RAG 与 GPT-4 的上下文窗口比较:准确性、成本和响应速度 [译]
摘要:(RAG + GPT-4) 提供卓越性能,成本仅为 4%。
引言
在大语言模型应用阶段,重点是让回答变得非常具体,无论是针对数据集、用户、使用场景,还是特定的调用请求。
通常,这通过以下三种主要技术之一实现:
-
上下文填充
-
RAG(检索增强生成)
-
微调。
与常见的误解不同,实际上在定制 LLM 的回答时,主要使用的是上下文填充和RAG,而不是微调。(微调在其他方面有其独特且重要的作用 - 我将在下一篇文章中详细讨论)。
最近,我为 CopilotKit 添加了一个新的面向文档的反应钩子,专门用于处理(可能是长篇的)文档。
在选择合理的默认设置时(受到 Greg Kamradt) 的启发),我对RAG和GPT-4-Turbo的上下文窗口进行了一场“海底捞针”式的压力测试,关注三个关键指标: (1)准确性,(2) 成本,和 (3) 响应速度。
我对两种不同的 RAG 管道进行了基准测试:
-
Llama-Index - 最受欢迎的开源 RAG 框架(默认设置)。
-
OpenAI 最新的助手API 检索工具 - 它内部使用了 RAG,已经被证明使用了Qdrant向量数据库。
结果
先来看结果:
摘要: 现代 RAG 表现出色。根据您的使用场景,您可能永远不需要把上下文窗口填得满满的(至少在处理文本时)。
(1) 准确性

如上图所示,助理 API(结合了 GPT-4 和 RAG 技术)的表现极为出色,几乎可以说是完美的。
需要注意的是,这种高水平的表现仅限于搜索类型的查询。 在处理涉及较大上下文范围的其他场景时(比如少样本学习),情况可能会有所不同。
(2) 成本
在 AI 技术中,使用上下文窗口填充技术仅会造成每个 Token(数据单位)的成本增加。相比之下,RAG 技术不仅增加每个 Token 的成本,还额外增加了一种固定的大语言模型 (LLM) 推理成本。
这里有一个 每个 Token 成本的概览:
![]()
值得注意的是,这些成本在 四个数量级上有显著差异(使用对数尺度测量)。 (详见分析部分的图表和计算)。
*注:OpenAI 计划在 2024 年 1 月中旬之前不对数据检索收费。这可能是一次沟通上的失误,未来可能会有所更正(例如,他们可能未提到他们将另行收取数据嵌入成本)。另一种可能性是,他们正在使用一种还未公布的新型数据嵌入模型。
—
然而,值得再次强调的是,RAG 技术同样带来了大致固定的大语言模型智能体循环成本。
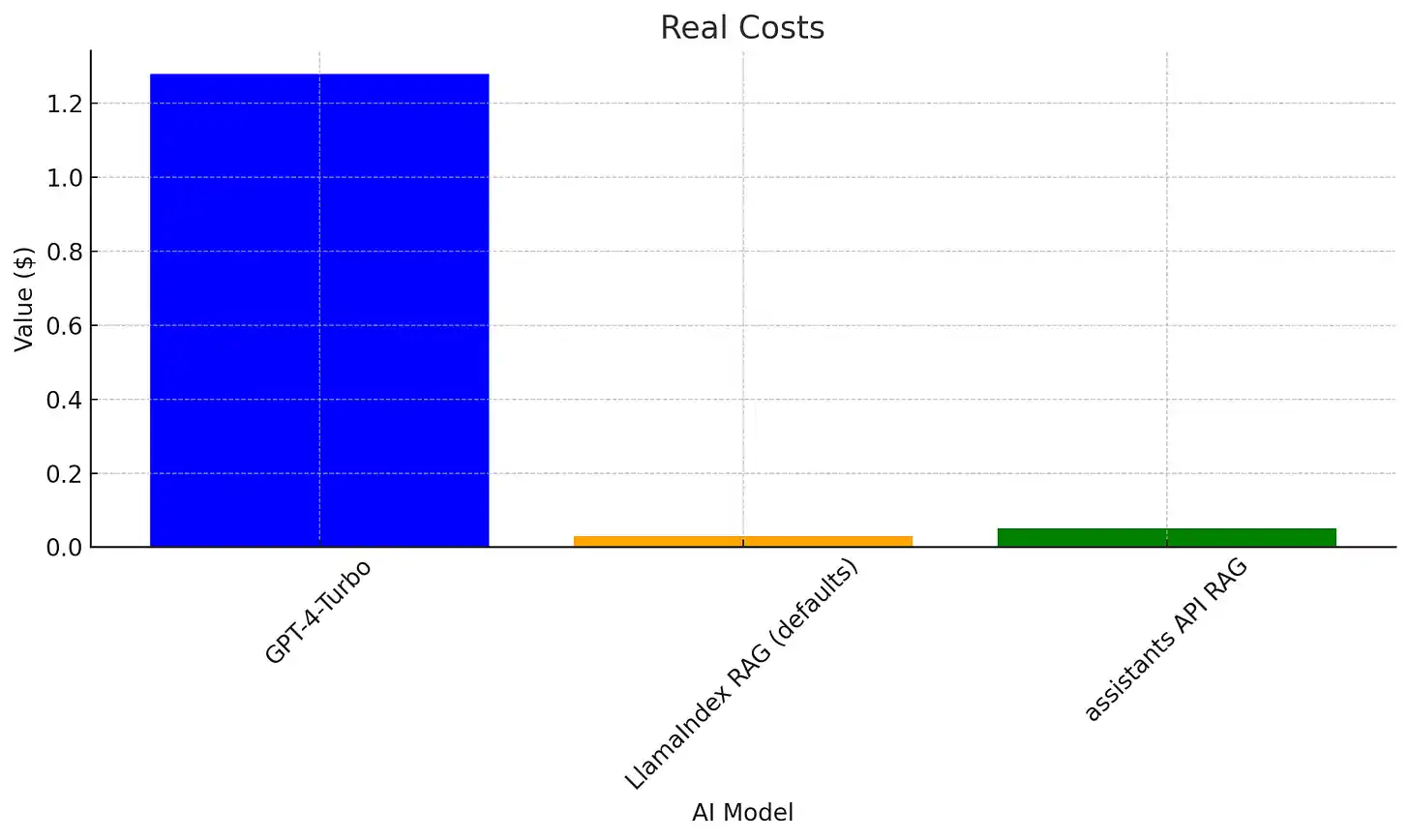
以 128k 上下文窗口为例,平均总成本大约是 每 1000 Token $0.0004,大约占 GPT-4-Turbo 成本的 4%。
而 LlamaIndex 的成本稍低,每 1000 Token 为 $0.00028,原因是它采用了相对简单的智能体循环机制。
(3) 延迟分析
通常情况下,对离线数据进行的 RAG 操作的检索延迟是以毫秒计算的,而整个过程的延迟则主要取决于大语言模型(LLM)的调用时间。
但对比一下从上传文档到获得结果的整个过程的延迟会很有意思, 特别是为了了解 RAG 在面对“在线”数据时是否能与之竞争(相对于离线数据)。简单来说,答案是肯定的!
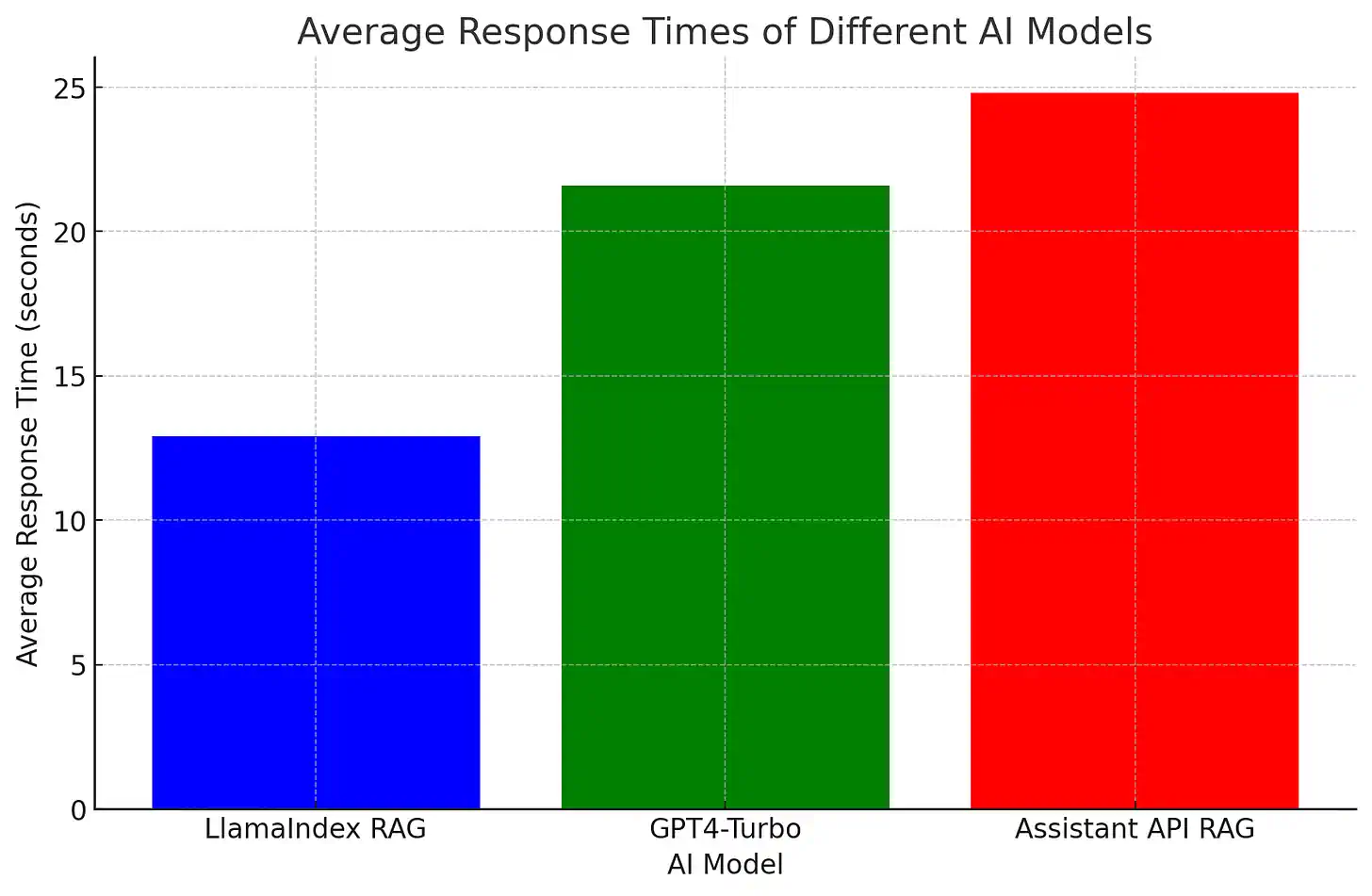
以下是对 128k token 文档 进行查询时的整体延迟情况:
-
LlamaIndex RAG 的平均延迟最短,为 12.9 秒。
-
GPT4-Turbo 紧随其后,平均延迟为 21.6 秒 - 但实际延迟从 7 秒到 36 秒不等。
-
助手 API RAG 的检索延迟为 24.8 秒
另外,大部分应用都可以通过 乐观上传文档 的方式来减少用户感知的延迟。由于 RAG 索引的成本非常低,这样做几乎没有什么损失。
方法论
我在 Greg Kamradt 的杰出研究基础上进一步发展了我的工作。Greg 最近发布了关于 GPT-4-Turbo 和 Claude 2.1 在“大海捞针”测试中的表现。
我们的方法很简单,就像在“大海”里隐藏一根“针”,然后探询这根“针”的位置。我把“针”放在“大海”中的不同位置,从起点到终点,每隔约 10% 改变一次。
在上下文窗口填充的实验中,我直接将这个“大海”放进了大语言模型的上下文窗口里。在 RAG 实验中,我创建了一个文档,并在这个文档上使用了 RAG。
(如同 Greg 精彩的分析所述,这个“大海”是由 Paul Graham 的文章组成的,而“针”则是一个与之无关的小知识。)
分析
(1) 准确性
GPT-4 加上 RAG 展示了出色的表现。
这个发现并不令人意外。把无关信息加入到大语言模型的上下文窗口里不仅代价高昂,而且还会对性能产生负面影响。少了这些无关信息,结果自然更佳。
这个结果突显出我们仍处于大语言模型革命的初期。 整个社区还在探索如何更合理地将这些新型大语言模型的组件结合起来。过去一年中,围绕上下文窗口的争论可能会平淡地结束——我们渐渐认识到,对于处理文本信息而言,关键在于运用越来越先进的 RAG 技术,而不是简单地扩大上下文窗口的大小。
LlamaIndex
在测试 RAG 时,我原以为随着上下文窗口的扩大,它的表现会大体一致。但事实并非如此 — 我发现当上下文长度超过大约 100k 后,性能明显下降了。我怀疑这是因为超出了某个临界点,检索过程没能有效地找到关键信息。我打算深入研究一下底层机制来验证这一猜想(也许会在下一篇文章中提及)。
当然,不同的数据分块和检索设置可能会影响这个结果。不过我这次测试主要是针对默认设置。
总体来看,我对 LlamaIndex 以及开源大语言模型技术持乐观态度。 RAG 还处于容易取得进展的阶段,而简化操作框架显得尤为关键。LlamaIndex 很可能会继续吸收新技术和最佳实践。
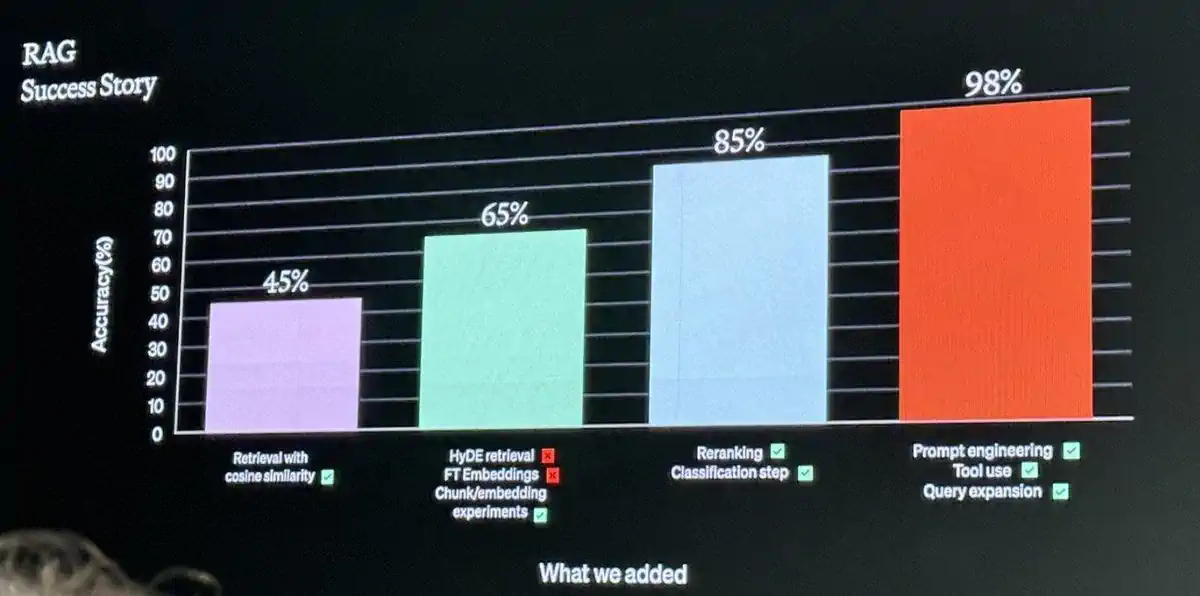
这张 OpenAI DevDay 的泄露幻灯片可能会给你一些启发:
(2) 成本
关于 RAG 的成本分析,需要注意的是,它不完全是确定性的。
RAG 的第一步是检索 - 它从大量数据中挑选出最有可能的文档片段,这个选择通常是基于一些规则(如向量搜索)。第二步是生成增强 - 将挑选出的片段输入到标准的大语言模型中,或者像 OpenAI 那样,使用 AI 智能体循环进行处理。
理论上,检索可以通过多种方式实现,比如关键词搜索、关系搜索或混合方法。但实际上,现代的 RAG 方法多数依赖向量搜索 - 这种方式对每个 Token 有一次性的索引成本。随着技术的发展,我们可能会看到越来越多的混合技术被采用。
每个 Token 的成本分析
首先,我们来看看不同场景下每个 Token 的成本情况:
-
GPT-4-Turbo 对输入的 Token收费为每千个 0.01 美元。
(这比 GPT-4 和 GPT-4-32k 分别便宜了 3 倍和 6 倍)。 -
OpenAI 的ada v2嵌入模型的收费是每千个 Token 0.0001 美元,比 GPT-4-Turbo 便宜了 100 倍。
-
OpenAI 助理 API 的检索功能价格更为低廉,按“无服务器”方式计费,每 GB 每助理每天收费 0.20 美元。假设 1 Token 约 5 字节,这相当于每千个 Token 每助理每天仅需 0.000001 美元。
这比 ada v2 便宜 100 倍,比 GPT-4 输入的 Token 便宜了 10,000 倍。
固定成本分析
关于固定成本,很难具体计算(在 OpenAI 的情况下甚至不可能),所以我是根据实际操作来估算的。
根据结果部分所述,RAG 也会产生一定的固定成本,这主要是由 LLM 推理步骤造成的。在 128k 的上下文中,这种固定成本大约占 GPT-4 上下文窗口的 4%。
简单估算表明,从成本角度考虑,只有当上下文窗口小于 5k 时,使用上下文填充才划算。
(3) 延迟问题
理论上,嵌入计算可以高度并行化。因此,随着市场需求的增长,未来基础设施的改进很可能会显著降低延迟,甚至达到单个块嵌入往返时间的水平。
在这种情况下,即使是“在线”RAG 管道的延迟也会大幅缩短,届时“在线”RAG 的延迟将主要受到 LLM 思维链环节的延迟影响。
—
结束语
充满期待的未来即将来临。
如果你正打算在你的应用中集成 Copilot,对贡献感兴趣,或者想了解和参与开放 Copilot 协议的发展,不要忘记加入我们的 GitHub 或 Discord!