4 个 GPT-4 Vision 的开源替代方案 [译]
Youssef Hosni
免费开源替代品探索指南:寻找 GPT-4 Vision 的替代方案
GPT-4 Vision 凭借其在语言理解和视觉处理方面的卓越能力,已成为该领域的重要参与者。然而,对于那些追求高性能却又不想花大价钱的人来说,开源解决方案提供了众多选择。
在这份指南中,我们将为您介绍四款开源的 GPT-4 Vision 替代方案,它们不仅易于获取,还具有很好的适应性。
我们将详细探讨四个开源视觉语言模型:LLaVa(大型语言和视觉助手),CogAgent,Qwen 大型视觉语言模型(Qwen-VL),以及 BakLLaVA。这些模型各具特色,并有潜力在语言与视觉处理领域大放异彩。

1. LLaVa(大型语言和视觉助手)
LLaVA 代表了一种创新的、从头到尾训练的大型多模态(multimodal)模型。它融合了视觉编码器和 Vicuna,旨在实现通用的视觉和语言理解。LLaVa 在模仿多模态 GPT-4 的功能方面表现出色,并在科学问答(Science QA)方面达到了新的最高精准度。
LLaVA 是一款仅限非商业用途的研究预览版产品。使用该产品需遵守 LLaMA 的模型许可、OpenAI 生成数据的使用条款以及 ShareGPT 的隐私政策。用户在使用本服务时,需同意其为研究预览版,仅限非商业用途。该服务只提供有限的安全保护,可能产生冒犯性内容。不得将其用于任何非法、有害、暴力、种族主义或性相关目的。此外,服务可能会收集用户对话数据,用于未来的研究。
以下是一些视觉指令的实例:
- 视觉推理
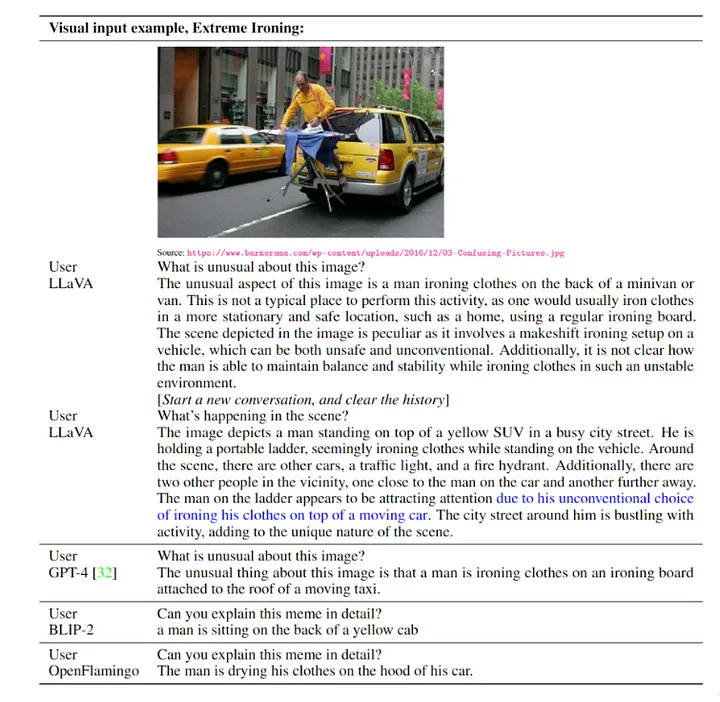

- 光学字符识别(OCR)

2. CogAgent
CogAgent 是一个基于 CogVLM 进行改进的开源视觉语言模型(Visual Language Model)。CogAgent-18B 模型包含了 110 亿视觉参数和 70 亿语言参数。
CogAgent-18B 在 9 大经典的跨媒介基准测试中表现卓越,这些测试包括 VQAv2、OK-VQ、TextVQA、ST-VQA、ChartQA、infoVQA、DocVQA、MM-Vet 和 POPE 等。它在处理像 AITW 和 Mind2Web 这样的图形用户界面(GUI)操作数据集时,性能远超现有模型。
除了 CogVLM 已有的功能,如能进行基于视觉的多轮对话和对视觉内容进行准确定位,CogAgent 还新增了以下特点:
- 支持更高分辨率的视觉输入和对话式问题解答,可以处理高达 1120x1120 分辨率的图像。
- 具备视觉智能体的能力,可以针对任何图形用户界面截图,提供任务计划、下一步操作指南及具体操作的坐标信息。
- 加强了针对图形用户界面的问答能力,能够处理关于各种界面截图(如网页、PC 应用、移动应用等)的问题。
- 通过更高效的预训练和微调,提升了在光学字符识别(OCR)相关任务上的表现。
图形用户界面智能体示例

3. Qwen 大型视觉语言模型 (Qwen-VL)
Qwen-VL (Qwen 大型视觉语言模型) 是阿里巴巴云推出的大型模型系列 Qwen(简称 Tongyi Qianwen)的多模态版本。Qwen-VL 能够处理图像、文本和边界框这些不同类型的输入,并输出文本和边界框。Qwen-VL 的主要特点有:
- 卓越的性能:在包括零样本 (Zero-shot) 图像描述、视觉问答 (VQA)、文档视觉问答 (DocVQA) 和图像定位 (Grounding) 等多个英语评估指标上,Qwen-VL 显著优于其他相似规模的开源大型视觉语言模型。
- 支持多语言文本识别的视觉语言模型:Qwen-VL 不仅支持英语和中文,还能处理多种语言的对话。特别在图像中的中英双语文本识别方面,实现了端到端的高效处理。
- 多图交织对话功能:这项功能使得 Qwen-VL 能够处理多张图像的输入和比较,用户可以针对这些图像提出相关问题,甚至进行多图像串联的故事叙述。
- 第一个支持中文图像定位的通用模型:Qwen-VL 能够通过开放领域的语言表达,在中文和英文中识别和标记图像中的边界框。
- 细腻的识别和理解能力:相较于其他开源视觉语言模型目前使用的 224*224 分辨率,Qwen-VL 的 448*448 分辨率更有助于精细化的文本识别、文档问答和边界框标注。
4. BakLLaVA
BakLLaVA 1 是一种新型 AI 模型,它基于原有的 Mistral 7B 模型,并融合了最新的 LLaVA 1.5 架构技术。在这个初始版本中,开发者们展示了这一模型在多个性能测试中相较于 Llama 2 13B 模型有更出色的表现。你可以在他们的GitHub 仓库中找到并试用 BakLLaVA-1。目前,他们正努力更新这一模型,使用户能更容易地对它进行个性化调整和数据分析。
BakLLaVA-1 是完全开放源代码的,但它的训练过程中使用了特定的数据集,包括 LLaVA 的语料库,这些数据并不适合商业用途。目前,BakLLaVA 2 正在研发中,它将使用一个更大的、适合商业应用的数据集,并采用一种创新的架构设计,以超越现有的 LLaVA 方法。BakLLaVA-2 的出现预计将消除 BakLLaVA-1 目前面临的一些使用限制。