关于 Viberary 的回顾 [译]
Vicki Boykis
Viberary 是我在 2023 年进行的一个副项目,主要功能是根据读者的情感倾向(vibe)来进行图书的语义搜索。项目网站托管在 [viberary.pizza]。
由于以下原因,我决定关闭这个应用程序,并将其代码库转为维护状态:
- 我想要在该项目上继续进行的工作(比如更换嵌入模型 (embedding models),修改训练数据)需要构建更加复杂的基础架构,如模型库、特征库 (feature store)、数据管理和评估基础设施,这些工作所需的时间远超过我所能投入的。
- 维护一个运行中的应用程序(如 Python 依赖等)需要大量工作。就像 所有代码都是技术债务。
- 成本考虑。我不愿意维护一个每月亏损超过 100 美元的应用程序,特别是当我没有计划通过它盈利时。尽管如此,我从这个项目中学到了很多,并且我很享受构建和分享它的过程。
- 我有了一个新的项目想法,需要为其腾出时间和空间。
通过这个项目,我学到了许多宝贵的经验。这些经验大部分在下面的文章中有详细介绍,所以请继续阅读。但如果你想要一个总结,这里有一些要点:
- 项目必须是你真正感兴趣的。只有这样,你才会投入其中。我热爱阅读,渴望获得好书推荐,而且在开始这个项目之前,我已经对这个领域有了深入的了解。
- 尽量简单地开始,但不要过于简化。你应该能够在本地测试你部署的任何内容,而无需依赖外部因素。项目初期的高效进展是保持兴趣的关键。
- 同时,你只有在尝试了一些事情后,才会知道什么是简单的。
- “简单”意味着你编写的大多数代码应该是库逻辑,而非云组件间的粘合代码。
- 将 Docker 适配到新的 Mac M1+ 架构并移植到 Linux 可能会遇到一些麻烦,但这是可以解决的。
- 熟练掌握 nginx 可以大大节省时间。
- 有时候,你不需要使用大型语言模型 (LLM),BERT 就已经足够好用。
- 评估无监督排名和检索的结果是非常困难的,这个问题目前还没有人能够完全解决。
- Digital Ocean 提供了一系列适合小型和中等规模项目的出色产品。
- 自己构建并发布产品的成就感是无与伦比的。
想要了解更多细节,请继续阅读!

2023 年 8 月 5 日
简要概述: Viberary 是我创立的一个副项目,旨在通过氛围来查找书籍。我创建这个项目,一方面是为了满足自己进行机器学习侧项目的兴趣,另一方面是为了探索当前搜索和推荐技术的界限。这个项目不仅是对我最近在嵌入技术方面深入研究的一个补充,而且是一个符合生产级标准的实践。
虽然这个项目很有趣,但它也确切地证实了我一直以来对自己的理解:达到 MLE(机器学习启蒙)是一个循环过程,涉及建模、工程和 UI 设计等多个方面,并将这些方面紧密结合在一起 - 将系统投入生产就是最终的奖赏。和任何生产级系统一样,机器学习并非魔法,即使数据输出不是确定性的,构建这类系统也需要精心的工程和设计选择。我认为,这是当前机器学习领域中常被忽视的一个方面。
通过这篇文章,我不仅想要回顾我所做的工作,还想概述一下搭建一个基于 Transformer 的机器学习应用所需的一切,哪怕是一个小型的、使用预训练模型的应用,我希望这篇文章能成为一个有用的资源和参考。
Viberary 的机器学习架构是一个基于双塔模型的语义检索系统。它使用Sentence Transformers 预训练的不对称 MSMarco 模型对用户的搜索查询和 Goodreads 书籍数据库进行编码。

训练数据是在本地通过处理 JSON 的 DuckDB生成的。模型经转换为 ONNX 格式,以实现高效推理,并在AWS P3 实例上学习获得的语料库嵌入,存储于 Redis。检索过程使用Redis 搜索功能,结合HNSW 算法在余弦相似度上进行搜索。结果通过运行四个Gunicorn工作进程的 Flask API 提供,并通过 Flask 静态渲染Jinja 模板功能展现在Bootstrap 前端上。项目内部没有依赖于 JavaScript。
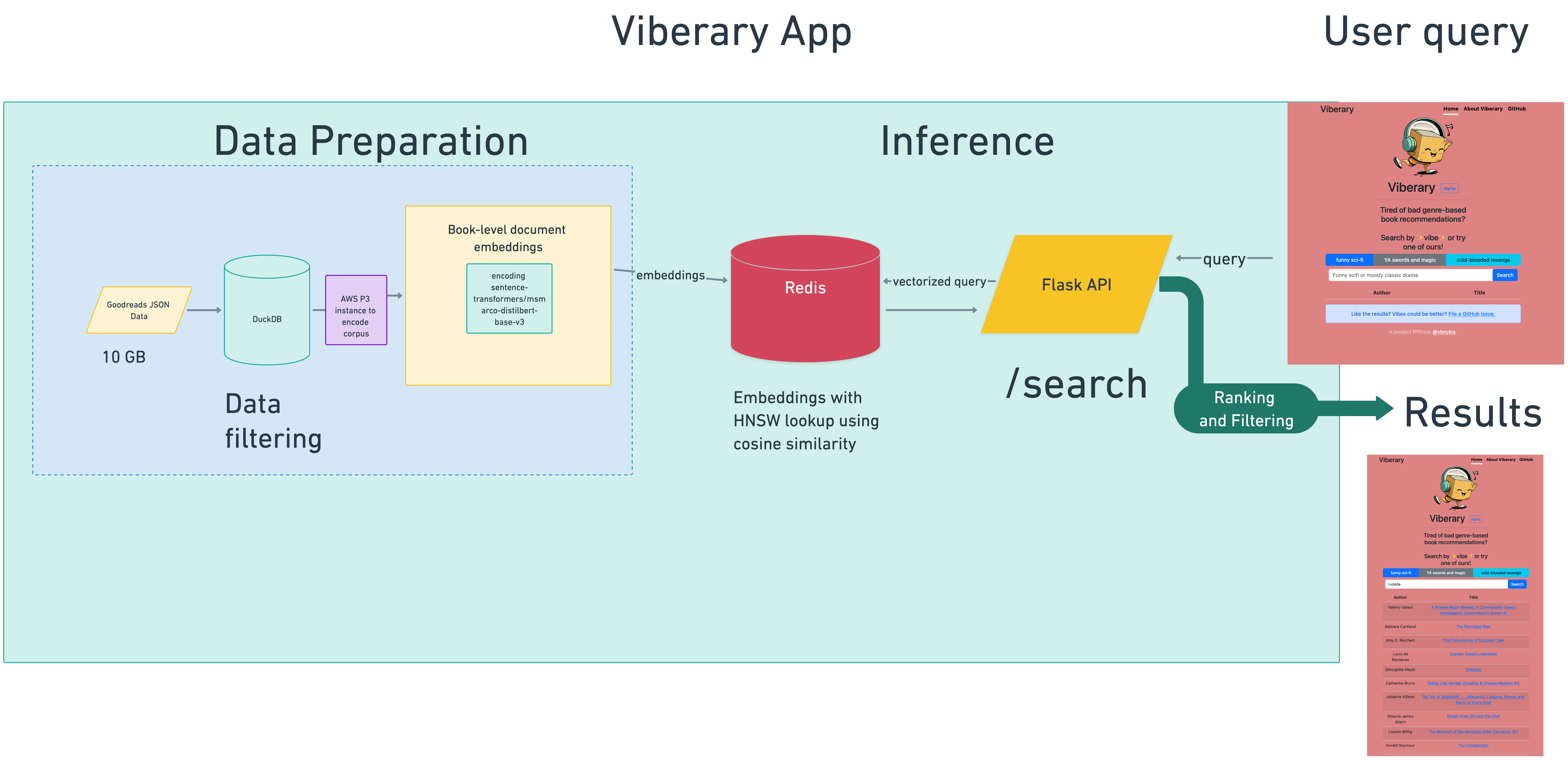
该系统部署在两个Digital Ocean 云服务器上,通过Digital Ocean 负载均衡器和Nginx进行管理。作为一个 Docker 化的应用,它通过 Docker compose 在 Web 服务器和 Redis Docker 镜像之间建立网络,数据则持久化到DigitalOcean 提供的外部卷上。[Digital Ocean] 还负责域名注册和负载均衡器的路由设置。

可部署的代码工件是通过GitHub Actions在仓库的主分支上自动生成的。然后我会手动通过 Makefile 命令更新云服务器上的 Docker 镜像。目前,这个系统在当前规模下运行得相当顺畅。
什么是语义搜索?
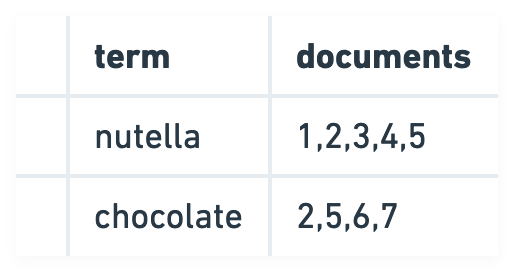
Viberary 是一个基于语义搜索的图书搜索引擎。与传统的基于关键字匹配的搜索引擎不同,它通过✨氛围✨来搜索书籍。例如,在传统搜索引擎中,如果你输入“Nutella”,它会寻找所有包含“Nutella”这个词的文档。
传统搜索引擎(如 Elasticsearch/OpenSearch)通过构建倒排索引(一种键为术语、值为匹配该术语的所有文档集合的数据结构)来高效地进行查找。从倒排索引中的检索性能可以变化,但在最佳情况下的时间复杂度为O(1),表现出高效性。
倒排索引的常见检索方法之一是BM25,它基于TF-IDF计算每个元素的相关性得分。检索机制先从索引中选择所有包含关键字的文档,计算其相关性得分,然后根据这些得分对文档进行排序。
与之相对的是,语义搜索关注于寻找基于近义词的意义,正如《AI 助力搜索》一书中所述,它关注的是“事物,而非字符串”。换句话说,
“如果你搜索‘狗’这个词,能够找到包含‘贵宾犬’、‘梗犬’和‘比格犬’等词汇的文档,即使这些文档中并没有直接使用‘狗’这个词,那岂不是很好?”
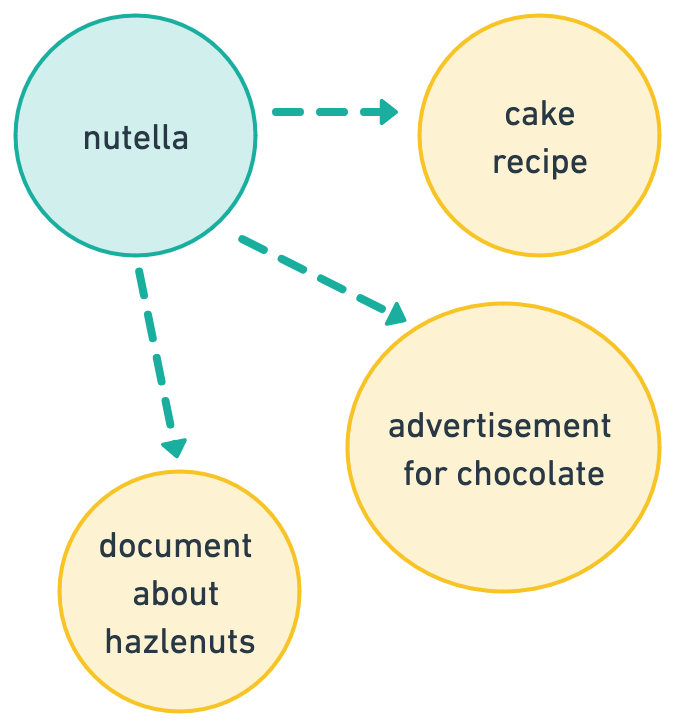
语义搜索可以被看作是一种氛围感。氛围感可能难以具体定义,但通常它更多关联于一种感觉,而非具体的东西:一种心境、一种颜色或一个短语。例如,Viberary 在搜索时不会直接为“Nutella”提供精确匹配,但如果你输入“巧克力榛子美味”,它预期会找到与 Nutella 相关的内容,甚至可能包括“蛋糕”和“费列罗”。
如今,许多搜索引擎采用了关键字和语义相结合的方法,这被称为混合搜索。语义搜索包括诸如学习排序、结合多种检索模型、查询扩展(通过添加同义词来丰富搜索结果)、基于用户历史和位置的上下文搜索,以及向量相似性搜索(使用自然语言处理技术帮助将用户查询映射到向量空间)等方法。

语义搜索的挑战是信息检索领域的研究者和公司数十年来一直在努力解决的问题。这个领域最初起源于图书馆学。例如,1998 年介绍谷歌的论文就讨论了仅限于关键词搜索的问题。
Netflix 是最早开始进行基于氛围的内容探索的公司之一,它在 2010 年代提出了超过 36,000 种类型的列表,如“温和的英国真人秀”和“巫术与黑暗艺术”。他们动用了大量的团队来观看电影并用元数据进行标记。这个过程非常详细,标签人员甚至收到了一份 36 页的文件,教他们如何根据性暗示内容、血腥程度、浪漫水平以及情节的完整性等因素来评估电影。
Netflix 将这些标签纳入其推荐架构,作为训练数据的特征。
将这些特征融入推荐系统比搜索系统更为容易,因为推荐是通过分析用户数据隐式学习用户偏好,并根据他们的历史行为以及整个平台用户的历史,或者基于内容本身的特性,向他们推荐内容或商品。因此,[推荐界面通常包括如"你可能会喜欢..."、"为你推荐"或"因为你与 X 互动..."等建议列表。
而搜索则是一个用户期望他们的查询与结果精确匹配的活动,因此用户对现代搜索界面有特定的期望。
- 他们是 极其响应迅速且低延迟的
- 结果准确,我们在第一页就能得到我们需要的内容
- 我们使用文本框的方式就像我们过去 30 年里被训练 使用 Google 搜索那样,在 SERP(搜索引擎结果页面)中
因此,在某些方面,传统搜索界面和语义搜索成功所依赖的特征之间存在一种紧张关系,因为语义搜索处于搜索和推荐之间的灰色地带,而传统搜索期望对确切查询得到确切结果。在设计对话或语义搜索界面时,这些都是需要牢记的重要方面。更
为什么要进行书籍的语义搜索?
我酷爱阅读,尤其偏爱小说。阅读已成为我的日常。你可以浏览我的过往书评,如 2021 年,2020 年,2019 年,便可一窥究竟。身为狂热读者,我总在寻觅佳作。通常我会在诸如 LitHub 这样的网站上寻找推荐,但有时我会特别想寻找某一类型或能唤起特定感觉的书。例如,读完 Richard Powers 的《The Overstory》 后,我迫切希望阅读更多关于神秘主题的多代传奇巨著(现在我对树木可谓了如指掌!)
然而,除非有位博览群书的人亲自整理,否则你很难找到如此精心策划、品质卓越的推荐书单。我最钟爱的一种推荐形式是 Biblioracle,在这里,读者会向 John Warner —— 一位极富阅读经验的小说家 —— 提供他们最近读过的五本书,他会基于他们的阅读喜好推荐下一本书。
随着语义搜索和向量数据库日渐兴盛,加之我最近完成的关于嵌入(embeddings)的论文,我开始构想,若能打造一个书籍搜索引擎,至少在某种程度上能模拟得上那些书籍狂热分子的推荐,那该多好。
我的起点是将这个机器学习任务定义为一个推荐问题:如果你对用户或物品有所了解,能否生成一个类似用户喜欢的物品列表?这可以通过协同过滤(collaborative filtering)来实现,它依据以往的用户 - 物品互动,或者通过内容过滤(content filtering),即仅根据物品的元数据来寻找相似物品。鉴于我无意深入用户数据收集,除非是搜索查询和搜索结果列表(我确实会记录这些数据,以期微调模型或在查询时提供建议),因此协同过滤从一开始就被排除了。
对于书籍来说,基于内容的过滤(即关注书籍元数据而非围绕内容的具体行为)效果甚佳。然而,这种方法同样需要用户偏好信息,而我并未保留这些数据。
我意识到,用户必须提供查询的上下文来启动推荐过程,但我们对用户本身一无所知。根据这个启发式原则,问题开始转向搜索领域。

另一个考虑点是,传统的推荐界面通常是在用户登录时呈现的卡片或列表,这是我没有且不打算从前端实现的。我希望用户能够自行输入搜索查询。
这个想法最终演化成一种认识,即在我的项目限制和偏好下,我所面临的实际上是一个特定于书籍的非个性化语义搜索问题。
经过文献调研后,我找到了一篇极好的论文,恰好描述了我想解决的问题,只是它应用于电子商务领域。

该论文描述的问题更为复杂,因为他们不仅要进行语义搜索,还要将其个性化,并且需要从零开始基于手头的数据学习一个模型。但是,这种架构是我可以在我的项目中采用的,而我实际需要实施的是其简化的在线服务部分。
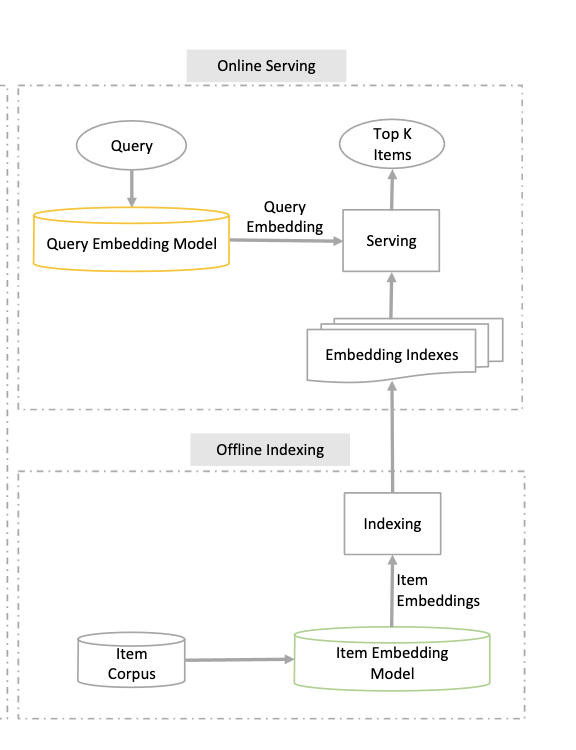
构建语义搜索
构建语义搜索包含几个关键阶段,这些阶段与传统的四阶段推荐系统中的某些阶段相似:

- 数据收集
- 建模并生成嵌入(embeddings)
- 对嵌入内容进行索引
- 模型推断,包括筛选
还有一个第五阶段,通常不包含在搜索/推荐系统架构中,但同样至关重要,那就是搜索/对话式用户体验(UX)设计。
大部分搜索和推荐架构都有一套基本的共同特性,这些特性是我们多年来持续发展的。有趣的是,Tapestry,上世纪 90 年代开发的首批工业级推荐系统之一,用于协同筛选电子邮件,其结构与当今任何搜索和推荐系统极为相似,包括了索引和筛选等组成部分。
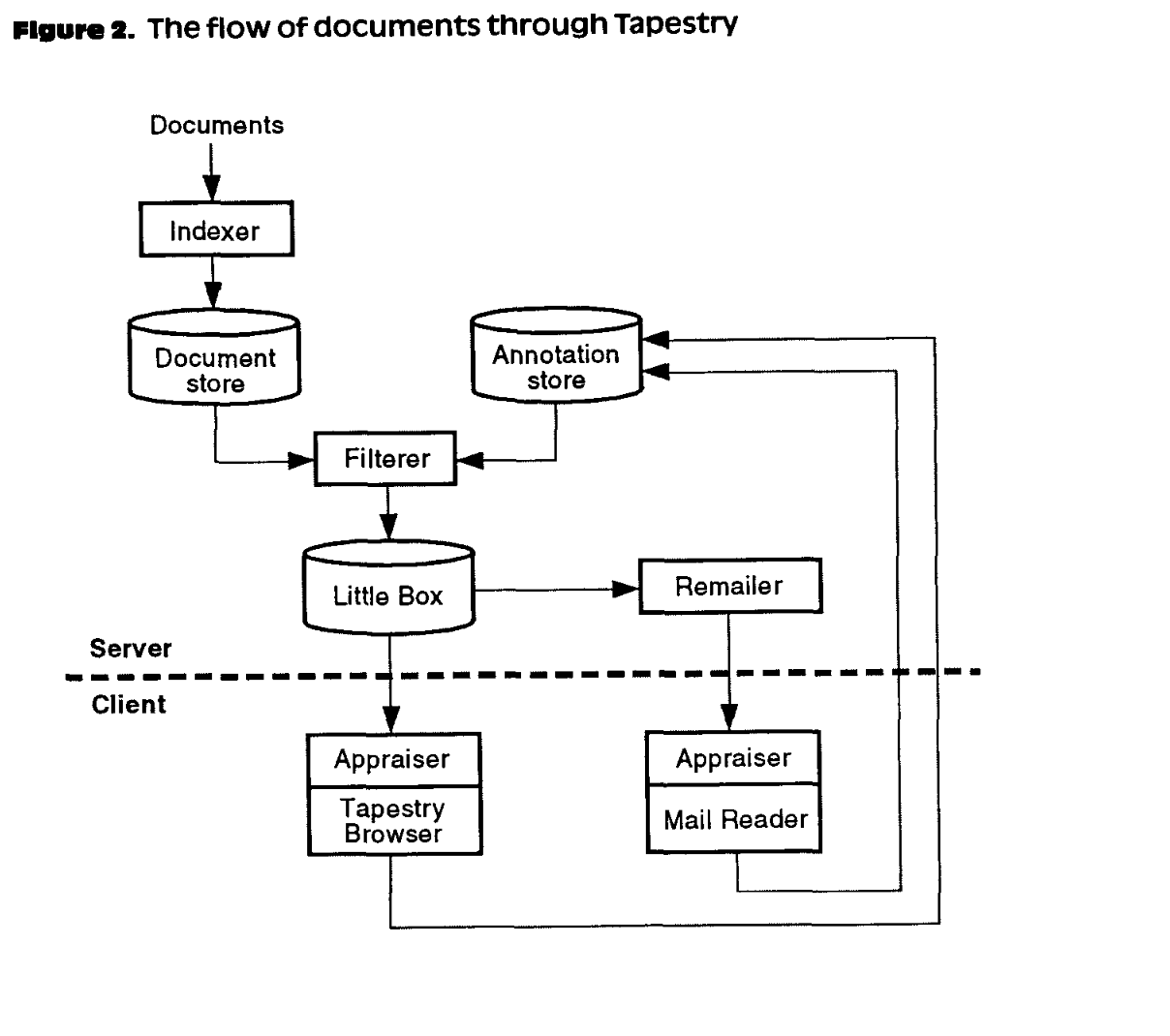
我们的工作从收集和处理大量文档开始。在信息检索的过程中,我们的目标是找到与我们相关的文档,无论“相关”如何定义。我们通过索引功能对这些文档集进行更新,使其能够进行大规模搜索。我们利用启发式方法或机器学习技术选出一组相关文档的候选集。在我们的例子中,这是通过查找与我们在查询框中输入的文本类似的压缩数值表示来完成的。这些表示是利用属于变换器(Transformer)家族的深度学习模型创建的嵌入空间生成的。
接下来,当我们找到大约 50 个可能与查询相关的候选项后,我们会对它们进行筛选并最终排名,最后通过前端界面展示给用户。
此外,还有许多与之相关的问题并未列出,但它们是机器学习项目核心的组成部分:对干净数据的迭代、线上和线下测试的评估指标、随时间监控模型在生产中的性能、在模型商店中跟踪模型工件、探索性数据分析、创建过滤规则的业务逻辑、用户测试等等。考虑到时间因素,我决定在项目合理的情况下省略掉其中的一些步骤。
项目架构决策
面对这个项目的架构和时间限制,我在几个方面对自己进行了约束。首先,我决定做一个范围明确且含有用户界面的项目,这样能激发我去完成它,因为最失败的机器学习项目就是那些永远没完成的。Mitch 在他的博客中提到,如果你能展示一些实实在在的成果,自然就会有动力继续前进。
其次,我想要在探索新技术的同时,也注意不要浪费我的创新代币。简而言之,我打算构建一些常规的东西,选择合适的工具完成合适的工作,并且不走极端。我不打算从大型语言模型、Kubernetes、Flink 或 MLOps 开始。相反,我会从编写简单的 Python 类开始,并根据实际需求逐步完善。
第三个考虑是尽量忽略当前机器学习生态系统的炒作,即那些每天都在推出新模型、新产品及其包装的喧嚣。这并不容易,特别是在大量关于大型语言模型的讨论中尝试专注于构建,尤其是当这些讨论已经在整个社会上广泛传播时。
最后,我希望将所有内容构建成一个传统的、独立的应用程序,其中包括各种易于理解且可在应用中重复使用的组件。目前的架构如下所示:
├── __init__.py├── api│ ├── __init__.py│ ├── main.py - runs the API and defines routes│ ├── static - all the static assets for the site│ ├── templates - index.HTML│ └── wsgi.py - serves the API via gunicorn├── conf│ ├── __init__.py│ ├── config_manager.py - Allows access to config files│ └── redis_conn.py - Connection to Redis├── index - Embeddings indexing operations│ ├── __init__.py│ ├── index_embeddings.py - Runs index delete and reindexing as a module│ ├── index_fields.py - Field schema│ ├── indexer.py - Indexer class that calls Redis and performs indexing│ ├── parquet_reader.py - Reads embeddings parquet file into embeddings index│ └── tests├── load│ └── load_test.py - Locust load testing├── model│ ├── README.md│ ├── __init__.py│ ├── generate_embeddings.ipynb - Generates embeddings on a P3 instance on AWS│ ├── generate_training_data.py - Cleans training data│ ├── onnx_embedding_generator.py - Converts model to ONNX for fast inference│ └── sentence_embedding_pipeline.py - ONNX helper module├── notebooks - exploratory code│ ├── 00_viberary_json_eda.ipynb│ ├── 01_memray_tracing.ipynb│ ├── 02_parquet_eda.ipynb│ ├── 03_duckdb_eda.ipynb│ ├── 04_word2vec.ipynb│ ├── 05_duckdb_0.7.1.ipynb│ ├── 06_doc2vec.ipynb│ ├── 07_bert_sentence_transformer.ipynb│ ├── 08_bert_sentence_transformer_gpu.ipynb│ ├── 09_redis_query_tuning.ipynb│ ├── cbow.ipynb│ ├── onnx.ipynb│ └── redis_hset.ipynb├── search│ ├── __init__.py│ ├── knn_search.py - Search inference module│ └── tests└── training_data└── 20230711_learned_embeddings.snappy
查看原始内容structure.md 由 GitHub ❤ 托管
我本希望能说这一切都是事先计划好的,而最终完成的项目完全符合我的预想。但实际上,就像任何工程项目一样,我遇到了一些曲折和挫折。起初我采用了大型云服务,这是一个策略上的失误,因为我发现很难深入理解云组件的工作原理,这不仅浪费了大量时间,也让我感到沮丧。这一选择拖慢了开发进程。最终,我转而使用 DuckDB 进行本地数据处理,但在理解数据并做出这一改变上仍然花费了很长时间,这在任何以数据为中心的项目中都是常见的。
接着,我花了很多时间在Word2Vec 上构建基准模型,以便为 Transformer 时代之前的基础文本检索方法提供一些参考。最后,在从本地开发转向生产的过程中,我遇到了许多不同的难题,这些难题主要与优化 Docker 镜像大小、考虑适合的机器规模、Docker 网络配置、流量负载测试,以及在负载均衡器后正确配置 Nginx 路由有关。
总体来说,我对这个项目感到非常满意。它是在Normconf 精神的指导下,以及我从这个领域的实践者那里学到并应用的众多实用 ML 工程理念的成果。
技术栈
我的项目技术栈,目前主要是基于 Python 在 虚拟环境 中开发的,配置文件为 requirements.txt,具体包括:
- 原始数据以 gzipped JSON 格式存储于本地,未纳入版本控制
- 利用 DuckDB 的 Python 客户端处理这些文件
- 使用 SBERT 对文档进行模型嵌入编码,特别采用了 MS-Marco Asymmetric 模型
- 部署了一个 Redis 实例,创建了一个专门的搜索索引,用于嵌入的检索
- 通过 Flask API 设计了一个搜索查询路由,该路由使用相同的 MS-Marco 模型对查询进行编码,然后实时在 Redis 搜索索引中进行 HNSW 查找
- 搭建了一个 Bootstrap UI 界面,展示前 10 名的搜索结果
- 根据架构(arm 或 AMD)使用 Dockerfile 在 docker compose 网络配置中封装了 Redis 和 Flask
- 一个 Makefile 用于执行应用周边的常规操作,如重新索引嵌入和启动应用
- 在托管服务器上部署 Nginx,用于将负载均衡器的请求进行反向代理
- 使用 pre-commit 进行代码格式化和静态检查
- 采用 Locust 进行负载测试
- 设置了一个日志模块,用于记录查询和输出
- 并且在 pytest 中编写了测试用例
工具
- 使用 PyCharm 进行开发,包括在 Docker 中通过绑定挂载的方式
- iterm2
- 特别使用 VSCode 编写文档,因为它在这方面比 PyCharm 更加友好
- 使用 Whimsical 绘制图表
- Mac 上的 Docker Desktop(曾考虑短暂切换到 Podman,但还未实施)
训练数据
原始图书数据源自 UCSD 书籍图谱(UCSD Book Graph),这些数据是在 2017-2019 年间从 Goodreads 网站爬取的,主要用于学术研究。
这些数据被存储在几个压缩的 JSON 文件中:
样本行:请注意,所有内容均以字符串形式编码!
{"isbn": "0413675106","text_reviews_count": "2","series": ["1070125"],"country_code": "US","language_code": "","popular_shelves": [{"count": "2979","name": "to-read"},{"count": "291","name": "philosophy"}],"asin": "","is_ebook": "false","average_rating": "3.81","kindle_asin": "","similar_books": ["888460"],"description": "Taoist philosophy explained using examples from A A Milne's Winnie-the-Pooh.","format": "","link": "https://www.goodreads.com/book/show/89371.The_Te_Of_Piglet","authors": [{"author_id": "27397","role": ""}],"publisher": "","num_pages": "","publication_day": "","isbn13": "9780413675101","publication_month": "","edition_information": "","publication_year": "","url": "https://www.goodreads.com/book/show/89371.The_Te_Of_Piglet","image_url": "https://s.gr-assets.com/assets/nophoto/book/111x148-bcc042a9c91a29c1d680899eff700a03.png","book_id": "89371","ratings_count": "11","work_id": "41333541","title": "The Te Of Piglet","title_without_series": "The Te Of Piglet"}
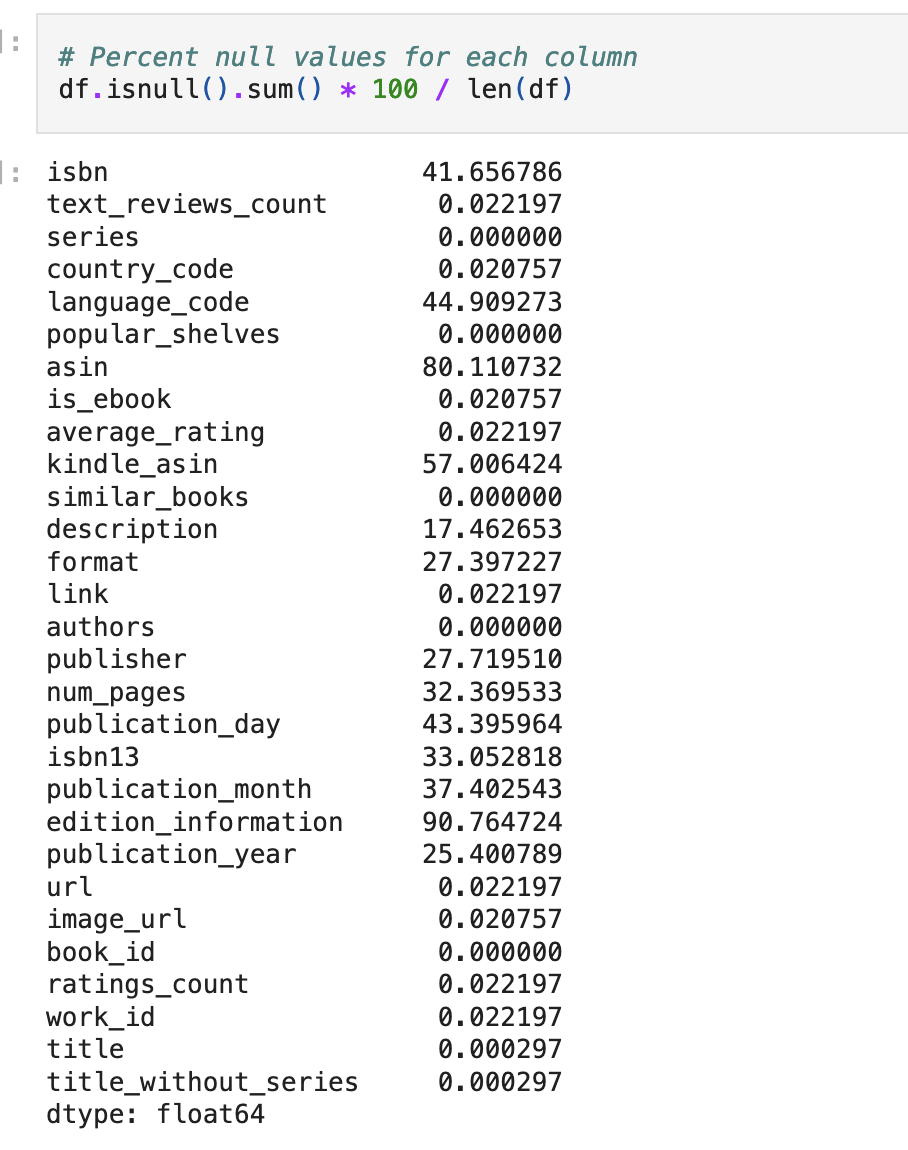
这批数据包含了大量有价值的信息!因此,像一名优秀的数据科学家那样,我首先进行了一些数据探索,以便更好地了解我手头的数据。我想要了解这个数据集的完整性、缺失数据量、评论主要使用的语言等,这些都将有助于理解模型的嵌入空间(embedding space)。
数据的输入格式通常如下所示:

接着,我在 DuckDB 中创建了几个表格,用于向嵌入模型(embedding model)发送信息,以生成文本的嵌入(embeddings)。最终,这些表格之间的关系如下图所示:
SELECTreview_text,goodreads_auth_ids.title,link,goodreads_auth_ids.description,goodreads_auth_ids.average_rating,goodreads_authors.name AS author,text_reviews_count,review_text || goodreads_auth_ids.title || goodreads_auth_ids.description|| goodreads_authors.name as sentenceFROM goodreads_auth_idsJOIN goodreads_reviewsON goodreads_auth_ids.book_id = goodreads_reviews.book_idJOIN goodreads_authorsON goodreads_auth_ids.author_id = goodreads_authors.author_idWHERE goodreads_auth_ids.author_id NOT ILIKE ''
查看原文book_sql.sql 由 GitHub ❤ 托管
其中最重要的列是 sentence,它将 review_text、goodreads_auth_ids.title 和 goodreads_auth_ids.description 连接起来。这一列作为文档的代表,被用于向嵌入模型呈现,并用于生成数值表示和查找输入向量之间的相似性。
关于这批数据,有几点需要注意。首先,由于数据来自 2019 年,因此基于这些数据的推荐时效性可能不佳,但它在经典书籍方面的表现应该还不错。其次,鉴于 Goodreads 不再提供 API,以任何合理的方式更新这些数据已成不可能。未来,Viberary 可能会考虑使用像 Open Library 这样的资源,但这需要大量基础数据工作。第三,这批数据存在明显的英语偏见,这意味着如果我们想将 Viberary 国际化,在其他语言中可能难以获得良好的查询结果。

最后,在检视每列数据的可用性时,我们发现作者、标题、评分和描述等方面的数据集相对完整(较低的百分比意味着每列的空值更少),这意味着我们能够利用我们的大部分数据来表示嵌入语料库。
模型
要深入理解这一节的背景,可以阅读我的嵌入论文。
Viberary 利用 Sentence Transformers,一种改进了的 BERT(Bidirectional Encoder Representations fromTransformers)架构。这个版本的 BERT 通过降低计算成本,使得为句子对生成嵌入变得更加高效和便捷。与原始 BERT 模型相比,Sentence Transformers 可以更快地生成并比较基于余弦相似度的句子级嵌入。
这种方法非常适合我们的需求。我们的输入文档通常包含几个句子,而我们的查询则类似于短句,长度通常不超过 10 或 11 个单词。
BERT 是一种基于双向编码器的 Transformer 模型,于 2018 年由谷歌发布。它旨在解决诸如情感分析、问答和文本摘要等常见的自然语言处理任务。BERT 的架构独特,仅包括编码器部分。它在 Google 搜索中的应用尤为显著,用于提高搜索结果的相关性。2019 年,谷歌在其博客中提到,他们将 BERT 纳入搜索排名,以上下文信息取代传统的关键字搜索方法。作为一种掩码语言模型 (masked language model),BERT 的工作方式是在句子中去除某些单词,然后预测填补这些空白的单词的概率。BERT 的“双向” (bi-directional) 特性意味着它能够通过缩放点积注意力机制来同时关注前后文。BERT 包含 12 层 Transformer 层,使用 WordPiece 算法将单词分割成子词(Token)。训练 BERT 的目标是根据上下文预测 Token。
BERT 的输出是单词及其上下文的潜在表示,即一组嵌入。本质上,BERT 是一个能够记住更长上下文窗口的巨大并行 Word2Vec。由于其灵活性,BERT 可用于多种任务,包括翻译、摘要和自动补全。但由于缺乏解码器组件,它无法生成文本,为 GPT 模型接替其位置铺平了道路。
然而,BERT 的架构不适合并行处理句子相似度计算,这正是 Sentence Transformers 的用武之地。
当我们有两个句子 a 和 b,它们来自于以 BERT 或类似模型为基础的上游模型,我们的目标是学习一个能输出这两个句子相似度得分的模型。在生成这个得分的过程中,模型的中间层会产生子句和单词的嵌入,我们可以利用这些嵌入来对查询和语料库进行编码,从而进行语义相似度匹配。
对于两个输入句子,我们通过句子变换器网络处理,并对句子中的单词/子词嵌入进行平均池化(即求平均值),然后利用余弦相似度——一种在多维向量空间中表现良好的常用距离度量——来比较最终的嵌入。

Sentence Transformers 提供了许多基于这种架构的预训练模型,其中最常见的是 sentence-transformers/all-MiniLM-L6-v2。该模型 将句子和段落映射 到一个 384 维的向量空间中,即每个句子被编码成一个包含 384 个数值的向量。
最初,这个模型的表现 只是一般,这让我面临一个选择:是更换一个不同的模型,还是对现有模型进行调整。我考虑的另一个模型是一系列基于 Bing 搜索样本训练的 MSMarco 模型。这些模型更接近我所需。此外,由于 搜索任务的不对称性,这些模型考虑到了语料库向量通常比查询向量长的情况。
我最终选择了 msmarco-distilbert-base-v3 模型。这款模型在性能上处于中等水平,关键是它专为余弦相似度查找而调整,而不是点积相似度——一种同时考虑大小和方向的度量方法。余弦相似度只考虑方向而非大小,因此更适合用于文本信息检索,因为它不太受文本长度的影响,且能更有效地处理数据的稀疏表示。
但这一系列模型的一个问题是,它们的向量长度是之前的两倍,达到了 768 维。向量越长,处理它就越计算密集,运行时间和内存需求与输入长度成二次方关系增长。然而,更长的向量意味着它能够压缩更多原始输入信息,因此在编码更多信息和加快推理速度之间,总是存在微妙的平衡,这对于搜索应用来说至关重要。
在学习嵌入向量的过程中,选择合适的模型并非易事,特别是在目前全球广泛使用 GPU 的情况下。
我起初尝试使用 Colab,但很快发现,即使是付费用户,我的实例也经常在周五晚上无预警地被关闭或性能降级,那时许多人正忙于个人项目。

接着我尝试了 Paperspace,但我发现其用户界面并不容易操作。有趣的是,Paperspace 最近被我一直钟爱的 Digital Ocean 收购,这让我对 Digital Ocean 的好感进一步增加。最终,我选择在 AWS 上进行训练,因为我已经有了 AWS 账户,且在为 PyTorch 做 PR 的过程中,我已经配置好了适用于深度学习的 EC2 实例。
整个训练过程比我预期的要顺利得多,唯一的问题是 P3 实例由于广泛用于训练而很快就被占用完。不过,我的模型生成嵌入向量只用了大约 20 分钟,这对于机器学习来说是相当快的反馈周期。然后我把这些数据导出到一个 snappy 压缩格式的 parquet 文件,并手动将其上传到执行推理的服务器。
from sentence_transformers import SentenceTransformer, util# A common value for BERT & Co. are 512 word pieces, which correspond to about 300-400 words (for English).# Longer texts than this are truncated to the first x word pieces.# By default, the provided methods use a limit fo 128 word pieces, longer inputs will be truncated# the runtime and the memory requirement grows quadratic with the input length - we'll have to play around with this# Change the length to 200model = SentenceTransformer("sentence-transformers/msmarco-distilbert-base-v3")model.max_seq_length = 200corpus_embeddings = model.encode(corpus, show_progress_bar=True, device="cuda", convert_to_numpy=False)
Redis 和索引
在为模型学习了嵌入向量之后,我需要找一个地方存储它们,以便在推理时使用。当用户输入一个查询时,该查询也会被同一模型转换成嵌入向量,然后执行 KNN 查找。目前,市面上有大约五百万种方法可以存储嵌入向量,用于各种操作。
这些方法各有千秋,取决于你的需求。以下是我的选择标准:
- 我之前使用过的现有技术
- 我能够自主托管并深入了解的技术
- 能提供极快推理速度的解决方案
- 其软件包文档能够告诉你其所有组成数据结构的
O(n)性能时间
虽然最后一点我是开玩笑的,但这确实是我喜欢 Redis 文档的一大原因。由于我之前使用过 Redis 作为缓存,并且已经知道它非常可靠、简单易用,能很好地配合高流量的 Web 应用,而且还可以通过 Docker 打包(这对我下一步的生产部署非常重要),我选择了 Redis Search,它能够提供即开即用的存储和推理功能,并且支持频繁更新的 Python 模块。
Redis Search 是 Redis 的一个扩展组件,可以作为 redis-stack-server Docker 镜像 的一部分进行加载。
它通过索引存储在 Redis 哈希数据结构中的向量来实现向量相似性搜索。这些哈希数据结构就像字段 - 值对,类似于字典或关联数组。处理哈希的常见 Redis 命令包括 HSET 和 HGET,我们可以先使用 HSET 存储嵌入向量,然后在其上创建一个带有架构的索引。需要注意的一点是,我们应该在存储嵌入向量之后再创建索引架构,否则会显著影响性能。
对于我们学习的包含大约 80 万文档的嵌入向量,这个过程大约需要 1 分钟。
查找和请求/响应
现在我们已经将数据存储在 Redis 中,我们可以在请求 - 响应周期内进行查找。这个过程如下所示:

由于我们将在网络应用的上下文中进行此操作,我们编写了一个小的 Flask 应用程序,该程序有几个路由,并捕获主页、搜索框和图像的相关静态文件,接收用户查询,将其通过创建的搜索索引对象进行清理后运行,并返回结果:
# this allows us to build a query string as well as use the search box@app.route("/search", methods=["POST", "GET"])def search() -> str:word = Noneif request.method == "POST":word = request.form.get("query", "")elif request.method == "GET":word = request.args.get("query", "")return get_model_results(word, retriever)
查看原始search_route.py 由 GitHub ❤ 托管
数据通过一个 KNN 搜索对象传递给模型,该对象接受一个 Redis 连接和一个配置帮助对象:
retriever = KNNSearch(RedisConnection().conn(), ConfigManager())conf = ConfigManager()def get_model_results(word: str, search_conn) -> str:data = search_conn.top_knn(word)return render_template("index.html", data=data, query=word)
搜索类 是大部分实际工作发生的地方。首先,用户查询字符串被解析和清理,尽管理论上,在 BERT 模型中,你应该可以原样发送文本,因为 BERT 最初是在不进行文本清理和解析的数据上训练的,与传统的自然语言处理不同。
然后,这些数据被重写为 Redis 查询语法的 Python 方言。搜索语法最初可能有点难以使用,无论是在 Python API 还是在 Redis CLI 上,所以我花了很多时间玩弄这个,弄清楚什么最有效,以及调整从配置文件中传入的超参数,例如结果数量、向量大小和浮点类型(确保所有这些超参数鉴于模型和向量输入都是正确的非常重要,否则这一切都无法正确工作。)
q = (Query(f"*=>[KNN {top_k} @{self.vector_field} $vec_param AS vector_score]").sort_by("vector_score", asc=False).sort_by(f"{self.review_count_field}", asc=False).paging(0, top_k).return_fields("vector_score",self.vector_field,self.title_field,self.author_field,self.link_field,self.review_count_field,).dialect(2))
HNSW 是最初在 Twitter 编写、在 Redis 中实现的算法,它实际执行查询以根据余弦相似度找到近似最近邻。它通过将最近邻问题表述为图搜索问题来寻找近似解决方案,从而能够大规模地找到最近邻。这里的原始解决方案意味着比较每个元素与其他元素,这一过程的计算成本与我们拥有的元素数量线性增长。HNSW 通过使用跳跃列表数据结构来创建多层链接列表来绕过这个问题,以跟踪最近的邻居。在导航过程中,HNSW 穿越图层以找到最短连接,从而找到给定点的最近邻居。
然后它返回按余弦相似度排名的最接近元素。在我们的案例中,它返回的是其 768 维向量与我们模型在查询时生成的 768 维向量最接近匹配的文档。
这个过程的最后一部分是过滤和排序。我们按余弦相似度降序排序,但还按评论数量排序 - 我们不仅想返回与查询相关的书籍,还想返回高质量的书籍,其中评论数量(有争议地)是人们已经阅读它们的一个代理指标。如果我们想要实验这一点,我们可以按余弦相似度然后按星级数量返回等。有多种方式可以进行微调。
打造合适的用户界面
当我们从 API 获得结果后,我们得到的是一个列表,其中包括书籍的标题、作者、余弦相似度和链接。我们的任务是将这些信息呈现给用户,确保他们对这些结果充满信心。此外,这些结果还应激发用户构建查询的兴趣。
研究发现,而且你可能也有这样的经验,当面对一个文本框时,特别是对于一个新的数据集,知道该搜索什么是非常困难的。此外,搜索结果页面的用户体验至关重要。这也是为什么像 Bard 和 OpenAI 这样的生成式 AI 产品经常提供使用建议或提示,以帮助用户更好地利用那个开放式搜索框。

我遇到的难题是如何让用户理解编写一条有效的基于语义而非直接搜索的 vibe 查询。我最初制作了一个相对简单的结果页面,上面显示了标题和排名。
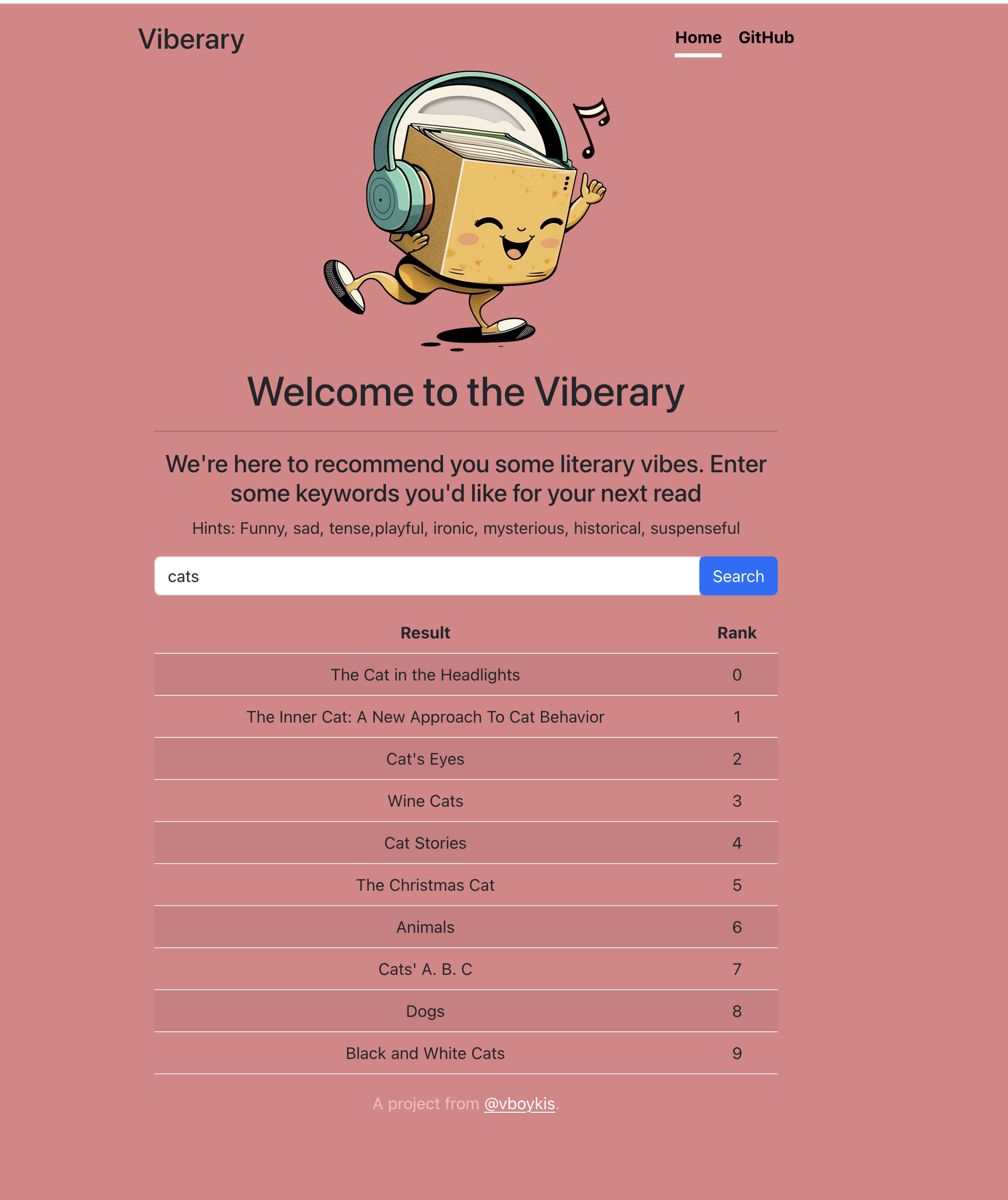
很快我发现这样做不够好:用户无法参考作者或查找书籍,而且对于不习惯零索引的非开发者来说,排名也令人困惑。于是,我在迭代中增加了书籍的链接,以便用户可以深入了解结果。

我取消了排名显示,因为它不仅让人迷惑,还需要更多的计算资源。而且,人们通常会认为最好的搜索结果会出现在最顶部。最后,我根据 Netflix 原创类别的列表,以及询问测试过应用的朋友的意见,添加了一些按钮建议用户如何编写查询。

除此之外,我还努力使网站在网页和移动端上都能快速加载,毕竟在 2023 年,大多数人首先使用移动设备访问网站。最后,我把网站的颜色调整为更浅的粉色,以增强可读性。至此,关于平面设计是我的激情这一部分的讨论就结束了。
DigitalOcean、Docker 与生产环境部署
在开发环境中一切顺利后,我开始着手将项目扩展到生产环境。我的核心需求包括:能够快速在本地进行开发并在生产实例中几乎完美复现这一环境;CI/CD 和 Docker 镜像的快速构建;在必要时能够水平扩展更多节点,但避免涉入自动伸缩或复杂的 AWS 方案;以及为 AI 应用制作体积更小的 Docker 镜像(这类应用的镜像往往因为 Cuda GPU 层而体积庞大,可达 10 GB)。考虑到我的数据集规模较小且应用在本地运行良好,我决定暂时使用基于 CPU 的操作,直到流量增长到需要调整的程度。
我遇到的另一个挑战是,在项目进行到一半时(绝对不推荐这么做),我换了一台 Macbook M2。这意味着我需要面对在arm和intel架构间保持代码一致性的全新挑战。
我的部署流程是这样的:Web 应用在一个 Docker 容器内开发,我通过 bind mounts 将其与本地目录链接,这样我可以在 PyCharm 中编写代码,并实时在 Docker 容器中看到变化。Web Docker 容器通过 Docker 的内部网络与 Redis 连接。Web 应用在主机的 8000 端口上可访问,在生产环境中 Nginx 代理 80 端口,使我们能够在不输入端口的情况下访问主域并访问 Viberary。在应用的 Dockerfile 中,我追求尽可能快的加载时间,因此我遵循了 Docker 最佳实践,将变化频繁的层放在最后,并通过缓存和文件挂载优化 Docker 镜像,避免频繁复制数据。
FROM bitnami/pytorchUSER rootENV PYTHONDONTWRITEBYTECODE 1ENV PYTHONUNBUFFERED 1COPY ../../requirements.txt requirements.txtRUN --mount=target=/var/lib/apt/lists,type=cache,sharing=locked \--mount=target=/var/cache/apt,type=cache,sharing=locked \rm -f /etc/apt/apt.conf.d/docker-clean \&& apt-get update \&& apt-get -y --no-install-recommends install \-y gitRUN --mount=type=cache,target=~/.cache/pip pip install -r requirements.txtRUN pip uninstall dataclasses -yRUN mkdir /viberary/data; exit 0RUN chmod 777 /viberary/data; exit 0ENV TRANSFORMERS_CACHE=/viberary/dataENV SENTENCE_TRANSFORMERS_HOME=/viberary/dataENV PYTHONPATH "${PYTHONPATH}:/viberary/src:/opt/bitnami/python/lib/python3.8/site-packages"ENV WORKDIR=/viberaryWORKDIR $WORKDIR
查看原文Dockerfile 由 GitHub 提供
Web 应用的 Docker 基础镜像为 bitnami:pytorch,它通过 requirements.txt 安装所需依赖。
我有两个 Dockerfile,一个用于本地环境,另一个用于生产环境。生产环境的 Dockerfile 通过 docker-compose 文件链接,并在 Digital Ocean 服务器上正确构建。本地的 Dockerfile 通过 docker-compose.override 文件链接,该文件不纳入版本控制,仅在本地环境工作,以确保每个环境都能得到适当的构建配置。
Docker Compose 使用这个 Dockerfile,并将其与 Redis 容器进行网络连接。
version: "3.8"services:redis:image: redis/redis-stack-server:latestvolumes:- redis-data:/datacontainer_name: rediscommand: redis-server --port 6379 --appendonly yes --protected-mode no --loadmodule /opt/redis-stack/lib/redisearch.so --loadmodule /opt/redis-stack/lib/rejson.soplatform: linux/amd64web:container_name: viberarybuild:context: .dockerfile: docker/prod/Dockerfileports:- "8000:8000"volumes:- ./:/viberary- ./viberary/src/training_data:/training_data- /mnt/viberary:/viberary/logsenvironment:- REDIS_HOST=redisdepends_on:- redisplatform: linux/amd64command: gunicorn -b 0.0.0.0:8000 -w 4 src.api.wsgi:app -t 900volumes:redis-data:
查看原文docker-compose.yml 由 GitHub 提供
所有这些都通过一个 Makefile 进行管理,其中包含构建、服务提供、关闭服务以及在目录根部运行 onnx 模型创建的命令。当我对代码满意并准备好推送时,我会将分支推送到 GitHub,GitHub Actions 会运行基本测试和代码静态检查。这些检查理论上已通过 pre-commit 钩子完成,包括 lint、代码格式化和清理工作,如 black、ruff 和 isort,在我将代码推送到分支之前。
一旦分支通过测试,我便将其合并到主分支。主分支会进行更多测试,并将最新的 git 提交推送到 Digital Ocean 服务器。接下来,我会手动进入服务器,先停止旧的 Docker 镜像,再启动新的镜像,以此来实现代码的实时更新。

最后,在服务器上,我使用了一个简单的 shell 脚本来配置额外的机器。由于我只需要配置两台机器,因此这个较为手动的方法目前还算可行。
# update machinesudo apt-get update# web app goes in wwwcd /var/www# Add Github keys# Sync with Github using keyhttps://docs.github.com/en/authentication/connecting-to-github-with-ssh/adding-a-new-ssh-key-to-your-github-account# Install nginx https://www.digitalocean.com/community/tutorials/how-to-install-nginx-on-ubuntu-20-04sudo apt updatesudo apt install nginx```server {listen 80;server_name ip address;access_log /var/log/nginx/access.log;error_log /var/log/nginx/error.log;root /var/www/src/api/static;location / {include uwsgi_params;uwsgi_pass unix:/var/www/viberary.sock;proxy_pass http://127.0.0.1:8000;}}`# 安装 Docker使用以下命令安装 Docker:```sudo apt install apt-transport-https ca-certificates curl software-properties-commoncurl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"apt-cache policy docker-cesudo apt install docker-cesudo systemctl status dockersudo apt-get install docker-compose-plugin```# 配置应用程序执行以下命令构建应用程序:```make build# 通过 Transformer 模型进行 SSH 连接scpmake up-intelmake embedvoila```# 配置指标和警报代理安装 DigitalOcean 的监控代理:```curl -sSL https://repos.insights.digitalocean.com/install.sh | sudo bashps aux | grep do-agent```
view rawspin_up.sh hosted with ❤ by GitHub
最后,我通过 nginx 将所有内容路由到了 80 端口,这是我在每个我在 DigitalOcean 上创建的虚拟服务器(droplet)中进行的设置。我使用负载均衡器,平衡了两个这样的虚拟服务器,它们指向同一个网址——一个我从 Amazon 的 Route 53 服务购买的域名。由于在同一供应商(Digital Ocean)管理 SSL(安全套接层)和 HTTPS(超文本传输安全协议)更为方便,我最终将这个域名转移了过去。
现在,我们有了一个运行中的应用程序。这个过程的最后一步是进行负载测试,我使用了 Python 的 Locust 库,它提供了一个友好的界面,可以针对你指定的任何端点运行各种代码。在负载测试的过程中,我发现我的模型响应缓慢,而搜索服务是需要即时结果的,因此我将它转换成了 ONNX(开放神经网络交换格式)制品,同时也对相关代码进行了修改。

最后,我编写了一个小型的日志模块,它在整个应用中传播,并在 docker compose 日志中跟踪记录所有活动。
关键收获
-
达到一个可测试的原型是关键。我在 Jupyter 笔记本中完成了所有初始的探索性工作,包括使用 Redis,这样我能直接看到每个单元格的数据输出。我坚信使用 REPL(交互式编程环境)能让你立即获得最快的结果。当我对所有数据类型和数据流程有了足够的了解后,我立即将代码转移到面向对象的、可测试的模块中。一旦你知道你需要结构,就立刻需要它,因为它会让你能更快速地使用可复用、模块化的组件进行开发。
-
向量大小和模型很重要。如果你不关注你的超参数,如果你为给定的机器学习任务选择了错误的模型,结果将会很糟糕,完全不起作用。
-
如果不必要,就不要使用云服务。我正在使用 DigitalOcean,这对于中等规模的公司和项目来说非常好,经常被忽视,优于 AWS 和 GCP。虽然我对云服务非常熟悉,但如果不必要,能够直接在服务器上做更多事情而不必使用 BigCloud 是很好的。DigitalOcean 提供合理的价格、合理的服务器,以及一些额外的功能,如监控、负载均衡和块存储,这些功能来自 BigCloud,但不会让你在选择上不知所措。他们最近还收购了 Paperspace,我之前用它来训练模型,因此应该有 GPU 集成。
-
DuckDB 正在成为处理高达 100GB 本地数据的稳定工具。由于它是一个正在发展的项目,还有很多问题需要解决。例如,有两个月我因为它缺乏我需要的正则表达式功能而不能用它来解析 JSON,这在 0.7.1 版本中得到了添加,所以使用时要谨慎。此外,由于它是嵌入式的,你一次只能运行一个进程,这意味着你不能同时运行命令行查询和笔记本。但它是一个快速处理数据的非常棒的工具。
-
使用 Docker 仍然需要时间 我在 Docker 上花费了大量时间。为什么 Docker 与我的本地环境不同?如何让镜像快速构建,为什么我的镜像现在有 3 GB 大小?人们对 CUDA 库是如何处理的(如果你一开始认为不需要,就排除它们)。我花了很多时间确保这个过程足够好,以免在重建数百次时感到沮丧。相关地,在项目进行中更换笔记本电脑的架构是不明智的。
-
部署到生产环境就像魔法一样,即使你是一个人的孤独团队。正如许多未知变量填满了部署过程,所以尽可能使你的环境完全可复制。
最后,
- 真正的语义搜索非常困难,涉及大量的算法微调,包括在机器学习、用户界面设计以及部署流程中。人们对 Google 进行了多年的微调。Netflix 拥有成千上万的标注员。每家公司都有团队在搜索和推荐方面工作,引导算法朝正确的方向发展。看看前 Twitter 公司的算法栈就知道了。最初的结果不太好也没关系。
重要的是要不断对当前模型与之前的模型进行基准测试,并不断迭代,继续构建。
引用
@inproceedings{DBLP:conf/recsys/WanM18,author = {Mengting Wan andJulian J. McAuley},editor = {Sole Pera andMichael D. Ekstrand andXavier Amatriain andJohn O'Donovan},title = {Item recommendation on monotonic behavior chains},booktitle = {Proceedings of the 12th {ACM} Conference on Recommender Systems, RecSys2018, Vancouver, BC, Canada, October 2-7, 2018},pages = {86--94},publisher = {{ACM}},year = {2018},url = {https://doi.org/10.1145/3240323.3240369},doi = {10.1145/3240323.3240369},timestamp = {Mon, 22 Jul 2019 19:11:02 +0200},biburl = {https://dblp.org/rec/conf/recsys/WanM18.bib},bibsource = {dblp computer science bibliography, https://dblp.org}}@inproceedings{reimers-2019-sentence-bert,title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",author = "Reimers, Nils and Gurevych, Iryna",booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",month = "11",year = "2019",publisher = "Association for Computational Linguistics",url = "https://arxiv.org/abs/1908.10084",}
查看原始文件citations.md - 由 GitHub 提供支持 ❤
推荐资源
- 《相关搜索》一书,作者 Turnbull 和 Berryman,可在此处查看。
- Corise 搜索基础课程 和 带机器学习的搜索 - 我亲自参加过,推荐 Grant 和 Daniel 的教学。课程代码在此。
- 什么是嵌入式技术 (Embeddings) - 本文在编写过程中引用了该网站和参考文献中的大量资源。
- 朝向个性化和语义检索的端到端电商搜索解决方案:通过嵌入式学习。
- 文本排名的预训练 Transformer:BERT 及其后续发展。
- 高级信息检索 Youtube 系列。