载,这有助于在下载大型文件时避免内存问题。它还会在保存文件前检查响应的 HTTP 状态码,以便在下载过程中处理可能出现的任何错误。
这是一个非常周到的回答!
Mistral 7B 通过 llm-llama-cpp、llm-gpt4all 或 llm-mlc 运行
九月推出的小型 Mistral 7B 模型迅速确立了自己在同类尺寸中的领先地位——它的尺寸特别适合在个人设备上运行。
我现在甚至可以在我的 iPhone 上运行 Mistral 7B,这要感谢几天前 MLC Chat iOS 应用 的最新更新。
在 Mac 上本地运行这个模型及其变体有多种方式,我尚未亲自在 Linux 或 Windows 上测试这些方式:
-
使用 llm-llama-cpp: 你可以下载 这些为聊天优化的 Mistral-7B-Instruct GGUF 文件,或者 这些基础版 Mistral 文件,然后遵循上述步骤。
-
使用 llm-gpt4all。这是安装最简单的插件:
llm install llm-gpt4all
你第一次尝试使用时,模型会自动下载:
llm -m mistral-7b-instruct-v0 'Introduce yourself'
- 使用 llm-mlc。按照 README 文档中的指引安装后,进行如下操作:
# Download the model:llm mlc download-model https://huggingface.co/mlc-ai/mlc-chat-Mistral-7B-Instruct-v0.2-q3f16_1# Run it like this:llm -m mlc-chat-Mistral-7B-Instruct-v0.2-q3f16_1 'Introduce yourself'
这些方法都是可行的,但我还没有深入比较它们在输出质量或性能上的差异。
利用 Mistral API 开发新的 Mistral-medium
Mistral 最近推出了 La plateforme,这是他们初期提供的 API,可以让用户调用他们托管的各种模型。
他们的这个新版 API 对原有的 Mistral 7B 模型进行了重新命名,现在叫做“Mistral-tiny”,同时推出了一个新的模型“Mistral-small”... 还有一个名为 Mistral-medium 的新产品:
我们目前最高质量的服务端点是一个原型模型,这个模型在标准的基准测试中是目前最优秀的服务模型之一。它擅长处理英语、法语、意大利语、德语、西班牙语以及编程语言,其在 MT-Bench 的评分高达 8.6。
我获取了他们 API 的访问权限,并借此开发了一个新插件 llm-mistral。使用方法如下:
- 安装插件:
llm install llm-mistral
- 设置你的 Mistral API 密钥:
llm keys set mistral# <paste key here>
- 按以下方式运行模型:
llm -m mistral-tiny 'Say hi'# Or mistral-small or mistral-mediumcat mycode.py | llm -m mistral-medium -s 'Explain this code'
这里是他们将 Mistral Small 和 Medium 与 GPT-3.5 对比的表格:
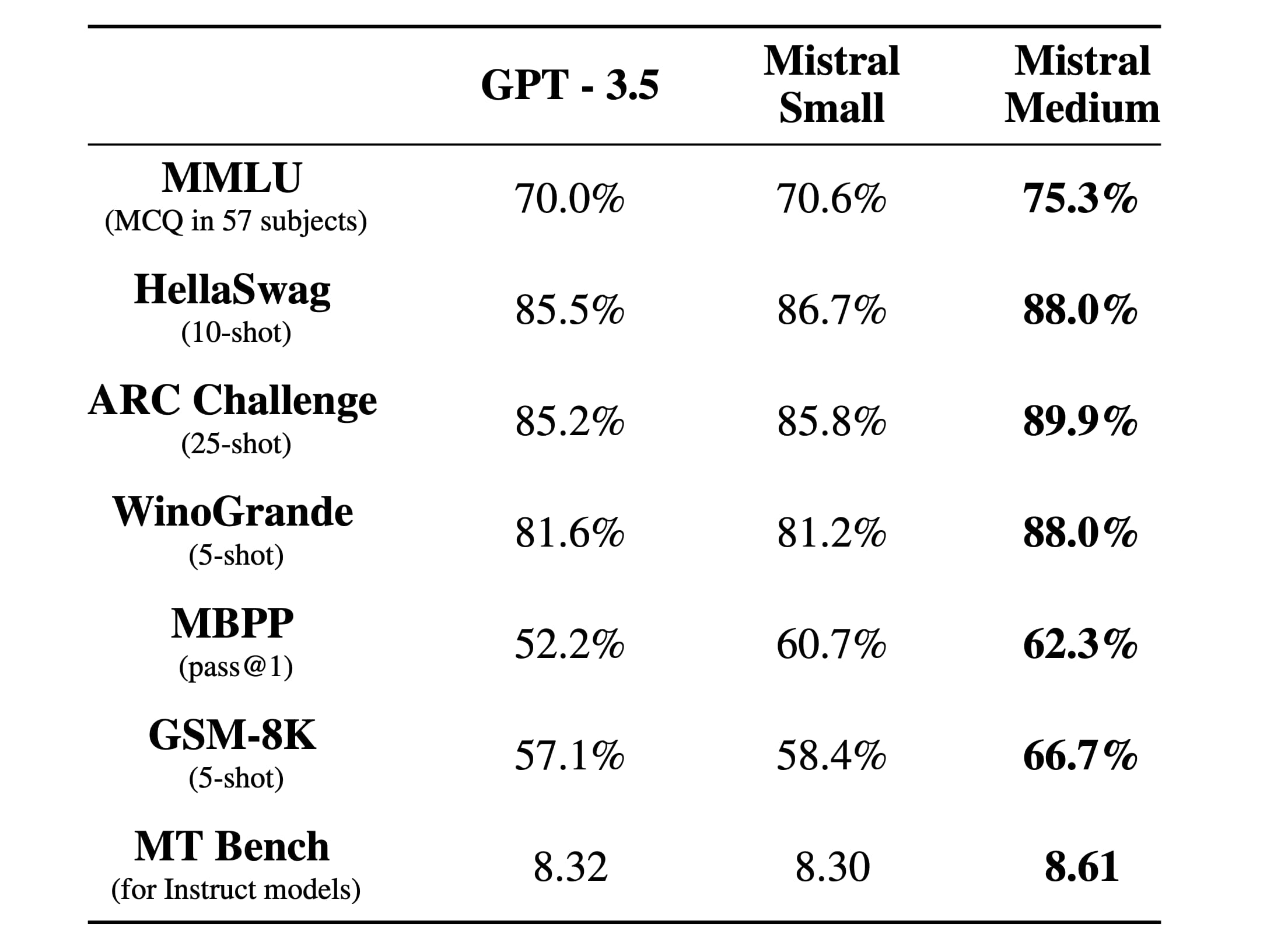
尽管这些数据可能是经过精心挑选的,但值得注意的是,Mistral Small 在几乎所有测试中都超过了 GPT-3.5,而 Mistral Medium 则在各个方面以更显著的差距领先。
这是 MT Bench 排行榜的链接,其中包括了 GPT-4 和 Claude 2.1 的表现评分:
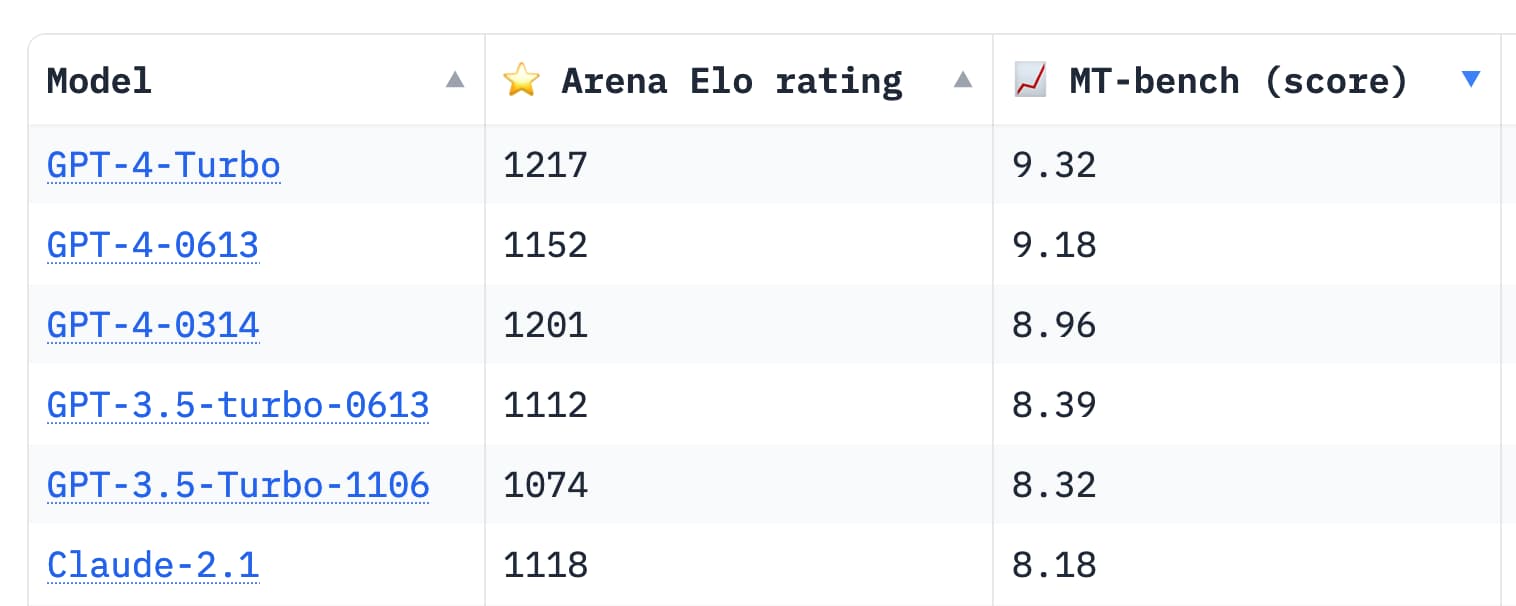
在 Medium 上,8.61 的分数让它处于 GPT-3.5 和 GPT-4 之间的位置。
尽管基准测试分数能提供一定参考,但想真正了解模型在各种任务中的表现,还是需要亲自体验。不过,GPT-4 的这些分数确实显示出极大的潜力。看来它不久后可能会有新的竞争者出现,挑战“最佳模型”的位置。
通过其他 API 提供商使用 Mistral
Mistral 7B 和 Mixtral 8x7B 作为开源项目(Apache 2 许可),使得其他大语言模型 (LLM) 托管提供商在价格上展开竞争。
这种价格竞争让人有些担心,因为它可能会降低 Mistral 和其他提供商发布开源模型的积极性,他们本想提供自己的托管服务。
目前已有几个 LLM 插件支持这些服务商。我尝试过的三个是 Replicate、Anyscale Endpoints 和 OpenRouter。
对于 Replicate:
llm install llm-replicatellm keys set replicate# <paste API key here>llm replicate add mistralai/mistral-7b-v0.1
你可以这样运行模型:
llm -m replicate-mistralai-mistral-7b-v0.1 '3 reasons to get a pet weasel:'
这个示例使用的是未经特别调整的模型,因此需要巧妙构造提示,让模型能够正确回应。
llm install llm-anyscale-endpointsllm keys set anyscale-endpoints# <paste API key here>
你现在可以同时运行 7B 和 Mixtral 8x7B 模型:
llm -m mistralai/Mixtral-8x7B-Instruct-v0.1 \'3 reasons to get a pet weasel'llm -m mistralai/Mistral-7B-Instruct-v0.1 \'3 reasons to get a pet weasel'
而对于 OpenRouter:
llm install llm-openrouterllm keys set openrouter# <paste API key here>
可以这样操作模型:
llm -m openrouter/mistralai/mistral-7b-instruct \'2 reasons to get a pet dragon'llm -m openrouter/mistralai/mixtral-8x7b-instruct \'2 reasons to get a pet dragon'
OpenRouter 目前通过其 API 免费提供 Mistral 和 Mixtral(每百万输入 token 0 美元)。虽然这种免费服务不太可能长期持续,但它确实为初步尝试这些模型提供了一个很好的平台。
如何使用 Llamafile 的 OpenAI API 端点
我最近撰写了一篇关于 Llamafile 的文章,这是一个引人入胜的选择,用于运行大语言模型 (LLM)。在这种方式中,LLM 能被封装成一个包含运行所需所有资源的可执行文件,并且支持多平台运行。
Justine Tunney 几天前发布了 Mixtral 的 llamafiles。
特别是,mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile 这个文件可以运行一个与 OpenAI API 兼容的端点,LLM 能与之通信。
使用它的步骤如下:
- 下载 llamafile:
curl -LO https://huggingface.co/jartine/Mixtral-8x7B-v0.1.llamafile/resolve/main/mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile
- 运行它:
./mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile
你可能需要先对它执行 chmod 755 mixtral-8x7b-instruct-v0.1.Q5_K_M-server.llamafile 命令,但我发现并不必要。
- 配置 LLM 识别这个端点,方法是在
~/Library/Application Support/io.datasette.llm/extra-openai-models.yaml文件中添加以下内容:
- model_id: llamafilemodel_name: llamafileapi_base: "http://127.0.0.1:8080/v1"
这将注册一个名为 llamafile 的模型,你现在可以像这样调用它:
llm -m llamafile 'Say hello to the world'
设置 llamafile 别名意味着,当你在默认的 8080 端口上运行任何 llamafile 模型时,都可以使用同样的命令行调用方法。
对于提供了模仿 OpenAI API 端点的其他模型托管选项,这种方法同样有效。
大语言模型插件的理想应用
我在为大语言模型增加插件支持时,正是怀着这样的想法:让添加新模型的支持变得尽可能简单,不论模型是部署在本地还是远程。
大语言模型插件目录现在共展示了 19 种插件。
如果你想自己动手做一个插件,不管是服务于本地模型还是连接远程 API 的模型,那么插件作者教程加上参考现有插件的代码,应该能帮到你。
同时,欢迎加入我们的#llm Discord 频道,与我们一起讨论你的项目构想。
文章发布于2023 年 12 月 18 日下午 6:18。你可以在Mastodon、Twitter上关注我,或者订阅我的新闻通讯。