最大化大语言模型性能 [译]
ANKIT SANGHVI
简述如何以可扩展的方式把大语言模型(LLMs)从原型提升至高性能
本博客内容源自于在 OpenAI DevDay 会议上由 Colin Jarvis 和 John Allard 所做的精彩演讲。这是相关 YouTube 视频链接 (https://www.youtube.com/watch?v=ahnGLM-RC1Y)
在自然语言处理的领域里,优化大语言模型(LLMs)的过程充满挑战。在高效与性能之间寻求平衡,就像是在计算的海洋中找到一根针。大语言模型的性能往往难以具体衡量,需要采用精细化的优化策略。在这篇博客中,我们将探索大语言模型优化的不同方案,帮助您了解何时使用适当的策略。
您将获得两个关键优化维度——上下文和大语言模型行为的基础理解,并能够深入了解模型细化的复杂世界。
优化的双重维度

1. 上下文优化
上下文优化的核心在于细化模型应掌握的信息。您可以通过以下方式进行:
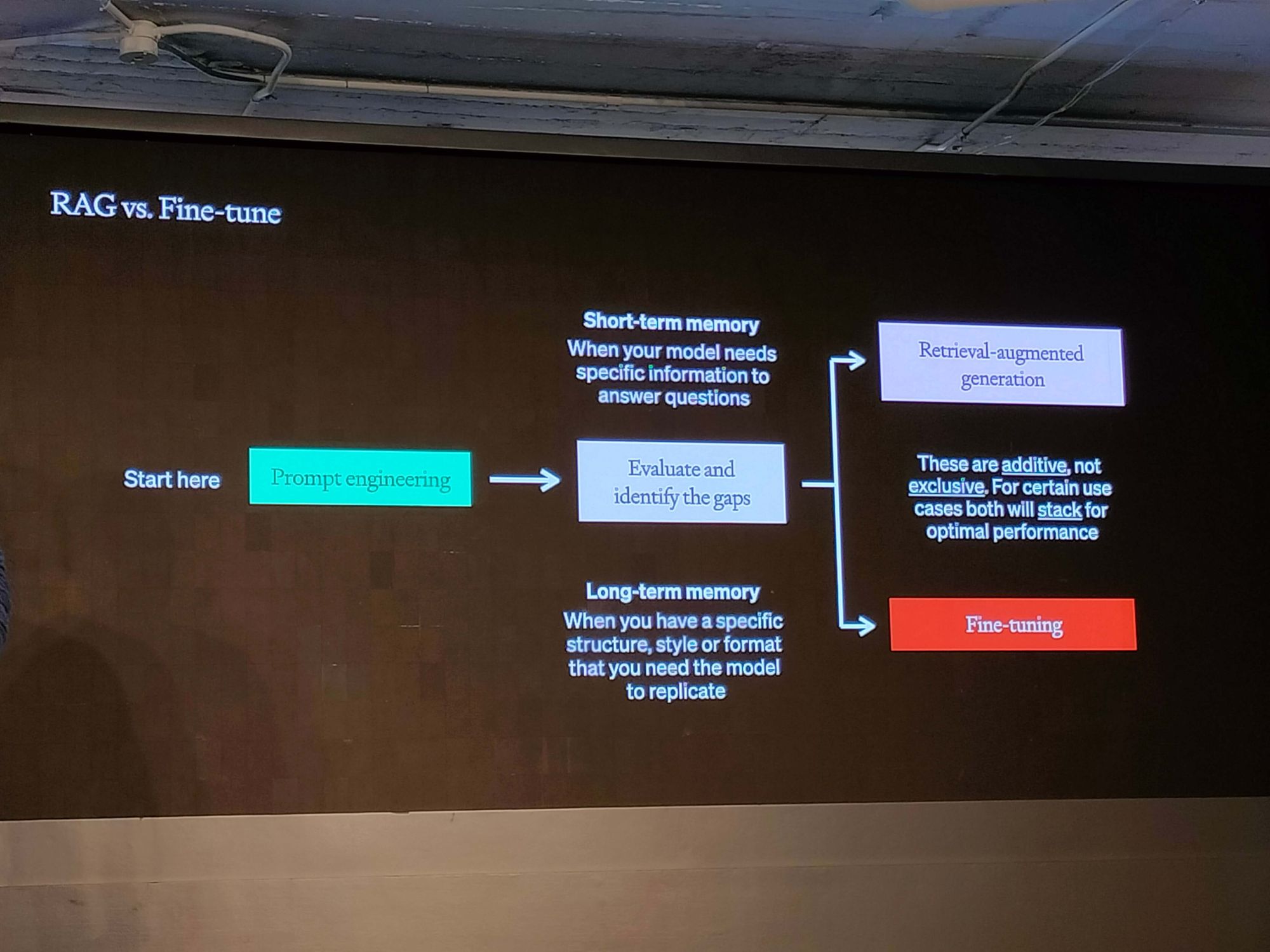
- 提示工程(Prompt Engineering): 在我们的优化矩阵中,提示工程位于左下方象限,是您迅速建立基准的关键。首先微调输入至大语言模型的提示,然后观察性能的变化。
- 检索增强生成(RAG): 位于左上方象限的 RAG 增加了更多上下文。可以从简单的检索机制开始,逐步进行微调以实现更细致的优化。
2. 大语言模型行为优化
深入探讨大语言模型应如何响应的行为优化。主要有两种策略:
- 微调(Fine-tuning): 右下象限代表微调,专门针对特定任务调整大语言模型的行为。
- 综合方法: 有时候,结合所有方法才能达到理想的性能水平。例如,将 HyDE 检索与事实核查步骤相结合。
关键在于从某处开始,进行评估,并根据结果选择另一种策略迭代。
探索的策略
提示工程:从哪里开始
明确且简洁的指令,以及将复杂任务分解成更简单的子任务,对于成功至关重要。让模型有足够的“思考时间”,并系统地测试不同方案,可以带来意想不到的提升。此外,提供参考文本和利用外部工具,也能显著增强最终的成果。

它擅长于:
- 快速测试与学习
- 为进一步的优化建立基线
它的限制:
- 引入新信息
- 模仿复杂的风格或方法
检索增强生成:拓展知识边界
通过让大语言模型 (LLMs) 接触特定领域的内容,检索增强生成(RAG)有助于更新模型的知识库,并控制生成内容的准确性。

它擅长于:
- 引入新的、特定的信息
- 控制内容以降低错误率
它的限制:
- 对广泛领域的理解
- 学习新的语言、格式或风格
增强 RAG 的方法:
- 运用余弦相似度和 HyDE 进行检索
- 尝试 FT 嵌入和数据块处理
- 执行重排序和分类步骤
评估 RAG 的标准:
- 在大语言模型方面,关注答案的准确性和相关性。
- 在内容方面,评估检索到的上下文的精准度和召回率。更多的数据并不总意味着更高的准确度。

微调:专属定制
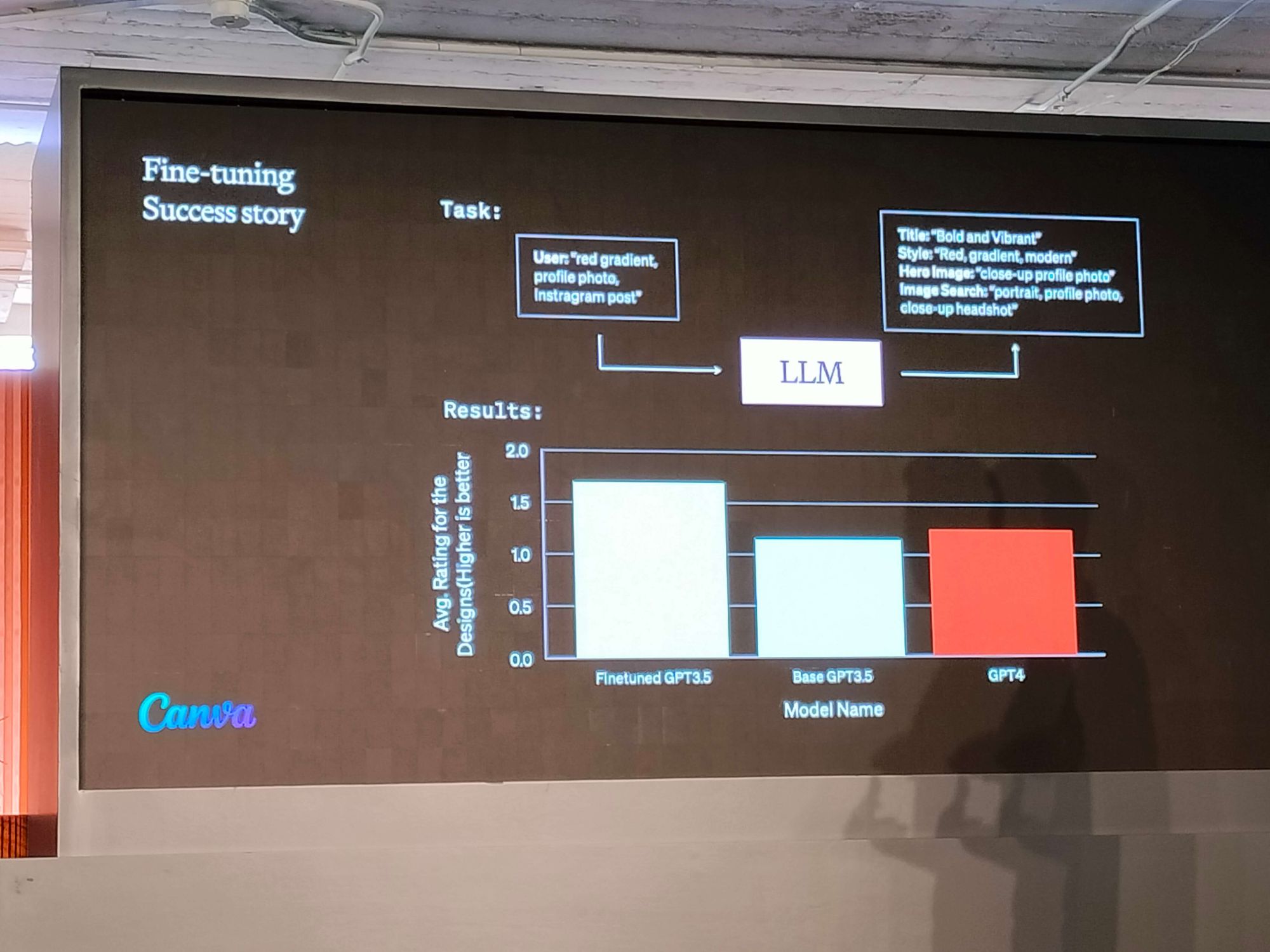
当单纯的提示设计不足以满足需求时,微调 (fine-tuning) 就显得尤为重要。继续使用特定领域的数据进行训练,可以提升模型的性能和效率。例如,Canva 就通过对 GPT-3.5 进行微调,成功生成了结构化的输出,这充分展示了高质量训练数据的强大作用。

微调的优势:
- 加强模型现有的知识基础
- 定制化回应的结构和语调
微调的局限:
- 为模型增加全新的知识
- 针对新场景的快速迭代能力
微调的步骤:
- 准备数据
- 在训练期间选择合适的超参数和理解损失函数
- 结合相关测试集和专家评价进行效果评估
微调的最佳实践:
- 首先尝试提示设计
- 明确设立基准
- 在训练数据上注重质量而非数量
结合使用微调和 RAG 的方法
有时,结合使用微调和 RAG (检索式增强生成,一种 AI 技术) 可以取得最佳效果。这种结合方法让模型以更少的 Token 理解复杂的指令,为引入更多的上下文信息创造空间,从而使性能更加强大和稳定。


实际应用在生活中的应用
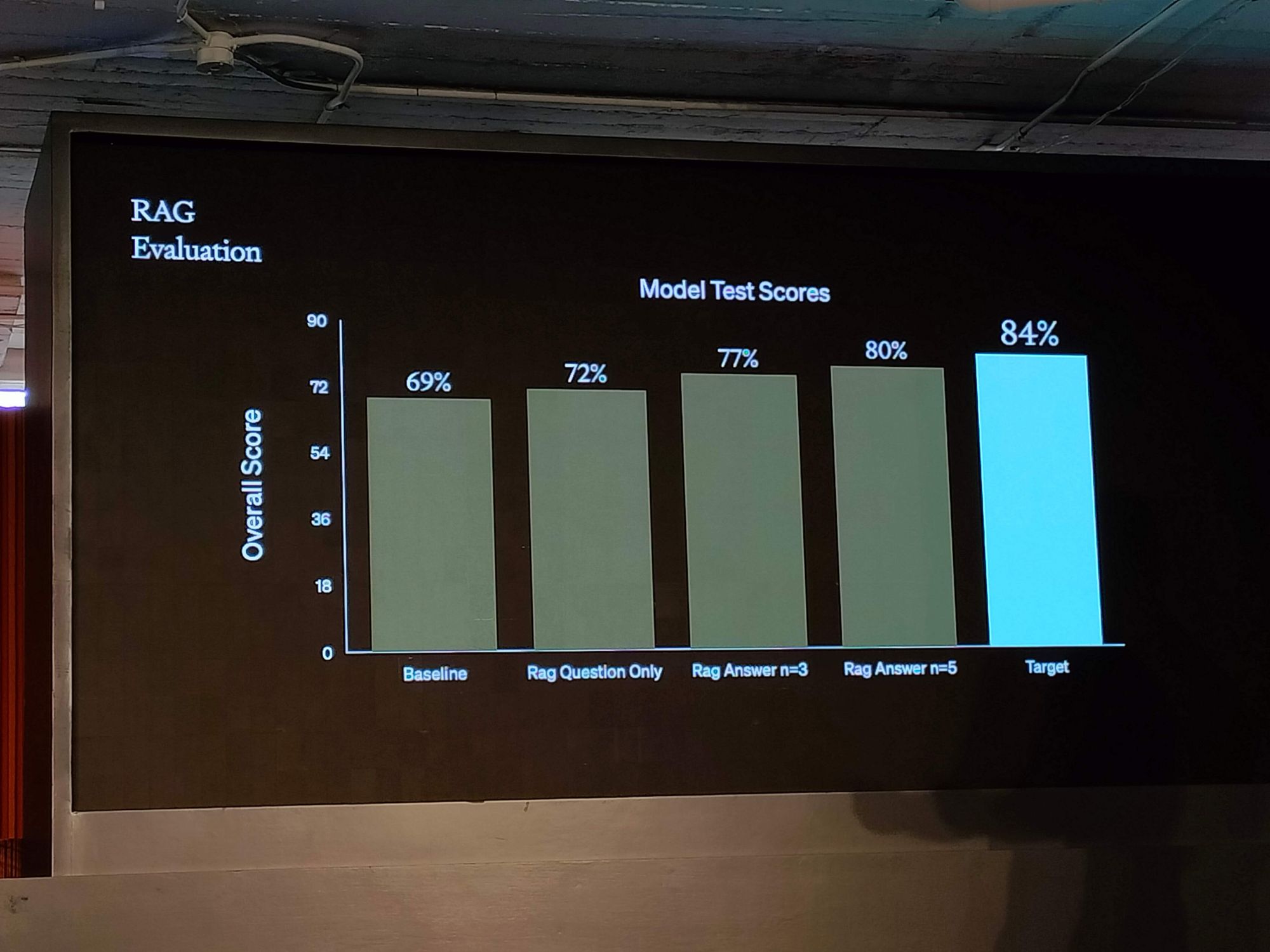
这些策略在现实生活中的应用可以非常具有创意,比如通过创造假设性的答案来增强相似性搜索的效果。举个例子,一开始的基准测试可能只有 69% 的准确率,但通过添加一个设计精良的答案的 RAG (检索增强型生成器),这个数字可以提高到 84%,相当于经过微调处理的效果。像 Scale AI 和 OpenAI 这样的合作案例,展示了如何通过结合不同方法来提升模型的效率和效果,达到新的高度。

在微调时要小心
总的来说,要想最大化大语言模型 (LLM) 的性能,并不是一个放之四海而皆准的方案。这需要一系列策略的组合,从提示工程 (prompt engineering) 到微调 (fine-tuning) 等,每一种都有其独特的优势和最适应的应用场景。