DREAM: 分布式 RAG 实验框架 [译]
Aishwarya Prabhat
使用 Ray, LlamaIndex, Ragas, MLFlow 和 MinIO 在 Kubernetes 上的分布式 RAG 实验蓝图
1. 🌟 什么是 DREAM?
a. 🤔 这究竟是什么?
在有那么多大语言模型(LLM)、嵌入模型、检索方法及重新排序方法可选时,要确定哪一种组合最符合你的需求确实挑战重重。毕竟,谁会有时间挨个尝试每一种组合呢?
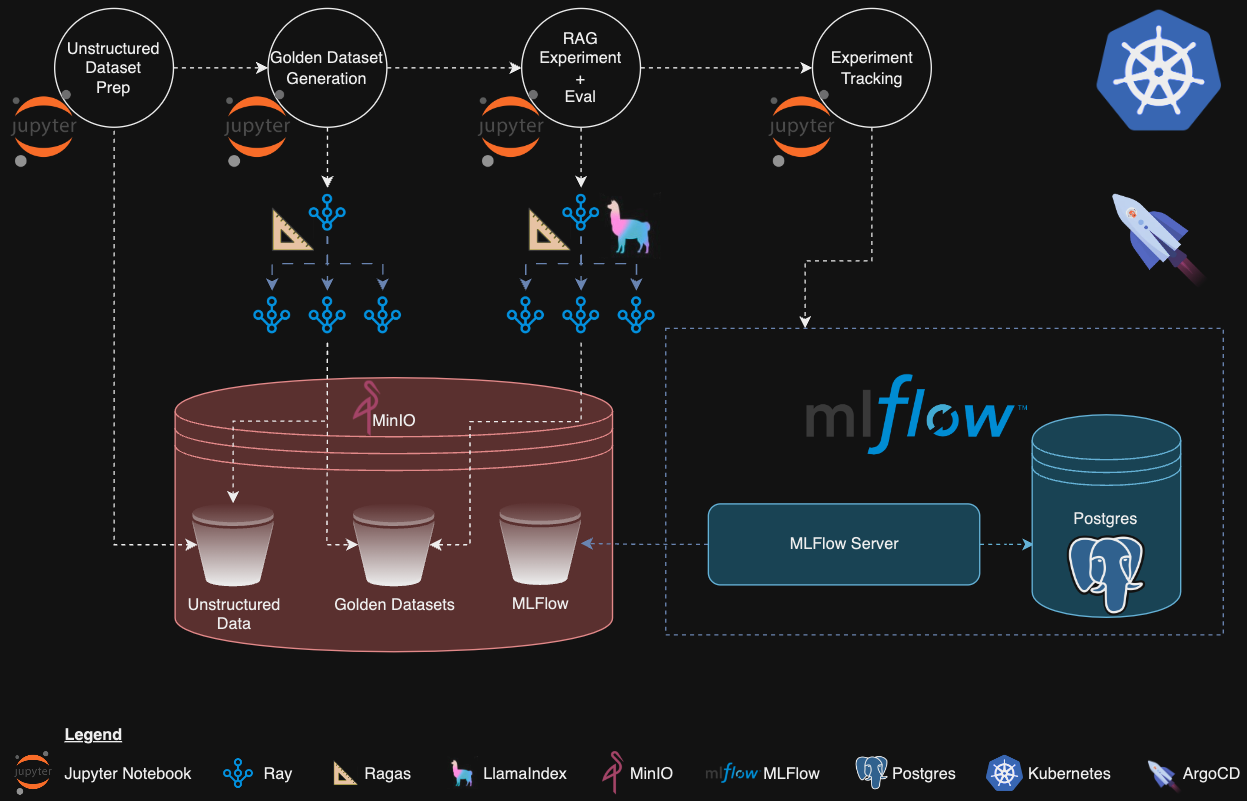
于是,我们有了分布式 RAG 实验框架(DREAM)——这是一套包括 Kubernetes 原生架构和示例代码的蓝图。它展示了如何在 Kubernetes 上利用 Ray, LlamaIndex, Ragas, MLFlow 和 MinIO 这些工具,以分布式的方式进行检索增强生成(RAG)的实验、评估和监控。
通过部署必要的 Kubernetes 工具并在分布式系统中进行实验和评估,我们的最终目标是比较各种 RAG 参数组合,找出最适合我们需求的那一种。
b. 🏛️ 架构
如图所示,DREAM 的技术栈包括:
- Ray (Kuberay)(由 Anyscale 开发)适用于在 Kubernetes 上进行分布式计算,可以用于通过 Ray Tune 进行各种实验和通过 Ray jobs 执行其它分布式任务
- LlamaIndex(由 Jerry Liu 和他的团队开发)是一个专门处理非结构化数据和采用先进的 RAG 技术的框架
- ragas(由 Shahul ES, Jithin James 及其团队开发)用于生成模拟数据和进行大语言模型(LLM)辅助评估
- MinIO 用作 S3 和 Kubernetes 原生的对象存储方案,主要存放非结构化数据、关键数据集以及 MLFlow 的数据记录
- MLflow 用作科研项目的追踪工具,辅助数据库采用 PostgreSQL,存储则使用 MinIO
- Project Jupyter 笔记本用于在 Ray 集群上开展互动式实验活动
- Kubernetes 作为主要的容器管理系统……自然不在话下!(在 DigitalOcean 的小型服务器上通过 kubeadm 部署,当然,您也可以选择 minikube 或其他的版本)
- ArgoCD(由 Argo Project 开发)负责将各种工具部署到 Kubernetes 集群上,并利用 GitOps 技术维护集群的运行状态。
要安装这些组件,您可以遵循 安装指南 中的步骤。您会发现,DREAM 实际上是我即将推出的一个宏大项目“GOKU(在 Kubernetes 上的生成式 AI 运营)”的一部分。
c. 💻 展示代码!
Here you go: DREAM Github :)
2. 🚶 代码导览
a. 📂 准备非结构化数据
这些步骤在 此 Jupyter 笔记本 中非常简单直接:
- 从 github 下载 PDF 文件到本地机器
- 利用 boto3 技术,把 PDF 文件上传到 S3 (MinIO) 存储服务
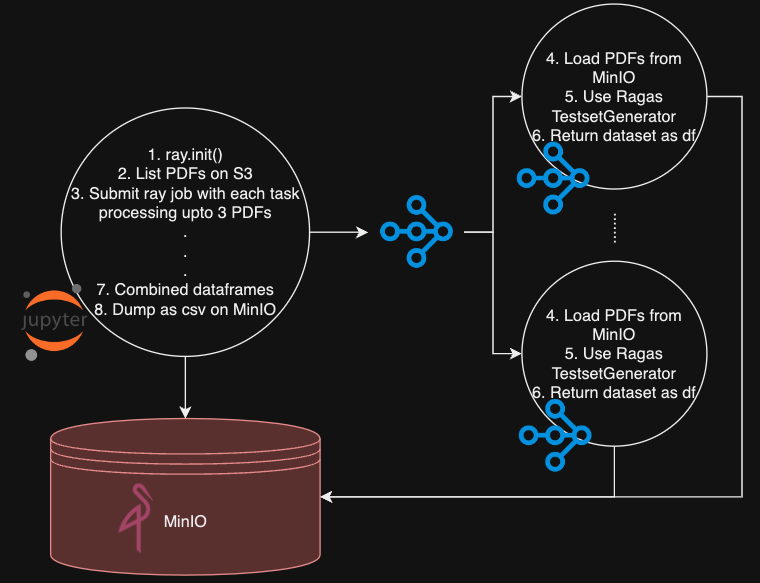
b. 🥇 分布式创建黄金数据集 这里开始变得有趣!
- 利用我们的 Jupyter 笔记本 作为 Ray 驱动,通过 ray 客户端提交任务,分布式地创建黄金数据集。
- 在每一个 Ray 任务中,最多从 S3 加载三个 PDF,并运用 ragas 框架的 TestsetGenerator 生成仿真测试数据。每个任务会返回一个含有仿真数据的 Pandas 数据框。
- 驱动器 (Jupyter 笔记本) 将这些数据框合并,并将合并后的数据框以 CSV 文件的形式存储到 S3。
c. 🔬 分布式实验与评价
接下来的部分可能会比较复杂,以下是整个工作流程的图示说明:
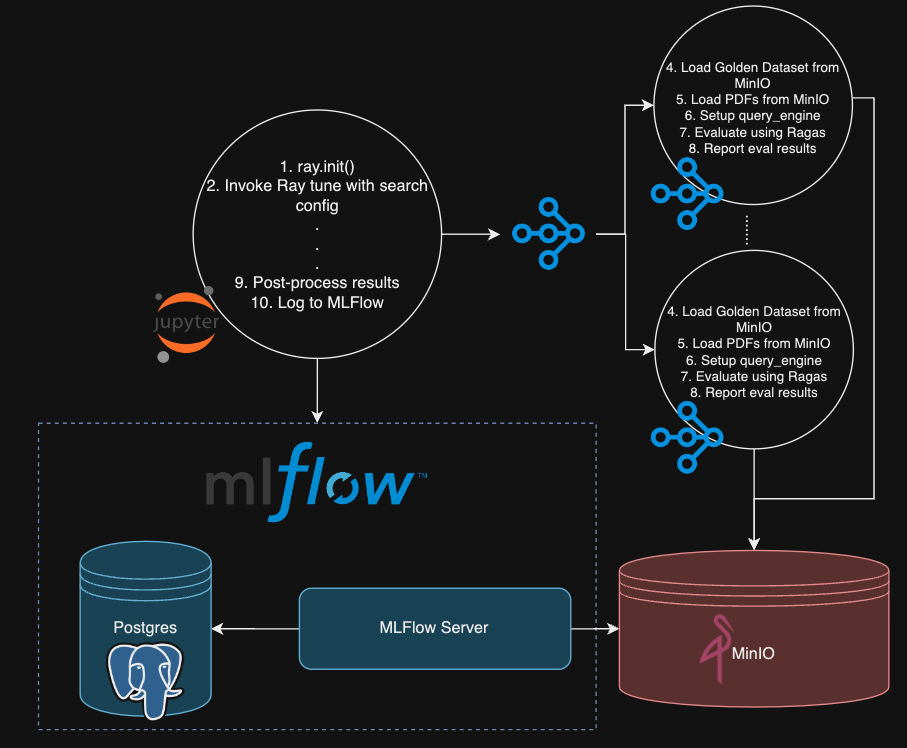
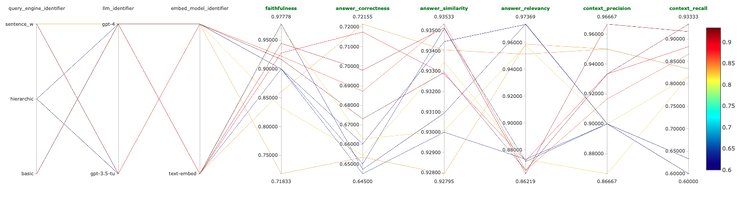
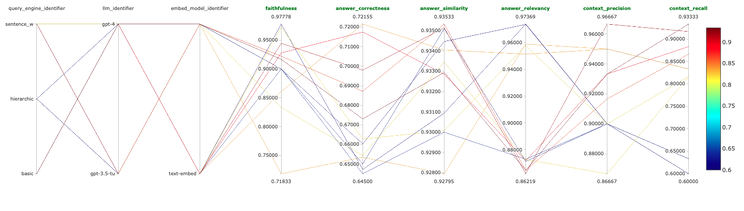
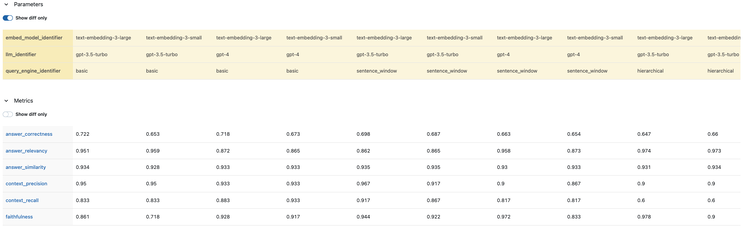
在详述核心内容前,先来看看我们的搜索空间及评估标准。我们的搜索空间涵盖三种 RAG 方法,两种大语言模型 (LLMs) 和两种嵌入模型。我们利用 LlamaIndex 提供的三种 RAG 方法:块重叠,句子窗口检索及层次化自动合并检索。使用的大语言模型包括 OpenAI 的 gpt-3.5-turbo 和 gpt-4,以及两种嵌入模型:text-embedding-3-small 和 text-embedding-3-large。评估使用 ragas 提供的六种标准:忠实度、答案相关性、上下文精确度、上下文回忆度、答案正确性及答案相似度。深入了解这些 RAG 方法和评估标准,欢迎阅读我之前的高级 RAG 文章。
- 在 Jupyter 笔记本充当 Ray 驱动程序的情况下,我们使用 Ray 客户端提交 Ray Tune 作业

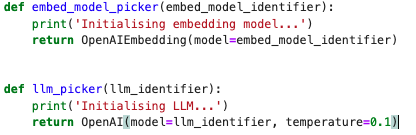
- 在处理嵌入模型和大语言模型(LLM)时,我们通过特定的代码字符串来选择和启动这些模型,这一过程在实验的辅助功能中完成。
- 完成模型选择后,实验中的下一步是使用评估工具,这个工具通过分析标准数据集来帮助我们获取问题的上下文和答案。通过一个特别的程序 ragas 对结果进行评价并计算不同的性能指标,然后通过一个记录功能将这些数据保存下来。

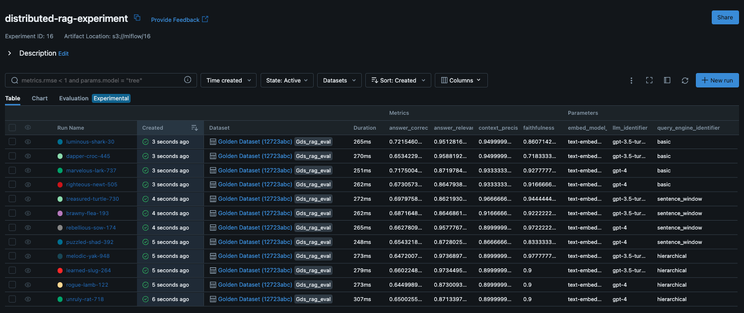
d. 📊 实验追踪
最后,我们通过使用 MLflow 的强大实验追踪功能,不仅记录了实验的成果,也建立了与核心数据集的连接,并把实验结果可视化。以下是一些直观的截图,它们足以自述其效果。

3. 📍 结论
在这篇文章里,我们详细介绍了 DREAM 项目。这个项目不仅是一系列工具和代码的设计方案,还展示了如何利用 Ray, LlamaIndex, Ragas, MLFlow 和 MinIO 这些开源技术,在 Kubernetes 平台上进行分布式的 RAG (retrieval-augmented generation) 实验、评估和监控。