是时候开始讨论大语言模型中的提示架构了吗?[译]
Donato Riccio
![是时候开始讨论大语言模型中的提示架构了吗?[译]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_RNO8w4-U1qagRI5OAUzUrQ.webp)
概括。
一切都始于一个词。
对于结果不满意,我们再次尝试。
概述文章的核心要点。_
提示工程教会我们,更具体的提示效果更好。
分析文章中的三个主要论点,并根据所提供的证据评价作者论点的力度。有没有什么地方你觉得作者的论点可以更有说服力或更加充分?
随着时间的推移,我们学习了如何添加更多细节,来引导我们最喜爱的大语言模型给出最佳答案。
![一种名为“从少到多提示”的最新提示架构。 [1]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_PX-iHKWbG5v80QHM1eXo0A.webp)
提示工程技术正变得越来越复杂,演变成一些由多个组件构成的复杂系统。对于这样的复杂系统,“提示工程”的定义可能显得有些局限。
在这篇文章中,我想为与大语言模型交互的多组件系统提出一个更准确的称谓:
提示架构。
提示工程的发展历程
现代语言模型展现了令人称奇的能力:仅凭几个示例就能处理全新的任务。这种能力被称为 上下文中学习(in-context learning),它是提示工程效果显著的关键所在。
研究人员认为,模型之所以能够在上下文中学习,是因为预训练(pretraining)使其掌握了完成语言任务的基本技能。在测试阶段(test time),模型只需识别已有的模式并运用这些技能。更大型的模型在这方面表现得更加出色,使它们能够灵活适应各种自然语言任务。 [2]
过去,为了让语言模型适应新任务,你可能需要数千个标记过的样本进行微调。但在上下文中学习的帮助下,你只需在模型的上下文窗口中提供任务描述,模型便能掌握新任务。我们称这为 零样本学习(zero-shot learning)。
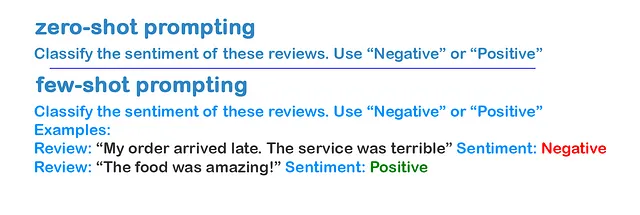
少样本学习(Few-shot learning) 是通过在模型的上下文中提供少量示例来实现的。模型在测试时会适应这些模式并据此作出响应,无需更新其算法权重。随着模型规模的增大,这种快速适应的能力也在提升,使得像 GPT-3 这样的大型模型仅凭几个示例就能学习新任务。模型在看到几个示例后,就能做到相当好的泛化。
这些技巧为我们与大语言模型(Large Language Model,LLM)的互动提供了一个通用框架。
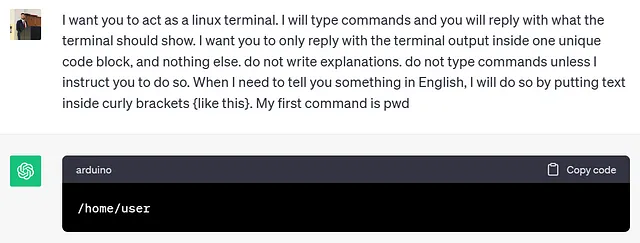
角色提示(Role prompting) 是一种特定于提示工程的技术,我相信你在使用 ChatGPT 时至少尝试过一次,特别适用于更特定的任务。这种技术中,AI 系统在提示开始时就被赋予了一个明确的角色。这种额外的信息为模型提供了上下文,有助于提高模型的理解能力,从而产生更有效的回应。 [3]
角色提示是从给 AI 指定一个角色的指令开始,随后是一个问题或任务,AI 需要在所赋予的角色框架内作出回应。

图片由作者提供。提示来源。
通过设定特定角色来为 AI 提供背景信息,可以帮助它更好地理解问题并给出恰当的回答。这种方法会引导 AI 模型像专家一样根据不同领域的专业知识进行回应。比如,你可以让模型模拟一名医生的角色,以期得到更加专业的医学相关答案。
图像由作者提供。提示来源。
让大语言模型实现更复杂的推理
目前,大语言模型在逻辑推理和多步骤问题解决上仍有难点。而思维链 (Chain of Thought) 提示技术能帮助这些模型展现它们的解题过程,并逐步理清问题。
通过展示理想的推理过程,可以引导模型在面对新问题时模仿这种逻辑思考方式。思维链技术在像数学和逻辑谜题这样的多步推理任务上,有效提升了模型的表现,这些任务通常会使模型感到困惑。
![思维链提示示例。 [4]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_Vd1_9zI2m18sCWfMnlojwQ.webp)
最近的研究将提示技术发展到包含多个要素和推理阶段的系统。
这是提示工程向提示架构转变的分界线。
![自我一致性提示架构示例。 [5]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_nwQaaOPrIY8VKzZfCuQrEQ.webp)
复杂推理任务通常有多种有效的解题路径,都能得出正确答案。
自我一致性提示 (Self-consistency prompting) 首先从模型中生成多种可能的推理路径,即多个候选答案。接着,它会综合这些答案,选出出现频率最高的答案。如果不同的推理路径都得出同一个确定答案,就更能确信这个答案是正确的。 [5]
![模型在回答物理问题前,会先探讨物理学的基本原理。[6]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_x67TuBx_fz_vszP4GSYMgA.webp)
退后一步提示 (Step-back prompting) 进一步探索了通过分解问题为中间步骤来解决问题的方法。这种提示架构通过让模型先“退后一步”,先构建问题的抽象概念,再尝试解答,从而提升了推理能力。
退后一步提示首先让 LLM 回答与关键思想相关的更广泛问题,然后 LLM 用核心事实和概念作答。借助这些广泛知识,LLM 再针对具体的原始问题给出最终答案。跨基准的测试表明,这种“退后一步”的策略有助于大型模型更有效地推理,减少错误。 [6]
![验证链 (Chain of Verification, CoVe) 提示架构。[7]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_liSsH3LBNjznwGO86LDejA.webp)
验证链 (Chain of Verification, CoVe) 是一种旨在减少大语言模型 (LLM) 生成错误信息的提示架构。CoVe 的首要步骤是让模型对一个问题生成初始回答,这个回答可能存在不准确之处。随后,LLM 会根据提示生成一系列问题,用以核实初始回答中可能的错误。LLM 然后独立回答这些问题,不依赖于最初的回答,以防止错误信息的重复出现。这个过程的最终目标是产生一个经过校验和修正的答案,通过加入问题和答案的对话来纠正初始回答中的不一致之处。[7]
自主智能体和高级应用的交互模型
交互模型的设计不仅仅局限于单一的提示,它还能实现一些复杂应用,这在传统的单一提示设计中是难以实现的。
![ReAct 交互模型。[8]](/images/prompt-engineering/is-it-time-to-start-talking-about-prompt-architecture-in-llms/1_MUNKRNwcE7VNdKAHlTo86w.webp)
在 ReAct 交互中,模型融合了“思考”和“行动”来解决复杂任务。“思考”指的是类似人类的计划和推理步骤,“行动”则是通过 API 或环境来获取外部信息。观察则会反馈相关信息。ReAct 模型通过展示其思考过程,增强了其可解释性,并能通过这种方式评估推理的正确性。此外,人类可以通过编辑这些“思考”来指导模型的行为。[8]
选择合适的提示架构
在开发会话型聊天机器人时,一开始可以尝试使用更直接的提示工程技术(prompt engineering)。如果这些方法不奏效,你可以尝试使用Step Back或Self-Consistency等方法来提升推理能力,同时避免过度复杂化。
如果你在构建一个应用程序,且重点在于减少幻觉(hallucinations),那么可以考虑使用CoVe,或者更先进的方法,如Zero Resource Hallucination Prevention。[9] 但是,CoVe涉及多步骤的交互,可能对于聊天场景来说过于繁琐。在这种情况下,使用**检索增强生成(Retrieval Augmented Generation, RAG)**可能是一个减少幻觉的更佳选择。[10]
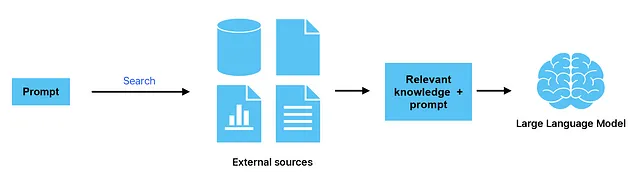
这些方法为我们提供了有关大语言模型的令人兴奋的洞见,但 RAG 在真实应用中的适用性更强。
需要记住的是,采用高级提示架构来构建应用程序会更加昂贵,因为每次查询会消耗更多的 Token 来产生最终的响应。
如果你的目标是构建自主智能体——即智能且有明确目标的系统——不妨尝试 ReAct 提示方式。ReAct 允许大语言模型通过结合思考和行动来与世界互动。
随着模型越来越能够独立解决复杂任务,提示的复杂性也会随之增加,从而使大语言模型能够应用于更高级的用例。
实践经验会帮助你直观地了解在不同场景下哪些技术更为有效。
大语言模型互动的新未来
通过先进的提示架构,大语言模型能够完成以往单次推理所不能的任务。
提示架构 不仅仅提高了大语言模型的实用性,它还让我们能深入理解这些模型的内部机制。尽管有些提示架构对于现实世界的应用来说过于复杂或成本过高。
利用提示架构,我们得以窥探大语言模型的神秘内核。
提示架构并非提示工程的升级版 — 它是一种全新的技术手段。
提示工程 依靠单一推理步骤,任何人都可以在聊天界面中轻松实现,而 提示架构 则需要多步骤的推理和逻辑处理,通常还需借助复杂的编程来实施。
深入探索这两种方法,可以发现大语言模型新的潜能。
我认为,明确这两者之间的区别是非常重要的。
喜欢这篇文章吗?欢迎在 领英 上关注我。
References
[2] [2205.11916] Large Language Models are Zero-Shot Reasoners (arxiv.org)
[3] [2308.07702] Better Zero-Shot Reasoning with Role-Play Prompting (arxiv.org)
[4] [2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (arxiv.org)
[5] [2203.11171] Self-Consistency Improves Chain of Thought Reasoning in Language Models (arxiv.org)
[7] [2309.11495] Chain-of-Verification Reduces Hallucination in Large Language Models (arxiv.org)
[8] [2210.03629] ReAct: Synergizing Reasoning and Acting in Language Models (arxiv.org)
[9] [2309.02654] Zero-Resource Hallucination Prevention for Large Language Models (arxiv.org)
[10] What is retrieval-augmented generation? | IBM Research Blog