令人难以置信!用这项新技术在仅有 4GB GPU 的设备上运行 70B 大语言模型推理 [译]
![令人难以置信!用这项新技术在仅有 4GB GPU 的设备上运行 70B 大语言模型推理 [译]](/images/llm/unbelievable-run-70b-llm-inference-on-a-single-4gb-gpu-with-this-new-technique/1_H7xkrF-6ryxIcUPNwnQ4Xg.png)
Gavin Li,11 月 18 日
通常,大语言模型需要大量的 GPU 内存才能运行。但是,有没有可能仅用单个 GPU 来进行推理计算呢?如果可以,最少需要多少 GPU 内存呢?
比如说,一个拥有 70B 参数的大语言模型,其大小达到了惊人的 130GB。光是要把这个模型加载到 GPU 上,就需要两个各有 100GB 内存的 A100 GPU。
而在实际进行推理计算时,整个输入序列还需要被加载进内存中,以便进行复杂的“注意力”运算。而这种注意力机制对内存的需求是随着输入长度成二次方增长的。这意味着除了本来的 130GB 模型大小之外,还需要更多额外的内存。
那么,有什么技术可以在仅有 4GB GPU 内存的情况下,节约如此巨大的内存需求,实现推理计算呢?
值得注意的是,这里所说的内存优化技术并不涉及任何可能损害模型性能的模型压缩手段,比如量化、蒸馏或剪枝等。
今天我们将为您揭秘这些用于大型模型的极端内存优化的关键技术。
文章的最后,我们还将分享一个开源库,您可以通过简单几行代码就能实现这一切!
01
分层推理技术
其中最关键的技术是分层推理。这实际上是计算机科学中经典的分而治之策略。
让我们先来看看大语言模型的架构。如今的大语言模型都是基于谷歌在“Attention is all you need”一文中提出的多头自我注意力结构,这就是后来大家熟知的 Transformer 结构。
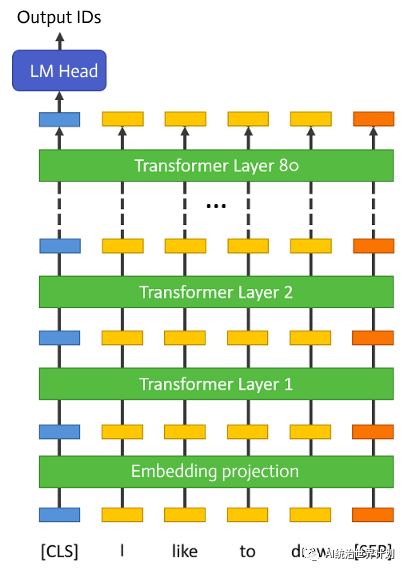
一个典型的大语言模型,其起始是一个嵌入投影层,接着是 80 个结构完全一致的 Transformer 层,最后是一个用于预测 Token ID 概率的规范化层和全连接层。
在推理过程中,这些层会依序执行,每一层的输出都会成为下一层的输入。在任何时刻,只有一个层在执行。
因此,实际上没有必要把所有层都保留在 GPU 内存中。我们可以根据需要从磁盘加载相应的层进行计算,并在计算完成后立即释放内存。
在这种情况下,每层 GPU 所需的内存仅约为一个 Transformer 层的参数大小,大约占整个模型的 1/80,大约为 1.6GB。
除此之外,GPU 内存中还存储了一些输出缓存,其中最大的是为了避免重复计算而设的 KV 缓存。
以 70B 模型为例,我们简单算一下这个 KV 缓存的大小:
2 * 输入长度 * 层数 * 头数 * 向量维度 * 4
假设输入长度为 100,这个缓存的大小就是 2 * 100 * 80 * 8 * 128 * 4,也就是 30MB 的 GPU 内存。
根据我们的监测数据显示,整个推理过程中 GPU 内存的使用量不超过 4GB!
02
单层优化 — 闪电注意力(Flash Attention)
在当今大语言模型的发展中,闪电注意力技术可谓是一项至关重要且关键的优化手段。
市面上的各种大语言模型基本上都是基于相同的底层代码构建的,而闪电注意力则是其中最显著的提升。
闪电注意力的概念虽不全新,但我们不得不提及另一篇研究论文《自我注意力不需要 O(n²) 的内存》。
传统的自我注意力机制需要 O(n²) 的内存(其中 n 是序列长度)。
而这篇论文则提出,我们实际上不需要保留这些 O(n²) 的中间结果。我们可以顺序计算这些结果,持续更新一个中间结果,并丢弃其余所有。这样做将内存复杂度降至 O(logn)。
闪电注意力在本质上与此相似,尽管其内存复杂度略高,为 O(n),但 它通过深度优化 cuda 内存访问,大幅提升了推理和训练的速度。

如图所示,传统的自我注意力会计算并存储 O(n²) 的中间结果。而闪电注意力则将这一过程划分为多个小块,逐块计算,从而将所需内存减少到一个块的大小。
03
模型文件分片处理
一般来说,原始的模型文件会被分成多个部分,每部分大约为 10GB。
我们的处理方式是按层逐步进行。每一层仅需 1.6GB。如果按照原始的 10GB 分片来加载,每执行一层就需要重新加载整个 10GB 的文件,而实际上只用到了其中的 1.6GB。
这样会导致大量内存和磁盘读取资源的浪费。事实上,磁盘读取速度是整个推理过程中最大的瓶颈,因此我们尽可能地减少这一过程。
首先,我们对原始的 HuggingFace 模型文件进行了预处理,将其按照不同的层级进行分片。
在存储方面,我们采用了 safetensor 技术(https://github.com/huggingface/safetensors),它确保了存储格式与内存格式的紧密匹配,并利用内存映射技术来加载数据,以此来提高速度。
04
Meta Device(元设备)
在实现过程中,我们利用了 HuggingFace Accelerate 提供的元设备特性(https://huggingface.co/docs/accelerate/usage_guides/big_modeling)。元设备是一个专为运行超大型模型设计的虚拟设备。通过元设备加载模型时,并不会实际读取模型数据,只加载代码,因此内存的使用量为零。
在执行过程中,您可以将模型的部分内容从元设备动态转移到真实的设备,如 CPU 或 GPU,此时数据才会真正加载到内存中。
使用 init_empty_weights() 函数,可以通过元设备来加载模型。
from accelerate import init_empty_weightswith init_empty_weights():my_model = ModelClass(...)
05
开源库
我们将所有相关代码开源 —— AirLLM。这使您能够通过几行代码来实现上述功能。
相关代码可在 Anima 的 GitHub 页面找到:https://github.com/lyogavin/Anima/tree/main/air_llm。
使用过程非常简单。首先,您需要安装相关软件包:
pip install airllm
之后,您就可以像操作普通 Transformer 模型那样进行分层推理。
from airllm import AirLLMLlama2MAX_LENGTH = 128# 我们可以使用 hugging face 提供的模型仓库 id 来加载模型:model = AirLLMLlama2("garage-bAInd/Platypus2-70B-instruct")# 或者直接使用本地路径加载模型...#model = AirLLMLlama2("/home/ubuntu/.cache/huggingface/hub/models--garage-bAInd--Platypus2-70B-instruct/snapshots/b585e74bcaae02e52665d9ac6d23f4d0dbc81a0f")input_text = ['美国的首都是哪里?',]input_tokens = model.tokenizer(input_text,返回张量="pt",不返回注意力掩码=True,截断=True,最大长度=MAX_LENGTH,填充=True)generation_output = model.generate(input_tokens['input_ids'].cuda(),最大新增令牌=20,使用缓存=True,返回生成字典=True)output = model.tokenizer.decode(generation_output.sequences[0])print(output)
我们在一块 16GB Nvidia T4 GPU 上进行了代码测试。整个生成过程只使用了不到 4GB 的 GPU 内存。
需要注意的是,像 T4 这样的低端 GPU 在处理生成任务时速度会较慢。它并不适合需要实时交互的场景,例如聊天机器人,更适合进行一些离线数据分析,比如文档分析或 PDF 处理等。
目前,我们只支持基于 Llam2 的模型。如果您需要其他模型的支持,请告诉我们!
06
70B 大小的训练数据能否在单个 GPU 上完成?
尽管我们可以通过分层技术优化生成任务,但训练任务是否能在单个 GPU 上以类似方式进行呢?
在生成任务中,只需要使用前一层的输出来执行下一层的 Transformer,所以在数据有限的情况下是可以进行分层执行的。
但训练任务需要处理更多数据。它首先执行前向传播,以获得每个层和张量的输出,然后执行反向传播,计算每个张量的梯度。
由于梯度计算需要保存前向层的结果,所以分层执行并不会减少内存使用。
当然,还有一些其他技术,如梯度检查点,可以达到减少内存使用的效果。
如果您对梯度检查点如何显著降低训练内存需求感兴趣,请告诉我们!
07
在编写我们的代码时,我们广泛借鉴了 SIMJEG 在 Kaggle 平台上的成果:https://www.kaggle.com/code/simjeg/platypus2-70b-with-wikipedia-rag/notebook。在此,我们要向 Kaggle 社区的卓越贡献表示感谢!
我们会持续分享最新、最有效的人工智能技术和发展动态,致力于为开源社区贡献力量。敬请关注我们的最新动态。