WhisperKit [译]
Whisper 项目已经让我们看到了一个不远的未来:快速、免费并且几乎没有错误的翻译和转录技术无处不在。这一进步激励了许多开发者在保证最大性能的同时,以最少的阻力改进并部署这一技术。
iPhone 12 mini 和 iPhone 15 Pro 利用 WhisperKit 转录了 MKBHD 的内容。视频播放未进行加速处理,而是将 MKBHD 的播放速度设置为 1.5 倍,因为 WhisperKit 的转录速度受限于 MKBHD 说话的速度。
我们在 2023 年 11 月成立了 Argmax 公司,旨在赋能全球的开发者和企业能够在用户设备上部署商业级别的计算负载。对生产环境中 Whisper 推理的日益增长的需求促使我们选择它作为我们的首个项目。
今天,我们非常兴奋地宣布:WhisperKit 项目现以 beta 版本形式,在 MIT 许可下开放源代码!
-
Swift 包:仅需两行代码,即可在应用中实现 Whisper 推理功能
-
示例 App:支持 iOS 和 macOS,可通过 TestFlight 体验
-
Python 工具:用于在 Mac 上优化和评价 Whisper 性能
我们推出这个 beta 版本的目的,是为了收集开发者的反馈,并在未来几周内迅速迭代,达到稳定版发行候选,从而加速 WhisperKit 在设备上推理的实践应用!
加入我们的行动
如果你感兴趣...
-
获取技术概览:请继续阅读本文的剩余部分。如果你有任何反馈,欢迎与我们联系。
-
在你的应用中试用 WhisperKit:只需在 Xcode 中添加包依赖,即可轻松部署:
let pipe = try await WhisperKit(model: "large-v3")let result = try await pipe.transcribe(audioPath: "test.")?.text
查看源代码WhisperKit.swift —— 由 GitHub 提供托管
只是想了解更多? 简单地下载我们的示例应用,并加入我们的 Discord,提出你的问题,认识 Argmax 团队!
设计理念
我们创建 WhisperKit 的宗旨是:
- 灵活性。 用户可以灵活组合或单独使用 GPU 和 Neural Engine。在 iPhone 上,单独使用 Neural Engine 可以实现最优的能效和最低的延时。而在 Mac 上,多个 WhisperKit 进程能够独立地同时利用 GPU 和/或 Neural Engine,以实现批量处理的最高效率(参见 asitop 提供的图示)。对于依赖电池供电的 Mac 而言,单独使用 Neural Engine 同样可以达到高效的能源利用。
配置 1: WhisperKit 命令行工具在 Mac Studio 上同时使用 GPU 和 ANE 处理 16 个音频文件
配置 2: 同上,但仅使用 ANE(其余进程占用约 14% 的 GPU 资源,ANE 处理过程中出现绿色条溢出)
配置 3: 同上,但仅使用 GPU
-
可扩展性。 通过 Swift 协议的模块化设计,用户可以简单地通过协议扩展来实现定制化功能。我们还优化了代码的易读性,使得扩展 WhisperKit 变得更加简单直接。贡献指南和发展路线图旨在为开发者提供一个明确的时间表,帮助他们了解项目达到功能完善和稳定发布的预期时间。
-
可预测性。 我们采用了以精准度为核心的开发策略,通过内部测试基础设施对代码和模型提交进行验证,涵盖了 Whisper 准确性评估的基准测试,这包括了 librispeech 数据集(大约 2.6k 短音频,总时长约 5 小时)和 earnings22 数据集(大约 120 长音频,总时长约 120 小时)。我们定期发布测试结果于此处,这使我们能够及时发现和处理因 WhisperKit 更新或底层软件堆栈变化引起的质量下降或性能问题。这样不仅缩短了问题发现和修复的时间,还提升了整体的工作效率。更进一步,我们对开发者和企业提供客户级服务协议,承诺在规定时间内解决所有特定模型和设备版本的问题。
-
自动部署功能。 我们已经在这里上线了许多兼容 WhisperKit 的模型。WhisperKit 提供了一系列 API,用于列出此服务器上的特定版本并进行下载。我们的示例应用就是基于这套在线部署架构构建的。此外,开发者还可以通过 whisperkittools(一套 Python 工具包)来发布自定义 Whisper 版本,对其在私有数据集上进行评估,并在生产环境中进行部署和服务。
性能焦点:实时性
WhisperKit 的目标是在苹果硅芯片上同时实现最低延迟与最高吞吐量。在今天的测试版发布中,我们优先考虑最低延迟,目的是为 iPhone、iPad 和 Mac 提供流式语音转写功能。
实现实时速度的流式语音转写非常有挑战性,因为 Whisper 原本不是为了处理低延迟音频而设计的。在转写出第一个文本片段之前,需要进行以下步骤:
步骤 1: 定期收集足够多的音频,以形成一个清晰的语音片段,比如 1-2 秒。这会造成一定的延迟,不论处理速度如何。
步骤 2: 根据现有的历史音频数据量,调整音频长度至 Whisper 需求的片段长度,即 30 秒。
步骤 3: 对这段 30 秒的音频片段,使用 0.6b Transformer 编码器处理,相当于处理了 1500 个音频片段。
步骤 4: 在步骤 3 的结果基础上,通过 1b Transformer 解码器处理 4 个特殊片段,以设置语言和任务参数。
步骤 5: 最后产出第一个文本片段!然后继续输出文本片段,直到出现特定的结束符号。
从步骤 1 到 4 的总延迟,决定了从开始到第一个文本片段产出的时间,这是评估交互式语音转写体验反应速度的一个重要指标。
步骤 5 的速度,即每秒可以产出多少文本片段,是衡量语音转为文本速度的一个指标。
在用户结束转写会话之前,将持续对实时录制的音频数据重复上述五个步骤。
如果这五个步骤的总延迟小于或等于音频片段的长度,那么可以认为推理是实时的。例如,如果转写流程(步骤 1-5)每秒执行一次,且仅需 500 毫秒即可完成,则推理速度是两倍的实时速度(即 0.5 实时因子,以倒数形式表示)。
如果推理速度稍慢于实时,音频数据会积压,处理速度赶不上数据产生的速度。这种情况下,积压的数据会越来越多,直到用户因为延迟太高而停止说话,或是系统不得不丢弃一些过时的音频数据。
我们从头到尾对 Whisper 处理流程进行了优化,以尽量避免这种不希望发生的情况。由于实时性受到说话速度的影响,我们无法保证所有情况下都能实现实时处理。但我们会尽可能优化处理流程,以确保最大限度地提高每个音频片段的文本输出量。
特别是,我们将重点放在 openai/whisper-large-v3 版本,因为迄今为止,这是最具挑战性的部署版本。我们的出发点是假设有 1 秒钟转录 1 秒语音 的预算。
提速音频编码器
在 第三步 中提到的音频编码器,之前已通过 whisper.cpp 项目利用 Core ML 进行了优化,这是依据 在苹果神经引擎上部署 Transformer 的实践。简而言之,该项工作通过引入一系列 作为 PyTorch 代码的神经引擎编译器提示,一旦转化为 Core ML,便能够实现高性能的模型。考虑到神经引擎编译器是苹果公司的专有技术,这种优化方法可以看作是一种黑盒策略,旨在提高硬件的利用率。
这为加快 Whisper 音频编码器的速度提供了一个良好的起点,我们很高兴地看到,我们以前的工作被许多开源项目采纳。
在 WhisperKit 中,我们对这些编译器提示进行了进一步改进,相较于以往的最佳实现,在 iPhone 12 到 15 上实现了 1.86 倍到 2.85 倍 的速度提升:
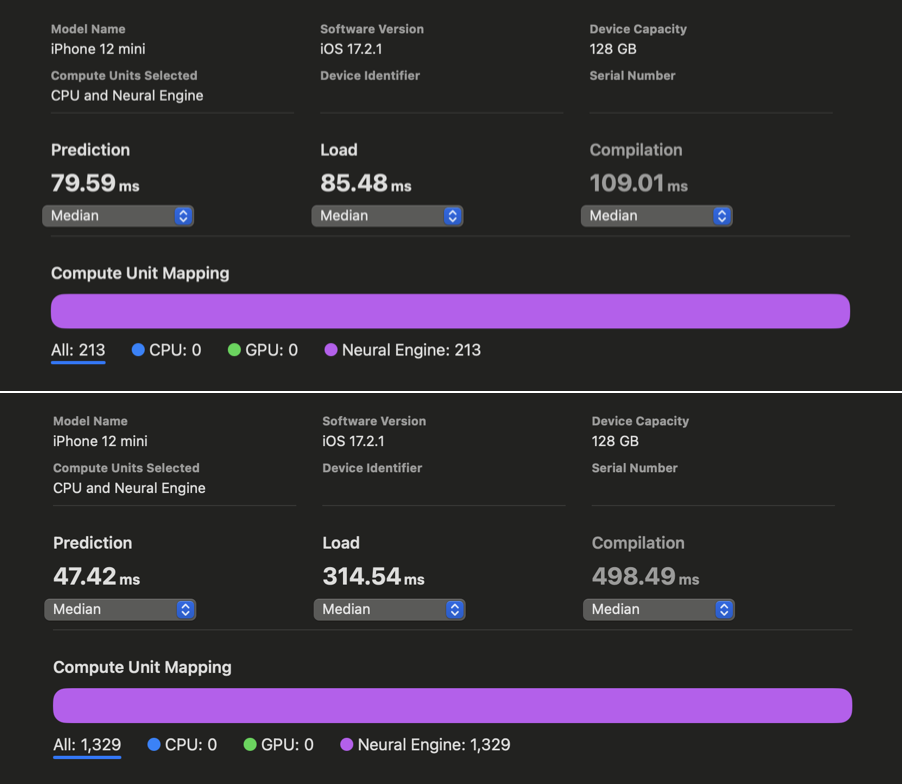
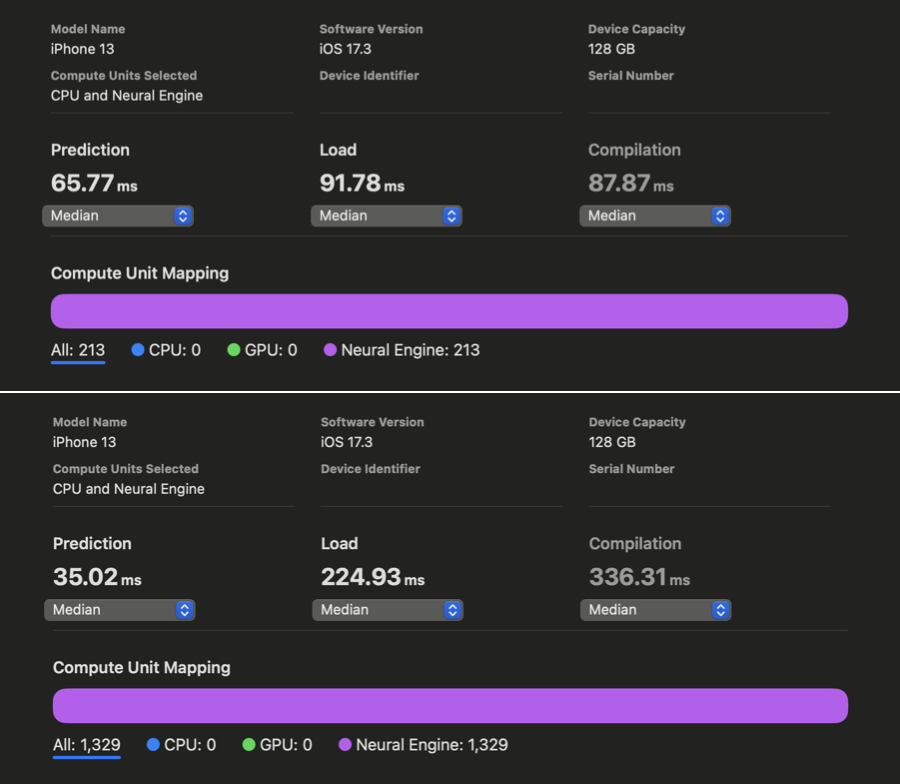
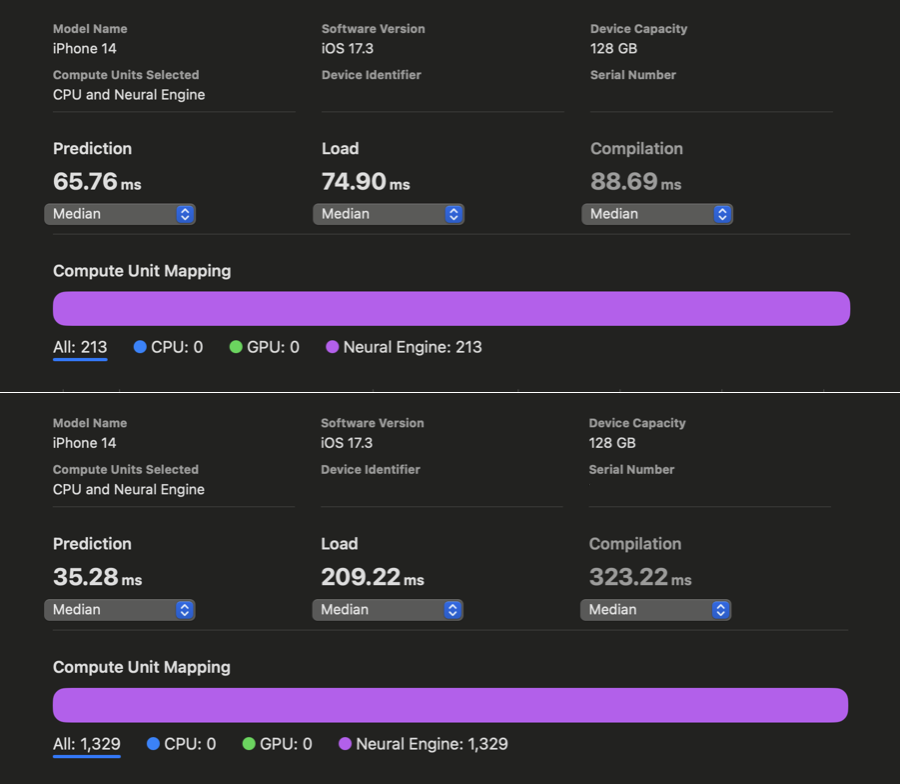
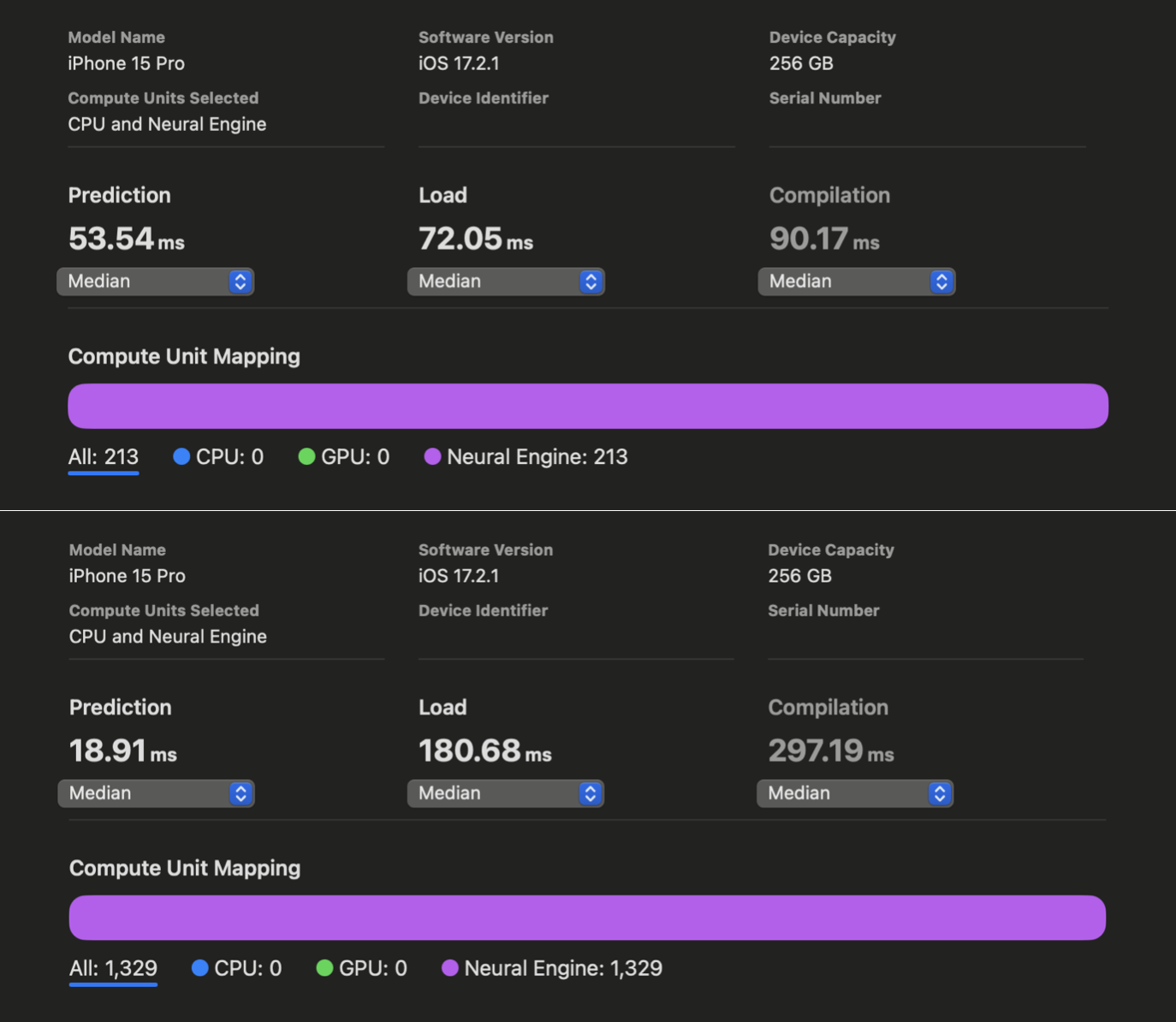
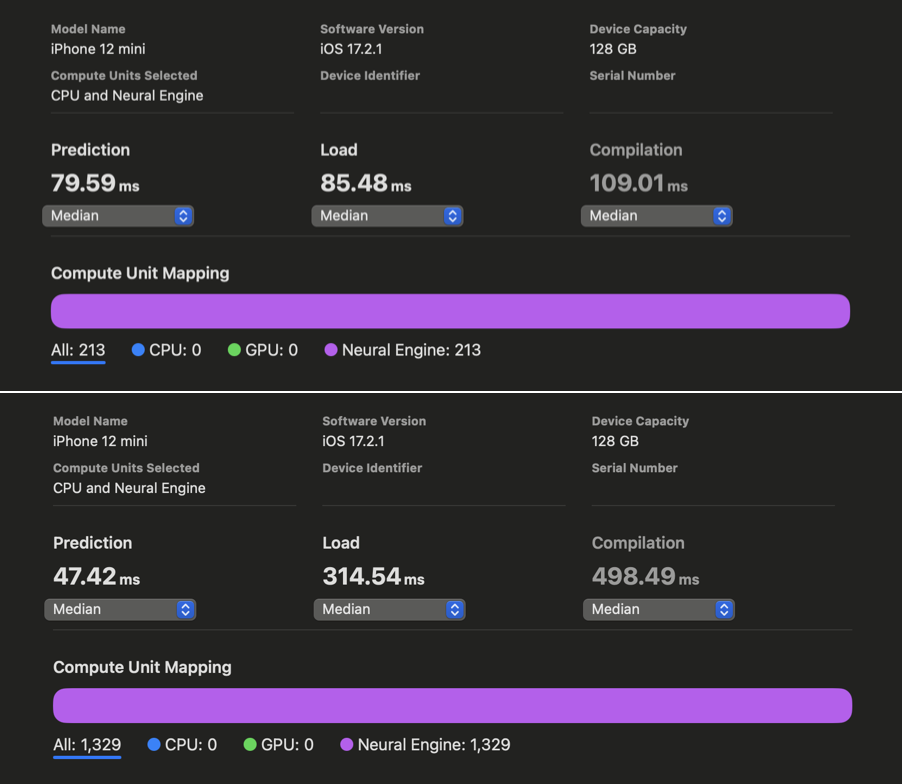
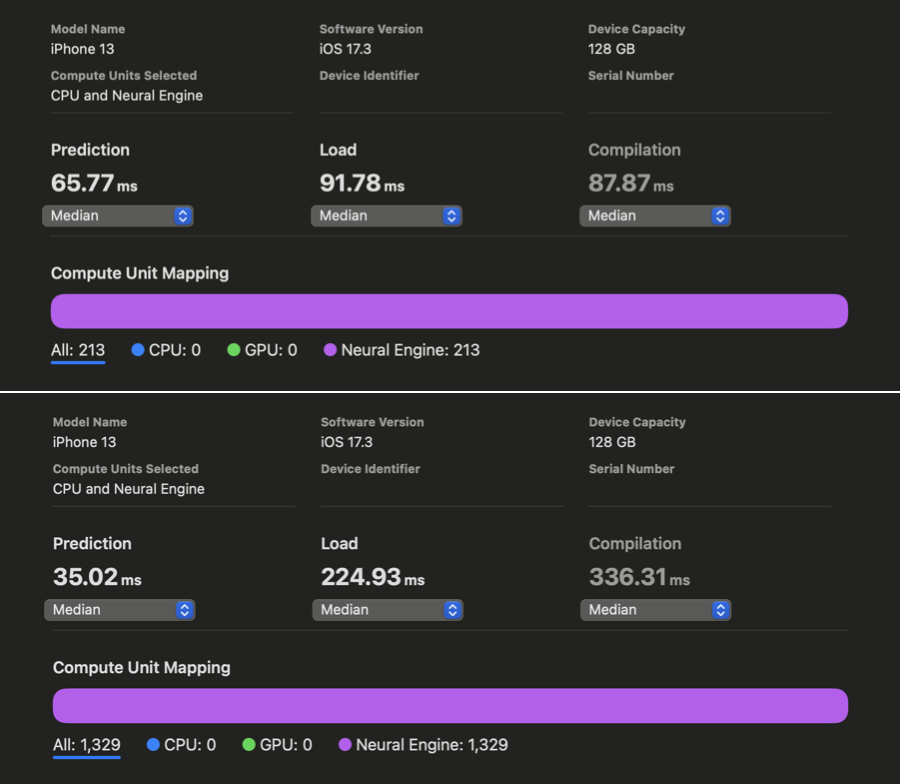
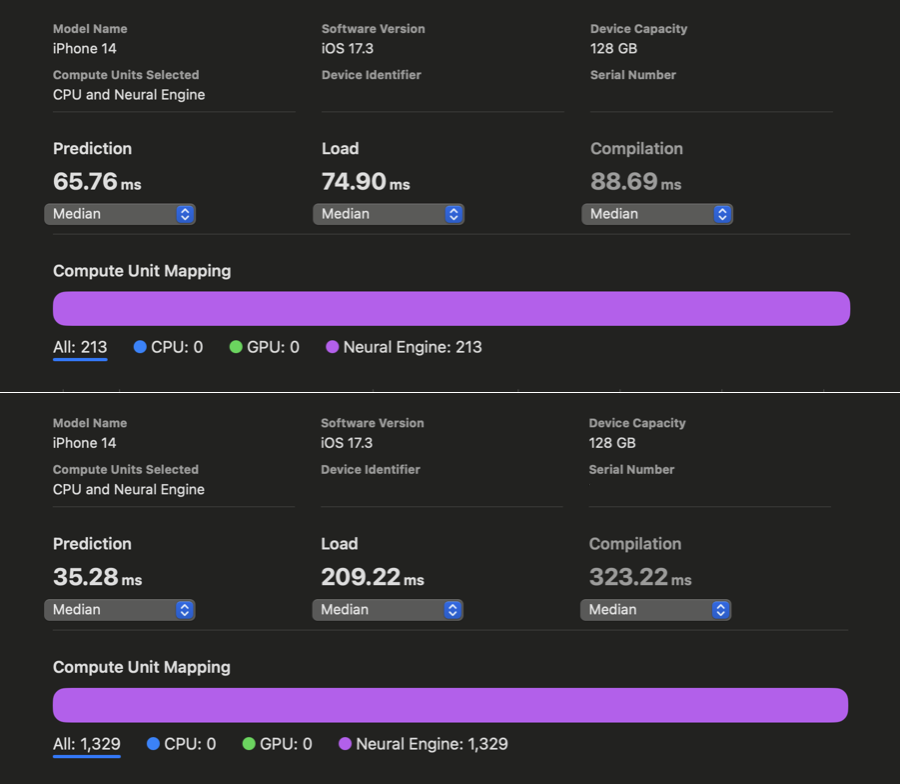
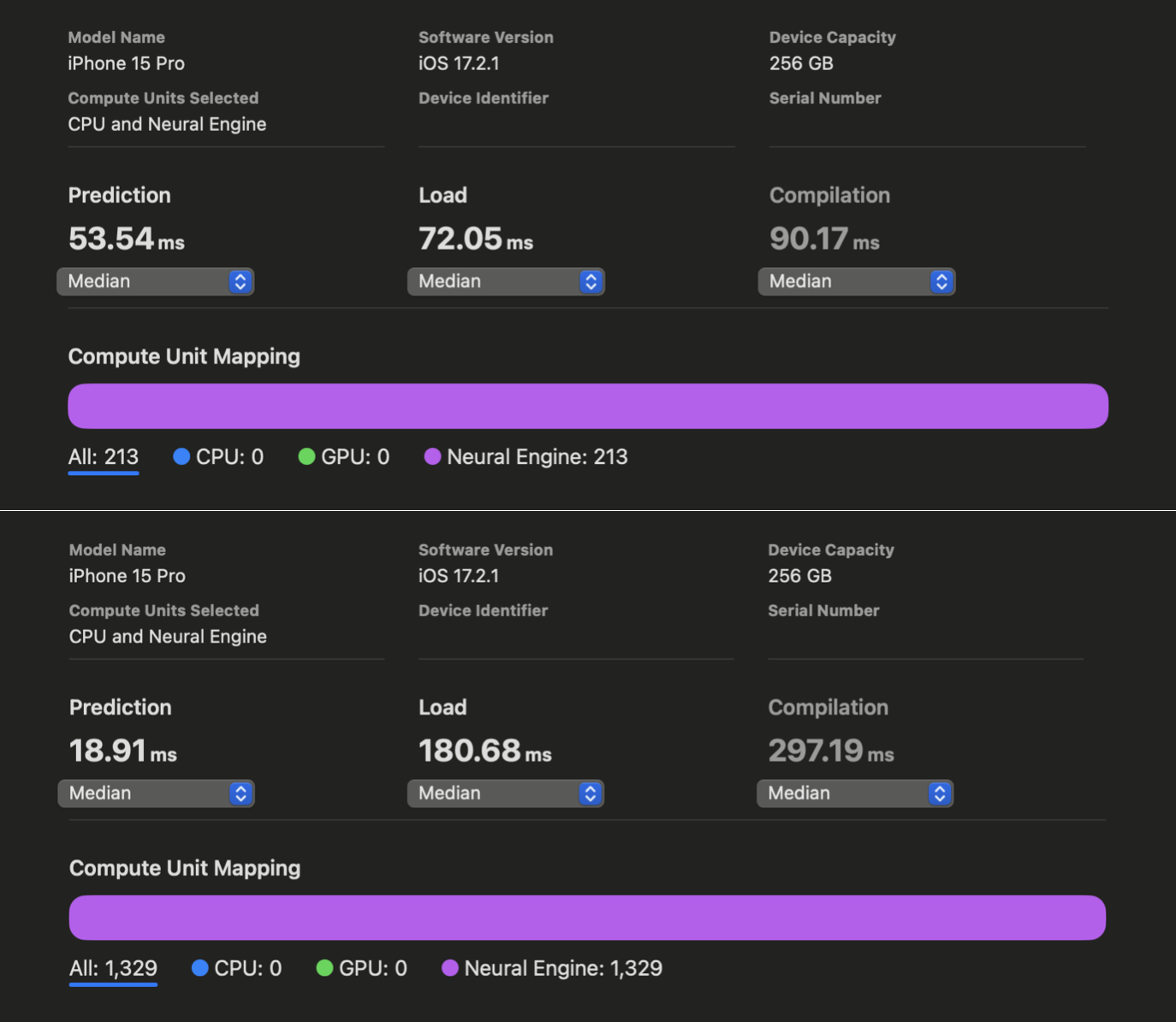
在 Xcode Core ML 的性能报告中,我们可以看到在对 openai/whisper-base 进行优化之前和之后,AI 的预测反应时间有了明显改善。虽然我们没能为 iPhone 上的 large-v3 版本生成同样的报告,但根据我们的实际使用测试,openai/whisper-large-v3 在 iPhone 上的响应速度提高了将近两倍,延迟时间减少到只有大约 350 毫秒(之前大约是 650 毫秒)。这项改进意味着,在处理语音指令时,我们现在能够比原计划快近 300 毫秒,从而有更多时间来处理更复杂的指令。我们现在还有 650 毫秒的时间可以用来开始解码过程。
值得一提的是,我们特地为这些经过优化的模型加上了“turbo”后缀,以此来区别我们针对 GPU 开发的不同版本(想了解更多详情,请联系我们)。
让文本解码更快
我们不仅对音频编码器进行了优化,还特别将文本解码器调整到了 iPhone 的 Neural Engine 上,这一改进让 iPhone 在运行时既能节能又能大幅减少延迟。
我们还在原有基础上大幅提升了混合位调色板技术(MBP)的准确性保持能力,并额外推出了模型的量化版本,以及其原始的 float16 格式,目的是为了降低内存占用。这项优化虽然是可选的,但所有 Mac 设备都能通过 float16 精度支持各种 Whisper 变体。只有在 RAM 较少的旧版 iPhone 上运行 large-v3 模型时,才需要进行数据压缩。考虑到这一压缩并非无损,我们引入了一个新的概念:推理质量(QoI),并对所有进行压缩的模型版本进行了此项评估。关于 QoI 的更多详情和背景信息,可以查阅这里。
除了帮助节省内存,这种压缩方式还能被 Neural Engine 直接加速,尤其是在文本解码过程中,因为压缩后的模型权重能够针对那些通常受到带宽限制的任务提供加速效果。
经过这些优化后,文本解码器在不同设备上的响应时间可以控制在 50 至 100 毫秒之间,这让我们有可能在剩余的 650 毫秒处理时间内,生成6 至 12 个文本标记。
针对特殊令牌的 KV 缓存预计算
在最后,我们注意到,文章开头的几个令牌是特殊令牌,它们与语言及任务设定有关,但和语音内容本身无关。一种思路是,我们可以在编译时就预先完成这些令牌所需的前向计算,并将结果存入 KV 缓存,这样就无需在处理每个音频片段时重复这一计算过程。通过这种方式,我们能够实际增加 3 个文本令牌的计算,而不是每次都重新计算这些特殊令牌。这也能将获得首个令牌的时间延迟缩短至多达文本解码器前向计算时间的三分之一。
然而,与这些特殊令牌相关的 KV 缓存值也取决于音频输入,而音频输入只在运行时才可得。尽管如此,我们深信,由于因果遮蔽和内容无关的梯度平均计算,Whisper 训练目标不会使音频嵌入与这些特殊令牌相关的 KV 缓存值产生强烈的相关性。我们通过对一系列随机输入数据(而不是真实音频编码)进行预计算 KV 缓存值来验证这一直觉,并创建了一个查找表,在推理时用以替代运行文本解码器的过程。
我们通过重新进行所有评估并将此优化纳入 large-v3 的 turbo 版本,验证了这种方法的有效性。结果显示,质量和错误率与之前相比没有变化!
我们还尝试了一些零假设测试,比如使用全零或简单的高斯噪声向量来预填充 KV 缓存,但这些方法都未能产生有意义的结果,因此我们没有进一步探索。通过这项优化,我们现在能够在流式模式下每秒处理大约 9-15 个令牌,这对大多数日常语音处理来说已经相当迅速了。
直至稳定版本发布前的工作
我们期待您的反馈和贡献,以帮助我们迈向稳定版本的发布!
同时,我们计划在 WhisperKit 首次稳定版本发布之前,至少引入以下几项功能和改进: