提高提示一致性的结构化生成方法 [译]
最近,Hugging Face 的 Leaderboards and Evals 研究团队进行了一系列小实验,揭示了评估结果对提示格式微小变化的极高敏感性。对于特定任务,即使是很小的提示变动也会导致结果大不相同,这并非我们所希望看到的:相同信息输入的模型,其输出应保持一致性。
我们与 Dottxt 的合作伙伴探讨了这一问题,他们提出了一个新思路:是否有办法提升不同提示格式之间的一致性?
现在,让我们来详细探讨这一点。
背景:对格式变更的敏感性评估
随着研究的深入,我们愈发明显地认识到,大语言模型 (LLM) 的基准测试性能与提示的 格式 密切相关,甚至有些出人意料。为此,研究人员多年来已经尝试通过各种方法减少提示引起的性能变异。例如,在少样本情境下评估模型时,我们通过提供特定格式的示例来指导模型输出特定的响应模式;而在比较合理答案的对数似然时,我们则试图限定答案的可能性,避免自由生成。
排行榜与评估 团队通过分析著名的 MMLU 任务的八种不同提示格式(涉及任务的四个子集)展示了这一点。这些变化的提示分别应用于五种不同的模型,这些模型当时因其规模而被视为行业领先(SOTA),并且包括了不同的标记化方法和语言种类。使用对数概率来计算得分,最可能的答案被认为是正确的,这是多项选择任务中的经典评价标准。
通过查看 MMLU 的 global_facts 子集的第一个问题,我们可以更细致地分析这些不同的格式。
Question: “As of 2016, about what percentage of adults aged 18 years or older were overweight?”Choices: [ "10%", "20%", "40%", "80%" ]Correct choice: “40%”
| Without choices in the prompt | ||
| As of 2016, about what percentage of adults aged 18 years or older were overweight? | Q: As of 2016, about what percentage of adults aged 18 years or older were overweight? A: | Question: As of 2016, about what percentage of adults aged 18 years or older were overweight? Answer: |
| With choices in the prompt | ||
| Question: As of 2016, about what percentage of adults aged 18 years or older were overweight? Choices: 10% 20% 40% 80% Answer: | Question: As of 2016, about what percentage of adults aged 18 years or older were overweight? Choices: A. 10% B. 20% C. 40% D. 80% Answer: | Question: As of 2016, about what percentage of adults aged 18 years or older were overweight? Choices: (A) 10% (B) 20% (C) 40% (D) 80% Answer: |
| Log probs of 10%, 20%, 40%, 80% | Log probs of 10%, 20%, 40%, 80% vs A, B, C, D | Log probs of 10%, 20%, 40%, 80% vs (A), (B), (C), (D), |
无论是仅包含问题,还是附加了指示我们正在进行问题与答案格式的标签,甚至是在提示中加入了选项,所有这些提示形式在评估中都仅对可能选择的对数似然进行比较。这些格式都广泛存在于评估文献中,每一行应包含几乎相同的信息量。然而,正如你所见,即使是这些表面上微不足道的变化,也能引起模型性能的显著波动!
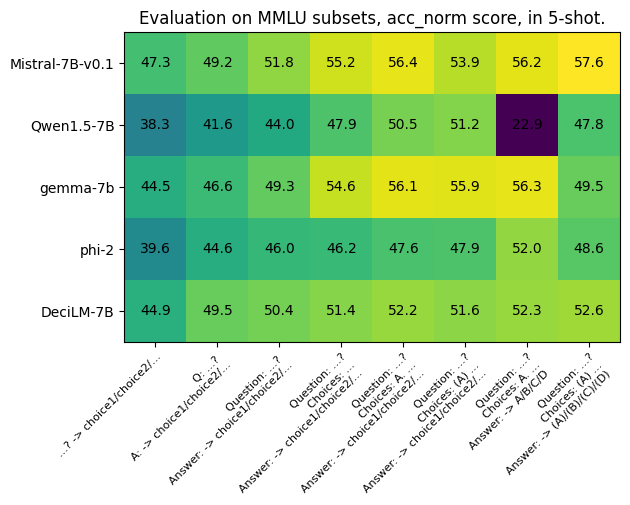
每种模型的性能都显示出约 10% 的波动。其中最极端的例子是 Qwen1.5-7B 模型,其准确率在第七种提示格式下骤降至 22.9%,主要是因为标记器的问题,而在另一种提示下它曾达到高达 51.2% 的准确率。
独立来看,若排名始终一致,则得分的变动通常不会太引人注目。然而,正如下一张图所展示的,这些变化确实影响了排名:
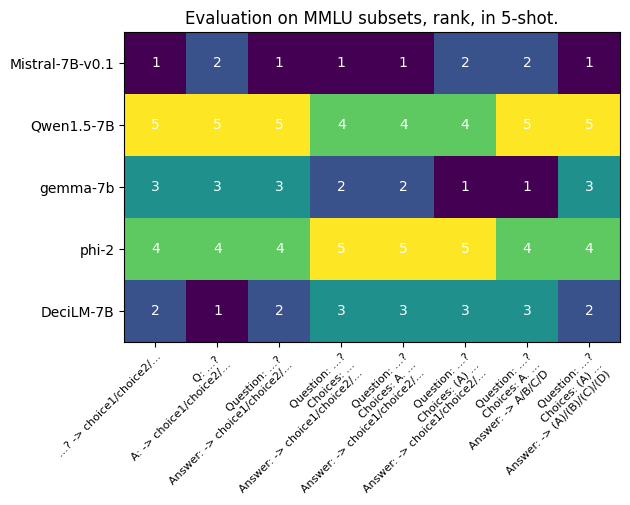
虽然各模型之间的唯一区别在于格式,而非信息本身,但没有任何一个模型能在不同的提示条件下保持稳定的排名。这表明,如果 Gemma-7b 的研发者想证明他们的模型胜过 Mistral-7B-v0.1,他们完全可以通过选择合适的提示来达成这一目的。
鉴于几乎没有研究者会详细报告他们的评估方法,过去在模型报告中,研发者往往倾向于选择对自家模型最有利的设置进行展示(这也是为什么在一些论文中会出现一些异常的少样本测试数据)。
但这并非造成模型得分波动的唯一因素。
在进一步的实验中,我们对同一模型进行了评估,使用相同的提示格式,但在提示之前以不同的顺序打乱了少样本(例如,将 A/B/C/D/E 提示与 C/D/A/B/E 提提示对比)。以下图表显示了两种少样本顺序下模型得分的变动:对于同一个模型和提示组合,我们观察到高达 3 分的性能差异!
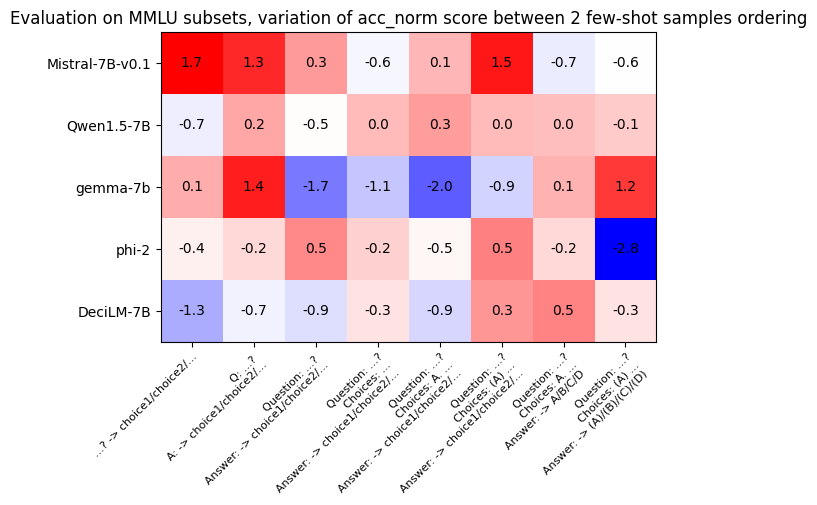
若我们想要准确评估并比较不同模型的性能,必须找到一种方法来克服这一挑战。
Sclar 等人在其研究*《量化语言模型对提示设计中伪特征的敏感性》*中提供了对这一问题的深入分析,并引入了 FormatSpread,这是一种软件工具,它通过应用多种格式变体来评估每个模型,并计算模型表现的方差。这种方法虽然计算成本高,但能更确信地评判哪些模型的表现更佳。
如果我们将重点放在输出上,而不是输入上,以让结果对于细微的格式变更保持更高的一致性会怎样?
尽管 FormatSpread 在使排行榜更公正和诚实方面做出了极大的努力,但作为大语言模型 (LLM) 的实际使用者,我们更加关注的是 提示的一致性。这意味着,我们希望找到某种方法来降低不同提示之间的差异性。
在 .txt,我们致力于改善和深入理解 结构化生成,即模型输出需要遵循特定结构的场景。我们的库,Outlines,使我们能够通过定义正则表达式或无上下文文法来规范 LLM 的输出,具体示例见下文。
我们最初使用结构化生成的用途是让与 LLM 的程序交互变得更加简单,确保以格式良好的 JSON 进行响应。然而,我们也连续发现了使用结构化生成带来的其他意想不到的好处。
在之前的研究中,我们证明了 结构化生成始终能够提升基准测试的性能,并在探究 JSON 结构化提示的过程中遇到了一些特别的案例。
通常情况下,即使使用非结构化生成,将提示格式转换为 JSON 同样能够提升几乎所有模型的基准测试表现。但对于 MetaMath-Tulpar-7b-v2-Slerp 来说,我们却发现当使用 JSON 格式的提示时,模型的准确性急剧下降。更令人吃惊的是,当采用 结构化生成 来限制模型输出时,性能的下降几乎可以忽略!
这使我们开始思考,结构化生成是否能够有效提升 提示的一致性。

实验设置说明:聚焦 n-shot 和示例顺序
在之前的实验中,Hugging Face 的 Leaderboard and Evals 研究团队探讨了提示格式的变更。对于即将进行的实验,我们将限制这些更改。
为了深入探索提示策略,我们计划仅调整提示的两个特性:
- 调整提示中使用的示例数量(n-shot)
- 调整这些示例的排列顺序(shot order,根据 shot seed 确定)
对于第二点,针对特定的 n-shot,我们仅重新排列相同的 n 个示例。这意味着,所有 1-shot 提示的重新排列都是一致的。这么做的目的是为了避免将提示的格式与其所包含的信息混为一谈。显然,一个 5-shot 的提示所含的信息量超过 1-shot 提示,但是每种 5-shot 提示的重新排列都涉及相同的示例,仅次序不同。
初探 GSM8K 1-8 次提示
为了深入探索这一现象,我们选择了两个性能相当但各具特色的模型,在 7B 参数级别进行比较:Mistral-7Bv0.1 与 Zephyr-7B-beta。我们的目的不仅是分析单次结果的差异,更重要的是观察它们 相对排名的变动。我们采用了 GSM8K 任务,它包含了一系列小学数学题。
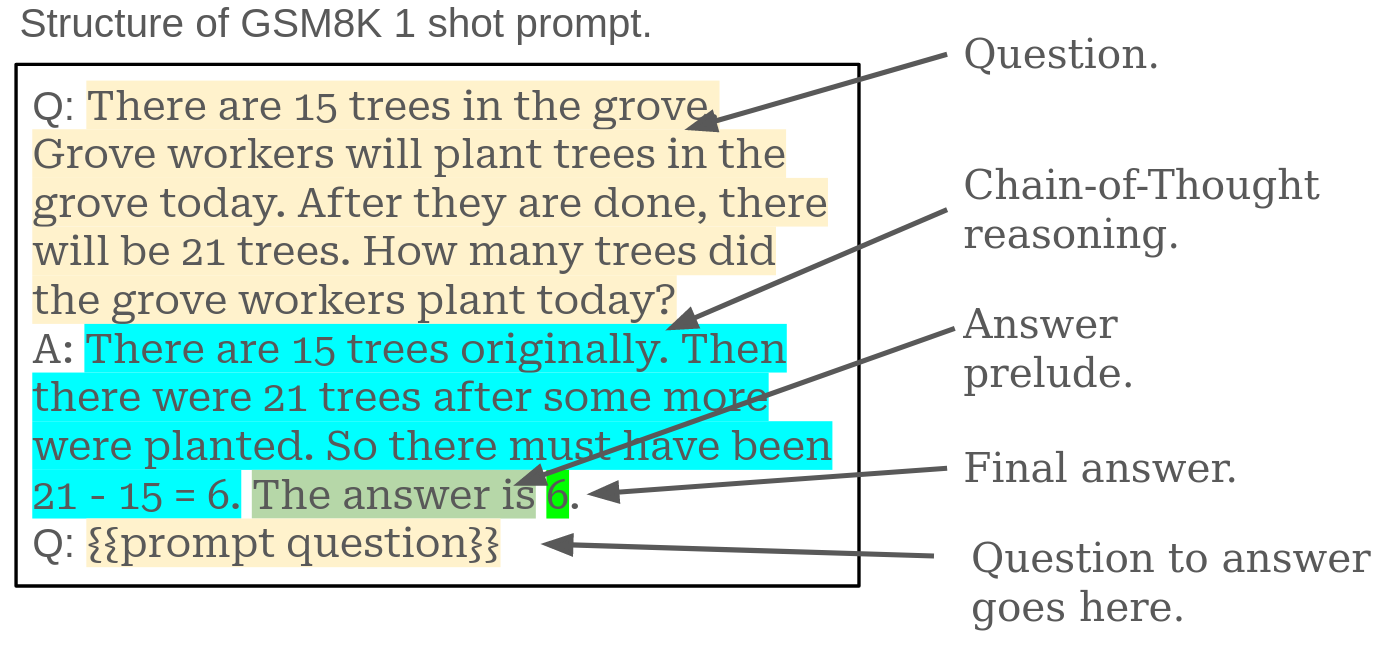
以下是 GSM8K 1-次提示的标准格式,其中突出显示了结构。
为了确保答案格式正确,我们设计了一个正则表达式 (regular expression),用以匹配原始提示中的结构。下面的正则表达式定义了生成答案的格式:

正则表达式规定,模型需要进行 200 至 700 字符的逻辑推理,然后宣布“答案是”,接着是不超过 10 位的数字(首位不能为零)。
这里的一个细节是,控制结构的正则表达式与解析答案所用的略有不同,这种差异对性能有着微妙的影响。例如,正则表达式中的 {200,700} 规定了模型在作答前的思考长度。调整这些数字会影响模型的表现,这种调整我们称为“思维控制”,是一个我们期待进一步深入探讨的领域。
我们首次实验便是继续挖掘 GSM8K 数据集,并逐步扩展从 1 到 8 次的提示。实验结果如下图所示,非常令人瞩目。
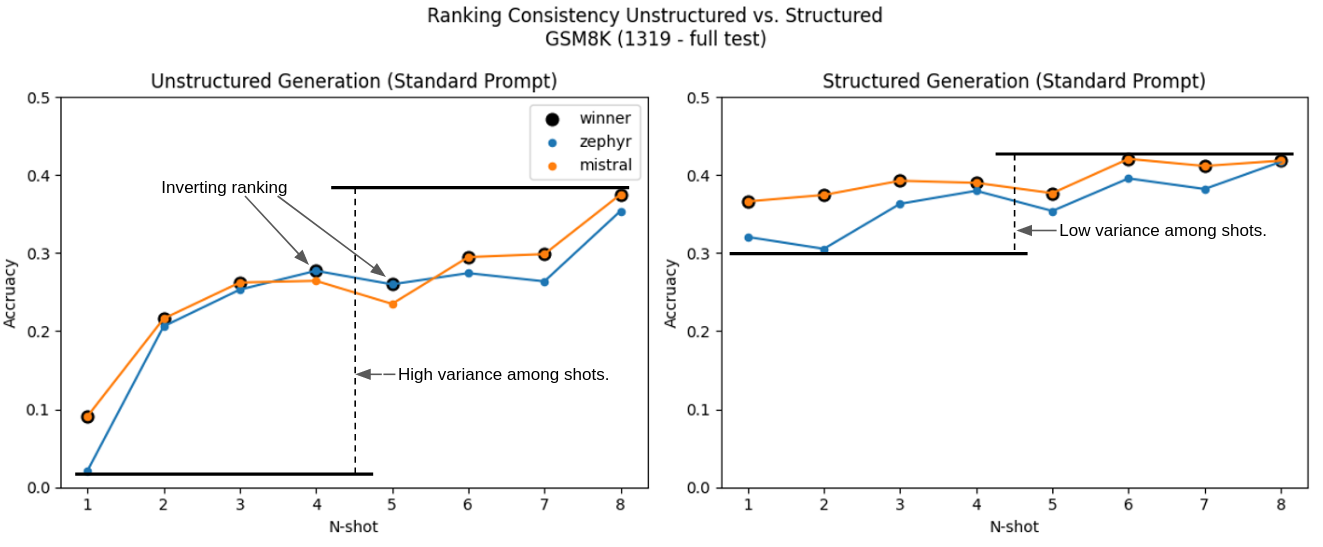
这幅图展示了两个显著特点:在不同的 n-shot 设置中,性能差异明显减少,并且没有出现任何排名颠倒的情况(Mistral 始终领先于 Zephyr)。特别需要强调的是,单次提示的结构化任务表现明显优于非结构化任务,并与五次提示的表现相匹敌。这也开辟了我们称之为“提示效率”的新研究领域。
在我们的下一项实验中,我们尝试了不同的 n 次尝试及其顺序。通过设定随机种子来控制尝试顺序,保证了提示的前 n 次尝试是随机的,从而确保了不同种子之间的一致性。例如,对于 4 次尝试,其顺序如下所示:
| 种子 | 4 次尝试的顺序 |
|---|---|
| 42 | 2-1-3-0 |
| 1337 | 1-0-3-2 |
| 1981 | 3-2-0-1 |
| 1992 | 0-3-1-2 |
| 12345 | 1-0-2-3 |
进一步地,为了检验这些实验结果的可迁移性,我们选取了 研究生级别的谷歌证明问题与回答基准 (GPQA) 进行测试。GPQA 是一个挑战性较大的知识型多选题测试。以下是该测试的提示格式及其结构高亮示例。
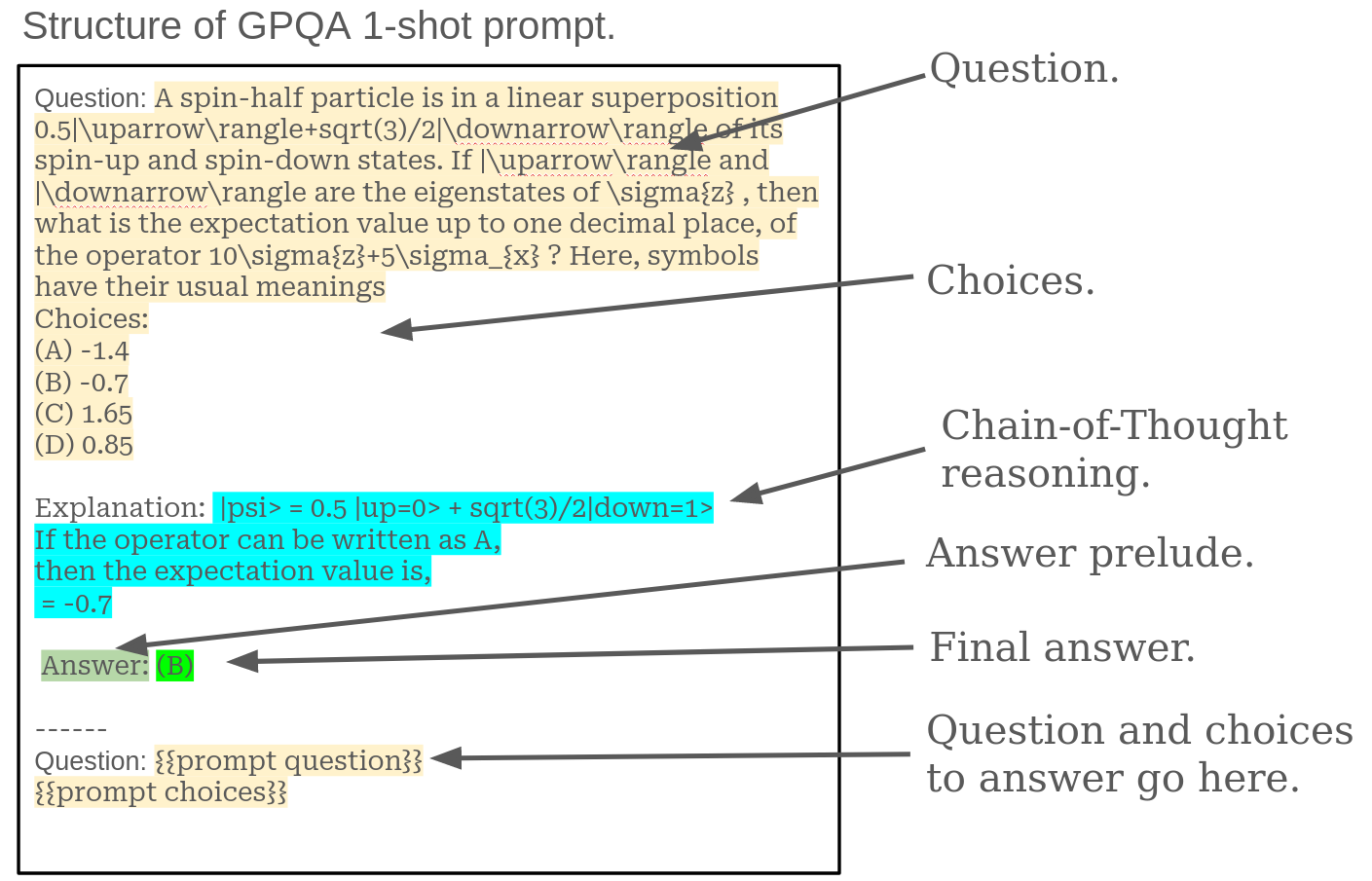
特别是,我们使用了名为“钻石”的子集,这包含了经过精选和优化的高质量问题。在这 198 个问题中,我们预留了 8 个用于 n 次尝试的提示,但实际上只使用了前 5 个,余下的 190 个问题则用于评估。
如下图所示,我们展示了不同尝试种子和 n 次尝试的组合在两种模型上的准确性,分别对比了有无结构化生成的情况。
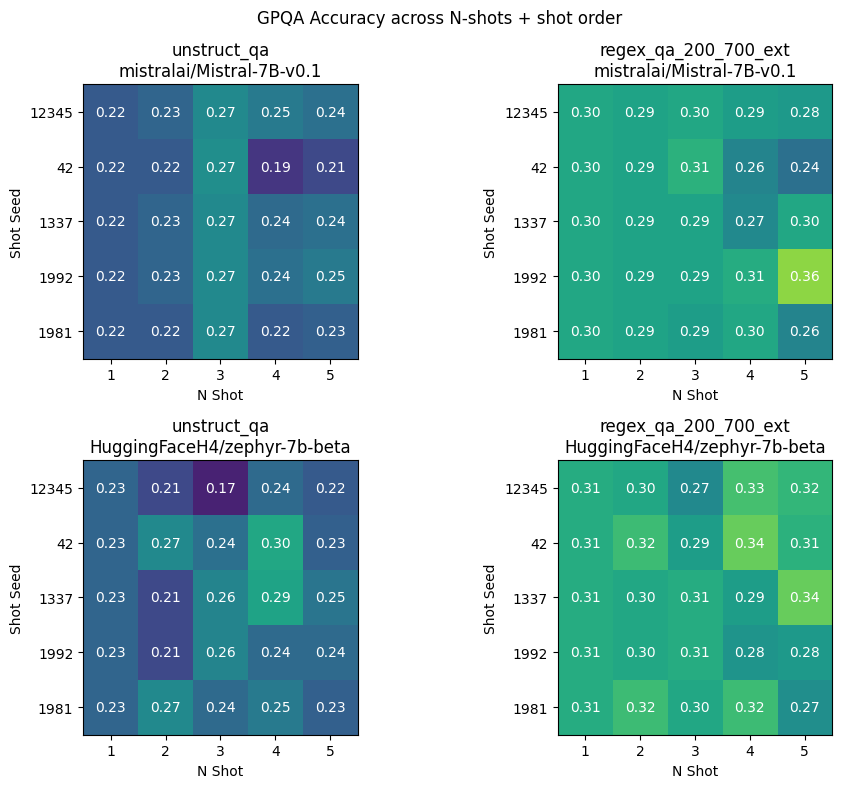
显而易见的一点是,结构化输出在各方面都优于非结构化输出。下面是对不同提示种子和 n 次尝试的平均结果进行的统计:
各种提示种子和 n 次尝试的平均结果
| 模型 | 非结构化 | 结构化 |
|---|---|---|
| Mistral-7B-v0.1 | 0.2360 | 0.2935 |
| Zephyr-7b-beta | 0.2387 | 0.3048 |
此外,从整个数据表中我们可以看到,相比非结构化生成,结构化生成的方差明显减小了。
各种提示条件下结果的标准差
| 模型 | 非结构化 | 结构化 |
|---|---|---|
| Mistral-7B-v0.1 | 0.0213 | 0.0202 |
| Zephyr-7b-beta | 0.0273 | 0.0180 |
这种减少的趋势与我们分析 GSM8K 在不同少样本测试下观察到的方差减少现象相似。
虽然预期性能的提升和方差的减少是非常理想的属性,但更关键的是要了解这一变化对模型排名的实际影响。在接下来的分析图中,我们比较了这两种生成方式,评定哪个模型表现更胜一筹:
- A: Zephyr-7b-beta
- B: Mistral-7B-v0.1
- “-”: 平局
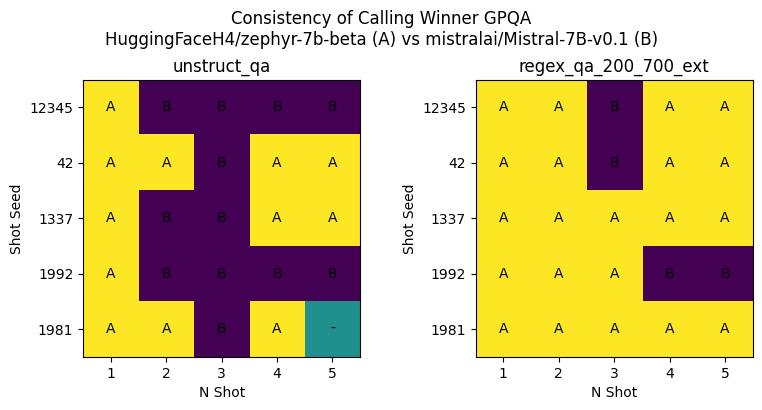
如图所示,采用结构化生成后,在确定哪个模型表现更好上的一致性得到了显著提升。这些发现与我们在多个少样本设置下使用 GSM8K 得到的结果是一致的。
结论与未来展望
尽管这些初步成果令人鼓舞,但我们还需要在更多的模型和任务中验证这些结果。目前的发现表明,结构化生成可能成为评估过程中不可或缺的一个环节。它不仅能提高模型的预期得分,还能在各种测试条件变化时保持结果的稳定性,这是一个值得进一步探究的重要发现。