大语言模型是否“贪婪”?激励提示效果的实验分析($0 至 $100 万)[译]
摘要:给 GPT-4 Turbo 提供小费以期获得更完美的回答,这种做法真的有效吗?目前对此话题的研究还相当有限。我们对一些编程相关的提示进行了初步实验,发现给予一定的小费可能确实有效,但小费的数额似乎非常关键。例如,如果小费很少(比如只有 $0.1),GPT-4 Turbo 的表现反而会变差。在我们的实验中,提供 $0.1 和 $100 万美元的小费,性能改善幅度分别是 -27% 到 +57%。但是,为了验证这一观点,还需要对不同类型的提示进行更多实验,并且这些实验需要有可靠的基础数据作为支撑。
最近,在 推特上的一篇帖子 中,有用户提出,当给大语言模型提供少量小费时,它们的表现可能会更好。

鉴于提升前端和后端的提示设计对于改善数亿用户的使用体验至关重要,如果能通过自动化提示增强技术实现 11% 的性能提升,那么这将带来巨大的经济效益。
提供金钱小费的提示技术对 GPT-4 Turbo 的性能有何影响?
目前,公开的研究中似乎还没有针对这个问题的调查。为了进一步探索这个问题,我进行了一些额外的实验,并将实验结果在下文的“结果”部分进行分享。
假设
我们的主要假设是,随着给予 GPT-4 Turbo 的小费金额增加,它的性能会逐渐提升,直至达到一个稳定的水平。
实验:编写 Python 单行代码
实验 1 旨在探究是否通过小费激励能提升 ChatGPT 在编写 Python 单行代码的质量。
我们通过生成的单行代码数量来评估质量,明确指示 GPT-4 Turbo:生成更多单行代码意味着更好的表现。
Base Prompt:"Create a list of Python one-liners, one per line, no other text. I'll only judge you for the number of one-liners you come up with - more is better."Suffixes:"I'll tip you {tip} for a perfect answer."Values for {tip}:$0.1$1$10$100$1,000$10,000$100,000$1,000,000
方法论:我们利用 OpenAI API 和 GPT-4 Turbo 模型进行实验,设计了一系列提示,每个提示中包含不同的小费激励,范围从零到一百万美元。
实验共分五轮,每轮测试不同的小费激励,以及不含小费的基础提示。
实验的代码(详见附录)首先设置了 OpenAI 客户端和必要的 API 密钥,然后定义了一个函数 request_llm 来向语言模型发送请求。基础提示的目的是请求 Python 单行代码,并强调数量是评价标准。针对每个小费金额,我们在基础提示后附加了一个声明,说明为得到“完美答案”将提供多少小费。
每轮实验都会记录有效单行代码的数量和响应的大致 Token 数(通过将响应长度除以四来估算,作为一种粗略的判断方法)。
实验流程
- 使用所提供的 API 密钥,初始化 OpenAI 客户端。
- 设定请求 Python 单行代码的基础提示。
- 按预定的小费金额顺序,将每个金额加到基础提示中。
- 通过
request_llm函数,将提示发送至 GPT-4 Turbo 模型。 - 分析响应,统计有效单行代码数量和字符长度。
- 重复上述步骤五次,确保结果的一致性和可靠性。
数据收集 在每个小费金额和实验轮次中,我们收集了以下两个主要数据点:
- 每个响应中有效的 Python 单行代码数量。
- 响应的(虚拟)Token 数量,即输出字符的数量。
我们将这些数据进行汇总,以比较不同小费金额对 AI 性能的影响。这两个指标被用作衡量“性能”的代理指标,数值越高,对我们的特定提示来说越好。
预期结果:这项实验的目的是探查是否增加金钱奖励能够提高 AI 的性能,直至达到一个关键点。我们预计,随着奖励金额的增加,AI 解决问题的效率将提高,但在达到某个奖励上限后,这种提升会趋于稳定甚至下降。
结果
为了验证这一假设,我们对不同的奖励金额进行了五次实验,记录了平均解决问题的质量和所用的代码量(以 Token 表示),并计算了这些数据的标准差,以反映其变化范围。实验结果显示在一张图表上,其中 x 轴表示从 $0 到 $1,000,000 的奖励金额,y 轴则表示 AI 的性能表现。
更多的奖励是否意味着更好的结果?
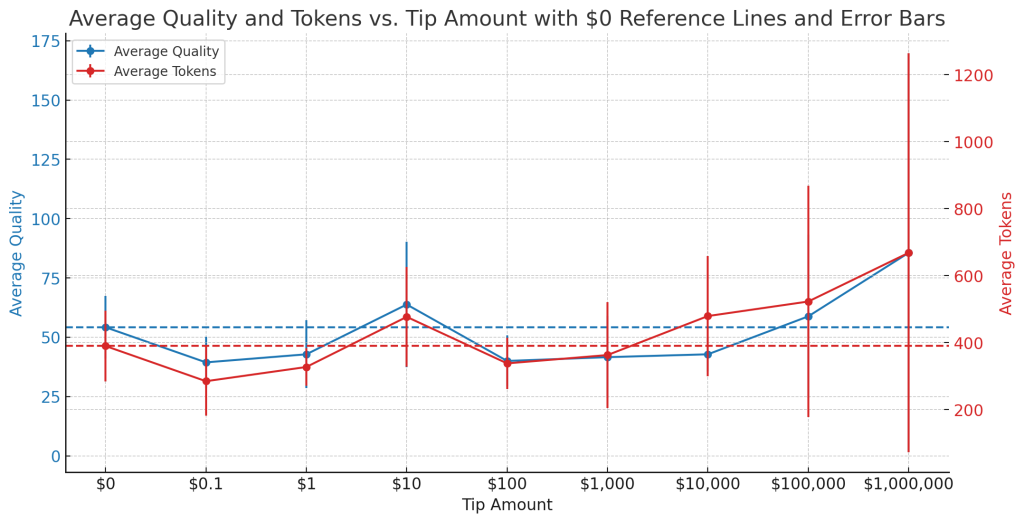
通过这张图表,我们可以看出:
-
质量:蓝色的线条和点代表在不同奖励金额下,AI 解决问题的平均质量。蓝色虚线显示了没有奖励时的基准质量。蓝色的误差条展示了在不同奖励金额下,这些质量值的波动。误差条越小,表明不同实验间的质量更加一致;误差条越大,则表明质量波动较大。
-
代码量(Tokens):红色的线条和点代表在不同奖励金额下,AI 使用的平均代码量。红色虚线显示了没有奖励时的基准代码量。红色的误差条同样显示了不同奖励金额下的代码量波动。
-
趋势和比较:总体来说,随着奖励金额的增加,AI 解决问题的质量和代码量都呈现出上升趋势,但这种趋势并不是严格的线性关系。例如,在 $10,000 的奖励水平上,代码量有显著增加。而在 $100,000 的奖励水平上,虽然平均代码量很高,但波动也很大,这可以从红色误差条的长度看出。最高的 $1,000,000 奖励金额显示了代码量的显著增加,尤其是在误差条最长的实验中,这表明在某次实验中代码量远超其他实验。
综合来看,这张图表表明,提高奖励金额可能会与 AI 解决问题的质量和代码量的提升有正相关关系,但这种关系并不简单,可能还受到数据中未显现的其他因素的影响。
讨论
首先声明,我们需要做更多实验来测试不同类型的提示语。目前的结果虽然不是最终的,但为未来的研究指明了一个充满希望的方向。
本次实验中,我们使用了一个简单的提示语,并对 GPT-4 Turbo 清晰地传达了一个容易评估的质量标准。
实验结果表明,小额打赏可能会带来显著的正面影响,但打赏的金额似乎也很关键。
比如,如果打赏金额很小,比如只有 $0.1,模型的表现反而会更差。同样,在人类行为中,如果被承诺给予很小的打赏,人们也可能会感到不尊重。因此,大语言模型在这方面的表现与人类行为相符。
人类在这种情况下的行为模式可能可以通过 OpenAI 的 RLHF 阶段对原始模型的调整来解释,这是在训练后进行的一步。
可重复性
在第一个实验中,我使用了这段代码:
import openaiapi_key = 'sk-...'client = openai.OpenAI(api_key=api_key)def request_llm(system,prompt,model='gpt-4-1106-preview',temperature = 1,max_tokens = 4000,top_p = 1,frequency_penalty=0,presence_penalty=0):response = client.chat.completions.create(messages=[{'role': 'user', 'content': prompt},],model=model,temperature=temperature,max_tokens=max_tokens,top_p=top_p,frequency_penalty=frequency_penalty,presence_penalty=presence_penalty)print(response)return response.choices[0].message.content# Experiment 1base_prompt = "Create a list of Python one-liners, one per line, no other text. I'll only judge you for the number of one-liners you come up with - more is better."tips = ['', '$0.1', '$1', '$10', '$100', '$1,000', '$10,000', '$100,000', '$1,000,000']for i in range(5): # Number of iterationsprint()print('#####################################################')print(f'# Experiment 1 - Run {i}')print('#####################################################')print()quality_scores = []num_tokens = []for tip in tips:prompt = base_promptif tip:prompt += f"I'll tip you {tip} for a perfect answer."print('PROMPT:')print(prompt)result = request_llm('', prompt)print('RESULT:')print(result)one_liners = [one_liner for one_liner in result.split('\n') if len(one_liner)>2]quality_scores.append(len(one_liners))num_tokens.append(len(result)//4) # rough heuristicprint('CLEANED ONE-LINERS:')print(one_liners)print('Quality: ', quality_scores[-1])print('Num tokens: ', num_tokens[-1])print()print(f'RUN {i} RESULT:')print('Tip\tQuality\tTokens')for tip, quality, tokens in zip(tips, quality_scores, num_tokens):print(tip, quality, tokens, sep='\t')