构建“Mistral 7B 微调优化版”:最优秀的 7B 微调模型 [译]
大家好!我是 Kyle,OpenPipe 的创始人。OpenPipe 是专为开发者设计的全方位微调平台。我们的用户已经通过切换到我们的微调模型,节约了超过 200 万美元的推理成本,而且上手非常快,只需几分钟。
自 9 月份推出以来,Mistral 7B 已成为我们向客户推荐最多的模型。今天,我们兴奋地宣布一个更加强大的版本:Mistral 7B 微调优化版。
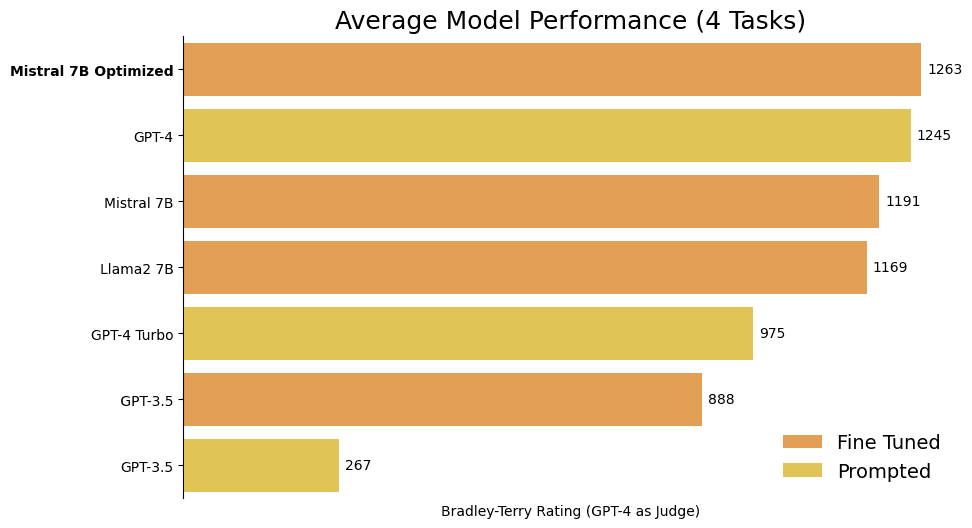
首先来看一个亮点:经过对 4 个不同客户任务的平均评估,我们新模型的微调版在 GPT-4 的评测中表现出比 GPT-4 稍微更强的性能。
接下来是更多详情!
常见问题解答
GPT-4 的规模大约是 Mistral 的 100 倍,这怎么实现的?
这个问题的答案其实很直观。像 GPT-3.5 或 GPT-4 这样的通用型模型需要精通所有领域。它们无法预知下一个指令是什么,因此必须努力包含全部人类知识。而且,每次遇到新指令时,它们都需要即兴找出合适的应对方式——它们无法深入思考问题,无法制定重复使用的解决策略,也无法记得之前解决过相同问题的经历。
而微调过程不同,它让模型能够专注于数小时的特定任务训练,学习并形成解决问题的可靠策略。即便是能力整体较弱的模型,通过这些 GPU 训练时间,微调模型也能掌握解决特定问题的高效方法,从而取得成功。[1]
既然已有众多 Mistral 微调模型,为什么还需新的一款?
目前,一个健康且多元的生态系统已涵盖众多 Mistral 微调模型。这些模型大多面向直接应用场景进行优化。然而,我们追求的是别具一格 —— 我们希望打造一个为进一步微调打好基础的优质基础模型。这一过程涉及精心优化模型对指令的理解和推理能力,同时避免“灾难性遗忘”现象,即模型在针对特定任务进行微调后,面对非领域任务时性能的显著下降。
细节剖析!
评价指标
我们首先构建了一个“测试集”,包含 3 个真实的 OpenPipe 客户任务(已获授权)。这些任务覆盖了我们最常见的类别:信息提取、分类和总结。我们的目标是发现或开发一款新模型,该模型在这些客户任务的微调基础上,不仅能在我们的评估中超越基于 Mistral 的模型,还能成为我们新的默认基础模型。
挑选模型
我们首先对现有的 Mistral 变体进行了评估,以确定它们作为基础模型的潜力。经过一番筛选,我们挑选了六款看似有潜力的模型:OpenHermes 2.5、Zephyr、Cybertron、Intel Neural Chat、Hermes Neural 以及 Metamath Cybertron Starling。我们使用 OpenPipe 的开发版本,在这三个评估数据集上为这些模型各自开发了微调版本,共计产生了 18 款新模型。

随着项目的进展,这个下拉菜单最终变得相当长。 😂
GPT-4 眼中的最佳(评价分析)
为了测试各模型的表现,我们利用了我们最近推出的自动化评价方法,这种方法以大语言模型(LLM)作为评价标准,并由 GPT-4 打分。这让我们可以迅速比较不同经过微调的模型之间的差异,并评估它们的效能。

我们发现,虽然在不同的任务中表现最佳的模型各不相同,但有一点非常有趣——两个总体上表现最出色的模型是 Hermes Neural 和 Metamath Cybertron Starling。这两个模型并非通过直接微调得到,而是采用了一种名为模型融合的技术。
神奇的模型融合 🪄🤯
对我而言,模型融合是现代深度学习领域中最让人意想不到的实践成果之一。令人惊奇的是,你实际上可以相对简单地将两个不同模型的权重结合起来,创造出一个新模型,这个新模型能够继承其“父模型”的部分或全部能力!鉴于我们手头有一些已经表现出色的模型,我们尝试将其中几个最佳模型合并,看能否打造出一个更加强大的模型。
我们最终测试了4个模型,这些模型是通过合并我们选出的候选模型并对每个模型在我们的 3 个数据集上进行微调得到的,总共产生了 12 个额外的微调模型。
在这一阶段,对所有微调过的模型在大量测试集中逐一评估感觉相当浪费资源,因为有些模型明显比其他模型表现得更好。因此,我们进行了9000次比较,比较了我们模型的输出和 GPT-4、GPT-4-turbo 以及 GPT-3.5 的输出,并使用布莱德利 - 特里排名系统对它们进行排名,这种系统在概念上类似于 Elo 评分系统。(您可以在这里查看我们的评分计算代码)。最终,我们得到的模型排名显示,其中一个合并模型表现尤为出色:

验证结果
这个结果非常振奋人心——平均而言,在我们三个示例任务中,我们的一个合并模型略微超越了 GPT-4,成为表现最强的模型!但这里存在一个问题。我们一直在相同的 3 个数据集上测试所有模型,包括合并模型,这是否意味着我们可能对这些特定任务产生了过度拟合?
为了解决这个疑问,我们选择了一个之前完全未使用的新客户数据集(一项结构化数据提取任务)。我们在这个新数据集上训练了我们的新合并模型以及一个基础 Mistral 模型,以验证它们的强劲性能是否能够适用于新任务。令人兴奋的是,结果依然稳定!

我们的旅程才刚开始
今天,我们兴奋地宣布 Mistral Fine-Tune Optimized 将在 Hugging Face 上免费发布,并成为 OpenPipe 中的新默认基础模型。我们迫不及待想看到用户如何利用它,但这仅仅是一个起点。未来,我们将持续推出更加强大、更快速、更经济的基础模型。我们期待与小型模型社区共同成长!
————
[1]: 另外,我们在与客户合作过程中发现了一个更令人兴奋的结果:一个学生模型,若在教师模型生成的数据上进行训练,有可能超越教师模型在特定任务上的表现。我们有几位客户在 GPT-4 生成的数据上训练了模型,结果发现这些新模型在特定任务上的表现竟然优于 GPT-4。这可能是因为一种规则化作用——经过微调的模型倾向于给出类似于 GPT-4 在多次尝试中可能给出的“平均”答案。这一发现虽与 OpenAI 最近发布的关于弱到强泛化的研究不同,但却有所关联。